Здавствуйте, в этом туториале мы рассмотрим как разработать очень простую, но контролируемую форму в React, сфокусировавшись на качестве кода.
При разработке нашей формы мы будем следовать принципам «KISS», «YAGNI», «DRY». Для успешного прохождения данного туториала вам не нужно знать этих принципов, я буду объяснять их по ходу дела. Однако, я полагаю, что вы хорошо владеете современным javascript и умеете мыслить на React.
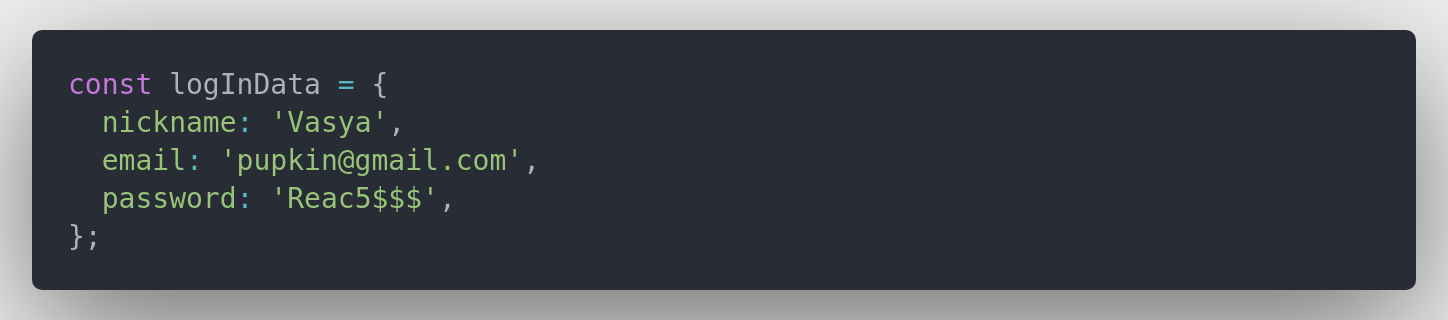
Итак, представим, что у нас есть задание реализовать форму авторизации:
Начнем нашу разработку с анализа принципов KISS и YAGNI, временно забывая об остальных принципах.
KISS — «Оставьте код простым и тупым». Думаю, с понятием простого кода вы знакомы. Но что значит «тупой» код? В моем понимании, это код, который решает задачу, используя минимальное количество абстракций, при этом вложенность этих абстракций друг в друга также минимальна.
YAGNI — «Вам это не понадобится». Код должен уметь делать только то, для чего он написан. Мы не создаем никакой функционал, который может понадобиться потом или который делает приложение лучше на наш взгляд. Делаем только то, что нужно конкретно для реализации поставленной задачи.
Давайте будем строго следовать этим принципам, но также учтем:
К тому же, давайте упустим стилизацию, так как она нам не интересна, и валидацю, поскольку это тема для отдельного туториала.
Пожалуйста, реализуйте форму самостоятельно, следуя принципам, описанным выше.
Ваше решение, скорее всего, чем-то отличается, ведь каждый разработчик мыслит по-своему. Вы можете создать для каждого поля свое состояние или выносить функции-обработчики в отдельную переменную, в любом случае это не важно.
Но если вы сразу создали одну функцию-обработчик для всех полей, то это уже не является «тупейшим» решением задачи. А наша цель на этом этапе — создать максимально простой и «тупой» код, чтобы потом посмотреть на всю картинку и выделить самые лучше абстракции.
Если у вас получился точно такой же код, это круто и означает, что наше с вами мышление сходится!
Далее мы будем работотать с этим кодом. Он прост, но пока далек от идеала.
Пришло время разобраться с принципом DRY.
DRY, упрощенная формулировка — «не дублируйте свой код». Принцип кажется простым, но в нем есть подвох: для избавления от дублирования кода нужно создавать абстракции. Если эти абстракции будут недостаточно хороши, мы нарушим принцип KISS.
Также важно понимать, что DRY нужен не для того, чтобы писать код быстрее. Его задача — упростить чтение и поддержку нашего решения. Поэтому не спешите создавать абстракции сразу. Лучше сделать простую реализацию какой-то части кода, а потом проанализировать, какие абстракции нужно создать, чтобы упростить чтение кода и уменьшить количество мест для изменений, когда они понадобятся.
Чеклист правильной абстракции:
Итак, давайте приступим к рефакторингу.
А у нас есть ярко выраженный дублирующийся код:
В данном коде дублируется композиция из 2-х элементов:

Теперь наш

Читать стало проще. Имя абстракции соответсвует задаче, которую она решает. Цель компонента очевидна. Кода стало меньше. Значит мы идем в правильном направлении!
Сейчас видно, что в
То, что там происходит, можно разбить на 2 этапа:

Первая функция описывает детали получения значения с события
Для того, чтобы наверняка правильно определиться к какой из абстракций нам нужно отнести свой код, придется обратиться к полной формулировке принципа DRY: «Каждая часть знания должна иметь единственное, непротиворечивое и авторитетное представление в рамках системы».
