Уже работает прием заявок на конкурс стартапов на Blogcamp CEE 2008, который будет проходить в Киеве. Поток заявок пошел большой, торопитесь успеть. Мы специально отшли от стандарта и разделили конкурс на две части: Seed Stage (потребность в финансировании 50-150 тысяч евро) и Early Growth Stage (потребность в финансировании 500 тысяч — 1 миллион евро), таким образом мы решили дать возможность совсем молодым стартапам принять участие в подобном мероприятии, обычно они не могут конкурировать с уже сформировавшимися. Конкурс проводится в соответствии с принципами конкурса конференции SVOD (Silicon Valley Open Doors). Более детально с правилами можно ознакомиться на страничке конкурса. В качестве экспертов и судей мы решили пригласить людей из трех групп – ангелы (частные инвесторы, которые инвестируют небольшие суммы), фонды и консультанты, которые работают в этом сегменте (маркетинг, ПР, биздев, юристы). По географии жури, пытались охватить регион Центральная и Восточная Европа, но у нас уже есть подтверждения и из Франции, Англии, Норвегии и Швеции. Конечно, основные участники будут из России и Украины.

zipo @zipo
Пользователь
Репозиторий пакетов популярных игровых программ для Ubuntu
1 мин
Нашел в сети ресурс Playdeb с репозиторием сборок пакетов распространенных игр для Ubuntu Linux. Список игр на данном ресурсе полностью аналогичен списку игр с ресурса www.getdeb.net, но установка и обновление проще, т.к. позволяет установить игру в один клик(используя AptURL) и обновлять потом через репозиторий.
Раньше я такого ресурса не видел и думаю он многим «ленивым»(и не только ;-) ) геймерам будет полезен.
UPD. Топик перенес в Убунтариум.
Раньше я такого ресурса не видел и думаю он многим «ленивым»(и не только ;-) ) геймерам будет полезен.
UPD. Топик перенес в Убунтариум.
High Performance MySQL, Second Edition
1 мин
Наконец нашел на бесплатном торренте эту долгожданную книгу, тут недавно её продавали за 10 вмз :-)
Но теперь каждый может скачать её бессплатно!!! :-) Что и я сделал и уже наслаждаюсь чтением этой книги.
http://www.btmon.com/Other/Unsorted/High_Performance_MySQL_2nd_Edition_Jun_2008_eBook-DDU.torrent.html
P.S. Спасибо всем, кто мне добавил кармы, я благодаря этому смог выполнить свое обещание и написать эту статью
habrahabr.ru/blogs/mysql/38907
Но теперь каждый может скачать её бессплатно!!! :-) Что и я сделал и уже наслаждаюсь чтением этой книги.
http://www.btmon.com/Other/Unsorted/High_Performance_MySQL_2nd_Edition_Jun_2008_eBook-DDU.torrent.html
P.S. Спасибо всем, кто мне добавил кармы, я благодаря этому смог выполнить свое обещание и написать эту статью
habrahabr.ru/blogs/mysql/38907
MySQL Performance real life Tips and Tricks
9 мин
Пообещал вчера написать статью о реальных случаях оптимизации БД MySQL.
Пришлось сегодня вставать утром пораньше чтобы воплотить обещанное в жизнь.
Централизованное управление мыслями поддерживать еще сложно, поэтому не судите строго за казусы и ляпсусы в моей статье.
В последнее время приходится достаточно часто заниматься оптимизацией производительности сайтов. И как правило «бутылочным горлышком» в производительности работы этих сайтов является именно БД, ошибки как в архитектуре так и в выполнении запросов. Начиная от неправильной расстановки индексов, либо совершенным их отсутствием, неправильным (неэкономным) выбором типов данных под определенное поле, заканчивая абсолютно нелогичной архитектурой БД и такими же нелогичными запросами.
В данной статье опишу несколько приемов, которые были использованы для приложения с 4млн+ пользователей и которое имея порядка 100млн+ хитов в сутки, а в конце опишу задачу, которая решалась недавно и может быть многоуважаемое сообщество предложит мне решения этой задачи более эффективное нежели то, к которому пришел я.
Пришлось сегодня вставать утром пораньше чтобы воплотить обещанное в жизнь.
Централизованное управление мыслями поддерживать еще сложно, поэтому не судите строго за казусы и ляпсусы в моей статье.
В последнее время приходится достаточно часто заниматься оптимизацией производительности сайтов. И как правило «бутылочным горлышком» в производительности работы этих сайтов является именно БД, ошибки как в архитектуре так и в выполнении запросов. Начиная от неправильной расстановки индексов, либо совершенным их отсутствием, неправильным (неэкономным) выбором типов данных под определенное поле, заканчивая абсолютно нелогичной архитектурой БД и такими же нелогичными запросами.
В данной статье опишу несколько приемов, которые были использованы для приложения с 4млн+ пользователей и которое имея порядка 100млн+ хитов в сутки, а в конце опишу задачу, которая решалась недавно и может быть многоуважаемое сообщество предложит мне решения этой задачи более эффективное нежели то, к которому пришел я.
Теория кэша (часть вторая, практическая, дополненная)
7 мин
Это вторая, дополнительная (upd: дополненная), часть моей статьи посвященной кэшированию информации при веб-разработке. Первая имеет название Теория кэша.
UPD: После многочисленных коментариев я сильно переработал статью, внес в неё больше конкретики и примеров, а так же убрал спорные моменты (например, касательно memcached). Спасибо всем, за конструктивную критику.
В данной статье я попытаюсь описать практические стороны кэширования, ориентированные, прежде всего, на сайты и системы управления контентом. Сразу предупреждаю, это мое личное мнение, которое не претендует на истину в последней инстанции. Большинство терминологии — моё, вы можете использовать его, если считаете нужным на своё усмотрение. Конструктивная критика приветствуется.
UPD: После многочисленных коментариев я сильно переработал статью, внес в неё больше конкретики и примеров, а так же убрал спорные моменты (например, касательно memcached). Спасибо всем, за конструктивную критику.
В данной статье я попытаюсь описать практические стороны кэширования, ориентированные, прежде всего, на сайты и системы управления контентом. Сразу предупреждаю, это мое личное мнение, которое не претендует на истину в последней инстанции. Большинство терминологии — моё, вы можете использовать его, если считаете нужным на своё усмотрение. Конструктивная критика приветствуется.
wysiwyg своими руками
3 мин
Существует куча платных\бесплатных визуальных редакторов на любой вкус и цвет. Но что, если они работают не во всех браузерах, Вас не устраивает дизайн или функциональность, или просто душа лежит к написанию своего собственного? Ответ на вопрос, как это сделать —
Firefox плагин Ubiquity
1 мин

Новый экспериментальный опенсорс плагин для Firefox от Азы Раскина предназначен для того, чтобы соединить человеческий язык и сеть.
Даже сложно обьяснить. Посмотрите лучше видео:
А здесь можете скачать ubiquity-0.1.xpi
Мануал по использованию
От себя хочу добавить. Так как я использую quicksilver на маке, этот плагин мне очень понравился. Горячей клавишей вызывается меню и просто набираешь текст, команду или поисковый запрос, и он сразу ищет в Гугле. На втором месте ищет в Википедии. Советую попробовать.
Лучшие стартапы августа
6 мин
Кросспост из блога про стартапы

Предлагаю вашему вниманию 10 самых интересных стартапов Августа, по моему мнению. Постараюсь делать такие подборки ежемесячно.
10 Место

Tuddu.ru
Сервис, позволяющий без регистрации вести собственный список задач. Сервис сделан удобно, причем как мне показалось им удобнее управлять с клавиатуры(с помощью хоткеев), нежели с помощью мышки. Помимо своего функционала проект примечателен отсуствием регистрации. Сейчас многие стараются минимизировать процедурур регистрации. Создатели этого проекта довели эту идею до абсолюта.
Илья Васильев (Разработчик): «Несмотря на свою betta-версию, в tuddu воплощены некоторые штуки, которых мне так нехватало в других сервисах:
— Регистрация на сайтах приелась уже, в tuddu ее просто нет
— В tuddu, чтобы добавить задачу в список, не надо 10 минут выбирать приоритет, прописывать теги и выбирать даты. Дела могут быть срочными и несрочными.
— Настоящий русский интерфейс, наконец-то!»
Предлагаю вашему вниманию 10 самых интересных стартапов Августа, по моему мнению. Постараюсь делать такие подборки ежемесячно.
10 Место
Tuddu.ru
Сервис, позволяющий без регистрации вести собственный список задач. Сервис сделан удобно, причем как мне показалось им удобнее управлять с клавиатуры(с помощью хоткеев), нежели с помощью мышки. Помимо своего функционала проект примечателен отсуствием регистрации. Сейчас многие стараются минимизировать процедурур регистрации. Создатели этого проекта довели эту идею до абсолюта.
Илья Васильев (Разработчик): «Несмотря на свою betta-версию, в tuddu воплощены некоторые штуки, которых мне так нехватало в других сервисах:
— Регистрация на сайтах приелась уже, в tuddu ее просто нет
— В tuddu, чтобы добавить задачу в список, не надо 10 минут выбирать приоритет, прописывать теги и выбирать даты. Дела могут быть срочными и несрочными.
— Настоящий русский интерфейс, наконец-то!»
Польза кеширования данных. Пример из реальной практики.
3 мин
С появлением и развитием memcached-подобных систем в архитектурах веб-приложений появилось еще одно звено, а именно кеш-серверы. Обычно это машины с большим объемом оперативной памяти, в которой хранятся заранее подготовленные данные. Это могут быть результаты сложных запросов к БД или же отрендеренные динамические части страниц сайта. На самом деле, кеш, как и любая другая система, может использоваться как угодно, чтобы удовлетворить нужды приложения.
nginx как reverse proxy
1 мин
Несколько читателей блога webo.in просили меня выложить конфигурацию связки nginx + Apache, на которой работает сервер. Хотя это и не относится напрямую к теме клиентской оптимизации. Однако, большинству специалистов, занимающихся клиентской оптимизацией, будет интересно узнать о настройке нескольких хостов для выдачи статики и пара других трюков, связанных с балансировкой запросов.
Также я подробно комментирую все настройки конкретно Apache, которые так или иначе относятся к самой оптимизации времени загрузки страниц.
читать дальше на webo.in →
Также я подробно комментирую все настройки конкретно Apache, которые так или иначе относятся к самой оптимизации времени загрузки страниц.
читать дальше на webo.in →
Каждый владелец сайта желает знать, где зарыта собака…
3 мин
За последние 4-года я был инициатором создания 5-ти стартапов. И на собственном опыте испытал все прелести этапа «что-то тут не так, но что?»
Мы создаем сервисы для людей. Кто хочет поспорить на эту тему? Никто? Ну и правильно. Потому что не о чем тут спорить: сегодня именно пользователи диктуют, чему быть, а чему не быть в Интернете.
Главное – уметь слушать и слышать не только и не столько хвалебные речи в адрес своего ресурса, но и критику недовольных.
Скажу больше: «недовольным» пользователям надо создавать особые, «тепличные» условия для самого полного мыслеизъявления. И вот почему.
Как обычно поступают «недовольные» пользователи?
Делюсь совершенно несекретными наработками.
Часть «недовольных» уходит и никогда больше не возвращается на сайт. Часть – отправляется перемывать косточки ресурсу на всех доступных форумах. Несколько самых смелых представителей недовольного «большинства» штурмуют почтовый ящик админа (т.е., например, мой), забрасывая его невнятно сформулированными идеями по улучшению и исправлению…
Результат?
Мозги админа – пухнут, извилины владельца – распрямляются, проект – лихорадит. Но к лучшему практически ничего не меняется.
В какой-то момент я задумался:
Мы создаем сервисы для людей. Кто хочет поспорить на эту тему? Никто? Ну и правильно. Потому что не о чем тут спорить: сегодня именно пользователи диктуют, чему быть, а чему не быть в Интернете.
Главное – уметь слушать и слышать не только и не столько хвалебные речи в адрес своего ресурса, но и критику недовольных.
Скажу больше: «недовольным» пользователям надо создавать особые, «тепличные» условия для самого полного мыслеизъявления. И вот почему.
Как обычно поступают «недовольные» пользователи?
Делюсь совершенно несекретными наработками.
Часть «недовольных» уходит и никогда больше не возвращается на сайт. Часть – отправляется перемывать косточки ресурсу на всех доступных форумах. Несколько самых смелых представителей недовольного «большинства» штурмуют почтовый ящик админа (т.е., например, мой), забрасывая его невнятно сформулированными идеями по улучшению и исправлению…
Результат?
Мозги админа – пухнут, извилины владельца – распрямляются, проект – лихорадит. Но к лучшему практически ничего не меняется.
В какой-то момент я задумался:
Бесплатный сервис для выслеживания потерянных ноутбуков
2 мин
В наши дни потерять ноутбук — значит лишиться значительной части собственной цифровой жизни. Потеря важных фотографий, записок, паролей, веб-ссылок, файлов зачастую гораздо важнее, чем несколько сотен долларов на новое железо. Вот почему вчерашний запуск проекта Adeona так важен для всех нас.
