

Вячеслав Москаленко (Ленвендо)
Я буду рассказывать вам об инструментах высоконагруженных проектов, кэшировании, в частности, о memcached, Redis-е и о сервисе очередей RabbitMQ или в простонародье «кролике».
В первой части доклада я расскажу о том, что такое memcached — базовые понятия, что такое Redis, о его особенностях, и чем эти два сервиса отличаются. Расскажу о практическом применении в наших проектах обоих сервисов.
А во второй части я буду рассказывать о брокере сообщений RabbitMQ, об основных понятиях, которые есть в «кролике», о том, как работает маршрутизация сообщений между продюсерами и консьюмерами. Также расскажу о практическом применении в наших проектах данного брокера сообщений.
О кэшировании. Думаю, многие из вас хоть что-то кэшировали в своих веб-проектах, поэтому все будет очень просто и доступно.
Что такое кэш? Это посредник между клиентом, который запрашивает данные, и основным, как правило, медленным, хранилищем. Такой посредник позволяет получать наши данные очень быстро. Как правило, данные хранятся в оперативной памяти в случае memcached и Redis-a. Эффективное использование кэша позволяет нам снизить нагрузку на наши сервера БД.
Возникает вопрос — когда и что нам кэшировать? Понятно, что полезно кэшировать часто запрашиваемые данные, т.е. если у нас какой то маленький садик и там 100 пользователей в час, то большой нагрузки на базу не будет, и кэширование будет малоэффективно. Вот, в больших высоконагруженных проектах, когда мы хотим снизить нагрузку на БД, мы используем кэш.
Также необходимо понимать, какие данные мы можем/не можем кэшировать. Простой пример: когда пользователь оформляет заказ в интернет-магазине, и нам необходимо получить остатки товара из внешних систем, нам приходится делать это в онлайне, потому что эти данные мы не можем кэшировать, т.к. может случиться так, что следующий пользователь возьмет данные из кэша и будет ошибка. Соответственно, кэшировать можно только те данные, которые можно сохранять, например, несколько часов, сутки и т.д.
Инструменты кэширования, о которых пойдет речь, это memcached и Redis.
Начнем с первого. Мemcached — сервис для кэширования данных в оперативной памяти, обладающий высокой производительностью. Его история начинается в 2003 г. Brad Fitzpatrick разработал его для Livejournal, где его успешно внедрили и ускорили свой сервис.
Возможности memcached: он очень быстрый, вне зависимости от количества данных, которые мы храним, у него простой интерфейс — можно засетить (set) данные, можно получить, через время жизни удалить ключ и т.д.; в memcached поддерживаются атомарные операции — incr/decr, append/prepend; позволяет легко расширять количество серверов, и даже падение одного из серверов просто рассчитывается как непопадание в кэш, т.е. просто нет данных в кэше.
Ограничения memcached: длина ключей максимум 250 байт, объем данных, который можно хранить под одним ключом, ограничивается 1 Мб. Потеря ключей в memcached может случаться по времени жизни, по лимиту памяти, либо при отказе сервера.
Т.к. я являюсь PHP-программистом, я привел пример, как в PHP использовать memcached.

Для PHP есть 2 расширения — одно использует библиотеку libmemcached, а второе — просто расширение php-memcache. Libmemcached имеет больше возможностей реализовывать данные, по умолчанию сериализуют их при помощи PHP, но можно определить сериализатор JSON, например. Мы создаем объект memcached, добавляем наш сервер на localhost-е, дефолтный порт у нас 11211. Мы можем засетить некую строку, засетить некий массив под ключ «array», выставить время жизни, когда данные должны «протухнуть». Простой операцией get мы получаем свои данные. Т.е. ничего сложного. Попросите своих системных администраторов, кто еще не использовал, поставить memcached, php-расширение, написать свою грамотную «обертку» для memcached, и использовать для кэширования часто запрашиваемых данных, которые нагружают вашу БД и которые можно кэшировать.
Далее я расскажу о том, что такое Redis, чем он отличается от memcached.