Частью знания в конкретном примере является знание о том, как получать значение из события в
Если вас смущает, что вам в будущем может понадобиться событие, вспомните о принципе YAGNI. Всегда можно будет добавить дополнительный prop
А до тех пор

Таким образом соблюдается однородность типа при вводе и выводе в компонент и скрывается истинная природа происходящего для внешнего кода. Если нам в будущем понадобится другой компонент ui, например, checkbox или select, то в нем мы тоже будем сохранять однородность типа на вводе-выводе.
Такой подход дает нам дополнительную гибкость, так как наша форма может работать с любыми источниками ввода-вывода без надобности плодить дополнительные уникальные обработчики для каждого.
Этот эвристический прием встроен по-умолчанию во многие фреймворки. Например, это основная идея
Вернемся к делу, обновим наш компонент
Это выглядит уже совсем неплохо, но мы можем еще лучше!
Давайте реализуем эту функцию:

Как видите, функция получает аргумент и соханяет его в замыкании обработчика, а обработчик тут же возвращается во внешний код. Такие функции, которые как бы принимают аргументы по одному за вызов, еще называют каррированными.
Посмотрим на получившийся код:

Данный код является короткой, лаконичной и в меру декларативной реализацией поставленной задачи. Дальнейшей его рефакторинг в контексте задачи, на мой взгляд, не имеет смысла.
Если у вас много форм в проекте, то вы можете вынести рассчет handleChange в отдельный хук

Заметка:
Так как это чистая функция (имеется ввиду при первом вызове, потому что возвращает всегда одинаковую функцию), это не обязательно должен быть хук. На момент написания статьи, хук смотрелся для меня более концептуально правильным и природным решением для React.
Добавим поддержку
Пример использования с нашей формой:

Но если в вашем приложении только одна форма, все это делать не нужно! Потому, что это противоречит принципу YAGNI, следуя которому мы не должны делать то, что нам не нужно для решения конкретной задачи. Если у вас только одна форма, то реальной пользы от таких телодвижений мало. Ведь мы сократили код нашего компонента только на 3 строчки, но ввели дополнительную абстракцию, скрыв определенную логику формы, которую лучше держать на поверхности.
Замоканные конфиги — это как webpack конфиг, только для формы.
Лучше на примере, посмотрите на этот псевдокод:

Некоторым может показаться, что здесь дублируется код, ведь мы же вызываем один и тот же компонент InputField, передавая туда одни и те же параметры label, value и onChange. И они начинают за-DRY-ивать собственный код, чтобы избежать мнимого дублирования.
Часто это делают примерно так:
JSX стало меньше.
Но, как результат, мы получили более сложный код, нарушив принцип KISS. Ведь теперь он состоит из 2-х абстракций: fields и алгоритм (да, алгоритм — это тоже абстракция), который превращает его в дерево React-элементов. При чтении этого кода нам придется постоянно прыгать между этими абстракциями.
Но самая большая проблема этого кода — это его поддержка и расширение.
Представте, что с ним случится, если:
Этот список можно продолжать долго…
Для реализации этого всегда придется хранить какие-то функции в вашем конфиге, а код, который рендерит конфиг, постепенно превратится в Франкенштейна, принимая кучу разных пропсов и закидывая их по разным компонентам.
Код, который был написан до этого, основанный на композиции компонентов, будет спокойно расширяться, меняться как угодно, при этом не сильно усложнясь благодаря отсутсвию промежуточной абстракции — алгоритма, который строит дерево React-элементов из нашего конфига. Этот код не является дублирующимся. Он просто следует определенному шаблону проектирования, поэтому и выглядит «шаблонным».
После появления хуков в React появилась тенденция оборачивають все обработчики и компоненты без разбора в
Мемоизация всегда сделает ваш код сложнее, но не всегда производительнее.
Давайте рассмотрим код из реального проекта. Сравните, как выглядит функция с использованием

Читабельность кода явно выросла после удаления обертки, ведь идеальный код — это его отсутсвие.
Производительность этого кода не выросла, ведь эта функция используется так:

Где
Если этих аргументов вам недостаточно, прочитайте статью, в которой эта тема раскрыта шире.
Изначально я планировал написать о декларативной валидации сложных вложенных форм. Но, в итоге, решил подготовить аудиторию к этому, чтобы картина была максимально полной.
Следующий туториал будет о валидации простой формы, реализованной в этом туториале.
Огромное спасибо всем, кто дочитал до конца!
Не важно, как вы пишите код или чем занимаетесь, главное — получайте от этого удовольствие.
При разработке нашей формы мы будем следовать принципам «KISS», «YAGNI», «DRY». Для успешного прохождения данного туториала вам не нужно знать этих принципов, я буду объяснять их по ходу дела. Однако, я полагаю, что вы хорошо владеете современным javascript и умеете мыслить на React.
Структура туториала:
- За дело! Пишем простую форму, используя KISS и YAGNI
- Рефакторинг и DRY
- Что еще можно сделать?
- О, нет! Не делайте так, пожалуйста!
- Выводы
За дело! Пишем простую форму, используя KISS и YAGNI
Итак, представим, что у нас есть задание реализовать форму авторизации:
Код для копирования
const logInData = { nickname: 'Vasya', email: 'pupkin@gmail.com', password: 'Reac5$$$', };
Начнем нашу разработку с анализа принципов KISS и YAGNI, временно забывая об остальных принципах.
