В PostgreSQL существует очень удобный механизм рекомендательных блокировок, они же — advisory locks. Мы в «Тензоре» используем их во многих местах системы, но мало кто детально понимает, как конкретно они работают, и какие проблемы можно получить при неправильном обращении.
Принципиальное отличие этого механизма от «обычных» блокировок уровня таблицы/страницы/записи заключается в наличии нескольких ключевых возможностей.
«Обычные» блокировки в PG всегда привязаны к конкретному объекту БД (таблице, записи, странице данных) и процессу, обслуживающему соединение. Advisory locks — тоже к процессу, но вместо реального объекта — абстрактный идентификатор, который можно задать как (bigint) или как (integer, integer).
Кстати, привязка каждой блокировки к процессу означает, что «прибив» его через
CAS — это Compare-and-Set, то есть проверка возможности захвата и сам захват блокировки проходят как одна атомарная операция, и между ними заведомо никто не может «вклиниться».
То есть если вы сначала делаете проверочный запрос к pg_locks, смотрите на результат, потом решаете накладывать или нет блокировку, то вам никто не гарантирует, что между этими операциями никто не успеет занять нужный вам объект. А вот если пользуетесь pg_try_advisory_lock — то вы эту блокировку сразу или получите, или функция просто вернет
«Обычные» блокировки существуют в модели «Если уж ты попросил блокировку — то жди. Если не захотел ждать (
Единственный способ избежать такого поведения — использовать конструкцию
Рекомендательные же блокировки, вызываемые try-функциями, просто возвращают
Как я упомянул выше, блокировки объектов «привязаны» к процессу и существуют только в рамках выполнения текущей транзакции в нем. Даже просто так наложить — не удастся:
Соответственно, при завершении транзакции все наложенные ей блокировки снимаются. В отличие от них, advisory locks изначально были спроектированы с возможностью удержания блокировки и за рамками транзакции:
Но уже с версии 9.1 появились xact-версии advisory-функций позволяющие реализовать поведение «обычных» блокировок, автоматически снимающихся при завершении наложившей их транзакции.
Собственно, как и любая другая блокировка, advisory служат для обеспечения единственности обработки какого-то ресурса. У нас такими ресурсами обычно выступают или таблица целиком или конкретная запись таблицы, которую по каким-то причинам не хочется «лочить жестко».
Если необходимость обработки каких-то данных в базе инициируется внешним событием, но многопроцессная обработка избыточна или может привести к состоянию гонки, разумно сделать так, чтобы работать на этих данных мог всего лишь один процесс одновременно.
Для этого попытаемся наложить блокировку с идентификатором таблицы в качестве первого параметра и ID конкретной прикладной обработки — в качестве второго:
Если нам вернулось
Теперь задача «от обратного» — мы хотим, чтобы задачи в некоторой таблице-очереди обрабатывались максимально быстро, многопоточно, отказоустойчиво, да еще и с разных бизнес-логик (ну, не хватает нам мощности одной) — например, как это делают наш оператор по передаче электронной отчетности в госорганы или сервис ОФД.
Поскольку «обрабатывающие» БЛ — разные серверы, то никакой mutex уже не «повесишь». Выделять некий особый раздающий задачи процесс-координатор — небезопасно, «сдохни» он — и все встанет. Вот так и получается, что эффективнее всего распределять задачи прямо на уровне БД, и такой способ существует — модель была в незапамятные времена честно подсмотрена у Дмитрия Котерова и потом творчески доработана.
В этом случае мы накладываем блокировку на ID таблицы и PK конкретной записи:
То есть процесс получит из таблицы первую же пока-еще-не-заблокированную его собратьями-конкурентами запись.
Впрочем, если PK состоит не из (integer), а из (integer, integer) (как в том же расчете себестоимости, например), можно накладывать блокировку прямо на эту пару — вряд ли пересечение с «конкурентом» возникнет.
Важно! Не забываем периодически правильно обслуживать свою таблицу-очередь!
Применяется у нас повсеместно в решениях для документооборота. Ведь в распределенной web-системе один и тот же документ одновременно может открываться на просмотр разными пользователями, а вот обрабатываться (изменять свое состояние и т.п.) в каждый момент времени — только кем-то одним.
Куда же без них! Почти все сводятся к одному: не разлочили то, что залочили.
