Недавно мы проводили вебинар «Обкафкился по полной. Фейлы с Apache Kafka». На нём спикер Всеволод Севостьянов, Engineering Manager в HelloFresh, поделился фейлами из личной практики, а ещё рассказал, как мастерски ходить по тонкому льду Kafka и прокачать свой бэкенд. Для тех, кто пропустил или предпочитает читать, а не смотреть, подготовили текстовый вариант.

Фейл №0: Kafka сложнее, чем кажется
Apache Kafka подаётся как суперпростой инструмент, из-за чего многие специалисты не до конца понимают, как она работает. Например, есть заблуждение, что Kafka очень легко настраивается, поэтому с ней не должно возникать проблем. На самом деле у неё под капотом множество computer science.
Есть топики — что-то вроде контейнеров, в которых хранятся сообщения, объединённые темой или форматом. Чтобы масштабироваться внутри Kafka, топики делятся на партиции — единицы хранения сообщений. И часто возникает проблема, связанная с тем, что сообщения дробятся рандомным образом: какие-то попадают в Partition1, а какие-то — в Partition2, какие-то — в Partition3 и т.д. В результате сервисы, привязанные к Kafka, начинают читать данные из топиков в неправильном порядке.
Для Kafka партиционирование — это нормально. Но я часто видел команды, которые усердно старались обойти топики, делали всего одну партицию и настраивали всё не так. Хотя здесь можно пойти простым путем: сделать Partition Key, который позволит хранить сообщения, зависящие друг от друга, в том порядке, в котором вы хотите их передать.
Фейл №1: создавали 150 топиков, а нужно было заменить Kafka на Rabbit
Я работаю в компании, которая занимается Meal Kit — доставкой продуктов для приготовления блюд по рецепту. И у нас есть тулза для создания рецептов. В ней заводят рецепты, записывают данные в Kafka и затем их куда-то отправляют. Кто потребляет эти данные, тулза не должна знать.
Проблема: Kafka слушают планировщик, составляющий меню на неделю, Data Warehouse, отвечающий за обработку данных, Predictor, оценивающий, сколько продуктов у нас уйдет на этой неделе и сколько нужно заказывать на следующую, и ещё куча сервисов. Всем сервисам нужны разные данные. Например, планировщику меню — только готовые рецепты, а Predictor — рецепты, которые заказали минимум 1 раз.
Изначально мы попытались решить проблему, сделав много разных топиков на каждого потребителя. И это закономерно привело к тому, что Kafka «встала колом». Kafka не умеет по содержимому топика понимать, куда и какому потребителю его надо доставить. Всё работает по принципу подписной модели, когда вы говорите: «Я хочу получать газету каждый день». И каждый день вам приходит газета со всеми новостями, а не исключительно с новостями, которые вам интересны.
Итак, на каждый топик у нас был ровно один потребитель. И логика, которая должна выполняться на стороне потребителя (он сам фильтрует, что ему интересно), выполнялась на стороне Recipe Dev. Это был полный обкафкинг, потому что у нас получилась не разделённая система, а система, которая просто знает о существовании всех своих компонентов и обменивается сообщениями между ними, используя Kafka как шину данных или механизм сохранения. Это довольно дорого и неэффективно.
Решение: мы заменили Kafka на RabbitMQ, который может по ключу определить, в какой канал отправить конкретное сообщение и кто его должен получить. Также по этому ключу потребители могут подписываться на обновления.
У нас было давление со стороны инфраструктуры — система реплицировалась много раз, у неё был мультирегиональный деплой и около 30-40 инстансов. На таком масштабе RabbitMQ вышёл дешевле, чем Kafka.
Фейл №2: Leader not available
Проблема: есть consumer, который потребляет данные. Вы радостно отправляете данные в Kafka, но потом замечаете, что consumer ничего не потребляет. Kafka работает, consumer работает, но ничего не происходит.
