
У нас было 4 Amazon-аккаунта, 9 VPC и 30 мощнейших девелоперских окружений, стейджей, регрессий — всего более 1000 EC2 instance всех цветов и оттенков. Раз уж начал коллекционировать облачные решения для бизнеса, то надо идти в своем увлечении до конца и продумать, как все это автоматизировать.
Привет! Меня зовут Кирилл Казарин, я работаю инженером в компании DINS. Мы занимаемся разработкой облачных коммуникационных решений для бизнеса. В своей работе мы активно используем Terraform, с помощью которого мы гибко управляем нашей инфраструктурой. Поделюсь опытом работы с этим решением.
Статья длинная, поэтому запаситесь
И еще один нюанс — статья писалась на основе версии 0.11, в свежей 0.12 многое изменилось но основные практики и советы по прежнему актуальны. Вопрос миграции с 0.11 на 0.12 заслуживает отдельной статьи!
Что такое Terraform
Terraform — это популярный инструмент компании Hashicorp, который появился в 2014 году.
Эта утилита позволяет управлять вашей облачной инфраструктурой в парадигме Infrastructure as a Code на очень дружественном, легко читаемом декларативном языке. Его применение обеспечивает вам единый вид ресурсов и применение практик работы с кодом для управления инфраструктурой, которые за долгое время уже выработаны сообществом разработчиков. Terraform поддерживает все современные облачные платформы, позволяет безопасно и предсказуемо изменять инфраструктуру.
При запуске Terraform читает код и, используя представленные провайдерами облачного сервиса плагины, приводит вашу инфраструктуру к описанному состоянию, совершая необходимые вызовы к API.
Наш проект полностью находится в Amazon, развернут на базе AWS-сервисов, и поэтому я пишу о применении Terraformа именно в этом ключе. Отдельно замечу, что он может применяться не только для Amazon. Он позволяет управлять всем, у чего есть API.
Помимо этого мы управляем настройками VPC, IAM-политиками и ролями. Мы управляем таблицами маршрутизации, сертификатами, сетевыми ACL. Мы управляем настройками нашего web application firewall, S3-бакетами, SQS-очередями – всем, что может использовать наш сервис в Amazon. Я пока не встречал фичи у Amazon, которую нельзя было бы Terraform-ом описать с точки зрения инфраструктуры.
Получается немаленькая инфраструктура, руками это просто убьешься поддерживать. Но с Terraform это оказывается удобно и просто.
Из чего состоит Terraform
Провайдеры — это плагины для работы с API того или иного сервиса. Я насчитал их более 100. В их числе провайдеры для Amazon, Google, DigitalOcean, VMware Vsphere, Docker. Я даже нашел у них в этом официальном списке провайдера, который позволяет вам управлять правилами для Cisco ASA!
Помимо прочего вы можете управлять:
- Дашбордами, датасорсами и алертами в Grafana.
- Проектами в GitHub и GitLab.
- RabbitMQ.
- Базами данных, пользователями и правами в MySQL.
И это только официальные провайдеры, неофициальных провайдеров еще больше. В ходе экспериментов я натыкался на GitHub на сторонний, не включенный в официальный список провайдер, который позволял работать с DNS от GoDaddy, а также с ресурсами Proxmox.
В рамках одного Terraform проекта вы можете использовать разные провайдеры и, соответственно, ресурсы разных поставщиков услуг или технологии. Например, вы можете управлять инфраструктурой в AWS, с внешним DNS — от GoDaddy. А завтра ваша компания купила стартап который хостился в DO или Azure. И пока вы решаете мигрировать это в AWS или нет, вы также можете это поддержать с помощью того же инструмента!
Ресурсы. Это сущности облака, которые вы можете создавать, используя Terraform. Их список, синтаксис и свойства зависят от используемого провайдера, по сути — от используемого облака. Или не только облака.
Модули. Это сущности, при помощи которых Terraform позволяет вам шаблонизировать вашу конфигурацию. Тем самым шаблоны позволяют сделать ваш код меньше, позволяют переиспользовать его. Ну и помогают комфортно с ним работать.
Почему мы выбрали Terraform
Для себя мы выделили 5 основных причин. Возможно с вашей точки зрения не все они покажутся значимыми:
- Terraform — это
Сloud Agnosticmultiple cloud support утилита (спасибо за ценное замечание в комментариях). Когда мы выбирали этот инструмент, думали: — А что будет, если завтра или через неделю к нам придет менеджмент и скажет: "Ребята, а мы подумали — давайте-ка будем разворачиваться не только в Amazon. У нас есть какой-то проект, где нам нужно будет инфраструктуру завести в Google Cloud. Или в Azure — ну, мало ли". Мы решили, что нам хотелось бы иметь инструмент, который не будет жестко привязан к какому-либо облачному сервису. - Открытый код. Terraform — это опенсорсное решение. У репозитория проекта рейтинг больше 16 тысяч звезд, это неплохое подтверждение репутации проекта.
Мы не раз и не два сталкивались с тем, что в некоторых версиях бывают баги или не совсем понятное поведение. Наличие открытого репозитория позволяет убедиться в том, что это действительно баг, и мы можем решить проблему, просто обновив движок или версию плагина. Или что это баг, но «Ребята, подождите, буквально через два дня выйдет новая версия и мы его пофиксим». Или: «Да, это что-то непонятное, странное, с ним разбираются, но есть work-around». Это очень удобно. - Контроль. Terraform как утилита находится полностью под вашим контролем. Его можно установить на ноутбук, на сервер, он может быть легко встроен в ваш пайплайн, который может быть сделан на базе любого инструмента. Мы например используем его в GitLab CI.
- Проверка состояния инфраструктуры. Terraform умеет и хорошо проверяет состояния вашей инфраструктуры.
Предположим, вы начали использовать Terraform в своей команде. Вы создаете описание какого-то ресурса в Amazon, например Security Group, применяете — она у вас создается, все хорошо. И тут — бац! Ваш коллега, который вчера вернулся из отпуска и еще не в курсе, что вы тут все так красиво устроили, или вообще коллега из другого отдела заходит и настройки этой Security Group меняет ручками.
И не встретившись с ним, не пообщавшись, или не напоровшись потом на некую проблему, вы об этом в обычной ситуации никогда не узнаете. Но, если вы используете Terraform, даже прогон плана вхолостую по этому ресурсу покажет вам, что есть изменения в рабочей среде.
Когда Terraform просматривает ваш код, он параллельно с этим обращается к API облачного провайдера, получает от него состояние объектов и сравнивает: «А сейчас там то же самое, что я делал до этого, о чем я помню?» Потом сравнивает это с кодом, смотрит, что нужно еще изменить. И, например, если в его стейте, в его памяти, и в вашем коде всё одинаково, но там есть изменения — он вам покажет, и предложит его откатить. На мой взгляд, тоже очень хорошее свойство. Таким образом, это еще один шаг, лично для нас, к тому, чтобы получить иммутабельную инфраструктуру. - Еще одна очень важная фича — это модули, о которых я упоминал, и counts. Об этом я чуть попозже расскажу. Когда буду сравнивать с инструментами.
А также вишенка на торте: у Terraform-а есть довольно большой список встроенных функций. Эти функции, несмотря на декларативный язык, позволяют нам реализовать некоторую, не сказать чтобы программную, но логику.
Например, некоторые авто-вычисления, split строк, приведение к нижнему и верхнему кейсу, удаление символов этой строки. Мы это довольно активно используем. Они сильно облегчают жизнь, особенно когда вы пишите модуль, который потом будет переиспользован в разных окружениях.
Terraform vs CloudFormation
В сети часто сравнивают Terraform с CloudFormation. Мы тоже этим вопросом задавались, когда выбирали его. И вот результат нашего сравнения.
| Сравнение | Terraform | CloudFormation |
|---|---|---|
| Multiple cloud support | За счет использования различных провайдеров-плагинов может работать с любым крупным облачным провайдером. |
Жестко привязан к Amazon. |
| Отслеживание изменений | Если у вас произошло изменение не в коде TF, а на ресурсе, который он создал, TF сможет это обнаружить и позволит Вам исправить ситуацию |
Аналогичная функция появилась лишь в ноябре 2018 года. |
| Условия | Нет поддержки условий (только в виде тернарных операторов). |
Условия поддерживаются. |
| Хранение состояний |
Позволяет здесь выбрать несколько видов бэкэнда, например локально на вашей машине (это поведение по умолчанию), на файловой шаре, в S3 и где-нибудь еще. Это порой бывает полезно, потому что tfstate Terraform представлен в виде большого текстового файла JSON- подобной структурой. И бывает порой полезно в него залезть, почитать — и как минимум иметь возможность сделать его бекап, потому что мало ли что. Лично мне, например, спокойнее от того, что это находится в каком-то контролируемом мной месте. |
Хранение состояния только где-то внутри AWS |
| Импорт ресурсов | Terraform позволяет легко импортировать ресурсы. Вы можете взять все ресурсы под свой контроль. Вам достаточно написать код, который будет характеризовать этот объект, или использовать Terraforming. Она ходит в тот же Amazon, забирает оттуда информацию о стейте окружения и потом вываливает в виде кода. Он машинно-сгенерированный, не оптимизированный, но это хороший первый шаг чтобы начать миграцию. А потом вы просто даете команду на импорт. Terraform сравнит, заведет это в свое состояние окружение — и теперь он им управляет. |
CloudFormation такого не умеет. Если у вас что-то было сделано до этого руками, вы либо это грохнете и пересоздайте с помощью CloudFormation, либо живите так дальше. К сожалению, без вариантов. |
Как начать работу с Terraform
Вообще говоря, начать довольно просто. Вот кратко первые шаги:
- Прежде всего, создайте Git-репозиторий и сразу начните хранить там все ваши изменения, эксперименты, вообще всё.
- Прочитайте Getting-started guide. Он маленький, простенький, довольно подробный, хорошо описывает то, как вам начать работать с этой утилитой.
- Напишите немного демонстрационного, рабочего кода. Можно даже скопировать какой то пример чтобы потом с ним поиграться.
