Comments 13
Как учить иностранные слова?
По моей программе «L’école» ( https://lecole.free.nf/Prg/Lecole.php ):


В программе три основных режима работы («Конспект», «Видео» и «Экзамен» : оригинал => перевод) и три альтернативных (перевод => оригинал). При этом выводится статистика правильных и неправильных ответов. Плюс озвучка оригинальных слов.
Не смог у вас на сайте найти описание методики Scholium.
Не смог у вас на сайте найти описание методики Scholium.
Методики, особой, как таковой – нет. Есть описание старых версий программы «Scholium-1.02» и «Scholium-2.1» ( https://lecole.free.nf/articles.php ). То, что хоть как-то можно назвать «методикой», описано в статье: «Система обучения иностранным языкам «Scholium» («Сколиум»). Учим иностранный язык (и не только) самостоятельно и независимо по методу: Запоминание руками + Интерактивный звук.» ( https://lecole.free.nf/Articles/scholium0.php ).
По сути, это просто набор методов, под новым названием: Система обучения «L’école, v. 1.01» : Запоминание руками + Интерактивный звук + Чтение по слогам + Буквальный контекстный перевод by Scholium (Сколиум). Там (в последней версии обучающей программы) используются и другие моменты, но о них говорится в статьях, описывающих эту новую программу, которые на сайте выкладываются после их публикации, здесь, на «Хабре».
В общем, обучающая система, как и всё в этом Мире, неторопливо развивается :) .
Я правильно понимаю, что современные научные исследования в области SLA (да и обучения вообще) вы сознательно игнорируете?
Я правильно понимаю, что современные научные исследования в области SLA (да и обучения вообще) вы сознательно игнорируете?
Правильно! Только, не сознательно. Поскольку, просто не знаю, что это такое :) .
