
![]()
Working with speech recognition models we often encounter misconceptions among potential customers and users (mostly related to the fact that people have a hard time distinguishing substance over form). People also tend to believe that punctuation marks and spaces are somehow obviously present in spoken speech, when in fact real spoken speech and written speech are entirely different beasts.
Of course you can just start each sentence with a capital letter and put a full stop at the end. But it is preferable to have some relatively simple and universal solution for "restoring" punctuation marks and capital letters in sentences that our speech recognition system generates. And it would be really nice if such a system worked with any texts in general.
For this reason, we would like to share a system that:
- Inserts capital letters and basic punctuation marks (dot, comma, hyphen, question mark, exclamation mark, dash for Russian);
- Works for 4 languages (Russian, English, German, Spanish) and can be extended;
- By design is domain agnostic and is not based on any hard-coded rules;
- Has non-trivial metrics and succeeds in the task of improving text readability;
To reiterate — the purpose of such a system is only to improve the readability of the text. It does not add information to the text that did not originally exist.
The problem and the solution
Let's assume that the input is a sentence in lowercase letters without any punctuation, i.e. similar to the outputs of any speech recognition systems. We ideally need a model that makes texts proper, i.e. restores capital letters and punctuation marks. A set of punctuation marks .,—!?- was chosen based on characters most used on average.
