Привет, Хабр! В этой статье я бы хотел рассказать как я сделал распознавалку русских букв и прикрутил к этому небольшой графический интерфейс.
Спойлер: в результате должно получиться вот так:

Скачиваем датасет
Итак, начнём! Первое, что нам нужно это набор данных. В качестве датасета я выбрал CoMNIST. Скачиваем набор данных, распаковываем и удаляем папку с названием I, так как эта буква не входит в русский алфавит.
Обработка данных
Как мы можем увидеть, данные изображения имеют четыре канала. Четвёртый канал — альфа-канал, который нам не нужен и мы его удаляем:
def make_background():
image=' '
file_without_extension = image.split('.')[0]
image = cv2.imread(image, cv2.IMREAD_UNCHANGED)
trans_mask = image[:, :, 3] == 0
image[trans_mask] = [255, 255, 255, 255]
new_img = cv2.cvtColor(image, cv2.COLOR_BGRA2BGR)
cv2.imwrite(file_without_extension + '.jpeg', new_img)То есть на входе у нас было изображение, которое представлено слева, а на выходе должно получиться изображение, которое представлено справа:

Cледующее, что мы можем заметить, это то, что количество данных у нас маловато( 350 — 450 изображений на класс). Поэтому, нам нужно «раздуть» наши данные. Для этих целей я использовал следующие приёмы: сдвиги, это когда мы перемещаем нашу букву на какое-то значение вверх/вниз и влево/вправо по осям, и повороты, когда поворачиваем нашу букву на какой-то определённый градус.
Сдвиги
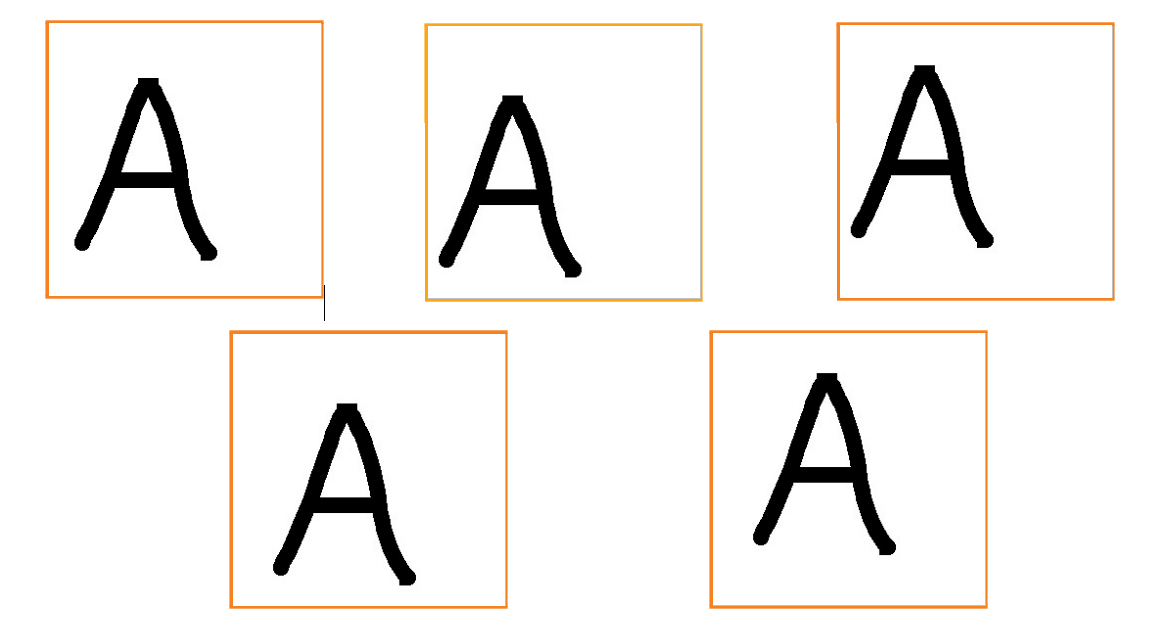
def shift():
image = ''
img = cv2.imread(image)
file_without_extension = image.split('.')[0]
arr_translation = [[15, -15], [-15, 15], [-15, -15],
[15, 15]]
arr_caption=['15-15','-1515','-15-15','1515']
for i in range(4):
transform = AffineTransform(
translation=tuple(arr_translation[i]))
warp_image = warp(img, transform, mode="wrap")
img_convert = cv2.convertScaleAbs(warp_image,
alpha=(255.0))
cv2.imwrite(file_without_extension +
arr_caption[i] + '.jpeg', img_convert)Повороты