Зачем это мне? Я же не коммерческий продукт делаю, а пет-проект, чтобы не скучать, ну и, если сильно повезет, то самому выучить один или несколько иностранных языков.
Да, как говорил Шестов, с возрастом способность к запоминанию иностранных слов и усвоению грамматики сильно падает. Легче написать несколько версий обучающей программы и подготовить кучу данных для нее, чем реально их освоить. Ибо «такова селява!» (либо «се ля ви», либо «се ля вас»).
Тем не менее, даже если ничего у меня лично с языками не выйдет, то, я не вижу в этом ничего страшного. Всегда смогу сказать: «Зато было нескучно!» :) . Но, если программа и данные к ней окажутся полезными для молодых мозгов, то я буду этому только рад.
Фактически моя метода заключается в следующем. Реально мы учим язык по принципу триграммы либо пентаграммы. Триграмма это:
Работа с обучающей программой (набор руками, интерактивный звук, чтение по слогам, видео-режим просмотра данных, контроль усвоения, случайная последовательность отображаемых данных, БКП – буквальный контекстный перевод – см. https://polezp.narod.ru/Pics/BKP.jpg , прямой и обратный порядок – оригинал / перевод и обратно).
Создание двуязычных субтитров к оригинальным видео (типа: https://my.mail.ru/mail/emmerald/video/_myvideo/28.html ) и видео-книг (вроде: https://my.mail.ru/mail/emmerald/video/_myvideo/27.html )
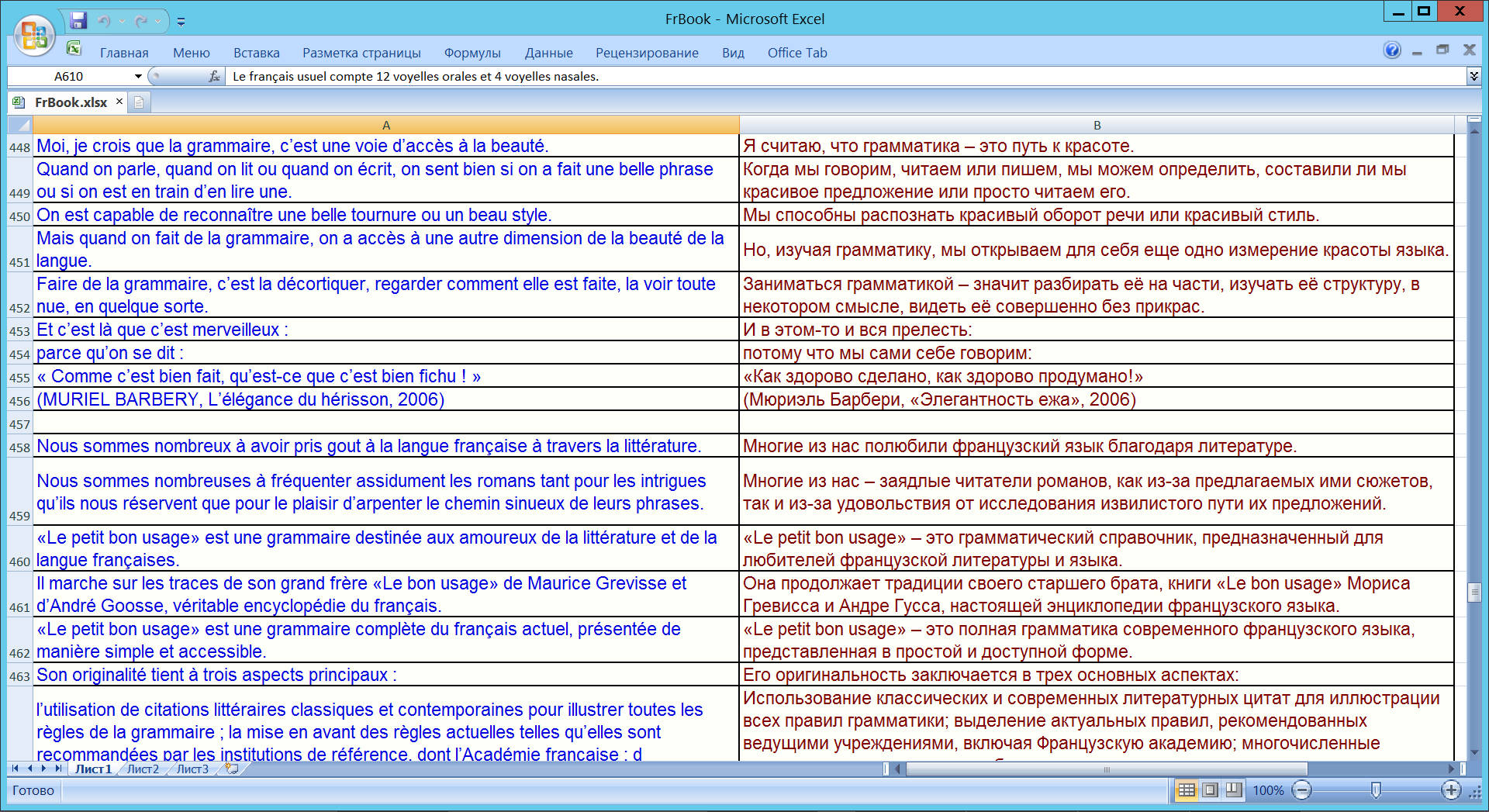
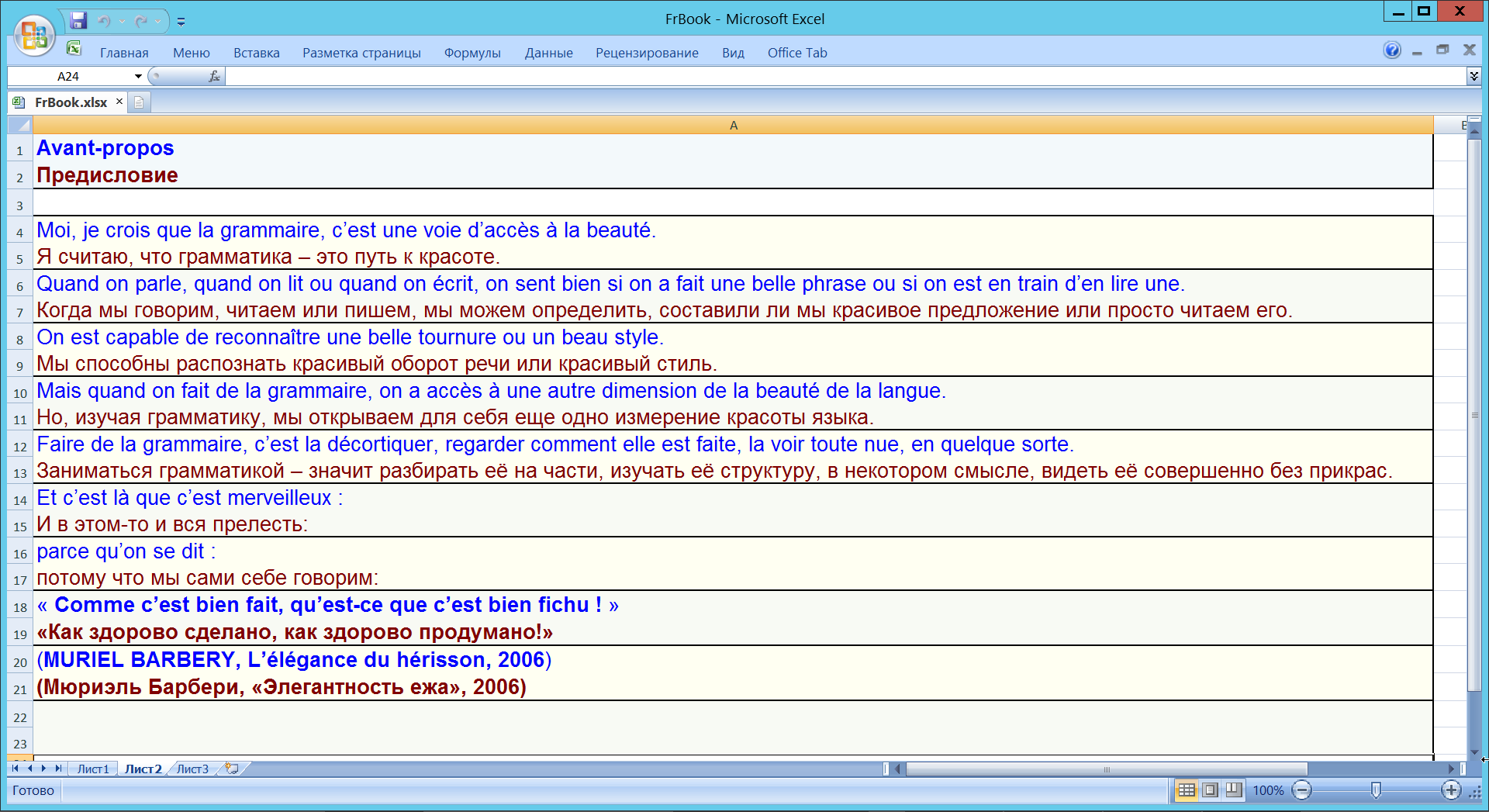
Создание двуязычных книг (см. http://zarion.webservis.ru/Pics/FrBookH.png и http://zarion.webservis.ru/Pics/FrBookV.png )
{kind=link}
{kind=link}
{kind=link}
Пентаграмма.это тоже самое, плюс:
Работа с репетиторами либо преподавателями иностранного языка. При желании, можно ограничится видео-лекциями, например для изучения французского весьма хорош видео-курс @lhexagoneplus на Ютубе.
Контакты с носителями языка, например, общение на международных форумах, в комментариях под видео иностранцев и т.п.
Пока, меня больше устраивает «триграмма»: Программа + Видео + Книги. В данный момент занимаются созданием двуязычных книг по грамматике на языках оригинала (французском, английском и т.п.). В том числе для англоязычной книги по грамматике французского языка. Читать такие книги – менее скучно, чем аналогичные книги русскоязычных авторов.
Как-то так. Вот и спрашивается, зачем мне SLA, если мне и без него нескучно :) ?
Интересный подход и сайт. Тоже пришёл к пониманию того, что пассивного словарного запаса недостаточно, но в какой-то мере это исправляется тренажёрами, в которых сначала показывается русское слово, а потом английское. Anki как-то всегда отпугивала сложностью, привязкой к компьютеру, не очень дружелюбным интерфейсом, использовал другие. Но да, возникает проблема не тех ассоциаций. Ты видишь слово, пусть даже русское, вспоминаешь английское и вроде бы кажется, что раз уж по русскому слову смог вспомнить, то в речи на ура будет вылетать, но не совсем так. В речи ты переключаешься на английский и возвращаться на русский для срабатывания ассоциации не успеешь и вообще неправильно. Да и ассоциация будет визуальная, а картинок со словами нет, когда говоришь. Нужна ассоциация "ощущение потребности слова - английское слово". Ну и со временем осваиваешь по несколько синонимов и не знаешь, что выбирать. Правда, решал это просто. Отключал режим написания, а в голове давал сразу все синонимы, переворачивал карточку и отмечал, вспомнилось или нет.