KISS — «Оставьте код простым и тупым». Думаю, с понятием простого кода вы знакомы. Но что значит «тупой» код? В моем понимании, это код, который решает задачу, используя минимальное количество абстракций, при этом вложенность этих абстракций друг в друга также минимальна.
YAGNI — «Вам это не понадобится». Код должен уметь делать только то, для чего он написан. Мы не создаем никакой функционал, который может понадобиться потом или который делает приложение лучше на наш взгляд. Делаем только то, что нужно конкретно для реализации поставленной задачи.
Давайте будем строго следовать этим принципам, но также учтем:
initialDataиonSubmitдляLogInFormприходит с верху (это полезный прием, особенно когда форма должна уметь обрабатыватьcreateиupdateодновременно)- должна иметь для каждого поля
label
К тому же, давайте упустим стилизацию, так как она нам не интересна, и валидацю, поскольку это тема для отдельного туториала.
Пожалуйста, реализуйте форму самостоятельно, следуя принципам, описанным выше.
Моя реализация формы

Код для копирования
const LogInForm = ({ initialData, onSubmit }) => { const [logInData, setLogInData] = useState(initialData); const handleSubmit = e => { e.preventDefault(); onSubmit(logInData); }; return ( <form onSubmit={handleSubmit}> <label> Enter your nickname <input value={logInData.nickname} onChange={e => setLogInData({ ...logInData, nickname: e.target.value })} /> </label> <label> Enter your email <input type="email" value={logInData.email} onChange={e => setLogInData({ ...logInData, email: e.target.value })} /> </label> <label> Enter your password <input type="password" value={logInData.password} onChange={e => setLogInData({ ...logInData, password: e.target.value })} /> </label> <button>Submit</button> </form> ); };
Ваше решение, скорее всего, чем-то отличается, ведь каждый разработчик мыслит по-своему. Вы можете создать для каждого поля свое состояние или выносить функции-обработчики в отдельную переменную, в любом случае это не важно.
Но если вы сразу создали одну функцию-обработчик для всех полей, то это уже не является «тупейшим» решением задачи. А наша цель на этом этапе — создать максимально простой и «тупой» код, чтобы потом посмотреть на всю картинку и выделить самые лучше абстракции.
Если у вас получился точно такой же код, это круто и означает, что наше с вами мышление сходится!
Далее мы будем работотать с этим кодом. Он прост, но пока далек от идеала.
Рефакторинг и DRY
Пришло время разобраться с принципом DRY.
DRY, упрощенная формулировка — «не дублируйте свой код». Принцип кажется простым, но в нем есть подвох: для избавления от дублирования кода нужно создавать абстракции. Если эти абстракции будут недостаточно хороши, мы нарушим принцип KISS.
Также важно понимать, что DRY нужен не для того, чтобы писать код быстрее. Его задача — упростить чтение и поддержку нашего решения. Поэтому не спешите создавать абстракции сразу. Лучше сделать простую реализацию какой-то части кода, а потом проанализировать, какие абстракции нужно создать, чтобы упростить чтение кода и уменьшить количество мест для изменений, когда они понадобятся.
Чеклист правильной абстракции:
- имя абстракции полностью соответствует ее назначению
- абстракция выполняет конкретную, понятную задачу
- чтение кода, из которого была выделена абстракция, улучшилось
Итак, давайте приступим к рефакторингу.
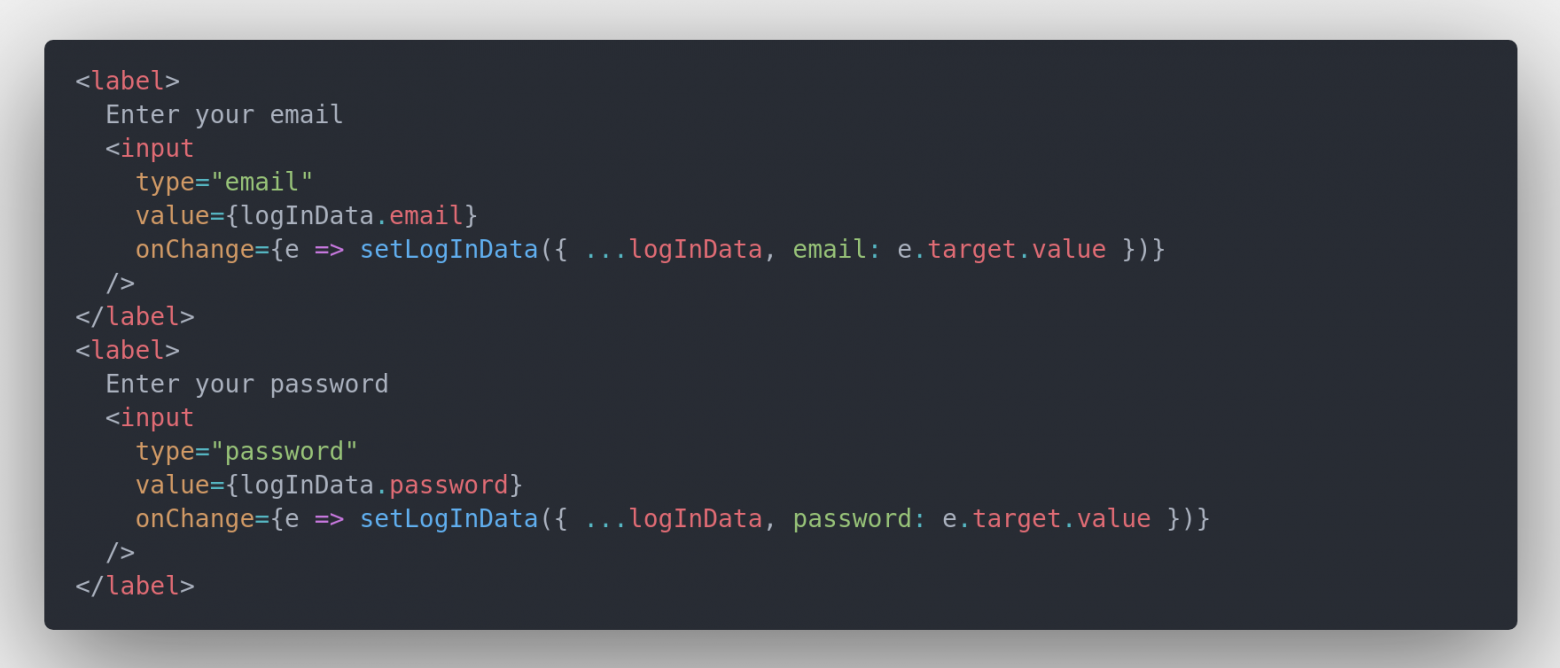
А у нас есть ярко выраженный дублирующийся код:
Код для копирования
