Оптимизация flatpages проекта на django под минимальные системные требования. Статья-шутка
10 мин

Под катом много букв, но не беспокойтесь — вы всех их знаете.

Пользователь

 Вебразработчики частенько сталкиваются с классической задачей определения местоположения пользователя по его IP-адресу. Существует множество различных решений, например на основе мировой базы Maxmind Geolite или российской IpgeoBase. Все они обладают достаточно низкуровневыми API, ну оно и понятно: на входе айпишник, на выходе страна, либо город и, если повезёт, ещё какая-нибудь полезная информация.
Вебразработчики частенько сталкиваются с классической задачей определения местоположения пользователя по его IP-адресу. Существует множество различных решений, например на основе мировой базы Maxmind Geolite или российской IpgeoBase. Все они обладают достаточно низкуровневыми API, ну оно и понятно: на входе айпишник, на выходе страна, либо город и, если повезёт, ещё какая-нибудь полезная информация. 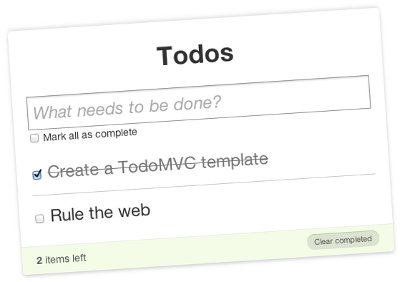 Cуществует уже несколько десятков JavaScript-фреймворков для построения сложных приложений в браузере. Чтобы сравнить их между собой и выбрать наиболее подходящий, примитивного примера вроде классического «Hello, world» явно недостаточно. Более сложные и реалистичные примеры программ в книгах и документации каждого фреймворка могут сильно отличаться, и сравнивать их между собой затруднительно. Проект TodoMVC решает именно эту проблему. Это набор примеров реализации одного и того же простого, но вполне законченного веб-приложения с использованием разных фреймворков + эталонный пример на чистом JavaScript.
Cуществует уже несколько десятков JavaScript-фреймворков для построения сложных приложений в браузере. Чтобы сравнить их между собой и выбрать наиболее подходящий, примитивного примера вроде классического «Hello, world» явно недостаточно. Более сложные и реалистичные примеры программ в книгах и документации каждого фреймворка могут сильно отличаться, и сравнивать их между собой затруднительно. Проект TodoMVC решает именно эту проблему. Это набор примеров реализации одного и того же простого, но вполне законченного веб-приложения с использованием разных фреймворков + эталонный пример на чистом JavaScript. action.name.len() len(action.name) 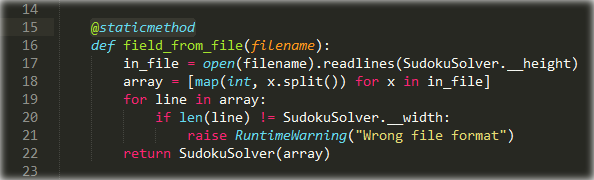
 Интерактивные прототипы сложных информационных систем (в нашем случае это система электронного архива), как известно, могут использоваться на разных стадиях разработки, например:
Интерактивные прототипы сложных информационных систем (в нашем случае это система электронного архива), как известно, могут использоваться на разных стадиях разработки, например:
