Что делать с данными в 2021 году, если вы финансовая компания с традиционной инфраструктурой и не смотрели дальше BI? Как и зачем договариваться разным бизнесам в B2B и что можно найти среди маленьких данных?
Мы расскажем про опыт НРД — центрального депозитария РФ. НРД хранит активы на сумму более 60 трлн руб. и аккумулирует практически весь рынок ценных бумаг в России. Основной бизнес сфокусирован на надежности: хранение, проведение расчетов, отчетность.
Если вы тоже задаетесь похожими вопросами или вам знакомы слова финансовый бэк-офис, добро пожаловать под кат.

Согласно Big Data Executive Survey 2020, 98,8% опрошенных компаний, входящих в список Fortune-1000, инвестировали в создание дата-центричного бизнеса. Две трети опрошенных компаний инвестировали больше 50 млн долл., а каждая пятая – больше 500 млн долл. Но то же исследование из года в год показывает: примерно две трети опрошенных руководителей признают, что их бизнес так и не стал дата-центричным. А трое из четверых замечают, что эта тема стала для них настоящим вызовом. Что делать с этой информацией, если последние 15 лет вы прицельно не занимались данными и наконец решили, что пора?
Данные, или что мы делали позапрошлым летом
Сначала задали себе ряд ключевых вопросов:
Сколько у нас данных? Как быстро они прирастают или обновляются? Какие они? Где хранятся?
Какие из наших данных уникальны?
Как устроены процессы работы с данными? Как данные появляются в системах, где дублируются и теряются?
С какой задержкой мы получаем информацию? Сколько занимает и стоит типичный запрос или сложная аналитика?
Что нам на самом деле нужно от данных?
Ответы на них не статичны и могут и будут меняться на разных стадиях зрелости компании. Например, мы ориентируемся на классификацию Google и Deloitte, а можно рассчитать data maturity index по аналогии с BCG. Сейчас мы считаем, что идеи ниже актуальны как минимум до уровня mature.
Чтобы понять картину в НРД, мы начали с аудита. Аудит данных и процессов работы с ними занял 3 месяца. Команда на этом этапе: продакт и техлид, занятые на 30-50%, по 1-2 представителя каждого бизнеса для интервью и по одному лиду ключевых систем для единичных запросов.
Результат получился неоднозначный: с одной стороны, в силу законодательных требований и глубокой интеграции с глобальной финансовой инфраструктурой системы и процессы управления данными в бизнесах сейчас работают отлично. В какой-то степени весь современный финансовый бизнес и есть бизнес вокруг данных. С другой стороны, как и другие финансовые компании, мы в основном работаем со структурированными данными: транзакции, профили контрагентов, счета, плановые денежные потоки, отчетность, статусы процессов и т.д. Неструктурированные данные: переписка, логи, переговоры, видео и фотоинформация — хранятся в разных системах и используются в основном для аудита.
И болевая точка, которую выявил аудит: без радикальных изменений никакие новые направления, связанные с комбинацией имеющихся, а тем более с новыми данными, невозможны. Мы просто не сможем поддержать взрывной рост или выход в новый сегмент.
В целом если учитывать только объем и скорость прироста структурированной информации, то НРД при всём масштабе бизнеса раз в 10 не дотягивает до традиционной границы big data. Но если смотреть на ценность и уникальность наших данных, мы в топе.
Проблемы с данными, с которыми часто встречаются наши коллеги в индустрии:
Внутренних данных мало, доступные внешние данные не используются.
Не все доступные данные надлежащим образом собираются, обрабатываются и хранятся.
Те, что собираются, содержат ошибки и не всегда появляются вовремя.
Те, что собраны и почищены могут дублироваться незаметно для бизнес-процессов и критично для аналитики или наоборот.
Аналитика ассоциируется с ошибочным выбором метрик или возможностей монетизации.
Мы поймали все проблемы в разном объеме. Тут главное не отчаиваться. Если данных не хватает, проверьте открытые. Kaggle, тестовые датасеты вендоров, прямые запросы партнерам, открытые API интернет-сервисов. Проверьте на истории, насколько вам подходит сет. Как только вы поняли, что конкретные данные ценны для вас и работают, можно покупать. Если данные нужно разметить и они не конфиденциальные, привлекайте студентов, придумывайте исследование. Если данные дублируются, выбирайте мастер источник, которому будете доверять. Если в данных есть ошибки, оцените трезво, насколько они влияют на результат и вносят вклад в конечную точность анализа. Важно — исправляйте, неважно — смиритесь.
Кстати, бюрократический ответ на аудит и концепцию KYD (know your data; понимание «профиля» данных, которыми вы оперируете) — каталог данных. Но, по-честному, тут все зависит от масштаба: если можете описать данные в простом виде и вам все понятно, пункт выполнен. Если нет, усложняйте постепенно. Начните с таблички и, если действительно потребуется, добавляйте документы и спецрешения. По поисковому запросу «data catalogue» есть варианты на любой кошелек :) Для себя мы остановились на Amundsen, но об этом в следующей серии.
Технологии: копать, не копать, делать вид, что копаешь?
Следующий шаг после понимания своих данных — технологии. Заманчивый ответ для задачи «внедрить биг дату» from the top – предложить правильную архитектуру и красивое технологическое решение для работы с абстрактными большими данными. Но во-первых, не факт, что ваши данные большие, а во-вторых, не факт, что вы с технологиями справитесь и создадите новую ценность.

Для ответа на вопрос про размер данных можно ориентироваться на концепцию 3V Gartner: volume, velocity, variety. И добавить любые слова на V, которые кажутся вам подходящими для классификации (например, «Спутник V» к данным не относится, но если очень хочется, тоже можно использовать для классификации).
Очень условно стадии развития инфраструктуры работы с данными можно описать так:
1C/Excel — все понятно. Данных мало, хоть мелом на заборе графики рисуй.
BI-решения. Могут быть «витринами» и собирать данные из нескольких БД, могут основываться на DWH. Сюда же Tableau, Cognus, Qlik и аналоги.
Специализированные решения для хранения и анализа больших или быстрых данных. Сюда попадает все дорогое и не всегда полезное и условно бесплатное, но требующее классной команды: in-memory БД, кластерные решения на основе Hadoop/Spark/Kafka/Hive/NiFi и другие.
Облачные решения: Amazon Athena/Redshift, Google BigQuery, Data Lake Analytics. Интересно, но страшно для финансовых компаний с точки зрения информационной безопасности. Как альтернатива возникают внутренние облака для группы компаний.
Платформы данных, комбинирующие пункты 2-4, виртуализация данных.
При этом любая инфраструктура устаревает примерно раз в 5 лет. Поэтому, говоря о технологиях работы с данными, мы обсуждали стратегию развития инфраструктуры компании в целом, а не только локальное решение по работе с данными. Не data lake, не универсальное хранилище, не аналитическая система.
Мы стартовали с технологического уровня 2 (работающий BI) и надеялись не переходить к следующим пунктам в ближайшие 2 года. Команда на этом этапе: 1 продакт, 1 дата-аналитик, 1/2 тимлида, 1 стажер. Плюс 1 человек от каждого бизнес-линии и от каждой системы для периодических консультаций.
Ключевые вопросы к технологиям на этом этапе входят в категории «как сделать» и «действительно ли нам это нужно». Как быстро аналитик получит доступ к новым данным? Сколько человек действительно потребуется, чтобы выгрузить данные для аналитики? Можно ли сделать новый отчет или получить доступ к данным в новом разрезе без разработки? Что мешает? Какую задержку в задачи вносит data mining? Какие технологические ограничения есть у разных систем?
На первый взгляд, схема BI плюс прямые запросы к источникам «под задачу» работала. Но через полгода мы поняли, что с текущими технологиями получение данных, не включая очистку и разметку, занимает 75% времени аналитики. Основные ограничения: legacy мастер систем со сложными структурами баз данных, не унифицированные API и множественные интеграции систем, последовательное согласование между разными бизнес-линиями и ИТ-функциями и привязка ролей доступа к конкретным системам, а не данным.
Мы вернулись к вопросу централизованной инфраструктуры по работе с данными. Три важных для нас элемента: каталог данных для поиска нужной информации, ETL и, собственно, хранилище. А основной риск — делать инфраструктурные проекты больно, а переделывать — еще больнее.
Поэтому мы начали с proof of concept (POC). На POC стоит проверять максимальное количество технологий на реальной задаче. Задача должна включать в себя максимально разнообразные данные и проверять самые архитектурно сложные места. Как референс можно использовать riskiest assumption test из продуктовой разработки. То есть если вы больше всего сомневаетесь в работе с объемными данными, пробуйте на объеме. Если в сохранности данных — прогоняйте все риск-сценарии для нагруженных систем. Если в объединении данных из разных источников и доступности для аналитики — подключайте максимум источников и ограничивайте объем. Если в гибкости — пробуйте радикальные изменения. Например, мы выбрали для тест��рования работу с профилем клиента и предсказание вероятности покупки дополнительных продуктов из линейки с учетом того, что часть данных обезличена.
Команда на этом этапе: 1 продакт, 2 дата-аналитика/дата-сайнтиста, 1 ИТ тимлид, 1 дата-инженер, 1 ML-разработчик, 1/2 аналитика. С этого момента все завязано на людей.
Люди, или «у нас другие cultural references»
По большому счету вся работа с данными – вопрос людей: их компетенций, открытости, культуры, участия. Поэтому люди, выстраивание процессов и культуры работы с данными — ключевая часть дата-стратегии НРД.
До пандемии мы думали, что можно не инвестировать, пока не проверим гипотезы и не поймем, как монетизировать. Это полуправда. Чтобы проверить гипотезу, нужны как минимум:
Аналитик(и).
Сервер или облако для экспериментов (Сюрприз! Даже если данные пролезают в 1 скрипт или на ПК, совместной работы не получается и времени на коммуникации уходит больше, чем на анализ).
Дата-инженер — настраивать доставку данных не больше, чем за 30% времени задачи.
Участие бизнеса — владельцев данных и дата-стюардов.
Поэтому параллельно с тестированием технологий мы начали строить матричное взаимодействие между людьми в разных бизнесах и подразделениях. Ключевые роли в дата-матрице НРД: дата-аналитики/дата-саентисты, дата-стюарды, дата-инженеры и ML-инженеры. Дата-аналитик отвечает за построение моделей, проверку гипотез, прототипирование. Дата-стюард — за данные внутри бизнес-линий. При этом роль дата-стюарда совмещена с продуктовой — за данные отвечают те же люди, что и за развитие бизнеса и продуктовую разработку. Сейчас так получается избежать конфликта интересов между быстрым развитием и доступностью данных. Дата-стюарды есть в каждой бизнес-линии. Дата-инженер делает данные доступнее, а ML-инженер помогает докатить сервисы до продакшн.
Такая структура матрицы дает взгляд на развитие с трех сторон: сам бизнес, ИТ-архитектура, управление данными (на C-level это управляющие директора, CIO и CDO) — и подходит для текущего уровня зрелости компании.
