ClickHouse — высокопроизводительная аналитическая база данных с открытыми исходниками, разработанная в Яндексе. Изначально ClickHouse создавался для задач Яндекс.Метрики, но постепенно нашёл множество применений как внутри Яндекса, так и в других компаниях. Я расскажу, как ClickHouse устроен внутри с акцентом на то, какие у выбранной архитектуры следствия с точки зрения прикладного разработчика.
Будут затронуты следующие темы:
- Как ClickHouse хранит данные на диске и выполняет запрос, почему такой способ хранения позволяет на несколько порядков ускорить аналитические запросы, но плохо подходит для OLTP и key-value нагрузки.
- Как устроена репликация и шардирование, как добиться линейного масштабирования и что делать с eventual consistency.
- Как диагностировать проблемы на production-кластере ClickHouse.

Видео:
Идея доклада довольно проста: что если каким-то инструментом пользуешься или собираешься пользоваться, то желательно хотя бы в общих чертах представлять, что там внутри происходит, чтобы каких-то неправильных решений избежать и принять правильное решение. Вот такое понимание про ClickHouse постараюсь сегодня донести.

Я ClickHouse занимаюсь недавно. До этого я несколько лет работал в Яндекс.Картах. Был прикладным разработчиком. Много там работал с базами данных, с Postgres, поэтому я еще вирусом ClickHouse не сильно заражен, я еще помню, что такое быть прикладным разработчиком. Но, в принципе, уже все довольно хорошо понимаю.

Начнем сразу с задач. ClickHouse – это база специального назначения, везде ее пихать не надо, но спектр применения достаточно широкий. Он выражается вот такой формулой.
У нас есть некие события. Они постоянно приходят. Я тут выписал какие-то примеры. Вот Яндекс.Метрика – это сервис, для которого ClickHouse изначально создавался.
- Это какие-то действия пользователя на сайте.
- Реклама.
- Финансовые транзакции, покупки в магазинах.
- И DNS-запросы.
Что мы хотим с этими событиями сделать? Мы хотим о них сохранить информацию и что-то о них понять потом, т. е. построить какие-то отчеты, аналитику, потом на них посмотреть и что-то понять.

Но любая система, которая эти задачи решает, имеет идеологию. Т. е. что важно было для создателей этой системы, чем они готовы были поступиться, чем они готовы были пожертвовать.
Для ClickHouse самое важное:
- Это интерактивные запросы. Что это такое? Это выполнение за секунды, а лучше меньше, чем за секунду. Почему это важно? Во-первых, когда Яндекс.Метрика показывает отчет, пользователь не будет ждать, если он загружается больше секунды. Но даже если вы, как аналитик, работаете с ClickHouse, с базой данной, то очень хорошо, если ответы на запросы тут же приходят. Вы тогда их можете много задать. Вы можете не отвлекаться. Вы можете погрузиться в работу с данными. Это другое качество работы.
- Язык запросов у нас SQL. Это тоже и плюсы, и минусы. Плюсы в том, что SQL декларативный и поэтому простой запрос можно очень хорошо оптимизировать, т. е. очень оптимально выполнить. Но SQL не очень гибкий. Т. е. произвольную трансформацию данных с помощью SQL не задать, поэтому там у нас куча каких-то расширений, очень много функций дополнительных. А преимущество в том, что SQL все аналитики знают, это очень популярный язык.
- Стараемся ничего заранее не агрегировать. Т. е. когда такую систему делаешь, то очень велик соблазн сначала подумать о том, какие отчеты нужны. Подумать, что у меня события будут поступать, я их буду потихоньку агрегировать и нужно будет показать отчет, я быстренько вот это все покажу. Но есть проблема такого подхода. Если вы два события слили вместе, то вы уже их ни в каком отчете больше не различите. Они у вас вместе. Поэтому чтобы сохранить гибкость, стараемся всегда хранить индивидуальные события и заранее ничего не агрегировать.
- Еще один важный пункт, который требуется от прикладного разработчика, который работает с ClickHouse. Нужно заранее понять, какие есть атрибуты события. Нужно их самому выделить, вычленить и уже эти атрибуты запихивать в ClickHouse, т. е. какие-то json в свободной форме или текстовые blob, которые вы просто берете и пихаете, и надеетесь потом распарсить. Так лучше не делать, иначе у вас интерактивных запросов не будет.

Возьмем пример достаточно простой. Представим, что мы делаем клон Яндекс.Метрики, систему веб-аналитики. У нас есть счетчик, который мы на сайт ставим. Он идентифицируется колонкой CounterID. У нас есть таблица hits, в которую мы складываем просмотры страниц. И есть еще колонка Referer, и еще что-то. Т. е. куча всего, там 100 атрибутов.
Очень простой запрос делаем. Берем и группируем по Referer, считаем count, сортируем по count. И первые 10 результатов показываем.

Запрос нужно выполнить быстро. Как это сделать?
Во-первых, нужно очень быстро прочитать:
- Самое простое, что тут надо сделать, это столбцовая организация. Т. е. храним данные по столбцам. Это нам позволит загрузить только нужные столбцы. В этом запросе это: ConterID, Date, Referrer. Как я уже сказал, их может быть 100. Естественно, если мы их все будем загружать, это все очень сильно нас затормозит.
- Поскольку данные у нас в память, наверное, не помещаются, нам нужно читать локально. Конечно, мы не хотим читать всю таблицу, поэтому нам нужен индекс. Но даже если мы читаем эту маленькую часть, которая нам нужна, нам нужно локальное чтение. Мы не можем по диску прыгать и искать данные, которые нам нужны для выполнения запроса.
- И обязательно нужно данные сжимать. Они в несколько раз сжимаются и пропускную способность диска очень сильно экономят.

И после того, как мы данные прочитали, нам нужно их очень быстро обработать. В ClickHouse много чего для этого делается:
- Самое главное, что он их обрабатывает блоками. Что такое блок? Блок – это небольшая часть таблицы, размером где-то в несколько тысяч строк. Почему это важно? Потому что ClickHouse – это интерпретатор. Все знают, что интерпретаторы – это очень медленно. Но если мы overhead размажем на несколько тысяч строк, то он будет незаметен. Зато это нам позволит применить SIMD инструкции. И для кэша процессора это очень хорошо, потому что если мы блок подняли в кэш, там его обрабатываем, то это будет гораздо быстрее, чем если он куда-то в память будет проваливаться.
- И очень много низкоуровневых оптимизаций. Я про это не буду говорить.

