 Эта статья является второй из серии статей о нововведениях на сайте Государственной Думы (статья 1).
Эта статья является второй из серии статей о нововведениях на сайте Государственной Думы (статья 1).В настоящий момент набирает популярность концепция open government («открытое государство»). К примеру, на сайте data.gov публикуются большие объемы данных государственных ведомств США, а на сайте data.gov.uk публикуются аналогичные материалы Великобритании. Важным аспектом публикации структурированной информации является возможность её получения в машиночитаемом виде. Понятно, что и HTML таблицу можно достаточно успешно распарсить, но предоставление информации в удобном для интеграции с внешними системами виде — очень важный показатель открытости. Поэтому, разработка API для системы поиска по законопроектам стала важным этапом реализации концепции «открытое государство» в рамках сайта Государственной Думы. Теперь данные о законопроектах могут быть легко интегрированы во внешние информационные системы. Например, аналитический портал может рядом со статьей, посвященной тому или иному законопроекту, разместить виджет, который будет отражать актульную информацию о ходе рассмотрения законопроекта.
Возможности API
Предоставляемое API реализует, собственно, поиск по законопроектам, с учетом множества параметров. Кроме этого он обеспечивает доступ ко всевозможным справочникам и просмотру стенограммам по каждому законопроекту. Со списком запросов и их параметрами можно ознакомиться в документации.
Рассмотрим несколько примеров поисковых запросов, обрабатываемых API:
- Отклоненные законопроекты, предложенные депутатом ГД Жириновским В.В.;
- Законопроект «О полиции» и поправки к нему;
- Законопроекты, внесенные президентом РФ, в данный момент ожидающие рассмотрения комитетами ГД.
Результаты поиска по данным запросам можно посмотреть здесь, а исходный код на PHP — в документации.
Взаимодействие с API осуществляется в соответствии со стилем архитектуры REST, то есть используется протокол HTTP, ответ выдается в форматах XML, JSON (включая JSONP) и RSS. Широкий спектр поддерживаемых форматах позволяет применять API в различных ситуациях. К нему можно обращаться непосредственно из JavaScript'а браузера. Можно посылать запросы из серверной части приложения или даже из толстого клиента. А можно подписаться на определенный поисковый запрос по RSS, и непосредственно следить за самой свежей информацией.
Статистика
С момента ввода в действие нового сайта ГД системой поиска по законопроектам воспользовалось более 70 тысяч человек. С введением API поиск обещает стать ещё более востребованным, поэтому было важно, чтобы он не просто работал, но и работал быстро. Перед непосредственной оптимизацией была собрана статистика о том, какие запросы пользователи делают в существующей форме поиска по законопроектам.
Сначала была проанализирована частота использования поисковых параметров (сумма процентов больше 100, т.к. в одном запросе может использоваться несклько параметров).
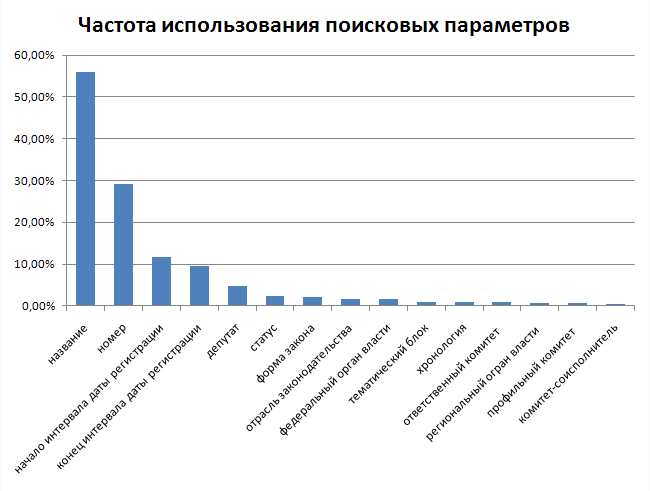
Как видим, распределение очень неравномерное, сразу видно, по каким параметрам нужно индексировать данные в первую очередь. Конечно, после публикации API распределение запросов можен оказаться несколько другим чем у формы поиска законопроектов на сайте, но был получен неплохой ориентир.
Теперь посмотрим, как пользователи пользуются пагинацией.