Also we embraced the assumption that the model should insert only one symbol after each token (a punctuation mark or a space). This automatically rules out complex punctuation cases (i.e. direct speech). This is an intentional simplification, because the main task is to improve readability as opposed to achieving grammatically ideal text.
The solution had to be universal enough to support several key languages. By design we can easily extend our system to an arbitrary number of languages should need arise.
Initially we envisaged the solution to be small BERT-like model with some classifiers on top. We used internal text corpora for training.
We acquainted ourselves with a solution of a similar problem from here. However, for our purposes we needed:
- A lighter model with a more general specialization;
- An implementation that does not directly use extrnal APIs and a lot of third-party libraries;
As a result, our solution mostly depends only on PyTorch.
Looking for the backbone model
We wanted to use as small pretrained language model as possible. However, a quick search through the list of pretrained models on https://huggingface.co/ did not give inspiring results. In fact there is only one multi-language decently sized model available, which still weighs about 500 megabytes.
Model compression
After extensive experiments we eventually settled on the simplest possible architecture, and the final weight of the model was still 520 megabytes.
So we tried to compress the model. The simplest option is of course quantization (particularly a combination of static and dynamic as described here).
As a result, the model was compressed to around 130 megabytes without significant loss of quality. Also we reduced the redundant vocabulary by throwing out tokens for non-used languages. This allowed us to compress the embedding from 120,000 tokens to 75,000 tokens.
