Когда я начал изучать стандартный ввод/вывод в Java, то первое время был немного шокирован обилием интерфейсов и классов пакета
java.io.*, дополненных еще и целым перечнем специфических исключений.
Потратив изрядное количество часов на изучение и реализацию кучи разнообразных туториалов из Интернета, начал чувствовать себя уверенно и вздохнул с облегчением. Но в один прекрасный момент понял, что для меня все только начинается, так как существует еще и пакет
java.nio.*, известный ещё под названием Java NIO или Java New IO. Вначале казалось, что это тоже самое, ну типа вид сбоку. Однако, как оказалось, есть существенные отличия, как в принципе работы, так и в решаемых с их помощью задачах.
Разобраться во всем этом мне здорово помогла статья Джакоба Дженкова (Jakob Jenkov) –
“Java NIO vs. IO”. Ниже она приводиться в адаптированном виде.
Поспешу заметить, что статья не является руководством по использованию Java IO и Java NIO. Её цель – дать людям, начинающим изучать Java, возможность понять концептуальные отличия между двумя указанными инструментами организации ввода/вывода.







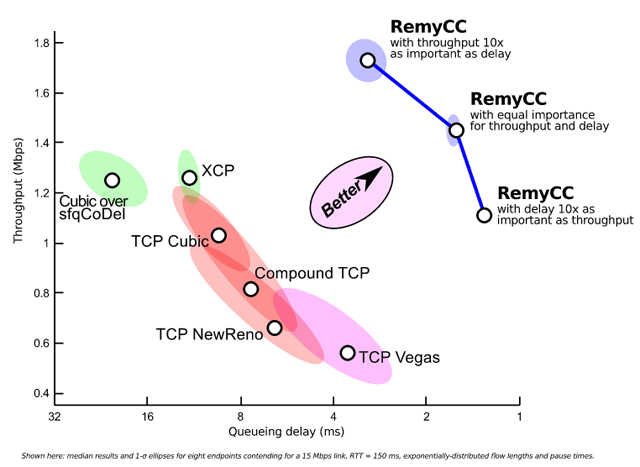
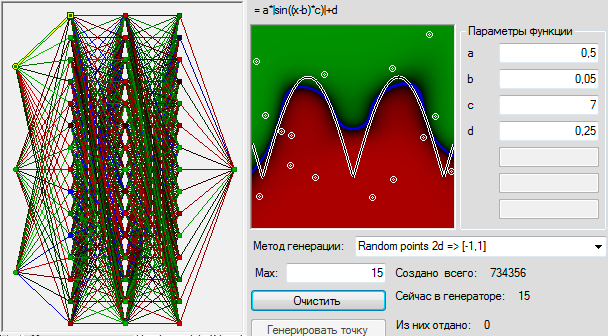 В последнее время на Хабре появилось множество статей о нейронных сетях. Из них очень интересными показались статьи о Перцептроне Розенблатта:
В последнее время на Хабре появилось множество статей о нейронных сетях. Из них очень интересными показались статьи о Перцептроне Розенблатта: