В одной из дискуссий недавно, я перечислил основные системы, делающие работу ИТ-компании цивилизованной. Список получился весьма обширный, и я решил оформить его как самостоятельную статью.
Похожую конструкцию можно увидеть во многих компаниях, более того, я наблюдал компании, в которых долгое время отсутствовала часть этих систем, и из-за нерешаемых постоянных проблем эти системы начали появляться стихийно.
Всё ниженаписанное касается компаний/отделов, в которых работает работает квалифицированный персонал, то есть курсы «офис для начинающих» им не нужны. Так же как не нужны групповые политики на рабочих станций и специальный админ для перекладывания ярлычков на рабочем столе и установки любимой программы. Другими словами, это бэк-офис айтишников, значительно отличающийся от бэк-офиса остальных отделов.
Краткий спойлер содержимого: VCS, репозиторий исходного кода, code-review, build-сервера, CI, таск-трекер, вики, корпоративный блог, функциональное тестирование, репозиторий для пакетов, система управления конфигурацией, бэкапы, почта/jabber.
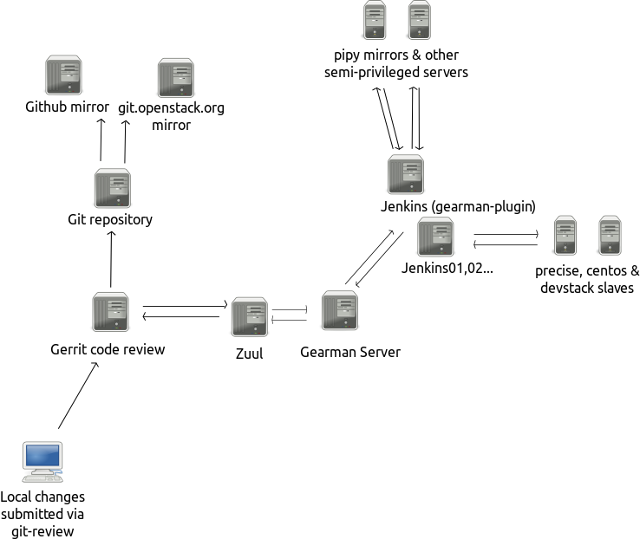
Картинка с фрагментом обсуждаемой инфраструктуры:
Итак, начнём с простого.
Рабочие места: компьютер с кнопками (порядка 90-100 шт) на каждое рабочее место. Желательно так же внешний/второй/третий монитор. Обычно используются ноутбуки, весьма широко — макбуки. Пользователи имеют админа или sudo на своих машинах, сами определяют себе комплект удобного ПО, включая редактор, отладчик, почтовый клиент, браузер, терминалку и т.д.
Интернет. Обычно в офисе WiFi и BYOD (другими словами, свободно приносимые свои собственные ноутбуки, планшеты и телефоны, злоупотребляющие офисным WiFi'ем). Часто проводной сети может вообще не быть. Безопасность в такой сети условная, потому что все коммуникации идут зашифрованными. Интернетов надо много. И не только для котиков на ютубе в рабочее время, но и для внезапно срочно «прямо сейчас скачать DVD с сырцами, чтобы сравнить версию пакета». Из реальной жизни, кстати. С учётом всяких stackoverflow и прочих айтишных ресурсов, интернет должен быть неограниченный, неконтролируемый, и чем быстрее, тем лучше.
Проехали простое. Дальше серьёзное.
Cистема контроля версий (VCS) должна быть общей, «каждому своё» тут не прокатит. Стандарт де-факто — git, условно популярен mercurial (hg), экзотичен bazar (bzr), из прошлого века svn/cvs/vcs. Плюс у виндузятников свой мир, там что-то другое.
Система контроля версий работает локально, так что должен быть центральный репозиторий исходных кодов, в который пушат все (кто должен пушить). Весьма и весьма популярным является gitlab. Есть проприетарные решения, есть github для тех, кому лениво самому поднимать. Она же решает вторую важную вещь: pull requests. Чтобы один человек мог посмотреть, что сделал другой до того, как оно попадёт в основную ветку (общий репозиторий). Замечу, что pull requests имеет смысл, даже если code review как таковой не проводится. Принцип простой — один написал, другой смерджил (merge).
