Предлагаю ознакомиться с расшифровкой доклада Александра Сигачева Service Discovery в распределенных системах на примере Consul.
Service Discovery создан для того, чтобы с минимальными затратами можно подключить новое приложение в уже существующее наше окружение. Используя Service Discovery, мы можем максимально разделить либо контейнер в виде докера, либо виртуальный сервис от того окружения, в котором он запущен.
Я всех приветствую! Я Сигачев Александр, работаю в компании Inventos. И сегодня я вас познакомлю с таким понятием как Service Discovery. Рассмотрим мы Service Discovery на примере Consul.
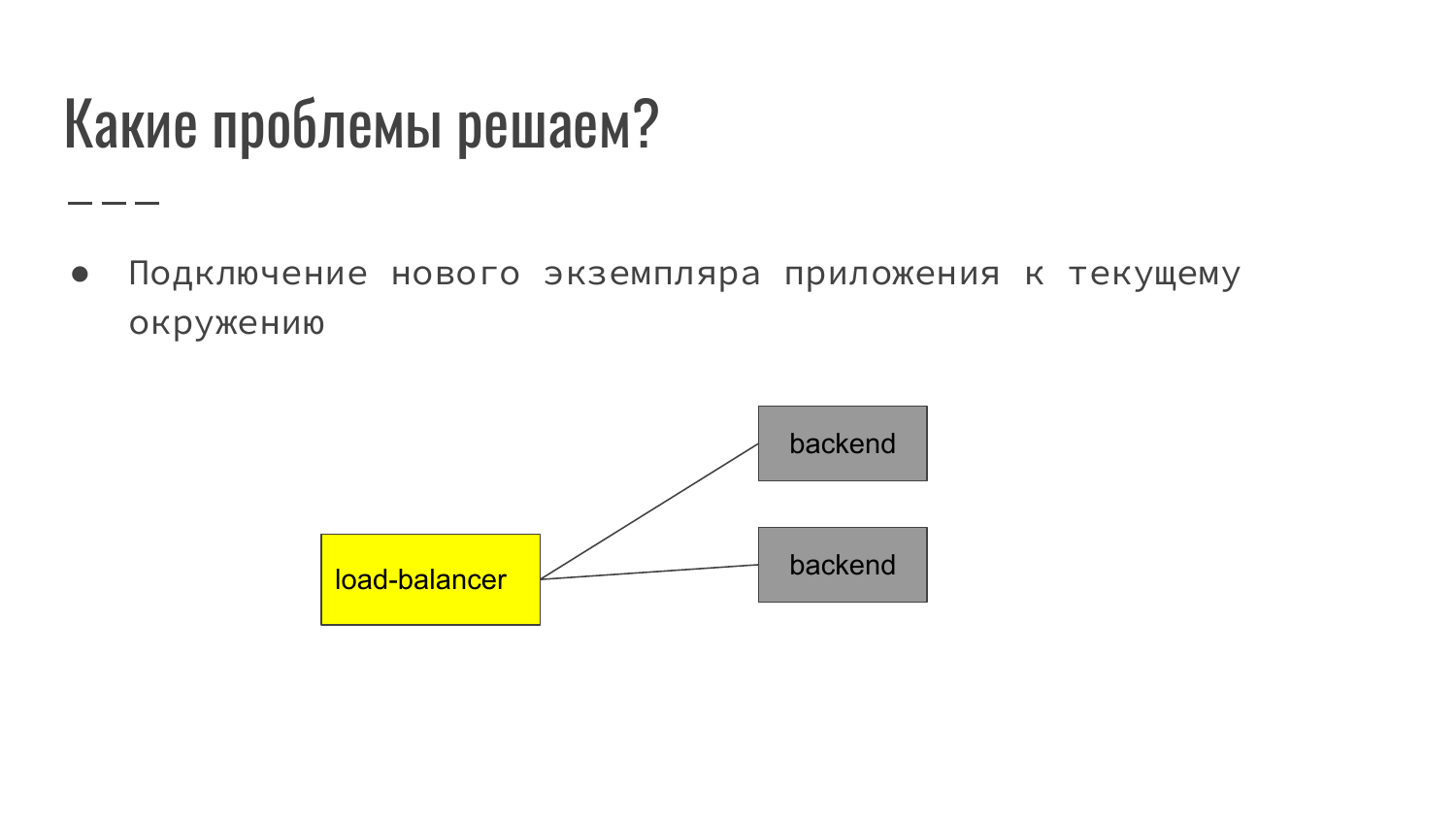
Какие проблемы решает Service Discovery?
