Всем привет! Меня зовут Сергей Орешкин, я CDO Московской Биржи. Вместе с моими коллегами – Петром Лукьянченко (бизнес), Владимиром Молостовым и Федором Темнохудом (ИТ) – мы расскажем об опыте поиска, выбора решения и запуска платформы ресурсоемких вычислений на большом объёме данных на базе Hadoop.
Каждый день только на рынке акций Мосбиржи почти 100 тысяч частных инвесторов совершает более 20 млн транзакций объемом от 40 млрд рублей. Один из ключевых параметров, которыми оперируют инвесторы, принимая решения о сделке, – это ликвидность бумаги. Бумага считается ликвидной, если её можно купить или продать по желаемой цене за минимальное время. По малоликвидным бумагам и��вестору приходится ждать, прежде чем найдется другой инвестор, готовый заключить сделку на взаимовыгодных условиях. Для инвестора такое ожидание – это издержки, а вероятность образования таких издержек называется риском ликвидности.
Для Биржи риск ликвидности – тоже явление нежелательное, в результате его реализации резко падает объем торгов, и клиент не может продать/купить бумагу по комфортной для него цене. А задача биржи обеспечить такую возможность для клиента в любой момент – причем по хорошей цене. Чтобы минимизировать риск ликвидности во всем мире работает институт маркетмейкерства: брокеры и банки наполняют стаканы заявками на покупку и продажу бумаг, за что получают вознаграждение от биржи. И, конечно же, мы хотим платить маркетмейкерам только тогда, когда их услуги действительно нужны – а это значит, что мы должны точно знать, что происходит с инструментами, которые представлены на том или ином рынке, и насколько велик риск ликвидности по каждому из них. Учитывая, что количество торгуемых бумаг крайне велико, и торгуются они высокочастотно и супербыстро, нам нужен инструмент, который позволит обсчитать огромный объем данных «на лету».
Говоря «биржевым» языком, перед нами встала задача расчета метрик ликвидности и метрик маркетмейкерских программ. Для её решения нам потребовалась система, выполняющая большой объем расчетов на торговых данных, которая позволила бы на основе данных об изменениях рыночных заявок рассчитывать сотни аналитических показателей в различных разрезах, а также моделировать поведение рынка, оценивая вклад конкретного участника. Чтобы создать ядро этой системы, мы разработали прототип горизонтально масштабируемой платформы для массово-параллельных вычислений на базе кластера Hadoop. В целевой конфигурации платформа способна эффективно обрабатывать огромные массивы информации – десятки триллионов вычислений в день.
Рассказываем, почему мы выбрали именно это решение и в чем его польза для Биржи.
Зачем всё это нужно
Ещё раз коротко о цели: нам нужно было решение, позволяющее быстро выявлять инструменты с ухудшающейся ликвидностью, чтобы мы могли с помощью маркетмейкеров обеспечить комфортный для инвесторов объем спроса и предложения. А если ликвидность бумаги достаточная, перенаправить усилия маркетмейкеров на решение других задач.