Наша практика работы с Terraform
Исходники
Вы начали ваш первый проект и храните все в одном большом main.tf файле. Вот типовой пример (честно взял первое попавшееся с GitHub).
Ничего плохого, но размер кодовой базы со временем имеет свойство расти. Так же растут зависимости между ресурсами. Через какое то время файл становится огромным, сложным, нечитаемым, плохо сопровождаемым — и неосторожным изменением в одном месте можно натворить бед.
Первое, что я рекомендую — выделить так называемый core-репозиторий, или core-стейт вашего проекта, вашего окружения. Как только вы начнете создавать инфраструктуру при помощи Terraform, или ее импортировать — вы сразу столкнетесь с тем, что у вас есть некоторые сущности, которые будучи один раз развернутыми, настроенными, крайне редко меняются. Например, это настройки VPC, или сам VPC. Это сети, базовые, общие Security-groups типа SSH-access — можно собрать довольно большой список.
Нет смысла держать это в том же репозитории, что и сервисы, которые вы часто меняете. Выделите их в отдельный репозиторий и состыкуйте через такую фичу Terraformа, как remote state.
- Вы уменьшаете кодовую базу того участка проекта, с которым вы часто работаете непосредственно.
- Вместо одного большого tfstate-файла, который хранит в себе описание состояния вашей инфраструктуры два файла меньшего размера, и в конкретный момент времени вы работаете с одним из них.
В чем тут хитрость? Когда Terraform строит план, то есть обсчитывает, калькулирует то, что он должен изменить, применить — он пересчитывает полностью этот стейт, сверяется с кодом, сверяется с состоянием в AWS. Чем ваш стейт больше, тем план будет дольше строиться.
Мы пришли к этой практике тогда, когда у нас построение плана на все окружение в продакшене стал занимать 20 минут. За счет того, что мы вытащили в отдельный core всё, что мы не подвержено частым изменениям, мы сократили время построения плана вдвое. У нас есть идея, как это можно сократить дальше, разбив уже не только на core и non-core, но еще и по подсистемам, потому что они у нас связаны и обычно меняются вместе. Тем самым мы, скажем, 10 минут превратим в 3. Но мы пока в процессе реализации такого решения.
Кода меньше — читать легче
С небольшим кодом легче разобраться и удобнее работать. Если у вас большая команда и в ней люди с разным уровнем опыта — вынесите то, что вы меняете редко, но глобально, в отдельную репу, и предоставьте к ней более узкий доступ.
Скажем, у вас в команде есть джуниоры, и вы не даете им доступ к глобальному репозиторию, в котором описаны настройки VPC — так вы себя страхуете от ошибок. Если инженер допустит ошибку в написании инстанса, и что-то будет создано не так — это не страшно. А если он допустит ошибку в опциях, которые ставятся на все машинки, поломает, или что-то сделает с настройками подсетей, с роутингом — это куда болезненней.
Выделение core-репозитория происходит в несколько шагов.
Этап 1. Создайте отдельный репозиторий. Храните в нем весь код, отдельно — и описываете те сущности, которые должны быть переиспользованы в стороннем репозитории при помощи такого вывода. Скажем, мы создаем ресурс AWS subnet, в котором описываем, где он располагается, какая зона доступности, адресное пространство.
resource "aws_subnet" "lab_pub1a" { vpc_id = "${aws_vpc.lab.id}" cidr_block = "10.10.10.0/24" Availability_zone = "us-east-1a" ... } output "sn_lab_pub1a-id" { value = "${aws_subnet.lab_pub1a.id}" }
А потом говорим, что мы в output отправляем id этого объекта. Можно сделать по output на каждый параметр, который вам необходим.
В чем здесь хитрость? Когда вы описываете значение, Terraform отдельно сохраняет его в tfstate core. И когда вы будете к нему обращаться, ему не нужно будет синхронизировать, пересчитать — он сможет сразу из этого стейта вам это дело отдать. Дальше, в репозитории, который non-core, вы описываете такую связь с удаленным state: у вас есть remote state такой-то, он лежит в S3-bucket таком-то, такой-то ключ и регион.
Этап 2. В non-core проекте создаем ссылку на стейт core проекта, чтобы мы могли обратиться к экспортированным через output параметрам.
data "terraform_remote_state" "lab_core" { backend = "s3" config { bucket = "lab-core-terraform-state" key = "terraform.tfstate" region = "us-east-1" } }
Этап 3. Начинаем использовать! Когда мне нужно развернуть новый сетевой интерфейс для инстанса в какой-то конкретной подсетке, я говорю: вот data remote state, в нем найди имя этого стейта, в нем найди вот этот вот параметр, который, собственно, совпадает, вот с этим именем.
resource "aws_network_interface" "fwl01" { ... subnet_id = "${data.terraform_remote_state.lab_core.sn_lab_pub1a-id}" }
И когда я буду строить план изменений в моем не core-репозитории, вот это значение для Terraform станет для него константой. Если вы захотите его изменить — придется делать это в репозитории вот этого конечно, core. Но так как это меняется редко, то это особо вас не тревожит.