Service Discovery создан для того, чтобы с минимальными затратами можно подключить новое приложение в уже существующее наше окружение. Используя Service Discovery, мы можем максимально разделить либо контейнер в виде докера, либо виртуальный сервис от того окружения, в котором он запущен.
Как это выглядит? На классическом примере в вебе – это фронтенд, который принимает запрос пользователя. Дальше выполняет маршрутизацию его на backend. На данном примере – это load-balancer балансирует на два backend.
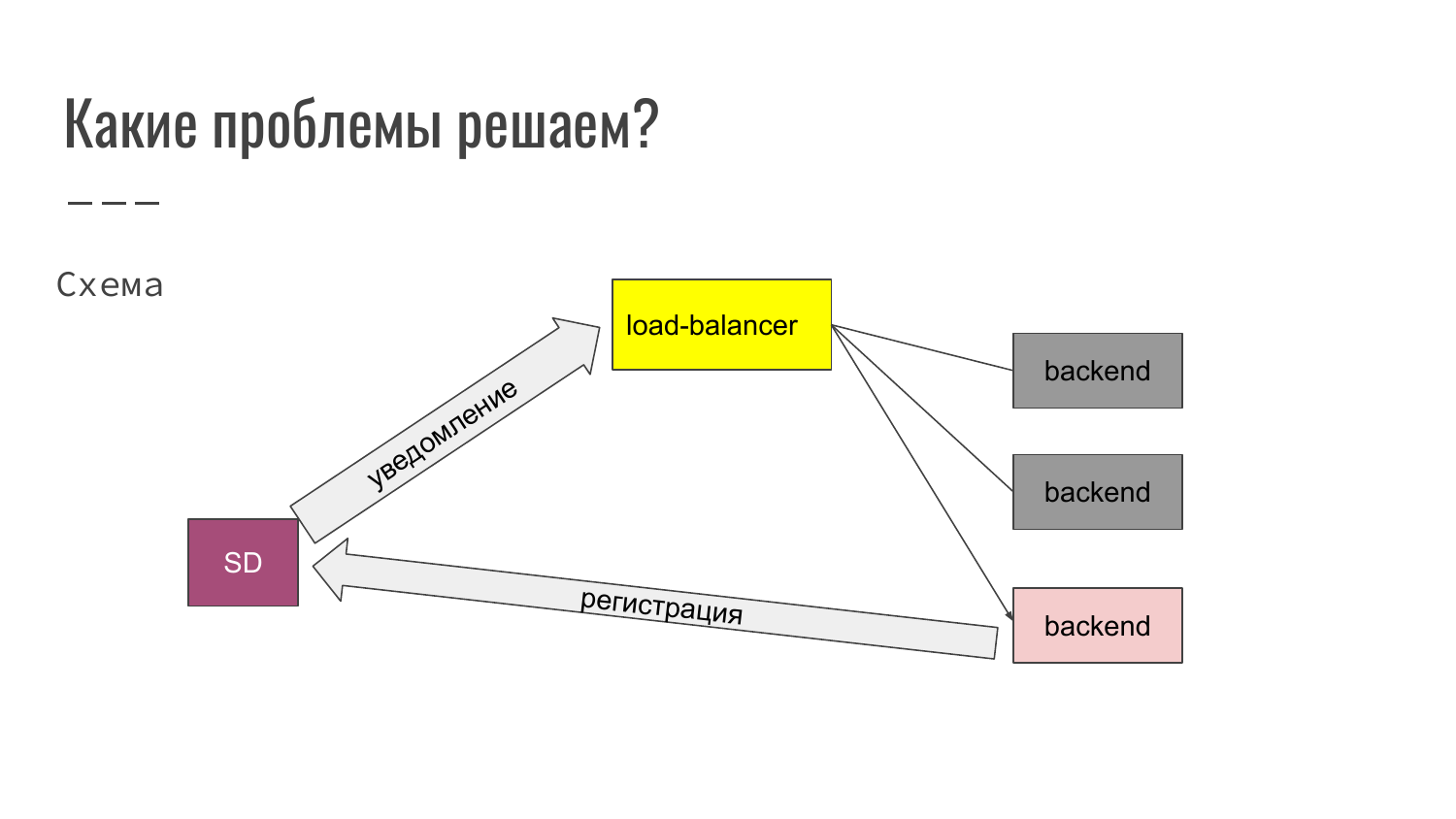
Здесь мы видим, что мы запускаем третий экземпляр приложения. Соответственно, когда приложение запускается, оно производит регистрацию в Service Discovery. Service Discovery уведомляет load-balancer. Load-balancer меняет свой конфиг автоматически и уже новый backend подключается в работу. Таким образом могут добавляться backend, либо, наоборот, исключаться из работы.