Так же, как и в обычных классических БД мы выбираем, смотрим, какие условия будут в большинстве запросов. В нашей системе веб-аналитике, скорее всего, это будет счетчик. Хозяин счетчика будет приходить и смотреть отчеты. А также дата, т. е. он будет смотреть отчеты за какой-то период времени. Или, может быть, он за все время существования захочет посмотреть, поэтому такой индекс – CounterID, Date.
Как мы можем проверить, что он подойдет? Сортируем таблицу по CounterID, Date и смотрим наши строки, которые нам нужны, они занимают вот такую небольшую область. Это значит, что индекс подойдет. Он будет сильно ускорять.
Но есть у ClickHouse индекса и особенности в отличие от привычных индексов. Во-первых, таблица будет упорядочена по ключу физически. В других системах еще называют кластер индекс. Это значит, что такой индекс на таблицу может быть только один. Второе, несмотря на то, что мы его называем первичный ключ, он не обеспечивает уникальности. Об этом нужно помнить.

Первое, что нужно понимать, то, что он разреженный, т. е. он не индексирует каждую строку в таблице, а он индексирует каждую десятитысячную строку. Физически он представляет собой значение выражения первичного ключа, которое записано для каждой 8 192 строки. По умолчанию такое значение мы предлагаем. Оно, в принципе, хорошо работает.
И когда у нас этот индекс есть, то при выполнении запроса, что мы делаем? Мы должны выбрать строки, которые нам могут пригодиться для выполнения запроса. В данном случае нам нужен счетчик 1234 и дата с 31 мая. А тут только есть запись на 23 мая. Это значит, что мы, начиная с этой даты, все должны прочитать. И до записи, счетчик которой начинается уже 1235. Получается, что мы будем читать немножко больше записей, чем нужно. И для аналитических задач, когда вам много нужно строк прочитать – это не страшно. Но если вам нужна какая-то одна строка, то работать все будет не так хорошо. Чтобы найти одну строку, вам придется 8 000 прочитать.
Столбцы, в которых лежат данные, упорядочены по тому же выражению первичного клича. И теперь из них нужно составить вот этот блок, который будет потом в ClickHouse обрабатываться. Для этого есть вот такие файлы, которые мы называем «файлы засечек», которые содержат указатели на значение, соответствующее строкам первичного ключа.
Как происходит чтение? Мы понимаем между какими значениями первичного ключа находятся интересующие нас строки по файлам засечек. В каждом столбце понимаем, что нам читать. Читаем. И дальше собираем блок. И дальше он пошел по конвейеру запроса.
Что тут важно? Key-Value сценарий будет плохо работать. У меня здесь светло-серым обозначено то, что мы прочитаем, и темно-серым то, что нам. И вполне может быть, что вам нужна будет одна строка, а вы прочитаете много.
И если у вас значения в столбце достаточно большие, например, 100 байт, а может, быть пара килобайт, то одна засечка, которую вы читаете, может занимать довольно много. Поэтому если у вас значения в столбцах большие, то, может быть, имеет смысл вот это значение чуть-чуть уменьшить.

Я сказал, что таблица упорядочена, но не рассказал, как это сделать. А нам очень хочется, чтобы данные, которые поступают в ClickHouse, тут же были доступны для отчетов. Т. е. после insert секунда прошла, и вы уже их видите в своих отчетах.
И тут есть проблема, потому что данные поступают примерно по времени, т. е. события за последние какие-то несколько минут. А нам нужно по первичному ключу, т. е. по счетчику. А события как раз поступают по счетчикам перемешано. И нужно как-то их упорядочивать.
Как это сделать? В ClickHouse прилагается вот такое решение. Движок таблицы MergeTree. Идея примерно такая же, как у LSM дерева. Т. е. у нас есть небольшое количество упорядоченных кусочков. Если их становится много, то мы берем несколько кусочков и из них делаем один. Таким образом поддерживаем каждый раз небольшое количество.

Вот примерно, как это происходит. У нас по Х – это номер вставки, т. е., грубо говоря, это время, которое вы вставляете. По У – первичный ключ. Поступили данные. Они обозначены зеленым цветом. Они не упорядоченные.
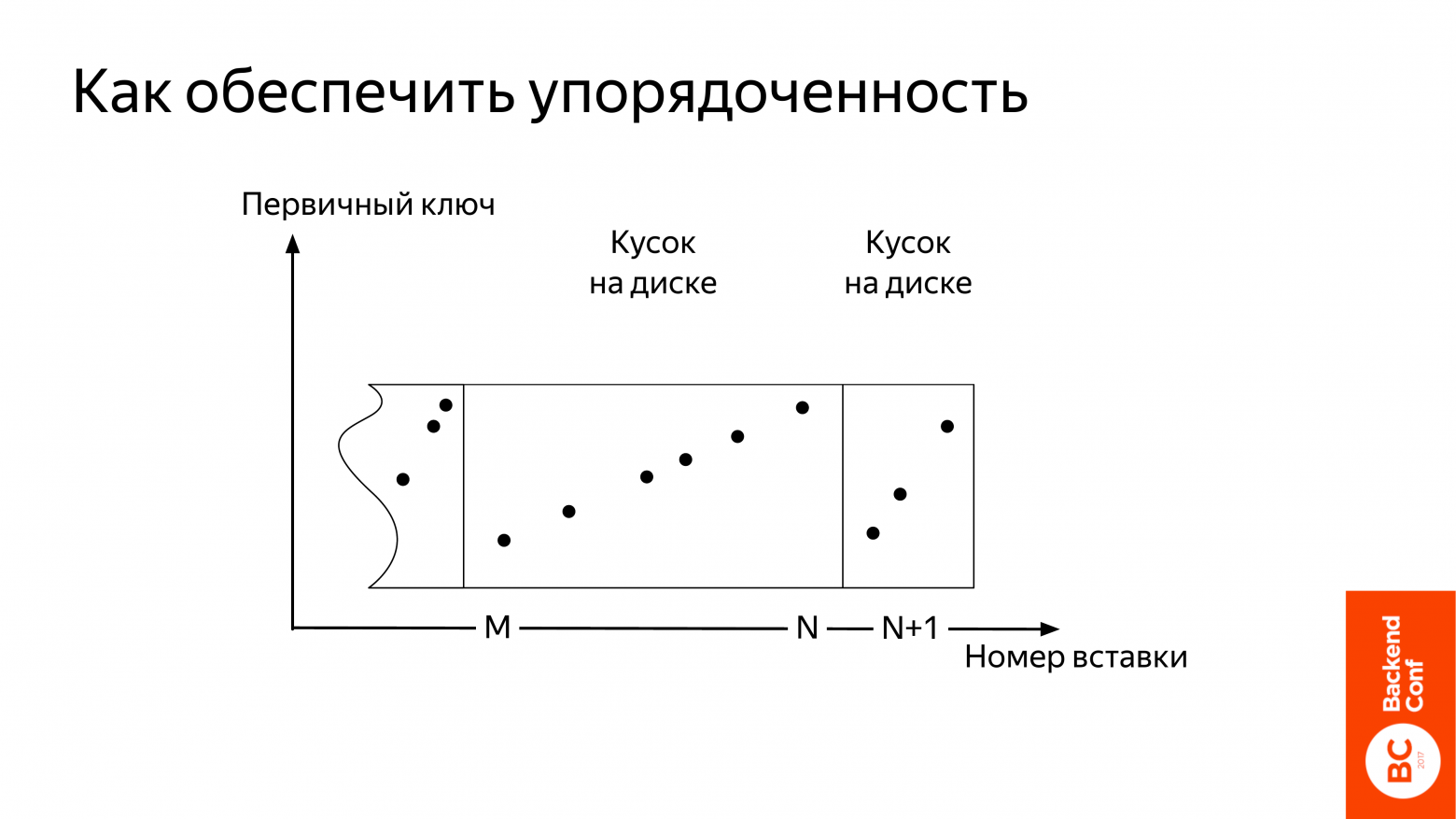
Что делает ClickHouse? Прежде всего он их сортирует и потом записывает на диск. Появляется новый кусок. Что тут важно? Данные из вашего insert сразу попадут на диск, т. е. буферизации какой-то не будет и поэтому индивидуальными записями будет очень плохо писать.
Есть средства, например, буфер-таблицы в ClickHouse, которые позволяют снизить эту проблему, но все равно нужно делать вставки большими кусками. Мы рекомендуем делать это раз в секунду и, как минимум, 1 000 записей, иначе очень много будет езды по диску, и все будет очень плохо работать.