График хорошо отражает то, что пользователи редко пролистывают результаты далеко: более 97% запросов приходятся на первые 3 страницы. Таким образом, можно было пренебречь оптимизацией выдачи страниц с большим номером.
Дальше было рассмотрено распределение запросов по виду сортировки.
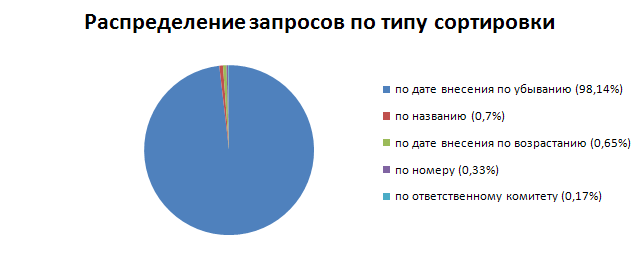
Как видно, сортировку по-умолчанию мало кто меняет, поэтому именно эта сортировка должна в первую очередь выдаваться по индексу.
Одним из методом оптимизации производительности является кэширование результатов поисковых запросов. Для того, чтобы кэширование имело смысл, запросы должны повторяться достаточно часто. Как было распределено число запросов с одинаковыми параметрами поиска можно видеть на графике ниже.
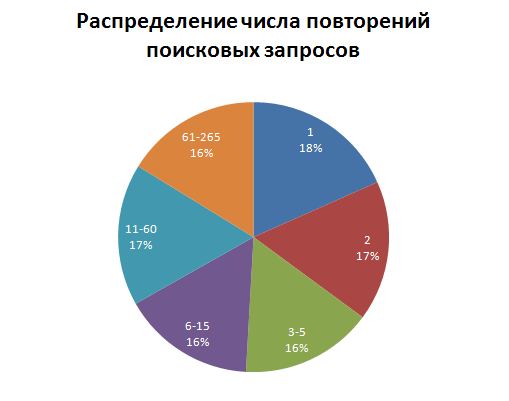
Видно, что запросы повторяются достаточно часто, так что кэширование вполне оправдано.
И в завершении статистики, TOP-10 поисковых запросов.
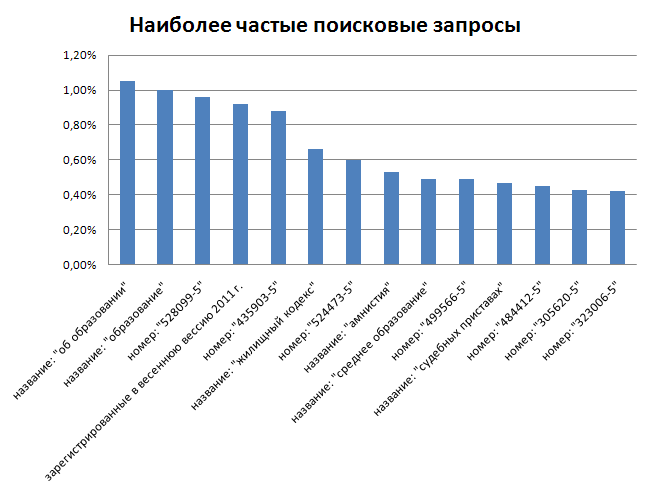
Одной из наиболее горячих тем на момент сбора статистики был закон об образовании.
Оптимизация
Вместе с разработкой API стояла также задача перевода базы данных «Законопроект» с Oracle на PostgreSQL (импорт данных был осуществлен с использованием ora2pg). Были применены следующие методы оптимизации.
Используется встроенный полнотекстовый поиск PostgreSQL с применением GIN индексов.
Были построены индексы по тем полям, по которым доступна сортировка, и по тем, по которым чаще всего осуществляется фильтрация.
Раньше, при использовании СУБД Oracle, для постраничной навигации накладывалось ограничение на виртуальный столбец rownum, отражающий номер строки в выборке. Т.е. если нужно показать, к примеру, первые 20 строк, возвращаемые некоторым запросом, использовалась следующая конструкция.
SELECT x.* FROM (основной_запрос) x WHERE rownum <= 20
Это был, в целом, не самый корректный способ, но в используемой версии (Oracle 9i) он работал нормально. А когда нужно было показать, к примеру 20 строк начиная с 100 применялась следующая конструкция. В ней внутренний запрос выбирает 120 первых строк, а внешний оставляет только 20 последних из них.