Что еще удобно делать при помощи Service Discovery?
В Service Discovery могут храниться конфиги nginx, сертификаты и список активных backend-серверов.
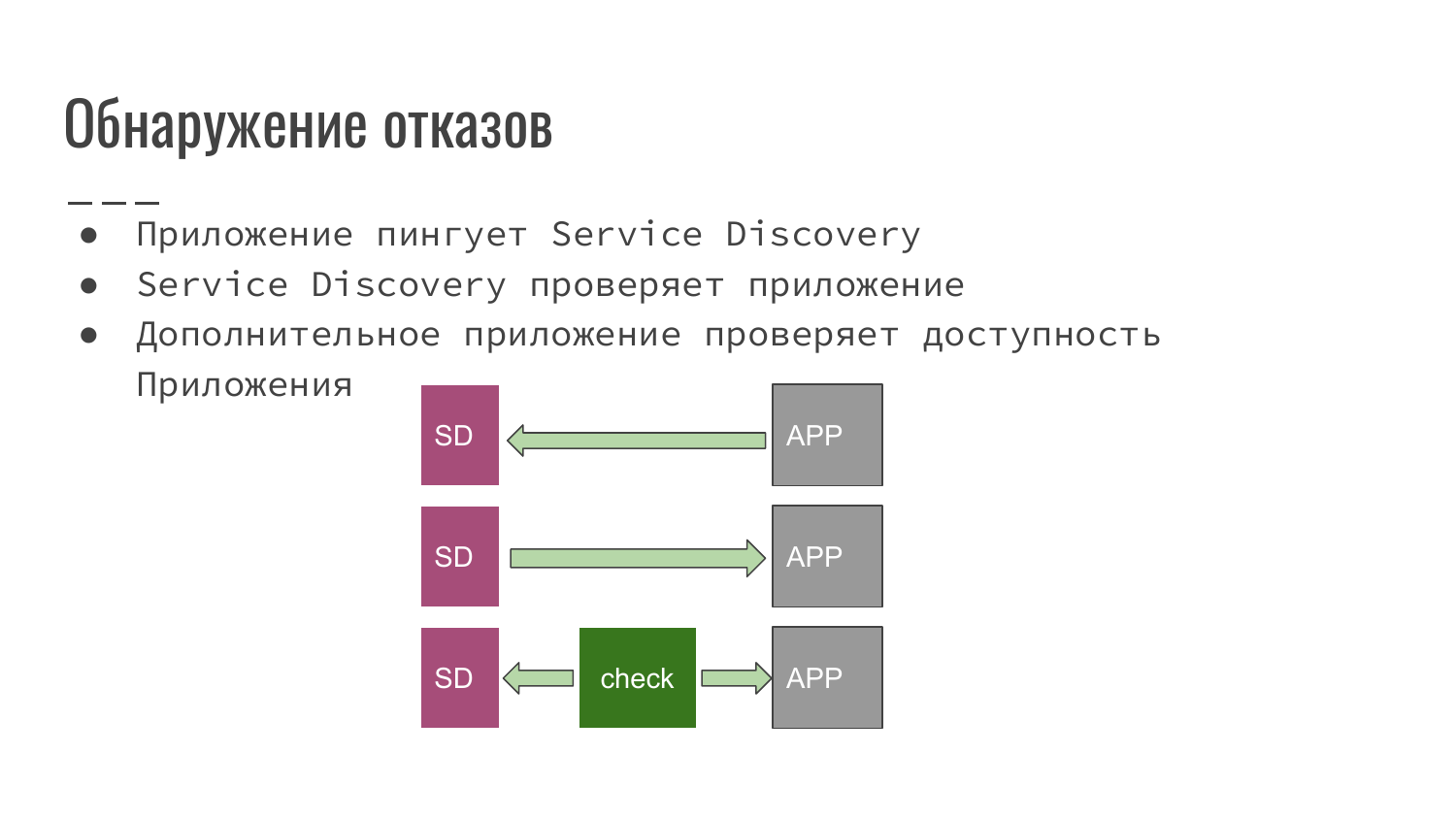
Также Service Discovery позволяет обнаружить сбой, обнаружить отказы.