Модули
Напомню что модуль — это самодостаточная конфигурация, состоящая из одного или более связанных ресурсов. Она управляется как группа:
Модуль — это крайне удобная вещь в силу того, что вы редко создаете один ресурс просто так, в вакууме, обычно он с чем-то логически связан.
module "AAA" { source = "..." count = "3" count_offset = "0" host_name_prefix = "XXX-YYY-AAA" ami_id = "${data.terraform_remote_state.lab_core.ami-base-ami_XXXX-id}" subnet_ids = ["${data.terraform_remote_state.lab_core.sn_lab_pub1a-id}", "${data.terraform_remote_state.lab_core.sn_lab_pub1b-id}"] instance_type = "t2.large" sgs_ids = [ "${data.terraform_remote_state.lab_core.sg_ssh_lab-id}", "${aws_security_group.XXX_lab.id}" ] boot_device = {volume_size = "50" volume_type = "gp2"} root_device = {device_name = "/dev/sdb" volume_size = "50" volume_type = "gp2" encrypted = "true"} tags = "${var.gas_tags}" }
Например: когда мы разворачиваем новый EC2-инстанс, мы делаем для него сетевой интерфейс и attachment, мы часто делаем для него Elastic IP-адрес, мы делаем route-53 запись, и что-то еще. То есть, у нас как минимум получаются 4 сущности.
Каждый раз описывать их четырьмя кусками кода неудобно. При этом они довольно типовые. Напрашивается — сделай шаблон, и потом просто обращайся к этому шаблону, передавая в него параметры: какое-нибудь имя, в какую сетку запихнуть, какую на него навесить секьюрити-группу. Это очень удобно.
В Terraform есть фича Count, это позволяет еще сильнее сократить ваш стейт. Можно одним куском кода описать большую пачку инстансов. Скажем, мне нужно развернуть 20 однотипных машин. Я не буду писать 20 кусков кода даже из шаблона, я напишу 1 кусочек кода, укажу в нем Count и число — сколько мне нужно сделать.
Например, есть некоторые модули, которые ссылаются на шаблон. Я передаю только специфические параметры: ID subnet; AMI, с которой развернуть; тип инстанса; настройки секьюрити-групп; что-нибудь еще, и указываю, сколько мне таких штук сделать. Отлично, взял их и развернул!
Завтра ко мне приходят разработчики и говорят: «Слушай, мы хотим поэкспериментировать с нагрузкой, дай нам, пожалуйста, еще два таких». Что мне нужно сделать: я одну цифру меняю на 5. Объем кода остается ровно тем же самым.
Условно можно модули разделить на два типа — ресурсные и инфраструктурные. С точки зрения кода отличия нет, это скорее более высокоуровневые понятия, которые вводит сам оператор.
Ресурсные модули дают шаблонизированную и параметризованную, логически связанную совокупность ресурсов. Пример выше — это типичный ресурсный модуль. Как с ними работать:
- Указываем путь к модулю — источник его конфигурации, через директиву Source.
- Указываем версию — да, и эксплуатация по принципу “latest and greatest” тут не лучший вариант. Вы же не включаете каждый раз в свой проект последнюю версию библиотеки? Но об этом чуть позже.
- Передаем в него аргументы.
Мы привязываемся к версии модуля, и берем просто последнюю — инфраструктура должна быть версионной (ресурсы не могут быть версионными, а код может). Ресурс может быть создан удален или пересоздан. Все! Так же мы должны четко знать, какой версии у нас создан каждый кусок инфраструктуры.
Инфраструктурные модули довольно просты. Они состоят из ресурсных, и включают стандарты компании (например теги, списки стандартных значений, принятые дефолты и так далее).
Что касается нашего проекта и нашего опыта — мы давно и прочно перешли на использование ресурсных модулей для всего, чего только можно, с очень жестким процессом версионирования и ревью. И сейчас активно внедряем практику инфраструктурных модулей на уровне лаб и стейджинга.
Рекомендации по использованию модулей
- Если можете не писать, а использовать готовые — не пишите. Особенно если в этом вы новичок. Доверьтесь готовым модулям или хотя бы посмотрите как это сделали до вас. Однако, если у вас все же есть необходимость писать свое — не используйте внутри обращение к провайдерам и будьте аккуратны с провиженерами.
- Проверьте, что Terraform Registry не содержит уже готовый ресурсный модуль.
- Если пишете свой модуль — спрячьте специфику под капот. Конечный пользователь не должен волноваться о том, что и как вы реализуете внутри.
- Делайте input параметров и output значений из вашего модуля. И лучше, если это будут отдельные файлы. Так удобней.
- Если пишите свои модули — храните их в репозитории и версионируйте. Лучше отдельный репозиторий под модуль.
- Не используйте локальные модули — они не версионируемые и не переиспользуемые.
- Избегайте использования описания провайдеров в модуле, потому что подключение credentials может быть настроено и применяться по разному у разных людей. Кто-то использует переменные окружения для этого, а кто то подразумевает хранение своих ключей и секретов в файлах с прописыванием путей для них. Это надо указывать уровнем выше.
- Осторожно используйте local provisioner. Он исполняется локально, на той машине, на которой запускается Terraform, но среда исполнения у разных пользователей может быть разная. До тех пор пока вы не встроите это в CI, вы можете натыкаться на различные артефакты: например local exec и запуск ansible. А у кого-то другой дистрибутив, другой shell, другая версия ansible, или вообще Windows.
