

Это вторая статья из серии введения в «Нейронные сети для начинающих». Здесь и далее мы постараемся разобраться с таким понятием — как обработка графических данных, визуализация данных, а также на практике решим пару простых задач. Предыдущая статья — #1 Нейронные сети для начинающих. Решение задачи классификации Ирисов Фишера
Маленький совет из будущего: «В данной статье будут затронуты некоторые понятия, о которых я писал раньше, так что для полного понимания темы, советую прочитать и предыдущую статью»На самом деле, на хабре было множество публикаций по этой теме, но все они говорят о разных вещах. Давайте разберёмся и соберём всё в одну кучку, для полноценного понимания картины мира.
Традиционно приведу небольшой перечень тем, которые будут освещены в этой статье:
- Знакомство с библиотекой NumPy.
- Знакомство с библиотекой MatplotLib.
- Поверхностное знакомство с библиотекой OpenCV.
Чтобы не терять зря времени, давайте приступим.
Знакомство с библиотекой NumPy
NumPy — библиотека с открытым исходным кодом для языка программирования Python. Возможности: поддержка многомерных массивов; поддержка высокоуровневых математических функций, предназначенных для работы с многомерными массивами.NumPy включает в себя несколько основных концепций массива:
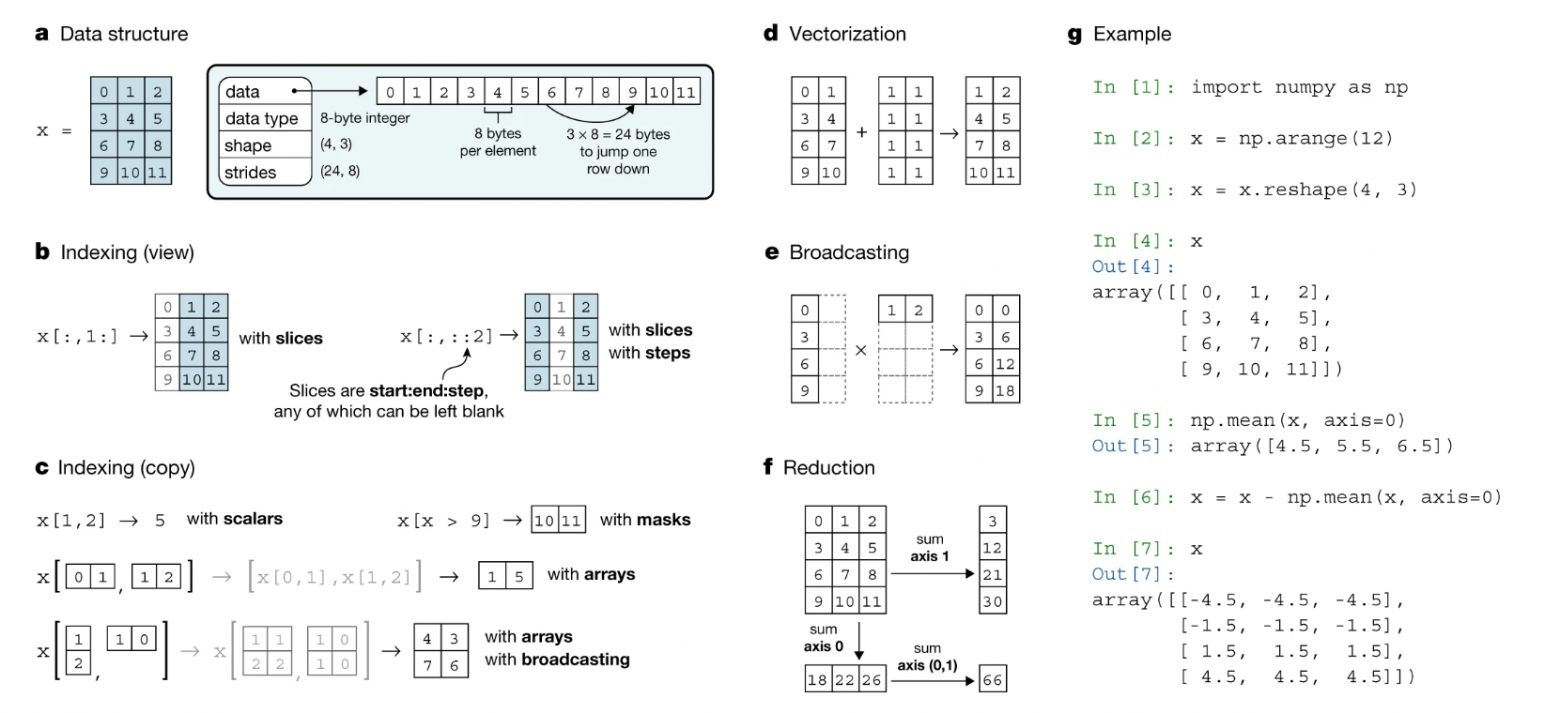
Пояснения к рисунку:
- a. Структура данных массива NumPy и связанные с ней поля метаданных.
- b. Индексирование массива срезами и шагами. Эти операции возвращают «представление» исходных данных.
- c. Индексация массива с масками, скалярными координатами или другими массивами, чтобы он возвращал «копию» исходных данных. В нижнем примере массив индексируется с другими массивами; это передаёт аргументы индексирования перед выполнением поиска.
- d. Векторизация эффективно применяет операции к группам элементов.
- e. Вещание при умножении двумерных массивов.
- f. Операции редукции действуют по одной или нескольким осям. В этом примере массив суммируется по выбранным осям для получения вектора или последовательно по двум осям для получения скаляра.
- g. Здесь есть пример кода NumPy, иллюстрирующий некоторые из этих концепций.
▍Пришло время разобраться с базовыми операциями над массивами
Небольшая оговорочка — математические операции над массивами выполняются поэлементно. Создаётся новый массив, который заполняется результатами действия оператора.И теперь сразу к коду:
import numpy as np # в программировании на Python библиотеку NumPy для удобства "обзывают" - np a = np.array([20, 30, 40, 50]) b = np.arange(4) a + b # array([20, 31, 42, 53]) a - b # array([20, 29, 38, 47]) a * b # array([ 0, 30, 80, 150]) a / b # При делении на 0 возвращается inf (бесконечность) a ** b # array([ 1, 30, 1600, 125000]) a % b # При взятии остатка от деления на 0 возвращается 0
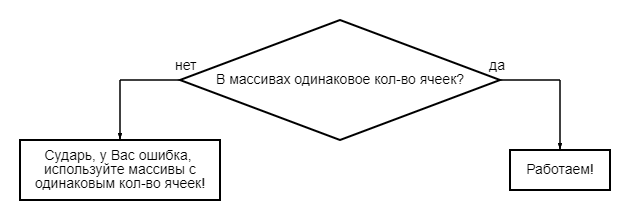
c = np.array([[1, 2, 3], [4, 5, 6]]) d = np.array([[1, 2], [3, 4], [5, 6]]) c + d # Вывод: # Traceback (most recent call last): # File "<input>", line 1, in <module> # ValueError: operands could not be broadcast together with shapes (2,3) (3,2)
Почему же так происходит? Ответ очень прост: массивы должны быть одинаковых размеров. Это то же самое, что в бутылку на 1.5 литра, пытаться перелить 5 литровую и наоборот, их нельзя считать равными, а как следствие, нельзя и совмещать. Всё просто:
В NumPy можно производить математические операции между массивом и числом. В этом случае к каждому элементу прибавляется (или что вы там делаете) это число:
a + 1 # array([21, 31, 41, 51]) a ** 3 # array([ 8000, 27000, 64000, 125000]) a < 35 # array([ True, True, False, False], dtype=bool)
NumPy также предоставляет множество математических операций для обработки массивов:
np.cos(a) # array([ 0.40808206, 0.15425145, -0.66693806, 0.96496603]) np.arctan(a) # array([ 1.52083793, 1.53747533, 1.54580153, 1.55079899]) np.sinh(a) # array([ 2.42582598e+08, 5.34323729e+12, 1.17692633e+17, 2.59235276e+21])
Подробнее со списком математических операций можно ознакомиться здесь.
Многие унарные операции, такие как, например, вычисление суммы всех элементов массива, представлены также и в виде методов класса ndarray:
a = np.array([[1, 2, 3], [4, 5, 6]]) np.sum(a) # 21 a.sum() # 21 a.min() #1 a.max() # 6
По умолчанию эти операции применяются к массиву, как если бы он был списком чисел, независимо от его формы. Однако, указав параметр axis, можно применить операцию для указанной оси массива:
a.min(axis=0) # Наименьшее число в каждом столбце: array([1, 2, 3]) a.min(axis=1) # Наименьшее число в каждой строке: array([1, 4])
▍ Встаёт вопрос, а в чём практическая польза таких массивов?
Давайте разберёмся. Представим, что мы хотим по-быстрому посмотреть, как выглядит график какой-то функции. Для определённости возьмём сигмоиду, часто используемую в качестве функции активации в нейронных сетях.