В Redis-е есть поддержка большого количества типов данных, среди которых строки, хэши, списки, множества и сортированные множества. Также Redis умеет периодически скидывать свои данные на диск — можно после, например, тысячи обновлений наших данных скидывать это все на диск. Redis поддерживает LRU очищение, там можно определять различные стратегии очистки ключей, можно рандомно, например, очищать, можно давно не используемые, либо удалять только те ключи, у которых выставлено время жизни и т.д. Также можно сделать так, чтобы он, вообще, не очищал свою память, но тогда при обновлении данных ваш клиент Redis-а будет выдавать ошибку. Лучше пусть он очищает самые неиспользуемые данные.
Redis поддерживает master-slave репликацию, поддерживает простейшие очереди, т.е. может создавать каналы, на них подписываться, публиковать в них какие-то сообщения, читать. Поддерживает транзакции с помощью команды MULTI/EXEC, LUA-скрипты. Еще у Redis-а отличная документация — заходим на сайт redis.io и там все доступно, с примерами, все расписано.
Далее я хочу рассказать о типах данных, и какие команды у нас есть в Redis-е.
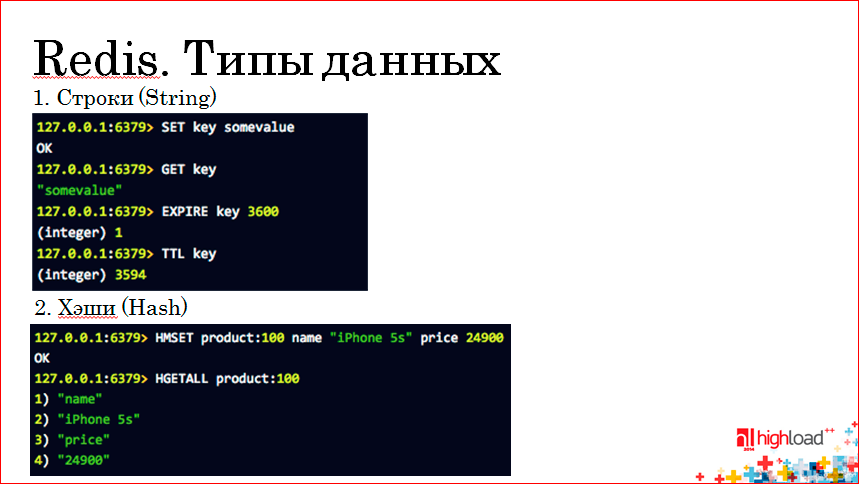
Первый тип данных — это строки. Интерфейс простой. Мы можем по конкретному ключу засетить некоторое значение. На слайде приведен пример-скриншот из консольного клиента к Redis-у. Мы так же, как к SQL коннектимся на определенный порт, на конкретный хост, и можем работать с Redis-ом, выставляя значения, получая их данные, выставляя время жизни в секундах, можно запросить время оставшееся.
Следующий тип данных — это хэши. Хэш — это структура, в которой можно сохранить поля и их значения некоего объекта.
Для работы с хэшами используются команды HSET, HMSE. Чтобы получить значение полей хэша, мы используем команду HGETALL и получаем все свойства нашего хэша.
Частный пример — в хэшах можно хранить сессию пользователя.
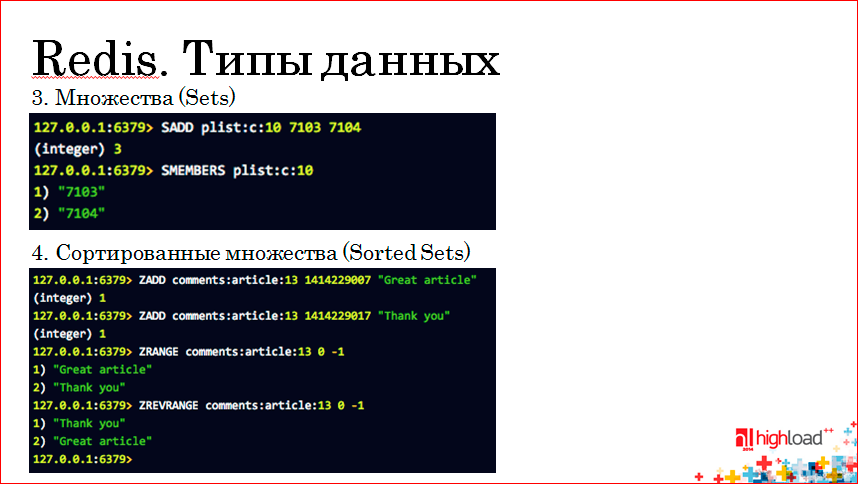
Следующий тип данных — это множества (Sets). Redis позволяет хранить по конкретному ключу некое множество элементов, при этом множество в Redis отвечает за его уникальность. Т.е. если мы добавим во множество два одинаковых элемента, то он всегда там будет один. Для добавления элемента во множество используется команда SADD, для получения всех элементов множества используется команда SMEMBERS. Ключам мы можем выставлять с помощью команды EXPIRE время жизни, удалять ключи и т.д.
Еще один тип данных — это сортированные множества. Они работают почти так же, как Sets, но за тем исключением, что мы можем выставить так называемые «очки» каждого элемента в нашем множестве. В качестве очков в примере на слайде выше — передается TIMESTAMP в комментариях к статье 13, т.е. мы именуем свой ключ так, чтобы было понятно, что это комментарий к статье 13.
Мы добавляем 2 элемента во множество и можем получить отсортированный список по убыванию либо по возрастанию наших очков.
Есть еще такой тип данных в Redis-е как списки. Здесь можно пушить в наше множество элементы слева, справа, брать элементы с конкретного индекса до конкретного индекса.
Какие есть клиенты для PHP?
Есть расширение phpredis, он написан на С. Также есть библиотеки Predis, написанная на PHP, Rediska, RedisServer — класс, который открывает сокет на конкретный порт и просто общается с Redis-ом, Resident — форк RedisServer-а, но он еще использует расширение phpredis для ускорения и для получения более высокой производительности.
Мои рекомендации — использовать, конечно, phpredis, потому что он по всем бенчмаркам и тестам быстрее, он написан на С, и все php-реализации зачастую медленнее.
На следующем слайде представлены различия между memcached и Redis.

На самом деле и Redis, и memcached нужно использовать под конкретные задачи, т.е. если нам нужно хранить какие-то свои структуры данных, какие-то множества, сортированные множества, и нам нельзя потерять данные, то, конечно, здесь на помощь приходит Redis. Нужно учитывать то, что Redis однопоточный.
Теперь о примерах.

У нас как-то на проекте возникла задача просто показывать карточку быстрого просмотра нашего товара, т.е. на странице есть миниатюрки наших товаров и при клике мы должны показать детальное описание нашего товара. Задача стала таким образом, чтобы снизить нагрузку максимально в бэкенд, т.е. меньше обращаться к базе и т.д.
Мы решили таким способом:
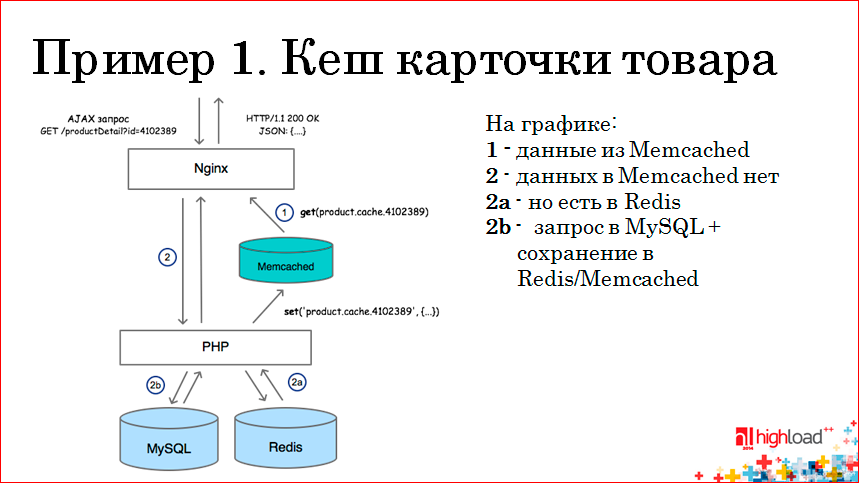
Т.е. когда прилетает AJAX-запрос на наш фронтенд Ngnix, у Ngnix стоит модуль, который умеет работать с memcached, т.е. мы сначала запрашиваем данные в memcached по ключу, и если данные есть (а там хранится JSON у нас для продуктов), то мы сразу же возвращаем этот JSON. Это работает очень быстро.
