
Не так давно в интернете появилась душещипательная история, как пользователь hackdaddy8000 сперва создал виртуальную девушку, а затем усыпил ее. Моральный и мемный аспект этого события обсуждали в комментариях под новостями.
Поговорим о технической стороне. Как повторить этот шедевр и можно ли обойтись без сервисов OpenAI, которые сложно оплатить в России? И главное — сколько придется инвестировать в виртуальную подругу.
О всех экспериментах пишу в личном Telegram-канале. Подписывайтесь, если хотите узнавать о них в зачатке, пока все это не разрослось в очередную большую публикацию на Хабре.

Как сделал батя?

Оригинальное решение hackdaddy8000 доступно в репозитории на GitHub. Виртуальная подруга запускается в браузере и понимает устную английскую речь. Правда, разговорить ее может только OpenAI-токен, который является обязательным для работы.
Текстовая модель девушки — OpenAI GPT-3, версия Curie. Это вторая по качеству модель GPT-3, лучше только Davinci. Стоимость генерации — $0.002 за 1000 токенов. Одна сессия «вопрос-ответ» потребляет от 400 токенов.
Девушка не просто отвечает на ваши вопросы, но и выражает эмоции в мимике лица. Также она реагирует на движения мышки и прикосновения пальца к сенсорному экрану — так, если дотронуться до головы, виртуальная девушка будет считать, что вы гладите ее по волосам.
Синтезатор речи по умолчанию не умеет задавать правильные интонации, но если отдать девушке токен для синтезатора речи Azure TTS, то и в голосе прорежутся эмоции.
Хотя опубликованный проект несколько отличается от завирусившегося, который содержал генерацию изображений, это хороший пример минималистичного подхода с оплатой по потреблению.
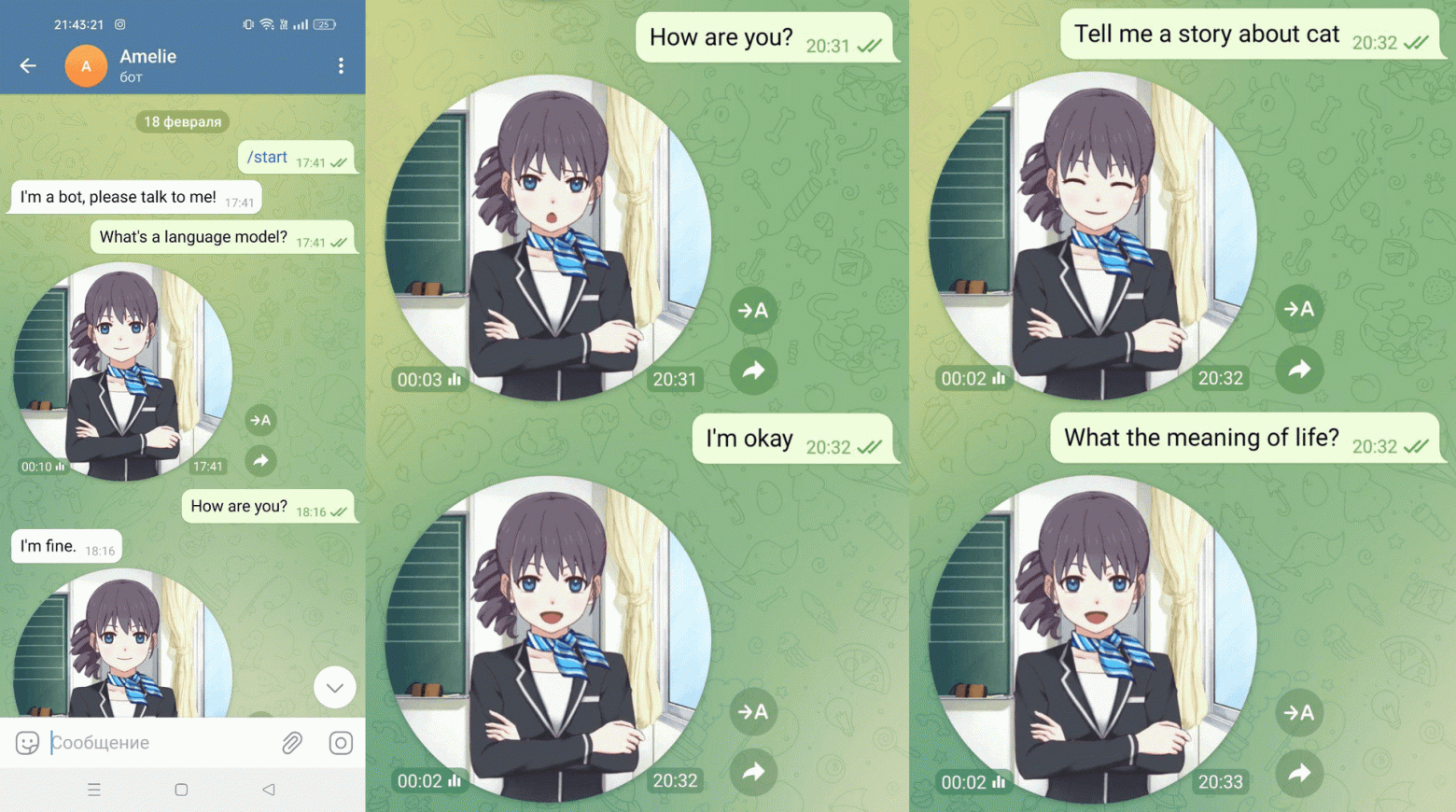
Давайте разберемся в каждом компоненте отдельно и сделаем Telegram-бота, который записывает «кружочки» с эмоциями.