Рисовать будем при помощи библиотеки Matplotlib, с которой подробнее познакомимся далее. Путём написания небольшого скрипта на Python, мы сможем получить преинтереснейший результат:
# vim: set ai et ts=4 sw=4: import matplotlib.pyplot as plt import numpy as np x = np.linspace(-5, 5, 100) def sigmoid(alpha): return 1 / ( 1 + np.exp(- alpha * x) ) def main(): dpi = 80 fig = plt.figure(dpi = dpi, figsize = (512 / dpi, 384 / dpi) ) plt.plot(x, sigmoid(0.5), 'ro-') plt.plot(x, sigmoid(1.0), 'go-') plt.plot(x, sigmoid(2.0), 'bo-') plt.legend(['A = 0.5', 'A = 1.0', 'A = 2.0'], loc = 'upper left') fig.savefig('sigmoid.png') main()
Если запустить наш код, то мы получим вот такое изображение с названием 'sigmoid.png':
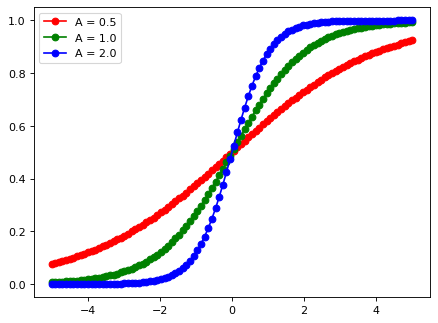
Заметьте, что больше не нужно писать циклы, вычисляющие значение функции в различных точках, поскольку NumPy делает всё это за нас. Фактически мы просто применяем функции к функциям и выводим получившиеся функции. Декларативное и чисто функциональное программирование в самом натуральном его виде!
Как видите, библиотека NumPy оказалась крайне полезной в целом ряде задач. И это мы рассмотрели далеко не все её возможности. В качестве источников дополнительной информации можно порекомендовать книги, NumPy посвящено точно больше одной.
Считается, что NumPy потребляет меньше памяти и работает до 10 раз быстрее аналогичного кода, написанного на чистом Python. Здесь я решил не приводить никаких бенчмарков, потому что тут есть масса нюансов, и всё сильно зависит от специфики конкретного приложения (объёмы данных, размеры массивов и т.д.). А доводилось ли вам использовать NumPy, и если да, то для решения каких задач? Напишите свой опыт в комментариях!
Знакомство с библиотекой MatplotLib
Matplotlib — библиотека на языке программирования Python для визуализации данных двумерной графикой. Получаемые изображения могут быть использованы в качестве иллюстраций в публикациях. Matplotlib написан и поддерживался в основном Джоном Хантером и распространяется на условиях BSD-подобной лицензии.Перед тем как углубиться в дебри библиотеки Matplotlib, для того чтобы появилось интуитивное понимание принципов работы с этим инструментом, рассмотрим несколько примеров, изучив которые вы уже сможете использовать библиотеку для решения своих задач.
Если вы работаете в Jupyter Notebook, для того чтобы получать графики рядом с ячейками, с кодом необходимо выполнить специальную magic-команду после того как импортируете matplotlib:
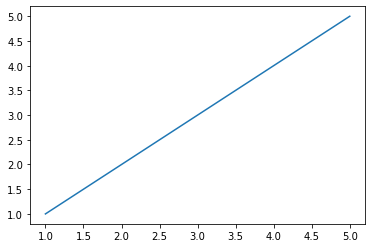
# Построим график прямой, используя MatplotLib import matplotlib.pyplot as plt %matplotlib inline plt.plot([1, 2, 3, 4, 5], [1, 2, 3, 4, 5])
Результат будет следующим:
Если вы пишете код в .py файле, а потом запускаете его через вызов интерпретатора Python, то строка %matplotlib inline вам не нужна, используйте только импорт библиотеки.
Пример, аналогичный тому, что представлен на рисунке выше, для отдельного Python файла будет выглядеть так:
import matplotlib.pyplot as plt plt.plot([1, 2, 3, 4, 5], [1, 2, 3, 4, 5]) plt.show()
Результатом будет тот же самый график, но в отдельном окне.
▍ Построение графика и результат
Для начал построим простую линейную зависимость, дадим нашему графику название, подпишем оси и отобразим сетку. Код программы:
import numpy as np # Независимая (x) и зависимая (y) переменные x = np.linspace(0, 10, 50) y = x # Построение графика plt.title("Линейная зависимость y = x") # заголовок plt.xlabel("x") # ось абсцисс plt.ylabel("y") # ось ординат plt.grid() # включение отображения сетки plt.plot(x, y) # построение графика
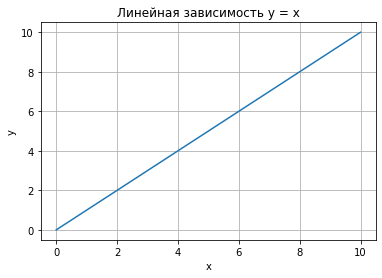
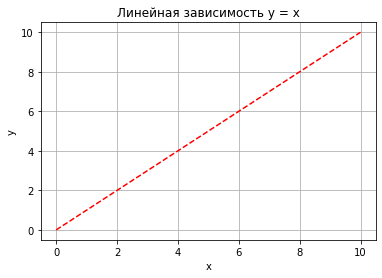
Изменим тип линии и её цвет, для этого в функцию
plot(), в качестве третьего параметра передадим строку, сформированную определённым образом, в нашем случае это “r–”, где “r” означает красный цвет, а “–” – тип линии – пунктирная линия. Код программы:# Построение графика plt.title("Линейная зависимость y = x") # заголовок plt.xlabel("x") # ось абсцисс plt.ylabel("y") # ось ординат plt.grid() # включение отображения сетки plt.plot(x, y, "r--") # построение графика
▍ Несколько графиков на одном поле
Вам не кажется, что графику одному будет скучно? Построим несколько графиков на одном поле, для этого добавим квадратичную зависимость:
# Линейная зависимость x = np.linspace(0, 10, 50) y1 = x # Квадратичная зависимость y2 = [i**2 for i in x] # Построение графика plt.title("Зависимости: y1 = x, y2 = x^2") # заголовок plt.xlabel("x") # ось абсцисс plt.ylabel("y1, y2") # ось ординат plt.grid() # включение отображения сетки plt.plot(x, y1, x, y2) # построение графика
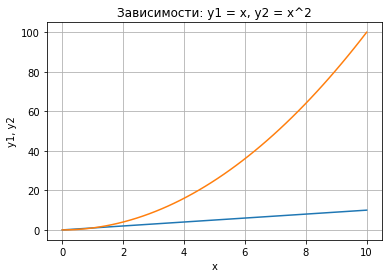
В приведённом примере в функцию
plot() последовательно передаются два массива для построения первого графика и два массива для построения второго, при этом как вы можете заметить, для обоих графиков массив значений независимой переменной x один и то же.▍ Несколько разделённых полей с графиками
Третья, довольно часто встречающаяся задача – это отобразить два или более различных поля, на которых будет отображено по одному или более графику.
Построим уже известные нам две зависимость на разных полях:
# Линейная зависимость x = np.linspace(0, 10, 50) y1 = x # Квадратичная зависимость y2 = [i**2 for i in x] # Построение графиков plt.figure(figsize=(9, 9)) plt.subplot(2, 1, 1) plt.plot(x, y1) # построение графика plt.title("Зависимости: y1 = x, y2 = x^2") # заголовок plt.ylabel("y1", fontsize=14) # ось ординат plt.grid(True) # включение отображения сетки plt.subplot(2, 1, 2) plt.plot(x, y2) # построение графика plt.xlabel("x", fontsize=14) # ось абсцисс plt.ylabel("y2", fontsize=14) # ось ординат plt.grid(True) # включение отображения сетки
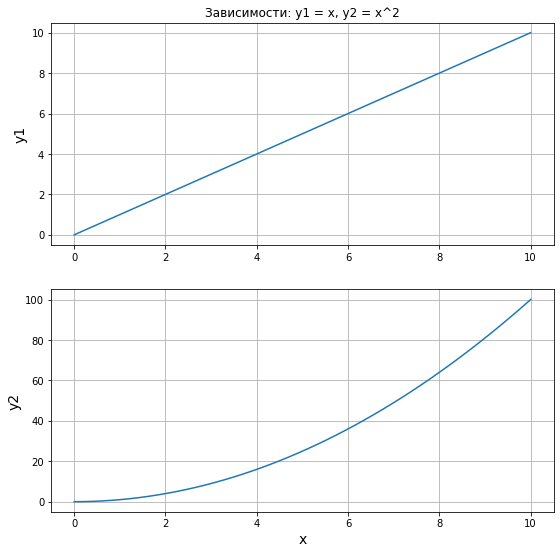
Здесь используем новые функции:
- figure() – функция для задания глобальных параметров отображения графиков. В неё, в качестве аргумента, передаём кортеж, определяющий размер общего поля.
- subplot() – функция для задания местоположения поля с графиком. Существует несколько способов задания областей для вывода через функцию subplot() мы воспользовались следующим: первый аргумент – количество строк, второй – столбцов в формируемом поле, третий – индекс (номер поля, считаем сверху вниз, слева направо).
Остальные функции уже нам знакомы, дополнительно мы использовали параметр fontsize для функций
xlabel() и ylabel(), для задания размера шрифта.▍ Построение диаграммы для категориальных данных
До этого у нас были графики по численным данным, т.е. зависимая и независимая переменные имели числовой тип. На практике довольно часто приходится работать с данными нечисловой природы – имена людей, название фруктов, и т.п.