Если код сложный, то понадобится система для code review. Code review подразумевает, что программисты (или сисадмины — devops, всё такое) просматривают код друг друга, и существует некоторая формальная процедура принятия кода — например, «должны посмотреть и одобрить не меньше двух человек, из них один должен быть сеньёр/лид». Примеры: gerrit, Crucible. Если сложность балансирует на грани, то можно попытаться соблюдать соглашение добровольно, обсуждая в комментариях в gitlab'е. Но как всё добровольное, за чем не следят роботы, оно иногда будет давать осечки.
Управление командой людей в минимальном виде осуществляется посредством планировщика задач (task-tracker'а) — redmine, jira, mantis. Чаще всего он выполняет и роль баг-трекера. Основная цель — формализация постановки задачи, снятие неоднозначностей и нахождение виновных, когда кто-то что-то сделал не так (ты так сказал? Нет, не так понял! — после этого смотрится текст задачи и становится понятно, кто промахнулся). В случае появления таск-трекера следует старательно изживать устное право, особенно со стороны начальника/тимлида. Надо что-то поменять? Ставь задачу. Объём бюрократии минимальный, количество хаоса уменьшается кратно.
Практически обязательным можно считать наличие своей собственной вики — mediawiki, moin-moin, confluence, dokuwiki — что угодно, куда можно писать статьи, видимые другим членам команды, и где можно редактировать за другими. Идеальное место для складывания текстов «как сделать то-то», регламентов, результатов обсуждения, планируемых архитектурных решений, объяснения почему будет сделано именно так, а не иначе. Хорошо структурированная вики хорошо, но даже беспорядочная груда текстов кратно полезнее устного предания, которое затухает вместе с уволившимся сотрудником, который «всё это знал».
Если вики поддерживает блоггинг, хорошо, если нет, надо либо договориться о формате ведения блога в вики, либо поднять что-то для его внутрикорпоративного ведения. Что писать в такой блог? Потратили 4 часа вылавливая странный баг в конфиге? Описать в блоге — в следующий раз сами же искать будете, ибо прочитать быстро, а делать самому медленно. Начали разбираться с долгой-долгой проблемой, которую целиком в голове не удержать? Вместо текстового редактора на компьютере в качестве блокнотика — писать в вики. Иногда может оказаться так, что кто-то из коллег прямо в процессе отладки прочитает уже написанное и скажет более короткое решение. А в какой-то момент блог компании станет едва ли не самым ценным ресурсом в сложных ситуациях (№2 после интернетов).
Писать код, который работает на рабочей станции, на которой его писали — это редкая роскошь. Чаще всего (и чем дальше, тем больше) код представляет из себя middleware — прослойку между другими крупными кусками серверного кода, и требует обширного окружения для продуктивной работы. «Этому приложению для отладки надо mysql с копией рабочей базы, memcached, redis и snmp к коммутатору». Такое окружение на рабочей станции поднимать — то ещё удовольствие. А бывает так, что проектов несколько, и у каждого своё окружение.
Таким образом, мы получаем первую сложную вещь: стенды для программистов. В реальной жизни это может быть микроконтроллер, подключенный по usb, или ферма серверов hadoop'а. Важно, что у программиста его стенд, похожий хоть в какой-то степени на рабочую конфигурацию, где программист может проверять результаты своей работы сразу, как написал. Экономить не стоит, и у каждого программиста должен быть свой стенд. Если слишком дорого — надо поднимать мокапы, если мокапы не могут быть подняты, то у компании проблемы — программисты пишут «на продакшене», причём если программистов несколько, то одновременно. Если программистов не пускают на продакшен, то они пишут вслепую — прощай продуктивность.
Далее, есть вопрос о том, как код появляется на продакшене. Чаще всего это пакеты (deb/rpm), исполняемые файлы (exe), либо просто скучная выкладка (html). Заметим, имеет смысл даже «скучную выкладку статики» завернуть в пакет. Есть команды, которые выкладывают прямо из гита (определённого бранча, тэга, или даже мастера, с предположением, что разработка идёт в других бранчах).
Сборка пакетов может быть очень запутанной и сложной, особенно, если код пишется не с нуля, а зависит от уже существующих конфигураций и кучи других пакетов. Имеет смысл настроить систему сборки пакетов. Для этого используют CI (continuous integration) в минимальной конфигурации, часто с ручным управлением (пойти в интерфейс и нажать на «запустить задачу» сборки пакета). Стандарт для opensource — jenkins. Из наиболее известных проприетарных — team city. Минимальная конфигурация просто берёт указанный бранч/тег/репозиторий и собирает пакет. Который потом можно скачать из интерфейса CI'я.
Но все привыкли к aptitude install — и для этого надо поднять свой миррор, или репозиторий пакетов. Тот же CI может выкладывать пакеты в репозиторий. Клик мышкой — и исходный код можно ставить на всех серверах, где подключен репозиторий. Заметим, наличие репозиториев позволяет быстро «выкатывать» приложение на большом числе серверов в автоматическом или полу-автоматическом режиме, и даже иметь разделение на experimental/testing/production/oldstable. Ещё это даёт возможность очень быстро восстанавливать повреждения, так как пакетные менеджеры имеют все необходимые средства для валидации целостности установленных файлов и могут скачать пакет заново и восстановить изменённые файлы (на заметку веб-мастерам, у которых всякие злые бэкдоры в вордпрессе портят любимые php-файлы). Если при сборке нужны пакеты, которых нет в дистрибутиве, то их следует так же пакетировать. Продакшен, подъём которого зависит от аптайма pypi, это грустное зрелище. Заметим, часть зависимостей может быть актуальной только при сборке, в этом случае имеет смысл настроить репликацию используемого каталога пакетов на свои сервера.
CI, заодно, может осуществлять прогон тестов. Юнит-тесты чаще всего прогоняются на этапе сборки пакета (после компиляции). А вот для функциональных (приёмочных) тестов надо поднимать (ещё одно, а то и много разных) тестовое окружение. После успешной компиляции запускается установка пакета на стенде и проверка на работоспособность. Если у компании есть ресурсы, то по каждому странному багу делается тест, который его отловит. В минимальном виде нужно проверить базовые happy paths, то есть «клиент может прийти, увидеть товар, положить в корзину, оплатить и купить». Всякие sad path (у клиента нет денег/версия ядра не соответствует модулю) проверять тоже можно, но это значительно больше ресурсов. Но даже happy path тесты сильно улучшают стабильность.
Если конфигураций и тестов много, то имеет смысл поднять интеграцию системы code-review с тестами. Наиболее известный — zuul, связывающий gerrit c jenkins'ом. В этом случае предложение на code review присылается только после того, как коммит программиста (сисадмина) прошёл тесты — экономится время людей, не говоря уже о том, что львиное число простых багов отлавливается на этапе «борьбы с gerrit'ом». Идеальным примером того, как это работает на сотнях независимых разработчиков, является инфраструктура проекта openstack.
Если тесты настроены, code review отработан, всегда есть предыдущая версия, то имеет смысл задуматься о continuous integration, его оригинальном смысле, то есть автоматическое выкатывание изменений на продакшен сразу, как прошли тесты и code review.
К этому обычно нужна почта, jabber (с которыми хорошо бы слинковать таск трекер и CI), возможно, рассылки. Часто имеет смысл поднять свой vpn-сервер, чтобы люди могли работать откуда угодно без затруднений с закрытыми портами и т.д.
Зачем «своё», когда есть гуглопочта? Ну, потому что когда начнут таинственно недоходить письма от nagios'а, потому что гуглю не нравятся bulk messages для group address, то борьба с гуглом может занять больше времени, чем свой почтовый сервер.
И, разумеется, ко всему этому прикладывается своя собственная мета-инфраструктура:
Вот такое скромное хозяйство у хорошей IT-компании. Заметим, это только рабочие инструменты, тут нет никаких «каталогов пользователей» (и, вообще, вопрос авторизации не разбирался), систем контроля доступа, учёта рабочего времени, зарплат, бизнес-планирования и других вещей, которые нужны не разработчикам/сисадминам, а стейкхолдерам.
Считаю в человеко-часах, на з/п умножайте сами. Цифры крайне приблизительные (то есть взяты с потолка):
Заметим, это чистое рафинированное время (которого не так уж много). Кроме того, многие вещи требуют вовлечения всех сотрудников, то есть их нельзя выделить на отдельного специального человека, то есть время внедрения будет размазываться поверх обычной работы.
При условии, что будет выделяться примерно 30% рабочего времени на собственную инфраструктуру (это много), то внедрение с нуля займёт от трёх месяцев до года. Это при постоянном энтузиазме, если возникают паузы, время увеличивается (непропорционально времени простоя, потому что всё вокруг меняется и после паузы придётся много переделывать). Ещё раз взяв с того же потолка зарплату, учтя отпуска/больничные/авралы, получаем порядка 1-2 миллионов рублей, без стоимости железа, электричества и лицензий, только за работу (цифра учитывает расходы на «белые» налоги и сборы).
О цене сопровождения. Очень сильно зависит от инвестиций в систему управления конфигурациями, бэкапы и тщательность реализации. В хорошей системе должна составлять не больше нескольких часов в месяц, плюс отдельные затраты на добавление новых проектов, конфигураций, изменения существующих и т.д.
Сколько на это нужно серверов? Ответ сильно зависит от тестовых конфигураций, если мы предположим, что тестовая конфигурация — это мелкий LAMP-сервер (1Гб памяти на всё про всё), то при плотной упаковке виртуалок можно обойтись 2-5 серверами (~200-300 т.р. на каждый) для всего, плюс отдельный бэкап-сервер. Ах, да, допишите в список работ по настройке, ещё поддержание этой стопки виртуалок и виртуализаторов.
Всё это, конечно, меркнет по сравнению со стоимостью одного рабочего места для оператора башенного подъёмного крана (6 миллионов рублей) или роботизированного фрезерно-сверлильного станка высокой точности (даже не нашёл цен в публичном доступе для примера).
Можно ли сэкономить и не делать?
Можно.
Более того, ничего фатального не произойдёт. Однако, некоторые рабочие процессы будут дольше, некоторые будут утомительными (отправка по почте друг другу zip'ов с изменениями), ряд сотрудников будет вынужден присутствовать в офисе для того, чтобы что-то сделать (например, согласовать изменения в коде), болезнь одного из сотрудников может сильно затруднить жизнь других (а кто у нас тут был, кто знал как правильно изменения выкатывать?). Частично будет страдать качество кода или снижаться скорость работы программистов. Какие-то особо крутые штуки будут просто не доступны, но и без них будет хорошо. Часть сотрудников будет занята низкопродуктивной работой, и из-за этого не только не заниматься тем, за что им деньги платят, но и демотивироваться, потому что монотонный скучный, чреватый ошибками, повторяющийся из раза в раз процесс на работе — просто отличный повод для внедрения вышенаписанного. Или обновления резюме, да.
Как все капитальные инвестиции в эффективность труда, эти все системы не являются обязательными. В конце-концов, ракеты в космос успешно запускали с какой-то там попытки и без git'а с code review и тестами.
Компании чаще идут по пути внедрения подобных систем постепенно, и было бы большой ошибкой начать стартап с трёхмесячного подъёма всей инфраструктуры, не написав ни одной полезной строчки кода.
Часто останавливаются на каком-то этапе. Они обычно вызваны нежеланием персонала, потому, что у него (персонала) нет той боли, которую должна устранить система. Если боли реально нет — отлично, можно сэкономить на особо продвинутых сложных вещах. Если же «боли нет» потому, что человек никогда не пробовал «по другому», то может быть, что остановка вызвана всего лишь нехваткой квалификации.
Заметим, если незнание гита можно считать аналогом безграмотности или невнятной речи, то есть, программист, который не умеет пользоваться гитом, либо очень «специальный» (1С, SAP), либо не очень программист, то «незнание» gerrit'а вполне понятно и потребует обучения. Чем выше уровень интеграции процессов, тем больше шансы, что критическая масса сотрудников просто не захочет учить так много. В отличие от бухгалтерш, сисадмины и программисты обучаемы довольно быстро, но если «быстро» не получается, то сопротивление может быть куда большее, чем возмущённые стоны от смены версии 1С. Нет ничего страшнее, чем ключевой технический персонал, возмущённый обязательным внедрением неудачного технического решения.
Чаще всего новые внедрения происходят при наличии энтузиазма со стороны кого-то из сотрудников, либо совсем невыносимой боли, которую не маскируют в саботаже, а высказывают явным образом коллегам/начальству.
Заметим, текст выше описывает именно бэк-офис, потому что вопросы мониторинга продакшена, сборки оттуда логов, метрик загрузки и прочих умных вещей совсем в этой статье не рассматриваются.
P. S. Ах да, чуть не забыл — в списке оборудования — ещё нужен принтер в офис, чтобы заявления на отпуск распечатывать.
Похожую конструкцию можно увидеть во многих компаниях, более того, я наблюдал компании, в которых долгое время отсутствовала часть этих систем, и из-за нерешаемых постоянных проблем эти системы начали появляться стихийно.
Всё ниженаписанное касается компаний/отделов, в которых работает работает квалифицированный персонал, то есть курсы «офис для начинающих» им не нужны. Так же как не нужны групповые политики на рабочих станций и специальный админ для перекладывания ярлычков на рабочем столе и установки любимой программы. Другими словами, это бэк-офис айтишников, значительно отличающийся от бэк-офиса остальных отделов.
Краткий спойлер содержимого: VCS, репозиторий исходного кода, code-review, build-сервера, CI, таск-трекер, вики, корпоративный блог, функциональное тестирование, репозиторий для пакетов, система управления конфигурацией, бэкапы, почта/jabber.
Картинка с фрагментом обсуждаемой инфраструктуры:
Итак, начнём с простого.
Рабочие места: компьютер с кнопками (порядка 90-100 шт) на каждое рабочее место. Желательно так же внешний/второй/третий монитор. Обычно используются ноутбуки, весьма широко — макбуки. Пользователи имеют админа или sudo на своих машинах, сами определяют себе комплект удобного ПО, включая редактор, отладчик, почтовый клиент, браузер, терминалку и т.д.
Интернет. Обычно в офисе WiFi и BYOD (другими словами, свободно приносимые свои собственные ноутбуки, планшеты и телефоны, злоупотребляющие офисным WiFi'ем). Часто проводной сети может вообще не быть. Безопасность в такой сети условная, потому что все коммуникации идут зашифрованными. Интернетов надо много. И не только для котиков на ютубе в рабочее время, но и для внезапно срочно «прямо сейчас скачать DVD с сырцами, чтобы сравнить версию пакета». Из реальной жизни, кстати. С учётом всяких stackoverflow и прочих айтишных ресурсов, интернет должен быть неограниченный, неконтролируемый, и чем быстрее, тем лучше.
Проехали простое. Дальше серьёзное.
Cистема контроля версий (VCS) должна быть общей, «каждому своё» тут не прокатит. Стандарт де-факто — git, условно популярен mercurial (hg), экзотичен bazar (bzr), из прошлого века svn/cvs/vcs. Плюс у виндузятников свой мир, там что-то другое.
Система контроля версий работает локально, так что должен быть центральный репозиторий исходных кодов, в который пушат все (кто должен пушить). Весьма и весьма популярным является gitlab. Есть проприетарные решения, есть github для тех, кому лениво самому поднимать. Она же решает вторую важную вещь: pull requests. Чтобы один человек мог посмотреть, что сделал другой до того, как оно попадёт в основную ветку (общий репозиторий). Замечу, что pull requests имеет смысл, даже если code review как таковой не проводится. Принцип простой — один написал, другой смерджил (merge).
Если код сложный, то понадобится система для code review. Code review подразумевает, что программисты (или сисадмины — devops, всё такое) просматривают код друг друга, и существует некоторая формальная процедура принятия кода — например, «должны посмотреть и одобрить не меньше двух человек, из них один должен быть сеньёр/лид». Примеры: gerrit, Crucible. Если сложность балансирует на грани, то можно попытаться соблюдать соглашение добровольно, обсуждая в комментариях в gitlab'е. Но как всё добровольное, за чем не следят роботы, оно иногда будет давать осечки.
Управление командой людей в минимальном виде осуществляется посредством планировщика задач (task-tracker'а) — redmine, jira, mantis. Чаще всего он выполняет и роль баг-трекера. Основная цель — формализация постановки задачи, снятие неоднозначностей и нахождение виновных, когда кто-то что-то сделал не так (ты так сказал? Нет, не так понял! — после этого смотрится текст задачи и становится понятно, кто промахнулся). В случае появления таск-трекера следует старательно изживать устное право, особенно со стороны начальника/тимлида. Надо что-то поменять? Ставь задачу. Объём бюрократии минимальный, количество хаоса уменьшается кратно.
Практически обязательным можно считать наличие своей собственной вики — mediawiki, moin-moin, confluence, dokuwiki — что угодно, куда можно писать статьи, видимые другим членам команды, и где можно редактировать за другими. Идеальное место для складывания текстов «как сделать то-то», регламентов, результатов обсуждения, планируемых архитектурных решений, объяснения почему будет сделано именно так, а не иначе. Хорошо структурированная вики хорошо, но даже беспорядочная груда текстов кратно полезнее устного предания, которое затухает вместе с уволившимся сотрудником, который «всё это знал».
Если вики поддерживает блоггинг, хорошо, если нет, надо либо договориться о формате ведения блога в вики, либо поднять что-то для его внутрикорпоративного ведения. Что писать в такой блог? Потратили 4 часа вылавливая странный баг в конфиге? Описать в блоге — в следующий раз сами же искать будете, ибо прочитать быстро, а делать самому медленно. Начали разбираться с долгой-долгой проблемой, которую целиком в голове не удержать? Вместо текстового редактора на компьютере в качестве блокнотика — писать в вики. Иногда может оказаться так, что кто-то из коллег прямо в процессе отладки прочитает уже написанное и скажет более короткое решение. А в какой-то момент блог компании станет едва ли не самым ценным ресурсом в сложных ситуациях (№2 после интернетов).
Писать код, который работает на рабочей станции, на которой его писали — это редкая роскошь. Чаще всего (и чем дальше, тем больше) код представляет из себя middleware — прослойку между другими крупными кусками серверного кода, и требует обширного окружения для продуктивной работы. «Этому приложению для отладки надо mysql с копией рабочей базы, memcached, redis и snmp к коммутатору». Такое окружение на рабочей станции поднимать — то ещё удовольствие. А бывает так, что проектов несколько, и у каждого своё окружение.
Таким образом, мы получаем первую сложную вещь: стенды для программистов. В реальной жизни это может быть микроконтроллер, подключенный по usb, или ферма серверов hadoop'а. Важно, что у программиста его стенд, похожий хоть в какой-то степени на рабочую конфигурацию, где программист может проверять результаты своей работы сразу, как написал. Экономить не стоит, и у каждого программиста должен быть свой стенд. Если слишком дорого — надо поднимать мокапы, если мокапы не могут быть подняты, то у компании проблемы — программисты пишут «на продакшене», причём если программистов несколько, то одновременно. Если программистов не пускают на продакшен, то они пишут вслепую — прощай продуктивность.
Далее, есть вопрос о том, как код появляется на продакшене. Чаще всего это пакеты (deb/rpm), исполняемые файлы (exe), либо просто скучная выкладка (html). Заметим, имеет смысл даже «скучную выкладку статики» завернуть в пакет. Есть команды, которые выкладывают прямо из гита (определённого бранча, тэга, или даже мастера, с предположением, что разработка идёт в других бранчах).
Сборка пакетов может быть очень запутанной и сложной, особенно, если код пишется не с нуля, а зависит от уже существующих конфигураций и кучи других пакетов. Имеет смысл настроить систему сборки пакетов. Для этого используют CI (continuous integration) в минимальной конфигурации, часто с ручным управлением (пойти в интерфейс и нажать на «запустить задачу» сборки пакета). Стандарт для opensource — jenkins. Из наиболее известных проприетарных — team city. Минимальная конфигурация просто берёт указанный бранч/тег/репозиторий и собирает пакет. Который потом можно скачать из интерфейса CI'я.
Но все привыкли к aptitude install — и для этого надо поднять свой миррор, или репозиторий пакетов. Тот же CI может выкладывать пакеты в репозиторий. Клик мышкой — и исходный код можно ставить на всех серверах, где подключен репозиторий. Заметим, наличие репозиториев позволяет быстро «выкатывать» приложение на большом числе серверов в автоматическом или полу-автоматическом режиме, и даже иметь разделение на experimental/testing/production/oldstable. Ещё это даёт возможность очень быстро восстанавливать повреждения, так как пакетные менеджеры имеют все необходимые средства для валидации целостности установленных файлов и могут скачать пакет заново и восстановить изменённые файлы (на заметку веб-мастерам, у которых всякие злые бэкдоры в вордпрессе портят любимые php-файлы). Если при сборке нужны пакеты, которых нет в дистрибутиве, то их следует так же пакетировать. Продакшен, подъём которого зависит от аптайма pypi, это грустное зрелище. Заметим, часть зависимостей может быть актуальной только при сборке, в этом случае имеет смысл настроить репликацию используемого каталога пакетов на свои сервера.
CI, заодно, может осуществлять прогон тестов. Юнит-тесты чаще всего прогоняются на этапе сборки пакета (после компиляции). А вот для функциональных (приёмочных) тестов надо поднимать (ещё одно, а то и много разных) тестовое окружение. После успешной компиляции запускается установка пакета на стенде и проверка на работоспособность. Если у компании есть ресурсы, то по каждому странному багу делается тест, который его отловит. В минимальном виде нужно проверить базовые happy paths, то есть «клиент может прийти, увидеть товар, положить в корзину, оплатить и купить». Всякие sad path (у клиента нет денег/версия ядра не соответствует модулю) проверять тоже можно, но это значительно больше ресурсов. Но даже happy path тесты сильно улучшают стабильность.
Если конфигураций и тестов много, то имеет смысл поднять интеграцию системы code-review с тестами. Наиболее известный — zuul, связывающий gerrit c jenkins'ом. В этом случае предложение на code review присылается только после того, как коммит программиста (сисадмина) прошёл тесты — экономится время людей, не говоря уже о том, что львиное число простых багов отлавливается на этапе «борьбы с gerrit'ом». Идеальным примером того, как это работает на сотнях независимых разработчиков, является инфраструктура проекта openstack.
Если тесты настроены, code review отработан, всегда есть предыдущая версия, то имеет смысл задуматься о continuous integration, его оригинальном смысле, то есть автоматическое выкатывание изменений на продакшен сразу, как прошли тесты и code review.
Финальные аккорды
К этому обычно нужна почта, jabber (с которыми хорошо бы слинковать таск трекер и CI), возможно, рассылки. Часто имеет смысл поднять свой vpn-сервер, чтобы люди могли работать откуда угодно без затруднений с закрытыми портами и т.д.
Зачем «своё», когда есть гуглопочта? Ну, потому что когда начнут таинственно недоходить письма от nagios'а, потому что гуглю не нравятся bulk messages для group address, то борьба с гуглом может занять больше времени, чем свой почтовый сервер.
И, разумеется, ко всему этому прикладывается своя собственная мета-инфраструктура:
- Это всё надо конфигурировать. По уму — система управления конфигурациями. chef, puppet, ansible, saltstack.
- Это всё надо мониторить. Мониторинг — nagios, shinken, zabbix, icinga
- Это всё надо бэкапить. Да-да, репозитории тоже надо бэкапить, потому что собирать по разработчикам 20-30 репозиториев с «у кого самая свежая версия» — то ещё удовольствие. А комментарии в merge request'ах вообще невосстановимы.
- Ко всему этому нужны доменные имена, и лучше, чтобы домен или поддомен был в полном управлении отдела, чтобы с каждой новой A-записью не надо было ходить и канючить «ну добавьте мне ещё один стенд в DNS». Свой DNS открывает ещё важную возможность генерировать записи автоматически (например, для адресов ipmi-интерфейсов серверов)
Вот такое скромное хозяйство у хорошей IT-компании. Заметим, это только рабочие инструменты, тут нет никаких «каталогов пользователей» (и, вообще, вопрос авторизации не разбирался), систем контроля доступа, учёта рабочего времени, зарплат, бизнес-планирования и других вещей, которые нужны не разработчикам/сисадминам, а стейкхолдерам.
И сколько это стоит?
Считаю в человеко-часах, на з/п умножайте сами. Цифры крайне приблизительные (то есть взяты с потолка):
- Рабочее место сотрудника — 8 часов на человека (обычно учитывается в «первый рабочий день»)
- gitlab — 4-8 часов
- gerrit — 16-24 часа
- jenkins (база) — 2-4 часа
- jenkins (сборка пакетов) — 1-32 часа на репозиторий (зависит от репозитория и количества уже поднятых — первые поднимать тяжело, дальше проще)
- собственный репозиторий — 2-4 часа
- wiki — 1-16 часов
- блог-система — 2-4 часа
- таск-трекер — 1-8 часов
- стенды для программистов — ???
- стенды для тестов — ???
- настройка запуска тестов (при условии их наличия) — 1-2 часа
- zuul — 2-16 часов
- jabber-сервер — 1-4 часа
- почтовый сервер — 0.5-12 часов (в зависимости от размеров и роли)
- Рассылки — 1-3 часа
- система управления конфигурацией — x2 от каждого пункта (кроме сборки пакетов)
- бэкап — ~1 час на каждый сервис
- dns к этому всему +1 час
Заметим, это чистое рафинированное время (которого не так уж много). Кроме того, многие вещи требуют вовлечения всех сотрудников, то есть их нельзя выделить на отдельного специального человека, то есть время внедрения будет размазываться поверх обычной работы.
При условии, что будет выделяться примерно 30% рабочего времени на собственную инфраструктуру (это много), то внедрение с нуля займёт от трёх месяцев до года. Это при постоянном энтузиазме, если возникают паузы, время увеличивается (непропорционально времени простоя, потому что всё вокруг меняется и после паузы придётся много переделывать). Ещё раз взяв с того же потолка зарплату, учтя отпуска/больничные/авралы, получаем порядка 1-2 миллионов рублей, без стоимости железа, электричества и лицензий, только за работу (цифра учитывает расходы на «белые» налоги и сборы).
О цене сопровождения. Очень сильно зависит от инвестиций в систему управления конфигурациями, бэкапы и тщательность реализации. В хорошей системе должна составлять не больше нескольких часов в месяц, плюс отдельные затраты на добавление новых проектов, конфигураций, изменения существующих и т.д.
Сколько на это нужно серверов? Ответ сильно зависит от тестовых конфигураций, если мы предположим, что тестовая конфигурация — это мелкий LAMP-сервер (1Гб памяти на всё про всё), то при плотной упаковке виртуалок можно обойтись 2-5 серверами (~200-300 т.р. на каждый) для всего, плюс отдельный бэкап-сервер. Ах, да, допишите в список работ по настройке, ещё поддержание этой стопки виртуалок и виртуализаторов.
Всё это, конечно, меркнет по сравнению со стоимостью одного рабочего места для оператора башенного подъёмного крана (6 миллионов рублей) или роботизированного фрезерно-сверлильного станка высокой точности (даже не нашёл цен в публичном доступе для примера).
А оно точно нужно?
Можно ли сэкономить и не делать?
Можно.
Более того, ничего фатального не произойдёт. Однако, некоторые рабочие процессы будут дольше, некоторые будут утомительными (отправка по почте друг другу zip'ов с изменениями), ряд сотрудников будет вынужден присутствовать в офисе для того, чтобы что-то сделать (например, согласовать изменения в коде), болезнь одного из сотрудников может сильно затруднить жизнь других (а кто у нас тут был, кто знал как правильно изменения выкатывать?). Частично будет страдать качество кода или снижаться скорость работы программистов. Какие-то особо крутые штуки будут просто не доступны, но и без них будет хорошо. Часть сотрудников будет занята низкопродуктивной работой, и из-за этого не только не заниматься тем, за что им деньги платят, но и демотивироваться, потому что монотонный скучный, чреватый ошибками, повторяющийся из раза в раз процесс на работе — просто отличный повод для внедрения вышенаписанного. Или обновления резюме, да.
Как все капитальные инвестиции в эффективность труда, эти все системы не являются обязательными. В конце-концов, ракеты в космос успешно запускали с какой-то там попытки и без git'а с code review и тестами.
Заключение
Компании чаще идут по пути внедрения подобных систем постепенно, и было бы большой ошибкой начать стартап с трёхмесячного подъёма всей инфраструктуры, не написав ни одной полезной строчки кода.
Часто останавливаются на каком-то этапе. Они обычно вызваны нежеланием персонала, потому, что у него (персонала) нет той боли, которую должна устранить система. Если боли реально нет — отлично, можно сэкономить на особо продвинутых сложных вещах. Если же «боли нет» потому, что человек никогда не пробовал «по другому», то может быть, что остановка вызвана всего лишь нехваткой квалификации.
Заметим, если незнание гита можно считать аналогом безграмотности или невнятной речи, то есть, программист, который не умеет пользоваться гитом, либо очень «специальный» (1С, SAP), либо не очень программист, то «незнание» gerrit'а вполне понятно и потребует обучения. Чем выше уровень интеграции процессов, тем больше шансы, что критическая масса сотрудников просто не захочет учить так много. В отличие от бухгалтерш, сисадмины и программисты обучаемы довольно быстро, но если «быстро» не получается, то сопротивление может быть куда большее, чем возмущённые стоны от смены версии 1С. Нет ничего страшнее, чем ключевой технический персонал, возмущённый обязательным внедрением неудачного технического решения.
Чаще всего новые внедрения происходят при наличии энтузиазма со стороны кого-то из сотрудников, либо совсем невыносимой боли, которую не маскируют в саботаже, а высказывают явным образом коллегам/начальству.
Заметим, текст выше описывает именно бэк-офис, потому что вопросы мониторинга продакшена, сборки оттуда логов, метрик загрузки и прочих умных вещей совсем в этой статье не рассматриваются.
P. S. Ах да, чуть не забыл — в списке оборудования — ещё нужен принтер в офис, чтобы заявления на отпуск распечатывать.
