
Привет, Хабр. Перевод этой статьи занял намного больше времени, чем ожидалось. Мне очень хотелось сделать всё качественно и без обмана, но если найдёте неточности, буду рад услышать о них. Также я буду сам перечитывать и исправлять ошибки предыдущих статей, если где-то оказался не прав. Мне предстоит перевести ещё около 4-5 статей такого объёма, поэтому прошу оценить мой труд, если вам понравилось.
Оглавление
- 1 часть
- 2 часть
Компиляция исходного кода Python
Python обычно не рассматривается как компилируемый язык, но на самом деле он является таковым. Во время компиляции исходный код, написанный на Python, преобразуется в байт-код, который потом выполняется виртуальной машиной. Однако, процесс компиляции в Python является довольно простым и не включает в себя множество сложных этапов. Он состоит из следующих шагов в указанном порядке:
- Преобразование исходного python кода в «парсинговые» деревья.
- Преобразование «парсинговых» деревьев в абстрактные синтаксические деревья (AST).
- Генерация таблицы символов.
- Создание объектов кода из AST. Этот шаг включает в себя:
- Преобразование AST в граф потока управления.
- Получение объекта кода из графа потока управления.
Создание «парсинговых» деревьев и их преобразование в AST является стандартным процессом. Python не вносит в него каких-либо сложных нюансов, поэтому в этой главе основное внимание уделяется преобразованию AST в граф потока управления и получению из этого графа объектов кода. Для тех, кто заинтересован в парсинговых деревях и генерации AST, существует «драконья» книга, которая даёт более углубленный tour de force [прим. с французского: «Большое усилие»] по обоим из этих тем.
От исходников к дереву парсинга
Парсер Python — это синтаксический анализатор LL (1), он основывается на принципах, которые изложены в «драконьей» книге. Модуль Grammar/Grammar содержит расширенную форму Бэкуса — Наура (Extended Backus-Naur Form (EBNF)) со спецификацией грамматики языка Python. Отрывок этой спецификации показан в листинге 3.0.
1 stmt: simple_stmt | compound_stmt 2 simple_stmt: small_stmt (';' small_stmt)* [';'] NEWLINE 3 small_stmt: (expr_stmt | del_stmt | pass_stmt | flow_stmt | 4 import_stmt | global_stmt | nonlocal_stmt | assert_stmt) 5 expr_stmt: testlist_star_expr (augassign (yield_expr|testlist) | 6 ('=' (yield_expr|testlist_star_expr))*) 7 testlist_star_expr: (test|star_expr) (',' (test|star_expr))* [','] 8 augassign: ('+=' | '-=' | '*=' | '@=' | '/=' | '%=' | '&=' | '|=' | '^=' 9 | '<<=' | '>>=' | '**=' | '//=') 10 11 del_stmt: 'del' exprlist 12 pass_stmt: 'pass' 13 flow_stmt: break_stmt | continue_stmt | return_stmt | raise_stmt | 14 yield_stmt 15 break_stmt: 'break' 16 continue_stmt: 'continue' 17 return_stmt: 'return' [testlist] 18 yield_stmt: yield_expr 19 raise_stmt: 'raise' [test ['from' test]] 20 import_stmt: import_name | import_from 21 import_name: 'import' dotted_as_names 22 import_from: ('from' (('.' | '...')* dotted_name | ('.' | '...')+) 23 'import' ('*' | '(' import_as_names ')' | import_as_names)) 24 import_as_name: NAME ['as' NAME] 25 dotted_as_name: dotted_name ['as' NAME] 26 import_as_names: import_as_name (',' import_as_name)* [','] 27 dotted_as_names: dotted_as_name (',' dotted_as_name)* 28 dotted_name: NAME ('.' NAME)* 29 global_stmt: 'global' NAME (',' NAME)* 30 nonlocal_stmt: 'nonlocal' NAME (',' NAME)* 31 assert_stmt: 'assert' test [',' test] 32 33 ...
Листинг 3.0. Отрывок синтаксиса BNF в Python
При выполнении модуля, переданного интерпретатору в командной строке, совершается вызов PyParser_ParseFileObject. Эта функция инициирует синтаксический анализ файла. Она же вызывает функцию токенизации PyTokenizer_FromFile, передавая ей имя файла-модуля в качестве аргумента. Функция токенизации в Python разбивает содержимое модуля на правильные токены или же выдает исключение при обнаружении недопустимых.
Python токены
Исходный код Python состоит из токенов. Например, слово return является ключевым токеном, а литерал — 2 числовым и так далее. Первая задача при синтаксическом анализе состоит в том, чтобы токенизировать исходный код, разбив его на токены-компоненты. В Python есть несколько видов токенов:
- Идентификаторы — это имена, которые определены программистом. Они включают имена функций, переменных, классов и т.д. Они должны соответствовать правилам именования идентификаторов, указанным в документации python.
- Операторы — это специальные символы, такие как: + и *, которые работают со значениями данных и возвращают какой-то результат.
- Ограничители — эти символы служат для группировки выражений, пунктуации и присваивания. Члены этой категории включают в себя: (, ), {,}, =, *= и т.д.
- Литералы — это символы, которые обеспечивают постоянное значение для некоторого типа. У нас есть строковые и байтовые литералы, такие как «Fred» и b«Fred», числовые литералы, которые включают: целочисленные литералы, такие как 2, литералы с плавающей запятой: 1e100 и мнимые литералы: 10j.
- Комментарии — это строковые литералы, которые начинаются с символа #. Токены комментариев всегда заканчиваются «физическим» концом строки.
- NEWLINE — это специальный токен, который обозначает конец «логической» строки.
- INDENT и DEDENT — эти токены используются для представления уровней отступов, которые группируют инструкции.
Группа токенов, отделённая NEWLINE, образует логическую линию, которая соотносится с python инструкциями. То есть, мы можем сказать, что python-программа состоит из последовательности логических строк, каждая из которых отделена токеном NEWLINE. Каждая из этих логических строк состоит из нескольких физических, которые в свою очередь, оканчиваются символом перевода строки. Но в Python логические строки чаще всего совпадают с физическими, поэтому в большинстве случаев мы можем сказать, что логические строки разделяются символами конца строки. Составные инструкции могут занимать несколько физических строк, как это показано на рисунке 3.0. Логические строки могут быть образованы неявно (через заключение выражения в круглые, квадратные или фигурные скобки) или явно, с помощью символа обратной косой черты. Отступ также играет центральную роль в группировке операторов Python. Таким образом, одна из строк в грамматике питона может выглядеть так: suite: simple_stmt | NEWLINE INDENT stmt+ DEDENT. Как следствие, одна из основных задач токенайзера Python заключается в генерировании токенов отступа и обратного-отступа, которые добавляются в дерево парсинга. Токенайзер использует стек для отслеживания отступов и использует алгоритм из листинга 3.1
Инициируйте стек отступов значением 0. Для каждой логической строки с учетом объединения строк: A. Если отступ текущей строки больше отступа в верхней части стека 1. Добавьте отступ текущей строки в верхнюю часть стека. 2. Сгенерируйте токен INDENT. B. Если отступ текущей строки меньше отступа в верхней части стека 1. Если в стеке нет уровня отступа, соответствующего отступу текущей строки, сообщите об ошибке. 2. Для каждого значения в верхней части стека, которое не равно отступу текущей строки. a. Удалить значение из верхней части стека. b. Создайте токен DEDENT. C. Токенизация текущей строки. Для каждого отступа в стеке, кроме 0, создайте токен DEDENT.