Признаки хорошего модуля (вот чуть подробнее):
- Хорошие модули имеют документацию и описание примеров. Если каждый оформлен в виде отдельного репозитория — это легче сделать.
- Не имеют жестко заданных значений параметров (например регион AWS).
- Используют разумные значения по умолчанию, оформленные в виде defaults. Например модуль для EC2 инстанса по умолчанию не будет создавать вам виртуальную машину с типом m5d.24xlarge, использует для этого что-то из минимальных t2 или t3 типов.
- Код «чист» — структурирован, снабжен комментариями, не запутан излишне, оформлен в едином стиле.
- Очень желательно чтобы он был снабжен тестами, хоть это и сложно. К этому мы к сожалению, еще сами не пришли.
Тегирование
Теги — это важно.
Тегирование — это биллинг. У AWS есть инструменты, которые позволяют вам посмотреть, сколько денег вы тратите на свою инфраструктуру. И нашему менеджменту очень хотелось иметь инструмент, в котором они могли это посмотреть детерминировано. Например, сколько денег потребляют такие-то компоненты, или такая-то подсистема, такая-то команда, такое-то окружение
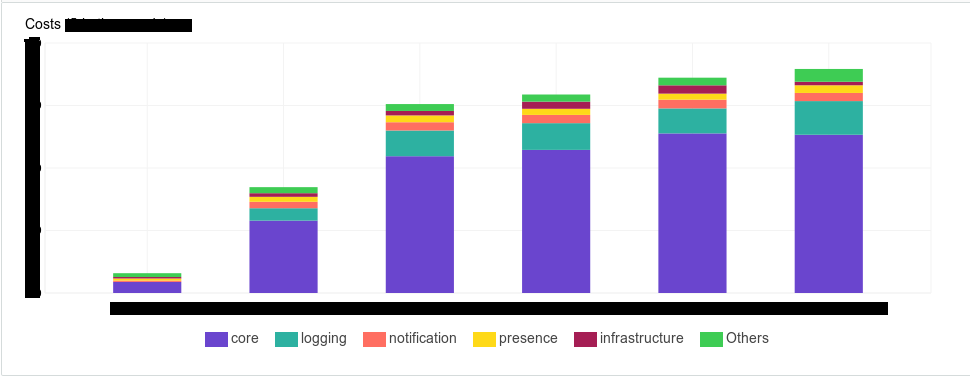
Тегирование — это документирование вашей системы. С его помощью вы упростите себе поиск. Даже просто в AWS-консоли, где эти теги аккуратненько выведены себе на экран — вам становится проще понимать, к чему относится тот или иной тип инстанса. Если приходят новые коллеги, вам проще это объяснить, показав: «Смотри, это вот — сюда». Мы начинали создавать тэги следующим образом — создавали массив тегов для каждого вида ресурсов.
Пример:
variable "XXX_tags" { description = "The set of XXX tags." type = "map" default = { "TerminationDate" = "03.23.2018", "Environment" = "env_name_here", "Department" = "dev", "Subsystem" = "subsystem_name", "Component" = "XXX", "Type" = "application", "Team" = "team_name" } }
Так получилось, что у нас в компании не одна наша команда использует AWS, и есть некоторый список обязательных тегов.
- Team — какая команда использует сколько ресурсов.
- Department — аналогично с департаментом.
- Environment — ресурсы бьются по «окружениям», но вы, например, можете заменить его на проект или что то подобное.
- Subsystem — подсистема к которой относится компонент. Компоненты могут относиться к одной подсистеме. Например, мы хотим посмотреть, сколько у нас эта подсистема и ее сущности стали потреблять. Вдруг она, допустим, за предыдущий месяц сильно выросла. Нам нужно прийти к разработчикам и сказать: «Ребята, дорого стоит. Бюджет вот уже впритык, давайте уже как-то оптимизировать логику».
- Type — тип компонента: балансировщик, хранилище, приложение или база данных.
- Component — сам компонент, его название во внутренней нотации.
- Termination date — время когда он должен быть удален, в формате даты. Если его удаление не предвидится, ставим “Permanent”. Мы ввели его, потому что в девелоперских окружениях, и даже в некоторых стейджовых у нас есть стейдж для стресс-тестирования, который поднимается на стресс-сессии, то есть мы не держим эти машинки регулярно. Мы указываем дату, когда ресурс должен быть уничтожен. Дальше к этому можно прикрутить автоматизацию на базе лямбды, каких-то внешних скриптов, которые работают через AWS Command Line Interface, которые будут по крону уничтожать эти ресурсы автоматически.
Теперь — том, как тегировать.
Мы решили, что будем делать для каждого компонента свою тег-мапу, в которой будем перечислять все указанные теги: когда его терминировать, к чему относится. Очень быстро поняли, что это неудобно. Потому что кодовая база у нас растет, поскольку у нас больше 30 компонент, и 30 таких кусков кода — неудобно. Если нужно что-то поменять, то бегаешь и меняешь.