RTFM, как говорится:
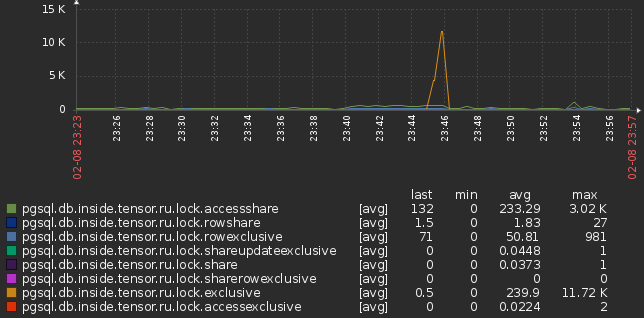
Тысячи их! Снова читаем мануал:
В общем, если возникает ситуация, когда вам хочется наложить несколько тысяч advisory locks (даже если вы их все корректно снимаете потом) — сильно-сильно подумайте, куда вы побежите, когда сервер «встанет колом».
Вот берем предыдущий запрос и добавляем безобидное условие типа проверки на четность ID —
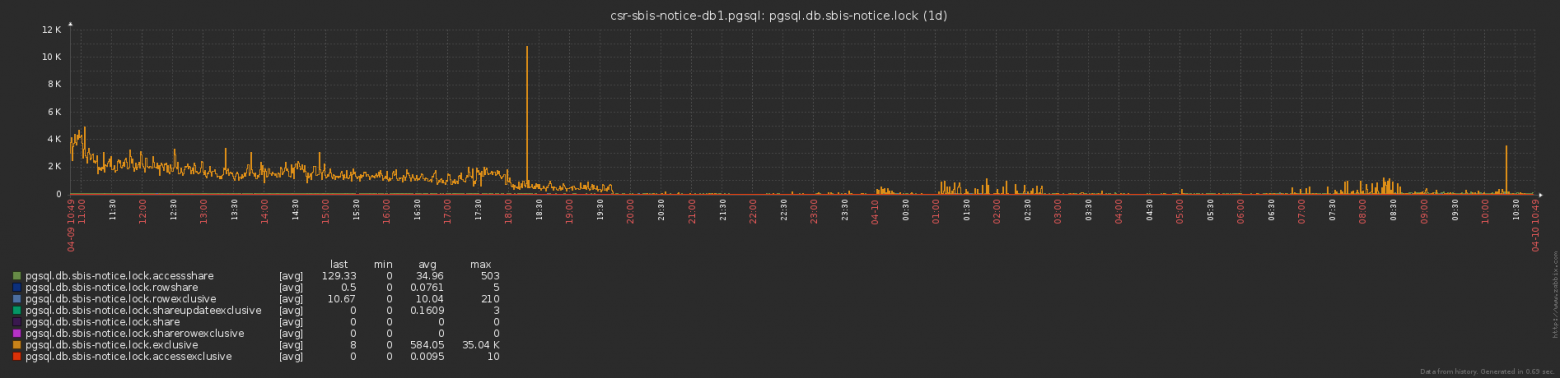
Или вариант из мануала:
Все — блокировка осталась, а мы об этом и не в курсе. Лечится правильными запросами, в худшем случае —
Классика жанра…
Перепутать
Перепутать
Это отдельный источник боли для многих, когда ради производительности работа с БД идет через pgbouncer в transaction mode.
Это означает, что две ваши соседние транзакции, выполняющиеся на одном и том же соединении «с БД» (которое на самом деле идет через pgbouncer), могут оказаться на выполнении в разных «физических» соединениях на стороне базы. А блокировки у них — свои у каждого…

Вариантов тут немного:
На этом пока все.
Еще почитать о блокировках
Для общего расширения кругозора, рекомендую ознакомиться с циклом статей Егора Рогова, о механике блокировок в PostgreSQL.
Преимущества рекомендательных блокировок
Принципиальное отличие этого механизма от «обычных» блокировок уровня таблицы/страницы/записи заключается в наличии нескольких ключевых возможностей.
Блокировка произвольного идентификатора
«Обычные» блокировки в PG всегда привязаны к конкретному объекту БД (таблице, записи, странице данных) и процессу, обслуживающему соединение. Advisory locks — тоже к процессу, но вместо реального объекта — абстрактный идентификатор, который можно задать как (bigint) или как (integer, integer).
