В лучших традициях «питоновского дзена» мы будем максимально красивы, явны, просты, в меру сложны, читаемы и даже попытаемся легко объяснить данную реализацию, что как всем известно является признаком хорошей идеи. Ах да, и это прямо сейчас, что не никогда, так сказать, все признаки хорошего материала уже на лицо, в путь.
На сегодняшний день существует большое количество алгоритмов машинного обучения для обработки различного типа данных, таких как табличные данные, изображения, текст, аудио файлы. Как раз о последнем типе пойдёт речь в данной работе, потому как аудио файлы являются одной из распространенных форм хранения данных в организациях, тщательный анализ которых может являться ключевым фактором к развитию не только коммерческих продуктов, но и опенсорсных решений. В то же время именно методы работы со звуком менее всего популярны, особенно в русскоязычном сегменте, но об этом далее.
Библиотека NeMo (Neural Models) является одной из наиболее быстроразвивающихся и открытых библиотек в области ML (Machine Learning), представляет собой набор инструментов для создания новых современных моделей разговорного ИИ. NeMo имеет отдельные коллекции для моделей автоматического распознавания речи (ASR), обработки естественного языка (NLP) и преобразования текста в речь (TTS). Из темы становится ясно, что целью обзора будут модели и методы раздела ASR, а именно мы рассмотрим следующие пункты:
Кратко рассмотрим какими готовыми моделями располагает библиотека;
Научимся эти модели загружать, транскрибировать аудио, оценивать качество;
Ответим на вопрос как дообучать модели и можно ли английскую нейронку научить понимать русский язык;
Похвалим Сбер;
Побудем лингвистами и оценим близость моделей одной языковой группы и получим интересный (возможно) результат (тоже возможно).
Как уже было упомянуто выше, библиотека NeMo является одной из самых продвинутых библиотек для задач распознавания речи на данный момент, так как не только располагает большим набором предобученных моделей на различных языках, но и занимается их разработкой, постоянным обновлением, написанием детальных инструкций. Следует упомянуть также, что github репозиторий данного проекта постоянно просматривается администраторами и ответы на вопросы появляются с удивительной скоростью. На глупый вопрос автора статьи в 12 часов ночи, ответ был получен через час от молодого человека из Сан-Хосе.
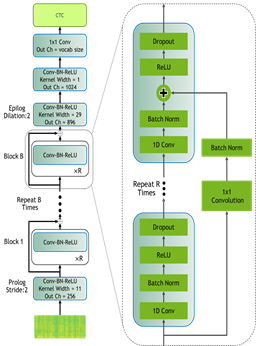
О моделях. Лучшие современные STT (speech to text) решения можно условно разделить на три типа, первый, это модели, которые произошли от архитектуры «Jasper» («Just Another Speech Recognizer»), на рисунке 1 ниже представлена классическая модель (слева) и улучшенная версия данной архитектуры под названием QuartzNet (справа), имеющая более крупные фильтры. Jasper представляет собой нейронную сеть с временной задержкой (TDNN), состоящую из блоков одномерных сверточных слоев. Семейство моделей Jasper обозначается как Jasper_[BxR], где B — количество блоков, а R — количество сверточных подблоков внутри блока. Каждый подблок содержит одномерную свертку, пакетную нормализацию, ReLU и отсев.

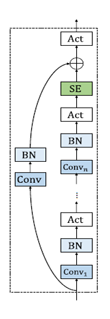
Далее идут модели под названием ContextNet на рисунке 2 слева представлена модель одного блока и Conformer на рисунке 2 справа. Первая — это модель, которая представляет собой полностью сверточный кодировщик, который включает глобальную контекстную информацию в слои свертки путем добавления модулей Squeeze-and-Excitation. Вторая — это модель conformer, на данный момент является составляющей SOTA решением, да-да трансформеры добрались и сюда. В этой модели используется комбинация модулей self-attention и свертки для достижения наилучшего из двух подходов: слои self-attention могут изучать глобальное взаимодействие, в то время как свертки эффективно фиксируют локальные корреляции.