Какие возможны схемы при обнаружении отказов?
- Это приложение, которое мы разработали, само уведомляет Service Discovery, что оно еще до сих пор работоспособно.
- Service Discovery со своей стороны опрашивает приложение на факт доступности.
- Или же используется сторонний скрипт или приложение, которое проверяет наше приложение на доступность и уведомляет Service Discovery, что все хорошо и можно работать, или, наоборот, что все плохо и необходимо этот экземпляр приложения исключить из балансировки.
Каждая из схем может применяться в зависимости от того, какое ПО мы используем. Например, мы только начали разрабатывать новый проект, то мы без проблем можем обеспечить схему, когда наше приложение уведомляет Service Discovery. Либо можем подключить, что Service Discovery проводит проверку.
Если же приложение досталось нам в наследство или разработано кем-то сторонним, то здесь подходит третий вариант, когда мы пишем обработчик, и все это встает в нашу работу автоматически.
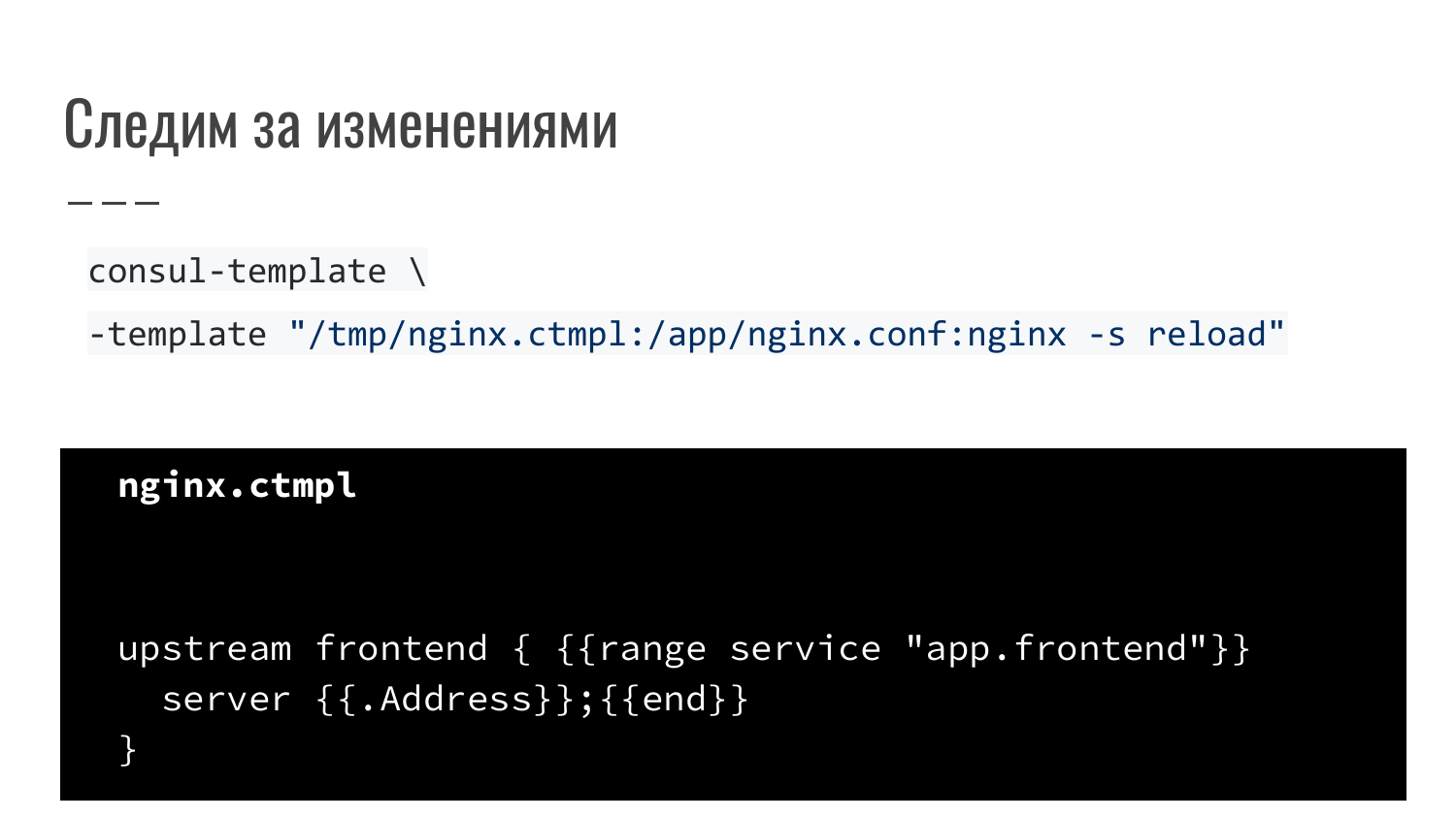
Это один из примеров. Load-balancer в виде nginx перезагружается. Это дополнительная утилита, которая предоставляется вместе с Consul. Это consul-template. Мы описываем правило. Говорим, что используем шаблон (Шаблонизатор Golang). При совершении событий, при уведомлениях, что произошли изменения, он перегенерируется и Service Discovery присылается команда «reload». Простейший пример, когда по событию переконфигурируется nginx и перезапускается.