Одна из самых частых причин, почему так происходит, — перебалансировка consumer. У Kafka существует механизм, который мы уже рассматривали выше: топики делятся на партиции. Предположим, вы добавили первый consumer. У вас появляется понятие «лидер группы». В данном случае он слушает и последовательно добавляет в consumer все партиции конкретного топика:
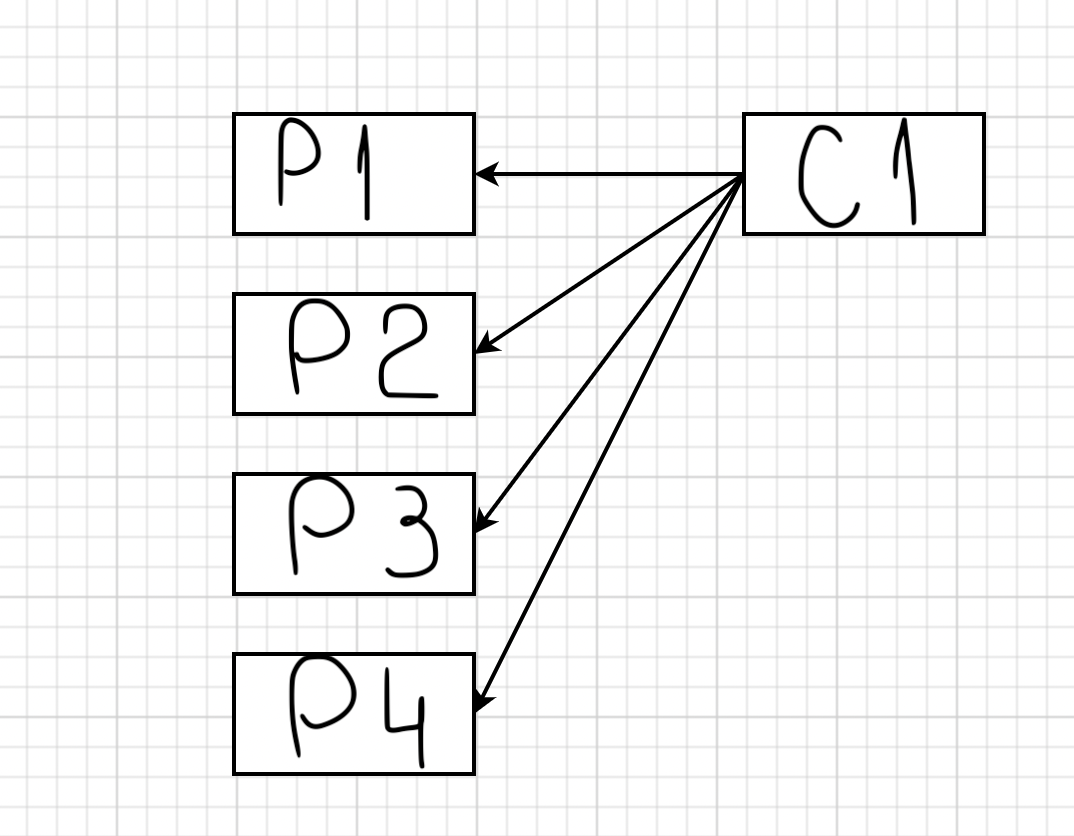
Если добавится второй consumer для этого топика, то к нему привяжутся P3 и P4:
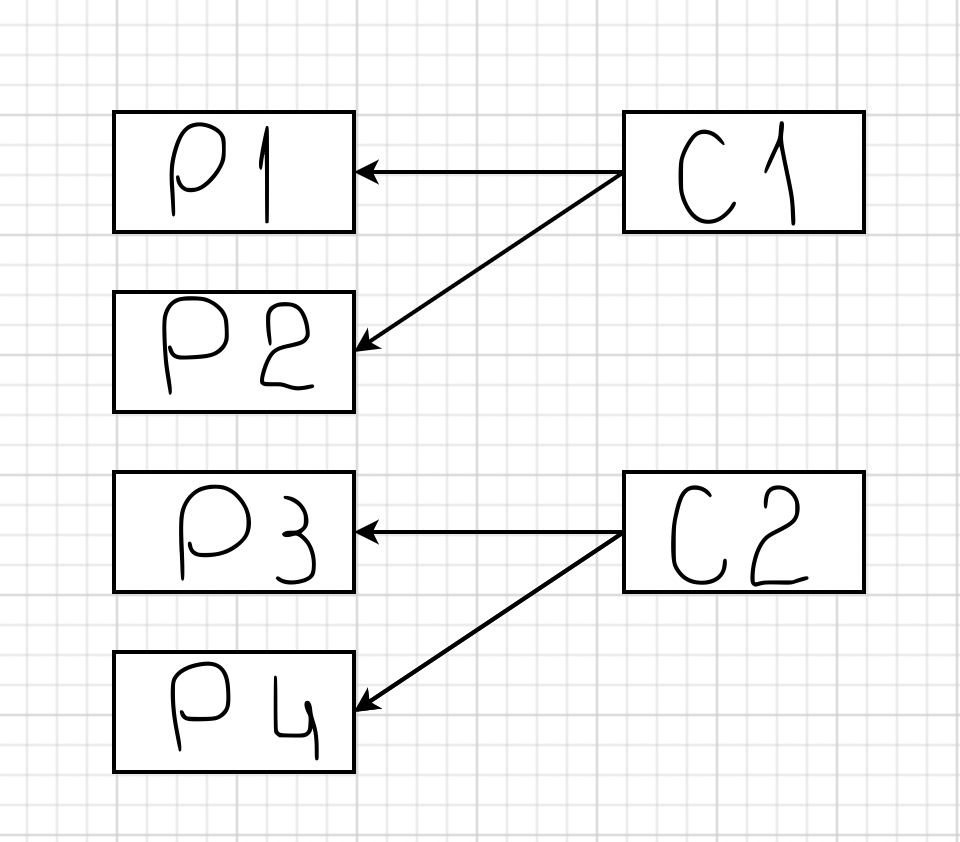
Этот процесс занимает какое-то время, так как второй consumer должен сообщить лидеру группы, что он доступен. Затем лидер группы обрабатывает эту информацию и возвращается с ответом, какие партиции должен потреблять consumer. И смысл в том, что если ваш софт написан неправильно, или у вас, например, Java под капотом, или Spring Boot, который долго стартует, такая перебалансировка будет происходить регулярно.