У нас появился новый кусок. Появилось что-то еще потом. Нужно количество кусков уменьшить. Вот этот процесс происходит в фоне. Называется слияние или merge.
У ClickHouse есть одна особенность. Слияние происходит только с кусками, которые были вставлены подряд. В нашем случае был кусок, которые объединяет вставки от M до N. И маленький кусочек, который мы вставили на предыдущем слайде, который был вставлен под номером N+1.

Мы берем их и сливаем. И получаем новый кусок М до N+1. Он упорядоченный.
Что тут важно? Этот процесс происходит в фоне. И за ним обязательно нужно следить, потому что, если там что-то пойдет не так, например, он замедлится или вы начнете слишком часто вставлять, и он не будет справляться, то рано или поздно все сломается.
Как это будет выглядеть в случае с ClickHouse? Когда у вас будет на партицию (партиция – это месяц) 200 кусков, то у вас внезапно затормозятся вставки. Таким образом ClickHouse попробует дать возможность слияниям догнать вставки. А если уже будет 300 кусков, то он вам просто запретит вставлять, потому что иначе данные будет очень тяжело прочитать из множества кусков. Поэтому, если будете использовать ClickHouse, то обязательно это мониторьте. Настройте в ClickHouse экспорт метрик в Graphite. Это очень просто делается. И следите за количеством кусков в партиции. Если количество большое, то вам нужно обязательно разобраться с этим. Может быть, что-то с диском или вы начали очень сильно вставлять. И это нужно чинить.

Все хорошо. У нас есть сервер ClickHouse, все работает. Но иногда его может не хватать.
- Самое банальное, когда данные на один сервер не поместились. Но это не единственный случай.
- Например, хочется еще ускориться, добавив железа.
- Или кластер ClickHouse стал таким популярным, что очень много одновременных запросов, они начинают мешать друг другу. И нужно добавить еще железа.
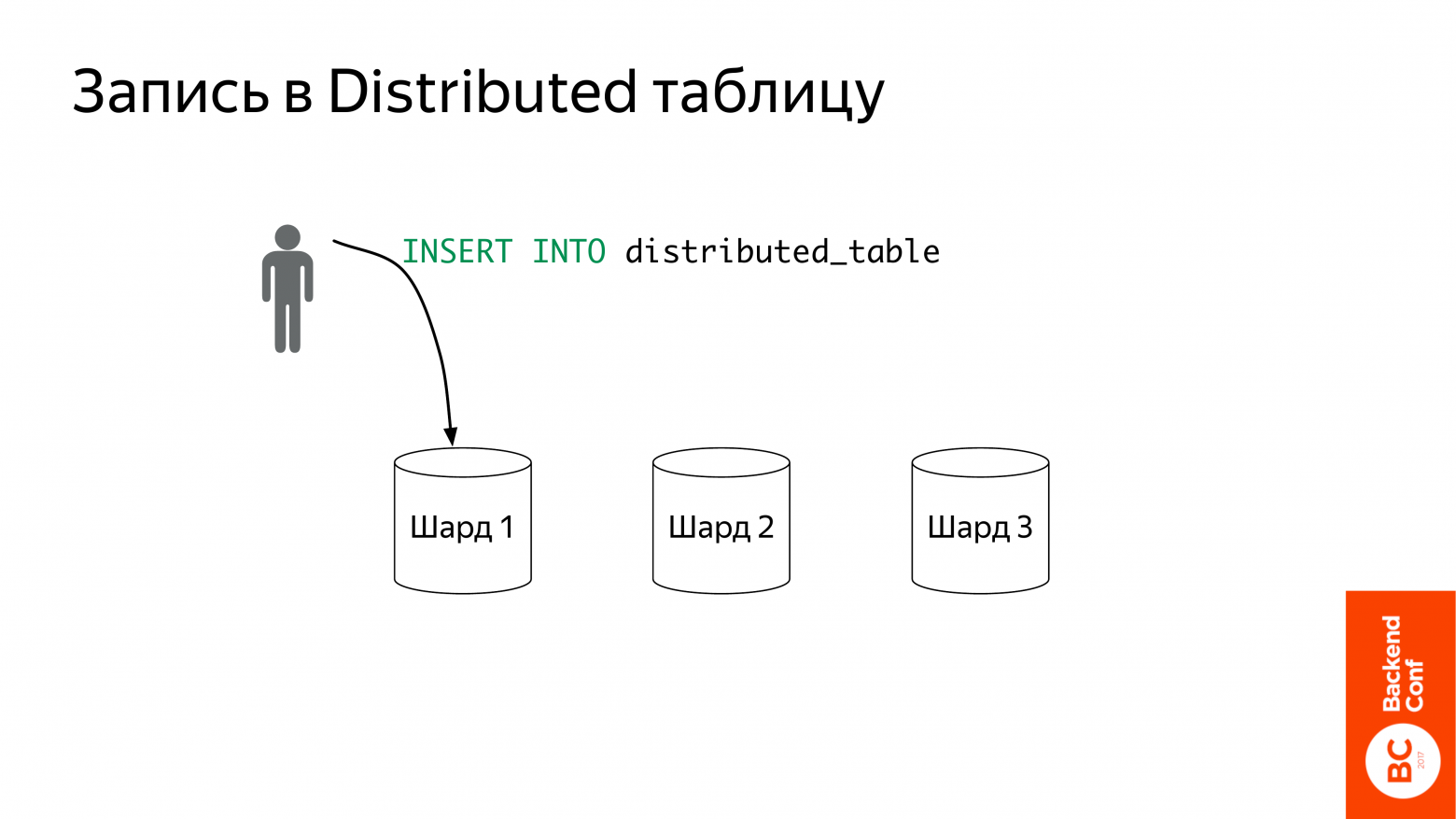
Что предлагает ClickHouse? Предлагает шардировать данные и использовать дистрибутивы таблицы.