С LingQ довольно долго занимался и нравится сама идея - есть корпус освоенных слов, можно взять любой текст и видеть насколько хорош твой "coverage" для него. Но это неплохо на начальных этапах. Когда уровень B2-C1 основные значения основных слов выучены, а дьявол в деталях: у обычных с виду слов могут быть необычные значения, всякие сочетания. Добавишь слово как неизвестное, повылезает на обычных значениях во многих текстах, портя картинку. Вот тут нейросеть и могла бы пригодиться - об этом дальше.
Посмотрел ваш сайт. Очень интересные идеи и грамотное ненавязчивое использование нейросетей как раз там, где надо. Понятно, что это не может быть долго бесплатным, но, надеюсь, удешевление нейросетей сделает цену доступной. Режим раскладки произнесенного по фонемам очень удобный. Видел такое еще в Elsa, но там всё стало слишком заморочено и дорого. Понравилась карта звуков и карта грамматики. Сразу виден текущий уровень и это наилучшая замена любой геймификации - показывает прогресс, горизонт того, что надо освоить. Но вот всё-таки было бы идеальным дополнением иметь такую же карту ещё и для лексики, тоже по уровням A1-C2. Причём отдельными единицами можно считать даже не слова, а семантические единицы, а также добавлять туда же и сочетания слов. Какой вот смысл учить слово "побери" в русском, если оно встречается исключительно в выражении "чёрт побери"? Можно, кстати, и словоформы выделять отдельно - неправильные глаголы, исключения из множественных. Всё это ведь не появится автоматически, требует запоминания. Есть словари, где разные значения слова разделяются по уровням, оксфордский, кажется.
Тогда была бы полная картина. Вот, на A1 надо знать минимум такой набор слов, правил грамматики. Знать слова это значит эффективно использовать в 4-х режимах: чтение, аудирование, написание, использование в речи. Для всего этого, думаю, можно было бы понаделать упражнений, где, например, человек свободно (или направленно на проработку пробелов) общается с нейросетью, а по результатам она выделяет какие режимы для каких слов усвоены и на каком уровне, обновляя результаты. Это покрывает и режим LingQ - даётся текст, непонятные вещи помечаются, из них выявляются отдельно неизвестные грамматические разделы и неизвестные слова, обновляется их уровень освоения.
Посмотрел ваше расширение к Chrome. Идея хорошая, но пришлось отключить, потому что текст всплывает сразу при выделении, а как веб-разработчику, мне надо всякое тестировать и чтоб ничего не мешало. Хорошо бы настройку и альтернативный вариант.
Вот несколько пожеланий по сайту:
- В тренировке разговорной практики мне не хватало иногда времени на пересказ рассказа - долго же думаешь, подбираешь слова. Где-то там еще текст выводился и он обрезался без возможности прокрутки.
- Хоткеи можно чуть улучшить - сейчас требуют двух рук на клавиатуре (1, space, enter). Лучше что-то покомпактнее (1,2,3, например).
- Вылезло вот "convert" с ударением на "o". Даже не знал о таком, потому что значение всё-таки очень редкое, "новообращённый, неофит". Для привычного глагола - другое ударение. Можно заучить неправильно. А в предложении потом уже как раз используется обычный вариант.
- Логичным было бы выбирать англоязычный интерфейс сайта для более полного погружения.
- В упражнениях добавил слово для тренировки произношения, но хорошо бы там где-то фиксировать текущий результат, чтобы накидать сложных слов и фраз и время от времени возвращаться, дорабатывать.
- Что-то странное распознала вместо "does she record the result": "Dašė record the result." Может в промпте надо явно указать не распознавать неанглийские слова/буквы. Или вот еще: "Das schützt die Methode?"
- В режиме тренировки грамматики, и может в других тоже, нет смысла давать произность что-то, пока не было выведено ни текста, и не проиграна фраза. По запарке можно записывать непонятно что.
- Хорошо бы чтобы можно было как-то побыстрее пробежать базовую грамматику, которую точно знаешь. Сейчас там, я так понял, только с нуля всё нужно проходить. Ошибки если и есть, то только из-за того, что не замечаю когда сменяется задание - с отрицания на вопрос, например.
В общем, программа хорошая, надеюсь, получится найти баланс и сделать цену приемлемой. Понятно, что с нейросетями это не может быть бесплатным.
Большое спасибо за такой развернутый комментарий, всё же приятно получать замечания от человека, который “в теме” :)
грамотное ненавязчивое использование нейросетей
Сейчас наделали кучу, на мой взгляд бесполезных, AI-tutors, а я вообще стараюсь не акцентировать внимание на том, что на сайте используется ИИ. Хотя, понятно, что без ИИ такой функционал просто невозможен. В моём понимании, ИИ это очень мощный инструмент, а не фича. Сам по себе он ничего не решает.
