
UPD: эта статья была написана до выхода интереснейшего материала о нейросети ruDALL-E. Мы решили всё равно её опубликовать — таким образом у читателей будет возможность сравнить изображения, сгенерированные отечественной и зарубежной сетями. Дальнейший текст публикуется без изменений.

Во времена старого Баша мне запомнилась одна цитата:
Ещё несколько лет назад мы смеялись над психоделическими картинками, где отовсюду торчали глаза или собачьи мордочки. В начале этого года — удивлялись возможностям сети DALL-E от Google, которая по достаточно сложному текстовому запросу создавала изображения, достойные кисти (ну или стилуса) профессионального иллюстратора. Сегодня попробовать в работе сходные по принципу действия сети может любой желающий, но почему-то об этом мало кто знает. Я попытаюсь это исправить при помощи данной статьи, в которой расскажу о своём опыте взаимодействия с нейросетью CLIP Guided Diffusion HQ.
Сразу оговорюсь, что я совершенно не являюсь специалистом по нейросетям. Для тех, кто хочет подробностей, есть замечательный материал за авторством Dirac о том, как работает «половинка» этой сети — CLIP. Моя же статья — не более чем попытка популяризации интересного инструмента, приглашение к творчеству и к размышлениюможет ли робот превратить кусок холста в шедевр искусства. Она написана скорее в развлекательном ключе, а из полезного содержит инструкцию, которая подскажет, как создать свои нейросетевые шедевры буквально в пару кликов.
Для тех, кто не готов читать большую статью по ссылке, кратко скажу, что CLIP (Contrastive Language-Image Pre-Training) — это мультимодальная нейросеть, обученная на 400 миллионах пар «текст-изображение» из интернета. Она предлагает наиболее вероятные подписи, которые могли бы сопровождать ту или иную картинку, причём хорошо справляется и с объектами, которых не было в её обучающей выборке.
Diffusion HQ — это диффузионная модель генерации изображения, реализованная при помощи алгоритма ImageNet. Она поэтапно удаляет шум из «затравочной» картинки, раз за разом делая её чётче и проработаннее. CLIP выступает своего рода критиком для Diffusion HQ, проверяя каждую промежуточную картинку на предмет того, больше или меньше она соответствует входной строке, и корректируя работу генератора в ту или иную сторону. Так за несколько сотен итераций даже из абсолютно случайного набора пикселей получаются детальные изображения.

Типичная затравка. Когда б вы знали, из какого сора…
Самый простой способ попробовать CLIP Guided Diffusion HQ в деле — это Colab-блокнот от Google, подготовленный Кэтрин Кроусон. «Блокнот» в данном случае — готовая среда для выполнения кода на Python. В принципе модель можно запускать и на локальном компьютере, но вам потребуется мощная видеокарта с не менее чем 8 ГБ видеопамяти, а сегодня не все могут похвастаться таким сокровищем. Поэтому проще использовать удалённую виртуальную машину.
Алгоритм действий таков:
1. Зайдите сюда под гугл-аккаунтом.
2. Нажмите «Подключиться» в правом верхнем углу. Скорее всего, вы увидите данные о загруженности виртуальной машины на базе GPU.
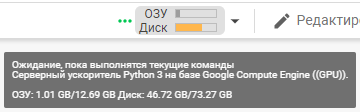
Если вам не повезёт (или если вы до этого злоупотребляли щедростью Google), может появиться сообщение, что доступен только центральный процессор. В этом случае результат работы увидят только ваши внуки.
3. Проверьте, какой именно GPU вам предоставили. Для этого установите курсор на первый блок кода и нажмите Ctrl+Enter, чтобы выполнить его. На экране появится информация о графическом ускорителе виртуальной машины.

