В PVS-Studio появилось одно крупное изменение – это поддержка межмодульного анализа C++ проектов. В статье речь пойдёт про то, как это реализовано в других инструментах, как сделали мы, как попробовать и что удалось найти.

Зачем нужен межмодульный анализ и что он даёт анализатору? Во время работы анализатор проверяет только один исходный файл, не имея информации о том, что находится в других файлах проекта. Межмодульный анализ позволяет дать информацию анализатору о полной структуре проекта, делая анализ более точным и качественным. Это очень схоже с задачей оптимизации на этапе компоновки (Link Time Optimization, LTO). Таким образом, анализатор может узнать поведение той или иной внешней функции из другого файла проекта и выдать срабатывание, к примеру, на разыменование нулевого указателя, переданного как аргумент внешней функции.
Чтобы разобраться, почему реализация межмодульного анализа является непростой задачей, стоит сначала познакомиться со структурой C++ проектов.
Краткая теория компиляции C++ проектов
До введения стандарта C++20 в языке была принята только одна схема компиляции. Как правило, код программ содержат раздельно в заголовочных файлах и файлах с исходным кодом. Рассмотрим всё по этапам:
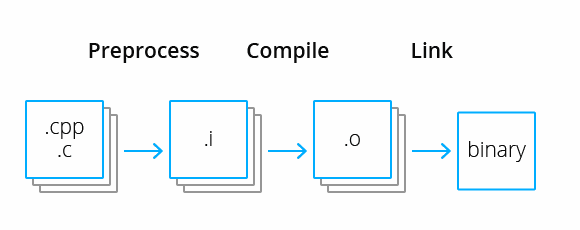
Препроцессор выполняет предварительные операции над каждым компилируемым файлом (единицей трансляции) перед тем, как передать его компилятору. На этом этапе происходит подстановка текста всех заголовочных файлов на место директив '#include' и раскрытие всех макросов. Результатом этого этапа являются так называемые препроцессированные файлы.
Компилятор преобразует каждый препроцессированный файл в файл с машинным кодом, специально подготовленным для компоновки в исполняемый бинарный файл. Такие файлы называют объектными.
Компоновщик объединяет все объектные файлы в бинарный исполняемый файл, разрешая при этом конфликты при совпадении символов. Только на этом этапе код, написанный в разных файлах, связывается в единое целое.
Преимущество такого подхода в параллелизме. Каждый файл с исходным кодом можно транслировать в отдельном потоке, что значительно экономит время. Однако для средств статического анализа такая особенность языка создаёт проблемы. Всё хорошо, пока происходит анализ одной конкретной единицы трансляции. Строится промежуточное представление, например, в виде абстрактного синтаксического дерева или дерева разбора, которое содержит актуальную для текущего модуля таблицу символов. После этого можно работать с ним и запускать различные диагностики. Однако для символов, определённых в других модулях (в нашем случае — других единицах трансляции) нет достаточной информации, чтобы делать про них выводы. Сбор этой информации и является межмодульным анализом.
Стоит отметить, что стандарт C++20 внёс изменения в конвейер компиляции. Речь идёт о введении модулей, которые позволяют уменьшить время компиляции проекта. Это отдельная тема для обсуждения и, очевидно, головная боль разработчиков инструментов для C++. Однако данная функциональность на момент написания статьи недостаточно поддерживается сборочными системами. По этой причине остановимся на классическом методе компиляции.
Межмодульный анализ в компиляторах
Одним из самых популярных инструментов в мире трансляторов является LLVM — набор инструментов для создания компиляторов и работы с кодом. На основе него построены многие компиляторы для таких языков, как C/C++ (Clang), Rust, Haskell, Fortran, Swift и многие другие. Это стало возможным благодаря тому, что промежуточное представление LLVM абстрагируется как от конкретного языка программирования, так и от платформы. Межмодульный анализ в LLVM выполняется именно над промежуточным представлением в ходе оптимизаций времени связывания (LTO — Link Time Optimization). В документации LLVM описаны четыре фазы LTO:
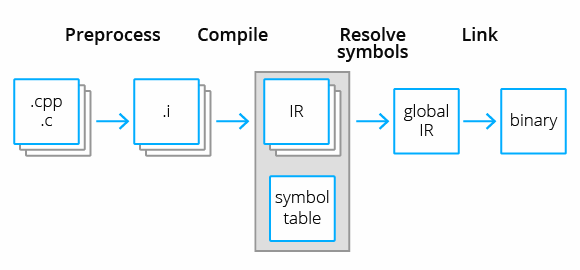
Чтение файлов с промежуточным представлением. Компоновщик читает объектные файлы в произвольном порядке и собирает информацию о встреченных символах в глобальную таблицу символов.