Кстати, привязка каждой блокировки к процессу означает, что «прибив» его через
pg_terminate_backend(pid) или корректно завершив соединение с клиентской стороны, можно избавиться от всех наложенных им блокировок.CAS-проверка возможности захвата блокировки
CAS — это Compare-and-Set, то есть проверка возможности захвата и сам захват блокировки проходят как одна атомарная операция, и между ними заведомо никто не может «вклиниться».
То есть если вы сначала делаете проверочный запрос к pg_locks, смотрите на результат, потом решаете накладывать или нет блокировку, то вам никто не гарантирует, что между этими операциями никто не успеет занять нужный вам объект. А вот если пользуетесь pg_try_advisory_lock — то вы эту блокировку сразу или получите, или функция просто вернет
FALSE.Не-захват без исключений и ожиданий
«Обычные» блокировки существуют в модели «Если уж ты попросил блокировку — то жди. Если не захотел ждать (
NOWAIT, statement_timeout, lock_timeout) — вот тебе исключение». Этот подход сильно мешает внутри транзакции, потому что тогда приходится или реализовывать блок BEGIN-EXCEPTION-END для обработки, или откатывать (ROLLBACK) транзакцию.Единственный способ избежать такого поведения — использовать конструкцию
SELECT ... SKIP LOCKED, появившуюся с версии 9.5. К сожалению, при таком способе варианты «вообще не было, что блокировать» и «было, но уже заблокировано» становятся неразличимы.Рекомендательные же блокировки, вызываемые try-функциями, просто возвращают
TRUE/FALSE.Не путайтеpg_advisory_lockиpg_try_advisory_lock— первая функция таки будет ждать, пока не получит блокировку, а вторая — просто сразу вернетFALSEпри невозможности захвата «прямо сейчас».
Блокировки в рамках транзакции и за ними
Как я упомянул выше, блокировки объектов «привязаны» к процессу и существуют только в рамках выполнения текущей транзакции в нем. Даже просто так наложить — не удастся:
LOCK TABLE tbl; -- ERROR: LOCK TABLE can only be used in transaction blocks
Соответственно, при завершении транзакции все наложенные ей блокировки снимаются. В отличие от них, advisory locks изначально были спроектированы с возможностью удержания блокировки и за рамками транзакции:
SELECT pg_advisory_lock(1); SELECT * FROM pg_locks WHERE pid = pg_backend_pid() AND locktype = 'advisory';
-[ RECORD 1 ]------+-------------- locktype | advisory database | 263911484 relation | page | tuple | virtualxid | transactionid | classid | 0 <-- аргумент int4 #1 или верхняя половина int8 objid | 1 <-- аргумент int4 #2 или нижняя половина int8 objsubid | 1 virtualtransaction | 416/475768 pid | 29264 mode | ExclusiveLock granted | t fastpath | f
Но уже с версии 9.1 появились xact-версии advisory-функций позволяющие реализовать поведение «обычных» блокировок, автоматически снимающихся при завершении наложившей их транзакции.
Примеры использования в СБИС
Собственно, как и любая другая блокировка, advisory служат для обеспечения единственности обработки какого-то ресурса. У нас такими ресурсами обычно выступают или таблица целиком или конкретная запись таблицы, которую по каким-то причинам не хочется «лочить жестко».
Монопроцессность работы worker'а
Если необходимость обработки каких-то данных в базе инициируется внешним событием, но многопроцессная обработка избыточна или может привести к состоянию гонки, разумно сделать так, чтобы работать на этих данных мог всего лишь один процесс одновременно.
Для этого попытаемся наложить блокировку с идентификатором таблицы в качестве первого параметра и ID конкретной прикладной обработки — в качестве второго:
SELECT pg_try_advisory_lock( 'processed_table'::regclass::oid , -1 -- ключ типа worker'а );
Если нам вернулось
FALSE, то кто-то другой уже держит «такую» блокировку, и конкретно этому процессу делать ничего не надо, а лучше всего просто тихо завершиться. Так работает, например, процесс динамического расчета себестоимости товаров на складе, изолированно для каждой отдельной клиентской схемы.Параллельная обработка очереди
Теперь задача «от обратного» — мы хотим, чтобы задачи в некоторой таблице-очереди обрабатывались максимально быстро, многопоточно, отказоустойчиво, да еще и с разных бизнес-логик (ну, не хватает нам мощности одной) — например, как это делают наш оператор по передаче электронной отчетности в госорганы или сервис ОФД.
