На момент написания этой статьи за плечами уже был опыт нескольких инсталляций версии 2.6.0 по рекомендациям-инструкциям, найденным на просторах сети.
Вчера же у меня возникло желание установить hadoop-3.0.0 альфа 1. Ниже я подробно изложу весь процесс и результат.
Установку будем делать на Ubuntu 16.10 Server в конфигурации кластера с одной нодой.
1. Установка Java
Из-под пользователя с правами администратора
обновляем пакет
$ sudo apt-get updateустанавливаем пакет с Java:
$ sudo apt-get install default-jdkпроверяем результат:
$ java -version
java version "1.8.0_111"
Java(TM) SE Runtime Environment (build 1.8.0_111-b14)
Java HotSpot(TM) 64-Bit Server VM (build 25.111-b14, mixed mode)
2. Создаем выделенного пользователя для запуска Hadoop и создаем для него SSH сертификат.
Добавляем в ОС нового пользователя (рекомендуется не предоставлять ему права администратора)
$ adduser hduser
$ passwd hduserДалее переходим на работу из-под пользователя hduser:
$ su - hadoopгенерируем SSH-сертификат:
$ ssh-keygen -t rsaсохраняем сертификат в файл:
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keysпредоставляем права на файл с сертификатом:
$ chmod 0600 ~/.ssh/authorized_keysПроверяем SSH-подключение:
$ ssh localhost
The authenticity of host 'localhost (127.0.0.1)' can't be established.
ECDSA key fingerprint is e1:8b:a0:a5:75:ef:f4:b4:5e:a9:ed:be:64:be:5c:2f.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'localhost' (ECDSA) to the list of known hosts.
Welcome to Ubuntu 16.10 (GNU/Linux 4.8.0-22-generic x86_64)
$ exit3. Скачиваем и распаковываем пакет Hadoop
$ cd ~
$ wget http://mirrors.sonic.net/apache/hadoop/common/hadoop-3.0.0-alpha1/hadoop-3.0.0-alpha1.tar.gz
$ tar xvzf hadoop-3.0.0-alpha1.tar.gz
$ mv hadoop-3.0.0-alpha1 hadoop4. Настройка переменных окружения для Hadoop
Открываем на редактирование файл ~/.bashrc и добавляем информацию. Для редактирования рекомендую использовать редактор nano (ctrl+O — сохранить и ctrl+X — выход)
$ nano ~/.bashrcВносим:
export HADOOP_HOME=/home/hduser/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/binПодтверждаем изменения:
$ source ~/.bashrcВносим переменную окружения в $HADOOP_HOME/etc/hadoop/hadoop-env.sh
$ nano $HADOOP_HOME/etc/hadoop/hadoop-env.shВносим:
export JAVA_HOME=/usr/lib/jvm/java-8-oracle/5. Редактируем конфигурационные файлы Hadoop
— редактируем core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
— редактируем hdfs-site.xml:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hduser/hadoopdata/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hduser/hadoopdata/hdfs/datanode</value>
</property>
</configuration>
— редактируем mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
— редактируем yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
6. Создаем Data каталоги и форматируем HDFS ноду
Создаем подкаталоги в папке hadoop домашнего каталога hduser:
$ mkdir -p /hadoopdata/hdfs/datanode
$ mkdir -p /hadoopdata/hdfs/namenodeформатируем ноду:
$ hdfs namenode -format
2016-12-06 21:56:37,131 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: user = hduser
STARTUP_MSG: host = hadoop01/127.0.1.1
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 3.0.0-alpha1
STARTUP_MSG: classpath = /home/hduser/hadoop/etc/hadoop:/home/hduser/hadoop/share/hadoop/common/lib/netty-
...
STARTUP_MSG: build = https://git-wip-us.apache.org/repos/asf/hadoop.git -r a990d2ebcd6de5d7dc2d3684930759b0f0ea4dc3; compiled by 'andrew' on 2016-08-30T07:02Z
STARTUP_MSG: java = 1.8.0_111
************************************************************/
2016-12-06 21:56:37,170 INFO namenode.NameNode: registered UNIX signal handlers for [TERM, HUP, INT]
....