Что такое Consul?
Прежде всего – это Service Discovery.
Он имеет механизм проверки доступности – Health Checking.
Также он имеет KV Store.
И в его основу заложено возможность использовать Multi Datacenter.
Для чего все это можно использовать? В KV Store мы можем хранить примеры конфигов. Health Checking мы можем проводить проверку локального сервиса и уведомлять. Multi Datacenter используется для того, чтобы можно было построить карту сервисов. Например, Amazon имеет несколько зон и маршрутизирует трафик наиболее оптимально, чтобы не было лишних запросов между дата-центрами, которые тарифицируются отдельно от локального трафика, и, соответственно, имеют меньшую задержку.

Немножко разберемся с терминами, которые в Consul используются.
- Consul – сервис, написанный на Go. Одним из преимуществ программы на Go – это 1 бинарный файл, который ты просто скачал. Запустил из любого места и у тебя никаких зависимостей нет.
- Дальше при помощи ключей мы можем запустить этот сервис либо в режиме клиента, либо в режиме сервера.
- Также атрибут «datacenter» позволяет поставить флаг к какому дата-центру принадлежит данный сервер.
- Consensus – базируется на протоколе raft. Если кому интересно, то об этом можно прочитать поподробнее на сайте Consul. Это протокол, который позволяет определить лидера и определить какие денные считать валидными и доступными.
- Gossip – это протокол, который обеспечивает взаимодействие между нодами. Причем эта система является децентрализованной. В рамках одного дата-центра все ноды общаются с соседями. И, соответственно, передается друг другу информация об актуальном состоянии. Можно сказать, что это сплетни между соседями.
- LAN Gossip – локальный обмен данных между соседями в рамках одного дата-центра.
- WAN Gossip – используется, когда нам необходимо синхронизировать информацию между двумя дата-центрами. Информация идет между нодами, которые помечены как сервер.
- RPC – позволяет выполнять запросы через клиента на сервере.
Описание RPC. Допустим, на виртуальной машине или физическом сервере запущен Consul в виде клиента. К нему локально обращаемся. А дальше локальный клиент запрашивает информацию у сервера и синхронизируется. Информация в зависимости от настроек может выдаваться из локального кэша, либо может быть синхронизирована с лидером, с мастером сервера.
У этих двух схем есть как плюсы, так и минусы. Если мы работаем с локальным кэшем, то это быстро. Если мы работаем с данными, которые хранятся на сервере, то это дольше, но получаем более актуальную информацию.