Листинг 3.1: Python алгоритм для генерации токенов INDENT и DEDENT.
Функция PyTokenizer_FromFile из модуля Parser/parsetok.c сканирует исходный Python файл слева-направо и сверху-вниз производя токенизацию содержимого. Символы пробелов (отличные от терминаторов) служат для разграничения токенов, но не являются обязательными. Там, где есть некоторая двусмысленность, такая как: 2+2, токенайзер пытается выделить максимально длинную строку, которая формирует легальный токен при чтении справа налево. В данном примере токенами являются литерал 2, оператор + и ещё один литерал 2.
Сгенерированные токены передаются парсеру, который пытается построить из них дерево «парсинга» (в соответствии с грамматикой python, подмножество которой указано в листинге 3.0). Когда анализатор обнаруживает токен, нарушающий грамматику, генерируется исключение SyntaxError. Модуль parser предоставляет ограниченный доступ к дереву конкретного кода Python и используется в листинге 3.2 для получения примера синтаксического дерева.
1 >>>code_str = """def hello_world(): 2 return 'hello world' 3 """ 4 >>> import parser 5 >>> from pprint import pprint 6 >>> st = parser.suite(code_str) 7 >>> pprint(parser.st2list(st)) 8 [257, 9 [269, 10 [294, 11 [263, 12 [1, 'def'], 13 [1, 'hello_world'], 14 [264, [7, '('], [8, ')']], 15 [11, ':'], 16 [303, 17 [4, ''], 18 [5, ''], 19 [269, 20 [270, 21 [271, 22 [277, 23 [280, 24 [1, 'return'], 25 [330, 26 [304, 27 [308, 28 [309, 29 [310, 30 [311, 31 [314, 32 [315, 33 [316, 34 [317, 35 [318, 36 [319, 37 [320, 38 [321, 39 [322, [323, [3, '"hello world"']]]]]]]]]]]]]]]]]]]], 40 [4, '']]], 41 [6, '']]]]], 42 [4, ''], 43 [0, '']] 44 >>>
Листинг 3.2. Использование модуля parser для получения дерева в Python
Вызов parser.suite(source) в листинге 3.2 возвращает объект дерева (ST), который является промежуточным представлением дерева парсинга из исходного кода (предполагается, что исходный код синтаксически корректен). Вызов parser.st2list возвращает фактическое синтаксическое дерево, представленное в виде списка python. Первые элементы в списках — целые числа, которое идентифицируют продукционные правила в грамматике Python.
Если я ещё сам правильно понял термин production rules...
Продукционных правило в информатике — специальное правило, определяющее рекурсивную замену одних символов на другие.
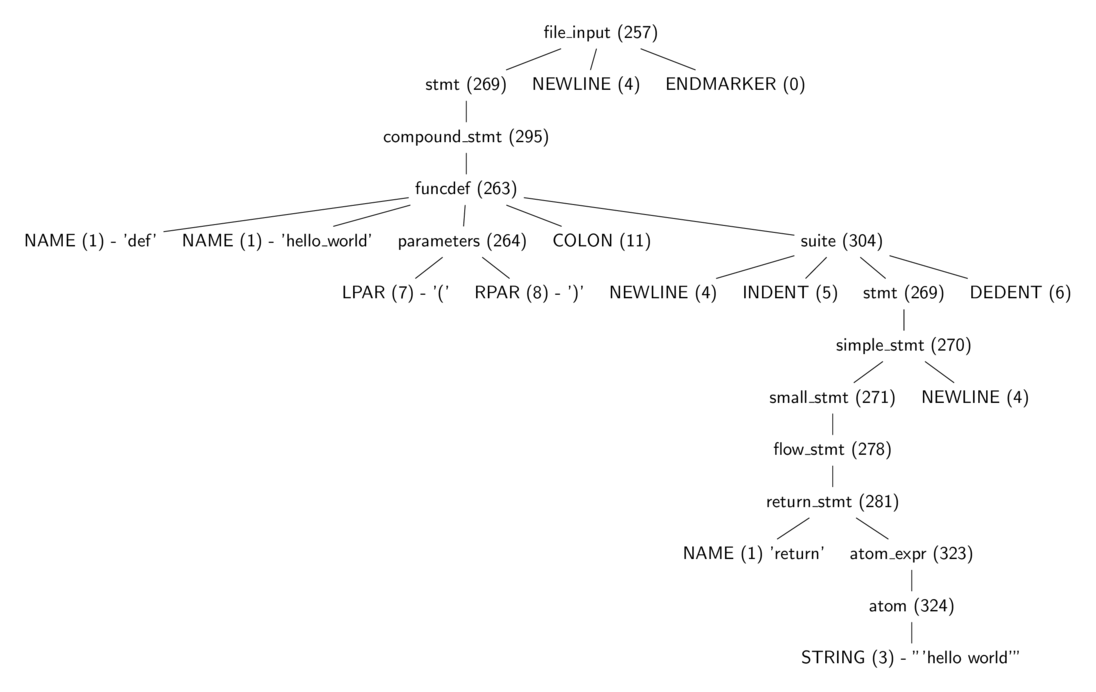
Рисунок 3.0: Дерево парсинга для листинга 3.2 (функция, возвращающая строку 'hello world')
Рисунок 3.0 — это древовидная диаграмма, показывающая то же дерево из листинга 3.2, но уже с некоторыми удаленными токенами, а также часть команд была заменена строковыми описаниями в соответствии числовым номерам. Все эти продукционные правила указаны в заголовочных файлах Include/token.h и Include/graminit.h.
В виртуальной машине CPython для представления дерева парсинга используется древовидная структура данных. Каждое продукционное правило — это узел в ней. Структура данных нода (узла) из Include/node.h показана в листинге 3.3.
1 typedef struct _node { 2 short n_type; 3 char *n_str; 4 int n_lineno; 5 int n_col_offset; 6 int n_nchildren; 7 struct _node *n_child; 8 } node;
Листинг 3.3: Структура данных нода в виртуальной машине
По мере обхода дерева парсинга узлы могут запрашиваться по их типу, дочерним элементам (если таковые имеются), номеру строки исходного файла (которая привела к созданию данного узла) и так далее. Макросы для взаимодействия с узлами дерева парсинга также определены в файле Include/node.h.
От дерева парсинга к абстрактному синтаксическому дереву
Следующим этапом процесса компиляции в python является преобразование деревьев парсинга в абстрактное синтаксическое дерево (AST). Абстрактное синтаксическое дерево является представлением кода, которое не зависит от тонкостей синтаксиса python. Например, дерево парсинга на рисунке 3.0 содержит узел «двоеточие» [прим. двоеточие объявления функции], потому что это синтаксическая конструкция, но, как показано в листинге 3.4, AST не будет содержать таких «подробностей».
