
Широкое распространение машинного обучения помогло стимулировать инновации, которые всё труднее предсказать и создавать на их основе интеллектуальный опыт для продуктов и услуг бизнеса. Чтобы решить эту задачу, важно применять передовые методы. Сергей Десяк, ведущий эксперт центра компетенций DevOps компании Neoflex, делится опытом использования Seldon Core для машинного обучения, в частности, для «выкатки» моделей.
Что такое ML
Машинное обучение (ML) — это использование математических моделей данных, которые помогают компьютеру обучаться без непосредственных инструкций. Оно считается одной из форм искусственного интеллекта (ИИ). При машинном обучении с помощью алгоритмов выявляются закономерности в данных и на их основе создаётся модель для прогнозирования. Чем больше данных обрабатывает и использует такая модель, тем точнее становятся результаты ее работы. Это очень похоже на то, как человек оттачивает навыки на практике.
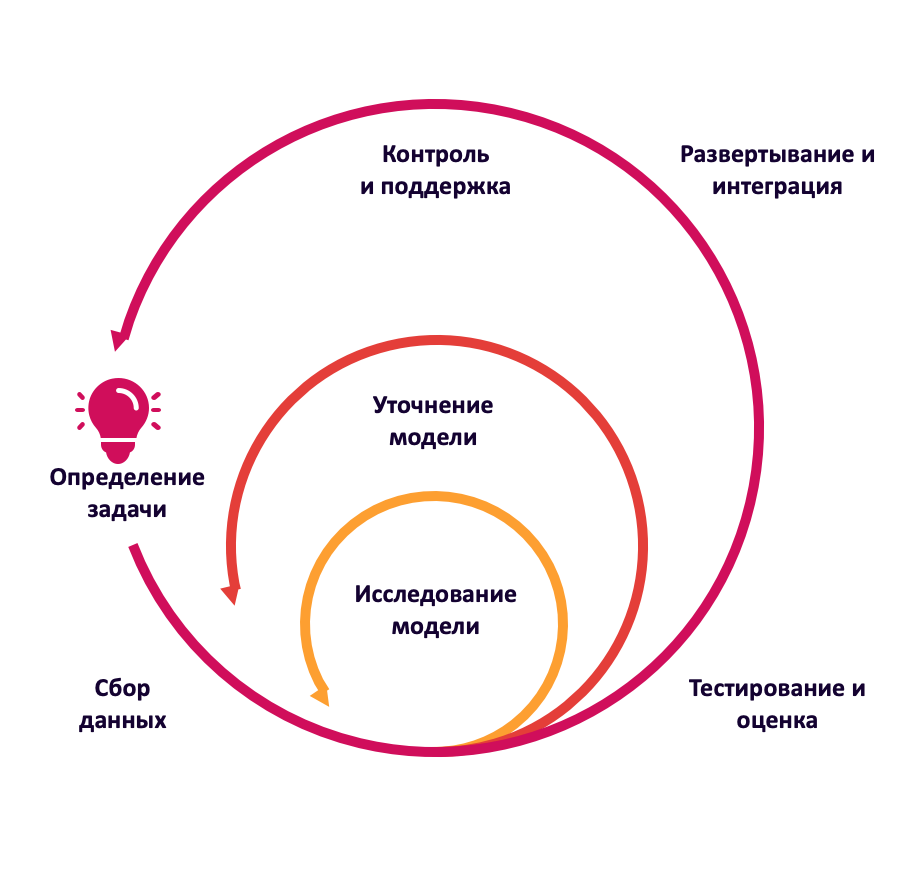
Все это называют жизненным циклом модели. Сначала ставят техническую задачу для дата-сайентистов, которые разрабатывают модели ML. В последствии эту модель обучают на архивных (накопленных) данных, чтобы в дальнейшем она работала с новыми данными. Нужного качества работы модели добиваются в зависимости от поставленной задачи и при необходимости «подкручивают» настроечные параметры пока не достигнут результата.
Благодаря такому адаптивному характеру машинное обучение отлично подходит для сценариев, когда постоянно изменяются данные и свойства запросов, и написать код для решения фактически невозможно.
Зачем ML DevOps
Хотя машинное обучение можно найти повсюду, оно создаёт определенные трудности при внедрении. Одной из них является потребность быстро и надёжно переходить от фазы экспериментов к фазе производства, где обученные модели могут начать оперативно работать, чтобы принести пользу бизнесу.
Индустрия ML предлагает множество инструментов, которые помогают решить эту проблему. Публичные облачные провайдеры имеют свои собственные управляемые решения для обслуживания моделей машинного обучения. В то же время существует множество проектов с открытым исходным кодом. Часть из них бесплатные (open source), часть — платные.
Со всем этим работают дата-сайентисты и MLOps.
MLOps — это стык таких технологий, как DevOps, Machine Learning, Data Engineering. Одни создают ML- модели, другие внедряют их в производство.