Если данных нет, наш запрос проксируется на PHP и там у нас две ситуации — карточка товара может лежать в Redis-е, также в виде JSON, тогда мы берем из Redis-а, сохраняем в memcached и отдаем ее дальше клиенту.
Если у нас нет ни там, ни там — ни в Redis-е, ни в memcached, мы запрашиваем нашу карточку товара из MySQL, сохраняем ее в Redis, дублируем эти данные в memcached и так же возвращаем. При следующих запросах наши карточки товаров выдаются уже напрямую из memcached.
Следующим, более сложным, примером, где используются большинство типов данных Redis-а, — это параметрический поиск:

У нас в каталоге есть рубрики, в каждой рубрике есть свой набор фильтров, то есть стандартная панель фильтров. В каждой группе фильтров есть свои варианты и при выборе конкретных вариантов мы должны пользователям показать список товаров, удовлетворяющий данным фильтрам.
Раньше это было все сделано запросами в MySQL, там были сложные выборки, анализ и всевозможных свойств, какие есть фильтры в данной рубрике и т.д. Это все работало очень медленно. Мы решили полностью поменять модель хранения данных и решили использовать Redis. При этом для каждого варианта фильтров в рубрике мы решили хранить ID товаров, удовлетворяющие каждому варианту.

Например, в категории «Телефоны», у которой ID=100, у нас есть две группы фильтров — «Производители» и «Цвет».
Допустим, у нас в Redis-е для Samsung-а есть вот 4 товара — 201, 202, 203, 204, а для Philips — 301, 302, 303. Ключ, соответственно, содержит ID рубрики, фильтр и вариант фильтра. Если пользователь выбирает в панели фильтров Samsung, мы запрашиваем в Redis, получаем ID товаров, отдаем их в компонент списка товаров, и наш компонент отображает 4 товара. Если пользователь выбирает еще производителя Philips, мы и делаем два запроса в Redis, берем объединение этих множеств и, соответственно, показываем семь элементов в нашем каталоге.
Далее, если пользователь выбирает вариант фильтра из другой группы фильтров, мы достаем, к примеру, цвет красный, т.е. мы хотим посмотреть все Samsung-и и Philips-ы красного цвета, мы берем множество объединения первых двух вариантов, пересекаем, соответственно, с красными телефонами и получаем два товара — 202, 303.
Особенности данной реализации — она гораздо быстрее, чем работа с MySQL, но есть одно но: необходимо при каждых изменениях наших сущностей, т.е. когда меняются свойства товара — товар переходит из рубрики в рубрику, у товара меняется производитель, товар активируется/деактивируется, создаются, меняются, удаляются фильтры, — мы должны эти множества все пересчитывать. Т.е. это основная работа, которую предстоит нам делать, и у нас это реализовано через очереди, т.е. мы наши множества пересчитываем, используя брокер сообщений RabbitMQ, о котором речь пойдет дальше.
Говоря об очередях, я буду говорить о «кролике». RabbitMQ — это платформа, реализующая систему обмена сообщениями посредством протокола AMQP. Особенности данного сервиса — это надежность, гибкая система маршрутизации сообщений, поддержка кластеризации, поддержка различных плагинов, которые позволяют нам смотреть состояние наших очередей, смотреть, сколько в них сообщений, какие консьюмеры их обрабатывают, также можно писать кастомные плагины, чтобы поменять стандартное поведение нашего брокера. Написан RabbitMQ на Erlang. И клиенты для работы с «кроликом» есть для большинства языков — для Java, Ruby, Python, .NET, PHP, Perl, C/C++ и др. На сайте «кролика» есть отличные tutorial-ы, хорошо задокументированные возможности. Для каждого языка есть даже примеры, все доступным языком описано.