2016-12-06 21:57:15,975 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at hadoop01/127.0.1.1
************************************************************/7. Запуск Hadoop кластера
Запускаем start-dfs.sh:
$ start-dfs.sh
Starting namenodes on [localhost]
Starting datanodes
Starting secondary namenodes [hadoop01]
2016-12-06 22:01:43,311 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Запускаем start-yarn.sh:
$ start-yarn.sh
Starting resourcemanager
Starting nodemanagersПроверяем результат:
$ jps
11985 SecondaryNameNode
12324 NodeManager
11661 NameNode
12205 ResourceManager
12686 Jps
Смотрим открывшиеся порты:
$ netstat -plten | grep java
(Не все процессы были идентифицированы, информация о процессах без владельца
не будет отображена, вам нужны права суперпользователя (root), чтобы увидеть всю информацию.)
tcp 0 0 0.0.0.0:8040 0.0.0.0:* LISTEN 1001 93147 12324/java
tcp 0 0 127.0.0.1:9000 0.0.0.0:* LISTEN 1001 84985 11661/java
tcp 0 0 0.0.0.0:8042 0.0.0.0:* LISTEN 1001 93869 12324/java
tcp 0 0 0.0.0.0:9868 0.0.0.0:* LISTEN 1001 86737 11985/java
tcp 0 0 0.0.0.0:9870 0.0.0.0:* LISTEN 1001 84126 11661/java
tcp 0 0 0.0.0.0:8088 0.0.0.0:* LISTEN 1001 89017 12205/java
tcp 0 0 0.0.0.0:34393 0.0.0.0:* LISTEN 1001 93139 12324/java
tcp 0 0 0.0.0.0:13562 0.0.0.0:* LISTEN 1001 93868 12324/java
tcp 0 0 0.0.0.0:8030 0.0.0.0:* LISTEN 1001 88618 12205/java
tcp 0 0 0.0.0.0:8031 0.0.0.0:* LISTEN 1001 88610 12205/java
tcp 0 0 0.0.0.0:8032 0.0.0.0:* LISTEN 1001 88624 12205/java
tcp 0 0 0.0.0.0:8033 0.0.0.0:* LISTEN 1001 93873 12205/java
8. Доступ к Hadoop из браузера
Информация о hadoop кластере: hadoop01:8088/cluster/nodes
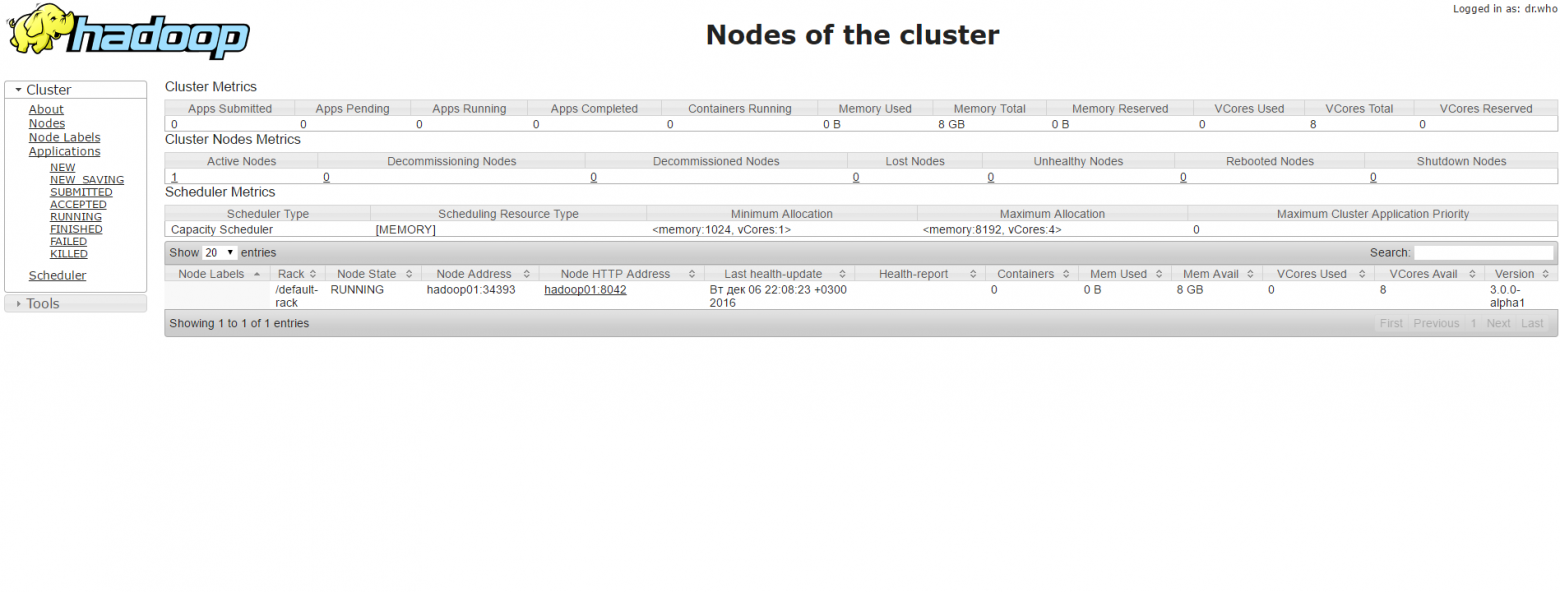
Состояние дата-нод:
hadoop01:9870/dfshealth.html#tab-overview

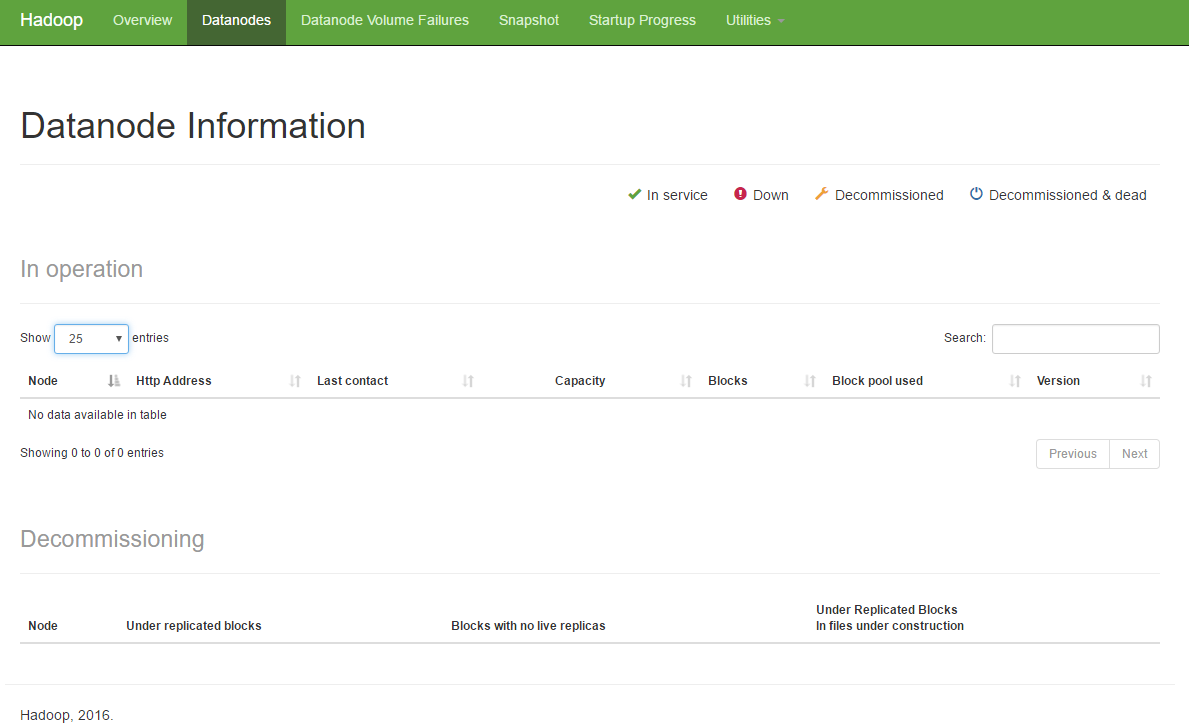
Информация о дата-ноде:
hadoop01:9870/dfshealth.html#tab-datanode
Это была моя первая статья. Надеюсь, было полезно. Планирую далее уделить время HP Vertica.