1 >>> import ast 2 >>> import pprint 3 >>> node = ast.parse(code_str, mode="exec") 4 >>> ast.dump(node) 5 ("Module(body=[FunctionDef(name='hello_world', args=arguments(args=[], " 6 'vararg=None, kwonlyargs=[], kw_defaults=[], kwarg=None, defaults=[]), ' 7 "body=[Return(value=Str(s='hello world'))], decorator_list=[], " 8 'returns=None)])')
Листинг 3.4. Использование astмодуля для управления AST исходного кода Python
Различные определения узлов AST находятся в файле Parser/Python.asdl. Большинство определений в AST соответствуют конкретной исходной конструкции, такой как оператор if или поиск атрибута. Модуль ast вместе с Python-интерпретатором дает нам возможность манипулировать AST. Такие инструменты как codegen могут по конкретному AST вывести исходный код python. В реализации CPython AST-узлы представлены C-структурами, которые определены в Include/Python-ast.h. Эти структуры фактически генерируются кодом Python. Модуль Parser/asdl_c.py генерирует этот файл из AST определения ASDL. Например, вот кусок из определения нода statement, который показан в листинге 3.5.
1 struct _stmt { 2 enum _stmt_kind kind; 3 union { 4 struct { 5 identifier name; 6 arguments_ty args; 7 asdl_seq *body; 8 asdl_seq *decorator_list; 9 expr_ty returns; 10 } FunctionDef; 11 12 struct { 13 identifier name; 14 arguments_ty args; 15 asdl_seq *body; 16 asdl_seq *decorator_list; 17 expr_ty returns; 18 } AsyncFunctionDef; 19 20 struct { 21 identifier name; 22 asdl_seq *bases; 23 asdl_seq *keywords; 24 asdl_seq *body; 25 asdl_seq *decorator_list; 26 } ClassDef; 27 ... 28 }v; 29 int lineno; 30 int col_offset 31 }
Union в листинге 3.5 — это ключевое слово языка C, которое используется для создания атрибута, который может принимать один из любых типов, перечисленных в самом union. Функция PyAST_FromNode в модуле Python/ast.c отвечает за генерацию AST из данного дерева парсинга. Теперь пришло время создавать байт-код из сгенерированного AST.
Построение таблицы символов
Следующим шагом после создания AST является генерация таблицы символов. Таблица символов, как и предполагает название, представляет собой набор имен, используемый в блоке кода и другом контекст. Процесс построения таблицы символов включает в себя анализ имен (содержащихся в блоке кода) и присвоение таким именам правильной области видимости. Возможно, прежде чем обсуждать тонкости построения таблиц символов, стоит повторить имена и связывания (binding) в python.
Имена и Связывания
В python на объекты ссылаются по именам. «Names» похожи на переменные в C++ или Java, но это не совсем так.
>>> x = 5
В приведенном выше примере x — это имя, которое ссылается на объект: 5. Процесс присвоения ссылки на значение 5 к x называется биндингом. Связывание приводит к тому, что имя начинает ссылаться на объект, расположенный внутри самой вложенной области видимости текущей исполняемой программы. Связывание происходит во многих случаях, например, при присваивании переменной, функции, а также метода, когда переданный параметр привязан к аргументу и т.д. Важно отметить, что имена — это просто символы и они не имеют типа, который ассоциируется с ними. Тип существует у самих объектов, на которые эти имена ссылаются.
Блоки кода
Блоки кода являются центральной частью для Python программы и их понимание имеет первостепенное значение для изучения внутреннего устройства виртуальной машины Python. Блок кода — это фрагмент программного кода, который выполняется в Python как единое целое. Примерами блоков кода являются модули, функции и классы. Команды, введенные в интерактивном режиме в REPL, команды сценария запускаемые с флагом -c, также являются блоками кода. Блок кода имеет несколько пространств имен, связанных с ним. Например, блок кода модуля имеет доступ к пространству имен global, а блок кода функции имеет также доступ к пространству имен local, по-мимо пространства global.
Пространства имен
Пространство имен (namespace) является контекстом, в котором какой-то набор имен связан с объектами. Пространства имен Python реализованы в виде словаря. Встроенное пространство имен является примером namespace, которое содержит все встроенные функции и доступ к нему можно получить через ввод __builtins__.__dict__ в терминале (выходной текст будет довольно большим). Интерпретатор имеет доступ к нескольким пространствам имен, в том числе к глобальному, встроенному и локальному. Данные в namespace создаются в разное время и также имеют разное время жизни. Например, новое локальное пространство имен создается при вызове функции и удаляется при её окончании или выходе из функции. Глобальное пространство имен создаётся в начале выполнения модуля и все имена, определенные в этом namespace, доступны во всём модуле. Встроенная область видимости создаётся, когда вызывается интерпретатор и он уже содержит все встроенные имена. Эти три пространства имен являются основными namespace доступными интерпретатору.
Области видимости
Область видимости — это часть программы, в которой набор биндингов (пространство имен) виден и доступен напрямую без использования точечной нотации. [прим. кажется, здесь опечатка и имеется ввиду доступ через функцию globals()]. Во время выполнения программы могут быть доступны следующие области видимости:
- Самая «внутренняя» область видимости, содержащая локальные переменные
- При вложенных функциях, во вложенной функции можно получить доступ к пространству имён более «внешней».
- Глобальная область видимости текущего модуля
- Область видимости, содержащая встроенное пространство имен
Когда в python упоминается имя, интерпретатор ищет пространство имен области видимости в порядке возрастания (как указано выше) и если имя не найдено ни в одном из пространств имен, возникает исключение. Python поддерживает статическую область видимости (также известную как лексическая область видимости). Это означает, что видимость биндингов имен может быть определена только путем проверки текста программы.
Примечание
В Python есть своеобразное правило для области видимости, которое предотвращает изменение ссылки на объект глобальной области видимости в локальной. Такое действие приведет к исключению UnboundLocalError. Следующий пример иллюстрирует это:
>>> a = 1 >>> def inc_a(): a += 2 ... >>> inc_a() Traceback (most recent call last): File "<stdin>", line 1, in <module> File "<stdin>", line 1, in inc_a UnboundLocalError: local variable 'a' referenced before assignment
Листинг A3.0. Попытка изменить глобальную переменную из функции
Чтобы изменить «глобальный» объект в локальной области, необходимо использовать ключевое слово global с именем объекта:
>>> a = 1 >>> def inc_a(): ... global a ... a += 1 ... >>> inc_a() >>> a 2
Листинг A3.1. Использование ключевого слова global для изменения глобальной переменной из функции
Python также имеет ключевое слово nonlocal. Оно используется, когда необходимо изменить переменную, находящуюся во внешней, но «не глобальной» области видимости. Это очень удобно при работе с вложенными функциями (также называемыми замыканиями). Очень простая иллюстрация ключевого слова nonlocal показана в следующем фрагменте, который определяет простой счетчик для объекта:
>>> def make_counter(): ... count = 0 ... def counter(): ... nonlocal count #capture count binding from enclosing not global scope ... count += 1 ... return count ... return counter ... >>> counter_1 = make_counter() >>> counter_2 = make_counter() >>> counter_1() 1 >>> counter_1() 2 >>> counter_2() 1 >>> counter_2() 2
Листинг A3.2. Вложенные функции со счётчиком
Последовательность вызовов функций run_mod -> PyAST_CompileObject -> PySymtable_BuildObject запускает процесс построения таблицы символов. Два аргумента функции PySymtable_BuildObject — это ранее сгенерированный AST и имя модуля. Алгоритм построения таблицы символов разбит на две части. В первой «посещается» каждый узел AST, чтобы создать коллекцию символов, используемых в AST. Очень простое описание этого процесса приведено в листинге 3.6, и термины, используемые в нем, станут более очевидными, когда мы обсудим структуры данных, используемые при построении таблицы символов.
for каждый_узел in AST if узел == начало_блока_кода: 1. Cоздайть новую запись в таблице символов и установите это значение текущей таблице символов 2. Сделайте "push" новой таблицы в st_stack. 3. Добавьте новую таблицу символов в список дочерних предыдущей таблицы. 4. Замените текущую таблицу только что созданной 5. for все_узлы in узлы_блока_кода: a. Рекурсивно посетить каждый узел функцией "symtable_visit_XXX", где "XXX" это тип узла. 6. Выйти из блока кода, через удаление текущей таблицы символов из стека. 7. Сделайте "pop" следующей таблицы символов из стека и обновите значение текующей таблицы символов этим значением. else: рекурсивно посетить узел и под-узел.
Листинг 3.6. Создание таблицы символов из AST
После первого прохода алгоритма таблица символов содержит все имена, которые использовались в модуле, но не содержит контекстной информации о них. Например, интерпретатор не может определить, является ли данная переменная глобальной, локальной или свободной. Вызов функции symtable_analyze из Parser/symtable.c инициирует вторую фазу генерации таблицы символов. Эта фаза алгоритма определяет область видимости (локальную, глобальную или свободную) для символов, полученных на первом этапе. Комментарии в файле Parser/symtable.c достаточно информативны и перефразированы ниже, чтобы дать представление о втором этапе процесса построения таблицы символов:
- Чтобы определить область видимости каждого имени необходимо два этапа. Первый собирает необработанные «факты» из AST через функции symtable_visit_ *, а второй анализирует эти «факты» во время прохода над объектами PySTEntryObject, созданными в первом этапе.
- Когда второй проход заходит внутрь функции, родительский элемент передает набор всех биндингов, видимых для его дочерних элементов. Эти связывания используются, что выяснить: являются ли non-local переменные свободными или неявными глобальными. Имена, которые явно объявлены non-local, должны существовать в этом наборе видимых имен — если их нет, возникает синтаксическая ошибка. После локального анализа функция анализирует каждый из своих дочерних блоков, используя обновленный набор биндингов.
- Есть также два вида глобальных переменных: явные и неявные. Явные глобальные переменные объявляются оператором global. Неявная глобальная переменная — это свободная переменная, для которой компилятор не нашел биндинга в локальной области видимости текующей функции. Неявные глобальные переменные является либо глобальным, либо встроенным.
Модули Python и блоки классов используют опкоды xxx_NAME для обработки этих имен, чтобы реализовать слегка странную семантику. В таком блоке имя обрабатывается как глобальное, пока оно не будет «переприсвоено». После этого переменная трактуется как локальная. - Потомки обновляют набор свободных переменных. Если локальная переменная добавляется в набор свободных переменных c пометкой «установлена дочерним элементом», то переменная помечается как ячейка. Объект функции должен обеспечивать runtime хранилище для переменной, которая может пережить фрейм функции. Поэтому переменные-ячейки удаляются из набора свободных переменных прежде, чем функция анализа возвращается к своему родителю.
Комментарии в модуле пытаются объяснить процесс построения таблицы символов понятным языком, но есть некоторые запутанные моменты. Например: родитель передает набор всех биндингов, видимых его дочерним элементам — но на какого родителя и на какие дочерние элементы они конкретно ссылаются? Чтобы получить представление об этом, нам нужно взглянуть на структуры данных, которые используются в процессе создания таблицы символов.
Структуры данных таблицы символов
Существует две структуры данных, которые являются центральными для генерации таблицы символов:
- Структура данных таблицы символов.
- Структура данных записи таблицы символов.
Структура данных таблицы символов приведена в листинге 3.7. Можно думать о ней, как о таблице состоящей из записей и содержащей информацию об именах, используемых в различных блоках кода данного модуля.
1 struct symtable { 2 PyObject *st_filename; /* name of file being compiled */ 3 struct _symtable_entry *st_cur; /* current symbol table entry */ 4 struct _symtable_entry *st_top; /* symbol table entry for module */ 5 PyObject *st_blocks; /* dict: map AST node addresses 6 * to symbol table entries */ 7 PyObject *st_stack; /*list: stack of namespace info */ 8 PyObject *st_global; /*borrowed ref to 9 st_top->ste_symbols*/ 10 int st_nblocks; /* number of blocks used. kept for 11 consistency with the corresponding 12 compiler structure */ 13 PyObject *st_private; /* name of current class or NULL */ 14 PyFutureFeatures *st_future; /* module's future features that 15 affect the symbol table */ 16 int recursion_depth; /* current recursion depth */ 17 int recursion_limit; /* recursion limit */ 18 };
Листинг 3.7. Структура данных таблицы символов.
Модуль Python может содержать несколько блоков кода — например, несколько определений функций. Поле st_blocks является отображением всех существующих блоков кода в один элемент таблицы символов. Запись таблицы st_top — это таблица символов для компилируемого модуля (напомним, что модуль также является блоком кода), поэтому она будет содержать имена, определенные в глобальном пространстве имен модуля. Поле st_cur относится к записи таблицы символов для кодового блока, который обрабатывается в данный момент. Каждый блок кода внутри «блока кода модуля» имеет свою собственную запись таблицы символов, которая содержит символы, определенные в этом блоке кода.
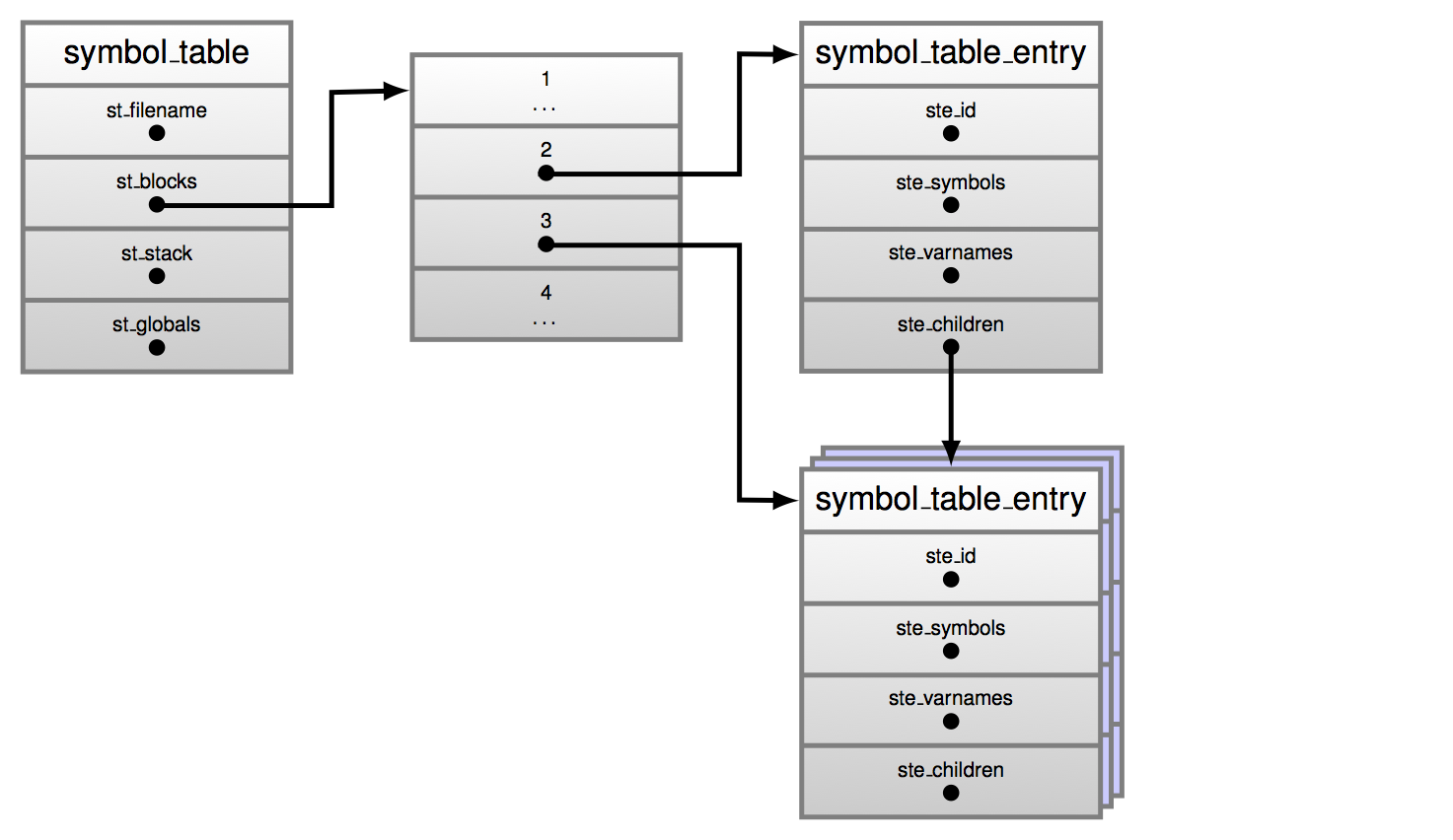
Рисунок 3.1: таблица символов и записи в ней.
В очередной раз, просмотр структуры данных _symtable_entry из файла Include/symtable.h очень полезен, чтобы понять, как она работает. Данная структура данных показана в листинге 3.8.
1 typedef struct _symtable_entry { 2 PyObject_HEAD 3 PyObject *ste_id; /* int: key in ste_table->st_blocks */ 4 PyObject *ste_symbols; /* dict: variable names to flags */ 5 PyObject *ste_name; /* string: name of current block */ 6 PyObject *ste_varnames; /* list of function parameters */ 7 PyObject *ste_children; /* list of child blocks */ 8 PyObject *ste_directives; /* locations of global and nonlocal 9 statements */ 10 _Py_block_ty ste_type; /* module, class, or function */ 11 int ste_nested; /* true if block is nested */ 12 unsigned ste_free : 1; /*true if block has free variables*/ 13 unsigned ste_child_free : 1; /* true if a child block has free 14 vars including free refs to globals*/ 15 unsigned ste_generator : 1; /* true if namespace is a generator */ 16 unsigned ste_varargs : 1; /* true if block has varargs */ 17 unsigned ste_varkeywords : 1; /* true if block has varkeywords */ 18 unsigned ste_returns_value : 1; /* true if namespace uses return with 19 an argument */ 20 unsigned ste_needs_class_closure : 1; /* for class scopes, true if a 21 closure over __class__ 22 should be created */ 23 int ste_lineno; /* first line of block */ 24 int ste_col_offset; /* offset of first line of block */ 25 int ste_opt_lineno; /* lineno of last exec or import * */ 26 int ste_opt_col_offset; /* offset of last exec or import * */ 27 int ste_tmpname; /* counter for listcomp temp vars */ 28 struct symtable *ste_table; 29 } PySTEntryObject;
Листинг 3.8. Структура данных _symtable_entry
Комментарии в исходном коде объясняют, что делает каждое поле. Поле ste_symbols содержит отображение символов/имен, которые встречаются при анализе блока кода. Флаги, на которые отображаются символы, представляют собой числовые значения, которые дают нам информацию о контексте, в котором используется символ/имя. Например, символ может быть аргументом функции или определением глобального оператора. Некоторые примеры этих флагов, определенных в модуле Include/symtable.h, приведены в листинге 3.9.
1 /* Flags for def-use information */ 2 #define DEF_GLOBAL 1 /* global stmt */ 3 #define DEF_LOCAL 2 /* assignment in code block */ 4 #define DEF_PARAM 2<<1 /* formal parameter */ 5 #define DEF_NONLOCAL 2<<2 /* nonlocal stmt */ 6 #define DEF_FREE 2<<4 /* name used but not defined in 7 nested block */
Листинг 3.9. Флаги, которые определяют контекст определения имени
Возвратимся же к обсуждению таблиц символов. Предположим, что компилируется модуль, содержащий код из листинга 3.10. После того, как таблица символов построена, есть три записи таблицы символов.
def make_counter(): count = 0 def counter(): nonlocal count count += 1 return count return counter
Листинг 3.10. Простая функция Python
Первая запись make_counter является замыканием модуля и будет определена областью видимости local. Следующая запись таблицы символов будет о том, что функция make_counter содержит имена count и counter, помеченные как локальные. Последняя запись таблицы символов будет о вложенной функции counter. Она будет иметь переменную count, помеченную как free. Следует отметить, что хоть make_counter и определена как локальная в записи таблицы символов, но она рассматривается как глобальная в самом блоке кода модуля, поскольку *st_global указывает на символы *st_top, которые в данном случае являются символами замыкающего модуля.
От AST к объектам кода
Следующим шагом для компилятора является генерация объектов кода из информации полученной благодаря AST и таблицам символов. Отвечающие за это функции, реализованы в модуле Python/compile.c. Процесс создания объектов кода является многоэтапным. На первом шаге AST преобразуется в базовые блоки инструкций байт-кода Python. Алгоритм преобразования похож на тот, который используется при генерации таблиц символов — функции с именами compiler_visit_xx (где xx этот тип узла) рекурсивно посещают каждый узел и генерируют базовые блоки инструкций байт-кода. Базовые блоки и связи между ними представляются в виде графа — графа потока управления [прим. именуемый также CFG — control flow graph]. Он показывает «пути» кода, которые могут быть использованы во время выполнения программы. На втором этапе сгенерированный граф потока управления «сглаживается» с использованием поиска по графу в глубину (DFS). После того как граф сглажен, рассчитывается смещения перехода и оно используется в качестве аргумента для инструкции jump байт-кода. Объекта кода генерируется из этого набора инструкций. Чтобы лучше разобраться в этом процессе, рассмотрим функцию fizzbuzz в листинге 3.11.
1 def fizzbuzz(n): 2 if n % 3 == 0 and n % 5 == 0: 3 return 'FizzBuzz' 4 elif n % 3 == 0: 5 return 'Fizz' 6 elif n % 5 == 0: 7 return 'Buzz' 8 else: 9 return str(n)
Листинг 3.11. Простая python функция
AST для этой функции показан на рисунке 3.2.
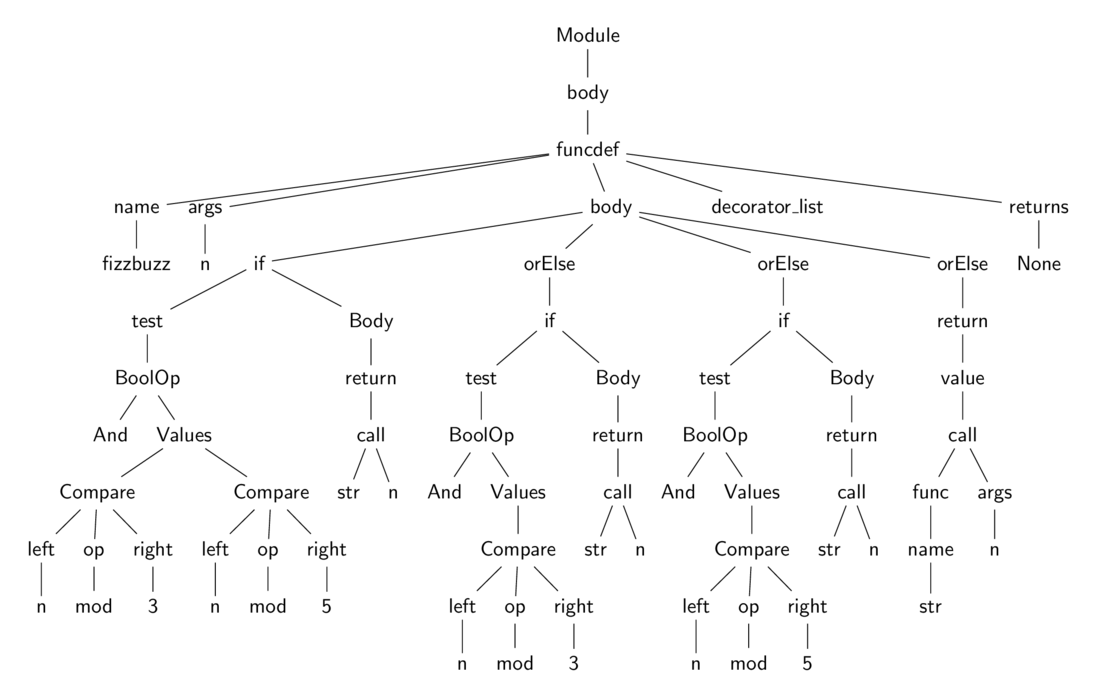
Рисунок 3.2: Очень простой AST для листинга 3.2
Этот AST из рисунка 3.2 при компиляции в CFG возвращает граф, аналогичный показанному на рисунке 3.3. Пустые блоки на рисунке были опущены. Рассмотрение этого графа обеспечит некоторую информацию о том, что скрывается за базовыми блоками. Базовые блоки имеют одну точку входа, но могут иметь несколько выходов. Эти блоки описаны более подробно далее.

Рисунок 3.3: Граф потока управления для функции fizzbuzz из листинга 3.11. Прямая линия представляет нормальное, прямолинейное выполнение кода, в то время как изогнутые линии представляют «прыжки».
В следующие описания включены только фактические инструкции. Для некоторых инструкций нужны аргументы, но он были удалены, поскольку сейчас нас не интересуют.
- Блок 1 содержит инструкции, являющиеся узлом BoolOp в AST на рисунке 3.2. Инструкции в этом блоке реализуют операцию: n%3==0 and n%5==0, используя следующий набор из одиннадцати команд:
LOAD_FAST LOAD_CONST BINARY_MODULO LOAD_CONST COMPARE_OP JUMP_IF_FALSE_OR_POP LOAD_FAST LOAD_CONST BINARY_MODULO LOAD_CONST COMPARE_OP
Удивительно, но остальная часть узла if (фактический тест, который определяет, нужно ли выполнить код ниже) не включен в этот блок. Причина станет более понятной, когда мы обсудим второй блок. Как показано на рисунке 3.3, есть два способа выйти из этого блока: либо через прямое выполнение всех опкодов, либо путем перехода к блоку 2 через инструкцию JUMP_IF_FALSE_OR_POP. - Блок 2 отображается на первый узел if, инкапсулирует тест if и последующий код. Второй блок содержит следующие четыре инструкции:
POP_JUMP_IF_FALSE LOAD_CONST RETURN_VALUE JUMP_FORWARD
Как мы увидим в следующих главах, когда интерпретатор выполняет инструкции байт-кода для оператора if, он производит считывание из стека значения и в зависимости от истинности данного объекта либо выполняет следующую инструкцию байт-кода, либо переходит к другой части набора инструкций и продолжает выполнение оттуда. Именно инструкция POP_JUMP_IF_FALSE отвечает за это. Данный опкод принимает аргумент, который указывает место назначения такого перехода. Можно задаться вопросом: почему инструкции для узла BoolOp и операторов if находятся в разных блоках? Чтобы понять это напомним, что python использует ленивые вычисления для логических операций. Таким образом, если значение n%3==0 равно false, то n%5==0 даже не будет вычислено. Посмотрев на инструкции из первого блока можно заметить инструкцию JUMP_IF_FALSE_OR_POP сразу после первого сравнения. Она как раз и является вариантом jump, а следовательно, нуждается «в цели». Задумайтесь об этом на секунду и потребность в разных блоках станет очевидной. JUMP_IF_FALSE_OR_POP нуждается в «цели», чтобы продолжить выполнение инструкций, когда первое логический выражение принимает значение «ложь» и из-за ленивых вычислений идёт переход к инструкции POP_JUMP_IF_FALSE в самом блоке if. Для того чтобы «прыжок» был возможен, мы оставляем инструкции тела if в другом блоке. Если все компоненты логического выражения оценены, то после выполнения инструкций в блоке BoolOp, вычисления продолжатся как обычно, по инструкциям в блоке if.
- Блок 3 соответствует первому узлу orElse в AST и содержит следующие 9 инструкций:
LOAD_FAST LOAD_CONST BINARY_MODULO LOAD_CONST COMPARE_OP POP_JUMP_IF_FALSE LOAD_CONST return_value JUMP_FORWARD
Заметьте, что здесь оператор elif, условие n%3==0, а также тело оператора находятся в одном блоке. Теперь легко понять, почему это так. Единственный вход в этот блок — через «прыжок» из первого if, а выход может быть выполнен либо с помощью инструкции возврата, либо также с помощью прыжка, если тест единственного условия в if не пройден. - Блок 4 является зеркальным по отношению к блоку 3 с точки зрения инструкций, но аргументы к инструкциям отличаются.
- Блок 5 является отображением конечного узла orElse и содержит следующие 4 инструкции:
LOAD_GLOBAL LOAD_FAST call_function return_value
Функция LOAD_GLOBAL принимает классическую функцию str в качестве аргумента и загружает ее в стек значений. LOAD_FAST загружает аргумент n в стек, а return_value возвращает значение, полученное через CALL_FUNCTION т.е. через инструкцию str(n).
Как и в предыдущем разделе, мы рассмотрим структуры данных, которые используются при построении базовых блоков, чтобы лучше понять данный процесс.
Структура данных: compiler
На рисунке 3.4 показана взаимосвязь между основными структурами данных, используемыми в процессе генерации базовых блоков, которые составляют граф потока управления.