Построим диаграмму, на которой будет отображаться количество фруктов в магазине:
fruits = ["apple", "peach", "orange", "bannana", "melon"] counts = [34, 25, 43, 31, 17] plt.bar(fruits, counts) plt.title("FRUETS") plt.xlabel("Fruit") plt.ylabel("Count")
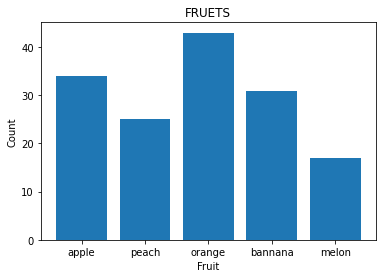
Для вывода диаграммы используем функцию
bar().К этому моменту, если вы самостоятельно попробовали запустить приведённые выше примеры, у вас уже должно сформировать некоторое понимание того, как осуществляется работа с этой библиотекой.
▍ Основные элементы графика
Рассмотрим основные термины и понятия, касающиеся изображения графика, с которыми вам необходимо будет познакомиться, для того чтобы в дальнейшем у вас не было трудностей при прочтении материалов из этого цикла статей и документации по библиотеке matplotlib.
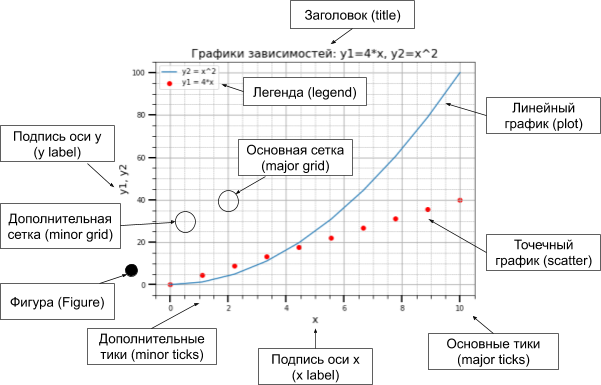
Корневым элементом при построении графиков в системе Matplotlib является Фигура (Figure). Всё, что нарисовано на рисунке выше, является элементами фигуры. Рассмотрим её составляющие более подробно:
График: на рисунке представлены два графика – линейный и точечный. Matplotlib предоставляет огромное количество различных настроек, которые можно использовать для того, чтобы придать графику вид, который вам нужен: цвет, толщина и тип линии, стиль линии и многое другое, всё это мы рассмотрим в ближайших статьях.Ниже представлен код, с помощью которого была построена фигура, изображённая на рисунке:
Оси: вторым, после непосредственно самого графика, по важности элементом фигуры являются оси. Для каждой оси можно задать метку (подпись), основные (major) и дополнительные (minor) тики, их подписи, размер и толщину, также можно задать диапазоны по каждой из осей.
Сетка и легенда: следующими элементами фигуры, которые значительно повышают информативность графика, являются сетка и легенда. Сетка также может быть основной (major) и дополнительной (minor). Каждому типу сетки можно задавать цвет, толщину линии и тип. Для отображения сетки и легенды используются соответствующие команды.
import matplotlib.pyplot as plt from matplotlib.ticker import (MultipleLocator, FormatStrFormatter, AutoMinorLocator) import numpy as np x = np.linspace(0, 10, 10) y1 = 4*x y2 = [i**2 for i in x] fig, ax = plt.subplots(figsize=(8, 6)) ax.set_title("Графики зависимостей: y1=4*x, y2=x^2", fontsize=16) ax.set_xlabel("x", fontsize=14) ax.set_ylabel("y1, y2", fontsize=14) ax.grid(which="major", linewidth=1.2) ax.grid(which="minor", linestyle="--", color="gray", linewidth=0.5) ax.scatter(x, y1, c="red", label="y1 = 4*x") ax.plot(x, y2, label="y2 = x^2") ax.legend() ax.xaxis.set_minor_locator(AutoMinorLocator()) ax.yaxis.set_minor_locator(AutoMinorLocator()) ax.tick_params(which='major', length=10, width=2) ax.tick_params(which='minor', length=5, width=1) plt.show()
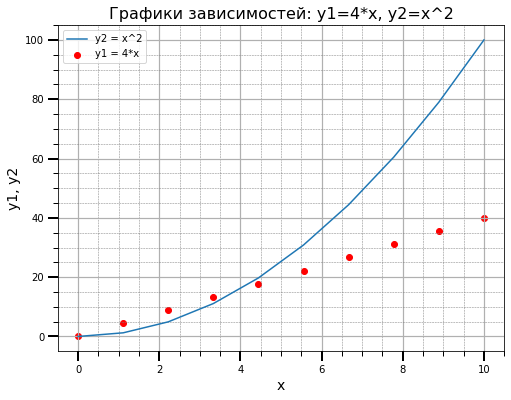
На этом закончим наше базовое знакомство с основными методами библиотеки MatplotLib.
