

Это руководство предназначено для тех, кто только начинает изучение Си и хочет получить ценный опыт в области низкоуровневого программирования, а также понять внутреннее устройство виртуальных машин. К завершению статьи у нас будет рабочая регистровая виртуальная машина, способная интерпретировать и выполнять ограниченный набор инструкций ASM, плюс несколько дополнительных программ для тестирования ее работоспособности.
Код мы будем писать на С11, и он наверняка скомпилируется на большинстве операционных систем. Репозиторий проекта можно найти здесь, а сам исходный код находится в
vm.c:git clone git@github.com:nomemory/lc3-vm.git
Если же вы являетесь опытным Си-разработчиком, и подобные вещи для вас не новы, то можете не тратить время на чтение, так как вся эта информация вам наверняка уже знакома.
Тем же, кто готов попрактиковаться, потребуются знания побитовых операций, шестнадцатеричной записи, указателей, функций указателей, макросов Си, а также некоторых функций из стандартной библиотеки (например,
fwrite и fread).Было бы нечестно оставить без упоминания уже существующие посты, описывающие аналогичные темы. Лучшим среди них я нахожу Write your own Virtual Machine Джастина Мейерса и Райана Пендлтона. Их код демонстрирует более углубленную реализацию виртуальной машины. Если сравнивать мою статью с их, то она немного проще, и код реализуется здесь несколько иным путем.
Содержание
- Виртуальные машины
- Модель фон Неймана
- Реализация виртуальной машины:
- Основная память
- Регистры
- Инструкции:
- add – сложение двух значений
- and – побитовое логическое «И»
- ld — загрузка в RPC + смещение
- ldi – косвенная загрузка
- ldr – загрузка в базу + смещение
- lea – загрузка действительного адреса
- not – побитовое дополнение
- st — сохранение
- sti – косвенное сохранение
- str – сохранение в базу + смещение
- jmp — переход
- jsr – переход к подпрограммам
- br – условное ветвление
- trap:
- tgetc
- toutc
- tputs
- tin
- thalt
- tinu16
- toutu16
Загрузка и выполнение программ:
- Наша первая программа
- Выполнение первой программы
- Заключение
- Ссылки на сообщества
Виртуальные машины
В мире вычислений термин VM (виртуальная машина) относится к системе, которая эмулирует/виртуализирует систему/архитектуру компьютера.
Если говорить в общем, то виртуальные машины разделяются на две категории:
- Системные, которые обеспечивают полноценную альтернативу реальной машины. Они реализуют достаточно функциональности для выполнения операционных систем, а также способны пользоваться и управлять общим оборудованием. При этом иногда на одной физической машине, не мешая друг другу, способны уживаться несколько сред.
- Процессные. Такие машины уже проще системных и предназначены для выполнения компьютерных программ в безразличной к платформе среде. В качестве удачного примера можно назвать JVM.
В этой статье мы займемся разработкой именно процессной виртуальной машины.Основана она будет на архитектуре LC-3 и сможет интерпретировать, а также выполнять подвид ассемблерного кода LC3.
LC-3, он же Little Computer 3, это вид обучающего языка программирования, а именно низкоуровневого ассемблера. Он снабжен относительно простым набором инструкций, но также может быть использован для написания среднесложных программ ассемблера и является допустимой целью для компилятора Си.
Этот язык менее сложен, чем x86 ассемблер, но обладает множеством возможностей, перекликающимися с более сложными языками. Эти возможности делают его пригодным для начинающих, в связи с чем он нередко используется для обучения основам программирования и знакомства с компьютерными архитектурами.
С целью упрощения мы намеренно избавили нашу реализацию LC-3 от: обработки прерываний, уровней приоритетности, процессов, регистров состояний (
PSR), режимов привилегий, стека супервизора и пользовательского стека. Мы виртуализируем только самое основное оборудование и будем взаимодействовать с внешним миром (stdin, stdout) через traps.Модель фон Неймана
Основана наша VM, как и большинство компьютеров общего назначения, на модели фон Неймана и состоять будет из трех фундаментальных компонентов: ЦПУ, основной памяти и устройств ввода/вывода.

