
Основы парсинга с помощью Python+lxml
6 мин
Добрый день, уважаемые читатели.
В сегодняшней статье я покажу основы разбора HTML разметки страниц с помощью библиотеки lxml для Python.
Если вкратце, то lxml это быстрая и гибкая библиотека для обработки разметки XML и HTML на Python. Кроме того, в ней присутствует возможность разложения элементов документа в дерево. В статье я постараюсь показать, насколько просто ее применение на практике.
В сегодняшней статье я покажу основы разбора HTML разметки страниц с помощью библиотеки lxml для Python.
Если вкратце, то lxml это быстрая и гибкая библиотека для обработки разметки XML и HTML на Python. Кроме того, в ней присутствует возможность разложения элементов документа в дерево. В статье я постараюсь показать, насколько просто ее применение на практике.

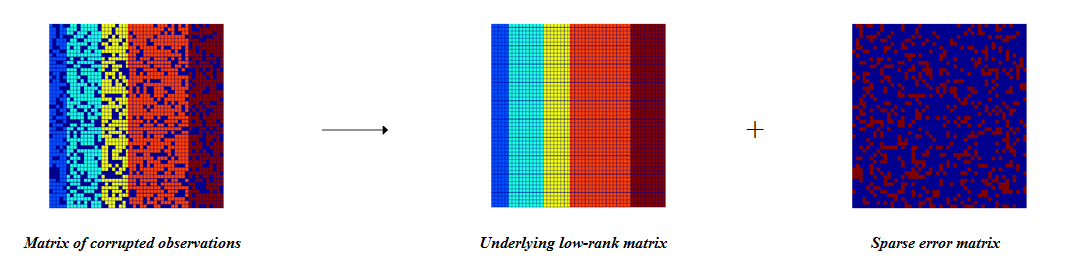
 Сначала я хотел честно и подробно написать о методах снижения размерности данных —
Сначала я хотел честно и подробно написать о методах снижения размерности данных — 