Поверхностное знакомство с библиотекой OpenCV
OpenCV — библиотека алгоритмов компьютерного зрения, обработки изображений и численных алгоритмов общего назначения с открытым кодом. Реализована на C/C++, также разрабатывается для Python, Java, Ruby, Matlab, Lua и других языков.OpenCV выпускается под лицензией BSD (лицензия Berkeley Software Distribution), поэтому её можно бесплатно использовать в научных и коммерческих целях. OpenCV имеет интерфейсы C ++, Python и Java и поддерживает Windows, Linux, Mac OS, iOS и Android. OpenCV предназначен для повышения эффективности вычислений, ориентируясь на приложения реального времени. Библиотека написана на оптимизированном C / C ++ и может использовать преимущества многоядерной обработки.
OpenCV принят во всём мире, с сообществом из более чем 47 000 пользователей и оценочной загрузкой более 14 миллионов. Использует диапазон от интерактивного искусства до инспекции мин, онлайн-карт мозаики или продвинутых роботов.
OpenCV можно использовать для разработки программ обработки изображений в реальном времени, компьютерного зрения и распознавания образов в следующих областях:
- Дополненная реальность.
- Распознавание лиц.
- Распознавание жестов
- Человеко-компьютерное взаимодействие.
- Распознавание действий.
- Отслеживание движения.
- Распознавание объектов.
- Раздел изображения.
- Роботы.
Чтобы установить OpenCV, необходимо ввести в консоль команду:
pip install opencv-python
Для того чтобы проверить, установилась ли библиотека, необходимо в командной строке/консоли написать «python» и в открывшемся редакторе написать «import cv2», если ошибок/подсказок не выведется, то я могу Вас поздравить, вы установили OpenCV!
Для проверки работоспособности окружения и самой библиотеки, напишем небольшой скрипт, который обращается к камере Вашего компьютера/ноутбука и выводит на экран потоковое видео с неё:
# Импорт import numpy as np import cv2 # Позвоните в камеру компьютера, 0: первая основная камера cap = cv2.VideoCapture(0) while(True): # Capture frame-by-frame ret, frame = cap.read() # Преобразование цветового пространства gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) # Отображение изображения cv2.imshow('frame', frame) cv2.imshow('gray',gray) # Конец, клавиша q if cv2.waitKey(1) & 0xFF == ord('q'): break # Закройте вызывающую программу камеры и закройте все окна изображений cap.release() cv2.destroyAllWindows()
Результат Вы можете проверить, запустив этот скрипт у себя на компьютере.
▍Немного про пиксели и цветовые пространства
Перед тем как перейти к практике, нам нужно разобраться немного с теорией. Каждое изображение состоит из набора пикселей. Пиксель — это строительный блок изображения. Если представить изображение в виде сетки, то каждый квадрат в сетке содержит один пиксель, где точке с координатой ( 0, 0 ) соответствует верхний левый угол изображения. К примеру, представим, что у нас есть изображение с разрешением 400x300 пикселей. Это означает, что наша сетка состоит из 400 строк и 300 столбцов. В совокупности в нашем изображении есть 400*300 = 120000 пикселей.
В большинстве изображений пиксели представлены двумя способами: в оттенках серого и в цветовом пространстве RGB. В изображениях в оттенках серого каждый пиксель имеет значение между 0 и 255, где 0 соответствует чёрному, а 255 соответствует белому. А значения между 0 и 255 принимают различные оттенки серого, где значения ближе к 0 более тёмные, а значения ближе к 255 более светлые.
Цветные пиксели обычно представлены в цветовом пространстве RGB(red, green, blue — красный, зелёный, синий), где одно значение для красной компоненты, одно для зелёной и одно для синей. Каждая из трёх компонент представлена целым числом в диапазоне от 0 до 255 включительно, которое указывает как «много» цвета содержится. Исходя из того, что каждая компонента представлена в диапазоне [0,255], то для того, чтобы представить насыщенность каждого цвета, нам будет достаточно 8-битного целого беззнакового числа. Затем мы объединяем значения всех трёх компонент в кортеж вида (красный, зелёный, синий). К примеру, чтобы получить белый цвет, каждая из компонент должна равняться 255: (255, 255, 255). Тогда, чтобы получить чёрный цвет, каждая из компонент должна быть равной 0: (0, 0, 0). Ниже приведены распространённые цвета, представленные в виде RGB кортежей:

▍ Обнаружение объектов с помощью цветовой сегментации изображений в Python
Теперь займёмся уже чем-нибудь более интересным, помимо скучной теории, а именно преисполнимся в оконтуривании с помощью Python и OpenCV.
Несколько важных понятий:
Контуры — контуром называется кривая, которая объединяет все непрерывные точки (по границе) одного цвета или интенсивности. Контуры являются весьма полезными инструментами для анализа форм, обнаружения и распознавания объектов.Теперь у вас есть всё необходимое для работы. Знакомство с цветовой сегментацией мы начнём с простого примера. Потерпите, скоро будет самое интересное.
Пороговые значения — пороговая обработка полутонового изображения (в оттенках серого) превращает его в бинарное. Вы задаёте некое пороговое значение, и все значения ниже порога становятся чёрными, а выше — белыми.
Возьмём в качестве примера круг Омбре:

Для чего? Всё просто, он мне нравится и хорошо пригодится в качестве примера.
В коде ниже я поделю данное изображение на 17 уровней серого. Затем измерю площадь каждого уровня с помощью оконтуривания:
import cv2 import numpy as np def viewImage(image): cv2.namedWindow(‘Display’, cv2.WINDOW_NORMAL) cv2.imshow(‘Display’, image) cv2.waitKey(0) cv2.destroyAllWindows() def grayscale_17_levels (image): high = 255 while(1): low = high — 15 col_to_be_changed_low = np.array([low]) col_to_be_changed_high = np.array([high]) curr_mask = cv2.inRange(gray, col_to_be_changed_low,col_to_be_changed_high) gray[curr_mask > 0] = (high) high -= 15 if(low == 0 ): break image = cv2.imread(‘./path/to/image’) viewImage(image) gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) grayscale_17_levels(gray) viewImage(gray)
Это же изображение, разделённое на 17 уровней серого:

def get_area_of_each_gray_level(im): ## преобразование изображения к оттенкам серого (обязательно делается до оконтуривания) image = cv2.cvtColor(im, cv2.COLOR_BGR2GRAY) output = [] high = 255 first = True while(1): low = high — 15 if(first == False): # Делаем значения выше уровня серого чёрными. Так они не будут обнаруживаться to_be_black_again_low = np.array([high]) to_be_black_again_high = np.array([255]) curr_mask = cv2.inRange(image, to_be_black_again_low, to_be_black_again_high) image[curr_mask > 0] = (0) # Делаем значения этого уровня белыми. Так мы рассчитаем их площадь ret, threshold = cv2.threshold(image, low, 255, 0) contours, hirerchy = cv2.findContours(threshold, cv2.RETR_LIST, cv2.CHAIN_APPROX_NONE) if(len(contours) > 0): output.append([cv2.contourArea(contours[0])]) cv2.drawContours(im, contours, -1, (0,0,255), 3) high -= 15 first = False if(low == 0 ): break return output
В этой функции я выполняю преобразование шкалы (интенсивности) серого, которую планирую оконтурить (выделить). Для этого я задаю одинаковое значение интенсивности всем уровням, находящимся в диапазоне данной шкалы. Остальная интенсивность (меньшая и большая) становится чёрной.
Второй шаг — это пороговая обработка изображения. Она делается для того, чтобы цвет, который я сейчас буду оконтуривать, стал белым, а всё остальные части окрасились в чёрный. Этот шаг мало что меняет, но выполнение его обязательно, поскольку лучше всего оконтуривание работает на чёрно-белых (пороговых) изображениях.
До выполнения пороговой обработки наше изображение будет выглядеть так же, с той лишь разницей, что белое кольцо окрашено серым (интенсивность серого из 10-го уровня (255–15*10)).
Показывается только 10–й сегмент для расчёта его площади:

image = cv2.imread(‘./path/to/image’) print(get_area_of_each_gray_level(image)) viewImage(image)
Контуры 17 уровней серого в исходном изображении:

Массив со значениями площадей:

Так мы получаем площади каждого уровня серого.
▍ Обнаружение объектов
Возьмём, в качестве примера, изображение обычного листика, например, вот такого:

Здесь мы будем оконтуривать листок. Текстура изображения неровная и неоднородная. Несмотря на то что на картинке не так много цветов, интенсивность зелёного также меняет и его яркость. Поэтому правильнее всего будет унифицировать зелёный цвет и свести его к одному оттенку. Тогда при оконтуривании лист будет рассматриваться единым объектом.