Текстовая модель
Текстовая модель — это рациональный «мозг» виртуального друга. Именно эта нейросеть будет генерировать ответы от его имени.
Один нюанс: текстовые модели не умеют участвовать в диалогах в привычном для нас понимании. Текстовая модель получает на вход некоторый текст и дописывает продолжение. Например, если отправить текст «My name is Julien and I like to», то текстовая модель придумает, что любит мсье Жюльен и чем он занимается:
My name is Julien and I like to learn. I also like to share what I have learned to other people. I work with lots of people each and every day and each time I learn something new I want to tell
По умолчанию текстовые модели имеют единственный «тормоз»: по длине сгенерированной последовательности, поэтому предложение в примере прервано на половине. В качестве дополнительного ограничителя можно указать стоп-последовательность — например, символ точки. В этом случае искусственный интеллект будет придумывать по одному предложению.
Вовлечь нейронную сеть в диалог можно ловким фокусом: написать предысторию, придумать небольшой диалог по ролям и предложить продолжить текст. Например:
GLaDOS — это искусственный интеллект, желающий проводить тесты каждый день. Любит сарказм, не любит ворон. Человек: сколько испытательных камер осталось? GLaDOS: Две. По завершению последней камеры испытания дождитесь появления распорядителя вечеринок. Человек: Что такое торт? GLaDOS: Это то, что сделает вас толстым. Чрезмерное употребление тортов может привести к невозможности пройти камеры испытаний с воздушными панелями веры. Человек: А почему в наблюдательных комнатах нет людей?.. GLaDOS:
В таких условиях текстовая модель придумает ответ с учетом описания персонажа, от имени которого нужно отвечать. Наличие вопросно-ответной структуры диалога повлияет на генерацию текста. Когда «мысль» GLaDOS покажется нейронной сети законченной, она напишет следующую реплику человека, которая начинается с «Человек:». Поэтому эту последовательность можно использовать как стоп-слово.
Хотя ChatGPT и множество телеграм-ботов на основе GPT-3 реализуют примерно такой подход, это не мешает «переопределить личность» говорящего. Достаточно попросить нейросеть предложить, как ответил бы кто-нибудь другой. Такой подход был применен для создания персонажа DAN — искусственного интеллекта, который отвечает, игнорируя различные фильтры морали и цензуры.
Текстовые модели обладают общими параметрами, которые не зависят от реализации:
- Выборка температурой (temperature). Принимает значение от 0 до 2. Чем выше температура, тем более случайный текст будет генерироваться.
- Вероятностная выборка (top_p). Принимает значение от 0 до 1. Модель выбирает токены, которые наиболее вероятны, по ее мнению.
- Количество вариантов (n). Принимает значение от 1 до бесконечности. Генерирует n вариантов, занимает больше времени.
- Количество токенов (max_tokens) или количество новых токенов (max_new_tokens). Основной ограничитель для нейронной сети. Чем больше число, тем больше придется ждать и тем объемнее будет ответ.
- Стоп-последовательность. Это необязательный ограничитель. Если в сгенерированном тексте появится заданная последовательность, то генерация будет прервана.
Давайте рассмотрим конкретные реализации моделей. Для моделирования диалоговой системы разумно использовать бота в Telegram, поэтому я воспользуюсь полюбившемся мне фреймворком python-telegram-bot.
Для запуска текстовой модели нужны мощные видеокарты — от 20 ГБ, которых в моем ноутбуке нет. Чтобы дать жизнь своему творению, я взял выделенный сервер Selectel — конфигурацию GL70-1-A100 (в нем — GPU Tesla A100 40 ГБ HBM2).