Рисунок 3.4: Четыре основные структуры данных, используемые при создании объекта кода.
На самом верхнем уровне находится структура данных compiler, которая отвечает за глобальный процесс компиляции модуля. Эта структура данных определена в листинге 3.12.
1 struct compiler { 2 PyObject *c_filename; 3 struct symtable *c_st; 4 PyFutureFeatures *c_future; /* pointer to module's __future__ */ 5 PyCompilerFlags *c_flags; 6 7 int c_optimize; /* optimization level */ 8 int c_interactive; /* true if in interactive mode */ 9 int c_nestlevel; 10 11 struct compiler_unit *u; /* compiler state for current block */ 12 PyObject *c_stack; /* Python list holding compiler_unit 13 ptrs */ 14 PyArena *c_arena; /* pointer to memory allocation arena */ 15 };
Листинг 3.12. Структура данных compiler
Поля, которые представляют для нас здесь интерес, следующие:
- *c_st — ссылка на таблицу символов, созданную в предыдущем разделе.
- *u — ссылка на структуру данных compiler unit. Эта инкапсулированная информация необходима для работы с блоком кода. Данное поле указывает на compiler unit выполняемого сейчас блока кода.
- *c_stack — ссылка на стек структур данных compiler_unit. Когда блок кода является составным, это поле управляет сохранением и восстановлением структур данных compile_unit при обнаружении новых блоков. Когда происходит вхождение в новый блок кода, создаётся новая область видимости, а затем compiler_enter_scope() делает «push» текущего compiler_unit (*u) в стек *c_stack, а затем создает новый объект compiler_unit и устанавливает его в качестве текущего. Когда происходит выход из блока, совершается операция «pop» из стека *c_stack, тем самым идёт восстановление предыдущего состояния.
Структура compiler инициализируется для каждого компилируемого модуля. В точности, как AST генерируется для каждого используемого модуля, также и структура compiler_unit создаётся для каждого блока кода в AST.
Структура данных: compiler_unit
Структура данных compiler_unit, показанная ниже в листинге 3.13, собирает информацию необходимую для генерации требуемых инструкций байт-кода в блоках кода. Большинство полей, определенных в compiler_unit, встретится нам при изучении объектов кода.
1 struct compiler_unit { 2 PySTEntryObject *u_ste; 3 4 PyObject *u_name; 5 PyObject *u_qualname; /* dot-separated qualified name (lazy) */ 6 int u_scope_type; 7 8 /* The following fields are dicts that map objects to 9 the index of them in co_XXX. The index is used as 10 the argument for opcodes that refer to those collections. 11 */ 12 PyObject *u_consts; /* all constants */ 13 PyObject *u_names; /* all names */ 14 PyObject *u_varnames; /* local variables */ 15 PyObject *u_cellvars; /* cell variables */ 16 PyObject *u_freevars; /* free variables */ 17 18 PyObject *u_private; /* for private name mangling */ 19 20 Py_ssize_t u_argcount; /* number of arguments for block */ 21 Py_ssize_t u_kwonlyargcount; /* number of keyword only arguments 22 for block */ 23 /* Pointer to the most recently allocated block. By following b_list 24 members, you can reach all early allocated blocks. */ 25 basicblock *u_blocks; 26 basicblock *u_curblock; /* pointer to current block */ 27 28 int u_nfblocks; 29 struct fblockinfo u_fblock[CO_MAXBLOCKS]; 30 31 int u_firstlineno; /* the first lineno of the block */ 32 int u_lineno; /* the lineno for the current stmt */ 33 int u_col_offset; /* the offset of the current stmt */ 34 int u_lineno_set; /* boolean to indicate whether instr 35 has been generated with current lineno */ 36 };
Листинг 3.13. Структура данных compiler_unit
Поля u_blocks и u_curblock ссылаются на базовые блоки, которые вместе составляют компилируемый блок кода. Поле *u_ste является ссылкой на запись таблицы символов для компилируемого блока кода. Остальные поля имеют довольно понятные имена, которые говорят сами за себя. Во время компиляции происходит обход различных узлов, составляющих блок кода. В зависимости от того, начинает ли данный тип узла новый базовый блок или нет, создается базовый блок (содержащий инструкции этих узлов), или же инструкции для узла добавляются в существующий базовый блок. Вот самые частые типы узлов, которые могут начинать новый базовый блок:
- Функциональные узлы.
- Узлы, где нужно совершить «прыжок».
- Обработчики исключений.
- Булевы операции и т.п.
Структуры данных basic_block и instruction
Структура данных базового блока довольно интересна в рамках процесса генерации графа потока управления. Базовый блок — это последовательность инструкций, которая имеет одну точку входа, но несколько точек выхода. Определение структуры данных basic_block, используемой в виртуальной машине python, приведено в листинге 3.14.
1 typedef struct basicblock_ { 2 /* Each basicblock in a compilation unit is linked via b_list in the 3 reverse order that the block are allocated. b_list points to the next 4 block, not to be confused with b_next, which is next by control flow. */ 5 struct basicblock_ *b_list; 6 /* number of instructions used */ 7 int b_iused; 8 /* length of instruction array (b_instr) */ 9 int b_ialloc; 10 /* pointer to an array of instructions, initially NULL */ 11 struct instr *b_instr; 12 /* If b_next is non-NULL, it is a pointer to the next 13 block reached by normal control flow. */ 14 struct basicblock_ *b_next; 15 /* b_seen is used to perform a DFS of basicblocks. */ 16 unsigned b_seen : 1; 17 /* b_return is true if a RETURN_VALUE opcode is inserted. */ 18 unsigned b_return : 1; 19 /* depth of stack upon entry of block, computed by stackdepth() */ 20 int b_startdepth; 21 /* instruction offset for block, computed by assemble_jump_offsets() */ 22 int b_offset; 23 } basicblock;
Листинг 3.14. Структура данных basicblock_
Как упоминалось ранее, CFG в основном состоит из базовых блоков и соединительных «путей» между ними. Поле *b_instr ссылается на массив структур данных instruction и каждая из этих структур данных содержит байт-код инструкцию. Эти байт-коды можно найти в заголовочном файле Include/opcode.h. Структура данных instruction показана в листинге 3.15.
1 struct instr { 2 unsigned i_jabs : 1; 3 unsigned i_jrel : 1; 4 unsigned char i_opcode; 5 int i_oparg; 6 struct basicblock_ *i_target; /* target block (if jump instruction) */ 7 int i_lineno; 8 };
Листинг 3.15. Структура данных instruction
Ещё раз взгляните на CFG для функции fizzbuzz. Мы видим, что на самом деле есть два пути способа перейти от выполнения блока 1 к блоку 2. Первый — через нормальное выполнение, когда все инструкции в блоке 1 выполняются и поэтому поток выполнения автоматически продолжается в блоке 2. Второй способ — инструкция перехода, мы видели такую сразу после первой операции сравнения. «Целью» такой инструкции перехода является другой базовый блок, но на самом деле виртуальная машина выполняет объекты кода, которые ничего не знают о базовых блоках. Блок кода содержит только поток байт-кодов, который индексируется с помощью смещения. Получается, мы должны взять блоки с «целями» прыжка и заменить их на смещения в массиве инструкций. Это то, что делает процесс сборки базовых блоков.