<label> Enter your email <input type="email" value={logInData.email} onChange={e => setLogInData({ ...logInData, email: e.target.value })} /> </label> <label> Enter your password <input type="password" value={logInData.password} onChange={e => setLogInData({ ...logInData, password: e.target.value })} /> </label>
В данном коде дублируется композиция из 2-х элементов:
label, input. Давайте объеденим их в новую абстракцию InputField:
Код для копирования
<label> Enter your email <input type="email" value={logInData.email} onChange={e => setLogInData({ ...logInData, email: e.target.value })} /> </label> <label> Enter your password <input type="password" value={logInData.password} onChange={e => setLogInData({ ...logInData, password: e.target.value })} /> </label>
Теперь наш
LogInForm выглядит так:
Код для копирования
const LogInForm = ({ initialData, onSubmit }) => { const [logInData, setLogInData] = useState(initialData); const handleSubmit = e => { e.preventDefault(); onSubmit(logInData); }; return ( <form onSubmit={handleSubmit}> <InputField label="Enter your nickname" value={logInData.nickname} onChange={e => setLogInData({ ...logInData, nickname: e.target.value })} /> <InputField type="email" label="Enter your email" value={logInData.email} onChange={e => setLogInData({ ...logInData, email: e.target.value })} /> <InputField type="password" label="Enter your password" value={logInData.password} onChange={e => setLogInData({ ...logInData, password: e.target.value })} /> <button>Submit</button> </form> ); };
Читать стало проще. Имя абстракции соответсвует задаче, которую она решает. Цель компонента очевидна. Кода стало меньше. Значит мы идем в правильном направлении!
Сейчас видно, что в
InputField.onChange дублируется логика.То, что там происходит, можно разбить на 2 этапа:
Код для копирования
const stage1 = e => e.target.value; const stage2 = password => setLogInData({ ...logInData, password });
Первая функция описывает детали получения значения с события
input. У нас есть на выбор 2 абстракции, в которых мы можем хранить эту логику: InputField и LogInForm.Для того, чтобы наверняка правильно определиться к какой из абстракций нам нужно отнести свой код, придется обратиться к полной формулировке принципа DRY: «Каждая часть знания должна иметь единственное, непротиворечивое и авторитетное представление в рамках системы».
Частью знания в конкретном примере является знание о том, как получать значение из события в
input. Если мы будем это знание хранить в нашем LogInForm, то очевидно, что при использовании нашего InputField в другой форме, нам придется продублировать наше знание, либо вынести его в одельную абстракцию и использовать ее оттуда. А исходя из принципа KISS, у нас должно быть минимально возможное количество абстракций. И действительно, зачем нам создавать еще одну абстракцию, если мы можем просто поместить эту логику в наш InputField, и внешний код не будет знать ничего о том, как работает input внутри самого InputField. Он будет просто принимать готовое значение, такое же, как передает внутрь.Если вас смущает, что вам в будущем может понадобиться событие, вспомните о принципе YAGNI. Всегда можно будет добавить дополнительный prop
onChangeEvent в наш компонент InputField.А до тех пор
InputField будет выглядеть так:
Код для копирования
const InputField = ({ label, type, value, onChange }) => ( <label> {label} <input type={type} value={value} onChange={e => onChange(e.target.value)} /> </label> );
Таким образом соблюдается однородность типа при вводе и выводе в компонент и скрывается истинная природа происходящего для внешнего кода. Если нам в будущем понадобится другой компонент ui, например, checkbox или select, то в нем мы тоже будем сохранять однородность типа на вводе-выводе.
Такой подход дает нам дополнительную гибкость, так как наша форма может работать с любыми источниками ввода-вывода без надобности плодить дополнительные уникальные обработчики для каждого.
Этот эвристический прием встроен по-умолчанию во многие фреймворки. Например, это основная идея
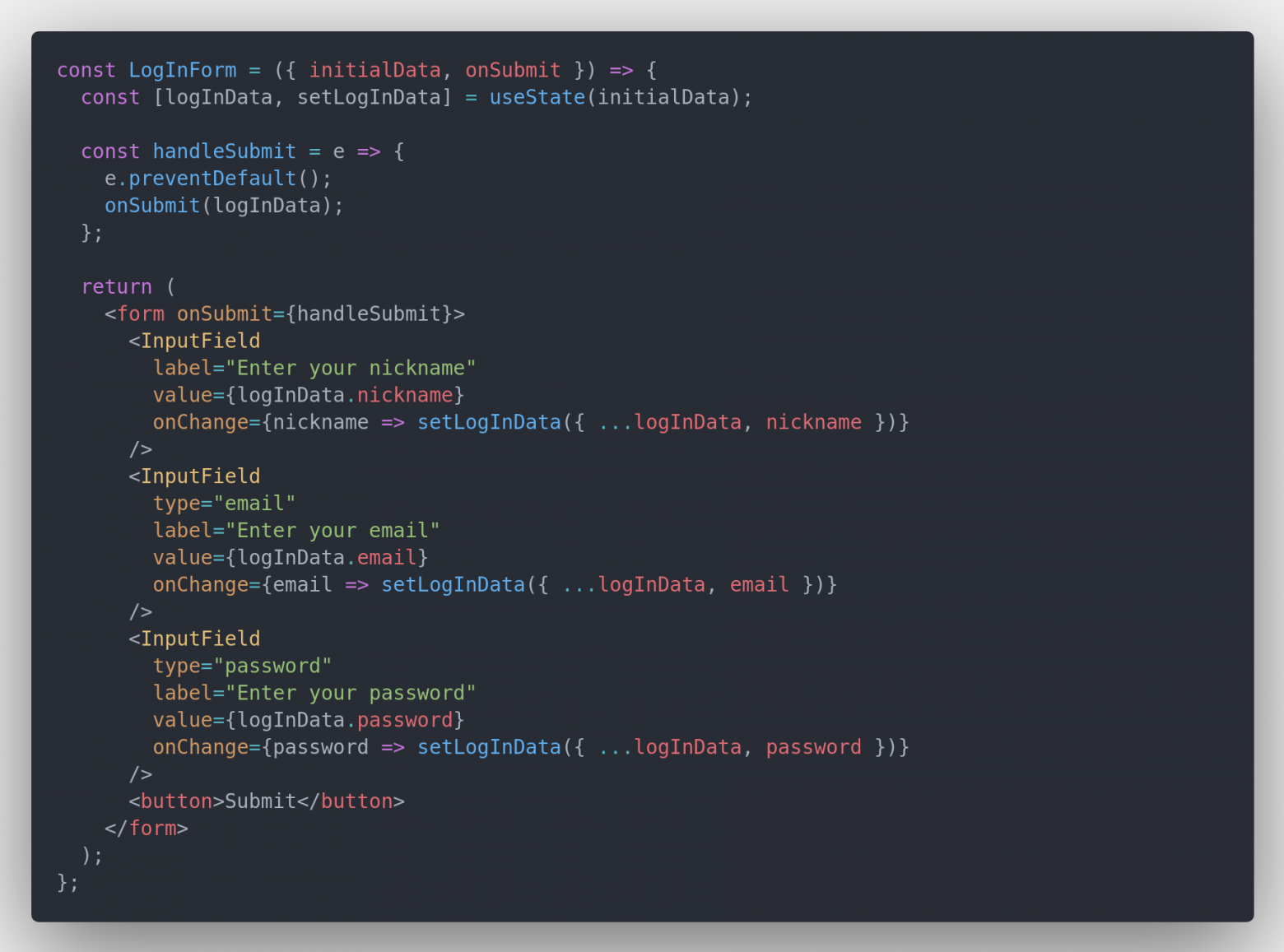
v-model во Vue, который многие любят за его простоту работы с формами.Вернемся к делу, обновим наш компонент
LogInForm в соответсвии с изменениями в InputField:
Код для копирования
const LogInForm = ({ initialData, onSubmit }) => { const [logInData, setLogInData] = useState(initialData); const handleSubmit = e => { e.preventDefault(); onSubmit(logInData); }; return ( <form onSubmit={handleSubmit}> <InputField label="Enter your nickname" value={logInData.nickname} onChange={nickname => setLogInData({ ...logInData, nickname })} /> <InputField type="email" label="Enter your email" value={logInData.email} onChange={email => setLogInData({ ...logInData, email })} /> <InputField type="password" label="Enter your password" value={logInData.password} onChange={password => setLogInData({ ...logInData, password })} /> <button>Submit</button> </form> ); };
Это выглядит уже совсем неплохо, но мы можем еще лучше!
Callback, который передается в onChange, всегда делает одно и то же. В нем меняется только ключ: password, email, nickname. Значит, мы можем заменить его на такой вызов функции: handleChange('password').Давайте реализуем эту функцию:
Код для копирования
const handleChange = fieldName => fieldValue => { setLogInData({ ...logInData, [fieldName]: fieldValue, }); };
Как видите, функция получает аргумент и соханяет его в замыкании обработчика, а обработчик тут же возвращается во внешний код. Такие функции, которые как бы принимают аргументы по одному за вызов, еще называют каррированными.
Посмотрим на получившийся код:
Код для копирования
const LogInForm = ({ initialData, onSubmit }) => { const [logInData, setLogInData] = useState(initialData); const handleSubmit = e => { e.preventDefault(); onSubmit(logInData); }; const handleChange = fieldName => fieldValue => { setLogInData({ ...logInData, [fieldName]: fieldValue, }); }; return ( <form onSubmit={handleSubmit}> <InputField label="Enter your nickname" value={logInData.nickname} onChange={handleChange('nickname')} /> <InputField type="email" label="Enter your email" value={logInData.email} onChange={handleChange('email')} /> <InputField type="password" label="Enter your password" value={logInData.password} onChange={handleChange('password')} /> <button>Submit</button> </form> ); }; // InputField.js const InputField = ({ type, label, value, onChange }) => ( <label> {label} <input type={type} value={value} onChange={e => onChange(e.target.value)} /> </label> );
Данный код является короткой, лаконичной и в меру декларативной реализацией поставленной задачи. Дальнейшей его рефакторинг в контексте задачи, на мой взгляд, не имеет смысла.
Что еще можно сделать?
Если у вас много форм в проекте, то вы можете вынести рассчет handleChange в отдельный хук
useFieldChange:
Код для копирования
// hooks/useFieldChange.js const useFieldChange = setState => fieldName => fieldValue => { setState(state => ({ ...state, [fieldName]: fieldValue, })); }; // LogInForm.js const handleChange = useFieldChange(setLogInData);
Заметка:
Так как это чистая функция (имеется ввиду при первом вызове, потому что возвращает всегда одинаковую функцию), это не обязательно должен быть хук. На момент написания статьи, хук смотрелся для меня более концептуально правильным и природным решением для React.
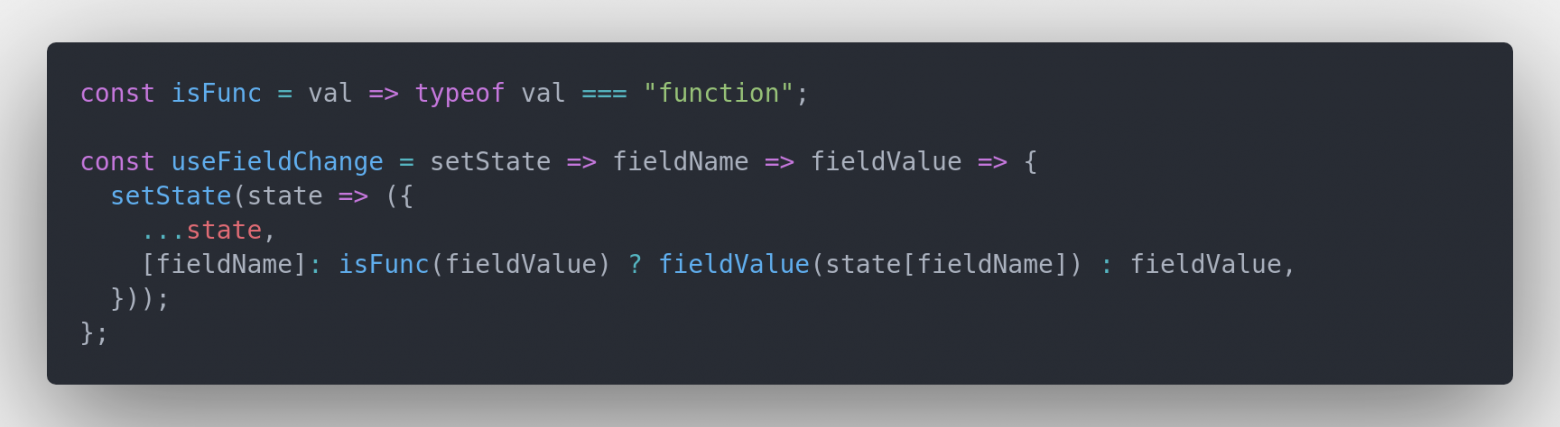
Добавим поддержку
callback на месте fieldValue, чтобы полностью повторить поведение обычного setState из React:
Код для копирования
const isFunc = val => typeof val === "function"; const useFieldChange = setState => fieldName => fieldValue => { setState(state => ({ ...state, [fieldName]: isFunc(fieldValue) ? fieldValue(state[fieldName]) : fieldValue, })); };
Пример использования с нашей формой:
Код для копирования
const LogInForm = ({ initialData, onSubmit }) => { const [logInData, setLogInData] = useState(initialData); const handleChange = useFieldChange(setLogInData); const handleSubmit = e => { e.preventDefault(); onSubmit(logInData); }; return ( <form onSubmit={handleSubmit}> <InputField label="Enter your nickname" value={logInData.nickname} onChange={handleChange('nickname')} /> <InputField type="email" label="Enter your email" value={logInData.email} onChange={handleChange('email')} /> <InputField type="password" label="Enter your password" value={logInData.password} onChange={handleChange('password')} /> <button>Submit</button> </form> ); };
Но если в вашем приложении только одна форма, все это делать не нужно! Потому, что это противоречит принципу YAGNI, следуя которому мы не должны делать то, что нам не нужно для решения конкретной задачи. Если у вас только одна форма, то реальной пользы от таких телодвижений мало. Ведь мы сократили код нашего компонента только на 3 строчки, но ввели дополнительную абстракцию, скрыв определенную логику формы, которую лучше держать на поверхности.
О, нет! Не делайте так, пожалуйста!
Формы из замоканых конфигов
Замоканные конфиги — это как webpack конфиг, только для формы.
Лучше на примере, посмотрите на этот псевдокод:
Код для копирования
const Form = () => ( <form onSubmit={handleSubmit}> <InputField label="Enter your nickname" value={state.nickname} onChange={handleChange('nickname')} /> <InputField type="email" label="Enter your email" value={state.email} onChange={handleChange('email')} /> <InputField type="password" label="Enter your password" value={state.password} onChange={handleChange('password')} /> <button>Submit</button> </form> );
Некоторым может показаться, что здесь дублируется код, ведь мы же вызываем один и тот же компонент InputField, передавая туда одни и те же параметры label, value и onChange. И они начинают за-DRY-ивать собственный код, чтобы избежать мнимого дублирования.
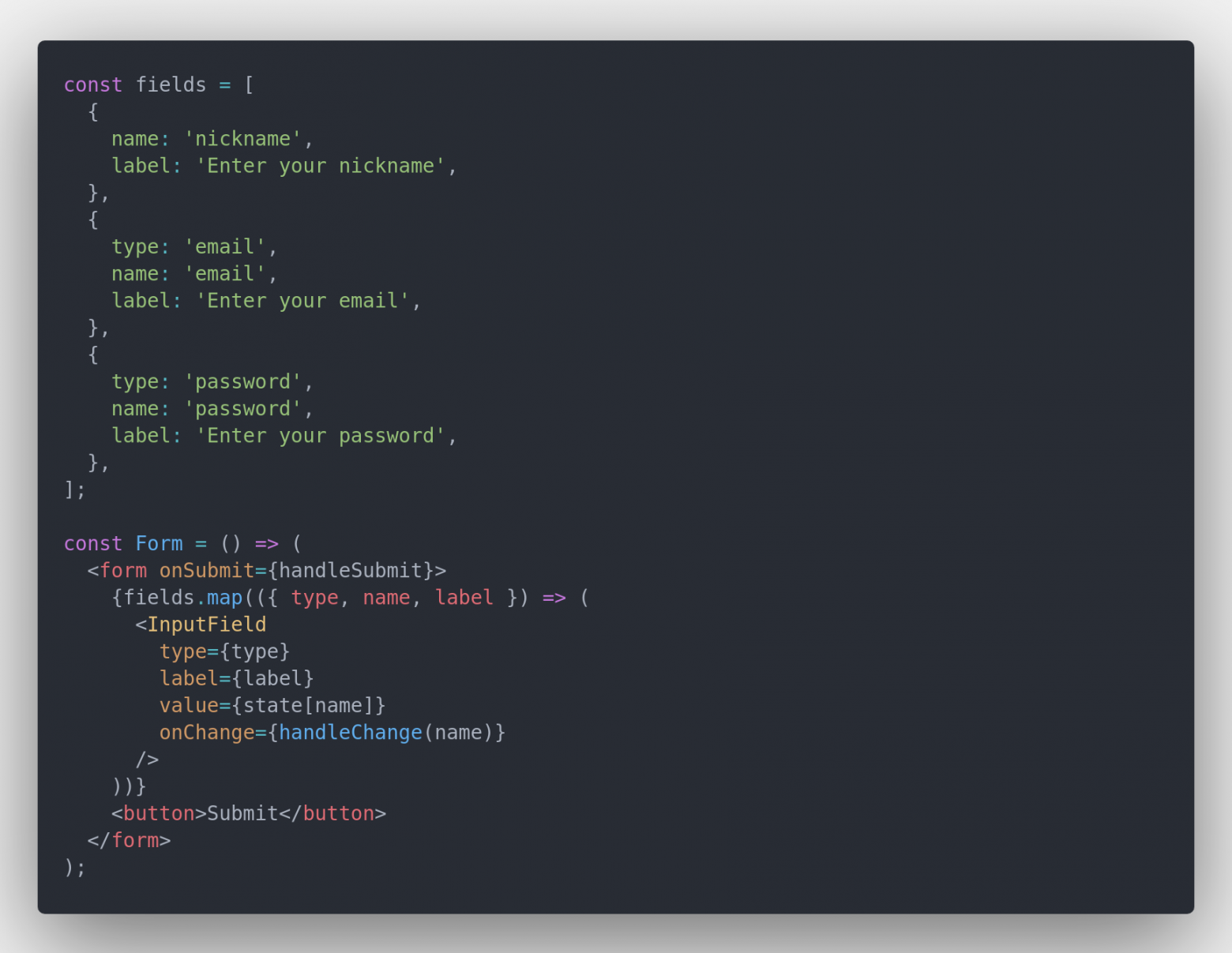
Часто это делают примерно так:
Код для копирования
const fields = [ { name: 'nickname', label: 'Enter your nickname', }, { type: 'email', name: 'email', label: 'Enter your email', }, { type: 'password', name: 'password', label: 'Enter your password', }, ]; const Form = () => ( <form onSubmit={handleSubmit}> {fields.map(({ type, name, label }) => ( <InputField type={type} label={label} value={state[name]} onChange={handleChange(name)} /> ))} <button>Submit</button> </form> );
JSX стало меньше.
Но, как результат, мы получили более сложный код, нарушив принцип KISS. Ведь теперь он состоит из 2-х абстракций: fields и алгоритм (да, алгоритм — это тоже абстракция), который превращает его в дерево React-элементов. При чтении этого кода нам придется постоянно прыгать между этими абстракциями.
Но самая большая проблема этого кода — это его поддержка и расширение.
Представте, что с ним случится, если:
- добавится еще несколько типов полей с разными возможными свойствами
- поля рендерятся или не рендерятся на основе ввода других полей
- некоторые поля требуют какой-то дополнительной обработки при изменении
- значения в селектах зависит от прерыдущих селектов
Этот список можно продолжать долго…
Для реализации этого всегда придется хранить какие-то функции в вашем конфиге, а код, который рендерит конфиг, постепенно превратится в Франкенштейна, принимая кучу разных пропсов и закидывая их по разным компонентам.
Код, который был написан до этого, основанный на композиции компонентов, будет спокойно расширяться, меняться как угодно, при этом не сильно усложнясь благодаря отсутсвию промежуточной абстракции — алгоритма, который строит дерево React-элементов из нашего конфига. Этот код не является дублирующимся. Он просто следует определенному шаблону проектирования, поэтому и выглядит «шаблонным».
Бесполезная оптимизация
После появления хуков в React появилась тенденция оборачивають все обработчики и компоненты без разбора в
useCallback и memo. Пожалуйста, не делайте этого! Данные хуки предоставлены разработчиками React не потому, что React медленный и все нужно оптимизировать. Они дают пространство для оптимизации вашему приложению в случае, если вы столкнетесь с проблемами производительности. И даже если вы столкнулись с такими проблемами, не нужно оборачивать весь проект в memo и useCallback. Используйте Profiler для выявления проблем и только потом мемоизацию в нужном месте.Мемоизация всегда сделает ваш код сложнее, но не всегда производительнее.
Давайте рассмотрим код из реального проекта. Сравните, как выглядит функция с использованием
useCallback и без него:
Код для копирования
const applyFilters = useCallback(() => { const newSelectedMetrics = Object.keys(selectedMetricsStatus).filter( metric => selectedMetricsStatus[metric], ); onApplyFilterClick(newSelectedMetrics); }, [selectedMetricsStatus, onApplyFilterClick]); const applyFilters = () => { const newSelectedMetrics = Object.keys(selectedMetricsStatus).filter( metric => selectedMetricsStatus[metric], ); onApplyFilterClick(newSelectedMetrics); };
Читабельность кода явно выросла после удаления обертки, ведь идеальный код — это его отсутсвие.
Производительность этого кода не выросла, ведь эта функция используется так:
Код для копирования
<RightFooterButton onClick={applyFilters}>APPLY</RightFooterButton>
Где
RightFooterButton — это просто styled.button из styled-components, который обновится очень быстро. А вот потребление памяти нашим приложением увеличиться, потому что React всегда будет держать в памяти selectedMetricsStatus, onApplyFilterClick и версию функции applyFilters, актуальную для этих зависимостей.Если этих аргументов вам недостаточно, прочитайте статью, в которой эта тема раскрыта шире.
Выводы
- Формы в React — это просто. Проблемы с ними возникают из-за самих разработчиков и документации React, в которой эта тема раскрыта недостаточно подробно.
- Для удобной работы с вашими компонентами держите ввод и вывод aka value и onChange одного типа. Это позволит вам использовать хук-утилиту useFieldChange, описанный выше и получить чуть более многословный, но не мение мощный аналог
v-modelизVueдля комфортной работы.
- При написании кода в первую очередь следуйте принципам KISS и YAGNI. А затем уже DRY, но осторожно, чтобы случайно не создать плохую абстракцию.
- Избегайте описывания ваших форм с помощью конфигов, если такой подход не навязывает ваш фреймворк или библиотека, ведь там алгоритм по превращению конфигов в React-дерево скрыт за их абстракцией.
- Всегда избегайте оптимизаций, если в них нет явной необходимости.
P.S.
Изначально я планировал написать о декларативной валидации сложных вложенных форм. Но, в итоге, решил подготовить аудиторию к этому, чтобы картина была максимально полной.
Следующий туториал будет о валидации простой формы, реализованной в этом туториале.
Огромное спасибо всем, кто дочитал до конца!
Не важно, как вы пишите код или чем занимаетесь, главное — получайте от этого удовольствие.