Symbol Resolution. На этом этапе компоновщик разрешает конфликты между символами в глобальной таблице символов. Как правило, именно тут обнаруживается большинство ошибок времени компоновки.
Оптимизация файлов с промежуточным представлением. Компоновщик осуществляет эквивалентные преобразования над файлами с промежуточным представлением, основываясь на собранной информации. Результатом работы этого шага является файл с объединённым промежуточным представлением, содержащий данные из всех единиц трансляции.
Symbol Resolution после оптимизаций. Необходимо сгенерировать новую таблицу символов для объединённого объектного файла. Далее компоновщик продолжает работу в штатном режиме.
Не все представленные этапы LTO необходимы для статического анализа, ведь нам не нужно производить никаких оптимизаций. Было бы достаточно первых двух этапов для сбора информации о символах и осуществлении самого анализа.
Нельзя обойти стороной GCC – второй популярный компилятор для языков C/C++. В нём также представлены оптимизации времени связывания. Однако устроены они немного по-другому.
Первым этапом GCC генерирует для каждого файла своё внутреннее промежуточное представление, называемое GIMPLE. Оно хранится в специальных объектных файлах в формате ELF. По умолчанию, эти файлы содержат только байткод. Но если указать флаг -ffat-lto-objects, то GCC поместит промежуточный код в отдельную секцию рядом с готовым объектным кодом. Это нужно для поддержки линковки без включения LTO. На этом этапе создаётся потоковое представление всех внутренних структур данных, необходимых для оптимизации кода.
Далее GCC второй раз проходится по объектным модулям с уже записанной в них межмодульной информацией и выполняет оптимизации. Затем происходит их связывание в единый объектный файл.
Кроме того, GCC поддерживает режим, называемый WHOPR, в котором связывание объектных файлов происходит по частям на основе графа вызовов. Это позволяет выполнять второй этап распараллеленно и не загружать всю программу в память целиком.
Наша реализация
Главное отличие нашего инструмента PVS-Studio, которое не позволит применить такой же метод, как и у компиляторов, в том, что анализатор не формирует абстрагированное от языкового контекста промежуточное представление. Поэтому, чтобы прочитать символ из другого модуля, необходимо заново выполнить для него трансляцию с построением представления программы в виде структур памяти (дерево разбора, граф потока управления и т. д.). Кроме того, анализ потока данных может потребовать разбор всего графа зависимостей по символам в разных модулях. Такая задача может выполняться слишком долго. Поэтому необходимо как-то сохранить отдельно информацию о символах, собранную в результате семантического анализа (в частности, анализа потока данных) заранее. Такая информация представляется в виде набора фактов для конкретного символа. На основе этой идеи был разработан нижеописанный подход.
Межмодульный анализ выполняется в три этапа:
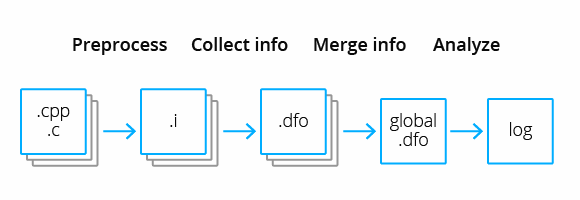
Семантический анализ каждой отдельной единицы трансляции. Анализатор собирает информацию о каждом символе программы, для которого нашлись потенциально интересные факты. После чего эта информация записывается в файлы в специальном формате. Такая обработка может выполняться параллельно, что хорошо для многопоточной сборки.
Слияние символов. На этом этапе анализатор объединяет информацию из разных файлов с фактами в один, попутно решая конфликты между символами. На выходе получаем один файл с необходимой для межмодульного анализа информацией.
Запуск диагностик. Анализатор вновь проходит каждую единицу трансляции. Однако, в отличие от однопроходного режима с выключенным межмодульным анализом, во время выполнения диагностик загружается информация о символах из объединённого файла. Таким образом становится доступной информация о фактах для символов из других модулей.