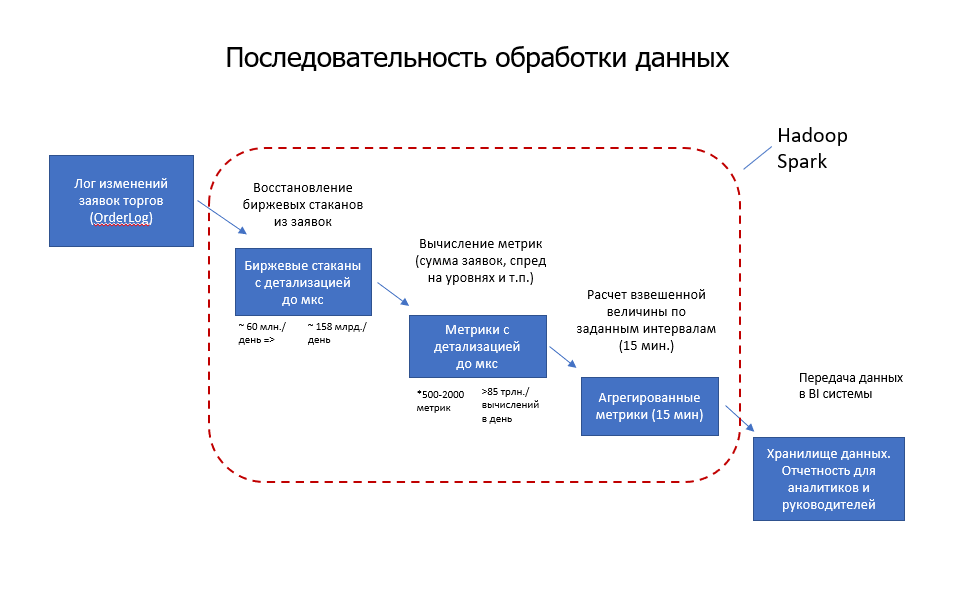
В основе нашего решения лежит высокопроизводительный вычислительный кластер. Для оценки мы выбрали 15 метрик ликвидности, которые характеризуют стабильность рынка, его популярность, риски для не связанных с ним участников и прочее. То есть с помощью нашей платформы Биржа может централизованно отслеживать динамику спроса на конкретные бумаги, какие инструменты больше чувствительны к ярким новостным событиям, как меняется ликвидность в течение торгового дня. У каждой метрики есть несколько параметров, то есть всего мы обрабатываем около 250 метрик. Обработка выполняется ежедневно с учетом изменений всех заявок на всех рынках, результаты агрегируются до значений с шагом в 15 минут. Результаты расчётов передаются в отчёты, которые используются для внутренней аналитики. Кроме того, мы можем предоставить заинтересованным компаниям доступ к этим отчётам.
Участники торгов могут использовать возможности системы для отслеживания динамики рисков: наблюдение за изменением ликвидности помогает оценивать вероятность, с которой игроки могут быстро закрыть какую-нибудь позицию. К тому же динамика ликвидности, объемов торгов, спреды и другие данные, собираемые системой, позволяют участникам находить для себя новые источники прибыли.
Выбор технологии
Прежде чем выбирать технологию для новой системы, мы оценили объём необходимых вычислений. Каждый день мы сохраняем журналы событий примерно по 60 млн торговых заявок. Из этих журналов мы с точностью до тика (несколько микросекунд) восстанавливаем биржевые стаканы – это около 150 млрд записей. Затем для каждого биржевого стакана рассчитываем от 500 до 2000 показателей рынка (метрик), и в результате получаем те самые 85 трлн вычислений в день (для усредненного объема за год). Один из сценариев использования системы предполагает ежедневную обработку данных за предыдущий день не дольше 5 часов. Другой сценарий — ретроспективный — должен обеспечивать возможность анализировать данные за год, моделировать исключения с рынка конкретных участников и/или изменения параметров расчетов. И в этом случае 85 трлн вычислений умножаются на количество торговых дней в году. К счастью, от этого объёма нужно считать лишь около 20 %, потому что мы анализируем только часть рынков. Но всё равно получается много.
Определившись с нагрузкой, мы начали искать подходящий инструмент.
Первоначально задача была реализована на базе SQL. Критерии выбора:
наличие экспертизы;
технология нам показалось наиболее простой в реализации;
нет передачи больших массивов данных между БД и сервером приложений.
Но специфика подготовки массивов данных для расчетов не позволила использовать стандартные средства SQL, что привело к значительным задержкам. В результате решение на базе SQL на нашей, хотя и достаточно мощной, СУБД изначально показало низкую скорость расчёта, и мы сразу закрыли для себя эту технологию.
Затем много экспериментировали с классическими Java-приложениями. К сожалению, здесь отсутствуют простые механизмы горизонтального масштабирования: нельзя увеличить скорость расчётов простым добавлением серверов. Многое приходится делать вручную. К тому же каждый новый экземпляр расчета требует отдельной инициализации, а это высокие накладные расходы. И мы понимали, что возможностей Java без горизонтального масштабирования нам скоро будет мало. Имевшиеся у нас технологии просто не позволяли решить стоящую задачу.