Что это такое? Шардирование – это понятно. У вас есть какая-то таблица. И вы ставите несколько компьютеров, и на каждом компьютере часть этих данных. У меня на картинке они в таблице local_table.
Что такое distributed таблицы? Это такой view над локальными таблицами, т. е. сама она данные не хранит. Она выступает как прокси, который отправит запрос на локальные таблицы. Ее можно создавать где угодно, хоть на отдельном компьютере от этих шардов, но стандартный способ – это создание на каждом шарде. Вы тогда приходите в любой шард и создаете запрос.
Что она делает? Вот пошел запрос в select from distributed_table. Она возьмет его и перепишет distributed_table на local_table. И дальше отправит на все шарды сразу же.
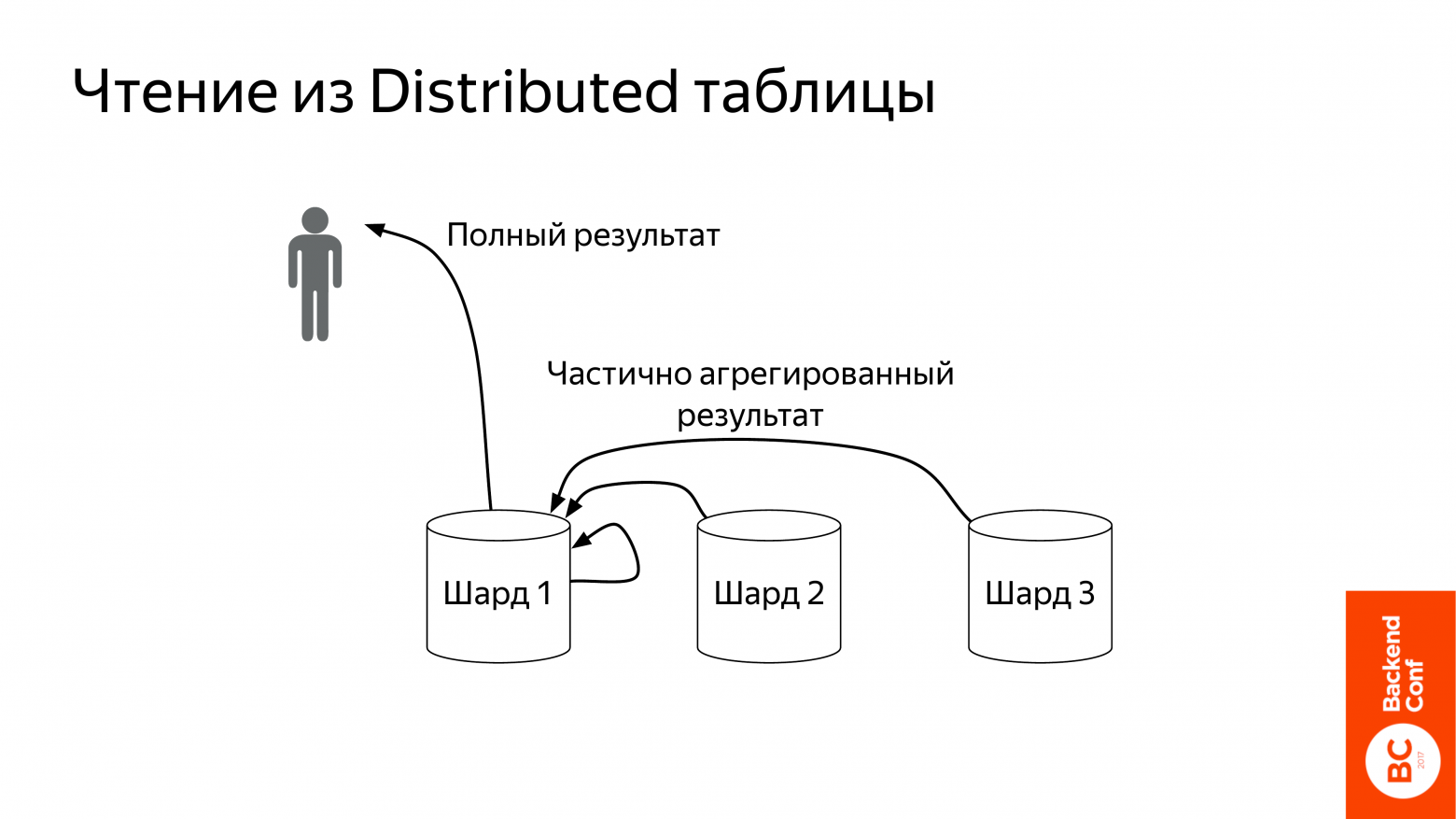
Шарды запрос обработают. Причем они его стараются обрабатывать до самого конца практически, чтобы поменьше данных по сети передавать. Т. е. если у нас есть какая-то агрегация, то эта агрегация будет частично проведена на шардах. Они отошлют частично агрегированный результат на distributed таблицы. Distributed эту таблицу сольет и отправит полный результат пользователю.

Вот такой забавный benchmark. Чуть больше миллиарда строк. Это данные о поездках нью-йоркского такси. Они в открытом доступе лежат. Можно самому попробовать.
Посчитаем любой запрос. Тут средняя цена в зависимости от количества пассажиров. Типичный аналитический запрос. На одном компьютере чуть больше секунды. Если мы три компьютера доставим, то в три раза быстрее будет. Если у вас есть 140 компьютеров, то можно эти данные разложить по 140 компьютерам и запрос будет вообще быстро выполняться, т. е. за несколько миллисекунд. Конечно, это уже не 140-кратное ускорение, потому что сетевые задержки уже там начинают играть роль, но все равно. Запрос можно ускорять до самого конца.
Как теперь раскладывать данные по шардам?
Самый простой вариант, который мы рекомендуем, это взять и вручную разложить по локальным таблицам, потому что distributed таблица, когда она делает запрос, она не задумывается о том, как данные пошардированы, она просто спрашивает у всех шардов одновременно. Главное, чтобы данные не были задублированы, иначе у вас какая-то ерунда начнется в результатах. А так вы можете, как вам удобно раскладывать все по шардам.
Но, в принципе, distributed таблица и сама умеет это делать, хотя есть несколько нюансов.
Во-первых, записи асинхронные, т. е. если вы вставили в distributed эту таблицу, она данные отложит куда-то во временную папочку.
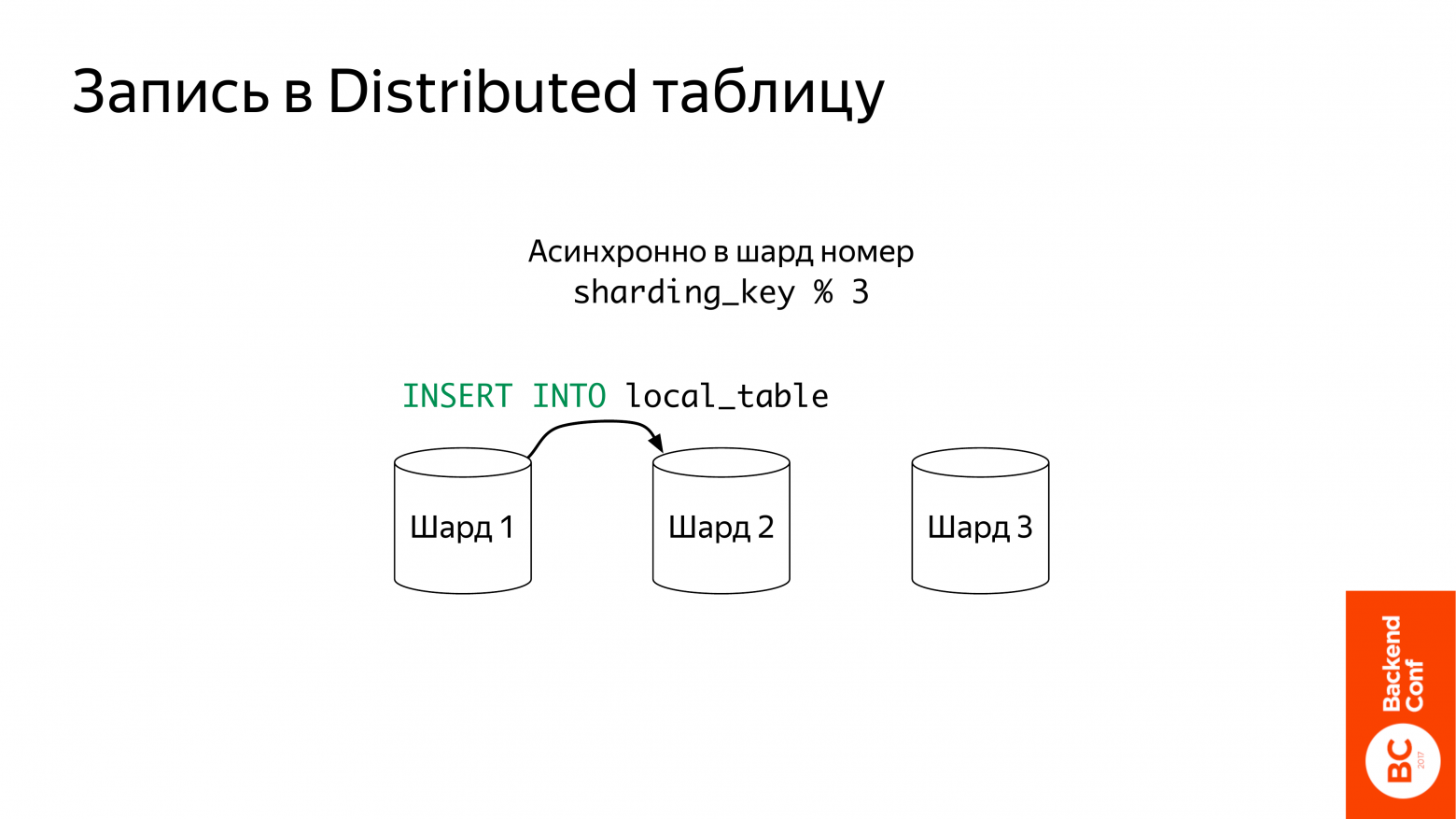
И дальше будет пытаться вставлять. Для этого ей нужен ключ шардирования. Она его посчитает, разделит на три. Там можно создавать веса. Далее выберет шард и вставит туда.
Что тут важно? Ключ шардирования можно даже рандом взять. Это тоже будет работать. Единственное, если вы хотите делать сложные joins и хотите, чтобы у вас данные, которые для joins нужны, были на одном шарде, тогда вам нужно уже задумываться о ключе шардирования.

Есть у нас кластер ClickHouse. Он большой, быстро работает, но иногда ломается. Иногда диски сбоят, а данные не хочется терять. И иногда там просто какие-то сетевые проблемы, а отчет нужно показывать. И данные о событиях, которые поступают постоянно, их тоже нельзя терять. Т. е. доступность должна быть и на чтение, и на запись.
ClickHouse предлагает для решения этой проблемы асинхронную мастер-мастер репликацию, которая работает на уровне таблиц — ReplicatedMergeTree. На сервере у вас могут быть и реплицированные таблицы, и не реплицированные.

Это полный хаос. У нас есть несколько реплик. И тут изображены те же самые куски, о которых я говорил в предыдущей части презентации. Т. е. тут понимание остается такое же. Это частично сортированные кусочки данных. И реплики стараются вот этот набор кусков у себя синхронизировать друг между другом.
При этом может происходить три типа событий:
- INSERT — вставка в реплику
- FETCH — одна реплика скачала кусок с другой
- MERGE — реплика взяла несколько кусков и слила их в один
Как происходит вставка? Вставляем на любую реплику. Тут видно, что Реплика 1 – не самая хорошая, но на нее все равно можно вставить. И информация о вставке записывается в ZooKeeper. Т. е. для того, чтобы у вас репликация работала, придется установить ZooKeeper.
При этом полный порядок на вставках все-таки поддерживается. У вас все реплики видят один и тот же набор кусков, и они видят в нем какие-то дырки, которых у них нет, и они пытаются их заполнить с помощью fetch.
Дальше нам нужно еще выполнять merge, т. е. сливать куски. Merge нужно выполнять согласовано, иначе наборы кусков разойдутся. Для этого одна реплика становится лидером. Не назовем мастером, потому что с мастером сразу идет ассоциация, что только туда можно вставлять, но это неправда. Т. е. у нас Реплика 2 – лидер. Она решила, что эти куски надо помержить, записала это в ZooKeeper, остальные реплики об этом информацию получат и тоже сделают такой же merge.
При этом реплики все время сравнивают друг с другом checksums. Если что-то не так, они выбросят кусок и заново скачают, т. е. пытаются поддержать набор данных байт-идентичным. Это место тоже нужно обязательно мониторить, т. е. мониторить, как у вас идет репликация, какое отставание, чтобы не дай бог не сломалось.