Скорее всего, вам достанется Tesla K80, на котором картинка в хорошем качестве считается полчаса–час. Но если повезёт (чаще всего это бывает ночью), можно заполучить и Tesla T4, а это уже означает ускорение почти на порядок плюс некоторые дополнительные возможности, о которых я скажу в конце.
4. Задайте параметры в блоке Settings for this run.
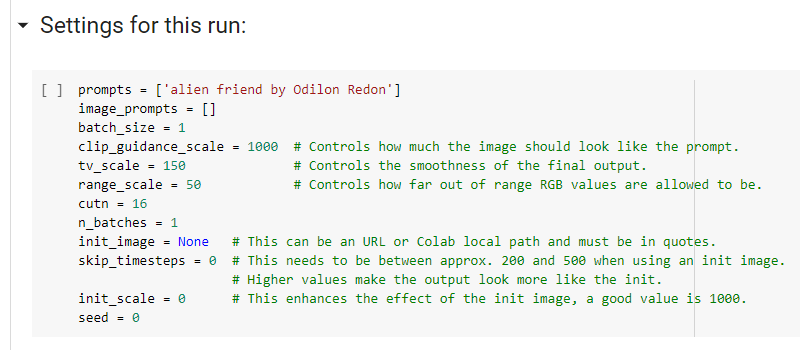
Впишите ваш текстовый запрос в строку prompts, сохраняя скобки и кавычки. Если вы хотите, чтобы нейросеть начала работу не с чистого листа, а с вашей стартовой картинки, вставьте её URL в одинарных кавычках вместо None сюда:
Для первой попытки рекомендую параметры skip_timesteps = 300 и init_scale = 1000.
Количество итераций задаётся в блоке Model settings параметром timestep_respacing. Значение должно быть в одинарных кавычках.
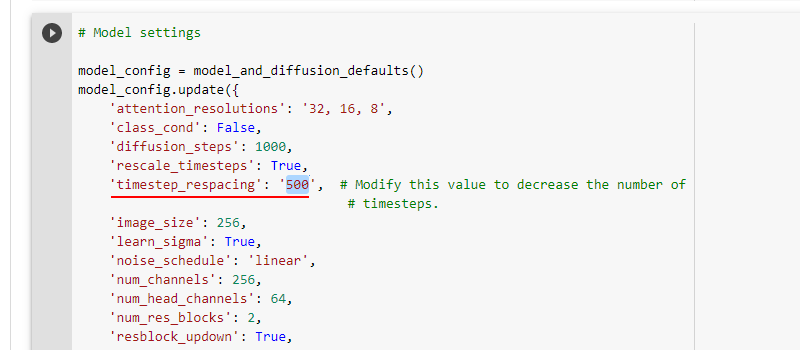
Я бы для начала ставил 500, особенно если вам достался слабый ускоритель. 1000 необходимо для максимальной проработки и звенящей чёткости деталей.
5. Нажмите Ctrl+F9 (ну или Среда выполнения → Выполнить всё). Потребуется время на установку необходимых пакетов и скачивание самой модели, обычно в пределах десяти минут. Далее начнётся собственно процесс расчёта, который отображается прогресс-баром внизу:

Через некоторое время, в зависимости от заданного числа итераций, вы получите изображение размером 256 × 256 пикселей. Негусто, но таковы ограничения используемого датасета и доступной аппаратуры. О том, как можно поднять разрешение, мы ещё поговорим в конце статьи.
6. Чтобы создать новое изображение в рамках той же сессии, не нужно перезапускать весь код. Поставьте курсор на то место, где были изменения (Settings for this run или Model settings), и нажмите Ctrl+F10 (Среда выполнения → Выполнить ниже).
А пока ваши картинки считаются, предлагаю посмотреть, что получилось у меня.
По запросу «Habr» ничего определённого сеть изобразить не смогла. Видимо, картинок с таким текстовым комментарием в её выборке было крайне мало.

Я попытался помочь ей, добавив больше знакомых слов — «Habr community of IT specialists». В результате получилось что-то похожее на небоскрёбы азиатского мегаполиса, на одном из которых при желании можно прочесть надпись «Habr». Вообще я заметил, что когда у CLIP Guided Diffusion HQ не получается что-то хорошо изобразить, она пытается это хотя бы подписать.

С абстрактными пейзажами сеть справляется куда увереннее. Например, вот эту иллюстрацию к циклу «A Song of Ice and Fire» можно хоть сейчас ставить на обложку метал-альбома.