К сожалению, при такой реализации теряется часть информации. Дело в том, что анализ потока данных может потребовать информацию о зависимостях между модулями для вычисления виртуальных значений (возможных диапазонов/множеств значений). Но это не представляется возможным, так как каждый модуль обходится только один раз. Чтобы решить эту проблему потребуется предварительный анализ вызова функций, как это делает GCC (граф вызовов). Кроме того, эти ограничения создают затруднения при реализации инкрементального межмодульного анализа.
Как попробовать
Режим межмодульного анализа можно запустить на всех трёх платформах, которые мы поддерживаем. Важное уточнение: на текущий момент межмодульный анализ несовместим с режимами запуска анализа на списке файлов и с режимом инкрементального анализа.
Запуск на Linux/macOS
Для анализа проектов под Linux/macOS используется утилита pvs-studio-analyzer. Для включения режима межмодульного анализа достаточно добавить флаг --intermodular к команде pvs-studio-analyzer analyze. В этом случае анализатор сгенерирует отчёт и удалит все временные файлы сам.
Межмодульный анализ также поддерживается в плагинах для IDE. На Linux и macOS он доступен в IDE JetBrains CLion. Для подключения межмодульного анализа достаточно включить соответствующую галочку в настройках плагина.
Важно: если попытаться установить галочку IntermodularAnalysis при включённом инкрементальном анализе, плагин сообщит об ошибке. Кроме того, если запускать анализ на ограниченном списке файлов, а не на всём проекте целиком, то результат будет неполным, о чём в окно с предупреждениями анализатора выведется сообщение V013: "Intermodular analysis may be incomplete, as it is not run on all source files". Также плагин синхронизирует свои настройки с глобальным файлом Settings.xml. Это позволяет иметь одни настройки для всех IDE, в которых интегрирован PVS-Studio. Поэтому сохраняется возможность вручную включить несовместимые настройки в нём. В таком случае плагин при попытке запуска анализа выведет в окно с предупреждениями ошибку "Error: Flags --incremental and --intermodular cannot be used together".
Запуск под Windows
Под Windows анализ можно запустить двумя способами: через консольные утилиты *PVS-Studio_Cmd *и CLMonitor или через плагин.
Для запуска через утилиты PVS-Studio_Cmd / CLMonitor достаточно выставить значение true у тега <IntermodularAnalysisCpp> в конфиге Settings.xml.
Анализ в плагине Visual Studio включается следующей опцией:
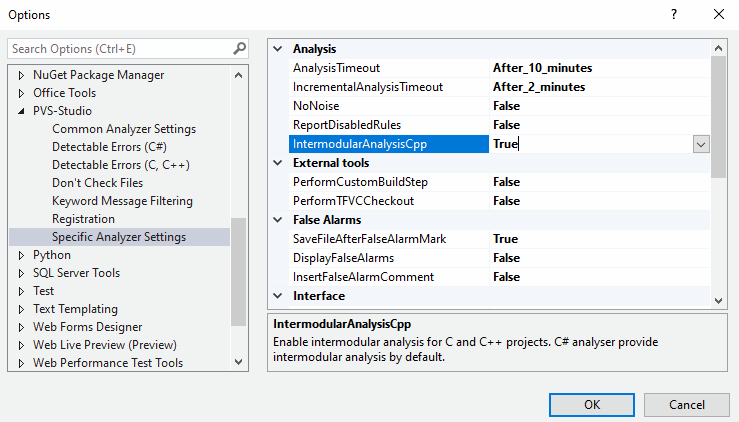
Что удалось найти
Конечно же, после того как межмодульный анализ был реализован, нам стало интересно проверить проекты из нашей тестовой базы и посмотреть на найденные ошибки.
zlib
V522 Dereferencing of the null pointer might take place. The null pointer is passed into '_tr_stored_block' function. Inspect the second argument. Check lines: 'trees.c:873', 'deflate.c:1690'.
// trees.c
void ZLIB_INTERNAL _tr_stored_block(s, buf, stored_len, last)
deflate_state *s;
charf *buf; /* input block */
ulg stored_len; /* length of input block */
int last; /* one if this is the last block for a file */
{
// ....
zmemcpy(s->pending_buf + s->pending, (Bytef *)buf, stored_len); // <=
// ....
}
// deflate.c
local block_state deflate_stored(s, flush)
deflate_state *s;
int flush;
{
....
/* Make a dummy stored block in pending to get the header bytes,
* including any pending bits. This also updates the debugging counts.
*/
last = flush == Z_FINISH && len == left + s->strm->avail_in ? 1 : 0;
_tr_stored_block(s, (char *)0, 0L, last); // <=
....
}
Нулевой указатель (char*)0 попадает в memcpy вторым аргументом через функцию _tr_stored_block. Хоть здесь и нет реальной проблемы (т.к. копируется ноль байт), в стандарте явно сказано, что при вызове функций типа memcpy указатели всегда должны указывать на валидные данные, даже если количество равно нулю. Если это не так, то мы имеем дело с undefined behavior.
Ошибка уже исправлена, но не в релизной версии, а в develop-ветке. Релизов у проекта не было уже 4 года. Изначально ошибка была найдена под санитайзерами.
mc
V774 The 'w' pointer was used after the memory was released. editcmd.c 2258
// editcmd.c
gboolean
edit_close_cmd (WEdit * edit)
{
// ....
Widget *w = WIDGET (edit);
WGroup *g = w->owner;
if (edit->locked != 0)
unlock_file (edit->filename_vpath);
group_remove_widget (w);
widget_destroy (w); // <=
if (edit_widget_is_editor (CONST_WIDGET (g->current->data)))
edit = (WEdit *) (g->current->data);
else
{
edit = find_editor (DIALOG (g));
if (edit != NULL)
widget_select (w); // <=
}
}
// widget-common.c
void
widget_destroy (Widget * w)
{
send_message (w, NULL, MSG_DESTROY, 0, NULL);
g_free (w);
}
void
widget_select (Widget * w)
{
WGroup *g;
if (!widget_get_options (w, WOP_SELECTABLE))
return;
// ....
}
// widget-common.h
static inline gboolean
widget_get_options (const Widget * w, widget_options_t options)
{
return ((w->options & options) == options);
}
Функция widget_destroy освобождает память по указателю, делая его невалидным. Однако после вызова он передаётся в widget_select, откуда попадает в widget_get_options, где и происходит разыменование.
Оригинальный Widget *w берётся из параметра edit, а перед вызовом widget_select происходит вызов find_editor, которая перебивает переданный параметр. Скорее всего, переменная w используется просто для оптимизации и упрощения кода, так что исправленный вызов будет выглядеть как *widget_select(WIDGET(edit))*.
Ошибка присутствует в master-ветке.
codelite
V597 The compiler could delete the 'memset' function call, which is used to flush 'current' object. The memset_s() function should be used to erase the private data. args.c 269
Был интересный случай с удалением вызова memset:
// args.c
extern void eFree (void *const ptr);
extern void argDelete (Arguments* const current)
{
Assert (current != NULL);
if (current->type == ARG_STRING && current->item != NULL)
eFree (current->item);
memset (current, 0, sizeof (Arguments)); // <=
eFree (current); // <=
}
// routines.c
extern void eFree (void *const ptr)
{
Assert (ptr != NULL);
free (ptr);
}
Вызов memset может быть удален при использовании оптимизаций LTO, т. к. компилятор в состоянии разобрать, что eFree не делает никаких полезных вычислений с данными по указателю, а лишь вызывает функцию free, которая освобождает память. Без LTO вызов eFree выглядит как неизвестная внешняя функция, поэтому memset останется.
Заключение
Межмодульный анализ открывает множество ранее недоступных возможностей для анализатора по поиску ошибок в программах на языках C, C++. Теперь анализатор учитывает информацию из всех файлов в проекте — это даёт больше сведений о поведении программы, что позволяет выявлять больше ошибок.
Новый режим можно попробовать уже сейчас. Он доступен, начиная с версии PVS-Studio v7.14, которую можно загрузить с нашего сайта. Обратите внимание, что при запросе триала по приведённой ссылке вы получите расширенную trial лицензию. Если у вас возникнут какие-то вопросы, вы можете написать нам. Надеемся, что этот режим окажется полезным в исправлении ошибок в вашем проекте.
Если хотите поделиться этой статьей с англоязычной аудиторией, то прошу использовать ссылку на перевод: Sergey Larin, Oleg Lisiy. Intermodular analysis of C++ projects in PVS-Studio.