def rotate():
image = ''
img = Image.open(image)
file_without_extension = image.split('.')[0]
angles = np.ndarray((2,),
buffer=np.array([-13, 13]), dtype=int)
for angle in angles:
transformed_image = transform.rotate(np.array(img),
angle, cval=255, preserve_range=True).astype(np.uint8)
cv2.imwrite(file_without_extension +
str(angle) + '.jpeg', transformed_image)Балансировка данных
Далее мы можем увидеть, что количество изображений, принадлежащих к каждому классу, разное, поэтому нам следует сбалансировать наш датасет.
def balancing():
arr_len_files = []
for path in root_path:
name_path = name_root_path+path+'/'
files=os.listdir(name_path)
arr_len_files.append(len(files))
min_value=min(arr_len_files)
for path in root_path:
folder = name_root_path+path
arr = []
for the_file in os.listdir(folder):
arr.append(folder + '/' + the_file)
d = 0
k = len(arr)
for i in arr:
os.remove(i)
d += 1
if d == k - min_value:
breakВ результате чего, для каждой буквы количество изображений должно быть одинаково. Далее следует самостоятельно разделить данные на тренировочные, тестовые и валидационные примерно в соотношении 70%, 20% и 10% соответственно.
Обучение нейронной сети
Переходим к самому продолжительному этапу — обучению сети. В качестве нейронной сети я выбрал CNN, так как она хороша для классификации объектов. Сам процесс обучения занимает 2-2,5 часа и точность составила примерно 94%, что довольно хорошо. Ниже представлен код для обучения сети.
import tensorflow as tf
ImageDataGenerator = tf.keras.preprocessing.image.ImageDataGenerator
TRAINING_DIR = "path/to/train/dataset"
train_datagen = ImageDataGenerator(rescale=1.0 / 255.)
train_generator = train_datagen.flow_from_directory(TRAINING_DIR,
batch_size=40,
class_mode='binary',
target_size=(278,278))
VALIDATION_DIR = "path/to/test/dataset"
validation_datagen = ImageDataGenerator(rescale=1.0 / 255.)
validation_generator = validation_datagen.flow_from_directory(VALIDATION_DIR,
batch_size=40,
class_mode='binary',
target_size=(278,278))
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(16, (3, 3), activation='relu',
input_shape=(278,278, 3)),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(32, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(64, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(33, activation='softmax')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy', metrics=['accuracy'])
model.summary()
history = model.fit_generator(train_generator,
epochs=2,
verbose=1,
validation_data=validation_generator)
model.save('model.h5')Дальше следует проверить нашу нейронную сеть на валидационных изображениях, для того, чтобы убедиться, что точность на тестовых данных соответствует реальности:
def print_letter(result):
letters = "ЁАБВГДЕЖЗИЙКЛМНОПРСТУФХЦЧШЩЪЫЬЭЮЯ"
return letters[result]
def predicting(path_to_image):
image = keras.preprocessing.image
model = keras.models.load_model('path/to/model')
img = image.load_img(path_to_image, target_size=(278, 278))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
images = np.vstack([x])
classes = model.predict(images, batch_size=1)
result = int(np.argmax(classes))
result = print_letter(result)
print(result)Прикручиваем GUI
И последнее, что нам предстоит сделать это прикрутить графический интерфейс с минимальными возможностями: холст, на котором можно будет рисовать цифры, поле, куда будет выводиться распознанная буква, кнопка для распознавания того, что находится на холсте, кнопка для очистки холста и объеденить это всё воедино.
from PyQt5.QtWidgets import QMainWindow, QApplication, QMenu, QMenuBar, QAction, QFileDialog, QPushButton, QTextBrowser
from PyQt5.QtGui import QIcon, QImage, QPainter, QPen, QBrush
from PyQt5.QtCore import Qt, QPoint
import sys
from PyQt5.QtWidgets import QMainWindow, QTextEdit, QAction, QApplication
from PyQt5.QtWidgets import (QWidget, QLabel, QLineEdit, QTextEdit, QGridLayout, QApplication)
import numpy as np
from tensorflow import keras
class Window(QMainWindow):
def __init__(self):
super().__init__()
title = "recognition cyrillic letter"
top = 200
left = 200
width = 540
height = 340
self.drawing = False
self.brushSize = 8
self.brushColor = Qt.black
self.lastPoint = QPoint()
self.image = QImage(278, 278, QImage.Format_RGB32)
self.image.fill(Qt.white)
self.nameLabel = QLabel(self)
self.nameLabel.setText('RES:')
self.line = QLineEdit(self)
self.line.move(360, 168)
self.line.resize(99, 42)
self.nameLabel.move(290, 170)
prediction_button = QPushButton('RECOGNITION', self)
prediction_button.move(290, 30)
prediction_button.resize(230, 33)
prediction_button.clicked.connect(self.save)
prediction_button.clicked.connect(self.predicting)
clean_button = QPushButton('CLEAN', self)
clean_button.move(290, 100)
clean_button.resize(230, 33)
clean_button.clicked.connect(self.clear)
self.setWindowTitle(title)
self.setGeometry(top, left, width, height)
def print_letter(self,result):
letters = "ЁАБВГДЕЖЗИЙКЛМНОПРСТУФХЦЧШЩЪЫЬЭЮЯ"
self.line.setText(letters[result])
return letters[result]
def predicting(self):
image = keras.preprocessing.image
model = keras.models.load_model('model/cyrillic_model.h5')
img = image.load_img('res.jpeg', target_size=(278, 278))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
images = np.vstack([x])
classes = model.predict(images, batch_size=1)
result = int(np.argmax(classes))
self.print_letter(result)
def mousePressEvent(self, event):
if event.button() == Qt.LeftButton:
self.drawing = True
self.lastPoint = event.pos()
def mouseMoveEvent(self, event):
if (event.buttons() & Qt.LeftButton) & self.drawing:
painter = QPainter(self.image)
painter.setPen(QPen(self.brushColor, self.brushSize, Qt.SolidLine, Qt.RoundCap, Qt.RoundJoin))
painter.drawLine(self.lastPoint, event.pos())
self.lastPoint = event.pos()
self.update()
def mouseReleaseEvent(self, event):
if event.button() == Qt.LeftButton:
self.drawing = False
def paintEvent(self, event):
canvasPainter = QPainter(self)
canvasPainter.drawImage(0, 0, self.image)
def save(self):
self.image.save('res.jpeg')
def clear(self):
self.image.fill(Qt.white)
self.update()
if __name__ == "__main__":
app = QApplication(sys.argv)
window = Window()
window.show()
app.exec()
Заключение
Как можно видеть, что казалось когда-то «магией», с помощью современных библиотек делается вполне несложно.
Поскольку Python является кроссплатформенным, работать код должен везде, на Windows, Linux и OSX. Я это всё делал на Ubuntu 18.04. Для желающих поэкспериментировать самостоятельно, исходный код я выложил на GitHub.