Чтобы хорошо тегировать, мы используем сущность Locals.
locals { common_tags = {"TerminationDate" = "XX.XX.XXXX", "Environment" = "env_name", "Department" = "dev", "Team" = "team_name"} subsystem_1_tags = "${merge(local.common_tags, map("Subsystem", "subsystem_1_name"))}" subsystem_2_tags = "${merge(local.common_tags, map("Subsystem", "subsystem_2_name"))}" }
В ней вы можете перечислить подмножество, и потом их друг с другом использовать.
Например, мы вынесли некоторые common-теги вот в такую структуру, и дальше — специфичные, по подсистемам. Мы говорим: «Возьми вот этот блок и в него добавь, например, subsystem 1. А для подсистемы 2 добавь subsystem 2». Мы говорим: «Теги, возьми, пожалуйста, общие и к ним добавь type, application, имя, component и кто такой». Получается очень кратко, наглядно и централизованное изменение, если вдруг это потребуется.
module "ZZZ02" { count = 1 count_offset = 1 name = "XXX-YYY-ZZZ" ... tags = "${merge(local.core_tags, map("Type", "application", "Component", "XXX"))}" }
Контроль версий
Ваши модули-шаблоны, если будете их использовать, должны где-то храниться. Самый простой путь, с которого, скорее всего, все начинают — локальное хранение. Просто в том же каталоге, просто некоторый подкаталог, в котором вы описываете, например, шаблон для какого-то вида сервиса. Это не очень хороший путь. Это удобно, это можно быстро поправить и быстро протестировать, но это сложно потом переиспользовать и сложно контролировать
module "ZZZ02" { source = "./modules/srvroles/ZZZ" name = "XXX-YYY-ZZZ" }
Предположим, к вам пришли разработчики и сказали: «Так, нам нужна такая-то сущность в такой-то конфигурации, в нашей инфраструктуре». Вы это написали, сделали в виде локального модуля в репозитории их проекта. Развернули — отлично. Они потестили, сказали: «Пойдет! В продакшн». Приходим в стейдж, стресс-тестирование, продакшн. Каждый раз Ctrl-C, Ctrl-V; Ctrl-C, Ctrl-V. Пока мы добрались до прода, наш коллега взял, скопировал код из лабораторного окружения, перенес в другое место и там поменял. И у нас получается уже несогласованное состояние. При горизонтальном масштабировании, когда у вас столько лабораторных окружений, сколько у нас — это просто адище.
Поэтому хороший путь — заводить под каждый ваш модуль отдельный Git-репозиторий, и потом просто на него ссылаться. Меняем всё в одном месте — хорошо, удобно, контролируемо.
module "ZZZ" { source = "git::ssh://git@GIT_SERVER_FQDN/terraform/modules/general-vm/2-disks.git" host_name_prefix = "XXX-YYY-ZZZ"
Упреждая вопрос, как же ваш код доезжает до продакшена. Для этого создается отдельный проект, который переиспользует подготовленные и проверенные модули.
Отлично, у нас один источник кода, который централизованно меняется. Я взял, написал, подготовил и поставил себе, что завтра с утра иду разворачивать в продакшн. Построил план, протестировал — отлично, идем. В этот момент мой коллега, руководствуясь исключительно благими побуждениями, пошел и что-то оптимизировал, добавил в этот модуль. И так получилось, что эти изменения ломают обратную совместимость.
Например, он добавил необходимые параметры, которые обязан передать, иначе модуль не соберется. Или он поменял названия этих параметров. Я прихожу с утра, у меня время для изменений строго ограничено, начинаю строить план, и Terraform подтягивает стейт-модули с Git-а, начинает строить план и говорит: «Упс Не могу. Не хватает у тебя, ты переименовал». Я удивляюсь: «Да я же этого не делал, как с этим быть?» А если это ресурс, который создан давно, то после подобных изменений придется пробегать по всем окружениям, как-то менять и приводить к одному виду. Это неудобно.
Это можно поправить, используя Git tags. Мы для себя решили, что будем использовать SemVer-нотацию и выработали простое правило: как только конфигурация нашего модуля достигает некоего стабильного состояния, то есть мы можем это использовать, мы на этот коммит вешаем тег. Если мы вносим изменения и они не ломают обратную совместимость, мы у тега меняем минорный номер, если ломают — меняем мажорный номер.
Так в адресе source привязаться к конкретному тегу и если хотя бы обеспечить что-то, что у вас собиралось раньше — будет собираться всегда. Пусть версия модуля уехала вперед, но в нужный момент мы придем, и когда нам это действительно нужно — поменяем. А то, что и до этого было работающим, хотя бы не сломается. Это удобно. Вот так примерно это выглядит у нас в GitLab.
Ветвление
Использование ветвления — еще одна важная практика. Мы для себя выработали правило, что изменения ты должен вносить только из мастера. Но на любое изменение, которое ты хочешь сделать и протестировать — сделай, пожалуйста, отдельную ветку, поиграй с ней, поэкспериментируй, построй планы, посмотри, как собирается. А потом сделай merge-request, и пусть коллега посмотрит на код и поможет.
Где хранить tfstate
Не стоит хранить ваш стейт локально. Не стоит хранить ваш стейт в Git-е.