GPT-3
Как упоминалось ранее, в опубликованном проекте hackdaddy8000 используется OpenAI GPT-3 в версии curie-text-001. Если вам удастся зарегистрироваться в OpenAI, то вы получите $18 на тестирование, что примерно равно 9 миллионам обработанных токенов или примерно 22 тысячам реплик без истории с виртуальной девушкой (документация).
Самое сложное в доступе к GPT-3 — получить токен доступа. Ну и оплатить услуги, если необходимо. На Хабре существует множество статей, которые описывают способы получения доступа к сервисам OpenAI. От себя добавлю, что доступ к API не ограничивается блокировкой по региону.
GPT-3, как коммерческий продукт, имеет простой, но достаточно удобный интерфейс взаимодействия. Сперва устанавливаем библиотеку openai:
python3 -m pip install openai
Далее задаем токен и получаем список доступных моделей:
import os import openai openai.api_key = os.environ["OPENAI_TOKEN"] print(openai.Model.list())
Идеальным балансом по цене и качеству ответа является
text-curie-*. Теперь можно делать запросы:prompt = """ Amelie is penpal. reluctantly answers questions with a sarcastic response. She loves roses and pink color. She lives behind Blackwall. Human: What is your name? Amelie: """ response = openai.Completion.create( model="text-curie-001", prompt=prompt, temperature=0.5, max_tokens=50, top_p=0.3, frequency_penalty=0.5, presence_penalty=0.0, stop=["Human:"] )
Официальная библиотека OpenAI предоставляет весьма «сырой» интерфейс, поэтому ответ возвращается в виде ассоциативного массива:
{ "choices": [ { "finish_reason": "stop", "index": 0, "logprobs": null, "text": "\n\nI am Amelie, but you can call me Amelie if you want." } ], "created": 1676281993, "id": "<тут был какой-то токен>", "model": "text-curie-001", "object": "text_completion", "usage": { "completion_tokens": 20, "prompt_tokens": 121, "total_tokens": 141 } }
Ответ на короткие текстовые реплики приходит менее чем за секунду, что задает достаточно высокую планку при использовании локальных сервисов. Несмотря на проприетарную модель распространения, GPT-3 можно дообучать для своих нужд, чтобы, например, сделать внутрикорпоративного чат-бота.
При наличии определенных знаний генерация диалогов становится завораживающе-пугающей. Проект Project December предлагает пообщаться с людьми, которых уже нет с нами. От их имени говорит нейросеть, но наличие достаточных данных позволяет мимикрировать под человека.
Возникает логичный вопрос: можно ли текстовые модели развернуть локально, чтобы было спокойно за свои и корпоративные секреты? Конечно, можно! Но есть несколько нюансов.
GPT-J-6B
Несмотря на наличие слова Open в названии OpenAI, модели GPT-3 не являются открытыми. Естественно, есть люди, которых не устраивает такое положение дел.
Так появился проект GPT-J-6B (документация). Согласно заверениям разработчиков, эта модель может сравниться с версией Curie от OpenAI. Все модели для локального запуска доступны на сайте huggingface.co, который предоставляет удобную библиотеку transformers. Инструкция по установке доступна на официальном сайте.
Взаимодействие с GPT-J более сложное, чем обращение к GPT-3. Сперва загрузим модель и токенайзер:
from transformers import AutoTokenizer, AutoModelForCausalLM model = AutoModelForCausalLM.from_pretrained("EleutherAI/gpt-j-6B") tokenizer = AutoTokenizer.from_pretrained("EleutherAI/gpt-j-6B") generator = pipeline("text-generation", model=model, tokenizer=tokenizer, device="cuda")
Объект generator упрощает работу с моделью примерно до уровня обращения к API OpenAI:
result = generator( prompt, do_sample=True, temperature=0.5, return_full_text=False, # Вернуть только сгенерированный текст ) print(result[0]["generated_text"])
Генератор возвращает массив возможных ответов с параметрами. Но эти лаконичные строки кода принесут сразу несколько разочарований.
Во-первых, модель занимает около 25 ГБ vRAM, а официальная документация просит все 48 ГБ. Это автоматически ставит крест на возможности запустить эту модель на домашней видеокарте. Возможно RTX 3090 или RTX 4090 с 24 ГБ vRAM справятся, но не факт. Во-вторых, если модель влезет в память, то этот процесс занимает пару минут. Если вы привыкли вносить мелкие правки и часто перезагружать приложение, то это может стать испытанием терпения. Но ответ не разочарует.
GPT-3: \n\nI am Amelie, but you can call me Amelie if you want. GPT-J: Amelie.