Почти всегда дают хороший результат запросы по мотивам популярных медиафраншиз. Вот, скажем, Mad Max:

В какой-то момент мне стало любопытно, не было ли в обучающей выборке текстов на кириллице. Я сформулировал максимально простой запрос, по которому было бы очевидно, поняла меня сеть или нет, — «синий треугольник». В общем, не повторяйте моих ошибок!

Теперь этот мужик будет являться мне в кошмарах.
Если написать тот же текст латиницей, результат будет не лучше. Хоба!

Значит, про русский язык можно забыть.
По запросу «steampunk» удалось получить затейливые узоры из латунных трубок и клапанов, эдакий Царь-саксофон.

Но в целом с техникой нейросеть не дружит. Сколько раз я ни просил её нарисовать самолёт, паровоз или танк, получалась какая-то ерунда.

Не стоит ждать от неё и понимания того, что именно вы имеете в виду. Скажем, вводя запрос «Heroes III», я был уверен, что получу какую-то вариацию на тему скриншотов из игры. А получил вот что:

Ну, тут смутно угадываются фигуры в доспехах и с оружием… Видимо, это герои. Три штуки!
Любопытные картинки получаются, когда сети попадаются слова с множественными значениями. Скажем, «Red Square» — и «Красная площадь», и «красный квадрат». Нейросеть не могла знать, что именно от неё хотят, поэтому на всякий случай сгенерировала картинку «и нашим, и вашим» — красный квадрат, но со структурой брусчатки.

Немного крипоты по запросу «The Hound of the Baskervilles».

«Это я, сэр Генри. Помоги выбраться из собаки!»
Чудесный триптих удалось получить по запросам «mad [french, german, russian] scientist»:

Так мы узнали, что обязательными атрибутами безумного учёного являются шухер на голове и очки, а далее возможны варианты.
А вот — попытка создать обложку для книги «Снятся ли андроидам электроовцы?». В результате получилось изображение с двумя подключёнными к электросети смартфонами (видимо, на Android), на экранах которых изображены овцы.

— Какие претензии? Андроиды есть? Есть. Овцы есть? Есть. Электрические? Ну так понятно, что не живые! Иди отсюда, кожаный мешок, ты сам не знаешь, чего хочешь!
Нейросеть честно пытается интерпретировать все слова, которые вы включили в запрос, и если ей знакомо что-то похожее, может получиться интересный результат. Нет никаких формальных правил — просто вписывайте туда всё, что придёт в голову. Например, добавляя в запрос by <имя_художника>, можно получать «картины» в его стиле.

Harry Potter by Wassily Kandinsky и Robinson Crusoe by Claude Monet
Если нужен конкретный цвет, это тоже можно указать — скорее всего, сработает. Повторю фрагмент картинки из анонса:

Scientific certainity by Salvador Dali in blue
Остальные иллюстрации оттуда — это «Alchemist by Boris Vallejo», «The thinking ocean of the planet Solaris», «The Picture of Dorian Gray by Giuseppe Arcimboldo», «The Lord of the Rings by Arnold Böcklin» и «Extent of impact of deep-sea nodule mining midwater plumes is influenced by sediment loading, turbulence and thresholds» (это я скормил сети название научной статьи).
Если требуется дорисовать (ну или сделать более наркоманской) существующую картинку, её URL нужно добавить в строку init_image. Параметр skip_timesteps определяет, на сколько итераций нейросеть может уйти в своих фантазиях от предложенного образа, а clip_guidance_scale указывает, как строго его нужно придерживаться.
Хороший результат получается не всегда. Скажем, попытка скрестить образы Бога-Императора и Владимира Путина лишь сделала Императора более недовольным.

Я обещал рассказать, как получить картинки большего размера, чем 256 × 256. Первый и самый простой способ — привлечь для этого другую нейросеть. Задача «увеличить разрешение с сохранением чёткости» куда проще, чем задача «нарисовать картинку по текстовому описанию», так что тут есть из чего выбрать. Предлагаю ознакомиться с обзором и попробовать разные варианты. Есть полностью бесплатные, есть с триальным периодом. Некоторые иллюстрации прямо сильно выигрывают от апскейла.