Мы на этом обожглись, когда у кого-то при раскатывании веток не-мастера получается свой tfstate, в котором сохранено состояние — потом он это включает через merge, кто-то добавляет свой, получаются merge-конфликты. Или получается без них, но несогласованное состояние, потому что «у него уже есть, у меня еще нет», и потом все это сидеть исправлять — это неприятная практика. Поэтому мы решили, что будем хранить это в надежном месте, версионируемом, но это будет вне Git-а.
Под это отлично подходит S3: он доступен, у него HA, насколько я помню четыре девятки точно, может быть, пять. Из коробки он дает версионированость, если даже вы свой tfstate сломаете — всегда можно откатиться. И еще он дает очень важную вещь в сочетании с DynamoDB, этому Terraform научился, по-моему, с версии 0.8. В DynamoDB вы заводите табличку, в которой Terraform записывает информацию о том, что он блокирует стейт.
То есть, предположим, я хочу внести какие-то изменения. Начинаю строить план или начинаю его применять, Terraform идет в DynamoDB и говорит, что он в этой табличке вносит информацию о том, что этот state заблокирован; пользователь, компьютер, время. В этот момент мой коллега, который работает удаленно или, может быть, в паре столов от меня, но сосредоточен на работе и не видит, что я делаю, тоже решил, что нужно что-то изменить. Он строит план, но запускает его чуть позже.
Terraform идет в динамку, видит — Lock, обламывается, сообщает пользователю: «Извини, tfstate заблокирован тем-то». Коллега видит, что я сейчас работаю, может ко мне подойти и сказать: «Слушай, у меня чейндж важнее, уступи мне, пожалуйста». Я говорю: «Хорошо», отменяю построение плана, снимаю блок, скорее даже, он автоматически снимается, если вы это делаете корректно, не прерывая по Ctrl-C. Коллега идет и делает. Тем самым мы страхуем себя от ситуации, когда вы вдвоем что-то меняете.
Merge-request
Мы используем ветвление в Git-е. Мы назначаем наши merge-request-ы на коллег. Более того, в Gitlab мы используем практически все доступные нам инструменты для совместной работы, для merge-request-ов или даже просто каких-то пулов: обсуждение вашего кода, его ревью, выставление in-progress или issue, еще чего-то подобного. Это очень полезно, это помогает в работе.
Плюс, в этом случае rollback тоже получается легче, можно вернуться на предыдущий коммит или, если вы, скажем, решили, что будете не только из мастера применять изменения, можно просто переключиться на стабильную ветку. Например, вы сделали ветку с фичей и решили, что будете вносить изменения сначала из фичевой ветки. А потом уже изменения, после того, как все хорошо сработало, вносить в мастер. Вы в своей ветке применили изменения, поняли, что что-то не то, переключились на мастер — никаких изменений нет, сказали apply — он вернулся.
Пайплайны
Мы решили что нам необходимо использовать CI процесс для применения наших изменений. Для этого на базе Gitlab CI мы пишем пайплайн, который автоматизирует применение изменений. Пока что у нас их два вида:
- Пайплайн для мастер веток (master pipeline)
- Пайплайн для всех прочих веток (branch pipeline)
Что делает бранч пайплайн? Он запускает автоматическую верификацию кода (тупо проверку на опечатки, например). А потом запускает построение плана. И коллега, который будет смотреть ваш merge-request, сразу может открыть построившийся план и увидеть не только код — а также то, что вы добавляете. Еще он увидит как это ляжет на вашу инфраструктуру. Это наглядно и полезно.

В мастере сюда добавляется еще один шаг. Отличие в том, что у вас план не просто генерируется, он еще и сохраняется в виде артефакта. Еще одна очень полезная фича Terraform-а в том, что план можно сохранить в виде файла, и потом применить его. Скажем, вы сделали merge-request и его отложили. Через месяц про него вспомнили и решили вернуться. У вас код уже далеко уехал вперед. За счет того, что вы храните у себя артефакт плана, вы можете применить именно его и на то, что вы хотели в тот момент.

В нашем случае этот артефакт потом передается на следующий шаг, который выполняется руками. То есть мы получаем единую точку применения наших изменений.
Недостатки Terraform
Функции. Несмотря на то что у Terraformа довольно большое число встроенных функций, не все из них так хороши, как нам хотелось бы думать.
Есть в нем неудобные функции, например «Элемент» — у нее в некоторых ситуациях при нехватке опыта поведение может быть не совсем тем, которое вы ожидали.
Например, вы используете модуль, в модуль передается count — сколько развернуть инстансов, и передается, скажем, список подсетей, разбитых по availability-зонам. Передали, применили, увеличили каунт, еще применили. А теперь вы решили передать в него увеличенный список подсетей. У вас появилась сетка, вы еще одну AZ решили задействовать. У вас меняется вторая часть списка, а count с этим списком сопоставляется через элемент.
Скажем, у вас было 4 AZ до этого и 5 инстансов, а потом вы добавили еще одну AZ — он первые 4, которые уже были по порядку, оставит. А про пятую скажет: «А сейчас я ее пересоздам». А вы не хотели! Вы хотели, чтобы у вас только новые приезжали. Такие баги происходят из за особенностей работы Terraform со списками.