Как создавали и использовали модели раньше
Изначально дата-сайентисты вели разработку на своих локальных компьютерах. Порядок их действий был таким:
Создавали модель;
Обучали и подбирали необходимые для запуска параметры;
Сохраняли в виде pkl-файла.
После этого модель готова, но её необходимо ещё и «выкатить». Для этого совершались дополнительные шаги:
На Flask писали «обвязку» для запуска модели в виде REST API сервиса (опять же – врукопашную);
Собирали образ;
Затем на основе образа любым удобным способом создавали сущности в Kubernetes (pod, deployment, replicaset, services and etc).
Обязательно в этом процессе были задействованы и дата-сайентисты, и DevOps-инженеры, потому что постоянно вносились правки и в код модели, и параметры запуска. В частности, при изменении модели приходилось переписывать код для REST API сервиса, пересобирать образ и, возможно, устанавливать новые пакеты, привлекая для консультации дата-сайентистов.
Как удалось оптимизировать процесс
Впоследствии стали использовать один из дополнительных инструментов для запуска моделей — MLflow. Он имеет графический интерфейс и позволяет с помощью UI наблюдать – как модель отрабатывает и с каким результатом. Кроме того, MLflow показывает предыдущие запуски и эксперименты. С помощью него порядок действия изменился:
Дата-сайентист создает модель (в Jupyter-Hub);
Обучает модель, подбирая параметры, в MLflow;
Собирается образ рабочей модели на основе пути к обученной модели и MLflow в режиме сервиса;
Используя этот образ, DevOps создаёт манифесты для запуска в Kubernetes.
Но впоследствии всё равно оставались проблемы: модель только в формате MLflow и язык п��-прежнему только Python. Вдобавок, невозможно было совершать дополнительные действия с данными, поступающими на вход модели. Если же модель менялась, то приходилось пересобирать образ и все делать заново.
Были и другие факторы, которые не устраивали:
• Ограниченность в самих форматах моделей;
• Отсутствие возможности строить из нескольких последовательных моделей pipeline (конвейер), то есть выходные данные одной модели подавать на вход другой, а также невозможность проведения предварительных преобразований входящих данных;
• Отсутствие контроля за работой модели, а также реакции на наличие сбоев;
• Невозможность проведения А/В тестов.
Компании стали искать более современное решение, потому что использовать лишь MLflow неудобно, сложно, затратно c точки зрения человеко-часов.
KFServing vs. Seldon Core
Выбор на рынке был из двух достаточно похожих продуктов:

KFServing
Использует Kubernetes CRD для создания сервиса из моделей. Из основных возможностей выделяют:
● Поддержку моделей различного типа (Tensorflow, XGBoost, ScikitLearn, PyTorch, ONNX);
● Наличие автомасштабирования, в том числе для графического процессора;
● Проверку работоспособности модели и конфигурации сервера при старте;
● Scale to Zero, то есть возможность практически останавливать работу, ожидая данные на входе;
● Canary Rollouts для развернутых сервисов.
Seldon Core
Seldon Core похож на KFServing. Он обладает теми же функциями, но с дополнительными «фичами» и поддержкой чуть большего количества типов моделей. Вдобавок, есть возможность из обычного скрипта (программы на Python, Java, NodeJS) разворачивать готовую модель в виде REST API и работать с ней. Не надо делать кучу промежуточных решений, просто взяли код на Python и запустили его как REST API сервис. Seldon готовит это всё под себя в нужном формате, поэтому никаких дополнительных ухищрений не надо.
Кроме того, он позволяет делать А/В тесты, канареечные выкатки и имеет Outlier Detector (детектор выбросов). Этот детектор проводит проверку входящих данных на схожесть их с теми, на которых модель обучалась. Если модель обучалась, например, на данных по температуре в Арктике, то эта температура никогда не была более +5 градусов. Поэтому, если вдруг выпадет +34, модель выдаст неправильный результат, Outlier Detector это «отловит» и сообщит, что что-то пошло не так. Это удобно, например, для скоринга в банках: когда оцениваются критерии выдачи кредита, модель при необходимости сообщит о том, что входные данные неверные, и не будет всем подряд одобрять кредит.
Благодаря наличию Language Wrapper Seldon Core позволяет из разных языков программирования строить модель.
Также по git у него более частые коммиты, то есть он чаще обновляется и имеет чуть получше документацию, чем в KFServing. Хотя она, честно скажу, не идеальна. Часто ищешь что-то на странице в доках, может выпасть 404 :). Так устроена документация. Но при этом в github у Seldon Core всё есть. Cайт просто не поспевает за ним.
Как использовать Seldon Core для машинного обучения?
Если в общем, то мы продолжим использовать MLflow для логирования экспериментов.
Всем дата-сайентистам известен продукт Jupyter Hub, так как они практически только в нём и работают. Именно здесь происходит создание моделей, их запуск и обучение. Для этого подбираются необходимые параметры запуска и проводится отладка моделей для получения необходимого качества работы. Каждый запуск мониторится в MLflow. В дальнейшем можно посмотреть логи и с какими параметрами модель лучше запустилась. Это нужно для того, чтобы выбрать лучшую по результатам метрик. Для этого просто импортируется библиотека MLflow и модель экспортируется туда.
Дальше стоит графический интерфейс и дата-сайентист может посмотреть – какой запуск его больше устроил.

Допустим, он добился своего – модель отработала как нужно. При достижении необходимых результатов он делает git push, модель сохраняется и отправляется в GitLab для сборки образа будущего контейнера модели. Тут используется утилита от Seldon s2i (Source-to-Image), которая из кода на языке (Python, Java и т.д.) создает рабочий образ в нужном формате, готовый для использования в Seldon Core. Образ можно запустить и отправить на вход тестовые данные (test stage) для проверки успешности сборки.

На выходе мы получаем готовый образ для Seldon: то есть не просто образ для какой-то системы, а образ в том формате, который нужен Seldon. В нём уже настроены эндпойнты, обработаны входные данные и выдан результат. Дальше всё это «пушится» в репу для выкатки в Кубер (деплоится манифест).
В случае успешной сборки, модель «выкатывается» в Kubernetes с необходимыми параметрами с помощью Helm chart (используется Seldon Deployment) и ArgoCD. Так на основе одного единственного манифеста идёт выкатка всех сущностей, необходимых для работы модели в качестве REST API сервиса. Seldon работает на основе Custom resources definition (CRD) в Kubernetes. Он видит тип деплоя (Seldon Deployment) и разворачивает необходимые сервисы, поды – то есть всё, что нужно, чтобы модель заработала.

Во время сборки необходимо задать всего лишь имя модели. Также задается тип модели (router, classifier, splitter) и список используемых ею пакетов. После этого «подкидывается» единственный файл со списком библиотек, который использовал сам дата-сайентист. Для DevOps неважно, что внутри. Дата-сайентист добавляет новую либу, указывает в файле и модель соберется. DevOps-инженер один раз настраивает pipeline и отдаёт его дата-сайентисту. Тот «пушит» в репу, всё это выкатывается с помощью, допустим, ArgoCD на Kubernetes, и можно уже посылать данные в «инстанс», который доступен снаружи на Kubernetes. При этом DevOps-инженер свободен, а дата-сайентист не отвлекается от своей работы. Это достаточно удобно, быстро и очень сильно экономит ресурсы.
Вывод
Подытожим плюсы использования Seldon Core для машинного обучения:
● Самое главное — процесс CI/CD для DevOps стал намного проще;
● Решение Kubernetes native за счет оператора автоматически уменьшает количество шагов во время «деплоя» модели. Нет необходимости привлекать большое количество сотрудников;
● Большая гибкость для использования разного типа моделей и в разных сочетаниях. Возможность создания конвейеров моделей, не прибегая к написанию большого количества кода;
● Интеграция с современными решениями: Istio, Prometheus;
● Логирование и управление из «коробки».
Дополнительно есть возможность в Prometheus следить за нагрузкой и результатом работы моделей. Если мы выкатываем A/B тесты, то можем видеть параметры отработки каждой модели на входных данных.
Это достаточно гибкое решение, потому что дата-сайентисты могут работать на разных языках. В основном это Python, но бывает NodeJS или Java. Образ с рабочей моделью соберется вне независимости от языка, на котором она написана.