Собственно, все эти архитектуры можно скачать из библиотеки Nemo, как предообученные, так и пустые. На данный момент версии с весами доступны на следующих языках: английский, французский, немецкий, итальянский, польский, каталонский, китайский, испанский, русский, другое дело, что некоторые из них дообучены с одной хитростью, но оставим интригу на немного попозже.
Чтобы установить библиотеку и импортировать нужную модель достаточно написать следующие строки кода (полная версия кода из данной статьи представлена в репозитории по ссылке):
#Установка библиотеки
# Установка зависимостей и самого немо
!pip install wget
!apt-get install sox libsndfile1 ffmpeg
!pip install unidecode
!pip install matplotlib>=3.3.2
!pip install --upgrade numba
BRANCH = 'main'
!python -m pip install git+https://github.com/NVIDIA/NeMo.git@$BRANCH#egg=nemo_toolkit[all]import nemo
import nemo.collections.asr as nemo_asr
#импорт предобученной модели на русском языке, которая дана в репозитории
nemo
rus_quartznet = nemo_asr.models.EncDecCTCModel.from_pretrained (model_name='stt_ru_quartznet15x5')
И всё! Далее можно заниматься транскрибацией. Распознаем небольшой аудиофайл с содержанием: «Внутренний аудит — это форма контроля деятельности организации изнутри. Процедура помогает руководству проверять финансовое состояние бизнеса и достоверность отчетности».
#Для прослушивания аудио
import IPython
audio_rus_file = ['/content/rus_text_audit_eto.mp3']
IPython.display.Audio(audio_rus_file[0])
#Транскрибация
rus_quartznet.transcribe(paths2audio_files=audio_rus_file)Результат: «внутренний алдид это форума контроля деятельности организации изнутри процедуры помогает руководство проверять финансовое состояние бизнеса и достоверность отчетности». Результат неплохой, но в модель необходимо добавить инструменты для пунктуации и определения заглавных букв.
Если пробовать распознавать русскую речь другими моделями, обученными на английских датасетах, то получается следующее:
Название модели | Результат транскрибации |
stt_ru_quartznet15x5 | внутренний алдид это форума контроля деятельности организации изнутри процедуры помогает руководство проверять финансовое состояние бизнеса и достоверность отчетности
|
stt_en_contextnet_1024
| vunutrini oudid at a former controller dating estraganizadse is notream parasadura pomagad rocavosto previous financier by a custiani business it has diverse acting
|
stt_en_conformer_ctc_large
| vutrni auditd a the former control aietister genizatse is nutri parazadura magatrukawosto prevared finanz stani business in st chotnsti
|
stt_en_conformer_transducer_large
| a form of controlling isi is notrencern
|
Результат достаточно интересный, очень похоже на то как пишут транслитом, это связано с тем, что многие буквы русского алфавита по звучанию достаточно похожи на звучание букв из английского.
Возвращаясь к оценке транскрибации речи, существует общепризнанная практика расчёта коэффициента WER (Word Error Rate), в ней сумма количества замен, удалений и вставок делится на количество слов в референсе. В библиотеке NeMo есть инструмент, помогающий рассчитать данную метрику, но перед этим необходимо указать в конфиге модели ссылку на манифест файл с тестовым датасетом, по которому и будет считаться WER. Для некоторых датасетов, например, an4 нужно писать алгоритм для создания такого json файла, в сете MCV (mozilla common voices), файлы манифеста уже есть, на них нужно лишь сослаться и инициализировать внутри модели, сделать это можно следующим образом:
VERSION = "cv-corpus-6.1-2020-12-11"
LANGUAGE = "ru"
tokenizer_dir = os.path.join('tokenizers', LANGUAGE)
manifest_dir = os.path.join('manifests', LANGUAGE)
train_manifest = f"{manifest_dir}/commonvoice_train_manifest.json"
dev_manifest = f"{manifest_dir}/commonvoice_dev_manifest.json"
test_manifest = f"{manifest_dir}/commonvoice_test_manifest.json"
rus_quartznet._cfg['validation_ds']['manifest_filepath'] = dev_manifest
#расчёт wer
rus_quartznet._cfg['validation_ds']['batch_size'] = 10 #чем больше данное значение, тем больше пропускная способность, тем быстрее посчитается
# Настройка загрузчика тестовых данных
rus_quartznet.setup_test_data(test_data_config=rus_quartznet._cfg['validation_ds'])
rus_quartznet.cuda()
rus_quartznet.eval()
# WER рассчитает числители и знаменатели
# Соберем все числители и знаменатели тестовых партий
wer_nums = []
wer_denoms = []
for test_batch in tqdm(rus_quartznet.test_dataloader()):
# print('='*20)
# test_batch = [x.cuda() for x in test_batch]
test_batch = [x.cuda() for x in test_batch]
targets = test_batch[2]
targets_lengths = test_batch[3]
log_probs, encoded_len, greedy_predictions = rus_quartznet(
input_signal=test_batch[0], input_signal_length=test_batch[1])
# rus_quartznet._wer.update(greedy_predictions, targets, targets_lengths) #такой изначальо
rus_quartznet._wer.update(predictions=greedy_predictions,
targets=targets,
target_lengths=targets_lengths,
predictions_lengths=encoded_len)
wer, wer_num, wer_denom= rus_quartznet._wer.compute()
# print(wer)
rus_quartznet._wer.reset()
wer_nums.append(wer_num.detach().cpu().numpy())
wer_denoms.append(wer_denom.detach().cpu().numpy())
del test_batch, targets, targets_lengths, encoded_len, greedy_predictions, log_probs
# print('='*20)
print(f"WER = {sum(wer_nums)/sum(wer_denoms)}")Инструментарий библиотеки Nemo также позволяет обучать модели с нуля, либо предобученные версии, которые выдают лучший результат, чем так называемое обучение моделей «from scratch». Интересно то, что предобученную языковую модель можно настроить на какой-либо другой язык. Например, все обученные модели в репозитории NeMo кроме английской, французской и немецкой изначально обучались примерно на 3-х тысячах часах различных английских наборов данных, но затем у такой модели менялся последний слой декодера, где расположен алфавит нужного языка, после, модель дообучалась на данных соответствующих языку измененного слоя. В NeMo подобные операции выглядят следующим образом, дообучим английский quartznet_15х5 на русский лад.
#Взаимодействие с моделями от немо всегда происходит через их config файл
# посмотреть какие параметры есть внутри архитектуры можно командой вызова ключей:
ru_quartz.cfg.keys()
#Например вызов оптимайзера , в котором определены гиперпараметры для обучения нейросети:
ru_quartz.cfg.optim
#определяем новый новый словарь, который пойдёт на замену старого (английского)
new_vocab = [' ', 'а', 'б', 'в', 'г', 'д', 'е', 'ё', 'ж', 'з', 'и', 'й', 'к', 'л', 'м', 'н', 'о', 'п', 'р', 'с', 'т', 'у', 'ф', 'х', 'ц', 'ч', 'ш', 'щ', 'ъ', 'ы', 'ь', 'э', 'ю', 'я']
ru_quartz.cfg.decoder.vocabulary = new_vocab
#замена
ru_quartz.cfg.decoder['num_classes'] = len(new_vocab)
#обучеие происходит через библиотеку pytorch_lightning
import pytorch_lightning as pl
#прописываем кол-во гпу и эпох
trainer = pl.Trainer(gpus=1, max_epochs=5)
#определяем в конфиге модели тренировочный и тестовый манифест
ru_quartz._cfg['train_ds']['manifest_filepath'] = train_manifest
ru_quartz._cfg['validation_ds']['manifest_filepath'] = test_manifest
#устанавливаем эти манифесты как трэин и валидация для дообучения
ru_quartz.setup_training_data(train_data_config=ru_quartz.cfg['train_ds'])
ru_quartz.setup_validation_data(val_data_config=ru_quartz._cfg['validation_ds'])
#устанавливаем размеры батчей исходя из возможностей gpu на компьютере
ru_quartz._cfg['train_ds']['batch_size'] = 32
ru_quartz._cfg['validation_ds']['batch_size'] = 16
#начинаем обучение
trainer.fit(ru_quartz)STT нейронные модели достаточно долгие в обучении. Расчёт одной эпохи из примера выше занимает, примерно, 12 минут на видеокарте Nvidia P100 с 16 Gb видеопамяти. Для получения хорошего результата требуется больше 100 эпох. Зависимость качества распознавания аудиофайла из раннее приведенного примера от длительности обучения:
№ эпохи | WER на MCV (dev) | Транскрибация |
5 | 75% | внудрене алдить эта форма контроледительность организации изнутрипроцедура пумогает руководству привереть нанцакое состояния бизеса и бестоянность отчетности |
10 | 63% | ввутреми алудит это форма контпралят деятельности организации изнутремпроцедуры омогает руководство провирательнарсовое состоянии безуса и достовирность обтерности |
15 | 55% | вмудренни адит это форма контрона деятельности организации изнутри процетура помагает руководство промирять финансоввое состояния бизнаса и бестоявенрность отчетности |
130 | 35% | внутренние алдит это форма контроля деятельности организации и знутрини процедура помогает руководство проверять финансовое состояние бизнеса и бостоверность отчетности |
Как видно из таблицы присутствует прямая зависимость между длительностью обучения и результативностью работы модели. Так что да, англичанина можно достаточно быстро научить понимать русский, но на это нужно немного времени и GPU.