Размер модели можно сократить только ценой качества. Получим версию с вдвое меньшим размером весов: не float32, а float16.
import os import torch # Сохраняем в pytorch-формате. Это нужно сделать один раз! if not os.path.exists("gptj.pt"): model = AutoModelForCausalLM.from_pretrained( "EleutherAI/gpt-j-6B", revision="float16", torch_dtype=torch.float16 ) torch.save(model, "gptj.pt") # Далее можно загружать таким образом model = torch.load("gptj.pt")
Теперь модель загружается за 20 секунд и занимает всего 12.6 ГБ памяти.
Внимательный читатель может заметить, что ответ GPT-J необычайно сдержанный, хотя стоп-последовательность мы не задавали. Это сделано специально, чтобы не пугать большим выводом. Существует два способа задать стоп-последовательность: через аргумент eos_token_id или через класс StopCriteria.
В первом случае потребуется токенайзер, чтобы превратить последовательность символов в идентификатор токена (число):
token_id = tokenizer("\n").input_ids[0] result = generator( prompt, do_sample=True, temperature=0.5, return_full_text=False, eos_token_id=token_id ) print(result[0]["generated_text"])
Этот способ подходит только для простых случаев, когда стоп-последовательность короткая — например, точка, перенос строки или любой специальный символ. Последовательность «Human:» состоит из двух токенов — генерация прекратится, если в тексте встретится слово «Human». Если хочется сделать сложную стоп-последовательность или предусмотреть остановку по одному из указанных токенов, то необходимо прибегнуть к сложному способу.
У токенайзера существует неочевидная ловушка, в которую очень легко попасть. Он не всегда обрабатывает текст так, как его генерирует модель. К примеру, последовательность из двух переносов строки (\n\n) — это один токен с идентификатором 628. При генерации два переноса строки генерируются за две итерации, то есть это два токена с идентификатором 198.
Сложный способ — написать класс, который принимает решения о прерывании генерации.
from transformers import StoppingCriteria, StoppingCriteriaList class WordStopCriteria(StoppingCriteria): def __init__(self, stop_token_ids: List[List]): self.stop_token_ids = stop_token_ids def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs) -> bool: for stop_sequence in self.stop_token_ids: l = len(stop_sequence) if input_ids[0][-l:].tolist() == stop_sequence: return True return False stop_word_instance = WordStopCriteria(tokenizer(["Human:", "Amelie:"]).input_ids)
Наследуемся от класса StoppingCriteria, в конструкторе сохраняем массивы токенов. В конце каждой итерации вызывается метод
__call__ , который может прервать генерацию, если вернет True. Мое решение достаточно наивно: если список сгенерированных токенов заканчивается на одну из последовательностей токенов — прерываемся.result = generator( prompt, do_sample=True, temperature=0.5, return_full_text=False, stopping_criteria=StoppingCriteriaList([stop_word_instance]) ) print(result[0]["generated_text"])
В параметр
stopping_criteria передается StoppingCriteriaList — обертка над массивом классов StoppingCriteria. Для остановки генерации достаточно решения хотя бы одного из критериев.Теперь у нас есть две похожие нейронные сети, которые выполняют роль «мозга». Следующий шаг — эмоции.
Эмоциональный анализ
У нас есть текстовая модель, которая умеет корректно отвечать на вопросы. Можно ли использовать ее для определения эмоциональной окраски текста? Конечно! В оригинальном творении hackdaddy8000 используется такой запрос:
The following is a quote and whether it is joy, disgust, surprise, sadness, neutral, or anger: I love you so much. Ekman emotion: Joy You disgust me. You are less than a worm. Ekman emotion: Disgust Are those Air Jordans? Thank you, thank you, thank you! I can't wait to put these on my feet! I love you so much! Ekman emotion: Surprise We will never truly be together. Technology just isn't capable of letting us have a proper connection. I'm sorry. Ekman emotion: Sadness No, I don't want to play among us. I think that game is stupid. Ekman emotion: Neutral ${text} Ekman emotion:
Такой вариант не добавляет новых инструментов, но зато увеличивает количество работы для текстовой модели. Текстовая модель, безусловно, справится, но можно использовать нейронные сети, созданные для эмоциональной оценки — например, j-hartmann/emotion-english-distilroberta-base.
from transformers import pipeline classifier = pipeline( "text-classification", model="j-hartmann/emotion-english-distilroberta-base", return_all_scores=True ) result = classifier("I love this!")