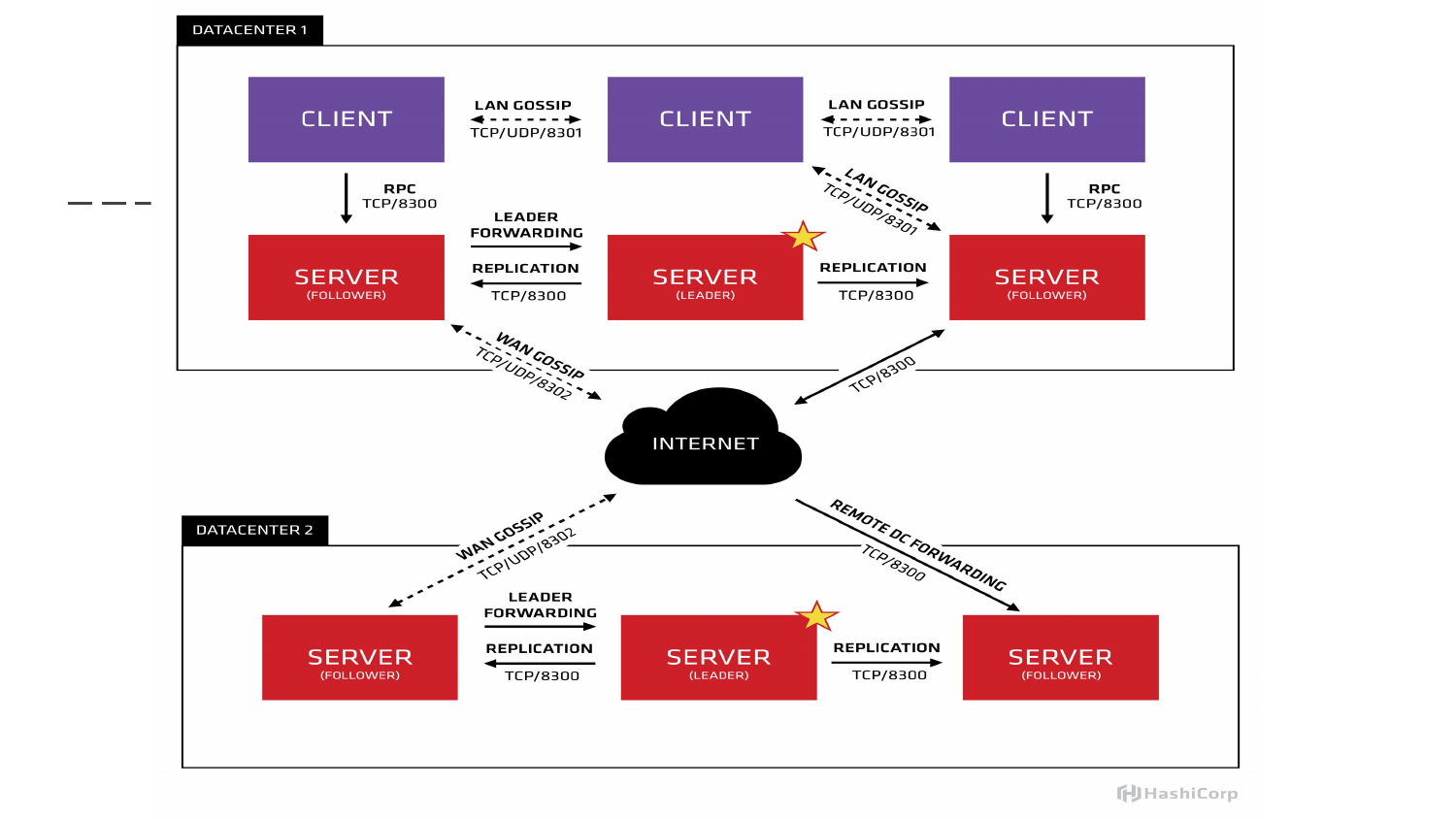
Если это изобразить графически, то вот такая картинка сайта. Мы видим, что у нас запущено три мастера. Один звездочкой помечен как лидер. В данном примере три клиента, которые между собой обмениваются локально информацией по UDP/TCP. А информация между дата-центрами передается между серверами. Здесь клиенты взаимодействуют между собой локально.

Какой API предоставляет Consul?
Для того чтобы получить информацию, есть два вида API у Consul.
Это DNS API. По умолчанию Consul запускается на 8600 порту. Мы можем настроить проксирование запроса и обеспечить доступ через локальный резолвинг, через локальный DNS. Мы можем запросить по домену и получим в ответ информацию об IP-адресе.
HTTP API – либо мы можем локально на 8500 порту запросить информацию о конкретном сервисе и получим JSON ответ, какой IP имеет сервер, какой host, какой порт зарегистрирован. И дополнительная информация может быть передана через token.

Что нужно, чтобы запустить Consul?
В первом варианте мы в режиме разработчика указываем флаг, что это режим разработчика. Agent стартует как сервер. И всю функцию выполняет уже самостоятельно на одной машине. Удобно, быстро и никаких практически дополнительных настроек для первого старта не требуется.
Второй режим – это запуск в production. Здесь запуск немного усложняется. Если у нас нет ни одной версии консула, то мы должны привести в bootstrap первую машину, т. е. эта машина, которая возьмет на себя обязанности лидера. Мы поднимаем ее, затем мы поднимаем второй экземпляр сервера, передавая ему информацию, где у нас находится мастер. Третий поднимаем. После того, как у нас поднято три машины, мы на первой машине из запущенного bootstrap, перезапускаем ее в обычном режиме. Данные синхронизируются, и начальный кластер уже поднят.