Интересное наблюдение! Поэкспериментировав с процессом дообучения моделей другим языкам появилась идея о том, что языки чья фонетика и грамматика похожа, например, языки одной группы скорее всего будут обучаться признакам друг друга быстрее и выдавать тот же WER, но с меньшим числом эпох, так и вышло! Мы решили взять два языка индоевропейской семьи, а именно польский и русский, и в качестве начальной модели выбрали QuartzNet15x5от Сбера, который хорошо обучен на русском корпусе Golos, в процессе дообучения на польский язык, модель достигла отметки WER в 45% уже на 10 эпохе, что говорит о схожести данных языков в противовес процессу дообучения английской модели русскому, где для подобного результата понадобилось больше 35 эпох.
Для сохранения новой обученной модели необходимо воспользоваться командой:
#Сохранение:
save_path = f"Название-{LANGUAGE}.nemo"
ru_quartz.save_to(f"{save_path}")Но не всё так радостно, как хотелось бы, самая большая проблема ASR моделей состоит в том, что в русскоязычном сегменте достаточно мало открытых, не коммерческих, высококачественных моделей по распознаванию голоса, причиной этого является резкая нехватка свободно распространяющихся проверенных обучающих данных. Не просто так на страничке каждой модели на сайте Nvidia есть надпись: «Поскольку эта модель была обучена на общедоступных наборах речевых данных, производительность этой модели может ухудшиться для речи, которая включает технические термины или разговорный язык, на котором модель не была обучена».
Всего существует, примерно, 5 датасетов, где можно найти вручную аннотированные аудиозаписи, выделяется из всех opensource датасет Golos от команды Сбера. Речь идёт примерно о 1240 часах различных аудиоданных тщательно размеченных вручную, в остальных датасетах размер проверенных данных крайне мал и редко, когда выходит за несколько часов. Также команда Сбера обучила модель QuartzNet15х5 используя инструменты библиотеки Nemo. Автор, по вышеописанной методике, рассчитал WER у этой модели на данных MCV (dev), результат получился 10,4% в то время как у русской модели на сайте Nvidia модель достигает только 17,2%.
Для загрузки и активации раннее сохраненной модели ниже приведён пример кода скачивания с гитхаба ./sberdevices/golos:
#Скачивание модели напрямую из репозитория Сбера
!wget https://sc.link/ZMv
#Активация
sber_quartzNet = nemo_asr.models.EncDecCTCModel.restore_from("/content/ZMv")Хочется отметить, что модели распознавания голоса, особенно русскоязычные, находятся на подъёме, не особо стремительном, но подъёме. Не так давно стали появляться большие профессиональные датасеты, такие как Golos, растёт количество проверенных данных и в без того огромном Open-STT, к концу 2022 проект SOVA обещают расширить до нескольких десятков тысяч часов, MCV постоянно растёт и т.д., всегда будут появляться более новые архитектуры, новые SOTA решения, а такие библиотеки как NeMo позволяют держать их под рукой, будь то для удовольствия или для реализации продакшн задач.