Примечание: ниже представлен результат оконтуривания без предварительной обработки изображения. Я хотел показать вам, как неравномерная структура листа мешает OpenCV понять, что на картинке изображён один объект. Оконтуривание без предварительной обработки. Обнаружен 531 контур:

import cv2 import numpy as np def viewImage(image): cv2.namedWindow(‘Display’, cv2.WINDOW_NORMAL) cv2.imshow(‘Display’, image) cv2.waitKey(0) cv2.destroyAllWindows()
Для начала необходимо определить HSV-представление цвета. Это можно сделать путём преобразования его RGB в HSV:
# Получаем HSV-представление для зелёного цвета green = np.uint8([[[0, 255, 0 ]]]) green_hsv = cv2.cvtColor(green,cv2.COLOR_BGR2HSV) print( green_hsv)
Зелёный HSV цвет: [[[60 255 255]]]
Конвертация изображения в HSV. С HSV проще получить полный диапазон одного цвета. H здесь означает Hue (тон), S — Saturation (насыщенность), а V — Value (значение). Мы уже знаем, что зелёный цвет — это [60, 255, 255]. Весь зелёный цвет в мире находится в диапазоне с [45, 100, 50] по [75, 255, 255], то есть с [60–15, 100, 50] по [60+15, 255, 255]. 15 — это примерное значение.
Мы берём этот диапазон и превращаем его в [75, 255, 200] или любой другой светлый цвет (третье значение должно быть сравнительно большим). Последняя цифра представляет собой яркость цвета — как раз та величина, которая «покрасит» данную область в белый после порогового преобразования изображения:
image = cv2.imread(‘./path/to/image.jpg’) hsv_img = cv2.cvtColor(image, cv2.COLOR_BGR2HSV) viewImage(hsv_img) # 1 green_low = np.array([45 , 100, 50] ) green_high = np.array([75, 255, 255]) curr_mask = cv2.inRange(hsv_img, green_low, green_high) hsv_img[curr_mask > 0] = ([75,255,200]) viewImage(hsv_img) # 2 # Преобразование HSV-изображения к оттенкам серого для дальнейшего оконтуривания RGB_again = cv2.cvtColor(hsv_img, cv2.COLOR_HSV2RGB) gray = cv2.cvtColor(RGB_again, cv2.COLOR_RGB2GRAY) viewImage(gray) # 3 ret, threshold = cv2.threshold(gray, 90, 255, 0) viewImage(threshold) # 4 contours, hierarchy = cv2.findContours(threshold,cv2.RETR_TREE,cv2.CHAIN_APPROX_SIMPLE) cv2.drawContours(image, contours, -1, (0, 0, 255), 3) viewImage(image) # 5
 Изображение после конвертации в HSV
Изображение после конвертации в HSV Изображение после наложения маски для унификации цвета
Изображение после наложения маски для унификации цвета Изображение после преобразования HSV к оттенкам серого
Изображение после преобразования HSV к оттенкам серого Пороговое изображение, последний этап
Пороговое изображение, последний этап Конечное оконтуривание
Конечное оконтуриваниеНа заднем плане всё ещё заметна неоднородность. С этим методом мы создадим самый крупный контур, и это — конечно же, лист.
Индекс контура листа можно получить из массива contours. Оттуда же берём площадь и центр листа.
Контуры обладают и другими признаками, которые можно использовать в работе: периметр контура, выпуклая оболочка, ограничивающий прямоугольник и т.д.
def findGreatesContour(contours): largest_area = 0 largest_contour_index = -1 i = 0 total_contours = len(contours) while (i < total_contours ): area = cv2.contourArea(contours[i]) if(area > largest_area): largest_area = area largest_contour_index = i i+=1 return largest_area, largest_contour_index # Чтобы получить центр контура cnt = contours[13] M = cv2.moments(cnt) cX = int(M[“m10”] / M[“m00”]) cY = int(M[“m01”] / M[“m00”]) largest_area, largest_contour_index = findGreatesContour(contours) print(largest_area) print(largest_contour_index) print(len(contours)) print(cX) print(cY)
Результат вывода операторов:
278482.5 13 34 482 603
Некоторый итог
Хух, мы с Вами проделали огромную работу, познакомились с тем, что такое библиотеки NumPy, MatplotLib, поработали с ними, освоив базовые операции, а также мы с Вами поработали и «потыкали» основу основ компьютерного зрения — библиотеку OpenCV, с которой будем работать и в дальнейших статьях. Я считаю, что мы с вами, начинающими датасаентистами, проделали колоссальную работу и достойны аплодисментов. Если что-то осталось непонятно, то я выложу весь код в формате Jupyter Notebook и обычного Python файла у себя на GitHub, скачайте понравившийся формат файла и «потыкайте» его, пройдите по нему ещё раз и я уверен, что всё сразу станет понятно!