Что-то по мотивам «Сталкера», не помню точный запрос. Увеличение 4x через deep-image.ai
Ну и, наконец, о дополнительных возможностях, которые дарует ускоритель Tesla T4. У него 16 ГБ памяти, а это значит, что на нём можно запускать продвинутую версию той же нейросети, которая сразу выдаёт картинки размером 512 × 512 пикселей.
***
Как уже было сказано вначале, CLIP — это самостоятельный модуль, который можно сопрягать с различными генераторами. Например, интересные результаты выдаёт спарка CLIP и более классической генеративно-состязательной сети VQGAN. Эта модель не столь требовательна к ресурсам (даже на Tesla K80 можно создавать изображения 512 × 512). Вот как она интерпретировала запрос про андроидов и электроовец:

Создавать и разглядывать картинки можно бесконечно, а статью пора бы и заканчивать. Надеюсь, что, поиграв с нейросетью, вы не только поднимете себе настроение, но и почерпнёте новые идеи для творчества. Например, мой друг, который на досуге пишет фантастическую литературу, всерьёз задумался, не иллюстрировать ли ему при помощи нейросетей свои книги. Делитесь в комментариях интересными картинками, которые у вас получатся!

Во времена старого Баша мне запомнилась одна цитата:
kok:Что ж, если не предъявлять слишком высоких требований к реалистичности результата, можно сказать, что сегодня у нас такие «проги» есть. Речь, конечно же, о нейросетях, которые умеют генерировать практически любые виды контента.
Подскажите какой прогой перегонять книги из txt в mp3
Izzzum:
^^^^^ No Comment а почему сразу не в 3gp или XviD?
kok:
А в каком по твоему формате аудиокниги?
kok:
Или ты думаешь, что какойто дурень сидит и начитывает перед микрофоном?
Ещё несколько лет назад мы смеялись над психоделическими картинками, где отовсюду торчали глаза или собачьи мордочки. В начале этого года — удивлялись возможностям сети DALL-E от Google, которая по достаточно сложному текстовому запросу создавала изображения, достойные кисти (ну или стилуса) профессионального иллюстратора. Сегодня попробовать в работе сходные по принципу действия сети может любой желающий, но почему-то об этом мало кто знает. Я попытаюсь это исправить при помощи данной статьи, в которой расскажу о своём опыте взаимодействия с нейросетью CLIP Guided Diffusion HQ.
Сразу оговорюсь, что я совершенно не являюсь специалистом по нейросетям. Для тех, кто хочет подробностей, есть замечательный материал за авторством Dirac о том, как работает «половинка» этой сети — CLIP. Моя же статья — не более чем попытка популяризации интересного инструмента, приглашение к творчеству и к размышлению
Для тех, кто не готов читать большую статью по ссылке, кратко скажу, что CLIP (Contrastive Language-Image Pre-Training) — это мультимодальная нейросеть, обученная на 400 миллионах пар «текст-изображение» из интернета. Она предлагает наиболее вероятные подписи, которые могли бы сопровождать ту или иную картинку, причём хорошо справляется и с объектами, которых не было в её обучающей выборке.
Diffusion HQ — это диффузионная модель генерации изображения, реализованная при помощи алгоритма ImageNet. Она поэтапно удаляет шум из «затравочной» картинки, раз за разом делая её чётче и проработаннее. CLIP выступает своего рода критиком для Diffusion HQ, проверяя каждую промежуточную картинку на предмет того, больше или меньше она соответствует входной строке, и корректируя работу генератора в ту или иную сторону. Так за несколько сотен итераций даже из абсолютно случайного набора пикселей получаются детальные изображения.
Типичная затравка. Когда б вы знали, из какого сора…
Самый простой способ попробовать CLIP Guided Diffusion HQ в деле — это Colab-блокнот от Google, подготовленный Кэтрин Кроусон. «Блокнот» в данном случае — готовая среда для выполнения кода на Python. В принципе модель можно запускать и на локальном компьютере, но вам потребуется мощная видеокарта с не менее чем 8 ГБ видеопамяти, а сегодня не все могут похвастаться таким сокровищем. Поэтому проще использовать удалённую виртуальную машину.
Алгоритм действий таков:
1. Зайдите сюда под гугл-аккаунтом.
2. Нажмите «Подключиться» в правом верхнем углу. Скорее всего, вы увидите данные о загруженности виртуальной машины на базе GPU.
Если вам не повезёт (или если вы до этого злоупотребляли щедростью Google), может появиться сообщение, что доступен только центральный процессор. В этом случае результат работы увидят только ваши внуки.
3. Проверьте, какой именно GPU вам предоставили. Для этого установите курсор на первый блок кода и нажмите Ctrl+Enter, чтобы выполнить его. На экране появится информация о графическом ускорителе виртуальной машины.
Скорее всего, вам достанется Tesla K80, на котором картинка в хорошем качестве считается полчаса–час. Но если повезёт (чаще всего это бывает ночью), можно заполучить и Tesla T4, а это уже означает ускорение почти на порядок плюс некоторые дополнительные возможности, о которых я скажу в конце.
4. Задайте параметры в блоке Settings for this run.
Впишите ваш текстовый запрос в строку prompts, сохраняя скобки и кавычки. Если вы хотите, чтобы нейросеть начала работу не с чистого листа, а с вашей стартовой картинки, вставьте её URL в одинарных кавычках вместо None сюда:
init_image = NoneДля первой попытки рекомендую параметры skip_timesteps = 300 и init_scale = 1000.
Количество итераций задаётся в блоке Model settings параметром timestep_respacing. Значение должно быть в одинарных кавычках.
Я бы для начала ставил 500, особенно если вам достался слабый ускоритель. 1000 необходимо для максимальной проработки и звенящей чёткости деталей.
5. Нажмите Ctrl+F9 (ну или Среда выполнения → Выполнить всё). Потребуется время на установку необходимых пакетов и скачивание самой модели, обычно в пределах десяти минут. Далее начнётся собственно процесс расчёта, который отображается прогресс-баром внизу:
Через некоторое время, в зависимости от заданного числа итераций, вы получите изображение размером 256 × 256 пикселей. Негусто, но таковы ограничения используемого датасета и доступной аппаратуры. О том, как можно поднять разрешение, мы ещё поговорим в конце статьи.
6. Чтобы создать новое изображение в рамках той же сессии, не нужно перезапускать весь код. Поставьте курсор на то место, где были изменения (Settings for this run или Model settings), и нажмите Ctrl+F10 (Среда выполнения → Выполнить ниже).
А пока ваши картинки считаются, предлагаю посмотреть, что получилось у меня.
По запросу «Habr» ничего определённого сеть изобразить не смогла. Видимо, картинок с таким текстовым комментарием в её выборке было крайне мало.
Я попытался помочь ей, добавив больше знакомых слов — «Habr community of IT specialists». В результате получилось что-то похожее на небоскрёбы азиатского мегаполиса, на одном из которых при желании можно прочесть надпись «Habr». Вообще я заметил, что когда у CLIP Guided Diffusion HQ не получается что-то хорошо изобразить, она пытается это хотя бы подписать.
С абстрактными пейзажами сеть справляется куда увереннее. Например, вот эту иллюстрацию к циклу «A Song of Ice and Fire» можно хоть сейчас ставить на обложку метал-альбома.
Почти всегда дают хороший результат запросы по мотивам популярных медиафраншиз. Вот, скажем, Mad Max:
В какой-то момент мне стало любопытно, не было ли в обучающей выборке текстов на кириллице. Я сформулировал максимально простой запрос, по которому было бы очевидно, поняла меня сеть или нет, — «синий треугольник». В общем, не повторяйте моих ошибок!
Теперь этот мужик будет являться мне в кошмарах.
Если написать тот же текст латиницей, результат будет не лучше. Хоба!
Значит, про русский язык можно забыть.
По запросу «steampunk» удалось получить затейливые узоры из латунных трубок и клапанов, эдакий Царь-саксофон.
Но в целом с техникой нейросеть не дружит. Сколько раз я ни просил её нарисовать самолёт, паровоз или танк, получалась какая-то ерунда.
Не стоит ждать от неё и понимания того, что именно вы имеете в виду. Скажем, вводя запрос «Heroes III», я был уверен, что получу какую-то вариацию на тему скриншотов из игры. А получил вот что:
Ну, тут смутно угадываются фигуры в доспехах и с оружием… Видимо, это герои. Три штуки!