SELECT
*
FROM (
SELECT
rownum AS xrownum,
x.*
FROM
(основной_запрос) x
WHERE
rownum <= 120)
WHERE
xrownum > 100;
С переходом на PostgreSQL стали применяться конструкции LIMIT и OFFSET. Кроме того, в целях оптимизации, конструкции LIMIT и OFFSET были расположены как можно глубже в объединениях таблиц. Рассмотрим пример. Пусть у нас объедияются таблицы a и b, сортировка идет по полю с индексом. Тогда если применить LIMIT и OFFSET ко всему запросу, то получится следующих план запроса.
SELECT
*
FROM
b
JOIN
a
ON
b.a_id = a.id
ORDER BY
b.value,
b.id
LIMIT 20
OFFSET 100;
QUERY PLAN
------------------------------------------------------------------------------------------------
Limit (cost=52.30..62.76 rows=20 width=39)
-> Nested Loop (cost=0.00..522980.13 rows=1000000 width=39)
-> Index Scan using b_value_id_idx on b (cost=0.00..242736.13 rows=1000000 width=27)
-> Index Scan using a_pkey on a (cost=0.00..0.27 rows=1 width=12)
Index Cond: (a.id = b.a_id)
Т.е. осуществляется проход по индексу b_value_id_idx, при этом для каждой найденной записи таблицы b присоединяется записи таблицы a по индексу a_pkey. Первые 100 найденных таким образом записей пропускаются и берутся следующие за ними 20. Теперь посмотрим что получится если применить LIMIT и OFFSET иключительно к таблице b. Более подробно про организацию постраничной навигации можно почитать здесь.
SELECT
*
FROM
(
SELECT
*
FROM
b
ORDER BY
b.value,
b.id
LIMIT 20
OFFSET 100
) b
JOIN
a
ON
b.a_id = a.id;
QUERY PLAN
------------------------------------------------------------------------------------------------------
Hash Join (cost=29.44..49.39 rows=20 width=60)
Hash Cond: (a.id = public.b.a_id)
-> Seq Scan on a (cost=0.00..16.00 rows=1000 width=12)
-> Hash (cost=29.19..29.19 rows=20 width=48)
-> Limit (cost=24.16..28.99 rows=20 width=27)
-> Index Scan using b_value_id_idx on b (cost=0.00..241620.14 rows=1000000 width=27)
Как видно, теперь соединение с таблцей a идет уже после выборки только нужных строк таблицы b, тем самым достигается экономия. И если присоединяется таким образом не 2 а, предположим, 10 таблиц, то эффект может быть очень значительным. В принципе у планер есть вся необходимая информация, чтобы самому проводить такую оптимизацию, учитывая что поле b.a_id not null, а поле a.id — это primary key. Но он её делать не умеет, возможно ситуация изменится в будущих версиях. Так что можно принять за правило располагать LIMIT и OFFSET как можно «глубже», хуже от этого в любом случае не станет.
Кэширование результатов запросов организовано с помощью memcached. Каждый запрос на поиск законопроектов характеризуется:
- набором наложенных фильтров,
- способом сортировки,
- номером отображаемой страницы.
Было предусмотрено два вида кэша:
- Ключом является набор наложенных фильтров, а значением — число удовлетворяющих его результатов.
- Ключом являются набор наложенных фильтров, способ сортировки и номер страницы (т.е. все параметры поиска), а значением — id найденных законопроектов.
Таким образом данные хранятся в кэше компактно, тем самым увеличивается число закэшированных запросов, хотя увеличивается стоимость их обработки т.к. часть данных загружается из основной базы.
Оптимизация БД позволила снизить время обработки тестовой выборки из 65 тысяч поисковых запросов с 10 часов до 15 минут.
Итог
Благодаря проделанной работе всё, что можно было раньше сделать через форму поиска по законопроектам на сайте, теперь можно сделать программно и использовать в самых разных ситуациях. Мы надеемся, что наши усилия были приложены не зря, и разработанный API станет полезным и востребованным сервисом.
В качестве примера мы решили разработать мобильное приложение «Поиск по законопроектам», где будут использоваться все те возможности, что доступны в API, а также функции подписки на поисковые запросы с получением уведомлений о новых законопроектах. В скором времени мы его опубликуем.