ЦПУ, или центральное процессорное устройство, является «схемой, отвечающей за контроль и управление данными». Более того, ЦПУ подразделяется на три уровня: АЛУ, УУ и регистры.
- АЛУ расшифровывается как арифметико-логическое устройство и представляет из себя электрические схемы, которые фактически выполняют инструкции для данных (операции вроде
ADD,XOR, деление и т.д.). - УУ, или управляющее устройство, координирует действия ЦПУ.
- Регистры же являются слотами быстрого доступа, расположенными на уровне ЦПУ. АЛУ работает с регистрами, которых, как правило, присутствует немного (хотя это относительное утверждение, так как количество зависит от архитектуры), поэтому загружать в ЦПУ можно лишь небольшой объем данных.
С помощью регистров мы взаимодействуем с основной памятью. Типичный сценарий подразумевает загрузку области памяти в регистр, выполнение нужных изменений и помещение данных обратно в память.
Основная память представляется как обширный «массив»
w слов из Nбит каждое. Программные инструкции и связанные данные хранятся в основной памяти в двоичном формате. Каждое слово в памяти содержит либо одну инструкцию, либо данные программы (например, число, используемое для вычисления).Устройства ввода/вывода позволяют компьютеру взаимодействовать с внешним миром.
Реализация VM
Наша VM будет функционировать так:
- загружаем программу в основную память;
- в регистре
RPCсохраняем текущую инструкцию, которую нужно выполнить; - получаем операционный код (первые 4 бита) из этой инструкции и исходя из него декодируем остальные параметры;
- выполняем метод, связанный с данной инструкцией;
- инкрементируем
RPCи переходим к следующей инструкции.
Основная память
У нашей машины
W=UINT16_MAX слов, каждое из N=16 бит. С позиции Си в этом случае память можно определить так:uint16_t PC_START = 0x3000; uint16_t mem[UINT16_MAX] = {0};
UINT16_MAX – это максимальный размер uint16_t (16-битное беззнаковое целое), UINT16_MAX=65535. Поэтому, если говорить о перспективе, то наша система довольно ограничена и не сможет выполнять/загружать программы с более, чем 65535 инструкциями. Понимаю, что для нынешних времен это звучит очень ограниченно, но компьютеры далекого прошлого были куда скромнее. Так что, 65535 – это более, чем достаточно для написания нескольких ASCII игрушек и их сохранения в памяти.По общему правилу нам следует начинать загрузку программ в основную память с адреса
0х3000. Слоты памяти вплоть до этого адреса мы оставляем в резерве для других потенциальных компонентов, например простенькой ОС. Но у кого вообще есть время на все это?На данном этапе будет удачной идеей написать пару инструкций для считывания
(mr(...)) и записи (mw(...)) в основную память:static inline uint16_t mr(uint16_t address) { return mem[address]; } static inline void mw(uint16_t address, uint16_t val) { mem[address] = val; }
Даже, если подобная реализация mr и mw выглядит излишней (ведь можно обращаться к памяти напрямую), в будущем нам может потребоваться добавить дополнительную логику или ввести проверки, так что будет правильным оставить эту функциональность изолированной.
Регистры
Всего у нашей VM 10 регистров, по 16 бит каждый:
R0является регистром общего назначения. Мы будем также использовать его для считывания/записи данных из/вstdin/stdout;R1, R2,..R7тоже являются регистрами общего назначения;RPC– это регистр счетчика программы. Он содержит адрес памяти следующей инструкции, которую мы собираемся выполнять.RCNDявляется условным регистром. Условный флаг дает нам информацию о предыдущей операции, выполненной в ЦПУ на уровне АЛУ.
В коде реализовать все эти регистры можно так:
enum regist { R0 = 0, R1, R2, R3, R4, R5, R6, R7, RPC, RCND, RCNT }; uint16_t reg[RCNT] = {0};
Для обращения к регистру мы просто используем
reg[R3]=....Инструкции
Инструкцию можно считать командой, которую мы отдаем виртуальной машине.
С помощью них мы просим ее выполнить простую (и детальную) задачу: считать символ с клавиатуры, сложить два числа, выполнить двоичное «И» для регистра и т.д.
Инструкции имеют тот же размер слова в памяти, что и регистры, то есть 16 бит. Это естественный выбор, ведь мы храним инструкции загруженными в основную память. Значит, с точки зрения Си, они являются беззнаковыми целыми
uint16_t.Наша VM поддерживает лишь ограниченный набор инструкций: 16 (на деле даже 14, поскольку две инструкции LC-3 смысла реализовывать не было).
Что касается их формата, то инструкции обычно кодируются так (внутри
uint16_t):
Первые 4 бита всегда представляют опкод инструкции. Затем, в зависимости от инструкции, идут 1, 2, 3, … параметра, закодированных в оставшихся 12 битах.
На основе опкода можно определить инструкцию и понять, как «декодировать»/«извлечь» остальные параметры из
uint16_t.Для извлечения самого опкода можно написать макрос, применяющий простое побитовое действие:
#define OPC(i) ((i)>>12)
Мы сдвигаем 12 бит вправо (
i>>12), чтобы получить 4 главных бита с опкодом:
Поскольку опкоды представлены в 4 битах, мы можем закодировать не более 16 инструкций (
2^4=16).В Си можно проделать интересный трюк (с точки зрения моделирования данных) – сохранить все возможные инструкции (и связанные с ними функции Си) в массиве. Его индекс будет представлять фактический опкод (ведь опкоды – это числа от 0 до 16), а значение будет указателем на соответствующую функцию Си.
#define NOPS (16) // количество инструкций typedef void (*op_ex_f)(uint16_t instruction); // // ... другие операции // static inline void add(uint16_t i) { /* код */ } static inline void and(uint16_t i) { /* код */ } // // ... другие операции // op_ex_f op_ex[NOPS] = { br, add, ld, st, jsr, and, ldr, str, rti, not, ldi, sti, jmp, res, lea, trap };
typedef void (*op_ex_f)(uint16_t i); — это typedef для указателя функции, который возвращает void и получает один параметр, фактическую uint16_t instruction.Теперь, если мы знаем опкод, то нам доступны все инструкции:
uint16_t instr = ...; op_ex[OP(instr)](instr); // эта инструкция выполнит операцию, связанную с OP(instr) // К примеру, если OP(instr)==0b0001, то мы выполним add(instr) // если же OP(instr)==0b0010, тогда выполним ld(instr) // (и так далее)
С помощью этого простого приема можно обойтись без написания
switch с 16(+1) cases.Теперь посмотрим, какие инструкции поддерживает наша VM. Как я уже говорил, я не стал оригинальничать и писать собственный ASM, а просто скопировал инструкции из спецификации LC-3.
| Инструкция | Hex-опкод | Двоичный опкод | Функция Си | Описание |
| br | 0x0 | 0b0000 | void br(uint16_t i) | Условное ответвление |
| add | 0x1 | 0b0001 | void add(uint16_t i) | Используется для сложения |
| ld | 0x2 | 0b0010 | void ld(uint16_t i) | Загрузка из RPC + смещение |
| st | 0x3 | 0b0011 | void st(uint16_t i) | Сохранение |
| jsr | 0x4 | 0b0100 | void jsr(uint16_t i) | Переход к подпрограмме |
| and | 0x5 | 0b0101 | void and(uint16_t i) | Побитовое логическое «И» |
| ldr | 0x6 | 0b0110 | void ldr(uint16_t i) | Загрузка из основы + смещение |
| str | 0x7 | 0b0111 | void str(uint16_t i) | Сохранение в основу + смещение |
| rti | 0x8 | 0b1000 | void rti(uint16_t i) | Возвращение из прерывания (не реализовано) |
| not | 0x9 | 0b1001 | void not(uint16_t i) | Побитовое дополнение |
| ldi | 0xA | 0b1010 | void ldi(uint16_t i) | Косвенная загрузка |
| sti | 0xB | 0b1011 | void sti(uint16_t i) | Косвенное сохранение |
| jmp | 0xC | 0b1100 | void jmp(uint16_t i) | Переход к/возвращение из подпрограммы |
| 0xD | 0b1101 | Неиспользуемый опкод | ||
| lea | 0xE | 0b1110 | void lea(uint16_t i) | Загрузка фактического адреса |
| trap | 0xF | 0b1111 | void trap(uint16_t i) | Системное прерывание/вызов |
Эти инструкции можно сгруппировать по 4 основным категориям, ориентируясь на их последовательность:
br,jmp,jsrиспользуются для реализации потока управления программ: перехода между инструкциями (аналогично инструкцииgo to) или условного перехода (аналогично условиюif);ld,ldr,ldi,leaиспользуются для загрузки данных из основной памяти в регистры;st,str,stiиспользуются для сохранения данных из регистров обратно в основную память;add,and,notвыполняют (математические) операции над данными в регистрах.
trap – это особая инструкция, которая позволит нам взаимодействовать с клавиатурой (считывать символы) и выводить информацию в stdout.Как вы заметите, наша VM не будет богата на функциональность в плане математических операций. Например, в ней не будет
XOR, деления или умножения. Хорошо в этом то, что мы сможем реализовать их в качестве упражнения, чтобы получше изучить ASM. Это будет непросто, но вполне возможно и послужит хорошей практикой.Но прежде, чем переходить к реализации каждой инструкции, нужно отметить, что некоторые операции оказывают на регистры дополнительные «побочные эффекты».
RCND, также известный как условный регистр флагов, используется для «отслеживания» дополнительной информации некоторых инструкций. В нашей реализации он может иметь всего три значения:1<<0(P) – если последняя операция дала положительный результат;1<<1(Z) – если последняя операция дала 0;1<<2(N) – если последняя операция дала отрицательный результат.
С помощью
RCND мы реализуем ветвление. К примеру, нам нужно понимать, больше ли число a числа b. Для этого можно вычислить их разность, и если она окажется отрицательной, то RCND будет 1<<2. Затем можно использовать инструкцию br для перехода к очередной инструкции. Это будет аналогично применению IF в высокоуровневых языках. В виде кода реализация описанного процесса в Си будет выглядеть так:
enum flags { FP = 1 << 0, FZ = 1 << 1, FN = 1 << 2 }; static inline void uf(enum regist r) { if (reg[r]==0) reg[RCND] = FZ; // значение в r равно нулю else if (reg[r]>>15) reg[RCND] = FN; // значение в r – это отрицательное число else reg[RCND] = FP; // значение в r – это положительное число }
Мы вызываем
uf(r) после каждой операции, имеющей «побочные эффекты», на предмет которых нужно выполнить проверку.Если вы не знакомы с побитовыми операциями, то вам может быть непонятно, что за магия здесь происходит:
else if (reg[r]>>15).Наша VM поддерживает отрицательные числа (пусть вас не сбивает с толку тот факт, что в качестве внутреннего типа памяти мы использовали
uint16_t). По соглашению старший бит отрицательных чисел (располагающийся в позиции 15) представлен 1.
add — сложение двух значений
Наличие возможности сложения двух чисел для создаваемой нами VM очень важно. Для ее реализации мы определим две инструкции
add. Они обе будут иметь одинаковый опкод, но остальная часть кодировки в них будет отличаться. bit[5] сообщает нам, какую версию инструкции add мы выбираем.Первая (
add1) используется для сложения значений двух регистров, а именно SR1, SR2 и сохранения результата в DR1:
Вторая версия,
add2, используется для сложения «константного» значения (IMM5) с SR1 и сохранения результата в DR1: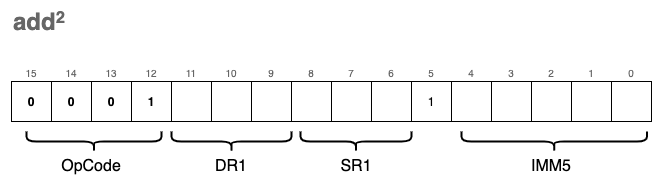
Примечание:DRозначает Destination Register (целевой регистр),SRозначает Source Register (исходный регистр).
IMM5 – это положительное или отрицательное число из 5 бит, старший из которых является знаковым. При написании кода нам необходимо это учитывать, поэтому мы напишем функцию, расширяющую знак, делая число совместимым с 16-битным форматом.#define SEXTIMM(i) sext(IMM(i),5) static inline uint16_t sext(uint16_t n, int b) { return ((n>>(b-1))&1) ? // если b-й бит n равен 1 (число отрицательно), (n|(0xFFFF << b)) : n; // заполняем оставшиеся 15 бит 1-ми. // В противном случае возвращаем число как есть }
Наглядно принцип действия
SEXTIMM(i) можно представить так (если число отрицательно):
Если же число положительно, то никаких изменений над ним производить не требуется.
Например, выполнение следующего кода выдаст верный результат:
uint16_t a = 0x16; // 5-й бит равен 1 // это означает, что число, содержащееся в оставшихся 5 битах отрицательно // Значит, важно правильно сохранить его в типе uint16_t // Для этого мы применяем SEXTIMM(a) fprintf_binary(stdout, a); fprintf(stdout, "\n"); fprintf_binary(stdout, SEXTIMM(a)); fprintf(stdout, "\n"); // Вывод // // 0000 0000 0001 0110 <--- a в двоичном виде // 1111 1111 1111 0110 <--- SEXTIMM(a) в двоичном виде
Теперь вернемся к нашим функциям
add.В Си можно сгруппировать их внутри одного метода, проверяющего, является ли
bit[5] 0 или 1, чтобы принять решение о дальнейшем декодировании.Если
bit[5] равен 0, мы реализуем add1. В противном случае add2.Для получения 5-го бита инструкции мы определяем макрос:
// Получаем 5-й бит i // Сдвигаемся вправо на 5 бит, чтобы получить бит из последней позиции #define FIMM(i) ((i>>5)&1)
Если представить наглядно, то
FIMM работает так:- сдвигает
iвправо на 5 бит; - получает последний бит с помощью
&1.

А вот остальные полезные макросы, которые мы можем использовать для «извлечения»
SR1, SR2, DR1 и IMM5:#define DR(i) (((i)>>9)&0x7) #define SR1(i) (((i)>>6)&0x7) #define SR2(i) ((i)&0x7) #define IMM(i) ((i)&0x1F)
Объяснение каждого из них уже выходит за рамки статьи, но все станет намного понятнее, если вы просто прочтете хороший урок, посвященный побитовым операциям. К тому же, работают они почти как
FIMM. Здесь мы лишь используем другую маску для получения последних 3 бит вместо 1.В общем виде наша функция
add получается такой:static inline void add(uint16_t i) { reg[DR(i)] = reg[SR1(i)] + (FIMM(i) ? // Если 5й бит равен 1, SEXTIMM(i) : // мы расширяем знак IMM5 и прибавляем его к SR1 (add2) reg[SR2(i)]); // В противном случае мы прибавляем к SR1 значение SR2 (add1) uf(DR(i)); // !! Обновление условного регистра в зависимости от значения DR1 }
and – побитовое логическое «И»
Эта инструкция очень похожа на
add и выражается в двух формах. В первой форме (
and1) она применяет двоичное & к значениям двух регистров: SR1 и SR2, сохраняя результат в DR1:
Во втором варианте (
and2) она примеряет двоичное & для SR1 и IMM5, также сохраняя результат в DR1:Здесь работает тот же принцип, что и прежде. Мы проверяем
bit[5], чтобы определить, какую форму декодируем.В виде кода реализация этой инструкции более-менее совпадает с предыдущей и переиспользует тот же макрос. Здесь мы только изменяем операцию с
+ на &:static inline void and(uint16_t i) { reg[DR(i)] = reg[SR1(i)] & (FIMM(i) ? // Если 5-й бит равен 1, SEXTIMM(i) : // мы расширяем IMM5 и & его с SR1 (and1) reg[SR2(i)]); // В противном случае мы & значение SR2 с SR1 uf(DR(i)); // Обновляем условный регистр }
ld — загрузка из RPC + смещение
ld – это инструкция загрузки данных из области основной памяти в целевой регистр,
DR1. Область памяти получается путем прибавления к регистру RPC значения смещения. Вызов ld не изменяет RPC, этот регистр мы просто используем как отправную точку.
Предположим, что RPC указывает на адрес памяти
0х3002. Если смещение установить на 100, то мы считаем данные из 0x3002+100==0x3066 и загрузим их в целевой регистр (в нашем случае R4, но им может быть и другой).Выглядит эта инструкция так:

Соответствующий код Си для описанной функциональности будет таким:
#define POFF9(i) sext((i)&0x1FF, 9) static inline void ld(uint16_t i) { reg[DR(i)] = mr(reg[RPC] + POFF9(i)); uf(DR(i)); }
Смещение кодируется в последних 9 битах инструкции, а значит его максимальным значением может быть
2^9-1=512-1=511. То есть, в зависимости от того, где (и как) хранится программа, некоторые области памяти останутся для инструкции ld недоступными. 
В двоичном виде 512 – это
0b1000000000. Как видите, для его представления нужно 10 бит. Вот и получается, что максимальным значением, которое может иметь смещение, является 511. В двоичной форме оно записывается как 0b111111111 (9 бит).Чтобы обойти это ограничение
ld, мы рассмотрим другую инструкцию для загрузки содержимого памяти в регистры, называемую ldi.ldi – косвенная загрузка
Эта инструкция используется для загрузки данных в регистры через промежуточные адреса, что позволяет достигать «удаленных» областей памяти.

Итак, предположим, что
RPC указывает на 0х3002. Как и раньше, мы используем 9-битовое смещение для обращения к другой области памяти в позиции (RPC + offset). В нашем случае offset=100, значит считывание происходит из 0x3066.Но вместо непосредственной загрузки в
DR содержимого 0x3066 мы смотрим на значение этого содержимого, которым является 0х3204 и помещаем его в DR.Использование
ldi устраняет проблему ограниченности 9-битного смещения, присущего ld.Хотя это вовсе не означает, что
ldi лучше, чем ld, так как вместо выполнения одного считывания нам нужно выполнить два. Просто он служит несколько иной цели.Формат этой инструкции практически идентичен
ld, отличается только опкод: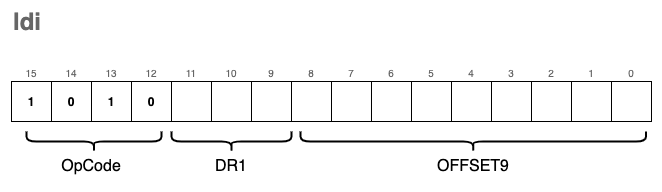
В Си соответствующий код будет выглядеть так:
static inline void ldi(uint16_t i) { reg[DR(i)] = mr(mr(reg[RPC]+POFF9(i))); // Выполняем два считывания из памяти uf(DR(i)); }
ldr – загрузка из основы + смещение
Это еще одна инструкция, с помощью которой мы загружаем данные в регистры. Однако, если сравнивать ее с
ld, где мы отталкиваемся от RPC, то на этот раз мы берем другую base (под base (основой) мы подразумеваем адрес памяти, хранящийся в регистре).Формат у этой инструкции следующий:

Чтобы извлечь из нее
BASER можно снова использовать макрос, уже определенный нами для ld(SR1(i)), потому что расположение битов здесь такое же.Для извлечения
OFFSET6 из инструкции мы задействуем следующий макрос:#define POFF(i) sext((i)&0x3F, 6)
Представление в коде также будет очень похожим на
ld с лишь одним небольшим изменением. Вместо использования reg[RPC] мы смещаемся относительно BASER.static inline void ld(uint16_t i) { reg[DR(i)] = mr(reg[RPC] + POFF9(i)); uf(DR(i)); } // в сравнении с static inline void ldr(uint16_t i) { reg[DR(i)] = mr(reg[SR1(i)] + POFF(i)); uf(DR(i)); }
lea – загрузка фактического адреса
Эта инструкция также позволяет нам загружать адреса памяти в регистры. В отличие от
ld, ldi и ldr она вносит в регистры не данные программы, а адреса памяти.Формат у
lea следующий:
В наглядном представлении работает она так:

Предположим, что
RPC указывает на 0x3002. При offset9=100 мы загружаем в регистр DR результат 0x3002+100=0x3066.В коде данный процесс будет выглядеть так:
static inline void lea(uint16_t i) { reg[DR(i)] =reg[RPC] + POFF9(i); uf(DR(i)); }
not – побитовое дополнение
Эта инструкция просто выполняет побитовое дополнение
~ для SR1 и сохраняет значение в DR1.Формат у нее такой:

Соответствующий код Си:
static inline void not(uint16_t i) { reg[DR(i)]=~(SR1(i)); uf(DR(i)); }
st — сохранение
С помощью инструкции
st мы сохраняем значение заданного регистра в область памяти. Формат этой инструкции такой:

Наглядно ее действие выглядит так:

Предположим, что
RPC указывает на 0x3002, а SR относится к R1=0x0001. Тогда инструкция st запишет в RPC+offset значение R1 . Код Си будет в этом случае прост:
static inline void st(uint16_t i) { mw(reg[RPC] + POFF9(i), reg[DR(i)]); // записывает значение DR(i) в адрес памяти }
Обновлять никакие флаги не нужно, потому что для регистров мы никаких вычислений не выполняем.
Аналогично ранее описанной
ld, у st та же проблема с ограничением доступа к адресам памяти. В связи с этим мы вводим еще одну инструкцию, sti.sti – косвенное сохранение
Формат этой инструкции аналогичен
st, изменяется только опкод:
А вот поведение уже отличается.
Вместо непосредственной записи в память мы используем для промежуточной записи
(mw(…)) промежуточный адрес основной памяти. Этот вторичный адрес содержит фактическую область памяти, куда и будет производиться запись.
Чтобы записать содержимое
R1=0x0001 (SR) в 0x3204, сначала нужно будет сделать запись в область памяти RPC+offsest = 0x3204. Здесь мы найдем значение адреса, куда и хотим в итоге произвести запись: 3204.В коде реализация
sti будет следующей:static inline void sti(uint16_t i) { mw(mr(reg[RPC] + POFF9(i)), reg[DR(i)]); }
str – сохранение в основу + смещение
Эта инструкция повторяет
st за одним отличием. Вместо того, чтобы начинать от RPC, мы можем указать в качестве опорного регистра другую основу (BASER), к которой будем прибавлять смещение (OFFSET6).Формат инструкции будет следующим:

А вот и код:
static inline void st(uint16_t i) { mw(reg[RPC] + POFF9(i), reg[DR(i)]); } // в сравнении с static inline void str(uint16_t i) { mw(reg[SR1(i)] + POFF(i), reg[DR(i)]); }
jmp — переход
Как правило, регистр
RPC после выполнения каждой инструкции автоматически инкрементируется.jmp – это инструкция, которая приводит к переходу RPC в область памяти, заданную содержимым BASER (базовым регистром).Формат у инструкции следующий:

Наглядно она выглядит так:

Предположим, что
RPC=0x3002, а R2=0x3066 (это BASER). При встрече инструкции jmp регистр RPC перейдет непосредственно к адресу памяти, хранящемуся в BASER (R2=0x3066), и поток программы продолжится.В некоторых высокоуровневых языках
jmp работает аналогично инструкции go to.Соответствующий код Си будет выглядеть так:
static inline void jmp(uint16_t i) { reg[RPC] = reg[BR(i)]; }
jsr – переход к подпрограммам
jsr является инструкцией потока управления, позволяющей реализовывать подпрограммы.
Подпрограммы в (нашем) ASM аналогичны функциям из высокоуровневых языков. Их можно представить как серию инструкций и их запуск. У них есть вход (ожидается чтение данных из регистров) и выход (возвращаемое значение они помещают в регистр).
При этом
jsr принимает две формы:
Псевдокод для этой операции будет следующим:
- Сохраняем
RPCвR7(чтобы запомнить, откуда происходит ответвление). - Если
bit[11]является 0, тогда мы устанавливаемRPC = BASER. - Если
bit[11]является 1, устанавливаемRPC = RPC + OFFSET11.
Соответствующий код Си получится таким:
static inline void jsr(uint16_t i) { reg[R7] = reg[RPC]; reg[RPC] = (FL(i)) ? // Проверяет bit[11] reg[RPC] + POFF11(i) : // rpc + offset BR(i); // базовый регистр }
Наглядно эту инструкцию можно представить так:

В примере выше
RPC изначально установлен как 3002. В данной позиции это инструкция jsr. Мы сохраняем RPC в R7, фиксируя точку, откуда делаем ответвление. Далее с помощью offset=100 переходим к позиции 0x3066 и обновляем RPC на это значение.br – условное ответвление
Эта инструкция работает аналогично
jsr, но есть одно существенное отличие – ветвление происходит только при выполнении заданных условий.
Если посмотреть внимательно, то биты
NZP не случайно названы именно так. Они используются для отражения изменений, которые мы производим посредством uf(…) над RCND:enum flags { FP = 1 << 0, FZ = 1 << 1, FN = 1 << 2 }; static inline void uf(enum regist r) { if (reg[r]==0) reg[RCND] = FZ; // значение в r равно нулю else if (reg[r]>>15) reg[RCND] = FN; // значение в r отрицательно else reg[RCND] = FP; // значение в r положительно }
По сути, все возможные значения
RCND – это FP=001, FZ=010 или FN=100. При реализации нашего кода для br мы можем легко это учесть и сравнить сегмент NZP инструкции с RCND:#define FCND(i) (((i)>>9)&0x7) static inline void br(uint16_t i) { if (reg[RCND] & FCND(i)) { // Если условие выполняется, reg[RPC] += POFF9(i); // ответвляемся на смещение } }
trap
Это уже более сложная инструкция, поскольку с ее помощью мы можем взаимодействовать с вводом/выводом и, теоретически, с другими устройствами.

В
TRAPVECT мы храним индекс других инструкций, которые дают нам возможность считывать числа и строки из stdin и выполнять их запись в stdout.Каждая ловушка (trap) будет находиться в массиве
trp_ex, содержащем указатели на связанные функции Си. Здесь мы следуем той же стратегии, что и с другим инструкциями, но использовать будем отдельный массив.Если делать все как положено, то ловушки нужно реализовывать в ASM, а с ними еще один механизм для взаимодействия с клавиатурой и
stdout.Как бы то ни было, структурируется код таким образом:
#define TRP(i) ((i)&0xFF) static inline void tgetc() { /* code */ } static inline void tout() { /* code */ } static inline void tputs() { /* code */ } static inline void tin() { /* code */ } static inline void tputsp() { /* code */ } static inline void thalt() { /* code */ } static inline void tinu16() { /* code */ } static inline void toutu16() { /* code */ } enum { trp_offset = 0x20 }; typedef void (*trp_ex_f)(); trp_ex_f trp_ex[8] = { tgetc, tout, tputs, tin, tputsp, thalt, tinu16, toutu16 }; static inline void trap(uint16_t i) { trp_ex[TRP(i)-trp_offset](); }
Всего получается 8 поддерживаемых функций ловушек:
| Функция ловушки | TRAPVECT | Индекс trp_ex[] | Описание |
| tgetc | 0x20 | 0 | Считывает с клавиатуры символ (char), который копируется в R0. |
| tout | 0x21 | 1 | Записывает символ (char) из R0 в консоль.. |
| tputs | 0x22 | 2 | Записывает строку символов в консоль. Как правило, символы хранятся в непрерывно связанных областях памяти, по одному на каждую область, начиная с адреса, указанного в R0. При встрече 0x0000 вывод прекращается. |
| tin | 0x23 | 3 | Считывает символ (char) с клавиатуры и копирует его в R0.После этого данный символ выводится в консоль. |
| tputsp | 0x24 | 4 | Не реализована. Это прерывание используется для сохранения не 1, а 2 символов в каждую область памяти. В противном случае она работает как tputs. Оставляю ее вам для реализации в качестве упражнения. |
| thalt | 0x25 | 5 | Прекращает выполнение программы. VM останавливается.. |
| tinu16 | 0x26 | 6 | Считывает с клавиатуры uint16_t и сохраняет его в R0. |
| toutu16 | 0x27 | 7 | Выводит считанный uint16_t из R0. |
Теперь рассмотрим реализацию каждого метода.
tgetc
Здесь мы просто используем
getchar() и сохраняем возвращаемое значение в R0:static inline void tgetc() { reg[R0] = getchar(); }
toutc
Выводим
R0 в stdout:static inline void tout() { fprintf(stdout, "%c", (char)reg[R0]); }
tputs
Перебираем область памяти, начиная с
R0, пока не находим 0x0000, и выводим каждый символ по порядку:static inline void tputs() { uint16_t *p = mem + reg[R0]; while(*p) { fprintf(stdout, "%c", (char)*p); p++; } }
tin
Этот метод практически идентичен
tgetc за одним небольшим отличием – мы выводим символ после его сохранения в R0:static inline void tin() { reg[R0] = getchar(); fprintf(stdout, "%c", reg[R0]); }
thalt
Для отслеживания активности VM мы поддерживаем глобальную логическую переменную
running. Когда происходит вызов thalt, running устанавливается как false, и машина автоматически останавливается:static inline void thalt() { running = false; }
tinu16
Мы считываем
uint16_t с клавиатуры и сохраняем его в R0:static inline void tinu16() { fscanf(stdin, "%hu", ®[R0]); }
toutu16
Выводим сохраненное значение
uint16_t из R0 в консоль:static inline void toutu16() { fprintf(stdout, "%hu\n", reg[R0]); }
Загрузка и выполнение программ
Если по ходу статьи вы также работали с кодом, то примите мои поздравления! На этом этапе у вас получилась рабочая игрушечная VM, способная выполнять простые программы, написанные на ASM.
Теперь нам недостает всего двух деталей: основного цикла и возможности загружать программы.
Основной цикл нашей VM будет выглядеть так:
bool running=true; uint16_t PC_START = 0x3000; void start(uint16_t offset) { reg[RPC] = PC_START + offset; // RPC установлен while(running) { uint16_t i = mr(reg[RPC]++); // Извлекаем инструкции из области памяти, // на которую указывает RPC // Автоматически инкрементируем RPC op_ex[OPC(i)](i); // Выполняем каждую инструкцию } }
Теперь недостает только возможности загружать программы в нашу VM, для чего мы напишем метод
ld_img, который сможет загружать двоичные файлы непосредственно в основную память:void ld_img(char *fname, uint16_t offset) { // Открываем (двоичный) файл, содержащий программу VM FILE *in = fopen(fname, "rb"); if (NULL==in) { fprintf(stderr, "Cannot open file %s.\n", fname); exit(1); } // Позиция, откуда мы начинаем копирование файла в основную память uint16_t *p = mem + PC_START + offset; // Загружаем программу в память fread(p, sizeof(uint16_t), (UINT16_MAX-PC_START), in); // Закрываем поток файла fclose(in); }