Adeona — это открытый и бесплатный проект. Названный по имени римской богини Адеоны, которая помогала потерянным детям найти путь обратно к маме, этот сервис отслеживает IP-адрес потерянного ноутбука. Сервис работает просто: сначала нужно скачать специальную программу-шпион (с открытыми исходниками), после установки эта программа начинает посылать зашифрованные послания на распределённый хостинг OpenDHT. Если ноутбук когда-нибудь потеряется, то пользователь скачивает другую программу, вводит свой логин и пароль, и получает всю информацию в расшифрованном виде, в том числе IP-адреса всех подключений ноутбука к интернету, а также служебную информацию обо всех окружающих маршрутизаторах (точках Wi-Fi). Этих данных может быть вполне достаточно, чтобы вычислить злоумышленника и быстро вернуть пропажу.
Версия «Адеоны» под Mac способна даже задействовать встроенную в ноутбук веб-камеру и сделать снимок злоумышленика.
Вся логика системы заточена на то, чтобы даже операторы сервиса не могли получить приватную информацию о владельце ноутбука в процессе работы программы-шпиона. Весь код открыт и используется надёжная криптография, так что без знания логина и пароля приватные данные невозможно расшифровать.
В альтернативных коммерческих сервисах, во-первых, приватные данные не так хорошо защищены, а, во-вторых, эти сервисы просто не бесплатные.
Поскольку код программы открыт, то любые разрабогтчики могут усовершенствовать программу и создать версию, например, для выслеживания потерянных «айфонов».
Adeona — это открытый и бесплатный проект. Названный по имени римской богини Адеоны, которая помогала потерянным детям найти путь обратно к маме, этот сервис отслеживает IP-адрес потерянного ноутбука. Сервис работает просто: сначала нужно скачать специальную программу-шпион (с открытыми исходниками), после установки эта программа начинает посылать зашифрованные послания на распределённый хостинг OpenDHT. Если ноутбук когда-нибудь потеряется, то пользователь скачивает другую программу, вводит свой логин и пароль, и получает всю информацию в расшифрованном виде, в том числе IP-адреса всех подключений ноутбука к интернету, а также служебную информацию обо всех окружающих маршрутизаторах (точках Wi-Fi). Этих данных может быть вполне достаточно, чтобы вычислить злоумышленника и быстро вернуть пропажу.
Версия «Адеоны» под Mac способна даже задействовать встроенную в ноутбук веб-камеру и сделать снимок злоумышленика.
Вся логика системы заточена на то, чтобы даже операторы сервиса не могли получить приватную информацию о владельце ноутбука в процессе работы программы-шпиона. Весь код открыт и используется надёжная криптография, так что без знания логина и пароля приватные данные невозможно расшифровать.
В альтернативных коммерческих сервисах, во-первых, приватные данные не так хорошо защищены, а, во-вторых, эти сервисы просто не бесплатные.
Поскольку код программы открыт, то любые разрабогтчики могут усовершенствовать программу и создать версию, например, для выслеживания потерянных «айфонов».
Презентация вашего стартапа
6 мин
Перевод
Вот вы развили свою идею до рабочего прототипа. Вы и ваши со-основатели опытны и уверены в себе. Ваш ангельский инвестор помог открыть вам некоторые двери, дав пару впечатляющих партнёров. Вы только и думаете о том, как бы действительно начать зарабатывать и нанять сотрудников.
Вы обеспечили внимание венчурного фонда. Ваши мечты бегут впереди возможности получить финансирование. Вы знаете, что финансирование от венчурных капиталистов предпочтительнее, чем любое другое. В действительности, вы верите, что инвестиции от правильного венчурного капиталиста сильно подвигают горизонты вашего успеха.
Так что вы открываете файл презентации вашей речи в Powerpoint.
Вы обеспечили внимание венчурного фонда. Ваши мечты бегут впереди возможности получить финансирование. Вы знаете, что финансирование от венчурных капиталистов предпочтительнее, чем любое другое. В действительности, вы верите, что инвестиции от правильного венчурного капиталиста сильно подвигают горизонты вашего успеха.
Так что вы открываете файл презентации вашей речи в Powerpoint.