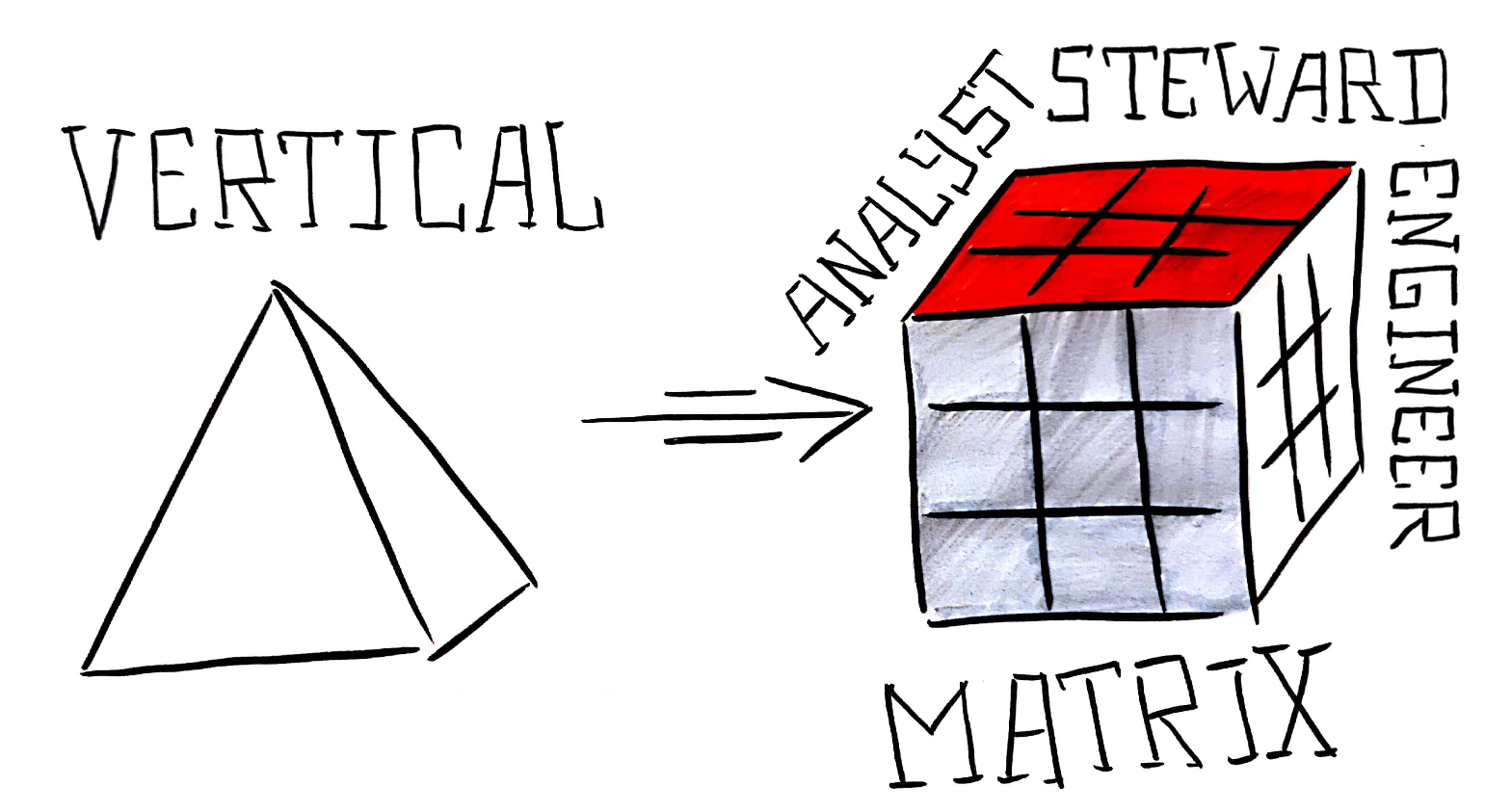
Что делать, если у дата-стюарда не будет хватать ресурса на 2 роли? Или снова появится конфликт интересов между развитием и архитектурно правильными решениями? Или работа замедлится еще по каким-то причинам? Договариваться.
Короче, сейчас мы понимаем data friendliness как открытость. Открытость для сотрудников компании: каждый может посмотреть задачи в работе, раз в 5-6 недель проводится демо и обсуждение с дата-стюардами и всеми, кому интересны данные. Открытость к идеям: идеи приходят из несвязанных областей, от студентов на конференциях, из самих данных. Открытость к людям: в финансы сложно нанимать звезд data science за разумные деньги, проще растить внутри.
Быть открытым — значит понимать и принимать риски. И risk taking культура в разумных количествах должна быть на каждом уровне. Например, мы не можем снижать контроль за конфиденциальными данными, но можем работать со студентами на открытых датасетах с похожей структурой. Не можем рисковать основным бизнесом, но можем проверить 10 новых гипотез, чтобы найти классную. Risk taking в нашем случае значит, что лучше решать задачу и ошибиться, чем не решать вообще. Право на ошибку на этапе исследований есть у каждого: дата-стюарда, дата аналитика, дата-инженера.
И финальный совет: не отдавайте работу с данными на аутсорс. Да, растить или собирать команду внутри дорого на горизонте года, но стоит того, если смотреть на данные как на актив на ближайшие 5-10 лет.