Пилот в облаке
Пилотирование других технологий требовало создания испытательных стендов, а это раздуло бы бюджет и сроки проекта. Тогда мы решили провести R&D и обратиться к известным на рынке горизонтально масштабируемым решениям на базе Hadoop и Spark. Большого опыта в технологии у нас не было, как и инфраструктуры для испытаний. Пилот решили выполнить в облачной среде, потому что это позволяет за минимальные деньги и время получить готовую инфраструктуру и инструменты, а также, в целевом варианте, позволяет платить только за те вычислительные ресурсы, которые фактически использованы в момент расчетов. Выбрали Яндекс.Облако, т.к. у них есть готовый сервис Yandex Data Proc на базе Apache Bigtop, а для консультаций по Spark пригласили компанию Glowbyte. Полностью обезличили данные и стали экспериментировать с публичным облаком.
На первом этапе мы перенесли код с классической Java на JavaSpark и запустили его на кластере Hadoop. Но изменить код, чтобы настроить параллельные вычисления на кластере, оказалось непростой задачей, код просто не работал, задачи не распараллеливались. А сроки пилота уже поджимали. Параллельно пробовали переносить старый SQL с Oracle на Spark SQL, но потом отказались от этого пути. Делегировать написание кода прототипа подрядчику мы не стали, потому что существенно увеличились бы сроки и бюджет пилота из-за отсутствия у подрядчика на входе экспертизы по достаточно сложной бизнес-логике. Самым эффективным способом восполнения экспертизы по Spark, необходимой нам для R&D, оказался режим совместной работы с прототипированием участков кода на целевой технологии на основе наших постановок для подрядчика. Это позволило очень быстро найти решение основных проблем в настройке кода, без необходимости погружения подрядчика в бизнес-логику. В результате написали пилот на Java Spark. Вместе с кодом на кластер перенесли обезличенные и искаженные алгоритмами массивы данных для расчетов. Применение корректной технологии партиционирования исходных данных позволило использовать механизм с базовым циклом foreachPartition, который позволяет автоматически распределять расчёты как на разные узлы кластера, так и на отдельные нити расчётов внутри одного узла. Таким образом мы:
обеспечили автоматическое горизонтальное масштабирование на нескольких узлах кластера;
оптимально загрузили мощности отдельных серверов;
сократили накладные расходы на операции с входными данными. Каждый узел работает только со своим массивом данных, а финальная сборка производится уже из агрегированных массивов.
Такая архитектура позволила приступить к тестовым расчетам для выбора оптимального кластера. Тестировать в облаке было очень удобно: просто указываешь в настройках нужную конфигурацию, перезапускаешь кластер, и можно начинать тесты. Замерять различные параметры нагрузки можно как через графический интерфейс, так и из консоли для сохранения данных для анализа. При этом кластер собирается практически на лету. В нём мы использовали серверы с мощными процессорами и для их загрузки требовалось достаточно много оперативной памяти. В результате тестирования выяснилось, что оптимальной конфигурацией под наши задачи, с точки зрения стоимости владения, является минимальное количество мощных серверов с максимальным количеством оперативной памяти.
В процессе пилота совместно с коллегами из информационной безопасности детально проанализировали возможности публичного облака обеспечить наши высокие требования к защите корпоративных данных.
Требования по ИБ, помимо прочих, включали следующие.
Минимизация рисков side channel атак. Yandex.Cloud среди прочих подходов по митигации этих рисков позволяет размещать пользовательские нагрузки на выделенных хостах для физической изоляции ВМ в публичном облаке.
Проводить аудит действий пользователей и администраторов облака. На момент тестов такой функциональности в Yandex.Cloud не было, но сейчас она уже доступна в preview.
Шифровать данные ключами, хранящимися на стороне заказчика. Реализация этого требования может быть достигнута при помощи программно-аппаратных криптографических модулей (HSM). Yandex.Cloud позволяет шифровать данные собственными ключами, которые хранятся в сервисе Yandex KMS. Однако на данный момент этот сервис поддерживает интеграцию с HSM, расположенным в облаке Яндекса, но не поддерживает интеграцию с HSM на стороне клиента.