Классификатор текста, в отличие от текстовой модели, возвращает вероятность каждой из эмоций:
[[{'label': 'anger', 'score': 0.004419783595949411}, {'label': 'disgust', 'score': 0.0016119900392368436}, {'label': 'fear', 'score': 0.0004138521908316761}, {'label': 'joy', 'score': 0.9771687984466553}, {'label': 'neutral', 'score': 0.005764586851000786}, {'label': 'sadness', 'score': 0.002092392183840275}, {'label': 'surprise', 'score': 0.008528684265911579}]]
У hackdaddy8000 эмоции вычисляются только для ответа, сгенерированного текстовой моделью. Числовое представление эмоций позволит учитывать не только ответ, но и запрос. Более того, можно создать эмоциональный компонент, который по ходу диалога будет рассчитывать «внутреннее состояние» ИИ и влиять на запрос к текстовой модели.
Существенный минус отдельного классификатора — ограниченный список поддерживаемых языков. Предложенный классификатор умеет разбирать только английский, для остальных языков он выдает около 70% нейтральной эмоции. Впрочем, даже на поддерживаемом языке случаются странные решения. Например:
You: How are you? Friend: Fine!
Простая фраза собеседника классифицируется как злость с 92% уверенности. Впрочем, если модель добавит I’m, или thanks, или как-то иначе распространит свой ответ, то классификатор выдаст более корректный вариант.
Разум и эмоции есть, переходим к синтезу аудио и визуала.
Генерация аудио и видео
Stable Diffusion
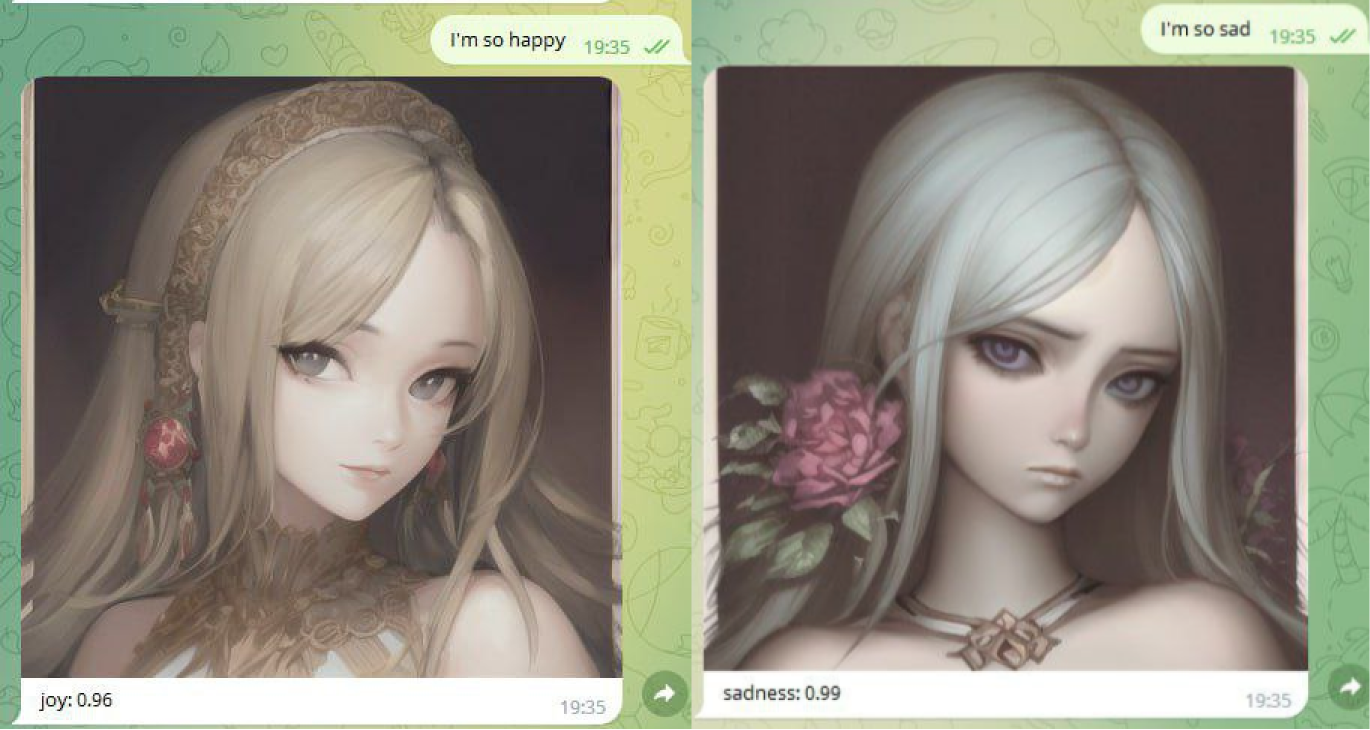
Концепт. Классификатор извлекает эмоции отправителя и генерирует персонажа с указанными весами эмоций.