Какие же есть основные понятия при работе с «кроликом»?
Я расскажу о том, какие есть типы обменников в «кролике», как происходит маршрутизация, и буду показывать диаграммы, как происходят в workflow сообщения от продюсера к консьюмеру.
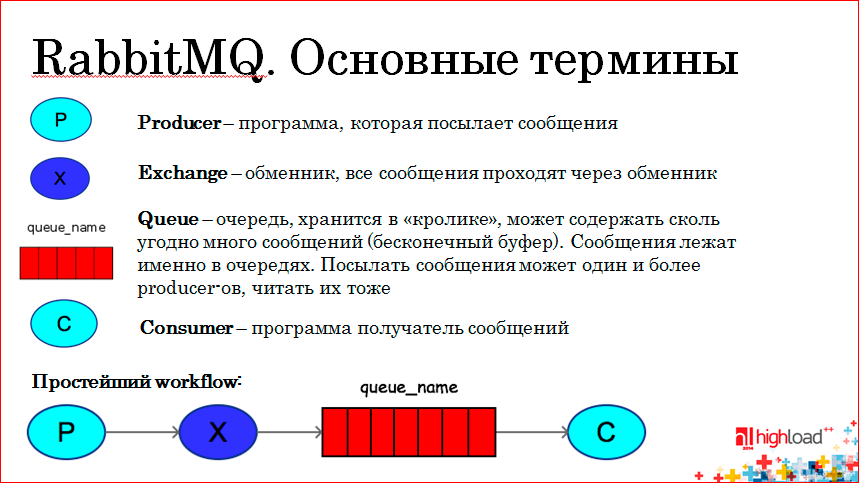
Продюсер (Р) — это программа, которая посылает сообщение. Сообщения попадают не напрямую в очередь, а через обменник — Exchange (Х), и уже обменник решает, в какую очередь мы должны послать то или иное сообщение. Понятно, что есть очереди, в которых хранятся сообщения, а также есть консьюмеры — программы, которые эти очереди читают и каким-то образом обрабатывают.
Простейший workflow — продюсер посылает сообщение в обменник, обменник решает, в какую очередь посредством binding-ключа послать сообщение, и консьюмер уже читает конкретную очередь. Получив сообщение из очереди, консьюмер может подтверждать, что да, я это сообщение получил, обработал, сообщение можно из очереди убирать, т.е. есть механизм подтверждения того, что сообщения обработано в «кролике». Если консьюмер взял сообщение и внезапно упал, то сообщение останется в очереди, пока мы и не подтвердим, что мы его обработали.
Можно настроить чтение из очереди таким образом, чтобы любое сообщение, взятое консьюмером, всегда забиралась, т.е. автоподтверждение выставляем в true и подтверждать ничего не надо, если это неважно.
Какие же у нас бывают обменники?
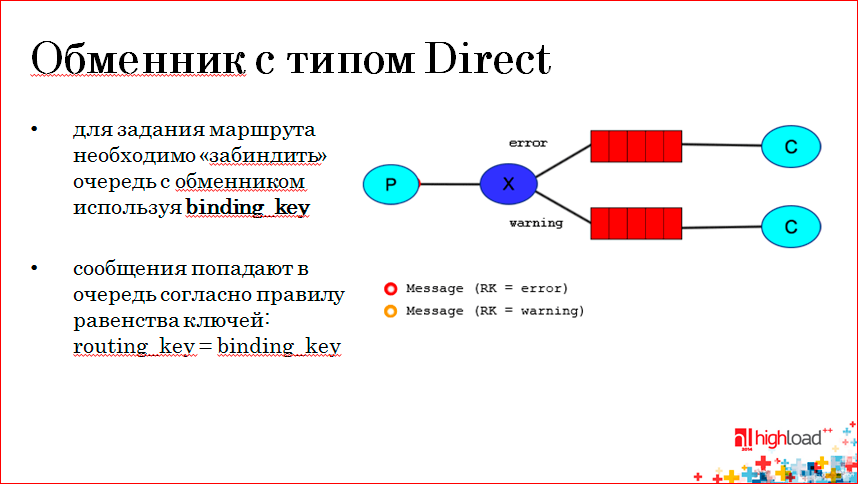
Первый тип — это Direct Exchange, и суть его в следующем: обменник может быть забинден с очередью различными правилами. Например, здесь верхняя очередь забиндена с Exchange посредством binding-ключа error, а нижняя очередь забиндена с обменником через ключ warning. Продюсер, посылая сообщение в обменник, передает routing-ключ сообщения и, вот например, на слайде красненькое сообщения имеет routing-ключ error, если оно совпадает с binding-ключом, то оно попадает в верхнюю очередь. Если сообщения имеет routing-ключ warning, т.е. строгое соответствие routing-ключ с binding-ключом конкретной очереди. Мы можем разные сообщения отдавать в разные консьюмеры.
Следующий тип обменника — это Fanout.
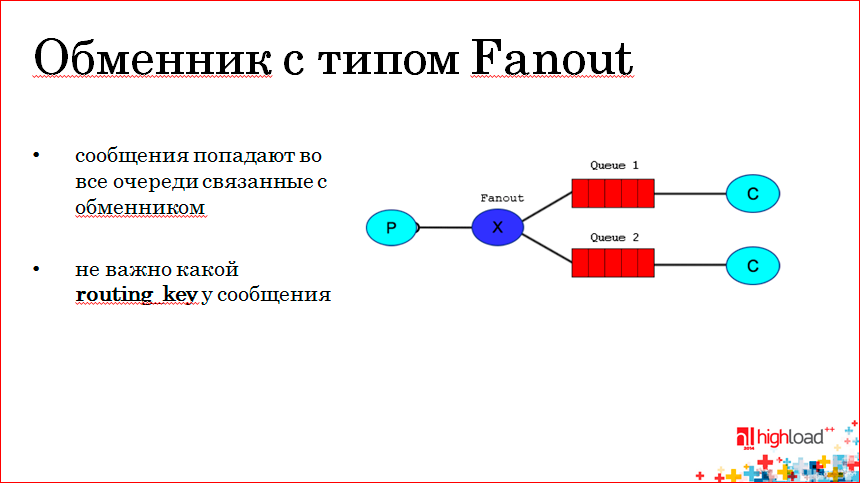
Здесь смысл в том, что наша очередь биндится с обменником неважно каким ключом, просто биндится, и все сообщения, которые попадают в Exchange с типом Fanout, попадают во все очереди, которые забиндены на этот обменник. Соответственно, послав одно сообщение, если необходимо послать некую информацию нескольким сервисам, мы можем использовать обменник с типом Fanout, и наше сообщение попадает в оба консьюмера.
Следующий тип — обменники с типом Topic.

Обменники этого типа могут биндиться с очередями посредством ключей, которые могут содержать такие спецсимволы как звездочка (*) и решетка (#). Что это значит? Звездочка в binding-ключе может заменяться ровно на одно слово, а решетка может заменяться на 0 и более слов.
В данном примере очередь Q1 забиндена посредством ключа *.orange.*, а вторая очередь забиндена двумя ключами, т.е. она будет принимать сообщения, которые начинаются с lazy, а остальное неважно — там может быть сколько угодно других слов, и слова разделяются точкой, и второй binding-ключ — это состоящий из трех слов: первые два неважно какие, главное чтобы в конце стоял «кролик».
Если у нас продюсер послал сообщение с таким routig-ключом, как первый пример на слайде, оно попадает в обе очереди, потому что оно состоит из трех слов, вторым словом содержит orange, а на конце у него слово rabbit.
RabbitMQ на практике.
Мы используем «кролика» много где, например, для пересчета данных в нашем Redis-e (см. выше). Т.е. у нас есть много процессов-продюсеров, которые меняют какие-то данные, мы посылаем эти команды на изменения в наши очереди, там у нас не две очереди, их больше, и консьюмеры уже обрабатывают конкретные сообщения. Например, товар А деактивировался, мы должны его удалить. Мы посылаем сообщение в виде JSON-а в нашу очередь, консьюмер его читает, коннектится к Redis-у, там у нас master-slave репликация, мы пишем, соответственно, в мастер, парсим этот JSON, видим, что необходимо удалить такой-то товар из такой-то рубрики, из таких-то множеств, удаляем его, и наш фронтенд уже читает со slave Redis-а и показывает обновленные данные.
Собственно, это все, что я хотел рассказать про эти простые инструменты — кэширование и очереди. Есть вопросы?
Вопрос из зала: Могли бы Вы поподробнее рассказать, как у вас реализовано «протухание» кэша, т.е. как вы его высчитываете, какие значения выставляете? Например, когда вы показываете карточку товара и, допустим, изменилась цена — как быстро у вас обновится кэш?
Ответ: На самом деле там все просто — при обновлении цены мы не обновляем кэш, по условиям задачи это не особо важно, мы кэшируем только на час, через час эти данные «протухают», т.е. цена обновится и через час.
Вопрос из зала: Тогда можно более актуальное? Допустим, у вас есть товар, который продается по акционной цене, очевидно, он быстро уйдет. Тогда как часто у вас обновляется остаток?
Ответ: Остатки мы не кэшируем. В случае с карточкой товара, на самом деле, можно просто дописать некую логику, которая при изменении цены товара будет брать из memcached соответствующую карточку товара, зная его ID, и обновлять в ней цену.
Вопрос из зала: Вот тут как раз это поподробнее — про логики обновления кэшей в разных ситуациях?
Ответ: Если нам необходимо обновить данные в кэше, у нас есть обработчики на изменение товаров. Если товар меняет цену, мы просто в этом обработчике коннектимся к memcached, просто формируем новую карточку товара и сохраняем ее в memcached. Моментально цена будет обновлена для клиентов.
Вопрос из зала: Есть ли какие-то встроенные средства понимания частоты использования данных в кэше, чтобы понять, какие редко используются и в случае переполнения их очищать? Или это все вручную надо делать?
Ответ: Я не знаю таких инструментов.
Вопрос из зала: Какое максимальное качество очередей вы использовали в одном проекте и для чего?
Ответ: У нас порядка 20-ти очередей в «кролике». Там есть очереди, которые пересчитывают наши данные в Redis, есть очередь, которая следит за тем, какие смс каким клиентам отослать, есть очередь по статусной схеме, жизненный цикл заказа тоже через очереди проходит, происходит смена статусов… Порядка 20 очередей, не так много. Наши консьюмеры успевают обрабатывать все сообщения, больше упираемся в запросы к MySQL. Можно несколько консьюмеров, если у вас очередь большая, натравить, и он разберет уже эту очередь быстрее в два-три раза.
Вопрос из зала: Как у вас устроена пагинация в Redis-е. когда фильтр выбирает значение?
Ответ: На самом деле наш компонент фильтров не занимается пагинацией, этим занимается другой компонент, которому мы отдаем результирующие ID товаров, т.е. мы отдает его в компонент, а он уже по ID делаем более простые выборки из нашего хранилища и делает пагинацию.
Вопрос из зала: У вас на диаграмме было — используется и memcached, и Redis. Я понимаю, что последний используется, потому что больше возможностей по множествам и типам данных, но почему в этом варианте еще и memcached используется, что это вам дало?
Ответ: Мemcached там используется, потому что у нас уже есть в ngnix модуль, который с memcached умеет работать, а Redis есть в бэкенде, потому что у нас есть еще и другие процессы, которые могут складывать карточку товара в Redis. Грубо говоря, клиент заходит на карточку товара, в обычную, не popup. Там уже кэшируется карточка товара в Redis и в следующий раз, если пользователь придет с другой страницы, но уже, например, откроет popup, у нас нет данных в memcached, и наш запрос долетел до PHP, то мы там, не подключая тяжелый framework, напрямую сначала обращаемся в Redis. Если данные в нем есть, то очень быстро отдаем. Соответственно, если данных в Redis-е нет, то мы подключаем тяжелый framework, берем данные из MySQL и складываем их в Redis и memcached.
Вопрос из зала: Скажите, вы как-нибудь мониторите работу очередей?
Ответ: Да, этим занимаются системные администраторы, плюс у нас поставлен плагин для «кролика», который отображает состояние очередей, а также с помощью munin-а системные администраторы настраивают какие-то критически значения.
Вопрос из зала: Бывают ситуации, когда обрабатываются слабо связанные данные, например, аккаунт, и к нему привязано несколько кэшей. Иногда используется тегирование ключей кэша. хотелось бы узнать, как вы решали эту проблему, насколько я знаю, у memcached нет этой опции и, вообще, решали ли вы ее?
Ответ: Такую задачу мы не решали, поддержки я такой не видел, но думаю, тут надо уже на уровне вашего приложения какие-то
Вопрос из зала: Есть ли у RabbitMQ система событий, чтобы не гонять каждый раз обработчик очередей по кругу, а чтобы «кролик» дергал при каком-то событии сам конкретный скрипт?
Ответ: Да, это на уровне врапперов. В консьюмер можно передать callback, и когда приходит сообщение, оно там автоматом выполняется.
Вопрос из зала: Как обстоят дела с отказоустойчивостью RabbitMQ? Насколько часто ваш администратор, насколько интенсивно вынужден за ним следить, и как в ваших приложениях, вообще, политика отказа сервиса очередей реализована, которая в отличие от системных очередей, в которых можно записать сообщения, все равно может отвалиться, и что при этом произойдет?
Ответ: Детали администрирования, честно говоря, я вам точно не расскажу, но ваши сообщения никуда не пропадают, если вдруг он отказал. Плюс есть кластеризация, с помощью которой системные админы могут построить решение данных проблем.
Вопрос из зала: Вы говорили о том, что в RabbitMQ реализован механизм гарантированной доставки, а существует ли механизм уведомления продюсера о том, что сообщение доставлено до консьюмера?
Ответ: Мы такого не делали, но думаю, можно реализовать такой механизм на уровне вашего приложения.
Вопрос из зала: Вы говорите, что Redis по всем параметрам лучше, чем memcached. А зачем тогда memcached использовать?
Ответ: Я не говорю, что Redis по всем параметрам лучше, чем memcached, просто потом под каждую свою задачу можно использовать либо Redis, либо memcached. Последний быстрее, но в Redis-e больше возможностей. Если что-то просто надо кэшировать, и эти данные не так важны, даже если они пропадут, то если вы используете memcached, то ничего страшного. Его можно использовать, он очень надежный, высокопроизводительный сервер.
Вопрос из зала: А насколько в среднем быстрее получается memcached? 10%, 20%, 50%?
Ответ: Ну, я смотрел различные бенчмарки, везде разные данные — кто-то в несколько потоков делает записи чтения, кто-то показывает, что Redis местами на 10% лучше, чем memcached, или наоборот. Сам бенчмарков не проводил, в наших приложениях это не самое узкое место, у нас другие проблемы. Но такие бенчмарки есть, и данные разнятся. Но скорости сопоставимы.
Этот доклад — расшифровка одного из лучших выступлений на конференции разработчиков высоконагруженных систем HighLoad++.
Также некоторые из этих материалов используются нами в обучающем онлайн-курсе по разработке высоконагруженных систем HighLoad.Guide — это цепочка специально подобранных писем, статей, материалов, видео. Уже сейчас в нашем учебнике более 30 уникальных материалов. Подключайтесь!
Ну и главная новость — мы начали подготовку весеннего фестиваля "Российские интернет-технологии", в который входит восемь конференций, включая HighLoad++ Junior. Мы, конечно, жадные коммерсы, но сейчас продаём билеты по себестоимости — можно успеть до повышения цен