Посмотрел ваше расширение к Chrome.
Ему буквально несколько дней :) Добавил в план.
не хватало иногда времени на пересказ рассказа
Ограничение на длительность записи обусловлено используемым провайдером для оценки произношения. Альтернатив особо нет, ELSA просто так свой API не даёт. Есть конкурент, который вроде дешевле и может обрабатывать более длинные аудио, надо тестировать, но пока есть более актуальные задачи.
Хоткеи можно чуть улучшить
Согласен
Вылезло вот “convert” с ударением на “o”.
Источником данных о произношении отдельных слов является CMUdict. Поскольку для некоторых слов есть несколько вариантов произношения, то при создании тренировки сейчас просто берётся первый. Что бы тренируемое произношение совпадало с вариантом используемым далее - требуется, скажем так, система немного другой сложности. Я думал об этом, но пока решил, что это не критично.
Логичным было бы выбирать англоязычный интерфейс сайта
Прямо сейчас это методическая особенность Отказ от полного погружения. В будущем, когда будет реализована интернациализация (пока она не нужна), думаю это будет возможным.
В упражнениях добавил слово для тренировки произношения
Да, тоже есть в списке идей, но пока приоритет у других задач.
Что-то странное распознала вместо “does she record the result”: “Dašė record the result.”
Это чудит openai/gpt-4o-transcribe, при том, что ей указано, что язык английский. Из-за юрисдикции не имею прямого доступа ко всему многообразию моделей, пока работаю только на тех, которые предоставляет openrouter.
В режиме тренировки грамматики, и может в других тоже, нет смысла давать произность что-то
Добавил в план.
побыстрее пробежать базовую грамматику, которую точно знаешь
Думал об этом, но тут есть несколько соображений. Например в спорте даже спортсмены очень высокого уровня часто тренируют самые базовые движения. Цель упражнений не “выучить”, а “автоматизировать”. Люди, у которых базовая грамматика, действительно уже автоматизирована, ну скажем так - их немного. Многие с формальным уровнем B2 продолжают часто делать базовые ошибки с артиклями, предлогами и т.п. Сейчас я думаю, что для подавляющего большинства изучающих целесообразно начинать делать с нуля. Есть группа людей, для которых стоит сделать возможность “отметить” базовые паттерны как освоенные - да, но вспоминаем про актуальный стэк задач.
надеюсь, получится найти баланс и сделать цену приемлемой.
Цена в любом случае будет заметно ниже занятий с репетитором, но годовую подписку за 10 баксов сделать не получится…
Если не возражаете, позже могу написать вам на почту. Некоторые идеи из комментария хотелось бы обсудить чуть подробнее.
Ограничение на длительность записи обусловлено используемым провайдером для оценки произношения.
Может можно из нескольких склеивать как-то, хотя по аудио это сложно, наверное. Текст-то можно разбить про предложениям. Ну, с другой стороны, стимулирует не тормозить. )
Сейчас я думаю, что для подавляющего большинства изучающих целесообразно начинать делать с нуля.
Да, мне тоже иногда нравится пробегать чуть ли не первую тысячу слов в тренажёрах лексики или базовую грамматику. Базу закреплять лишним не будет. Только может тогда как-то более явно отмечать смену типов заданий, чтобы по ошибке на старое не отвечать.
Если не возражаете, позже могу написать вам на почту. Некоторые идеи из комментария хотелось бы обсудить чуть подробнее.
Конечно, пишите.
Ещё вот, вы наверняка в курсе, но на всякий случай скину находку: https://englishprofile.org/?menu=egp-online Профиль грамматики с разбивкой по уровням. Может вы по нему и делали карту. И для лексики у них там похожее есть. Как раз хорошо на эту концепцию ложится.
может тогда как-то более явно отмечать смену типов заданий
Да, записал уже после предыдущего комментария. Изначально навигация в тренировке была двухуровневая, один уровень для упражнений, а другой для элементов внутри упражнения. Мне было понятно, а вот первым тестерам - не очень.