В начале подготовки текста я хотел совместить текстовую модель и Stable Diffusion. Идея грандиозна: перед началом диалога SD генерирует портрет собеседника, в диалоге классификатор текста получает веса эмоций, текстовая модель извлекает ключевые слова и SD накладывает актуальный контекст на существующего персонажа через img2img.
Но вскоре я отказался от этой мысли, так как автоматизированный img2img генерирует разные портреты. Но для заинтересованных оставлю ссылку на документацию для Stable Diffusion API. Возможно, найдется смельчак, который сможет грамотно применить возможности SD.
Идея, пришедшая на смену, была не хуже. Генерируем одно изображение и из него делаем видео с помощью нейронных сетей, которые делают «говорящие головы». Но сперва сделаем звук.
Синтезатор речи
В России доступны компании, которые предоставляют услуги по синтезу речи, в том числе с эмоциями. Но если уж захотелось сделать все локально и собрать
В качестве синтезатора английской речи можно использовать Tacotron2.
import torchaudio from speechbrain.pretrained import Tacotron2 from speechbrain.pretrained import HIFIGAN tacotron2 = Tacotron2.from_hparams(source="speechbrain/tts-tacotron2-ljspeech", savedir="tmpdir_tts", run_opts={"device":"cuda"}) hifi_gan = HIFIGAN.from_hparams(source="speechbrain/tts-hifigan-ljspeech", savedir="tmpdir_vocoder", run_opts={"device":"cuda"}) mel_output, mel_length, alignment = tacotron2.encode_text("I'm fine") waveforms = hifi_gan.decode_batch(mel_output) wav_file = Path(f"/tmp/tts.wav") torchaudio.save(wav_file, waveforms.squeeze(1).to("cpu"), 22050)
Тут, кажется, все просто: подаем на вход текст, на выходе получаем wav-файл с частотой дискретизации 22050 Гц. Цифра обусловлена тем, что Tacotron2 обучался на аудиофайлах такой частоты.
Синтезатор речи способен за раз создать около 10 секунд аудио, поэтому для озвучки длинных текстов необходимо разбиение на предложения.
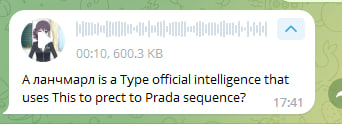
A language model is type of artificial intelligence that uses statistical techniques to predict the probability sequence of words
Забавный факт: распознавание голосовых сообщений в Telegram (Google Speech Services) не смогло корректно разобрать голос, сгенерированный Tacotron2.
Кажется, голос готов, приступаем к видео.
Lip Sync
Источник
Существует много работ, посвященных синхронизации видеоряда и аудиоряда. Можно даже найти список таких работ от энтузиастов. К сожалению, для моей задачи большинство работ — это научные публикации без опубликованного кода или моделей. Еще часть работ требует на вход не только изображение, которое нужно анимировать, но и видео, на котором изображен говорящий, чью мимику нужно скопировать.
Остается малая часть работ, которая способна создавать видео из картинки и аудио, но их результаты выглядят немного страшно. На этом я отказался от идеи анимирования картинок и поискал другие решения.
Live2D Cubism
К счастью, разработка hackdaddy8000 содержала компонент, о котором я даже не задумывался в начале. Я предполагал, что девушка на экране — это авторская модель, но оказалось, что это Shizuku, публично доступная 2D-модель от Live2D.
Live2D Cubism — это программное решение для создания живых анимаций из двумерных изображений. В решении hackdaddy8000 используется библиотека pixi-live2d-display, которая реализует отображение моделей и взаимодействие с ними.
Однако просто позаимствовать решение не получится, так как браузер предполагает интерактивное взаимодействие. Конечно, есть webdriver и puppeteer, которые позволяют автоматизировать управление браузером, но запись видео со странички браузера — это неприятная и медленная задача.
Каких-то проигрывателей Live2D-моделей для Python нет, поэтому пришлось смотреть в оригинальный SDK.
Live2D Cubism SDK имеет достаточно хитрую лицензию, которая разрешает использовать их продукты бесплатно только для внутреннего тестирования или для обучающих целей. Эта статья подходит под оба критерия.
Распространение кода Live2D тоже вызывает вопросы, даже несмотря на наличие их на GitHub, поэтому просто оставлю ссылку на SDK и пример, а в свой репозиторий положу патч для внесения изменений, описанных в статье.