Рекомендуется запускать от трех до семи экземпляров в режиме сервера. Это обуславливается тем, что если количество серверов растет, то увеличивается время на синхронизацию информации между ними. Количество нод должно быть нечетным, чтобы обеспечить кворум.

Как обеспечиваются Health Checks?
В директорию для конфигурации Consul мы в виде Json пишем правило проверки. Первый вариант – это доступность в данном примере домена google.com. И говорим, что через интервал в 30 секунд нужно выполнять эту проверку. Таким образом мы проверяем, что наша нода имеет доступ во внешнюю сеть.
Второй вариант – это проверка себя. Мы обычным curl дергаем localhost по указанному порту с интервалом в 10 секунд.
Эти проверки суммируются и поступают в Service Discovery. На основании доступности эти ноды либо исключаются, либо появляются в списке доступных и корректно работающих машинок.

Также Consul предоставляет UI-интерфейс, который с отдельным флагом запускается и будет доступен на машинке. Это позволяет просматривать информацию, а также можно вносить некоторые изменения.
В данном примере открыта вкладка «Сервис». Показано, что запущено три сервиса, один из них Consul. Количество выполненных проверок. И имеются три дата-центра, в которых находятся машинки.
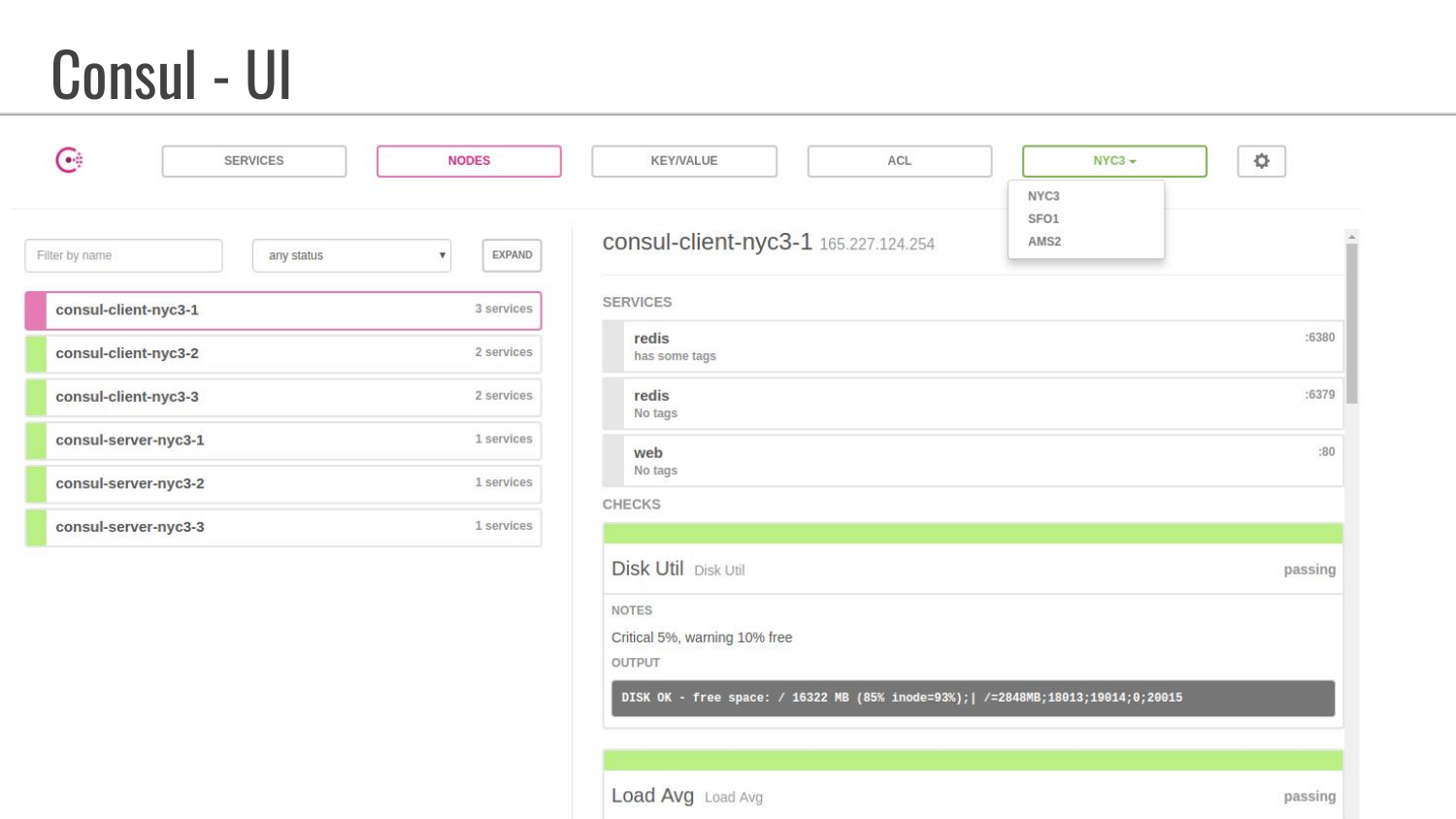
Это пример вкладки «Nodes». Видим, что у них составные имена с участием дата-центров. Здесь также показано, какие сервисы запущены, т. е. мы видим, что теги не заданы. В этих дополнительных тегах можно задать какую-то информацию, которую разработчик может использовать для указания дополнительных параметров.
