Руководство по масштабированию MLOps
8 мин
Перевод
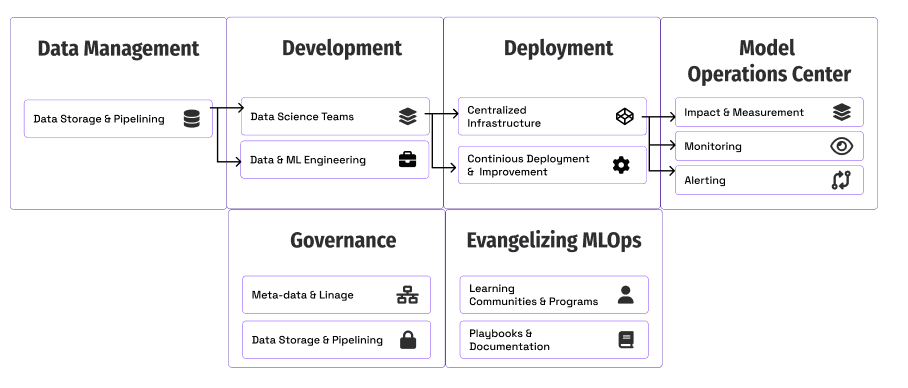
Команды MLOps вынуждены развивать свои возможности по масштабированию ИИ. В 2022 году мы столкнулись со взрывом популярности ИИ и MLOps в бизнесе и обществе. В 2023 год ажиотаж, учитывая успех ChatGPT и развитие корпоративных моделей, будет только расти.
Столкнувшись с потребностями бизнеса, команды MLOps стремятся расширять свои мощности. Эти команды начинают 2023 год с длинного списка возможностей постановки ИИ на поток. Как мы будем масштабировать компоненты MLOps (развёртывание, мониторинг и governance)? Каковы основные приоритеты нашей команды?
AlignAI совместно с Ford Motors написали это руководство, чтобы поделиться с командами MLOps своим успешным опытом масштабирования.