Provided that at that moment the model was smaller than 100 megabytes, we decided against investing time in more sophisticated compression techniques (i.e. dropping less used tokens or model factorization). All of the metrics below are calculated with this small quantized model.
Metrics used
Contrary to the popular trends we aim to provide as detailed, informative and honest metrics as possible. In this particular case, we used the following datasets for validation:
- Validation subsets of our private text corpora (5,000 sentences per language);
- Audiobooks, we use the caito dataset, which has texts in all the languages the model was trained on (20,000 random sentences for each language);
We use the following metrics:
- WER (word error rate) as a percentage: separately calculated for repunctuation
WER_p(both sentences are transformed to lowercase) and for recapitalizationWER_c(here we throw out all punctuation marks); - Precision / recall / F1 to check the quality of classification (i) between the space and the punctuation marks mentioned above
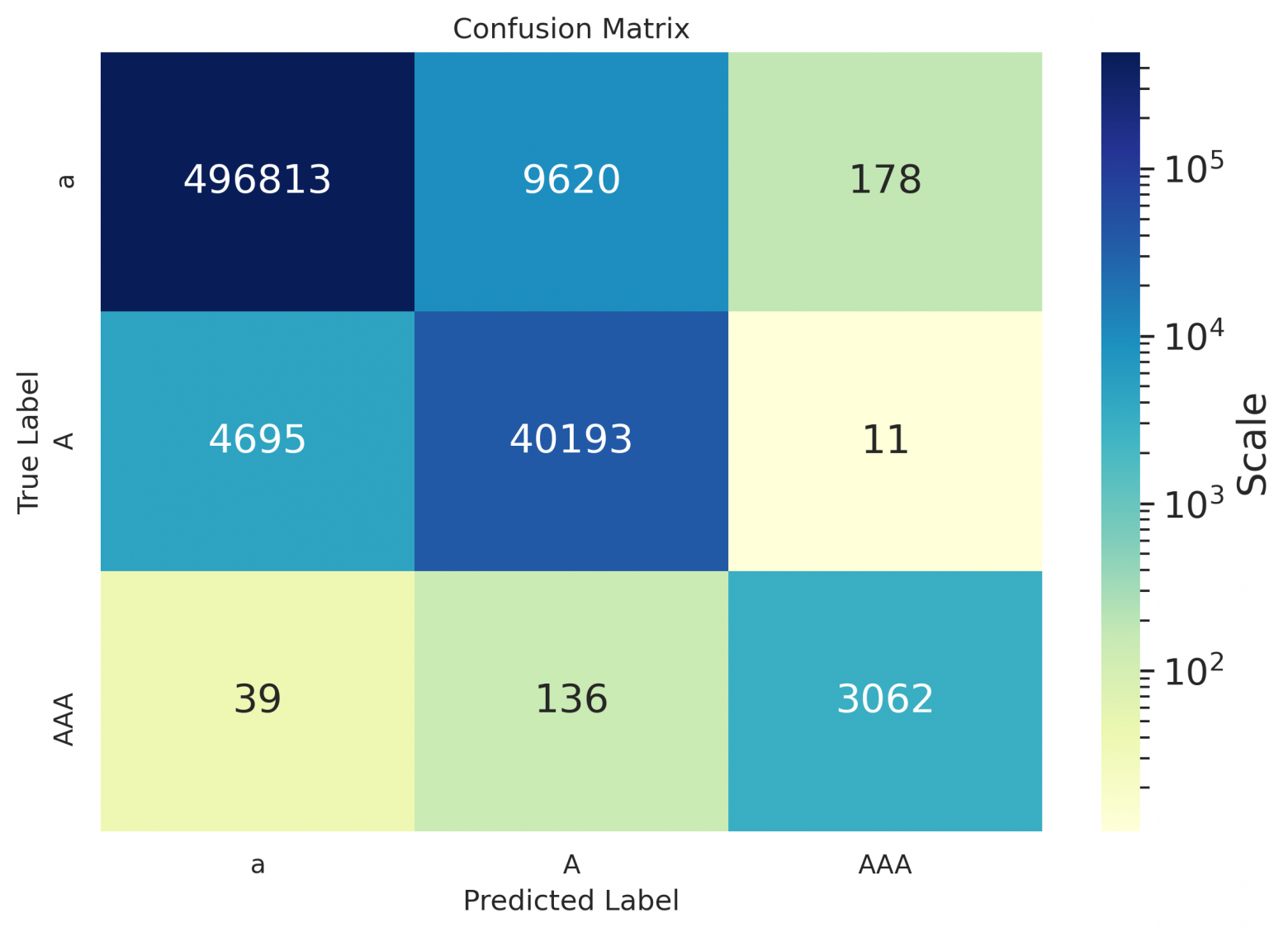
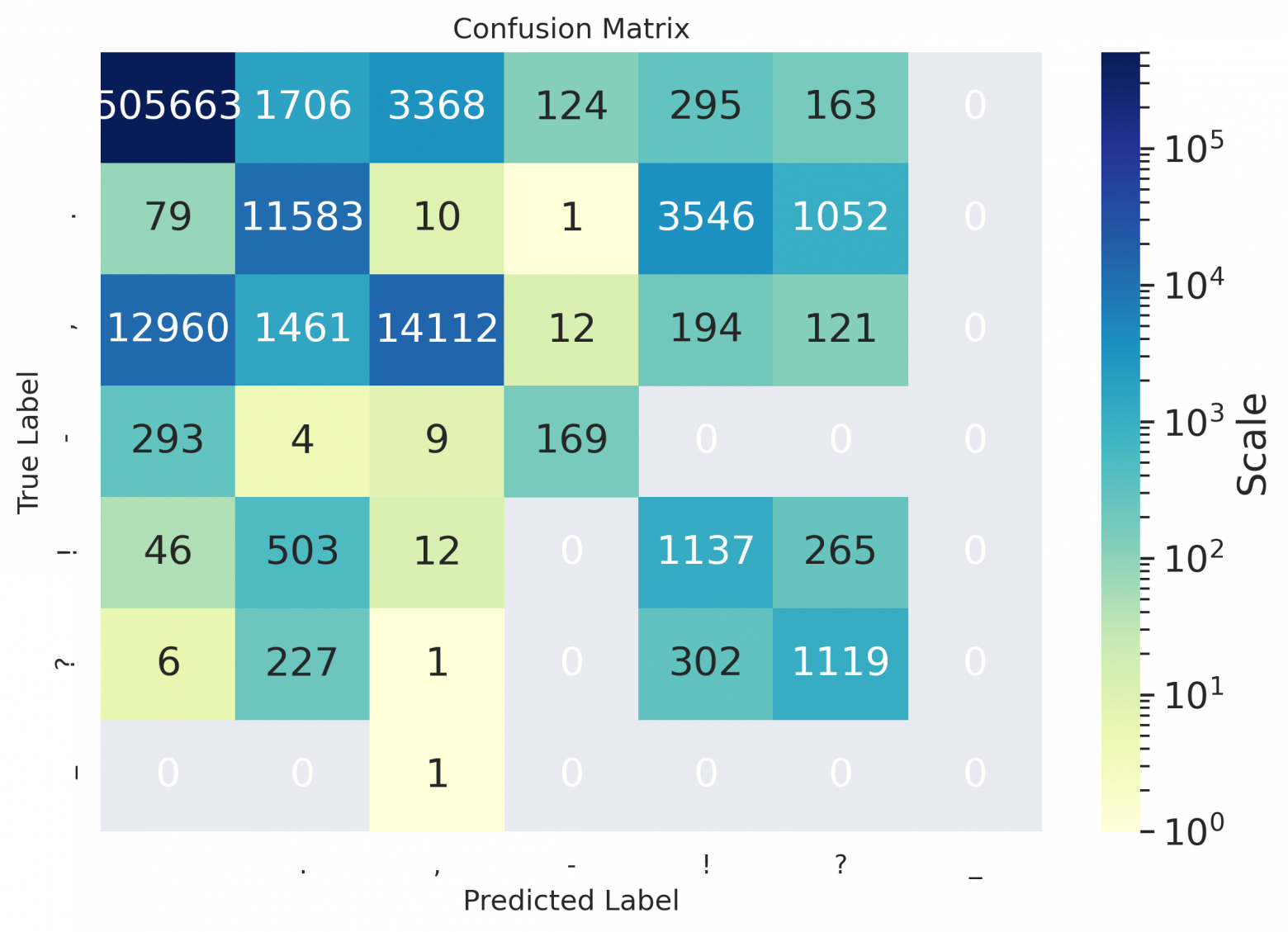
.,-!?-, and (ii) for the restoration of capital letters — between classes a token of lowercase letters / a token starts with a capital / a token of all caps. Also we provide confusion matrices for visualization;
Results
For the correct and informative metrics calculation, the following transformations were applied to the texts beforehand:
- Punctuation characters other than
.,-!?-were removed; - Punctuation at the beginning of a sentence was removed;
- In case of multiple consecutive punctuation marks we keep only the first one;
- For Spanish
¿¡were discarded from the model predictions, because they aren't in the texts of the books, but in general the model places them as well;
WER
WER_p / WER_c are specified in the cells below. The baseline metrics are calculated for a naive algorithm that starts the sentence with a capital letter and ends it with a full stop.
Domain — validation data:
| Languages | ||||
|---|---|---|---|---|
| en | de | ru | es | |
| baseline | 20 / 26 | 13 / 36 | 18 / 17 | 8 / 13 |
| model | 8 / 8 | 7 / 7 | 13 / 6 | 6 / 5 |
Domain — books:
| Languages | ||||
|---|---|---|---|---|
| en | de | ru | es | |
| baseline | 14 / 13 | 13 / 22 | 20 / 11 | 14 / 7 |
| model | 14 / 8 | 11 / 6 | 21 / 7 | 13 / 6 |
Precision / Recall / F1
Domain — validation data:
| Metric | ' ' | . | , | - | ! | ? | — |
|---|---|---|---|---|---|---|---|
| en | |||||||
| precision | 0.98 | 0.97 | 0.78 | 0.91 | 0.80 | 0.89 | nan |
| recall | 0.99 | 0.98 | 0.64 | 0.75 | 0.67 | 0.78 | nan |
| f1 | 0.98 | 0.98 | 0.71 | 0.82 | 0.73 | 0.84 | nan |
| de | |||||||
| precision | 0.98 | 0.98 | 0.86 | 0.81 | 0.74 | 0.90 | nan |
| recall | 0.99 | 0.99 | 0.68 | 0.60 | 0.70 | 0.71 | nan |
| f1 | 0.99 | 0.98 | 0.76 | 0.69 | 0.72 | 0.79 | nan |
| ru | |||||||
| precision | 0.98 | 0.97 | 0.80 | 0.90 | 0.80 | 0.84 | 0 |
| recall | 0.98 | 0.99 | 0.74 | 0.70 | 0.58 | 0.78 | nan |
| f1 | 0.98 | 0.98 | 0.77 | 0.78 | 0.67 | 0.81 | nan |
| es | |||||||
| precision | 0.98 | 0.96 | 0.70 | 0.74 | 0.85 | 0.83 | 0 |
| recall | 0.99 | 0.98 | 0.60 | 0.29 | 0.60 | 0.70 | nan |
| f1 | 0.98 | 0.98 | 0.64 | 0.42 | 0.70 | 0.76 | nan |
| Metric | a | A | AAA |
|---|---|---|---|
| en | |||
| precision | 0.98 | 0.94 | 0.97 |
| recall | 0.99 | 0.91 | 0.70 |
| f1 | 0.98 | 0.92 | 0.81 |
| de | |||
| precision | 0.99 | 0.98 | 0.89 |
| recall | 0.99 | 0.98 | 0.53 |
| f1 | 0.99 | 0.98 | 0.66 |
| ru | |||
| precision | 0.99 | 0.96 | 0.99 |
| recall | 0.99 | 0.92 | 0.99 |
| f1 | 0.99 | 0.94 | 0.99 |
| es | |||
| precision | 0.99 | 0.95 | 0.98 |
| recall | 0.99 | 0.90 | 0.82 |
| f1 | 0.99 | 0.92 | 0.89 |
Domain — books:
| Metric | ' ' | . | , | - | ! | ? | — |
|---|---|---|---|---|---|---|---|
| en | |||||||
| precision | 0.96 | 0.80 | 0.59 | 0.82 | 0.23 | 0.39 | nan |
| recall | 0.99 | 0.73 | 0.23 | 0.13 | 0.58 | 0.85 | 0 |
| f1 | 0.97 | 0.77 | 0.33 | 0.22 | 0.33 | 0.53 | nan |
| de | |||||||
| precision | 0.97 | 0.75 | 0.80 | 0.55 | 0.21 | 0.41 | nan |
| recall | 0.99 | 0.71 | 0.49 | 0.35 | 0.58 | 0.67 | 0 |
| f1 | 0.98 | 0.73 | 0.61 | 0.43 | 0.30 | 0.51 | nan |
| ru | |||||||
| precision | 0.97 | 0.77 | 0.69 | 0.90 | 0.17 | 0.49 | 0 |
| recall | 0.98 | 0.60 | 0.55 | 0.61 | 0.68 | 0.75 | nan |
| f1 | 0.98 | 0.68 | 0.61 | 0.72 | 0.28 | 0.60 | nan |
| es | |||||||
| precision | 0.96 | 0.57 | 0.59 | 0.96 | 0.30 | 0.24 | nan |
| recall | 0.98 | 0.70 | 0.29 | 0.02 | 0.40 | 0.68 | 0 |
| f1 | 0.97 | 0.63 | 0.38 | 0.04 | 0.34 | 0.36 | nan |
| Metric | a | A | AAA |
|---|---|---|---|
| en | |||
| precision | 0.99 | 0.80 | 0.94 |
| recall | 0.98 | 0.89 | 0.95 |
| f1 | 0.98 | 0.85 | 0.94 |
| de | |||
| precision | 0.99 | 0.90 | 0.77 |
| recall | 0.98 | 0.94 | 0.62 |
| f1 | 0.98 | 0.92 | 0.70 |
| ru | |||
| precision | 0.99 | 0.81 | 0.82 |
| recall | 0.99 | 0.87 | 0.96 |
| f1 | 0.99 | 0.84 | 0.89 |
| es | |||
| precision | 0.99 | 0.71 | 0.45 |
| recall | 0.98 | 0.82 | 0.91 |
| f1 | 0.98 | 0.76 | 0.60 |
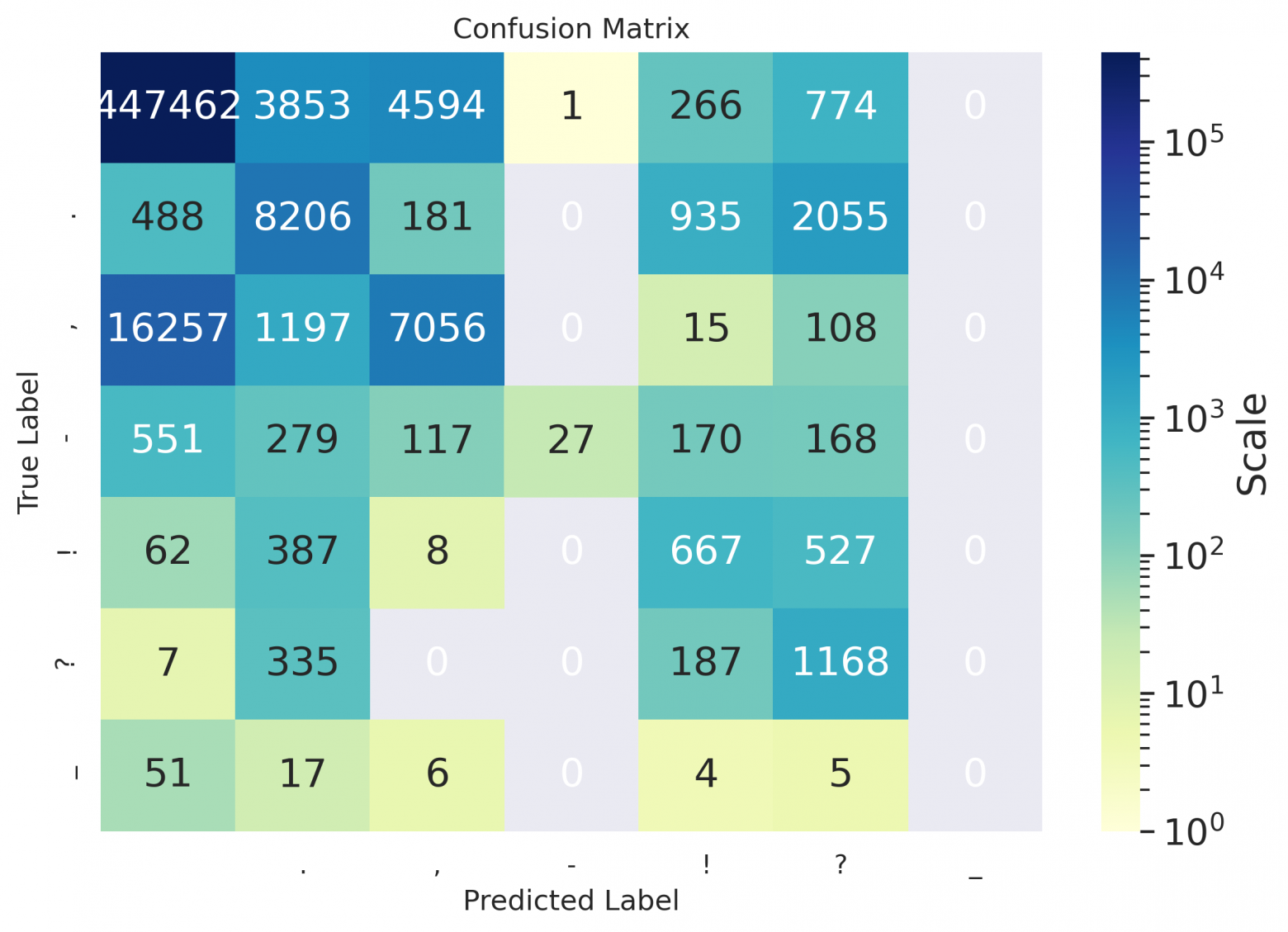
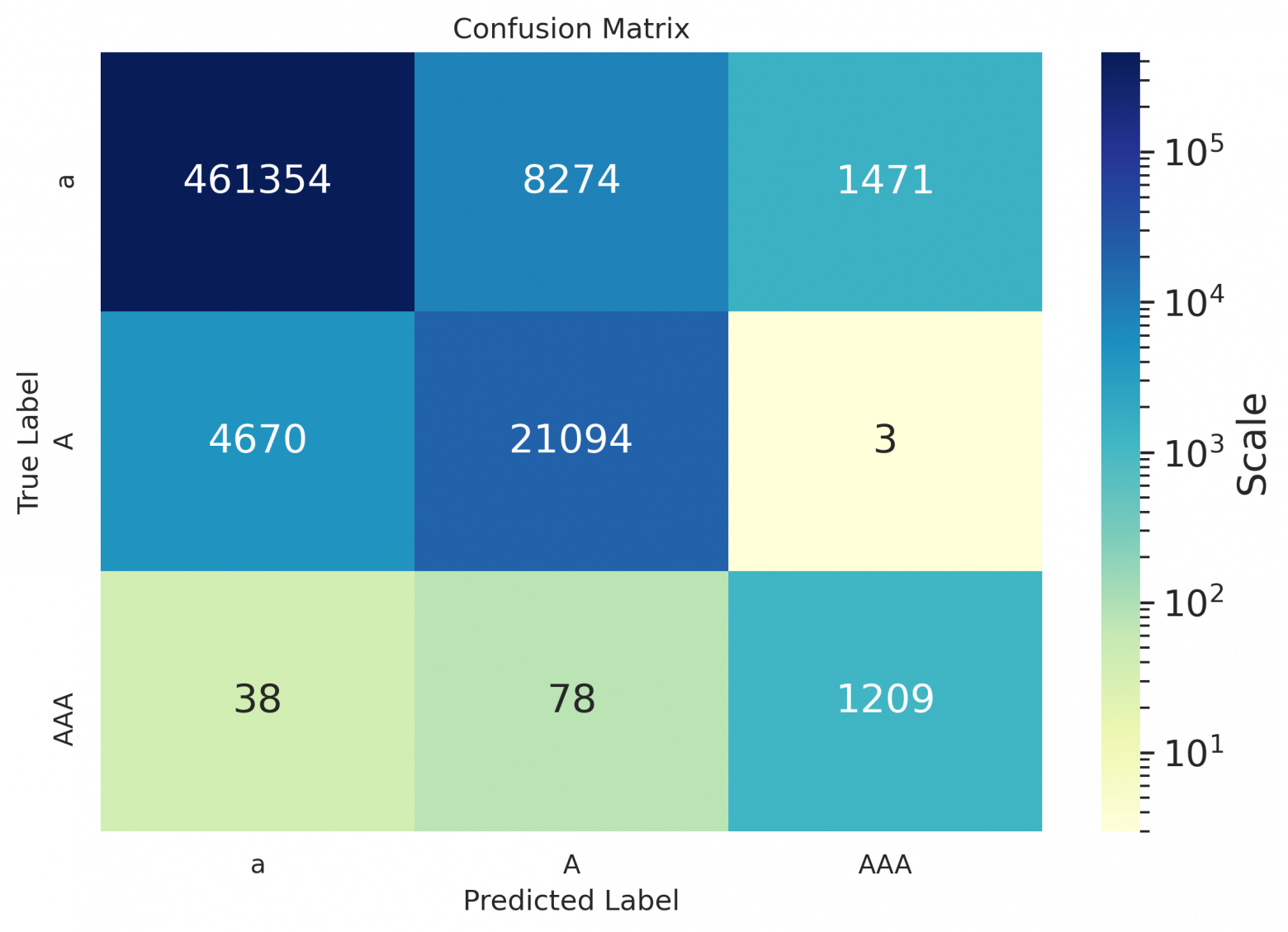
As one can see from the spreadsheets — even for Russian, the hyphen values remained empty, because the model suggested not to put it down at all on the data used for calculating metrics, or to replace the hyphen with some other symbol (as can be seen in the matrices below); seems that it's placed better in case of sentence in the form of definition (see the example at the end of the article).