Также можно передавать информацию в Consul о состоянии дисков, о средней загрузке.
Вопросы
Вопрос: У нас есть докер-контейнер, как его использовать с Consul ?
Ответ: Для докер-контейнера есть несколько подходов. Один из самых распространенных – это использовать сторонний докер-контейнер, отвечающий за регистрацию. При запуске ему прокидывается сокет докера. Все события по регистрации и депубликации контейнера заносятся в Consul.
Вопрос: Т. е. Consul сам запускает докер-контейнер?
Ответ: Нет. Мы запускаем докер-контейнер. И при конфигурации указываем – слушай такой-то сокет. Это примерно так же, как идет работа с сертификатом, когда мы прокидываем информацию, где и что у нас лежит.
Вопрос: Получается, что внутри докер-контейнера, который мы пытаемся подключить к Service Discovery должна быть какая-то логика, которая умеет отдавать данные Consul?
Ответ: Не совсем. Когда он стартует, то мы через переменное окружение передаем переменные. Допустим, сервис name, сервис порт. В регистре слушает эту информацию и заносит в Consul.
Вопрос: У меня еще по UI вопрос. Мы развернули UI, допустим, на production-сервере. Что с безопасностью? Где хранятся данные? Можно ли как-то аккумулировать данные?
Ответ: В UI как раз данные из базы и из Service Discovery. Пароли мы ставим в настройках самостоятельно.
Вопрос: Это можно публиковать в интернет?
Ответ: По умолчанию Consul стартует на localhost. Чтобы публиковать в это интернет, надо будет поставить какой-то proxy. За правила безопасности мы отвечаем сами.
Вопрос: Исторические данные из коробки выдает? Интересно посмотреть статистику по Health Checks. Можно же диагностировать проблемы, если сервер часто выходит из строя.
Ответ: Я не уверен, что там есть детали проверок.
Вопрос: Не столько важно текущее состояние, сколько важна динамика.
Ответ: Для анализа – да.
Вопрос: Service Discovery для докера Consul лучше не использовать?
Ответ: Я бы не рекомендовал его использовать. Цель доклада – познакомить, что есть такое понятие. Исторически он проделал путь, по-моему, до 1-ой версии. Сейчас уже есть более полноценные решения, например, Kubernetes, который все это имеет под капотом. В составе Kubernetes Service Discovery уступает Etcd. Но я с ним не так плотно знаком, как с Consul. Поэтому Service Discovery я решил сделать на примере Consul.
Вопрос: Схема с сервером лидером не тормозит старт приложения в целом? И как Consul определяет нового лидера, если этот лежит?
Ответ: У них описан целый протокол. Если интересно, то можно почитать.
Вопрос: Consul у нас выступает полноценным сервером и все запросы летают через него?
Ответ: Он выступает не полноценным сервером, а берет определенную зону. Она, как правило, оканчивается service.consul. И дальше мы уже по логике идем. Мы не используем в production доменные имена, а именно внутреннюю инфраструктуру, которая обычно прячется за кэширование сервера, если мы работаем по DNS.
Вопрос: Т. е. если мы хотим обратиться к базе данных, то мы в любом случае будем дергать Consul, чтобы найти эту базу сперва, правильно?
Ответ: Да. Если работаем по DNS, то это работает как без Consul, когда используем DNS имена. Обычно современные приложения не в каждом запросе дергают доменное имя, потому что мы connect установили, все работает и в ближайшее время мы практически не используем. Если connect разорвался, то – да, мы опять спрашиваем, где у нас лежит база и идем к ней.