Любопытные картинки получаются, когда сети попадаются слова с множественными значениями. Скажем, «Red Square» — и «Красная площадь», и «красный квадрат». Нейросеть не могла знать, что именно от неё хотят, поэтому на всякий случай сгенерировала картинку «и нашим, и вашим» — красный квадрат, но со структурой брусчатки.
Немного крипоты по запросу «The Hound of the Baskervilles».
«Это я, сэр Генри. Помоги выбраться из собаки!»
Чудесный триптих удалось получить по запросам «mad [french, german, russian] scientist»:
Так мы узнали, что обязательными атрибутами безумного учёного являются шухер на голове и очки, а далее возможны варианты.
А вот — попытка создать обложку для книги «Снятся ли андроидам электроовцы?». В результате получилось изображение с двумя подключёнными к электросети смартфонами (видимо, на Android), на экранах которых изображены овцы.
— Какие претензии? Андроиды есть? Есть. Овцы есть? Есть. Электрические? Ну так понятно, что не живые! Иди отсюда, кожаный мешок, ты сам не знаешь, чего хочешь!
Нейросеть честно пытается интерпретировать все слова, которые вы включили в запрос, и если ей знакомо что-то похожее, может получиться интересный результат. Нет никаких формальных правил — просто вписывайте туда всё, что придёт в голову. Например, добавляя в запрос by <имя_художника>, можно получать «картины» в его стиле.
Harry Potter by Wassily Kandinsky и Robinson Crusoe by Claude Monet
Если нужен конкретный цвет, это тоже можно указать — скорее всего, сработает. Повторю фрагмент картинки из анонса:
Scientific certainity by Salvador Dali in blue
Остальные иллюстрации оттуда — это «Alchemist by Boris Vallejo», «The thinking ocean of the planet Solaris», «The Picture of Dorian Gray by Giuseppe Arcimboldo», «The Lord of the Rings by Arnold Böcklin» и «Extent of impact of deep-sea nodule mining midwater plumes is influenced by sediment loading, turbulence and thresholds» (это я скормил сети название научной статьи).
Если требуется дорисовать (ну или сделать более наркоманской) существующую картинку, её URL нужно добавить в строку init_image. Параметр skip_timesteps определяет, на сколько итераций нейросеть может уйти в своих фантазиях от предложенного образа, а clip_guidance_scale указывает, как строго его нужно придерживаться.
Хороший результат получается не всегда. Скажем, попытка скрестить образы Бога-Императора и Владимира Путина лишь сделала Императора более недовольным.
Я обещал рассказать, как получить картинки большего размера, чем 256 × 256. Первый и самый простой способ — привлечь для этого другую нейросеть. Задача «увеличить разрешение с сохранением чёткости» куда проще, чем задача «нарисовать картинку по текстовому описанию», так что тут есть из чего выбрать. Предлагаю ознакомиться с обзором и попробовать разные варианты. Есть полностью бесплатные, есть с триальным периодом. Некоторые иллюстрации прямо сильно выигрывают от апскейла.
Что-то по мотивам «Сталкера», не помню точный запрос. Увеличение 4x через deep-image.ai
Ну и, наконец, о дополнительных возможностях, которые дарует ускоритель Tesla T4. У него 16 ГБ памяти, а это значит, что на нём можно запускать продвинутую версию той же нейросети, которая сразу выдаёт картинки размером 512 × 512 пикселей.
***
Как уже было сказано вначале, CLIP — это самостоятельный модуль, который можно сопрягать с различными генераторами. Например, интересные результаты выдаёт спарка CLIP и более классической генеративно-состязательной сети VQGAN. Эта модель не столь требовательна к ресурсам (даже на Tesla K80 можно создавать изображения 512 × 512). Вот как она интерпретировала запрос про андроидов и электроовец:
Создавать и разглядывать картинки можно бесконечно, а статью пора бы и заканчивать. Надеюсь, что, поиграв с нейросетью, вы не только поднимете себе настроение, но и почерпнёте новые идеи для творчества. Например, мой друг, который на досуге пишет фантастическую литературу, всерьёз задумался, не иллюстрировать ли ему при помощи нейросетей свои книги. Делитесь в комментариях интересными картинками, которые у вас получатся!