И любое обсуждение репликации упирается в CAP-теорему, т. е. у вас есть какое-то место, где вы можете читать и писать, и вы его реплицируете, то в случае сетевого сбоя вам нужно сделать выбор: либо вы продолжаете читать и писать, либо вам все-таки нужны свежие данные правильные.
Но консистентности данных в ClickHouse нет как и у любой системы с асинхронной репликацией. Вставляете данные в одну реплику, на второй реплике через пару секунд, может, появятся, а, может, через большее количество секунд. Есть зеленая звездочка – хорошие новости: можно включить, т. е. указать настройку при вставке, при чтении и тогда чтение будет консистентным. Но, конечно, вы за это заплатите производительностью.
Доступность почти есть. Как сделать неубиваемый кластер ClickHouse? Берете три дата-центра. ZK в 3-х дата-центрах, а реплики, как минимум, в 2-х. И если у вас локация взрывается, то все продолжает работать и на чтение, и на запись.
Часто спрашивают: «А как в двух дата-центрах сделать?». В двух не получится из-за ZooKeeper. Если у вас только две локации, то вы какой-то дата-центр объявляете главным. И если не главный отключается, то у вас все продолжает работать. Если главный отключаете, то у вас только на чтение.
Почему доступность почти? Почему красная звездочка? Строго говоря полной доступности нет, потому что нельзя записывать в сервер, если он у вас от quorum ZK, т. е. если это три ноды от двух нод отключены, тогда вы не сможете в него записать, но можете прочитать. Будут немножко отстающие данные.
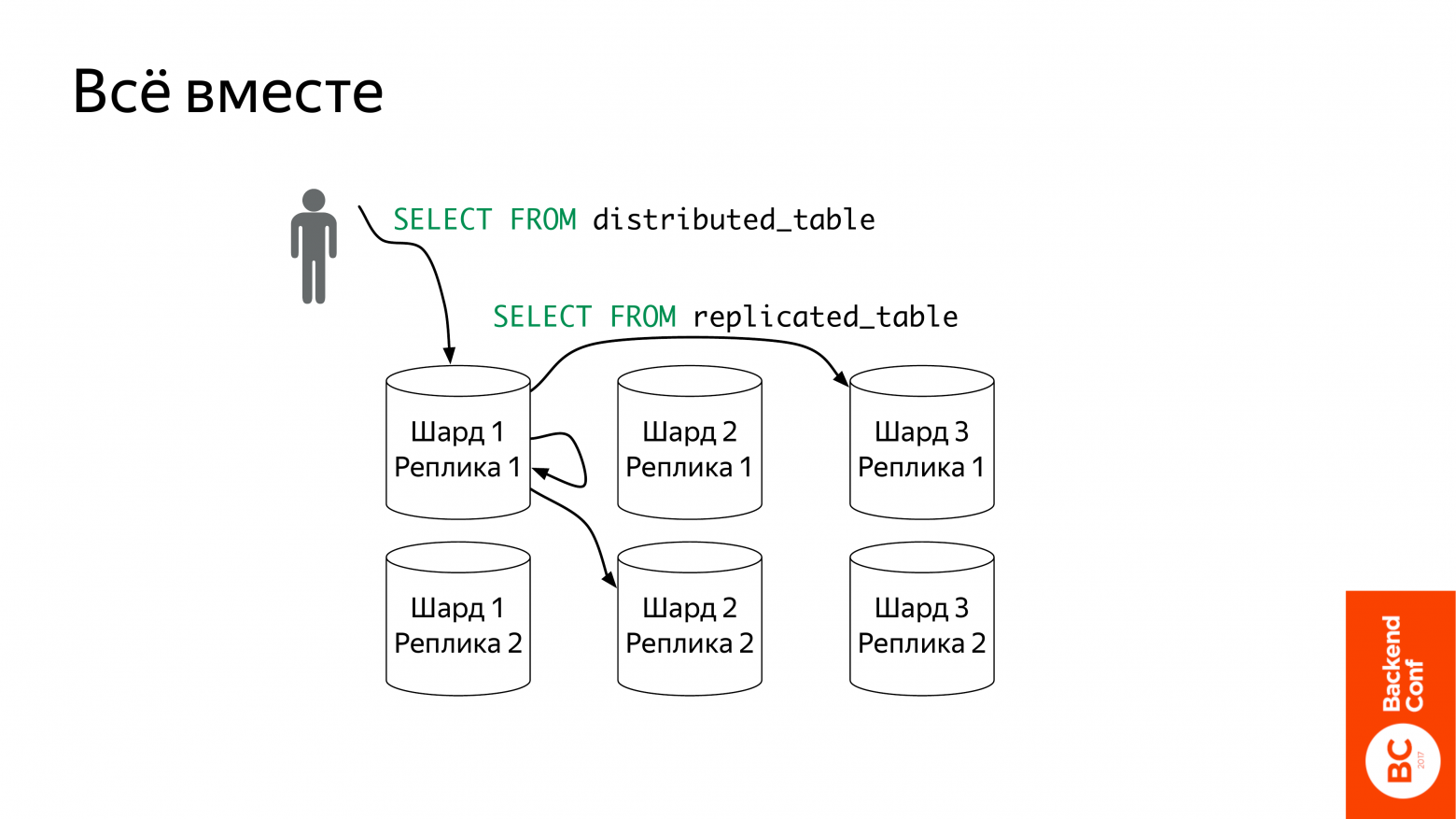
Вот эти две фичи: distributed_table, replicated_table независимы. Их можно независимо использовать. Но они очень хорошо работают вместе. Нормальный кластер ClickHouse мы его примерно так себе представляем. Т. е. у нас есть N шардов и каждый трехкратно реплицирован. И distributed таблица умеет понимает, что шарды – это реплики, могут отправлять запрос только в одну реплику шарда. И имеет отказоустойчивость, т. е. если у вас какая-то реплика недоступна, она в другую пойдет.
И еще один способ побороться с отсутствием consistency. Вы можете задать какое-то максимальное отставание. Если distributed таблица пришла на реплику, но отставание слишком большое, она другую попробует. Вот такой кластер будет хорошо работать.