Тернарный оператор. Условие — только тернарный оператор. Нам действительно не хватает условий. Хотелось бы все-таки какие-то более привычные If и Else. Жаль, что их нет — возможно, подвезут.
Сложности командной работы. Если у вас большая команда, или большой проект, на большое число окружений, или и то и другое, Terraform-ом вам становится сложновато пользоваться, не применив некоторый CI.
Без CI вы будете вносить изменения из своих локальных окружений со своего компьютера. По нашему опыту это ведет к тому, что вы ветку у себя сделали, завели, поэкспериментировали с ней — и забыли сделать merge, забыли запушить изменения. Это больно.
Например, у вас с коллегой были одинаковые версии на машинах. Потом коллега у себя обновил на единичку версию. Вы на следующий день приходите, начинаете вносить изменения, Terraform идет свериться, видит, что в tfstate требуемая версия Terraformа выше и говорит: «Нет, не могу, обнови меня». Когда у тебя маленькое окно для внесения изменений, то непросто увидеть, что тебе сначала нужно обновить утилиту.
Когда у вас есть CI, есть некоторая единая сущность, например в вашем pipeline контейнер — вы себя страхуете, что у вас не будет такого разъезжания версий утилиты.
Ну и наконец, в мастере может накапливаться сломанный или неиспользованный код. Вам будет каждый раз со своего места лень ждать, пока построится план на все окружение. Вы придете к тому, что будете стараться строить через опцию target применение только на то, что вы изменили. Например, вы добавили некоторый инстанс и говорите: «Terraform apply target instance», или секьюрити-груп. Но в таком случае если у вас что-то сломалось (скажем, устарела какая-то конфигурация), при построении полного плана вы бы это увидели.
Вам придется потратить довольно много сил и времени на то, чтобы привести это в актуальное состояние. Не нужно до такого доводить. Если есть CI — в нем мы просто принудительно говорим, что Terraform будет строить план полностью, вы запушили изменения. И пусть он свой план строит, вы пошли и занялись чем-то еще. Он построил, вы увидели, он у вас есть в виде артефакта, и вы пошли его применять. Это дисциплинирует.
Terraform — не серебряная пуля
Что он не позволит вам сделать:
- Terraform не позволяет вам описать зависимость между модулями, если они логически на одном уровне. С чем, например, столкнулись мы. У нас есть модуль, описывающий набор некоторых инстансов со всеми сопутствующими параметрами, и есть модуль, который описывает балансировщик. Когда мы хотим одно с другим состыковать, то на вход модуля, описывающего балансировщик, подаем из первого модуля с инстансами генерируемый список айдишников.
Так вот, пока вы не создали инстанс — этот список еще не появился в Tfstate, и модуль с балансировщиками не сможет собраться, потому что ему нечего будет к себе стыковать. То есть вам придется разворачивать это в два прохода. Сделать зависимость «сначала разверни этот модуль, а потом этот модуль» — не получается.
Мы сейчас пытаемся это реализовать за счет того что разбиваем нашу инфраструктуру по подсистемам и пишем модуль, во-первых, для ресурса, а во-вторых — модуль для подсистемы. Как раз те самые инфраструктурные модули, в которых уже модули как бы стыкуем на одном уровне. Пока не могу ничем похвастаться, мы лишь обкатываем это решение в лабе и первое с чем столкнулись из неприятного — сложно разрешаемые зависимости версий. - Terraform может успешно построить план, но этот план успешно не применяется. И Terraform в этом не виноват. Почему? Потому что он не отслеживает число свободных айпишников в ваших подсетях, которые у вас остались. Он не может его добыть. Например, он не отслеживает, что в некоторых AZ у вас нет каких-то инстанс-типов. Скажем, мы используем North Virginia, и там сейчас есть 6 зон доступности. В одной из них точно доступны не все типы инстансов. Мы с этим столкнулись, выясняли с техподдержкой, они сказали: «Да, это временное явление». Но до какого момента это будет — непонятно. Опять же — план у нас при этом строится, всё хорошо, Terraform ничего об этом не знает.
- Terraform ничего не знает про ваши лимиты в Амазоне. Скажем, у вас лимит — 200 машин, из них уже 198 развернули, хотите развернуть еще 5. План он вам построит. Но при выполнении плана он сделает две, а еще на три вернет вам ошибку от API Амазона. Увы.
- Также он не может учесть, что некоторые имена должны быть уникальными. Например, вы хотите сделать S3 bucket. Это глобальный сервис на регион, и даже если в вашем аккаунте вы не создавали сервис с таким именем — не факт, что его не создал кто-то другой. И когда вы будете его создавать с помощью Terraform – он прекрасно построит план, начнет его создавать, а Амазон скажет: «Извини, у кого-то это уже есть». Заранее этого не предусмотреть никак. Только если руками пытаться заранее как-то это сделать, хотя это идет вразрез с практикой.
В любом случае, Terraform — лучшее, что есть сейчас. И мы продолжаем это использовать, он очень сильно нам помогает.

