Существует множество опенсорсного ПО и инструментов для проектов компьютерного зрения и машинного обучения в сфере медицинских визуализаций.
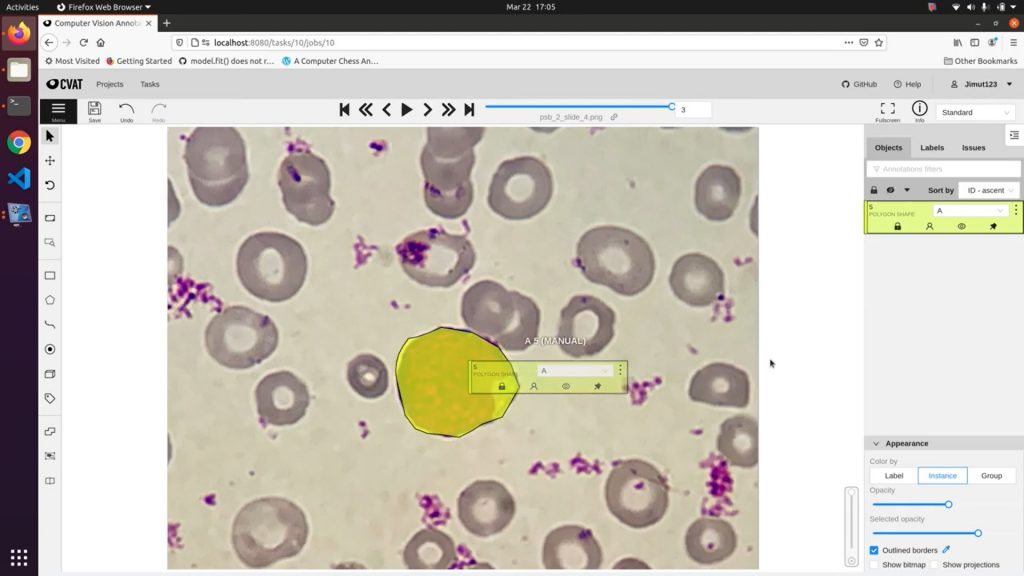
Иногда может быть выгодно использовать опенсорсные инструменты при тестировании и обучении модели ML на массивах данных медицинских снимков. Вы можете экономить деньги, а многие инструменты, например, 3DSlicer и ITK-Snap, предназначены специально для аннотирования медицинских снимков и обучения моделей ML на массивах данных из сферы здравоохранения.
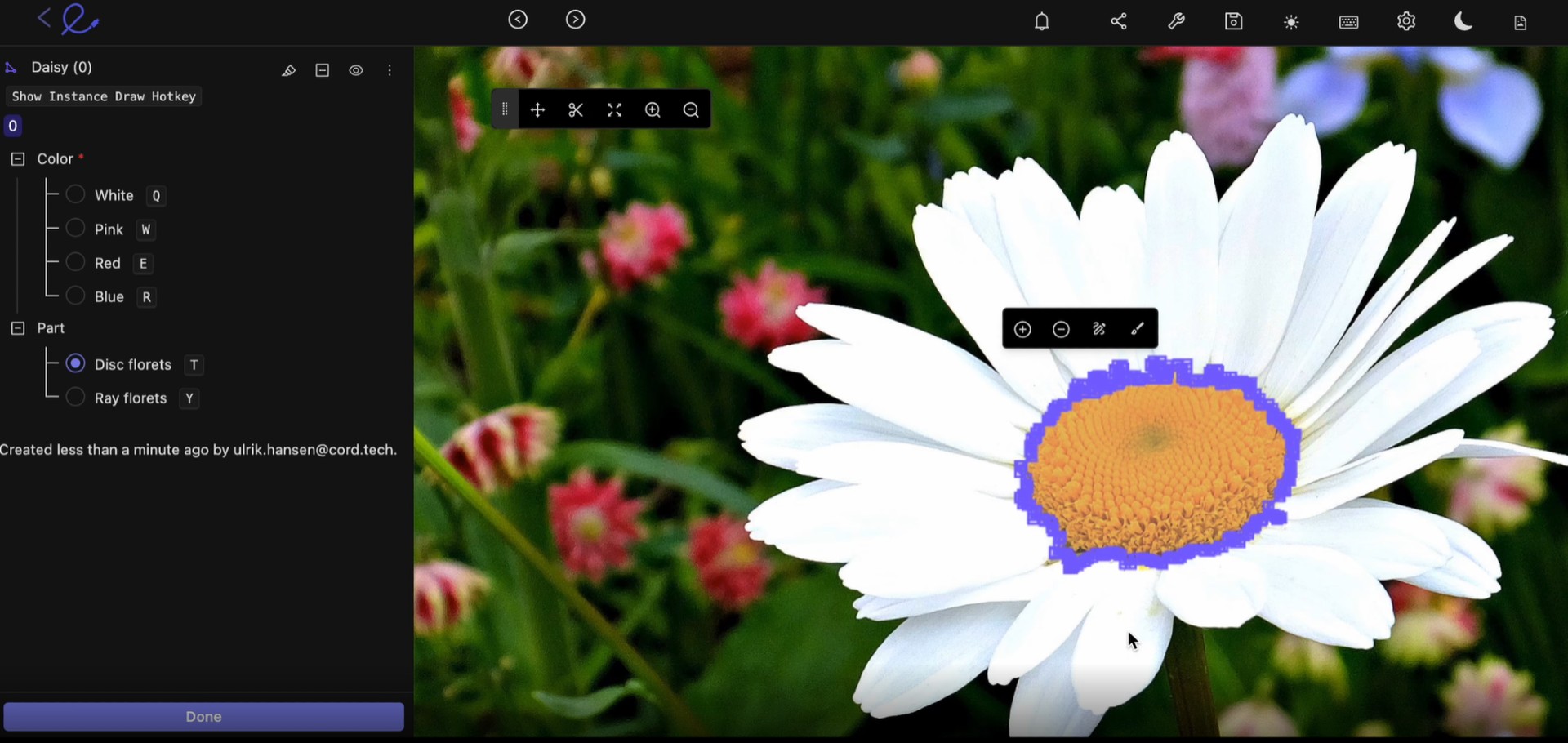
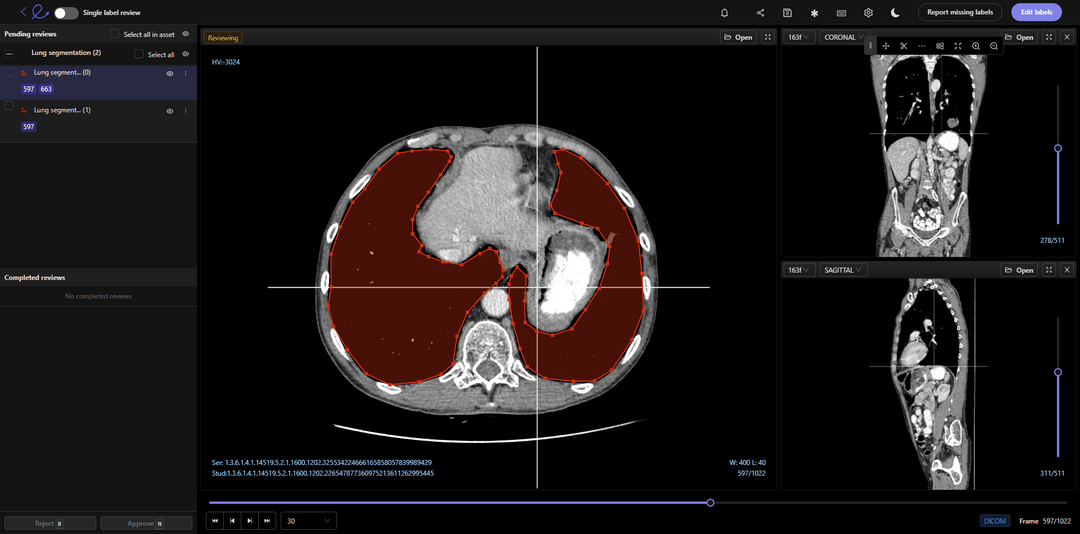
В здравоохранении критически важны качество массива данных и эффективность инструментов, используемых для аннотирования и обучения моделей ML. Это может стать вопросом жизни и смерти для пациентов, ведь для их диагностирования медицинским специалистам и врачам нужны максимально точные результаты моделей компьютерного зрения и машинного обучения.
Как известно командам клиницистов и обработки данных, слои данных в медицинских снимках сложны и детализированы. Для выполнения работы вам нужны подходящие инструменты. Применение неверного инструмента, например, опенсорсного приложения для аннотирования, может негативно повлиять на разработку модели.
В этой статье мы расскажем об основных опенсорсных инструментах для аннотирования медицинских снимков, сценариях применения таких инструментов и о том, как они препятствуют развитию вашего проекта. Мы перечислим те возможности инструмента аннотирования, которые помогут вам преодолеть эти трудности, в том числе и функции, которые обеспечат нужные вам результаты.