Other solutions
For reference here are some available F1 metrics for different solutions of similar tasks — for different languages, on different validation datasets. It's not possible to compare them directly, but they can serve as a first order approximations of metrics reported for overfit academic models. The classes in such models are also usually different and more simplified — COMMA, PERIOD, QUESTION:
| Source | COMMA | PERIOD | QUESTION |
|---|---|---|---|
| Paper 1 — en | 76.7 | 88.9 | 87.8 |
| Paper 2 — en | 71.8 | 84.2 | 85.7 |
| Paper 3 — es | 80.2 | 87.0 | 59.7 |
| Repository 4 — fr | 67.9 | 72.9 | 57.6 |
Confusion matrices
Confusion matrices for books:
en

de
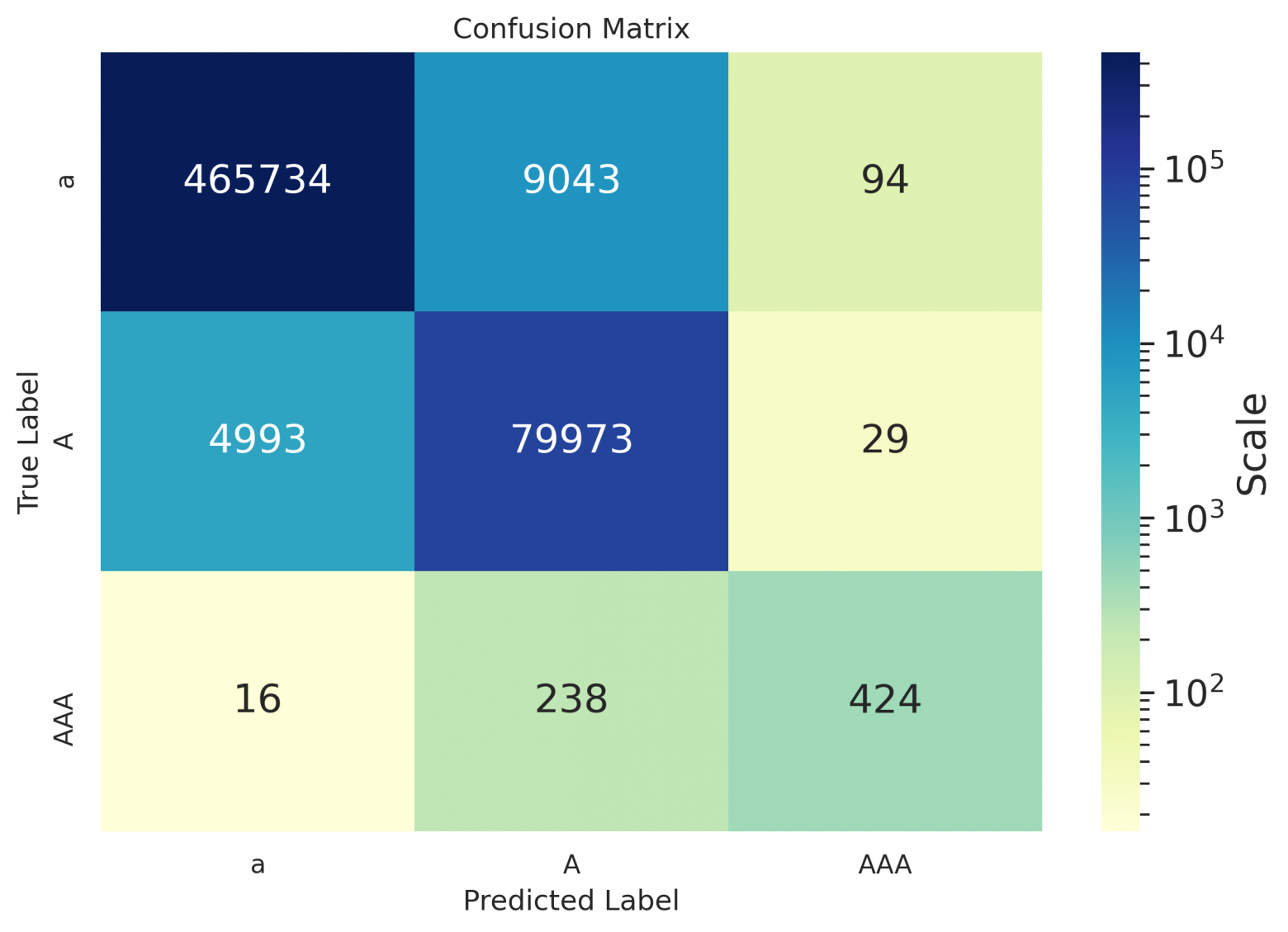
ru
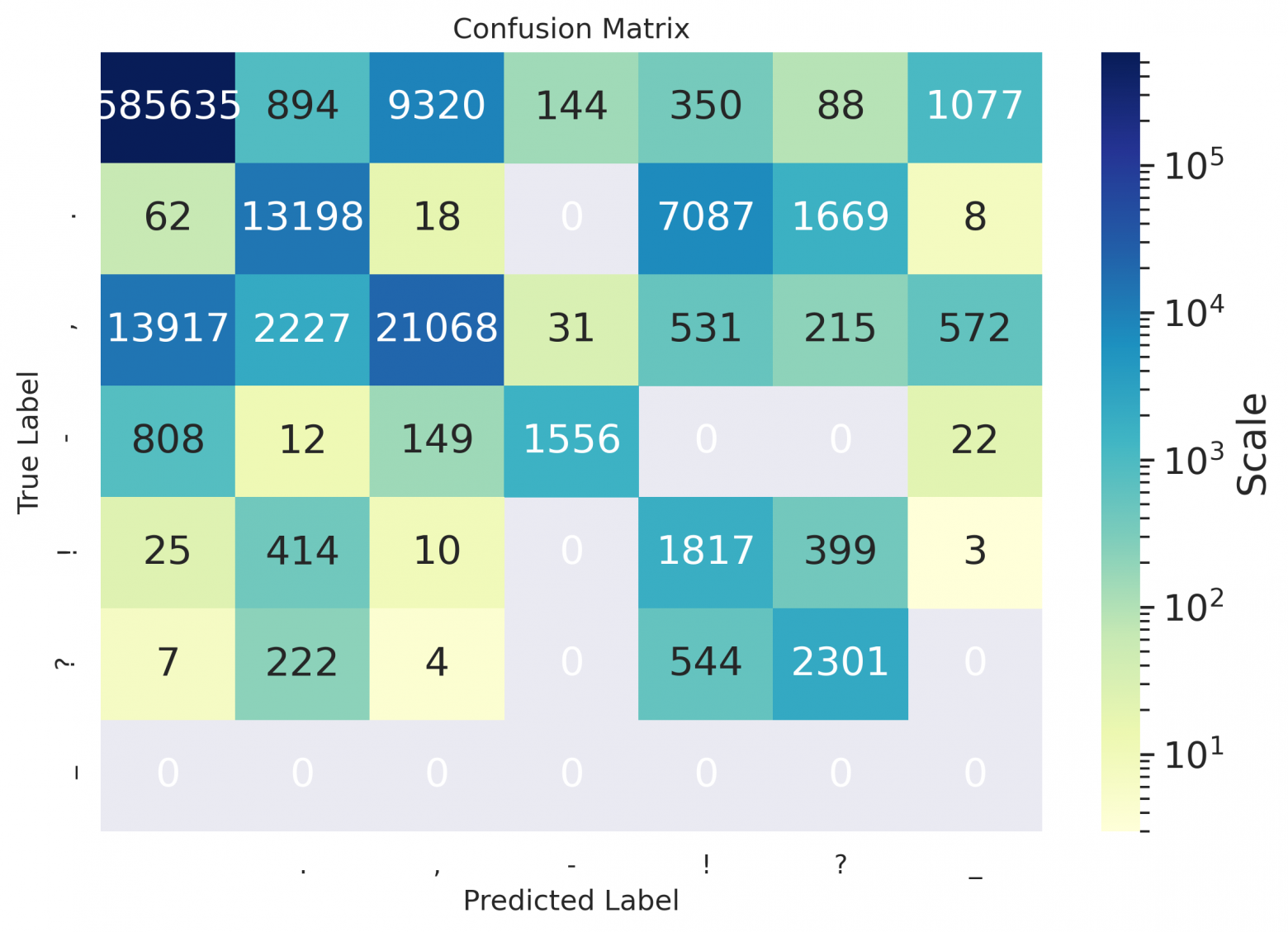
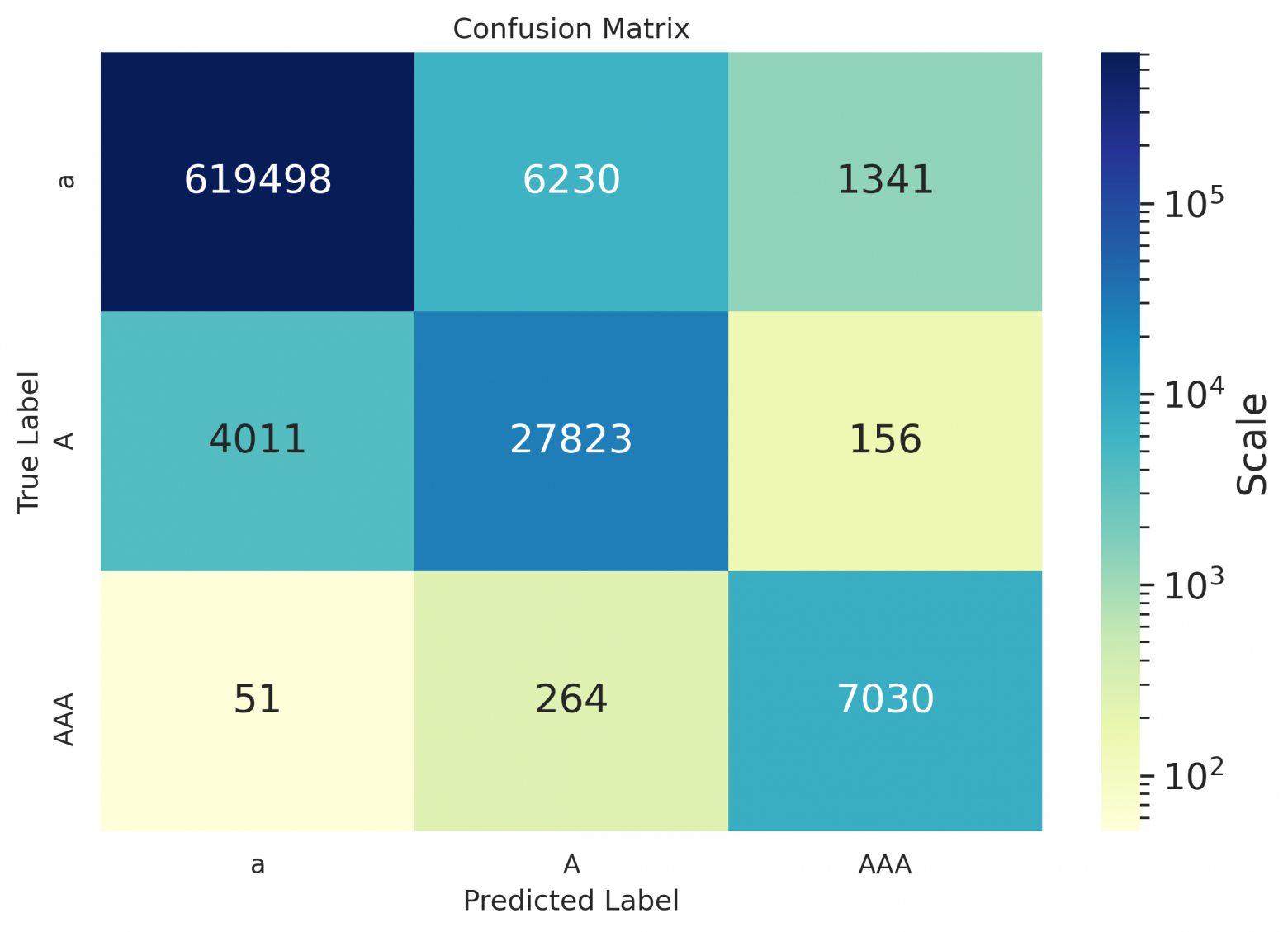
es
Model output examples
| Original | Model |
|---|---|
| She heard Missis Gibson talking on in a sweet monotone, and wished to attend to what she was saying, but the Squires visible annoyance struck sharper on her mind. | She heard Missis Gibson talking on in a sweet monotone and wished to attend to what she was saying, but the squires visible annoyance struck sharper on her mind. |
| Yet she blushed, as if with guilt, when Cynthia, reading her thoughts, said to her one day, Molly, youre very glad to get rid of us, are not you? | Yet she blushed as if with guilt when Cynthia reading her thoughts said to her one day, Molly youre very glad to get rid of us, are not you? |
| And I dont think Lady Harriet took it as such. | And I dont think Lady Harriet took it as such. |
| -- | -- |
| Alles das in begrenztem Kreis, hingestellt wie zum Exempel und Experiment, im Herzen Deutschlands. | Alles das in begrenztem Kreis hingestellt, wie zum Exempel und Experiment im Herzen Deutschlands. |
| Sein Leben nahm die Gestalt an, wie es der Leser zu Beginn dieses Kapitels gesehen hat er verbrachte es im Liegen und im Müßiggang. | Sein Leben nahm die Gestalt an, wie es der Leser zu Beginn dieses Kapitels gesehen hat er verbrachte es im Liegen und im Müßiggang. |
| Die Flußpferde schwammen wütend gegen uns an und suchten uns zu töten. | Die Flußpferde schwammen wütend gegen uns an und suchten uns zu töten. |
| -- | -- |
| Пожалуйста, расскажите все это Бенедикту — послушаем, по крайней мере, что он на это ответит. | Пожалуйста, расскажите все это бенедикту, послушаем, по крайней мере, что он на это ответит. |
| Есть слух, что хороша также работа Пунка, но моя лучше. | Есть слух, что хороша также работа пунка, но моя лучше! |
| После восстания чехословацкого корпуса Россия зажглась от края до края. | После восстания Чехословацкого корпуса Россия зажглась от края до края. |
| -- | -- |
| En seguida se dirigió a cortar la línea por la popa del Trinidad, y como el Bucentauro, durante el fuego, se había estrechado contra este hasta el punto de tocarse los penoles, | En seguida se dirigió a cortar la línea por la popa del Trinidad y como el Bucentauro, durante el fuego se había estrechado contra este hasta el punto de tocarse los penoles. |
| Su propio padre Plutón, sus mismas tartáreas hermanas aborrecen a este monstruo Tantas y tan espantosas caras muda, tantas negras sierpes erizan su cuerpo! | Su propio padre, Plutón, sus mismas tartáreas hermanas, aborrecen a este monstruo tantas y tan espantosas caras muda tantas negras sierpes erizan su cuerpo. |
| Bien es verdad que quiero confesar ahora que, puesto que yo veía con cuán justas causas don Fernando a Luscinda alababa. | Bien, es verdad que quiero confesar ahora que puesto que yo veía con cuán justas causas, don Fernando a Luscinda Alababa? |
How to run it
The model is published in the repository silero-models. And here is a simple snippet for model usage (more detailed examples can be found in colab):
import torch model, example_texts, languages, punct, apply_te = torch.hub.load(repo_or_dir='snakers4/silero-models', model='silero_te') input_text = input('Enter input text\n') apply_te(input_text, lan='en')
Limitations and future work
We had to put a full stop somewhere (pun intended), so the following ideas were left for future work:
- Support inputs consisting of several sentences;
- Try model factorization and pruning (i.e. attention head pruning);
- Add some relevant meta-data from the spoken utterances, i.e. pauses or intonations (or any other embedding);