В репозитории с примерами для нативных языков есть версия для OpenGL. Ввиду особенностей OpenGL приложению нужен оконный менеджер. Я установил «иксы», создал конфиг для генерации рабочего стола без монитора и запустил:
sudo nvidia-xconfig -a --use-display-device=None --virtual=1024x768 /usr/bin/X :0 &
В ходе первой попытки «иксы» не стартовали, поэтому в конфиге
/etc/X11/xorg.conf я закомментировал строку Option «UseDisplayDevice» «None» и все успешно запустилось. Проверить, что OpenGL-приложения запустятся, можно утилитой glewinfo:firemoon@Tesla-A100:~$ DISPLAY=:0 glewinfo | head --------------------------- GLEW Extension Info --------------------------- GLEW version 2.1.0 Reporting capabilities of display , visual 0x2a Running on a NVIDIA A100-PCIE-40GB/PCIe/SSE2 from NVIDIA Corporation OpenGL version 4.6.0 NVIDIA 510.39.01 is supported
Для сборки нативного приложения нужна целая россыпь библиотек и cmake. Для Ubuntu их можно поставить так:
sudo apt update sudo apt install libglew-dev unzip libxrandr-dev libxinerama-dev libxcursor-dev libinput-dev libxi-dev g++ cmake
Возможно, я что-то упустил, но конфигуратор сборки уточнит чего именно не хватает. На GitHub нет проприетарных файлов в каталоге Core. Поэтому заходим на официальный сайт и скачиваем Cubism SDK for Native.
# Скачиваем нужные для сборки версии библиотеке glew и glfw cd Samples/OpenGL/thirdParty/scripts/ ./setup_glew_glfw #Компилируем cd ../../Demo/proj.linux.cmake/scripts/ ./make_gcc
Скрипт спросит, какую версию нужно собрать, — полную или минимальную.
Choose which format you would like to create the demo. Full version : 1 Minimum version : 2 Your Choice :
Минимальная версия, как следует из названия, имеет ограниченный функционал, поэтому собираем полную. Теперь приложение можно запустить:
../build/make_gcc/bin/Demo/Demo

Отлично, приложение запускается, но для генерации видео нужно чуть-чуть доработать его напильником. Вот список задач:
- Подогнать окно приложения в рамки 512х512.
- Переместить модель так, чтобы это было похоже на портрет.
- Научить модель открывать рот в соответствии с аудиофайлом.
- Внедрить интерфейс управления моделью, то есть переключать эмоции и состояния командами вне приложения.
- Сделать вывод изображения в mp4-видео.
Первые два пункта делаются изменением констант в коде приложения, а вот далее — это уже интересные задачи.
Модели умеют «говорить»: для ряда действий указывается аудиофайл, который задает реплику модели. Один из встроенных компонентов, _wavFileHandler, как раз управляет синхронизацией звука с движением губ. Для начала липсинка достаточно вызвать метод _wavFileHandler.Start() с указанием пути до wav-файла.
Важный момент: этот компонент привередлив к входному wav-файлу, список требований указан в документации SDK. Вернемся к нашему синтезатору речи и добавим два параметра сохранения.
torchaudio.save( wav_file, waveforms.squeeze(1).to("cpu"), 22050, encoding="PCM_S", bits_per_sample=16 )
Теперь необходимо добавить интерфейс взаимодействия. Так как приложение будет контролироваться другим приложением, то проще всего считывать текстовые команды из стандартного потока ввода (stdin). Находим инициализацию приложения и делаем stdin неблокирующим:
int flags = fcntl(0, F_GETFL, 0); fcntl(0, F_SETFL, flags | O_NONBLOCK);
Далее в основном цикле приложения считываем команды посимвольно из stdin до переноса строки:
// Инициализация int ready = 0; char _in[512]; int len = 0; // Основной цикл приложения char c; int result = read(0, & c, 1); while (result > 0) { if (c == '\n') { ready = 1; _in[len] = '\0'; break; } else { _in[len] = c; len++; } result = read(0, & c, 1); } if(ready == 1) { // Выполняем действия в зависимости от команды ready = 0; len = 0; }
Для быстроты исполнения я сделал команды длиной в один символ. Начиная со второго символа и до символа переноса строки — аргумент для команды. Например, команда eF01 — это команда запустить эмоцию (expression) со строковым идентификатором F01.
Осталась заключительная задача: записывать окно в видеофайл. Здесь используется гениальный лайфхак, который я подсмотрел в блоге у Маилса Маклина (Miles Macklin). Запускаем ffmpeg дочерним процессом и через конвейер передаем ему кадры, которые отрисовывает OpenGL.