Спасибо, не видел, изучу. Список паттернов в значительной степени результат обсуждения между GPT, Gemini и Opus :) Я пропустил это всё через себя, плюс при чтении современной (это важно) художественной литературы если встречаю конструкцию, которую не знаю как интерпретировать, то прошу объяснить и оценить, если ли такой паттерн в системе. Если нет - добавляю. Но сейчас набор паттернов уже стабилизировался. Некоторые паттерны (один), правда, пока не удалось формализовать нормально - в книжках есть четкие правила на extreme adjectives, но современная устная речь им не то что бы не следует, но сильно размывает строгость. Со временем наверное будут добавлять ещё. Но я считаю важным не добавлять конструкции, которые ещё есть в книгах по грамматике, но в современном языке фактически не используются. Кстати, да, если чего из паттернов, что реально используется, не хватает - можно смело писать.
Отличная статья, спасибо. Очень грамотно разложено по полочкам, особенно про разницу между recognition и retrieval - это та вещь, которую многие изучающие осознают слишком поздно.
Полностью согласен с вашим выводом, что без реального output пассивный запас так и остаётся пассивным. И здесь, на мой взгляд, есть один интересный инструмент, который неплохо ложится в вашу логику - AudioLingo.
Это приложение для iOS, которое по сути закрывает ту самую проблему перехода от узнавания к извлечению. Оно позволяет загрузить любое аудио (подкаст, аудиокнигу, новости, диалог из фильма) и работать с ним активно: автоматически разбивает на короткие сегменты, даёт зациклить сложные фразы, замедлить их и, самое главное, записать себя и сравнить с оригиналом.
Это как раз та самая практика извлечения, о которой вы пишете, но в аудио-формате. Вместо пассивного прослушивания - активное повторение, попытка воспроизвести не просто слово, а целую фразу с её естественным ритмом и интонацией. Это тренирует не только recognition, но и retrieval, потому что мозг вынужден вспоминать слово и сразу произносить его в потоке речи.
Плюс, в отличие от Anki, у вас нет искусственного триггера в виде карточки — вы тренируетесь на реальных фрагментах реальной речи, что ближе к тому, с чем вы столкнётесь в живом общении. И да, оно работает офлайн и без аккаунта, что для многих тоже важно.
Про LingQ вы абсолютно правы - контекст это сила, но он не решает проблему говорения. AudioLingo не заменяет чтение или грамматику, но закрывает конкретную нишу: превратить пассивное аудирование в активную разговорную практику.
Если кому-то интересно, приложение лежит в App Store, называется AudioLingo. Я как раз сейчас собираю обратную связь от изучающих - что работает, что нет, чего не хватает. Так что если кто попробует - буду благодарен за мнение.
Судя по описанию (я прочитал вашу статью), речь идёт об инструменте для shadowing. Честно говоря, я никогда не встречал, чтобы кто-либо говорил об этой технике в контексте retrieval — всё-таки основное предназначение этого метода — работа над произношением. В этом есть смысл: если вы только что прослушали фрагмент, то нужные слова всё ещё находятся в working memory, и настоящего retrieval просто не происходит. Да и сам Alexander Arguelles (популяризатор метода) никогда не позиционировал эту технику подобным образом.
записать себя и сравнить с оригиналом.
В целом это самое проблемное место всего подхода. Для примера: мои музыкальные способности не позволяют использовать его сколько-нибудь эффективным образом. В начале 2000-х, вероятно, никакой особой альтернативы не было, и это был хороший подход. Но сейчас есть несколько провайдеров, которые дают автоматическую “объективную” оценку произношения (на уровне отдельных фонем) и просодии. Т. е. в моём понимании сам подход методически устарел. Но, возможно, он дешевле в использовании.
Интересно, как можно дать объективную оценку произношения, Вы, должно быть, правильно, написали это слово в кавычках :) если можете предложить мне какой-то алгоритм, я реализую его в своём приложении. Просто, честно говоря, я думаю, что все эти алгоритмические сравнения произношения - полная туфта. У меня далеко не музыкальный слух, но прослушав себя и диктора, примерно понимаю, где проблемы с каким звуком, ударением, паузой итд. На любительском уровне этого достаточно ИМХО.
Интересно, как можно дать объективную оценку произношения
Попробуйте приложение BoldVoice, после прохождения онбординга он весьма точно определяет акцент даже для людей с очень хорошим произношением. Технологии активно развиваются.
алгоритмические сравнения
Сейчас это делают специально обученные нейронки.
У меня далеко не музыкальный слух, но прослушав себя и диктора, примерно понимаю,
Good for you. Значит вам этого может быть достаточно. Мне вот точно нет, при том, что я хорошо понимаю английскую речь на слух.
Как учить иностранные слова?