Что такое ClickHouse?
- Это столбцовая column-oriented база данных, которая позволяет очень быстро выполнять аналитические и интерактивные запросы.
- Язык запросов – это SQL с расширениями.
- Плохо подходит для OLTP, потому что транзакций нет. Key-Value, потому что у нас разреженный индекс. Если вам нужна одна строчка, то вы много чего лишнего прочитаете. И если у вас Key-Value с большими blob, то это вообще будет плохо работать.
- Линейно масштабируется, если шардировать и использовать distributed таблицы.
- Отказоустойчивая, если использовать replicate таблицы.
- И все это в open source с очень активным community.

Вопросы
Здравствуйте! Меня зовут Дмитрий. Спасибо за доклад! Есть вопрос про дублирование данных. Я так понимаю, что в ClickHouse нет никакого способа решать эту проблему. Ее надо решать на этапе вставки или все-таки есть какие-то методы, которыми мы можем побороться с дублированием данных у нас в базе?
Откуда может возникнуть дублирование данных? Если у вас вставляльщик, который вставляет данные, отказоустойчивый, то он там делает retry. И когда он начинает делать retry, то, например, бац и ClickHouse отключился, а он продолжает делать retry. И в этот момент, конечно, может возникнуть дублирование данных. Но в ClickHouse оно не возникнет. Как мы от этого защищаемся?
Вот эта вставка блоками. В ZK хранятся checksums последних ста блоков. Это тоже настраиваемо, но 100 – неплохой вариант. Поэтому если вы вставили блок и у вас что-то взорвалось, и вы не уверены – вставили вы или нет, то вставьте еще раз. Если вставка прошла, то ClickHouse это обнаружит и не будет дублировать данные.
Т. е. если мы вставляем по 10 000 строк, у нас там будет храниться миллион строк, которые будут гарантировано недублированными?
Нет. Дублирование работает не на уровне строк.
Т. е. кусок, который мы вставляем, он 10 000. Соответственно, мы можем рассчитывать, что последний миллион у нас не будет дублироваться, если мы захотим повторить.
Да, но только если выставляете прямо такими же блоками.
Т. е. идентичными блоками, да?
Да, для идентичного блока считается checksum. Если checksum совпадает, значит блок уже вставили и дублировать не надо.
Я понял. И второй вопрос. Меня интересуют запросы distributed таблицы к replicated таблицам. Я так понимаю, что запрос у нас идет только к одной реплике. Можно ли как-то настроить, чтобы какие-то тяжелые запросы шли на обе реплики, чтобы часть данных оттуда, часть данных оттуда каким-то образом доставалась?
Да, можно так настроить. Это еще один способ заиспользовать больше компьютеров. Есть специальная настройка, вы ее устанавливаете. По-моему, она называется max_parallel_replicas. Что она делает? Она половину данных обрабатывает на одной реплике, половину на другой. Но сразу оговорюсь, это работает только, если при создании таблицы был указан ключ сэмплирования. В ClickHouse есть такая фича – ключ сэмплирования. Вы можете посчитать там запрос не по всем данным, а по одной десятой. И если у вас в реплицированной таблице задан ключ сэмплирования, то при указании этой настройки max_parallel_replicas, он сообразит, что можно одну вторую данных посчитать там и другую половину на второй реплике. И будет использовать обе.
Не будет ли еще раз сэмплирование?
Если вы не указали при запросе сэмпл, то сэмплирования не будет. Он просто это использует для того, чтобы разделить работу по двум репликам.
Понял, спасибо!
Спасибо за доклад! У меня три вопроса. Вы говорили, что индексы размазаны, т. е. там 8 000 с чем-то. И нужно писать большими объемами. Используете ли вы какую-то предбуферизацию? Рекомендуете ли вы что-то использовать?
Это больной вопрос, потому что все норовят по одной строчке вставлять. У нас в метрике, например, очень умный батчер, который отдельные команды разрабатывает, которые много дополнительной работы проводят, поэтому в ClickHouse его нет.
Что есть? Есть буфер-таблица, куда тоже по одной строчке не надо вставлять, потому что будет тормозить на какой-то ерунде. Но если вы туда вставляете, она по диску меньше ездит. Т. е. не будет на каждую вставку делать запись на диск. И очень многие люди, которые уже более серьезно подходят к ClickHouse, они используют Kafka. У вас в Kafka lock, ваша писалка берет записи из Kafka и вставляет их в ClickHouse. Это тоже хороший вариант.
Да, т. е. можно это вручную настроить. Еще вопрос. У нас есть distributed таблица, которая управляет всеми шардами. И, например, шард с distributed таблицы умер. Это значит, что все данные у нас умерли?
Distributed таблица не хранит ничего. Если она у вас умерла, то вы просто создаете заново, и все так же работает. Главное, сохранить local_tables, в которых данные лежат, поэтому, конечно, их нужно реплицировать.
И последний вопрос. Вы говорили, что можно вручную шардировать ее. А есть ли какие-то гарантированные транзакции, что я записал туда, записал туда, а если не записалось туда, то все это отменить? Я же пишу на три разных шарда.
Если кусок данных к вам пришел, то вы его должны на один шард записать. Только на один, главное, чтобы не было дублирование данных. В одно место записали и все хорошо.
Т. е. я должен хранить это, куда я записал?
Не обязательно это все хранить, потому что distributed таблица спрашивает все шарды. Когда у вас 500 серверов, как у нас, то начинает этого уже не хватать. Потому что на 500 серверов одновременно не очень хорошо ходить. Поэтому у нас там двухуровневое шардирование. Второй уровень уже знает, куда он положил данные и он на это обращает внимание. Но до 100 серверов этого за глаза хватает, т. е. просто во все серверы сходить и забрать результат обратно.
Спасибо большое!
Как изменять данные? Можно ли там чего-то изменить, например, блок целиком вынести и заново закачать, чтобы не целиком с нуля всю таблицу?
Да, можно изменить целиком блок, точнее не блок, а всю партицию. Сейчас – это месяц. Но у нас есть приоритетная задача сделать партицию произвольной. Вы берете и говорите «alter table drop partition» и он убирается, и вы можете обратно залить данные.
И еще есть кейсы, когда у вас какие-то данные, которые нужно обновить. Они есть и они немножко изменяются в реальном времени. Например, есть не хиты, а визиты пользователей. Т. е. пользователь пошел на одну страничку, на другую и у него длина визита растет. В ClickHouse для этого есть движок, который называется CollapsingMergeTree. Им не очень удобно пользоваться, но эту задачу он решает. И когда вы хотите что-то поменять, вы записываете две записи: первая – это удалить предыдущую запись, вторая – это записать новые данные. И эта таблица где-то у себя в фоне будет оптимизировать. И чуть-чуть вы можете изменять данные таким способом.