Что было у нас: подключался первый consumer, начинал слушать топик. Затем стартовали второй и третий consumer, посылали сигналы о перебалансировке и подключались. Но в какой-то момент третий consumer говорил, что отваливается. Причём он только говорил так — реально он никуда не отваливался и продолжал работать.
Это казалось мистикой, пока мы не открыли для себя удивительный мир параметров max.poll.interval и Session timeout.
Дело в том, что Kafka — система пассивного чтения, сама она никому ничего не пересылает. И чтобы обеспечить равномерность распределения сообщений партиций по consumer, ей нужно знать, сколько consumer всего. Для этого выбирается Consumer Leader, который слушает heartbeat — сообщения consumer о том, что он существует и готов принимать данные. Heartbeat отправляются всеми consumer в Kafka, при этом промежуток между двумя heartbeat не должен превышать max.poll.interval.
Это довольно очевидно, что мы не должны превышать тайм-аут сессии. Но абсолютно не очевидно, что consumer считается мертвым не только, когда превысил этот интервал, но и когда он взял сообщение, начал его обрабатывать и не смог обработать за max.poll.interval.
Нужно уметь оперировать значениями max.poll.interval и Session timeout. Они по умолчанию настроены на не очень большой интервал — около 2 секунд для тайм-аут сессии и 500 миллисекунд для max.poll.interval. Если у вас timeout-сессии 5 или 10 секунд, Kafka скажет: «Не успел — отключайся». То же самое и с обработкой сообщений: если не успел обработать сообщение в отведённый интервалом, возникает проблема.
Решение: мы увеличили max.poll.interval до двух часов и Session timeout до 5 часов. И пришли к следующей схеме — consumer подъезжал, загружал в себя данные и висел с ними около двух часов. В итоге топики блокировались, и из них ничего нельзя было достать.
Мы решили снизить max.pool.interval, а Session timeout оставить, как есть. Для этого нам потребовалась group.instance.id, которая позволила Kafka в случае, если отвалится первый consumer, дождаться Session Timeout Milliseconds, когда поднимается второй consumer и заберёт себе партиции.
group.instance.id — классная штука, но использовать её надо аккуратно, иначе может возникнуть ситуация, когда consumer лежит в тайм-ауте три часа, никто на это не реагирует, и один из топиков простаивает, пока все остальные двигаются вперёд.
Фейл №3: TTL
Проблема: у нас отвалился второй consumer. Он провисел какое-то количество времени, а затем начал забирать данные из топика. И в результате мы обнаружили, что у нас пропала часть рецептов.
Причина — случился TTL. Хотя Kafka можно использовать как базу данных, это не база данных. Kafka — это log, куда один за одним складываются сообщения и откуда в такой же последовательности забираются.
Kafka рассчитана на большую пропускную способность и резервирует свои сообщения на диск. Время от времени она выполняет операцию compacting — берёт и отрезает часть сообщений. По умолчанию, TTL у Kafka — одна неделя. Но часто об этом забывают, а потом обнаруживают, что в log отсутствует данные старше 7 дней.
Решение: нужно использовать max.poll.interval, ставить разумный Session timeout и следить за здоровьем consumer. Желательно делать мониторинг.
Пара слов о Kafka напоследок
Основная проблема в том, что Kafka воспринимают и настраивают неправильно. Казалось бы, всё очень просто (тот же Rabbit MQ в разы сложнее), но внутри есть огромное количество разных «крутилок». И очень важно научиться их правильно использовать. Не воспринимайте эту статью как рекомендацию не работать с Kafka. Напротив, Kafka — отличный инструмент. Но здесь мы попытались сделать честный обзор и рассказать о сложностях, с которыми вы можете столкнуться.
Для тех, кто хочет научиться работать с Kafka и избежать фейлов
У нас есть видеокурс «Apache Kafka для разработчиков». Он быстро переведёт вас на новый уровень владения инструментом и поможет:
уменьшить время на рабочие задачи с Kafka;
упростить работу с микросервисами;
разобраться в типовых шаблонах проектирования;
сделать приложение более отказоустойчивым;
получить опыт разработки приложений, использующих Kafka.
Также у нас есть курс «Apache Kafka База». Он ориентирован на системных администраторов, но архитекторам и разработчикам тоже будет полезен. Он комплексно охватывает Kafka и даёт понимание, какое место она занимает в жизни организации.