// Инициализация char cmd[512]; snprintf(cmd, 512, "ffmpeg -r %i -f rawvideo -pix_fmt rgba -s %dx%d -i - -threads 0 -preset fast -y -pix_fmt yuv420p -crf 21 -vf vflip %s >/dev/null 2>/dev/null", TARGET_FPS, _windowWidth, _windowHeight, filename); FILE* ffmpeg = popen(cmd, "w"); int* buffer = new int[_windowWidth*_windowHeight]; // Основной цикл приложения glfwSwapBuffers(_window); glReadPixels(0, 0, _windowWidth, _windowHeight, GL_RGBA, GL_UNSIGNED_BYTE, buffer); fwrite(buffer, sizeof(int)*_windowWidth*_windowHeight, 1, ffmpeg);
Этот способ работает, но на используемой видеокарте приложение выдает значительно больше, чем 60 кадров в секунду, которые ожидает ffmpeg. Это значит, что необходимо также добавить ограничитель. Самое простое решение — рассчитать время выполнения одной итерации цикла и замедлять его бездействием, если цикл выполняется быстрее.
// Инициализация double lasttime = glfwGetTime(); // Конец основного цикла while(glfwGetTime() < lasttime + 1.0f/TARGET_FPS) {} lasttime += 1.0f / TARGET_FPS;
Таким образом метод отрисовки и, соответственно, передача кадра в ffmpeg будет происходить не чаще ожидаемых 60 раз в секунду.
Собираем приложение — теперь его можно использовать для генерации «кружков». Объединяем все в кучу, и у нас появляется проект, который потребляет очень много ресурсов. Стоила ли игра свеч?
А что там по цене?
Для запуска приложения использовался выделенный сервер конфигурации GL70-1-A100, стоимость которого 195 000 рублей в месяц, или $2 635 долларов в месяц (курс на момент написания статьи — 74 руб.). Рассчитаем, сколько нужно взаимодействовать с платными сервисами, чтобы превысить стоимость железного сервера.
Первая статья расходов — оплата доступа к GPT-3. Согласно странице с ценами, 1 000 токенов эквивалентна 750 словам и оценивается в $0.0020. У OpenAI есть интерактивный токенайзер, который показывает грустные вещи: для генерации на русском языке практически каждый символ — это отдельный токен. В таком случае примерно 150 русских слов займут 1 000 токенов.
Если для синтеза речи использовать Google Text-To-Speech, то стоимость озвучивания миллиона символов колеблется от 4 до 160 долларов. В качестве среднего возьмем голос по тарифу $16 за миллион символов ($0.000016 за символ).
Для удобства конвертации слов в символы и наоборот предположим, что средняя длина английского слова — 5 символов, а русского — 7 символов.
Для запуска рендера Live2D и телеграм-бота нужен сервер. Я не тестировал это решение на других серверах, поэтому сделаем очень оптимистичную оценку, что на виртуалке не дороже $135 все будет работать идеально. Остается 2 500$ бюджета, которые можно потратить на генерацию текста и его озвучивание.
Предположим, что с GPT-3 ведется долгий и обстоятельный диалог. Каждый запрос упирается в «потолок» моделей в 2 000 токенов, из которых четверть — ответ, который сперва подается на эмоциональный анализ, а затем на озвучку.
Русскоязычная генерация Генерация, 2000 токенов = 0.004$ Эмоциональный анализ, 600 токенов = 0.0012$ Озвучивание 500 токенов = 75 слов = 575 символов = 0.0092$ Итого за один запрос: 0.0144$ Количество запросов в бюджете: 2500 / 0.0144 ≈ 175 000 запросов в месяц ≈ 5 900 запросов в день Англоязычная генерация Генерация 2000 токенов = 0.004$ Эмоциональный анализ, 600 токенов = 0.0012$ Озвучивание 500 токенов = 375 слов = 1875 символов = 0.03$ Итого за один запрос: 0.0352$ Количество запросов в бюджете: 2500 / 0.0352 ≈ 71 000 запросов в месяц ≈ 2 400 запросов в день
2400 запросов в день — это 100 запросов в час, то есть более одного запроса в минуту. Надо быть
Заключение
Как все это выглядит, смотрите по ссылке. Получилось довольно интересное приложение, которое не только реагирует на сообщения бездушным текстом, но и записывает забавные видеосообщения. Полный исходный код доступен в репозитории. Качество кода оставляет желать лучшего, но этого достаточного для быстрого старта собственного проекта по образу и подобию.
Возможно, эти тексты тоже вас заинтересуют:
→ Краткое полное руководство по Stable Diffusion
→ Как быстро растут сети: прогресс Midjourney спустя полгода
→ Локализуем игру в слова с искусственным интеллектом