Вам нужно будет хранить всю эту строку где-то. Вы, конечно, можете сходить в ClickHouse и спросить: «Какая последняя строка для этого ключа?», но это будет медленно уже.
И параллельный вопрос. Правильно ли я понимаю, что если мне нужна репликация на две точки, а не на три, то проще поставить Kafka и с нее две базы писать и не париться? Т. е. когда два дата-центра, а третьего нет.
Мы все-таки рекомендуем replicated таблицы. Почему? Потому что distributed таблица тоже умеет реплицировать.
Как replicated сделать на два ДЦ? У меня все равно получается, что если падает мастер, то писать никуда нельзя, а можно только читать. Или там какие-то простые способы? Slave сделать мастером, а потом догнать первого мастера до slave?
А с Kafka у вас как?
С Kafka я буду выливать каждую независимо. С Kafka все равно придется делать на три ДЦ.
Kafka тоже использует ZK.
На нее данных меньше надо. Но она только пару дней будет хранить, а не за всю историю, в Kafka меньше ресурсов. Но ее на три ДЦ дешевле делать, чем ClickHouse на три ДЦ.
ClickHouse не обязательно размазывать на три, вам только нужно ZK поставить.
А, все, только для quorum ZK, данные дублируются только два раза. Для quorum у нас есть ДЦ.
Почему мы еще рекомендуем replicated таблицу, а не просто в две таблицы запихивать? Потому что очень много проверок происходит, что данные именно идентичные. Если вы так будете записывать самостоятельно или через distributed таблицу, то легко получить какое-то расхождение. И потом оно уже никогда не исправится, потому что уже записали и до свидания. И не понятно – разошлось или нет. А replicated таблицы непрерывно пытаются поддерживать вот эту общность и единый набор кусков.
У меня вопрос касается утилизации памяти. Как наиболее эффективно распределять ее? Сколько под instants выделять?
Про память такая история, что в ClickHouse есть такая настройка, как max_memory_usage. Это сколько вы можете отъесть, когда обрабатываете запрос. Для чего еще нужна память? Память нужна под дисковый кэш. Т. е. у ClickHouse нет какого-то хитрого кэша. Некоторые системы, как делают? Они читают o_direct с диска и как-то у себя кэшируют. ClickHouse так не делает. Какую-то часть памяти (довольно большую) нужно оставить под дисковый кэш. У вас данные, которые недавно читались с диска, будут потом из памяти прочитываться. И треть вы отводите на память, которая нужна в запросе.
Для чего ClickHouse расходует память? Если у вас запрос стриминговый, т. е. просто пройтись и что-то там посчитать, например, count, то будут единицы памяти расходоваться.
Где может понадобиться память? Когда у вас group by с большим количеством ключей. Например, вы по тем же самым referrers что-то группируете и у вас очень много различных referrers, urls. И все эти ключи нужно хранить. Если вам хватило памяти, то хорошо, а если не хватило, то есть возможность group by выполнить на диске, но это будет гораздо медленнее.
Это он сам определит?
Нужно включить.
Есть какой-то объем, который вы рекомендуете выстраивать? Например, 32 GB на ноду? Т. е., когда эффективно используется.
Чем больше, тем лучше. У нас 128 GB.
И один instance все 128 использует, да?
Да, конечно, он их все заиспользует. Конечно, если у вас данные не такие большие, то столько не нужно. Сколько данных, столько и памяти берите. Но если у вас данные уже в памяти не помещаются, то чем больше, тем лучше.
Алексей, спасибо за доклад! Вы не измеряли падение производительности при сильной фрагментации файловой системы?
Я сейчас конкретных цифр привести не могу. Конечно, такая проблема есть. Когда диски почти заполнены, то файлы уже не так расположены локально, начинается уже фрагментация. И просто надо уже следить за тем, что у вас не сильно заполнены диски. И если начинают заполняться, то нужно новую ноду ставить. Конкретные цифры привести не могу.
Хотя бы примерный порядок?
Не знаю, процентов до 70 нормально будет.
Спасибо!
Добрый день! У меня два вопроса. Насколько я знаю, сейчас у ClickHouse только http-интерфейс для обмена данными с клиентом. А есть ли какой-то roadmap, чтобы сделать бинарный интерфейс?
У нас есть два интерфейса. Это http, который можно любым http-клиентом использовать, который в JDBC-драйвере используется. И есть нативный интерфейс, который мы всегда считали приватным и не хотели для него какой-то библиотеки делать. Но интерфейс этот не такой сложный. И мы поддерживаем там прямую-обратную совместимость, поэтому добрые люди использовали исходники как документацию и в Go есть, я слышал, отличный драйвер, которые нативные клиенты используют. И для C++ мой коллега сделал отдельный драйвер, который позволяет использовать нативный интерфейс и вам не нужно линковаться со всем ClickHouse, чтобы его использовать. И для других языков тоже, наверное, есть. Точно не знаю. Т. е. формально мы его считаем нашим приватным, но по факту он уже публичный. Из некоторых языков им можно пользоваться.
Спасибо! Вы говорили, что написали свою систему репликации данных. Допустим, Impala использует HDFS для репликации данных, она не делает репликацию самостоятельно. Почему вы написали репликацию, чем она лучше, чем HDFS?
Интересный вопрос. ClickHouse развивается послойно. Сначала были простые merge таблицы, потом появилась для них репликация. И вот эта схема с кусками, которая мержится, она просто так на HDFS не ложится. Наверное, можно было использовать HDFS как файловую систему и там хранить куски, но проще на локальной файловой системе это делать.
Т. е. вы напрямую не сравнивали?
Нам нужно, чтобы вот эти слияния кусков тоже были неотъемлемой частью репликации, т. е. какое-то готовое решение для этого использовать, по-моему, нельзя.
Один кусок – это будет один блок на HDFS и будет операция *opened*, если это возможно.
Т. е. использовать HDFS как хранилище?
Да. Чтобы не делать собственные репликации. Вы записали на HDFS и считайте, что оно уже реплицировано, и поддерживается отказоустойчивость.
А читать-то мы хотим с локального диска.
HDFS поддерживает локальное чтение. Вы можете узнать, на каких нодах хранятся данные и чтение запускать там, где они хранятся.
Интересная мысль, надо подумать.
Спасибо!