Сборка базовых блоков
После того как CFG сгенерирован, базовые блоки содержат инструкции байт-кода, являющиеся репрезентацией AST. Но блоки не упорядочены линейно, а инструкции перехода все ещё содержат базовые блоки в качестве целей перехода, вместо относительного или абсолютного смещения в потоке команд. Функция assemble обрабатывает линеаризацию CFG и создание объекта кода из CFG.
Во-первых, функция сборки базовых блоков добавляет инструкции return None в любой блок, который заканчивается без оператора RETURN. Теперь вы знаете, почему вы можете определять методы без добавления RETURN. Затем следует предварительный post-order обход графа CFG (дочерние элементы посещаются перед их корневым узлом), чтобы «сгладить» блоки.
Обход графа
При post-order depth-first обходе графа мы рекурсивно посещаем левый дочерний узел графа, за которым следует правый дочерний узел графа, а затем сам узел. В нашем графе на рисунке 3.5, когда график сглажен с использованием этого подхода, порядок узлов равен H -> D -> I -> J -> E -> B -> K -> L -> F -> G -> C -> A. При использовании pre-order обхода, мы получили бы A -> B -> D -> H -> E -> I -> J -> C -> F -> K -> L -> G. Также существует способ обхода in-order, где мы получили бы: H -> D -> B -> I -> E -> J -> A -> K -> L -> F -> C -> G
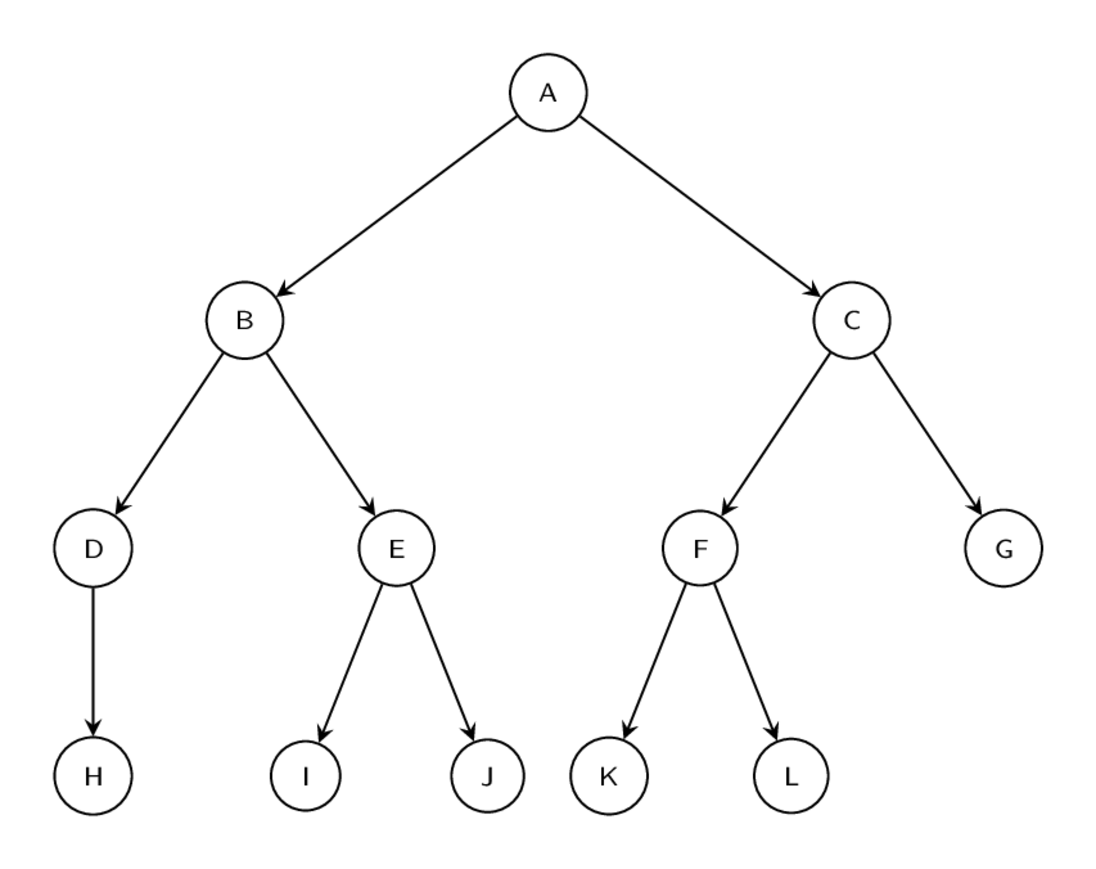
CFG для функции fizzbuzz, приведённый в листинге 3.3, довольно простой граф, поэтому результат при post-order обходе будет таковым: block 5 -> block 4 -> block 3 -> block 2 -> block 1. Как только граф линеаризирован (т.е. сглажен), смещения для «прыжков» можно рассчитать, вызвав функцию assemble_jump_offsets, передав ей полученный граф.
Расчёт смещения прыжка происходит в два этапа. На первом этапе смещение каждой инструкции в массиве инструкций рассчитывается, как показано во фрагменте из листинга 3.16. Это простой цикл, который работает с конца сглаженного массива, создавая смещение от 0.
1 ... 2 totsize = 0; 3 for (i = a->a_nblocks - 1; i >= 0; i--) { 4 b = a->a_postorder[i]; 5 bsize = blocksize(b); 6 b->b_offset = totsize; 7 totsize += bsize; 8 } 9 ...
Листинг 3.16. Расчет смещения байт-кода
На втором этапе, цели прыжка для команд перехода рассчитываются, как показано в листинге 3.17. Происходит вычисление относительных смещений при переходах и замена ими абсолютных значений.
1 ... 2 for (b = c->u->u_blocks; b != NULL; b = b->b_list) { 3 bsize = b->b_offset; 4 for (i = 0; i < b->b_iused; i++) { 5 struct instr *instr = &b->b_instr[i]; 6 int isize = instrsize(instr->i_oparg); 7 /* Relative jumps are computed relative to 8 the instruction pointer after fetching 9 the jump instruction. 10 */ 11 bsize += isize; 12 if (instr->i_jabs || instr->i_jrel) { 13 instr->i_oparg = instr->i_target->b_offset; 14 if (instr->i_jrel) { 15 instr->i_oparg -= bsize; 16 } 17 instr->i_oparg *= sizeof(_Py_CODEUNIT); 18 if (instrsize(instr->i_oparg) != isize) { 19 extended_arg_recompile = 1; 20 } 21 } 22 } 23 } 24 ...
Листинг 3.17. Сборка смещений перехода
Вычисленные смещения «прыжка» добавляются в сглаженный граф в порядке, обратном порядке обхода при линеаризации. Обратный post-order является топологической сортировкой CFG. Это означает, что для каждого ребра от вершины u до вершины v, u идет перед v в отсортированном порядке. Причина этого очевидна: мы хотим, чтобы узел, который перепрыгивает на другой, всегда был раньше «цели перехода». После завершения передачи байт-кода, объекты кода могут быть собраны для каждого блока кода, используя полученный байт-код и информацию из таблицы символов. Сгенерированный объект кода возвращается в вызывающую функцию, тем самым отмечая конец процесса компиляции.