Фонетический поиск
4 мин
Пару лет назад была задача написать для одного из сайтов такой поиск, который бы распознавал опечатки и предлагал бы исправленные запросы. Было перепробовано несколько вариантов, об одном из которых я и хотел тут написать. Поиск на основе звучания слов может стирать языковые границы, поскольку имена собственные на разных языках созвучны. Например, ищешь «Арнольд Шварцнеггер» на русском — находишь «Arnold Schwarzenegger» на английском, или ищешь «Michael Jordan» — находишь «Майкл Джордан», или ищешь «Чак Норрис» — и вдруг он сам тебя находит. Помимо поиска созвучных слов этот метод нивелирует большое количество опечаток. А то че-то задолбала попса, надо больше про инсайд…
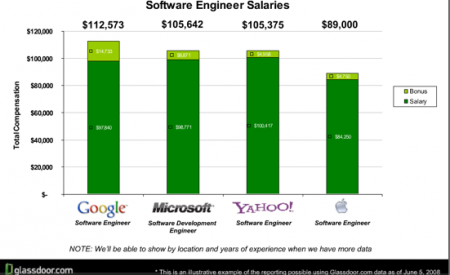
На Glassdoor можно узнать, сколько на самом деле зарабатывают в Google, Microsoft, Yahoo и где-либо еще
3 мин
Идея Glassdoor довольно проста: ты говоришь мне свою зарплату, а я тебе — свою. Этот хитрый стартап, которому удалось получить $3млн. от Benchmark Capital, появился совсем недавно. Как сообщает источник, на сайте собираются отзывы о компаниях и реальные заработные платы работников этих компаний. Все эти данные анонимны и доступны абсолютно всем зарегистрированным пользователям. (Создатели проекта планируют зарабатывать деньги на предоставлении собранной информации соискателям работы, премиум сервисам, то есть просто-напросто продавать собранную и упорядоченную информацию потенциальным рабочим).

Новый виджет Яндекс.Пробки для автолюбителей
1 мин
Привет, автолюбители и поклонники виджетов. Мы постарались и сделали симпатичный виджет, который сообщает о пробках на дорогах Москвы, Питера, Киева или Екатеринбурга, а также может являться украшением рабочего стола.
Например, он может быть мини-картой. Вот что сегодня происходило в Москве:

Вот такая, понимаешь, загогулина получается.
Например, он может быть мини-картой. Вот что сегодня происходило в Москве:
Вот такая, понимаешь, загогулина получается.
Веб сервер за пару вечеров — II
5 мин

Многие из нас собирали компьютер сами, из комплектующих. Дело не сложное, соединить с десяток шлейфов, да завинтить столько же винтиков. Но мало кто сталкивался с самостоятельной сборкой серверов, причем не обычных а в промышленном формате под стойку 19 дюймов. В этом небольшом обзоре я опишу свой опыт сборки такого сервера, постараюсь показать что это не сложно, и остановлюсь на главных моментах, на что нужно смотреть. На написание этого обзора меня толкнуло то, что информации о сборке rack 19’ серверов в рунете очень мало, и приходилось её искать буквально по крупицам.
Создание превью изображения на основне свойства Overflow
3 мин
Перевод
 По просьбам пользователей после прочтения статьи Визуализация данных на CSS
По просьбам пользователей после прочтения статьи Визуализация данных на CSS Цель данной статьи заключается в том, чтобы реализовать возможность создания превью для изображения, размеры которого можно устанавливать самостоятельно. Бывает так, что у нас нет свободного места на странице, чтобы показать превью картинки полностью. Но и делать из картинок обрезки не хочется. Трюк, приведенный в статье, позволит создать нужные нам размеры превью и отображать полный его размер при наведении курсора на превью.
PHP Performance Series: Caching Techniques
6 мин
Перевод
Кеширование промежуточного кода (Opcode Caching)
Кэширование кода это один из самых легких и эффективных путей увеличения производительности в PHP. Использовании данного вида кэширования позволит избавиться от большого количества неэффективностей, возникающих при процессе запуска выполнения кода. Кэширование кода сохраняет промежуточный код в памяти для того чтобы не компилировать PHP-код каждый раз при запуске файла.
Кэширование кода это один из самых легких и эффективных путей увеличения производительности в PHP. Использовании данного вида кэширования позволит избавиться от большого количества неэффективностей, возникающих при процессе запуска выполнения кода. Кэширование кода сохраняет промежуточный код в памяти для того чтобы не компилировать PHP-код каждый раз при запуске файла.
Установка и настройка Apache2+PHP5+MySQL+XDebug & Eclipse+PDT+XDebug в Ubuntu 7.10
4 мин
В этом топике я расскажу как установить и настроить Apache2 + PHP5 + MySQL + virtual hosts + xdebug, а также XDebug в Eclipse+PDT.