Этот метод возвращает
void и принимает два входных параметра:- путь к двоичному файлу с программой;
- смещение, откуда начинается загрузка первой инструкции программы в основную память.
Основной метод нашей VM выглядит так:
int main(int argc, char **argv) { ld_img(argv[1], 0x0); start(0x0); return 0; }
Наша первая программа
Нашим первенцем будет не привычная Hello, world!, а нечто более впечатляющее: сложная программа, считывающая два числа с клавиатуры и выводящая их сумму в
stdout.Ладно, шутки в сторону. Выглядеть она будет так:
0xF026 // 1111 0000 0010 0110 TRAP tinu16 ;read an uint16_t in R0 0x1220 // 0001 0010 0010 0000 ADD R1,R0,x0 ;add contents of R0 to R1 0xF026 // 1111 0000 0010 0110 TRAP tinu16 ;read an uint16_t in R0 0x1240 // 0001 0010 0010 0000 ADD R1,R1,R0 ;add contents of R0 to R1 0x1060 // 0001 0000 0110 0000 ADD R0,R1,x0 ;add contents of R1 to R0 0xF027 // 1111 0000 0010 0111 TRAP toutu16 ;show the contents of R0 to stdout 0xF025 // 1111 0000 0010 0101 HALT ;halt
Синтаксис не очень внятный, правда? По факту наша программа – это серия чисел:
0xF026 0x1220 0xF026 0x1240 0x1060 0xF027 0xF025. Если же взглянуть повнимательнее, то станет очевидно, что именно в этих числах мы и закодировали инструкции ASM.Возьмем, к примеру,
0xF026. Его двоичная форма – это 1111 0000 0010 0110. Легко подметить, что 1111 – это кодировка для trap, а его TRAPVECT, 100111, соответствует tinu16. Для более наглядного представления проанализируем
0x1220:0x1220 -> 0001 001 000 1 00000 ADD R1 R0 IMM5=0
Запуск первой программы
Плохие новости – у нас нет компилятора. Придется писать программы от руки, взяв ручку и бумагу (как пионеры программирования).
Хорошие же новости в том, что нам не нужен компилятор для генерации двоичного файла, который сможет выполнить наша VM – можно написать для этого программу Си.
Основной идеей будет сохранение инструкций в массиве (
uint16_t program[]) и последующем использовании fwrite() для генерации двоичного файла, который затем можно будет загружать с помощью ld_img().#include <stdio.h> #include <stdlib.h> uint16_t program[] = { /*mem[0x3000]=*/ 0xF026, // 1111 0000 0010 0110 TRAP trp_in_u16 ;считывает uint16_t из stdin и помещает его в R0 /*mem[0x3002]=*/ 0x1220, // 0001 0010 0010 0000 ADD R1,R0,x0 ;прибавляет содержимое R0 к R1 /*mem[0x3003]=*/ 0xF026, // 1111 0000 0010 0110 TRAP trp_in_u16 ;считывает uint16_t из stdin и помещает его в R0 /*mem[0x3004]=*/ 0x1240, // 0001 0010 0010 0000 ADD R1,R1,R0 ;прибавляет содержимое R0 к R1 /*mem[0x3006]=*/ 0x1060, // 0001 0000 0110 0000 ADD R0,R1,x0 ;прибавляет содержимое R1 к R0 /*mem[0x3007]=*/ 0xF027, // 1111 0000 0010 0111 TRAP trp_out_u16;выводит содержимое R0 в stdout /*mem[0x3006]=*/ 0xF025, // 1111 0000 0010 0101 HALT ;остановка }; int main(int argc, char** argv) { char *outf = "sum.obj"; FILE *f = fopen(outf, "wb"); if (NULL==f) { fprintf(stderr, "Cannot write to file %s\n", outf); } size_t writ = fwrite(program, sizeof(uint16_t), sizeof(program), f); fprintf(stdout, "Written size_t=%lu to file %s\n", writ, outf); fclose(f); return 0; }
Скомпилировав и выполнив вышеприведенную программу, мы сгенерируем двоичный файл
sum.obj.Затем можно использовать нашу VM для его загрузки и запуска:

На данный момент в репозитории лежит еще одна программа:
simple_program.c, которая складывает числа в массиве. Если вам интересно, можете запустить ее самостоятельно.Заключение
Во-первых, благодарю всех, кто дочитал до этого момента, и поздравляю тех, кто запустил свою первую VM.
Написать подобную «игрушечную» машину несложно, но вот создание чего-то полезного для удаленной работы уже требует серьезных усилий и подразумевает знакомство с куда большим объемом материала, нежели мы здесь затронули.
Быть может, в одной из будущих статей мы реализуем стековую виртуальную машину или современный гибрид из нее и нашей текущей версии.
После публикации этой статьи в разных сообществах (отклик, кстати, был потрясающий) люди обоснованно подметили использование в ней несколько туманного именования: названия функций слишком коротки, код излишне сжат и т.д.
Обычно я не называю компоненты таким образом, но с учетом того, что эта программа коротка, содержательна и ориентирована на низкоуровневый мир ASM (где компоненты именуются вразрез с привычными нормами), для меня показалось более естественным написать код именно так.
Вообще, я не предполагал рассмотрение кода вне контекста данной статьи, поэтому и не уделил его понятности лишнего внимания.
Ссылки на сообщества