Поскольку «обрабатывающие» БЛ — разные серверы, то никакой mutex уже не «повесишь». Выделять некий особый раздающий задачи процесс-координатор — небезопасно, «сдохни» он — и все встанет. Вот так и получается, что эффективнее всего распределять задачи прямо на уровне БД, и такой способ существует — модель была в незапамятные времена честно подсмотрена у Дмитрия Котерова и потом творчески доработана.
В этом случае мы накладываем блокировку на ID таблицы и PK конкретной записи:
SELECT * FROM queue_table WHERE pg_try_advisory_lock('queue_table'::regclass::oid, pk_id) ORDER BY pk_id LIMIT 1;
То есть процесс получит из таблицы первую же пока-еще-не-заблокированную его собратьями-конкурентами запись.
Впрочем, если PK состоит не из (integer), а из (integer, integer) (как в том же расчете себестоимости, например), можно накладывать блокировку прямо на эту пару — вряд ли пересечение с «конкурентом» возникнет.
Важно! Не забываем периодически правильно обслуживать свою таблицу-очередь!
Монопольная обработка документа
Применяется у нас повсеместно в решениях для документооборота. Ведь в распределенной web-системе один и тот же документ одновременно может открываться на просмотр разными пользователями, а вот обрабатываться (изменять свое состояние и т.п.) в каждый момент времени — только кем-то одним.
Традиционные проблемы
Куда же без них! Почти все сводятся к одному: не разлочили то, что залочили.
Мультиналожение одной advisory-блокировки
RTFM, как говорится:
Если поступает сразу несколько запросов на блокировку, они накапливаются, так что если один ресурс был заблокирован три раза, его необходимо три раза разблокировать, чтобы он был доступен в других сеансах.
Наложили слишком много блокировок сразу
Тысячи их! Снова читаем мануал:
И рекомендательные, и обычные блокировки сохраняются в области общей памяти, размер которой определяется параметрами конфигурацииmax_locks_per_transactionиmax_connections. Важно, чтобы этой памяти было достаточно, так как в противном случае сервер не сможет выдать никакую блокировку. Таким образом, число рекомендуемых блокировок, которые может выдать сервер, ограничивается обычно десятками или сотнями тысяч в зависимости от конфигурации сервера.
В общем, если возникает ситуация, когда вам хочется наложить несколько тысяч advisory locks (даже если вы их все корректно снимаете потом) — сильно-сильно подумайте, куда вы побежите, когда сервер «встанет колом».
Утечки при фильтрации записей
Вот берем предыдущий запрос и добавляем безобидное условие типа проверки на четность ID —
AND pk_id % 2 = 0. Проверены будут оба условия для каждой записи! В результате, pg_try_advisory_lock выполнилась, блокировка наложилась, а потом запись отфильтровалась по проверке четности.Или вариант из мануала:
SELECT pg_advisory_lock(id) FROM foo WHERE id = 12345; -- ok SELECT pg_advisory_lock(id) FROM foo WHERE id > 12345 LIMIT 100; -- опасно!
Все — блокировка осталась, а мы об этом и не в курсе. Лечится правильными запросами, в худшем случае —
pg_advisory_unlock_all.Ой, перепутал!
Классика жанра…
Перепутать
pg_try_advisory_lock и pg_advisory_lock, и удивляться, почему долго работает. А потому что не-try-версия — ждет.Перепутать
pg_try_advisory_lock и pg_try_advisory_xact_lock, и удивляться, куда пропала блокировка — а она «кончилась» вместе с транзакцией. А транзакция из одного того запроса и состояла, потому что нигде «явно» не объявлялась, ага.Работа через pgbouncer
Это отдельный источник боли для многих, когда ради производительности работа с БД идет через pgbouncer в transaction mode.
Это означает, что две ваши соседние транзакции, выполняющиеся на одном и том же соединении «с БД» (которое на самом деле идет через pgbouncer), могут оказаться на выполнении в разных «физических» соединениях на стороне базы. А блокировки у них — свои у каждого…
Вариантов тут немного:
- или переходите на работу через прямое соединение с БД
- или придумывайте алгоритм, чтобы все advisory-блокировки были только в рамках транзакции (xact)
На этом пока все.