Отсутствие интеграции HSM с облачным KMS не позволило нам развернуть промышленное решение в Yandex.Cloud. Впрочем, план развития Yandex.Cloud включает реализацию нужных нам технологий защиты по большинству пунктов в обозримом будущем, что позволит использовать облако не только для пилотных задач.
После того, как с помощью Облака нам удалось сравнительно быстро провести R&D и разработать прототип целевого решения, мы продолжили экспериментировать с размещением целевой конфигурации Hadoop в разных ЦОДах Биржи. Из-за особенностей нашей инфраструктуры оказалось невозможно распределить один кластер по нескольким ЦОДам – в каждом из них приходится делать отдельный кластер. На отладку локального Hadoop-решения ушло около месяца. Выбрали подходящую отказоустойчивую инфраструктуру и посчитали стоимость владения для двух оптимальных конфигураций, которые удовлетворяли требованиям к производительности и георезервированию. Одна производительнее, но дороже, вторая – наоборот. Hadoop удобен тем, что базовую конфигурацию можно в любой момент нарастить, добавив новые узлы.
Особенности реализации
При расчётах на Hadoop каждый узел обрабатывает те данные, которые на нём лежат, обмена информацией между узлами практически нет. Это очень сильно сокращает длительность расчёта, особенно первичного. А за счёт использования массивно-параллельных вычислений нам удалось создать гибкую систему: заказчик может выбирать конфигурацию, просто наращивая количество узлов, не переписывая код.
Hadoop из коробки предлагает много технологий распараллеливания. Хотя с их настройкой было очень много трудностей, как и с правильным распределением данных по партициям, с выбором формата хранения. В итоге остановились на формате Parquet с достаточно высоким уровнем сжатия, чтобы сократить дисковые операции. Затем мы решали проблемы с сохранением промежуточных данных в Hadoop: как и куда их правильно класть, как их партиционировать, чтобы каждый executor брал только свою партицию. Пришлось решать и задачу отказа от БД, в которой у нас хранилось всё, включая настройки и журналы.
На сегодняшний день мы реализовали в коде около 15% вычислений от запланированного объёма. Для определения оптимальной целевой конфигурации Hadoop и бюджета проекта нужно было создать точную модель прогнозирования финальной нагрузки. Первые прикидки были очень обобщенными и не учитывали, что все инструменты — торговые метрики — сильно отличаются своими стаканами, и поэтому объёмы вычислений могут различаться на порядки. Например, одна из метрик фьючерсного рынка занимала 40 % всех расчётов по этому рынку.
В результате мы ввели понятие интегральной метрики, которая описывала объём расчётов для каждого измеряемого инструмента. Предположили, что производительность вычислений будет прямо пропорциональна интегральной метрике отдельно для каждого инструмента. Далее нужно было понять, какие интегральные метрики ожидаются в будущем, когда будет написан весь код. Вывели для каждого инструмента прирост объёма расчётов — взвешенную величину, — и оценили рост объёма вычислений по каждому рынку. При прогнозировании учли и такую особенность: скорость вычисления на обезличенных данных примерно на 30 % выше, чем на реальных. Оказалось, что обезличивание настолько меняет характер данных, что это сильно увеличивает скорость расчётов на сопоставимых кластерах.
Итоги и планы по развитию
По итогам пилота длительностью три месяца мы подтвердили на практике гипотезу о выборе в качестве целевой технологии для нашей задачи горизонтально масштабируемых, массово-параллельных вычислений на базе Spark. Удалось быстро создать прототип решения, в том числе за счет адресного применения экспертизы GlowByte по новой для нас технологии.
Благодаря возможностям Yandex Cloud мы смогли очень быстро получить всю необходимую инфраструктуру и ПО для разработки и апробирования решения, смоделировать целевую нагрузку, а также выбрать оптимальную целевую конфигурацию количества и параметров узлов кластера, в том числе, с точки зрения оптимизации бюджета целевого решения.
Фактически мы получили успешный прототип решения. Осталось только расширить функционал на все биржевые рынки и увеличить количество вычисляемых метрик, удовлетворив все требования бизнеса.
