Постановка задачи поиска в строке
Часто приходится сталкиваться со специфическим поиском, так называемым поиском строки (поиском в строке). Пусть есть некоторый текст Т и слово (или образ) W. Необходимо найти первое вхождение этого слова в указанном тексте. Это действие типично для любых систем обработки текстов. (Элементы массивов Т и W – символы некоторого конечного алфавита – например, {0, 1}, или {a, …, z}, или {а, …, я}.)
Наиболее типичным приложением такой задачи является документальный поиск: задан фонд документов, состоящих из последовательности библиографических ссылок, каждая ссылка сопровождается «дескриптором», указывающим тему соответствующей ссылки. Надо найти некоторые ключевые слова, встречающиеся среди дескрипторов. Мог бы иметь место, например, запрос «Программирование» и «Java». Такой запрос можно трактовать следующим образом: существуют ли статьи, обладающие дескрипторами «Программирование» и «Java».
Поиск строки формально определяется следующим образом. Пусть задан массив Т из N элементов и массив W из M элементов, причем 0<M≤N. Поиск строки обнаруживает первое вхождение W в Т, результатом будем считать индекс i, указывающий на первое с начала строки (с начала массива Т) совпадение с образом (словом).
Пример. Требуется найти все вхождения образца W = abaa в текст T=abcabaabcabca.

Образец входит в текст только один раз, со сдвигом S=3, индекс i=4.



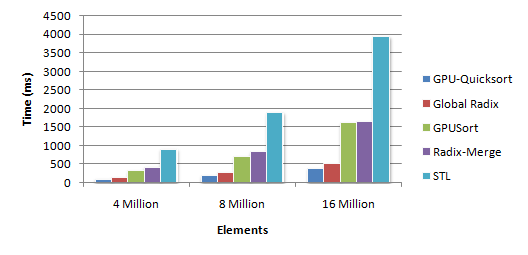



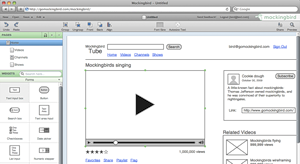 Для написания ТЗ я задался вопросом поиска простого и удобного средства создания прототипов веб-страниц. Хотелось чего-то бесплатного и в онлайне, некой альтернативы Axure. Такой сервис удалось найти, его я и предлагаю вашему вниманию. Итак, встречайте
Для написания ТЗ я задался вопросом поиска простого и удобного средства создания прототипов веб-страниц. Хотелось чего-то бесплатного и в онлайне, некой альтернативы Axure. Такой сервис удалось найти, его я и предлагаю вашему вниманию. Итак, встречайте