Comments 306
В вопросе ArrayList vs LinkedList очень важно ещё и понимать что элементы ArrayList`а хранятся массивом, т.е. линейно в памяти, и можно довольно удачно загрузить кусок массива в кэш процессора, что очень круто скажется на производительности.
советую почитать: kjellkod.wordpress.com/2012/08/08/java-galore-linkedlist-vs-arraylist-vs-dynamicintarray/
советую почитать: kjellkod.wordpress.com/2012/08/08/java-galore-linkedlist-vs-arraylist-vs-dynamicintarray/
Спасибо за замечание и статью, отметил себе на вечернее прочтение, судя по всему статья будет интересной.
Ага. Кстати, с ArrayList ещё интересна постановка вопроса о вставке в середину или удалении из середины. Да, с математической точки зрения это O(N-k), где k — позиция вставки/удаления. Но в действительности это делается за одну операцию System.arraycopy, которая реализована нативно и сводится к ассемблерным инструкциям копирования блока памяти, которые даже для незакэшированного массива отработают довольно быстро. У меня (CoreDuo E7300 @2.66GHz) вставка в начало ArrayList из миллиона элементов занимает около одной миллисекунды, то есть по сути дела сдвиг одного элемента в массиве занимает наносекунду. Поэтому здесь линейная сложность не так уж страшна для большинства задач.
Понятие сложность (с прилагательными линейная, квадратичная и т.д.) в принципе асимптотическое, т.е." для достаточно больших N". Никакие инструкции процессора не заменяют понимания алгоритмической сложности
Ну разумеется. Главное, углубляясь в теорию, не оторваться от практики и не забыть о константе. Почему, к примеру, не используют пирамидальную сортировку с её гарантированным O(n*ln(n)) и O(1) дополнительной памяти? Почему предпочитают quickSort с O(n^2) в худшем случае? Всё дело как раз в константе.
Сложность != скорость.
Ну, если заниматься уже такими подробностями работы процессора, то стоит сказать что на маленьких списках\в хвосте большого списка в случае ArrayList есть возможность что постоянные изменения одних и техже элементов в процессоре проинтерферируют в очереди записи и в память будет отображено только конечно состояние. В случае LinkedList на каждый чих будет выделятся новый обьект-контейнер, потому память будет использоваться разная а значит подобная оптимизация не сработает.
Почему нельзя использовать byte[] в качестве ключа в HashMap?
Очень удивился, прочитав название. Прочитал весь пункт целиком и хочу сказать, что я бы задал этот вопрос, например, так: «почему важно знать как работает equals для массивов?». Потому что в общем и целом разницы с другими типами нет, объекты действительно разные.
Ну, я конечно, не джавист, но все же считаю что такие вещи, как передача поссылке, должны быть очевидны любому специалисту.
> Класс массива в Java по какой-то причине очень бедный, в нем функционала практически нет. Объяснения этому я лично не знаю.
Есть Arrays.hashcode() и Arrays.equals() для особых ценителей, а так — меньше лишних телодвижений и додумок за программиста. Меньше магии в core API.
Есть Arrays.hashcode() и Arrays.equals() для особых ценителей, а так — меньше лишних телодвижений и додумок за программиста. Меньше магии в core API.
Сами разработчики из оракла высказывают на докладах иное мнение.
Project Lambda — больше магии в core API!
Project Lambda — больше магии в core API!
По мне, так это уже не магия, а попытка смены колес у стремительно мчащегося вперед поезда — проблема другого уровня.
Не все так плохо. Совместимость сохраняется, быстродействие не ухудшится, а смены парадигмы по сути не произойдет — уже и так есть библиотеки коллекций в функциональном стиле — вспомним хотя бы гуаву.
Да, реализации по умолчанию — это очень интересный ход для столь консервативного ЯП, но уже опробованный во многих языках.
Да, реализации по умолчанию — это очень интересный ход для столь консервативного ЯП, но уже опробованный во многих языках.
С недавнего времени у меня появилась настойчивая мысль, что профессиональное развитие сильно замедлилось и это хочется как-то исправить.
Пробовали смотреть в сторону многопоточности ;)
Пробовали смотреть в сторону многопоточности ;)
Да, начал копать в этом направлении, к сожалению по работе не сталкиваюсь с этим, хотелось бы попасть на высконагржуенный проект с использованием многопоточности — ищу.)
Попробуйте на тестовом примере реализовать модель распределенных вычислений с перераспределением нагрузки между узлами и с правильным перехватыванием при «умирании» посредника.
Хорошая такая задачка :-)
Хорошая такая задачка :-)
У меня на собеседовании был вопрос про удаление элементов в arrayliste, где порядок элементов был неважен. Очень похож на пятый вопрос, только там можно было сделать ход конем: если порядок элементов неважен, то можно поменять удаляемый элемент с последним и удалить уже последний — работает за O(1) не учитывая trimtosize.
Я, если честно, думал, что он так и работает, удивился, когда прочитал, что происходит сдвиг.
Если порядок элементов не важен, нет смысла использовать List, основное свойство которого, сохранение порядка элементов.
свойство arraylistа не в сохранении порядка, а к быстрому обращению по индексу. При прямых руках и правильном использовании — самое то.
Какой смысл в индексе, если порядок элементов по определению неизвестен? Для таких случаев существуют другие коллекции с безындексными итераторами.
Порядок не важен != порядок не известен
Эм… вообще-то как раз таки "==" в данном контексте. Структурой либо гарантируется порядок, либо нет. Если он не гарантируется, то как он может быть известным, поясните или пример структуры приведите?
Порядок элементов может использоваться с одной стороны в алгоритмах работающих по принципу divide and conquer, а также в различных системах с паралелльным выполнением операций и объединением полученных результатов (map-reduce).
Возьмем пример с быстрой сортировкой (quick sort). После определения пивот-элемента нам нужно переставить его в конец текущего интервала, потом менять местами элементы что меньше и больше пивота. Все эти операции осуществляются за константное время при наличии индекса.
Возьмем пример с быстрой сортировкой (quick sort). После определения пивот-элемента нам нужно переставить его в конец текущего интервала, потом менять местами элементы что меньше и больше пивота. Все эти операции осуществляются за константное время при наличии индекса.
Почему нельзя использовать byte[] в качестве ключа в HashMap?
Не понял вопроса. Можно и все будет работать правильно. А то, что автор придумал с динамическим хэшкодом для byte[] как раз работать не будет. Никогда не вставляйте в hashMap объекты, у которых может поменяться hashCode.
В 95% случаев моего использования HashMap достаю именно те объекты, которые туда положил (то есть не делаю hasMap.get(new Integer(oldInteger)); )
Согласно контракту hashCode меняться не должен. Если он меняется, значит, объест сконструирован неверно.
Не совсем так.
Согласно контракту при изменении hashCode с точки зрения HashMap мы имеем другой объект ключа.
Со всеми вытекающими.
Согласно контракту при изменении hashCode с точки зрения HashMap мы имеем другой объект ключа.
Со всеми вытекающими.
Это в каком смысде не совсем!!?!
The general contract of hashCode is:
Whenever it is invoked on the same object more than once during an execution of a Java application, the hashCode method must consistently return the same integer, provided no information used in equals comparisons on the object is modified. This integer need not remain consistent from one execution of an application to another execution of the same application…
The general contract of hashCode is:
Whenever it is invoked on the same object more than once during an execution of a Java application, the hashCode method must consistently return the same integer, provided no information used in equals comparisons on the object is modified. This integer need not remain consistent from one execution of an application to another execution of the same application…
Стоит обратить внимание на выделенный фрагмент:
"...the hashCode method must consistently return the same integer, provided no information used in equals comparisons on the object is modified..."
"… метод hashCode должен стабильно возвращать одно и то же число при условии, что данные, используемые для сравнения объектов методом equals, не изменились..."
"...the hashCode method must consistently return the same integer, provided no information used in equals comparisons on the object is modified..."
"… метод hashCode должен стабильно возвращать одно и то же число при условии, что данные, используемые для сравнения объектов методом equals, не изменились..."
hashCode полезен для immutable-объектов. Для mutable — просто опасен.
Народ, вы документацию читали? Значение hashCode после первого вызова меняться не может! Класс object, базовый как бы.
А что, где-то написано обратное?
А какая разница — mutable объект или нет?
Типичный случай — люди делают классы, в которых хэшкод является функцией от состояния экземпляра. Если состояние единственное (=immutable), то такая реализация корректна, ибо не нарушает контракт hashCode, о котором вы говорите. Если состояние может меняться — то контракт может нарушаться, поэтому делать так не стоит.
ну так это не имеет никакого отношения к типу объекта, а к кривости рук его создателя.
Выход из этой ситуации или не делать mutable объект, либо завязывать хеш-код на поля, которые не меняются в процессе жизни объекта? Есть ли еще варианты?
При этом надо, чтобы неравенство неменяющихся полей означало неравенство объектов? Для использования объекта в качестве ключа, может быть, подойдет. Но поиск «такого же» объекта с другим происхождением… может и не сработать.
Возможно, для таких классов (mutable, но которые хотят быть ключами) создавать парные immutable классы — «моментальные снимки»?
Возможно, для таких классов (mutable, но которые хотят быть ключами) создавать парные immutable классы — «моментальные снимки»?
Часто ключами являются строки, которые совсем не идентичные. К примеру, полученные из разных строк SQL-запроса, или вычитанные из разных строк файла, или пришедшие по сети из разных соединений. Когда я задумался над этим, оказалось, что далеко не так часто используются идентичные объекты.
Ну и с интегерами тоже. Как вы написали, конечно, никто не делает. А вот, например, в таком коде ключи будут неидентичными
Боксинг в ключах к стандартным коллекциям — не редкость (да-да, используйте Trove!)
hashMap.put(500, 1);
int value = hashMap.get(500);
Боксинг в ключах к стандартным коллекциям — не редкость (да-да, используйте Trove!)
Хм, я никоим образом не Java программист, пробовал этот язык еще в школе в последний раз, но ни один из этих вопросов не заставил меня даже задуматься — предположения абсолютно совпали с верными ответами.
Может в таком случае вам стоит почитать классической литературы? Например в такой классической литературе, как «Алгоритмы. Построение и анализ» Кормена, на фундаментальном уровне разобрана большая часть вопросов, касательная сложности алгоритмов, а эти знания, в свою очередь, можно будет уже экстраполировать на контейнеры/стандартные алгоритмы любого языка.
Это неправда же. Математическое ожидание времени выполнения этих функций — O(1), а в общем случае их сложность O(n).
В остальных случаях достаточно помнить, что сравнение в Java происходит по указателю, а не по значению, из чего можно делать уже соответствующие вывода.
Может в таком случае вам стоит почитать классической литературы? Например в такой классической литературе, как «Алгоритмы. Построение и анализ» Кормена, на фундаментальном уровне разобрана большая часть вопросов, касательная сложности алгоритмов, а эти знания, в свою очередь, можно будет уже экстраполировать на контейнеры/стандартные алгоритмы любого языка.
7. Как устроена HashMap?
Добавление, поиск и удаление элементов выполняется за константное время.
Это неправда же. Математическое ожидание времени выполнения этих функций — O(1), а в общем случае их сложность O(n).
В остальных случаях достаточно помнить, что сравнение в Java происходит по указателю, а не по значению, из чего можно делать уже соответствующие вывода.
Поправьте меня если я где-то ошибся:
Добавление — берём бакет по хэшкоду, добавление в список — везде константа
Поиск — берём бакет по хэшкоду, поиск в бакете фиксированного размера (в общем, не зависит от N) — опять O(1)
Удаление — аналогично поиску
Добавление — берём бакет по хэшкоду, добавление в список — везде константа
Поиск — берём бакет по хэшкоду, поиск в бакете фиксированного размера (в общем, не зависит от N) — опять O(1)
Удаление — аналогично поиску
В корзине в худшем случае будет O(n) элементов в связном списке (если не повезло немного с хеш-функцией, либо данными). Для добавления/поиска/удаления нужно пройтись по всему списку, сложность прохождения по списку длины O(n) — O(n), поэтому сложность каждой из операций — O(n).
Добавление в любом случае это O(1).
а для получения n элементов в бакете — это же нужно целенаправленно стрелять себе в ногу :)
Именно в общем случае будет всё ок, в худшем — да, грубо говоря O(N) — но на то это и худший случай.
а для получения n элементов в бакете — это же нужно целенаправленно стрелять себе в ногу :)
Именно в общем случае будет всё ок, в худшем — да, грубо говоря O(N) — но на то это и худший случай.
При добавлении надо еще проверить наличие такого же, так что сложность поиска.
При добавлении нужно убедиться, что не возникнет дублирования по ключу, для этого надо пройтись по всему списку. И если найдется элемент с таким-же ключом, то он будет заменен. А обход списка — это O(n).
И не путайте терминологию, O всегда обозначает худший из всех возможных случаев. (О-символика объясняется в Кормене в первой главе).
Нет, достаточно, чтобы вам кто-то попытался ее отстрелить) Программист всегда должен считать окружающий мир враждебным и писать код исходя из этого.
И не путайте терминологию, O всегда обозначает худший из всех возможных случаев. (О-символика объясняется в Кормене в первой главе).
это же нужно целенаправленно стрелять себе в ногу :)
Нет, достаточно, чтобы вам кто-то попытался ее отстрелить) Программист всегда должен считать окружающий мир враждебным и писать код исходя из этого.
Если мы подходим со строго формальной точки зрения — да O всегда описывает худший вариант.
Однако в реальной жизни нас более интересует не худшее время, а среднее. Кормен указывал что его больше интересуют худшие случаи — скорее для строгости дальнейшего повествования — худший случай нам даёт гарантию времени работы алгоритма.
В 90% случаев достаточно оперировать средним случаем, и большинство оценок делается именно для этого среднего случая.
Однако, если нам супер важно теоретически обосновать сложность алгоритма, или область работы такова, что худшие случаи часты — вы правы, HashMap это O(n) а quicksort это O(n^2) :)
Однако в реальной жизни нас более интересует не худшее время, а среднее. Кормен указывал что его больше интересуют худшие случаи — скорее для строгости дальнейшего повествования — худший случай нам даёт гарантию времени работы алгоритма.
В 90% случаев достаточно оперировать средним случаем, и большинство оценок делается именно для этого среднего случая.
Однако, если нам супер важно теоретически обосновать сложность алгоритма, или область работы такова, что худшие случаи часты — вы правы, HashMap это O(n) а quicksort это O(n^2) :)
Это элементарная грамотность, а не «строго формальная точка зрения». Собственно именно она позволяет понять, что далеко не всегда уместно использование hash table (в ряде случаев rb-tree/treap дают куда лучшие по скорости результаты), а quick sort (в его обычном виде) использовать вообще никогда не стоит.
Ок, ваш подход понятен.
Я придерживаюсь немного другой точки зрения:
в 95% случаев — средняя оценка реально отражает суть процессов. оставшиеся 5% — отдельный случай (и данные случаи часто хорошо видны) — тут надо анализировать отдельно. Иначе нам грозит оверинжениринг.
Я придерживаюсь немного другой точки зрения:
в 95% случаев — средняя оценка реально отражает суть процессов. оставшиеся 5% — отдельный случай (и данные случаи часто хорошо видны) — тут надо анализировать отдельно. Иначе нам грозит оверинжениринг.
А поясните, пожалуйста, про QuickSort.
При таком подходе, все совсем печально. При выборе структуры данных по вашей логике надо всегда брать список: и у него и у HashMap сложность O(N), зато список экономичней по памяти. :) Вы фактически не оставили HashMap шансов на жизнь, однако в жизни эта структура активно используется и скорость показывает вполне себе.
Чтобы у HashMap попасть на O(N), надо серьезно извращаться, это не «слегка» неповезло с функцией и данными, это капитально не повезло. Как правильно вспомнили выше quicksort тоже формально имеет временную сложность O(n^2), но все скорее держат это в голове как некий тонкий момент, нежели случай из практики, потому что вероятность его очень мала, даже если с данными так не повезет, все ориентируются на N lg N. Формально вы правы, но общепринятый вариант о константном времени выполнения операций, а O(N) практикуют как некий тонкий момент на собеседованиях, вероятность очень мала.
Чтобы у HashMap попасть на O(N), надо серьезно извращаться, это не «слегка» неповезло с функцией и данными, это капитально не повезло. Как правильно вспомнили выше quicksort тоже формально имеет временную сложность O(n^2), но все скорее держат это в голове как некий тонкий момент, нежели случай из практики, потому что вероятность его очень мала, даже если с данными так не повезет, все ориентируются на N lg N. Формально вы правы, но общепринятый вариант о константном времени выполнения операций, а O(N) практикуют как некий тонкий момент на собеседованиях, вероятность очень мала.
Почему список, а не красно-черное дерево, отсортированное по hash-коду? Там будет O(log N) в худшем случае.
Бывали случаи, когда из-за непонимания возможности вырождения операций хеш-таблицы в линию не проходили задачи на олимпиадах. И именно это причина появления perfect hash table, которая гарантируют сложность операций поиска за O(1).
perfect hash table — это которая требует предподсчета, занимающего время, пропорциональное мощности множества всех возможных значений ключей? Или она не имеет отношения к perfect hash function?
perfect hash table — это хеш таблица с фиксированными элементами, мат. ожидание сложности ее построения O(n), где n — количество элементов, поддерживает только операции поиска и удаления за O(1) (операция вставки новых элементов — не поддерживается)
Построение идёт после того, как все элементы известны? И оно гарантированно за O(n), или только в среднем?
После того как все известны. В среднем, но вероятность построения больше 50%, поэтому очень сомнительно, что потребуется больше 2 перестроений.
Тогда такой вопрос — «больше 50%» это в среднем по всем множествам, или для любого множества — в среднем по всем построениям? Иными словами, существуют ли «плохие» множества, вероятность успеха для которых заметно ниже?
В любом случае, спасибо за наводку. Я этого приёма раньше не замечал. Пригодится.
В любом случае, спасибо за наводку. Я этого приёма раньше не замечал. Пригодится.
Специально отыскал Кормена, и не нашел там утверждения что под О понимается ТОЛЬКО сложность в «худшем» случае. Возможно перевод плохой.
ИМХО, чаще всего используется понятие асимптотической сложности алгоритма. И для HashMap она равна константе. Это же указано и в javadoc.
ИМХО, чаще всего используется понятие асимптотической сложности алгоритма. И для HashMap она равна константе. Это же указано и в javadoc.
O — нотация это обозначение принадлежности к множеству.
Под записью O(g(x)) = f(x) имеется ввиду что f(x) принадлежит множеству функций асимптотически ограниченных сверху функцией g(x) умноженной на некую константу.
Никто не мешает на место f(x) засунуть более сложную функцию, например содержащую мат-ожидание.
И действительно для Хеш-таблицы с цепочковой индексацией матожидание(в пространстве таблиц с одинаковым размером и равновероятными ключами ) времени поиска будет O(1+loadFactor)
Под записью O(g(x)) = f(x) имеется ввиду что f(x) принадлежит множеству функций асимптотически ограниченных сверху функцией g(x) умноженной на некую константу.
Никто не мешает на место f(x) засунуть более сложную функцию, например содержащую мат-ожидание.
И действительно для Хеш-таблицы с цепочковой индексацией матожидание(в пространстве таблиц с одинаковым размером и равновероятными ключами ) времени поиска будет O(1+loadFactor)
Также добавлю, что из-за подобного непонимания принципов работы хеш-таблиц (или отсутствия должного внимания к ним) вообще становятся возможными такие вещи как hash collision DoS в каждом втором веб-сервисе. Например, статья на хабре, и более подробная статья.
А вообще, вопросы в статье — чисто джуниорские, для ответа на которые человеку достаточно один раз взять в руки книгу, или, хотя бы, прочитать документацию на Java.
А вообще, вопросы в статье — чисто джуниорские, для ответа на которые человеку достаточно один раз взять в руки книгу, или, хотя бы, прочитать документацию на Java.
Статья интересная, мне понравилась, как раз недавно начал писать приложение под андройд, и столкнулся с большим количеством списков.
Ваш бы пост, да днем ранее…
А откуда взялась логарифмическая оценка для HashMap в 7 и 9 ответах? Там вроде O(n) должно быть.
Мне тоже интересно :-)
А чуть выше как раз дискуссия на эту тему, а логарифмическая оценка по Р.Седжевику, эта оценка исходит из хеш-функции с нормальным распределением.
Да, чуть выше обсуждали сложность какая все таки будет сложность O(1) и O(n) у различных операций. Мне хотелось бы узнать у автора а откуда вообще взялся логарифм.
По Р.Седжевику? Я не смог найти у него такого (возможно не там искал), но мне кажется мы все таки о разных вещах говорим.
У автора указано:
… хеш-функций должна равномерно распределять элементы по корзинам, в этом случае временная сложность для этих 3 операций будет не ниже lg N, а в среднем случае как раз константное время…
Что значит не ниже lg N, а в среднем случае как раз константное время? Если не ниже lg N, то это O(lg n) будет.
и еще одно:
… если вы будете использовать хеш-функцию с равномерным распределением, в предельном случае гарантироваться будет только временная сложность lg N.
В предельном случае будет гарантирован сложность только O(n) — полный перебор всех элементов.
Возможно Седжевик что то другое доказал с логарифмической оценкой?
P.S.: А возможно я не правильно в чем то понял автора. Буду благодарен если разъясните.
По Р.Седжевику? Я не смог найти у него такого (возможно не там искал), но мне кажется мы все таки о разных вещах говорим.
У автора указано:
… хеш-функций должна равномерно распределять элементы по корзинам, в этом случае временная сложность для этих 3 операций будет не ниже lg N, а в среднем случае как раз константное время…
Что значит не ниже lg N, а в среднем случае как раз константное время? Если не ниже lg N, то это O(lg n) будет.
и еще одно:
… если вы будете использовать хеш-функцию с равномерным распределением, в предельном случае гарантироваться будет только временная сложность lg N.
В предельном случае будет гарантирован сложность только O(n) — полный перебор всех элементов.
Возможно Седжевик что то другое доказал с логарифмической оценкой?
P.S.: А возможно я не правильно в чем то понял автора. Буду благодарен если разъясните.
На самом деле Роберт Седжевик доказал совершенно другое:
при использовании SUHA — предположении о равновероятном и независимом от исходов уже проведенных эксперементов присвоении метки(это не просто «на одинаковые части», это намного больше) будет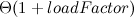 .
.
Факт связанный с логарифмами доказанный недавно Седжвиком совершенно другой:
он в 2008 году придумал более простую конструкцию родственную красно-черным древьям, называется Left-leaning red–black tree. У них оценка операций вставки\удаления log(n). Но они удобнее в реализации и константа меньше
Другой вариант из «логарифмы и Седжевик» — он доказал что, при испрользовании Cockoo hashing(это опять не то что в HashMap) в предположении SUHA, оценка сверху для для loadFactor будет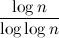
при использовании SUHA — предположении о равновероятном и независимом от исходов уже проведенных эксперементов присвоении метки(это не просто «на одинаковые части», это намного больше) будет
.Факт связанный с логарифмами доказанный недавно Седжвиком совершенно другой:
он в 2008 году придумал более простую конструкцию родственную красно-черным древьям, называется Left-leaning red–black tree. У них оценка операций вставки\удаления log(n). Но они удобнее в реализации и константа меньше
Другой вариант из «логарифмы и Седжевик» — он доказал что, при испрользовании Cockoo hashing(это опять не то что в HashMap) в предположении SUHA, оценка сверху для для loadFactor будет
Возможно я не так выразился… полазил по слайдам его лекций собственно вот:
www.cs.princeton.edu/courses/archive/spr10/cos226/lectures/10-34HashTables-2x2.pdf
На предпоследнем слайде, сводная табличка по структурам данных.
www.cs.princeton.edu/courses/archive/spr10/cos226/lectures/10-34HashTables-2x2.pdf
На предпоследнем слайде, сводная табличка по структурам данных.
Честно говоря так и не понял как он доказал гарантированную логарифмическую сложность. По-моему все же это вероятностный подход, т. е. если у Вас точно будет равномерное распределение элементов, что на практике недостижимо. Да и способ реализации хеш-таблицы там немного другой — с открытой индексацией (хотя не думаю что это важно).
В моем понимании, распределение не строго равномерное, а близкое к тому (в каком то списке чуть меньше чем lg n элементов, в каком то чуть больше), если в таком случае пытаться рассчитать точную зависимость, то будет lg n с каким-нибудь коэффициентов и/или дополнительным слагаемым, но в целом все вращается вокруг lg n. В общем, мне кажется интуитивно, что для подавляющего большинства практических случаев худшая оценка будет как раз такая, но здесь я принимаю на веру слова авторитетного ученого, поэтому мысли могу подгонять «под ответ». Не задавался вопросом поиска доказательств данного положения и как показывают обсуждения выше оценка сложности вещь довольно многогранная и сложная, мнений много как правильно считать.
Подавляющее большинство практических случаев это O(1) (у него там кстати так и указанно — 3-5).
Если данные заранее неизвестны, то для любой хеш-функции можно подобрать случай, приводящий к коллизиям и таким способом добиться O(n). А вот это точно будет худший случай.
Логарифмическая оценка у него описывает худший случай для данных которые распределяются равномерно (и как я уже сказал выше, на практике этого нельзя гарантировать). Так что на мой взгляд это лишь вносит путаницу.
Если данные заранее неизвестны, то для любой хеш-функции можно подобрать случай, приводящий к коллизиям и таким способом добиться O(n). А вот это точно будет худший случай.
Логарифмическая оценка у него описывает худший случай для данных которые распределяются равномерно (и как я уже сказал выше, на практике этого нельзя гарантировать). Так что на мой взгляд это лишь вносит путаницу.
Куда мир катиться, я всю жизнь думал что это даже для Джуниора слишком простые вопросы.
а что же вы спрашиваете у своих джуниоров?
Зы: вопросы которые я задаю Junior не сильно отличаются от тех что Senior. Просто ожидаю разный уровень ответов.
Теория — пару вопросов из этого списка, чуть под настроение(вычеты, сортировки, перестановки, графы, древья: чтото базовое что можно вывести на месте) и разные вопросы на многопоточность:
как устроен CopyOnWriteArrayList. Зачем он так устроен?
Когда имеет смысл паралелить алгортм(хорошо если знает закон Амдала)?
Прошу написать принципы реализации многопоточных списков и кольцевого буфера. а неблокирующие?
Прошу придумать как бы он реализовывал многопоточный HashMap в случае разных паттернов работы с ним.
Как бы он реализовал кеш для приложения? а персистентный?
Как можно остановить поток выполняющий код который не находится под нашим контролем?
Из чего состоит переключение контекста процессора между потоками и процессами? сколько оно стоит?
Когда не знает ответа на вопрос(или даже не понимает формулировки) поясняю ему вопрос, я хочу увидеть как он мыслит.
После прошу написать реалию минимального приложения, тоже под настроение и в зависимости от диалога: последние варианты были написать сервис быстро возвращающий среднее в массиве(то есть к нему по сети приходят запросы «добавить елемент a» и «верни среднее»). На задачку даю часа 3-4. Для этого даю ему некий костяк — интерфейс который он должен реализовать и интерфейсы которыми он может пользоваться. Сам быстренько реализую последние.
Тут смотрю как они пишет тесты и mock-реализации(и пишет ли), пишет ли комментарии, как структурирует код. Обычно я наблюдаю что это спрашивают устно, но ИМХО в таких вопросах устный ответ часто в корни разнится от реальности.
Теория — пару вопросов из этого списка, чуть под настроение(вычеты, сортировки, перестановки, графы, древья: чтото базовое что можно вывести на месте) и разные вопросы на многопоточность:
как устроен CopyOnWriteArrayList. Зачем он так устроен?
Когда имеет смысл паралелить алгортм(хорошо если знает закон Амдала)?
Прошу написать принципы реализации многопоточных списков и кольцевого буфера. а неблокирующие?
Прошу придумать как бы он реализовывал многопоточный HashMap в случае разных паттернов работы с ним.
Как бы он реализовал кеш для приложения? а персистентный?
Как можно остановить поток выполняющий код который не находится под нашим контролем?
Из чего состоит переключение контекста процессора между потоками и процессами? сколько оно стоит?
Когда не знает ответа на вопрос(или даже не понимает формулировки) поясняю ему вопрос, я хочу увидеть как он мыслит.
После прошу написать реалию минимального приложения, тоже под настроение и в зависимости от диалога: последние варианты были написать сервис быстро возвращающий среднее в массиве(то есть к нему по сети приходят запросы «добавить елемент a» и «верни среднее»). На задачку даю часа 3-4. Для этого даю ему некий костяк — интерфейс который он должен реализовать и интерфейсы которыми он может пользоваться. Сам быстренько реализую последние.
Тут смотрю как они пишет тесты и mock-реализации(и пишет ли), пишет ли комментарии, как структурирует код. Обычно я наблюдаю что это спрашивают устно, но ИМХО в таких вопросах устный ответ часто в корни разнится от реальности.
забыл: пару вопросов о GC, о загрузке классов, было просил написать свою реализацию gc: представим что GC у JVM нет, человек должен был сделать некий super-class для всех обьектов, и должен был быть «личным» gc для них.
Потом попросил его сделать анализ работы этого GC с профайлером и пояснить почему он так работает.
ЗЫ: это был очень сильный соискатель и было очень приятно с ним говорить, потому и писали такую интересную вещь.
Задаю вопросы о production-мониторинге. Что и как нужно отслеживать в продакшене. Разок когда дал кусок кода написанного в моей команде и попросил в течении 3 часов разобраться как он работает и там где считает нужным расставить мониторинговые вызовы(дал в руки библиотеку metrics)
Потом попросил его сделать анализ работы этого GC с профайлером и пояснить почему он так работает.
ЗЫ: это был очень сильный соискатель и было очень приятно с ним говорить, потому и писали такую интересную вещь.
Задаю вопросы о production-мониторинге. Что и как нужно отслеживать в продакшене. Разок когда дал кусок кода написанного в моей команде и попросил в течении 3 часов разобраться как он работает и там где считает нужным расставить мониторинговые вызовы(дал в руки библиотеку metrics)
Рядом с вопросом о GC и cache задаю вопросы о отличиях WeakRefferece, PhantomRefference и SoftReference.
Вопросы хорошие. А что в Яндексе теперь студенты собеседуют сеньёров?
в Яндексе теперь
Я не работаю в Яндексе.
Я там доучиваюсь, и у меня научрук из Яндекса.
студенты собеседуют сеньёров
Также мне тяжело себя отнести к junior\senior. У меня мало лет опыта, но учитывая что мне интересны алгоритмы и методологии разработки+организации людей, то претендую я обычно именно на позиции начиная с Senior.
На задачку даю часа 3-4.
И что ж это за компания такая, в которой вы работаете, что люди готовы на собеседованиях по 3-4 часа сидеть и писать что-то?
Обычно если доходит до этого этапа то я вижу что мне интересно с этим человеком и ему со мной.
Потому вопрос не встает.
Если же нам вместе не интересно — я не вижу смысла его нанимать, во всяком случае в мою команду. Атмосфера работы — тоже крайне важный фактор который проверяет такое собеседование.
Потому вопрос не встает.
Если же нам вместе не интересно — я не вижу смысла его нанимать, во всяком случае в мою команду. Атмосфера работы — тоже крайне важный фактор который проверяет такое собеседование.
А что за компания, если не секрет? Мне кажется, не так уж и много в нашей стране компаний, требующих от соискателей умения отвечать на обозначенные выше вопросы.
Компанию ответил в личку. Я не хочу чтоб люди гугля название компании приходили «подготовленные». Очень неприятно видеть человека, который чтото заучил но не понимает что это такое. Несколько раз попадались люди которые на вопросы про HashMap отвечали сумбурными рассуждениями про «бакеты», но что такое эти бакеты ответить не могли.
Как я уже говорил я ни в коем случае не «требую» умения отвечать на эти вопросы. Это просто вопросы которые мне самому интересно обсудить и которые мне кажется должны вызвать интерес у достойного соискателя. Я не ожидаю правильного ответа и на половину из них, но чаще всего двух-трех подобных вопросов достаточно чтобы у меня сложилось понимание, хочу ли я с этим человеком работать или нет.
Как я уже говорил я ни в коем случае не «требую» умения отвечать на эти вопросы. Это просто вопросы которые мне самому интересно обсудить и которые мне кажется должны вызвать интерес у достойного соискателя. Я не ожидаю правильного ответа и на половину из них, но чаще всего двух-трех подобных вопросов достаточно чтобы у меня сложилось понимание, хочу ли я с этим человеком работать или нет.
Нормальная компания. У нас бывает что устное собеседование длится 3-4 часа, и то не все успеваем спросить. Бывает и 2-3 минуты всего.
Свою схему собеседования я сделал как результат анализа тех которые проходил я. Прошлой зимой-весной зная что мне предстоит вскоре набирать сотрудников я 2-3 раза в неделю ходил на собеседования.
Основным недостатком большинства считаю как раз нерациональное использование времени: задают вопросы ответ на которые прост и однострочен и далее ходят вокруг да около простой темы, задают вопросы которые не отображают реальное состояние вещей, вроде теоретических «какие части кода нужно документировать».
Доходило до идиотизма когда спрашивали StyleGuide java в течении получаса. Лучше бы попросили написать код на любую задачу(да блин хоть сортировку пузырьком). Потратили бы меньше моего времени и больше узнали бы обо мне.
Еще большим идиотизмом было когда собеседующий начинал описывать проект и тратил на это более часа. Либо неся чтото невнятное либо вдаваясь в сугубо технические подробности их реализации элементарных вещей.
Основным недостатком большинства считаю как раз нерациональное использование времени: задают вопросы ответ на которые прост и однострочен и далее ходят вокруг да около простой темы, задают вопросы которые не отображают реальное состояние вещей, вроде теоретических «какие части кода нужно документировать».
Доходило до идиотизма когда спрашивали StyleGuide java в течении получаса. Лучше бы попросили написать код на любую задачу(да блин хоть сортировку пузырьком). Потратили бы меньше моего времени и больше узнали бы обо мне.
Еще большим идиотизмом было когда собеседующий начинал описывать проект и тратил на это более часа. Либо неся чтото невнятное либо вдаваясь в сугубо технические подробности их реализации элементарных вещей.
Можно поинтересоваться, чем вы занимаетесь, что спрашиваете такое на собеседованиях? Просто тематика вопросов совпадает с нашей, но за достаточно долгое время поисков разработчика я не видел ни одного, который смог бы ответить даже на половину вопросов.
Чем занимаюсь отписал в личку.
Как я уже говорил я не ожидаю получить правильный ответ на собеседовании. Каждый из этих вопросов требует отдельного исследования, или же гиканутости чтобы знать на них ответ. У меня нет цели набрать команду гиков и есть сомнения что команда гиков вообще может выполнять поставленные задачи в нужных объемах и в нужные строки.
Эти вопросы я использую как те, которые считаю что должны быть интересны людям в моей команде. Обсуждая с ним эти вопросы я узнаю как мыслит соискатель и будет ли ему интересно со мной и мне с ним.
Как я уже говорил я не ожидаю получить правильный ответ на собеседовании. Каждый из этих вопросов требует отдельного исследования, или же гиканутости чтобы знать на них ответ. У меня нет цели набрать команду гиков и есть сомнения что команда гиков вообще может выполнять поставленные задачи в нужных объемах и в нужные строки.
Эти вопросы я использую как те, которые считаю что должны быть интересны людям в моей команде. Обсуждая с ним эти вопросы я узнаю как мыслит соискатель и будет ли ему интересно со мной и мне с ним.
Я, кстати говоря, уже давно не задаю на собеседовании сложны, алгоритмических, либо практических вопросов, например напишите пожалуйста самый простой неблокирующий стек. Мы примерно час общаемся на интересные, в первую очередь для нас, темы, такие как: многопоточность и сихронизация, память и сборка мусора. Иногда разбираем какие-либо интересные, опять же для нас, проблемы с которыми сталкивались мы или соискатель. Такой разговор по большей части дает понять что из себя представляет человек, что знает, чем умеет пользоваться а о чем слышит впервые.
И опять же, если я задаю вопрос, то стараюсь формулировать его так, что бы соискатель не пытался вспомнить какую-нибудь конкретную вещь, а рассказал то, что знает. Например вопрос «какие три вида синхронизации применяются при использовании synchronized», я сформулирую примерно так: «что вы можете рассказать о ключевом слове synchronized», и при необходимости задать некоторые уточняющие вопросы, например «а чем он отличается от локов, кстати, каких именно, из пакета juc»
И опять же, если я задаю вопрос, то стараюсь формулировать его так, что бы соискатель не пытался вспомнить какую-нибудь конкретную вещь, а рассказал то, что знает. Например вопрос «какие три вида синхронизации применяются при использовании synchronized», я сформулирую примерно так: «что вы можете рассказать о ключевом слове synchronized», и при необходимости задать некоторые уточняющие вопросы, например «а чем он отличается от локов, кстати, каких именно, из пакета juc»
Спасибо за пищу для размышлений. Очень интересные темы вы обсуждаете при приёме на работу.
А может кто-нибудь подсказать, где почитать подобный материал, но применительно к C#? Кардинальных отличий при работе с коллекциями по сравнению с Java вроде бы нет, но может есть какие-то нюансы, которые стоит знать?
Есть очень хорошая книга, CLR via C#, покрывает многие аспекты языка и исполняющей среды.
Кстати, недавно вышло четвёртое издание, если будете покупать, обратите внимание.
LeoCcoder молодец, интересные вопросы придумал. К вопросу 14 добавлю, что использовать можно, иногда именно этого и добивается программист: используются только ключи идентичные (а не просто равные) тем, что уже помещены в Map. Например, у вас фиксированный набор объектов, с которыми вы хотите ассоциировать какую-то статистику и потом быстро её достать. Впрочем, для этих целей лучше использовать IdentityHashMap.
за 14й вопрос спасибо yandex'у, он у них в тесте есть на вакансию андроид девелопер, там в примере кеш релизован с ключами на byte[], которые пересоздавались и должны были сравниваться по содержимому… кеш в примере потяное дело не работал. использовать конечно же можно, но в большистве случаев результат будет не тем, который ожидают новички…
Вот вам задачка на коллекции.
Нужно придумать реализацию структуру данных со следующим интерфейсом:
Эта структура данных является массивом. Размер (максимальное количество элементов) фиксирован и задается при создании. Метод get может возвращать как Object так и null, в случае, если по данному индексу не было put c момента создания или с момента вызова clearAll().
И теперь самое важное. Методы get put и clearAll должны гарантированно работать за O(1).
Нужно придумать реализацию структуру данных со следующим интерфейсом:
Object get(int index);
void put(int index, Object value);
void clearAll();
Эта структура данных является массивом. Размер (максимальное количество элементов) фиксирован и задается при создании. Метод get может возвращать как Object так и null, в случае, если по данному индексу не было put c момента создания или с момента вызова clearAll().
И теперь самое важное. Методы get put и clearAll должны гарантированно работать за O(1).
Вести счетчик вызовов clearAll. По put рядом со значением положить текущее значение счетчика. По get сравнить сохраненное значение с текущим значеним счетчика, вернуть null, если меньше. Простовато для собеседования то.
По-моему для собеседования как раз и ничего. Если ещё и попросить код написать, то вполне. Посмотреть заодно как будет реализована структура.
Задачка не сложная, не спорю. Хотя 90% junior-to-middle java developers из тех, кого я собеседовал, не могли написать работающую реализаци задачки на merge двух отсортированных массивов, не говоря уже о красивом коде.
«Да 90% разработчиков не смогут и список односвязный развернуть!» — байка откуда-то.
Вы не согласны?
Отчего же, согласен, но дело ведь в том, что подобного от этих 90% и не требуется — для решаемых ими проблем в подобных знаниях и умениях необходимости нет.
Но если уж вопрос заходит о том, что от соискателя требуются хотя бы знания базовых алгоритмов, структур данных, минимальные навыки проектирования, да и просто голова на плечах — стоит придумать более сложные и разносторонние задачи.
Но если уж вопрос заходит о том, что от соискателя требуются хотя бы знания базовых алгоритмов, структур данных, минимальные навыки проектирования, да и просто голова на плечах — стоит придумать более сложные и разносторонние задачи.
Это из RSDN: Задача на собеседовании — обращение списка
Там развернулась бурная дискуссия на тему должен ли программист уметь написать простой алгоритм, который не требует каких-то особых знаний кроме умения оперировать тремя ссылками.
Там развернулась бурная дискуссия на тему должен ли программист уметь написать простой алгоритм, который не требует каких-то особых знаний кроме умения оперировать тремя ссылками.
Интересная дискуссия. Правда, целиком не осилил. Кто там победил?
Никогда такого не спрашивали, ради интереса попробовал на листке набросать, за пару минут рисования родилось 5 строчек кода. Вот сижу и не пойму, то ли я вхожу в 10% тех, кто может это написать, то ли я не понимаю сложности задачи.
А эти 5 строчек — через собственную реализацию или через стандартную? Насколько я понял, основная сложность там в том, что соискатели не могут поверить, что в наше время им вообще могут предложить написать самодельные структуры данных (вместо того, чтобы воспользоваться библиотечными). Тех, кто пытался в этой дискуссии предложить свои реализации, тут же закидывали тапками по самую шею.
Интересна задача про «выбрать K случайных элементов из массива за O(K)». Я так и не понял, там было только авторское решение, или кто-то предложил своё.
Интересна задача про «выбрать K случайных элементов из массива за O(K)». Я так и не понял, там было только авторское решение, или кто-то предложил своё.
Эти 5 строчек, основаны на классической «своей» реализации списка, есть поле под значение и есть ссылка на следующий элемент. То есть никаких коллекций и ничего подобного. А по дискуссии имелась в виду реализация через что-то стандартное? я не дочитал, много букв.
Выбрать К элементов, то же не дошел. Я так понимаю сложность задачи чтобы выбрать К неповторяющихся элементов?
Выбрать К элементов, то же не дошел. Я так понимаю сложность задачи чтобы выбрать К неповторяющихся элементов?
Да, неповторяющихся. И любое подмножество должно быть выдано с равной вероятностью. Число элементов исходного массива известно.
(А есть еще задача — выбрать K случайных элементов из последовательности неизвестной заранее длины. За один проход, с памятью O(K). Но это уже на смекалку...)
(А есть еще задача — выбрать K случайных элементов из последовательности неизвестной заранее длины. За один проход, с памятью O(K). Но это уже на смекалку...)
В цикле, k раз: выбрать рандомный индекс (от 0 до n), вернуть по нему значение из массива, обменять этот элемент с последним, уменьшить n на единицу, повторить. Время — O(k), память — O(1). Профит.
Я правильно понимаю, что модификация массива не особо то и нужна, нужно просто O(k) памяти? (портить входные данные — нехорошо)
Без модификации будет очень сложно избежать выдачи одинаковых элементов. За O(k^2) выдать k случайных различных индексов легко, за O(k*log(k)), вероятно, тоже возможно. Но как это сделать за O(k)?
Упс, действительно O(k^2). Извините
O(k*log(k)) — например, рекурсией и очень хитрым слиянием. Примерно как в задаче о рыцарском турнире. Вот только выданное множество индексов получится отсортированным.
Если преобразовать это же решение (т.е. запоминать «обмены» в отдельном месте, типа хеш-таблицы), то да — O(k) памяти, но время работы будет больше O(k) — необходимо находить индекс элемента в массиве по его новому (после «обмена») индексу.
Решение там примерно такое:
Список:
Разворот:
Так что «самодельная структура данных» это громко сказано, класс с двумя полями — значение и ссылка на следующий узел.
Список:
public class Node<T>
{
public T Value { get; set; }
public Node<T> Next { get; set; }
}Разворот:
public static Node<T> ReverseInPlace<T>(Node<T> root)
{
Node<T> prev = null;
Node<T> curr = root;
while (curr != null)
{
var next = curr.Next;
curr.Next = prev;
prev = curr;
curr = next;
}
return prev;
}
Так что «самодельная структура данных» это громко сказано, класс с двумя полями — значение и ссылка на следующий узел.
Такие структуры там и предлагались. И их в ответ называли «велосипедами с треугольными колёсами». И обсуждали, через какие списки надо решать эту задачу — через ArrayList или какие-то ещё…
Ну слово «самодельная» я применил, чтобы однозначно определить, что имею в виду. Мой код переписываю с листика буква в букву:
Собственно даже имена переменных совпали почти полностью.
while(list != null) {
next = list.next;
list.next = prev;
prev = list;
list = next;
}
Собственно даже имена переменных совпали почти полностью.
Мне кажется, что с К случайных решение примерно такое:
Сложность O(K), память O(K)
int K = 3; //количество необходимых чисел
int N = 15; //количество элементов в массиве.
var random = new Random();
var randomIndexes = new int[K]; // случайные индексы элементов, которые мы должны вытащить из массива
for (int i = 0; i < K; i++)
{
var prev = i > 0 ? (randomIndexes[i - 1] + 1) : 0;
randomIndexes[i] = random.Next(prev, N - (K - i - 1));
}
var shift = random.Next(0, N);
for (int i = 0; i < K; i++)
{
randomIndexes[i] = (randomIndexes[i] + shift) % N;
}
... // тут возвращаем все элементы с найденными индексами
Сложность O(K), память O(K)
то ли я вхожу в 10% тех, кто может это написать
Видимо, да. По моему опыту — мало кто может написать этот весьма простой алгоритм (пример ответа написал выше)
Я недавно обнаружил, что не могу сходу написать быструю сортировку. Вроде бы всё работает, но на массиве, в котором много одинаковых элементов, скорость падает до O(N^2)… Очень неприятно было.
Ну так вы вроде и правильно написали — если работает, но на плохих случаях до квадратичной сложности спускается. А pivot как выбирали?
Неправильно. Правильный алгоритм на любом массиве работает в среднем за N*log(N). А у меня на массиве, в котором всего 2 значения, почти всегда получалось N^2: когда разделяющее число оказывалось минимальным, отщеплялся 1 элемент, даже если почти все элементы массива были равны этому минимальному. Ни разу не увидел в описании алгоритма этой тонкости (или не обратил на неё внимания), вот и попался.
Как выбирал, не помню. Скорее всего — медиана из первого, центрального и последнего — как подглядел когда-то в стандартной библиотеке ещё на TurboC.
Как выбирал, не помню. Скорее всего — медиана из первого, центрального и последнего — как подглядел когда-то в стандартной библиотеке ещё на TurboC.
Посмотрите на 3-way QuickSort, это улучшенная быстрая сортировка, которая как раз и решает проблему с одинаковыми элементами в массиве.
Скорее всего, в каком-нибудь индексе была ошибка +-1. Работать будет корректно, но скорость сильно упадет.
Странно, я пока не увидел ваше решение думал, что-то не так понял.
Да никто не победил, все остались при своем мнении :)
Но мой ИМХО — программист должен уметь на компе в IDE за полчаса-час написать разворот списка. Там на самом деле идея тривиальная, проблемы могут быть только на граничных значениях, неправильная последовательность переброски элементов и пр. — но это должно решаться за 5-10 минут дебага.
Даже с учетом стресса на интервью
Но мой ИМХО — программист должен уметь на компе в IDE за полчаса-час написать разворот списка. Там на самом деле идея тривиальная, проблемы могут быть только на граничных значениях, неправильная последовательность переброски элементов и пр. — но это должно решаться за 5-10 минут дебага.
Даже с учетом стресса на интервью
Можно добавить методы «вернуть какой-нибудь элемент» и «очистить элемент». Тоже за O(1).
Кстати, то, что после MAXINT очисток класс сломается, это ничего?
Кстати, то, что после MAXINT очисток класс сломается, это ничего?
Обычно, предполагается, что 2^31 раз вы хеш-таблицу очищать не будете :) В противном случае ключик можно сделать и uint64_t, тогда это точно будет недостижимая оценка
Есть же get и put, который можно вызвать с null.
По поводу MAXINT — никто не заставляет использовать int для хранения версии.
По поводу MAXINT — никто не заставляет использовать int для хранения версии.
put(null) — да. А get не поможет: под «вернуть какой-нибудь элемент» имелся в виду аналог First в итераторе или какие там средства есть чтобы найти хоть какой-нибудь элемент в множестве (не зная индексов, в которых элементы уже лежат).
По поводу MAXINT — никто не заставляет использовать int для хранения версии
А что же использовать? Существует ли решение, когда размер массива ограничен (чтобы арифметика с индексами работала за константное время), а число обращений к нему — неограничено (вообще), и мы всё равно хотим решить задачу за O(1)?
Ага, есть решение для неограниченного числа очисток. Смешное такое :)
Софистика по поводу константы 264 и утверждение, что элементарные операции над long нельзя считать O(1) выглядит занудством.
По поводу head() — тут поможет связывать элементы двусвязным списком и хранить ссылку на голову. Да, хорошее дополнение.
По поводу head() — тут поможет связывать элементы двусвязным списком и хранить ссылку на голову. Да, хорошее дополнение.
Занудство и есть. Но предложение заменить int на int64, чтобы не переполнился счетчик очисток — тоже как-то не очень. Чистота задачи разрушается. Можно не выходя за int, подправить решение так, что ограничения на число очисток не будет совсем.
С другой стороны, не зря же сложность быстрого умножения оценивают как O(N*log(N)*log(log(N)))? Если log(N)=32 кажется достаточно большой константой, то log(log(N)) только-только перешагнул значение 5… Но его всё равно пишут.
Да пожалуйста. Храните размер и номер версии в разных переменных одного типа (т.е. либо оба int, либо оба uint). Заведите дополнительную переменную, указатель, какой элемент коллекции мы обновили в плане номера версии. После обнуления массива, обнуляем этот указатель. На каждой операции get\put дополнительно ставим переменной null, а её версии — версию коллекции, после увеличиваем Все, у нас никогда не получится такого, чтобы после ряда операций put(index), clearAll(), put ( rand() != index) * manytimes у нас в get(index) выдавал не null. Все операции до сих пор O(1). Но это конечно, если ваш язык после инкремента int_max не кидает эксепшен (но и это можно предотвратить). Единственное — нужно тщательно подобрать код и доказать, что для последнего (или последних) элемента массива размера int_max не будет проблем.
UPD: О да, прочитал нижнюю ветку и сказал, что таким образом мы чуть-чуть избавляемся от утечек.
UPD: О да, прочитал нижнюю ветку и сказал, что таким образом мы чуть-чуть избавляемся от утечек.
Это у меня было первой идеей. Потом придумал, что достаточно хранить только номер версии (по модулю N), и перед его увеличением прописывать его элементам с индексами Vold и Vnew, где Vnew=(Vold+1)%N (только на этапе очистки). Тогда после каждой очистки у нас гарантированно не окажется ни одного элемента с версией Vnew:
void Clear(){
int Vnew=(CurVersion+1)%N;
Versions[CurVersion]=Versions[Vnew]=CurVersion;
CurVersion=Vnew;
}
Или я не понял ваше решение, или оно не верное. В приведенном куске кода что хранится в массиве Versions? А еще лучше, пожалуйста, приведите код решения целиком (clear, put и get).
Мое решение требует еще O(n) дополнительной памяти.
Ничего, если на C#? Получается примерно так (не проверял):
Предполагается, что N>0.
Я пока не смог придумать, как его обмануть.
class FastSet{
int N; // size of array
int CurVersion; // current version of data, clearings counter
object[] Values; // values
int[] Versions; // versions of elements
public FastSet(int _N){
N=_N;
Values=new object[N];
CurVersion=1%N; // or N==1 ? 0 : 1
Versions=new int[N]; // versions of all elements are 0, just out of date
}
public void Clear(){
int NewVer=(CurVersion+1)%N;
Versions[CurVersion]=Versions[NewVer]=CurVersion;
Values[CurVersion]=null; // for case N=1
CurVersion=NewVer;
}
public void Put(int ind,object val){
if(ind<0 || ind>=N) return;
Values[ind]=val;
Versions[ind]=CurVersion;
}
public object Get(int ind){
if(ind<0 || ind>=N || Versions[ind]!=CurVersion) return null;
return Values[ind];
}
}
Предполагается, что N>0.
Я пока не смог придумать, как его обмануть.
Только если озвучено данное решение, надо выяснить у человека, видит ли он здесь утечки памяти.
Если хочется его завалить — то да. Потому что если он не видит утечек, показать ему, что ссылка на элемент всё ещё болтается в массиве, и поэтому объект не удалится, а если видит — то объяснить, что это никакая не утечка, потому что ссылка нам легко доступна, и при необходимости мы всегда можем её очистить. В обоих случаях — до свидания.
Но если с массивом идёт активная работа, то таких утечек легко можно избежать.
Но если с массивом идёт активная работа, то таких утечек легко можно избежать.
Причем тут завалить?
У каждого решения есть слабые и сильные стороны, и если человек не видит слабых сторон, велик риск использовать решение не эффективно. (и далее можно перейти на тему работы с памятью, дабы выяснить — он просто не заметил эту проблему или есть провал в знаниях)
У каждого решения есть слабые и сильные стороны, и если человек не видит слабых сторон, велик риск использовать решение не эффективно. (и далее можно перейти на тему работы с памятью, дабы выяснить — он просто не заметил эту проблему или есть провал в знаниях)
А какой правильный ответ? Утечка это или не утечка?
В общем случае — да, утечка.
В некоторых частных случаях — формально тоже утечка, но с которой можно мериться (малое время до следующей перезаписи — объекты не успеют попасть в old gen, малые объекты/малое количество объектов)
Конкретное решение очень зависит от задачи. В случае задачи на тех интервью — достаточно указать на данную особенность коллекции и сказать для финального решения по выбору (или не выбору данной структуры) не достаточно информации о том как коллекция будет использоваться.
В некоторых частных случаях — формально тоже утечка, но с которой можно мериться (малое время до следующей перезаписи — объекты не успеют попасть в old gen, малые объекты/малое количество объектов)
Конкретное решение очень зависит от задачи. В случае задачи на тех интервью — достаточно указать на данную особенность коллекции и сказать для финального решения по выбору (или не выбору данной структуры) не достаточно информации о том как коллекция будет использоваться.
один из способов:
в отличии от способа со счетчиками, мы не держим референсы на «удалённые» объекты.
clearAll() {
array = new Object[initSize];
}
в отличии от способа со счетчиками, мы не держим референсы на «удалённые» объекты.
Инициализация массива (null'ами) — O(n), да еще плюс накладные расходы на сборку мусора.
вы считаете, что это O(1)?
Спасибо! Ваш вопрос заставил меня задуматься глубже :)
компилируется в команду jvm «anewarray» c указанием размера. инициализация массива null'ами — тоже внутри этой операции.
И, честно говоря, я не знаю как оценить данный вызов.
Буду премного благодарен, если кто-нить подскажет куда посмотреть дабы узнать что реально делает эта команда.
array = new Object[initSize]
компилируется в команду jvm «anewarray» c указанием размера. инициализация массива null'ами — тоже внутри этой операции.
И, честно говоря, я не знаю как оценить данный вызов.
Буду премного благодарен, если кто-нить подскажет куда посмотреть дабы узнать что реально делает эта команда.
Реально оно сильно зависит от платформы и имеет право меняться даже между версиями и запусками одной и тойже JVM.
В свое время когда интересовался проверял: если срабатывает Escape Analysis то аллоцирует на стеке и обнуляет процессорной инструкцией,
иначе оно выделяет в эдеме обьект, и вызывает процессорную инструкцию обнуления.
В моем случае для обнуления вызывалась оптимизированная реализация из SSE.
В свое время когда интересовался проверял: если срабатывает Escape Analysis то аллоцирует на стеке и обнуляет процессорной инструкцией,
иначе оно выделяет в эдеме обьект, и вызывает процессорную инструкцию обнуления.
В моем случае для обнуления вызывалась оптимизированная реализация из SSE.
Все равно я не могу придумать, как обнулить кусок пямяти длиной n (n → ∞) быстрее, чем за O(n).
Когда вы занимаетесь теоретической разработкой алгоритма нужно говорить, в чем вы исчисляете операции. Говоря O(n) вы подразумеваете что элементарная операция это и есть обнуление одной ячейки. Если считать элементарной операцией такт процессора — думаю вы все еще правы, сложность имеет линейный рост. Но если считать byteCode инструкцию, то очевидно будет O(1). Это как договорится)
Когда вы занимаетесь не теоретической разработкой а практической становятся важны константы.
Например: есть реализации Map для целых чисел со сложностью log log M(при некоторых предположениях но упустим, не суть). Однако на практике константа у них больше и они становятся осмысленны когда количество данных сравнимо с числом атомов в наблюдаемой вселенной.
В данном конкретном случае это сродни System.arrayCopy, но еще быстрее.
офтопик: мне кажется что с использованием программной эмуляции версионирования памяти с помощью Y-fast tries можно добиться сложности log(количество инструкций УЖЕ выполненых програмой). В предположении что время работы вашей программы в целом суб-экспоненциально то это асимптотически быстрее.
Когда вы занимаетесь не теоретической разработкой а практической становятся важны константы.
Например: есть реализации Map для целых чисел со сложностью log log M(при некоторых предположениях но упустим, не суть). Однако на практике константа у них больше и они становятся осмысленны когда количество данных сравнимо с числом атомов в наблюдаемой вселенной.
В данном конкретном случае это сродни System.arrayCopy, но еще быстрее.
офтопик: мне кажется что с использованием программной эмуляции версионирования памяти с помощью Y-fast tries можно добиться сложности log(количество инструкций УЖЕ выполненых програмой). В предположении что время работы вашей программы в целом суб-экспоненциально то это асимптотически быстрее.
Все, что вы написали — верно. Но к исходному вопросу отношение имеет слабое.
Я думаю, вы сами понимаете, насколько нецелесообразно выбирать в качестве скалярной операции byteCode инструкцию.
Теоретизирование на тему гипотетических архитектур, специально заточенных на оптимизацию отдельных операций, также считаю не относящимся к исходной задаче.
Константы, конечно, имеют огромное практическое значение, но на ассимптотическую оценку не влияют.
Я думаю, вы сами понимаете, насколько нецелесообразно выбирать в качестве скалярной операции byteCode инструкцию.
Теоретизирование на тему гипотетических архитектур, специально заточенных на оптимизацию отдельных операций, также считаю не относящимся к исходной задаче.
Константы, конечно, имеют огромное практическое значение, но на ассимптотическую оценку не влияют.
Кстати: вопрос вдогонку на тему Generic+колекции:
у Map<K,V>
но
Почему в одном случае тип ключа V а в другом Object.
у Map<K,V>
put(K key, V value) но
V get(Object key).Почему в одном случае тип ключа V а в другом Object.
я когда первый раз увидел подумал, что это баг и пошел читать, зачем же так сделали… вот тут написано хорошо: smallwig.blogspot.ru/2007/12/why-does-setcontains-take-object-not-e.html
Хороший вопрос, прочитал по инфу по ссылке, суть ясна, но ввело в ступор следующее:
То есть в первом случае компилятор запретит любой тип, разрешен будет только null, а в методе add применяется тот же самый подход и разрешен не только null, но и тип E. По логике или и там и там, должно быть все запрещено или работать корректно в обоих случаях. Или я что-то все же не понял.
But the compiler doesn't know the type — it could be a Foo, or SubFoo, or SubSubFoo, or who knows what? Thus the compiler would have to forbid everything — the only safe parameter to a method like this is null.
This is the behavior you want for a method like Set.add() — if you can't make damn sure of the type, don't allow it.
То есть в первом случае компилятор запретит любой тип, разрешен будет только null, а в методе add применяется тот же самый подход и разрешен не только null, но и тип E. По логике или и там и там, должно быть все запрещено или работать корректно в обоих случаях. Или я что-то все же не понял.
Какая оценка временной сложности выборки элемента из HashMap? Гарантирует ли HashMap указанную сложность выборки элемента?Как я уже тут сказал вопрос очень странный, если рассматривать именно теорию сложностей, то гарантирует константную, да.
з.ы Как раз эти вопросы подойдут именно для отсеивания приличных джуниоров от непойми кого, по определению просто. Или теперь джуниором называется тот, кто не понимает элементарных вещей, типа устройства классических структур данных? Т.е. начал с обратной стороны обучаться? Оригианльноу.
Учитывая что на хабре люди всерьез обсуждают нужно ли высшее образование, то у многих кто выбрал не тратить на него время обучение начинается со случайной точки. И может происходить в хаотическом порядке.
ps:
Я согласен что даже современные курсы алгоритмов в вузах устарели.
Но они являются фундаментом для уже современных курсов, потому я не жалею что выбрал идти в вуз.
ps:
Я согласен что даже современные курсы алгоритмов в вузах устарели.
Но они являются фундаментом для уже современных курсов, потому я не жалею что выбрал идти в вуз.
Вещи эти не совсем элементарные, но, я соглашусь, простые при должном background`е. Теперь про него, этот самый background. К сожалению, в «уездных» городах, где нет академ городков, или исследовательских центров связанных с IT, образование в ВУЗах по IT специальностям, как правило, очень слабая. В итоге на выходе получаем непойми кого, как вы говорите, с навыкам кодинга, если человек сам не будет дальше развиваться, то все, вот его уровень теоретических знаний. Это очень здорово, если повезло учиться в ВУЗе с сильным обучением, но таких вузов мало в стране, так что жизнь и рынок диктуют свои условия. К тому же джуниор очень сильно отличает от компании к компании, где-то возьмут вчерашнего студента из уездного вуза с базовым пониманием программирования на джуниора, а где то может после пары лет опыта работы и хорошего вуза не потянет на джуниора (само собой если и тот и тот хорошо учились в своих вузах). Как я в самом начале написал, на некоторые из этих вопросов не смогли ответить знакомые разработчики (middle, junior). У них хороший опыт, они серьезно разбираются в своих узких сферах деятельности, они хорошо делают свою работу и я думаю вполне смогут пройти собеседование на аналогичную деятельность в другие, в том числе и крупные компании, но вот здесь у них пробелы из-за вуза, из-за отсуствия увлеченности в этом направлении, из-за отсуствия необходимости разбираться в этом по работе. И у меня язык не поворачивается назвать их «не пойми кто». Реалии жизни не всегда укладываются в представление о правильном образовании: сначала серьезный фундамент базовых вещей, потом более узкие предметы и т.д.
7. Как устроена HashMap?
Это второй из списка самых популярных вопросов по коллекциям. Уж даже не помню был ли случай, когда этот вопрос мне не задавали.
Вкратце, HashMap состоит из «корзин» (bucket`ов).
basket это корзина
bucket это translate.google.com/#en/ru/bucket
Большой совет — не переводите термины вроде этого, особенно на собеседовании. Если бы я Вас собеседовал, то кашлянул бы, лучше поверьте мне
Спасибо за замечание, про различие этих двух слов я знаю, и перевод (точнее не перевод, а адаптация термина на русский) принадлежит не мне. Я сейчас не вспомню откуда именно так пошло, но употребление именно этого термина не раз встречал. Может это конечно неверно закрепившийся термин, в каком-то ограниченном сообщество программистов. В любом случае учту ваше замечание.
то есть как, Вы читаете не оригиналы? Возможно этот термин и закрепился, я уже полгода не пишу на джава регулярно… но я его встречаю в первый раз. Наверное потому что не особо приходилось читать переводы, я вот как-то нормальных не находил никогда. Вообще лучше не читать авторов… брать спеку, и чехлить. Авторы вносят много выводов, лишая Вас удовольствия сделать их самому :)
Стараюсь читать оригиналы, но что греха таить бывает и в переводе читаю что-то, кроме того много информации в сети именно на русском (форумы, статьи), а там тоже бывает с переводом не все гладко.
послушайте The Java Posse, они, конечно, технические вопросы обсуждают вскользь (не сказать что вообще мимо :) ), но все-же это джава подкаст :) и не забивайте себе мозг Eckel-ем (thinking in java), хотя если у Вас есть киндл и Вы тратите больше часа в день на транспорт (метро) — эта книга будет интересным чтивом. для джуниора. трушные синьеры читают спеки :)
В русском ACM'е фигурирует именно «корзина» в большинстве случаев. Мне кажется неверным всегда прямо экстраполировать английские термины в русские, например здесь «корзина» больше подходит по смыслу, чем «ведро».
К тому же в университетах зачастую обучение алгоритмам происходит не по книгам, а передачей из уст в уста, в том же Кормене нет большей части используемого на олимпиадах — алгоритмы банально появились позже выхода книги, и многие из них пришли из России.
К тому же в университетах зачастую обучение алгоритмам происходит не по книгам, а передачей из уст в уста, в том же Кормене нет большей части используемого на олимпиадах — алгоритмы банально появились позже выхода книги, и многие из них пришли из России.
Чтобы сэкономить время, на собеседовании задаю вопрос, подсмотренный когда-то у Яндекса:
в каких из указанных наборов данных время поиска элемента составляет O(ln n):
Object[]
ArrayList
LinkedList
Vector
HashMap
LinkedHashMap
TreeMap
отсортированный Object[]
отсортированный ArrayList
отсортированный LinkedList
Еще хорошие вопросы про контракт equals-hashCode и обход коллекции итератором, в которую вносятся изменения не через итератор. Неизменяемые наборы данных тоже хорошая тема.
А про выбор между ArrayList или LinkedList меня бы устроил ответ, что в 90% случаев разницы нет (как правило, список формируется один раз из небольшого количества элементов и более не изменяется, обходится полностью).
в каких из указанных наборов данных время поиска элемента составляет O(ln n):
Object[]
ArrayList
LinkedList
Vector
HashMap
LinkedHashMap
TreeMap
отсортированный Object[]
отсортированный ArrayList
отсортированный LinkedList
Еще хорошие вопросы про контракт equals-hashCode и обход коллекции итератором, в которую вносятся изменения не через итератор. Неизменяемые наборы данных тоже хорошая тема.
А про выбор между ArrayList или LinkedList меня бы устроил ответ, что в 90% случаев разницы нет (как правило, список формируется один раз из небольшого количества элементов и более не изменяется, обходится полностью).
Object[]
ArrayList
LinkedList
Vector
здесь у нас полный перебор
HashMap
LinkedHashMap
здесь меньше, чем ln n, хотя опять же как смотреть, выше идут споры про HashMap и Big O.
TreeMap
отсортированный Object[]
отсортированный ArrayList
вот это, подходит
отсортированный LinkedList
а здесь не получится lg N, нет возможности быстрого доступа к по индексу элемента
ArrayList
LinkedList
Vector
здесь у нас полный перебор
HashMap
LinkedHashMap
здесь меньше, чем ln n, хотя опять же как смотреть, выше идут споры про HashMap и Big O.
TreeMap
отсортированный Object[]
отсортированный ArrayList
вот это, подходит
отсортированный LinkedList
а здесь не получится lg N, нет возможности быстрого доступа к по индексу элемента
Коллекции — это только первая часть вопросов. Дальше интереснее: nio/atomic/concurrent/locks/threads, дальше специализация под проект /sockets/javaee/gwt/sql/…
а с каких пор у вас HashMap стал коллекцией?
Вряд ли можно найти оправдание использованию LinkedList в качестве реализации списка. В качестве реализации Deque, ещё куда ни шло, но и здесь есть ArrayDeque.
На самом деле, вопрос, какую реализацию выбрать не так актуален, если не знаешь какой интерфейс тебе нужен. Программистов как-то уже научили, что в качестве параметра или при объявлении переменной не стоит использовать конкретную реализацию, т.к. это приводит к усложнению дальнейшей разработки. Все согласились, хорошо, не будет использовать конкретную реализацию, будем писать везде List. Но не все поняли основную мысль, надо не лепить List куда ни попадя, надо максимально абстрагироваться. Почему-то все всегда и везде используют List, а ведь есть множество других интерфейсов. При объявлении параметра метода или переменной, или поля в классе нужно использовать именно тот интерфейс, свойства которого вам нужны.
Iterable — говорит о том, что реализация может создавать итератор, в большинстве случаев от параметров метода большего и не нужно
Collection — обеспечивает методы добавления и удаления данных
List — гарантирует сохранение порядок
Set — гарантирует уникальность элементов
SortedSet — предоставляет элементы в естественном (ну можно с компаратором поиграть) порядке
Queue — часто забывают про очередь, в один конец очереди элементы добавляются, а из другого достаются
Deque — двунаправленная очередь, позволяет добавлять и удалять элементы с обоих концов, может быть использована в качестве стека
Map — отображает одни элементы на другие
SortedMap — опять же можно получить список кортежей, отсортированный по ключу
Ну еще есть всякие синхронизированные коллекции, но если вы используете их слишком часто, значит у вас конкретные проблемы. А если вы используете их не слишком часто, всегда можно почитать доку.
На самом деле, вопрос, какую реализацию выбрать не так актуален, если не знаешь какой интерфейс тебе нужен. Программистов как-то уже научили, что в качестве параметра или при объявлении переменной не стоит использовать конкретную реализацию, т.к. это приводит к усложнению дальнейшей разработки. Все согласились, хорошо, не будет использовать конкретную реализацию, будем писать везде List. Но не все поняли основную мысль, надо не лепить List куда ни попадя, надо максимально абстрагироваться. Почему-то все всегда и везде используют List, а ведь есть множество других интерфейсов. При объявлении параметра метода или переменной, или поля в классе нужно использовать именно тот интерфейс, свойства которого вам нужны.
Iterable — говорит о том, что реализация может создавать итератор, в большинстве случаев от параметров метода большего и не нужно
Collection — обеспечивает методы добавления и удаления данных
List — гарантирует сохранение порядок
Set — гарантирует уникальность элементов
SortedSet — предоставляет элементы в естественном (ну можно с компаратором поиграть) порядке
Queue — часто забывают про очередь, в один конец очереди элементы добавляются, а из другого достаются
Deque — двунаправленная очередь, позволяет добавлять и удалять элементы с обоих концов, может быть использована в качестве стека
Map — отображает одни элементы на другие
SortedMap — опять же можно получить список кортежей, отсортированный по ключу
Ну еще есть всякие синхронизированные коллекции, но если вы используете их слишком часто, значит у вас конкретные проблемы. А если вы используете их не слишком часто, всегда можно почитать доку.
А уж какую реализацию выбрать — совершенно не важно. Попробовал одну — работает херово. Поменял на другу — работает заебок. Оставил.
А если «херовость» проверяется только при больших нагрузках? Гораздо логичнее уметь оценивать теоретическую сложность получаемых алгоритмов, чтобы не тратить зря своего времени и просто решать задачи
Вы всерьез уверены, что ваши теоретические рассуждения помогут оценить сложность алгоритмов? Мой опыт показывает, что наибольшие потери производительности на практике происходят совсем не там, где ожидают теоретики. Короче говоря, профайлер в руки и вперед, а преждевременная оптимизация…
Да, теоретические рассуждения помогают экономить прорву времени. Особенно ярко это видно на олимпиадах, где на каждую задачу есть от силы полчаса-час времени на «придумать решение, написать, немного потестить и послать», там совершенно нет времени на проверку разных структур данных, разных алгоритмов, нужно уметь сразу выбирать наиболее подходящий инструмент и их комбинацию.
А, ну я то в контексте разработки коммерческих проектов, конечно.
Коммерческие проекты бывают очень и очень разные. Кроме того, относительно структур данных, дело вовсе не ограничивается только производительностью или потреблением памяти.
Иногда для того, чтобы банально все работало так, как ожидается, и не чесать неделю затылок, просто необходимо знать свойства этих структур данных. Например, возможно ли удалять элемент во время итерации по коллекции, какие контракты необходимо соблюдать при работе с ними.
С потокобезопасными коллекциями вообще отдельная песня — их или не используют вообще, тормозя поток на пустом месте блокировкой всего и вся, или используют неправильно, полагаясь на «раз написано Concurrent, значит сам все проблемы с потоками разрулит», и огребая гонки и прочие несогласованности.
Иногда для того, чтобы банально все работало так, как ожидается, и не чесать неделю затылок, просто необходимо знать свойства этих структур данных. Например, возможно ли удалять элемент во время итерации по коллекции, какие контракты необходимо соблюдать при работе с ними.
С потокобезопасными коллекциями вообще отдельная песня — их или не используют вообще, тормозя поток на пустом месте блокировкой всего и вся, или используют неправильно, полагаясь на «раз написано Concurrent, значит сам все проблемы с потоками разрулит», и огребая гонки и прочие несогласованности.
А потом говорят, что на хабре сливают не по делу…
Вы высказали абсолютно правильную мысль. Действительно всегда надо выбирать минимально необходимый контракт.
И вполне можно подискутировать на тему того а так ли часто имеет смысл выбирать конкретную реализацию.
Но заем вы все испортили высказыванием в столь странной форме?
Вы высказали абсолютно правильную мысль. Действительно всегда надо выбирать минимально необходимый контракт.
И вполне можно подискутировать на тему того а так ли часто имеет смысл выбирать конкретную реализацию.
Но заем вы все испортили высказыванием в столь странной форме?
Штирлиц ворвался к Мюллеру, врезал ему в ухо, отобрал секретные документы и спросил:
— А не найдется ли у вас канцелярских скрепок?
Штирлиц знал, что в разговоре всегда запоминается последняя фраза, и если Мюллера спросят:
— Зачем приходил Штирлиц? – тот наверняка ответит:
— За скрепками.
А я совершенно согласен с вами. Тем более интересно слышать разговоры про различную производительность от апологетов языка со сборкой мусора. Если говорить про Android — не высшим приоритетом UI потока. Дальше, какие бы в гугле не работали инженеры, любое простейшее приложение не сделать реально быстрым, какие ты коллекции не используй.
А мне вот это [[В целом же, LinkedList в абсолютных величинах проигрывает ArrayList и по потребляемой памяти и по скорости выполнения операций.]]] совсем не понятно! У автора есть какие нить аргументы, подтверждающие это высказывание? Как может структура, где не надо вообще копировать хип, уступать в производительности другой, где каждый шаг может привети к реевалюэйту аллоцированной памяти??!!! поясните, пожалуйста?
Каждый шаг — не может. Это раз.
А во-вторых, возьмите сами и попробуйте.
В-третиьх, вот можете посмотреть у Страуструпа описана интересная задача, в которой по асимптотике выигрывает связный список, но на практике std::vector быстрее из-за константы.
www.stroustrup.com/Software-for-infrastructure.pdf
А во-вторых, возьмите сами и попробуйте.
В-третиьх, вот можете посмотреть у Страуструпа описана интересная задача, в которой по асимптотике выигрывает связный список, но на практике std::vector быстрее из-за константы.
www.stroustrup.com/Software-for-infrastructure.pdf
Depending on the machine architecture and the programming language, the answer will be that the vector is best for small to medium values of N. When I ran the experiment on my 8-Gbyte laptop, I found N to be much larger than 500,000.
По потребляемой памяти я дал ссылку на хорошую статью, можете почитать, а по скорости, вбейте в гугл, получите кучу тестов, ну и кроме того, здравый смысл подсказывает, что работа с массивом быстрее создания объектов на каждом шаге.
В LinkedList, полагаю, используется двусвязный список, поэтому на каждый элемент тратится дополнительная память на два указателя: на предыдущий и следующий элементы. Добавление каждого элемента — это создание нового объекта в хипе, что довольно дорого.
В противовес этому ArrayList тратит память исключительно на массив указателей и его размер. Перевыделение памяти происходит довольно редко, можно доказать, что амортизированная сложность добавления нового элемента будет равна O(3), то есть O(1). Поэтому операция добавления элемента в конец ArrayList'а выполняется быстрее, чем для связного списка. Поиск нужного элемента так же может быть быстрее, т.к. мы идем последовательно по памяти, а в случае связного списка соседние элементы могут быть в противоположных кусках памяти. Обращение по индексу — без комментариев.
Как-то так. LinkedList может быть быстрее только если нам нужно часто удалять/добавлять элементы в произвольные места.
В противовес этому ArrayList тратит память исключительно на массив указателей и его размер. Перевыделение памяти происходит довольно редко, можно доказать, что амортизированная сложность добавления нового элемента будет равна O(3), то есть O(1). Поэтому операция добавления элемента в конец ArrayList'а выполняется быстрее, чем для связного списка. Поиск нужного элемента так же может быть быстрее, т.к. мы идем последовательно по памяти, а в случае связного списка соседние элементы могут быть в противоположных кусках памяти. Обращение по индексу — без комментариев.
Как-то так. LinkedList может быть быстрее только если нам нужно часто удалять/добавлять элементы в произвольные места.
Двусвязный список, все правильно. Сам всегда думал, что односвязный поэтому заглянул в сорцы.
LinkedList.java (author Josh Bloch)
LinkedList.java (author Josh Bloch)
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
На самом деле, одна из больших проблем связных списков — это пробой кеша, с чем часто можно встречаться, если писать на C++. Для Java это в большинстве случаев не так актуально, т.к. там все равно ссылаемые объекты в другом месте лежат, но если писать что-то высокопроизводительное на примитивных типах, можно серьезно споткнуться об это.
> LinkedList наоборот, за постоянное время может выполнять вставку/удаление элементов в списке (именно вставку и удаление, поиск позиции вставки и удаления сюда не входит)
Это очень странное предложение. Зачем рассматривать вставку в середину отдельно от поиска позиции?
Это очень странное предложение. Зачем рассматривать вставку в середину отдельно от поиска позиции?
А зачем смешивать две операции? Я согласен что в 90% случае они используются вместе, но все же бывают случаи, когда уже есть ссылка на нужный элемент (сохранили после вставки предыдущего элемента) + так удобнее, на мой взгляд все же сравнивать, операции не смешивая их и их сложности.
интересно, как Вы будете сохранять эту «ссылку на нужный элемент» в LinkedList'е? Откуда вы её возьмёте?
Да, согласен, как то интуитивно представил что создал объект, сделал add в список, а ссылка на объект у меня осталась. Отсюда и написал свой сценарий, но вы правы, дальше я что-то не додумал, с этой ссылкой в рамках списка уже ничего не сделать.
я просто пару раз на собеседованиях отвечал именно так на этот вопрос и «собеседователи» оба раза были сконфужены по той же причине)) С одной стороны — в исходном коде чётко видно, что список делится пополам и указатель начинает бежать до элемента либо с начала, либо с конца — в зависимости от того, что ближе.
В то же время, это ещё ничего не значит. Реально может выполяться немного другой код — бывают всякие alt-rt.jar, JIT-компиляторы и много всяких других технологий, которые где-то в глубине души могут хранить подобную ссылку.
В конце концов, имплементация от Оракла — не единственная. Любая другая имплементация может действительно кешировать имеющиеся промежуточные ссылки по какому-то алгоритму, и тогда описанное Вами будет работать. Но OracleJDK, судя по исходном коду, это не делает.
В то же время, это ещё ничего не значит. Реально может выполяться немного другой код — бывают всякие alt-rt.jar, JIT-компиляторы и много всяких других технологий, которые где-то в глубине души могут хранить подобную ссылку.
В конце концов, имплементация от Оракла — не единственная. Любая другая имплементация может действительно кешировать имеющиеся промежуточные ссылки по какому-то алгоритму, и тогда описанное Вами будет работать. Но OracleJDK, судя по исходном коду, это не делает.
Это очень правильное предложение. Рассматривать вставку/удаление элементов отдельно от поиска нужно именно потому, что эти операции имеют различную алгоритмическую сложность и характер этой сложности зависит от структуры данных. И не следует путать поиск с индексацией — получить доступ к элементу с уже известным индексом — не то же самое, что найти этот элемент. Вставить один элемент в связный список вы можете за константное время, в массив — за линейное. Тоже самое с удалением. Вставить одномоментно m последовательных элементов в список длины n вы сможете за константное время без копирования вставляемых элементов, за O(m) — с копированием. Проделать тоже самое с массивом вы сможете за O(n + m). Удалить m элементов из списка, если пренебречь работой сборщика мусора, вы можете за константное время. Из массива — за O(n — m + 1). Получить доступ к элементу по его индексу в списке вы можете за линейное время, в массиве — за константное. Выполнить поиск элемента в списке вы сможете за линейное время, в произвольном массиве — тоже за линейное, в отсортированном массиве — за логарифмическое, воспользовавшись бинарным поиском.
А как можно добавить m последовательных элементов в список за константное время? Или у вас уже эти m элементов «собраны» в другой список?
Я указал «без копирования». Без копирования это возможно, действительно, если элементы уже принадлежат другому списку. В STL C++ операция носит имя splice. Действительно, нужно было указать, что элементы принадлежат другому списку. Сорри.
Ах, простите, не все операции такого рода перечислил.
Доступ к элементу по указателю (ссылке, итератору) осуществляется одинаково быстро в случае обеих структур данных — за константное время.
Вы спросили, когда может понадобиться вставка/удаление элемента без его поиска. Отвечаю. На элемент коллекции некоторый иной объект может хранить указатель (ссылку, итератор), например с тем, чтобы иметь возможность его (этот элемент) удалить из коллекции в нужный момент. В этом случае, если предполагаемый размер коллекции достаточно велик, а необходима она только для того, чтобы была возможность периодически последовательно перебирать все элементы этой коллекции, лучшим выбором будет связный список, так как всего нам необходимы три вида операций — последовательный перебор элементов, доступ по указателю, удаление элемента. Первые две выполняются одинаково быстро и списком, и массивом, вторая значительно быстрее (O(1) против O(n)) выполняется связным списком. Условие на достаточно большой размер коллекции введено потому, что оценки сложности операций, выполняемых над списком, имеют большие константы по очевидным причинам.
Доступ к элементу по указателю (ссылке, итератору) осуществляется одинаково быстро в случае обеих структур данных — за константное время.
Вы спросили, когда может понадобиться вставка/удаление элемента без его поиска. Отвечаю. На элемент коллекции некоторый иной объект может хранить указатель (ссылку, итератор), например с тем, чтобы иметь возможность его (этот элемент) удалить из коллекции в нужный момент. В этом случае, если предполагаемый размер коллекции достаточно велик, а необходима она только для того, чтобы была возможность периодически последовательно перебирать все элементы этой коллекции, лучшим выбором будет связный список, так как всего нам необходимы три вида операций — последовательный перебор элементов, доступ по указателю, удаление элемента. Первые две выполняются одинаково быстро и списком, и массивом, вторая значительно быстрее (O(1) против O(n)) выполняется связным списком. Условие на достаточно большой размер коллекции введено потому, что оценки сложности операций, выполняемых над списком, имеют большие константы по очевидным причинам.
В
java.util.LinkedList нету метода «вставка/удаление элементов отдельно от поиска». Я рад, безусловно, что вы прочитали книжку Кормена, только вот топик не о том.LinkedList реализует интерфейс Iterable, так что вы можете хранить итератор на произвольную позицию в списке (итераторы в Java указывают не на сами элементы, как в STL C++, а на «промежутки» между ними). Итератор позволит вам удалить нужный элемент за константое время. Для справки.
Но чтобы итератор указывал на «нужный» элемент придется, перебрать несколько элементов. По этим перебором 23derevo и понимает «поиск».
Именно. Несколько — это O(N).
Я постарался повыше описать модель задачи, в которой этот поиск будет не нужен. Вы добавляете новый элемент в список, скажем, всякий раз в голову. Берете после этого от списка итератор. И передаете его тому объекту, которому этот итератор интересен. Когда такому объекту-владельцу понадобиться удалить этот элемент из списка, он сможет это сделать без поиска, несмотря на то, что к тому времени указуемый элемент не будет первым, вероятно. А будет непонятно где.
нифига не сможет. Вызов методов
В спеке это описано так:
Это именно — защита от того, что предлагаете Вы.
add и remove у LinkedList'ового listIteartor'а начинается с вызова замечательного метода checkForComodification().В спеке это описано так:
The list-iterator is fail-fast: if the list is structurally modified at any time after the Iterator is created, in any way except through the list-iterator's ownremoveoraddmethods, the list-iterator will throw aConcurrentModificationException.
Это именно — защита от того, что предлагаете Вы.
Да, в моём конкретном примере вы правы. Он неудачен, приводить примеры мне трудно, учитывая, что я работаю на C++ и ни одним глазом не Java-программист. C++ свободы предоставляет больше и позволяет использовать преимущества структур данных, жаль, что это происходит в Java реже. Уверен, тому есть причины (возможно, ограничения накладывает GC, возможно, особые взгляды Java на многопоточное программирование — не могу сказать). Но эти проблемы касаются только стандартных реализаций коллекций в Java. У ntz конкретные примеры получаются лучше, хотя мы оба преследуем одну и ту же цель — показать, что поиск элемента в коллекции, доступ к элементу по индексу, по указателю (не важно, как называется указатель в вашем языке программирования), удаление или вставка элемента — разные и отделимые друг от друга вещи. Если ваша конкретная задача не позволяет вам этого увидеть, это не значит, что завтра вы не столкнетесь с задачей, которая окажется чувствительнее к этим особенностям.
Вообще, в Java LinkedList очень даже можно вставлять и удалять элементы отдельно от их поиска.
Метод listIterator() вернет ListIterator, который поддерживает вставки и удаления элементов (add(T element) и remove() соответственно) в текущей позиции итератора, за константное время, естественно. При этом поиск позиции вставки / удаления является, очевидно, отдельной операцией.
Например, если мне надо вставить m элементов после элемента А в середине списка, я затрачу не O(mn) (если бы вставка была отделима от поиска), а O(n + m) (O(n) на поиск позиции для вставки, и O(m) на вставку всех m элементов).
Такие дела.
Метод listIterator() вернет ListIterator, который поддерживает вставки и удаления элементов (add(T element) и remove() соответственно) в текущей позиции итератора, за константное время, естественно. При этом поиск позиции вставки / удаления является, очевидно, отдельной операцией.
Например, если мне надо вставить m элементов после элемента А в середине списка, я затрачу не O(mn) (если бы вставка была отделима от поиска), а O(n + m) (O(n) на поиск позиции для вставки, и O(m) на вставку всех m элементов).
Такие дела.
Отвечаю по порядку:
1. listItertor'ом нужно дойти сначала до нужного места. А это O(N). Так что без поиска — не выйдет. Некоторый выигрыш можно получить, если все Ваши операции локализованы в каком-то куске. Тогда итерироваться туда-сюда действительно быстрее. Но в общем случае — шило на мыло.
2. Для вставки пачки элементов в середину списка есть
1. listItertor'ом нужно дойти сначала до нужного места. А это O(N). Так что без поиска — не выйдет. Некоторый выигрыш можно получить, если все Ваши операции локализованы в каком-то куске. Тогда итерироваться туда-сюда действительно быстрее. Но в общем случае — шило на мыло.
2. Для вставки пачки элементов в середину списка есть
addAll(int index, Collection<? extends E> c). Он тоже вполне себе за O(N+M) работает без всяких listIterator'ов.Существует отдельно операция поиска элемента и отдельно операция его удаления / вставки нового. Эти операции разные, и в разных ситуациях общая асимптотика времени будет отличаться от подхода в лоб «найти и вставить, повторить».
Пример, я согласен, привел не очень наглядный, вот лучше — проделать то же самое, но чередуя с элементами коллекции (т.е. вставить свой элемент, пропустить один существующий, вставить следующий свой элемент). Или другой пример — удалить m идущих подряд элементов, начиная с элемента A.
Пример, я согласен, привел не очень наглядный, вот лучше — проделать то же самое, но чередуя с элементами коллекции (т.е. вставить свой элемент, пропустить один существующий, вставить следующий свой элемент). Или другой пример — удалить m идущих подряд элементов, начиная с элемента A.
Да, операции разные. Да, в некоторых случаях
Это тоже элементарно сделать за O(N):
listIterator быстрее. Например, когда позиции локализованы.удалить m идущих подряд элементов, начиная с элемента A
Это тоже элементарно сделать за O(N):
list.sublist(0, n).addAll(list.sublist(m+n, N))
проделать то же самое, но чередуя с элементами коллекции (т.е. вставить свой элемент, пропустить один существующий, вставить следующий свой элемент)
не уверен, что понял Вас :) уточните, пожалуйста, этот сценарий.
Исходная коллекция: 1 2 3 4 5 6 7 8 9 — n элементов;
Вставляемые элементы: 10 11 12 — m элементов;
Хочу получить: 1 2 3 4 5 10 6 11 7 12 8 9.
Как это сделать за O(n+m) по вашему?
Я конечно предположу ваш ответ — взять кусок списка с 5 по 7, слить его со вставляемыми элементами, склеить кусок списка до 5 + полученный кусок + кусок списка после 7. Но нахрена так жить?
И почему же вы так боитесь итераторов?
Вставляемые элементы: 10 11 12 — m элементов;
Хочу получить: 1 2 3 4 5 10 6 11 7 12 8 9.
Как это сделать за O(n+m) по вашему?
Я конечно предположу ваш ответ — взять кусок списка с 5 по 7, слить его со вставляемыми элементами, склеить кусок списка до 5 + полученный кусок + кусок списка после 7. Но нахрена так жить?
И почему же вы так боитесь итераторов?
(меня тут жестоко минусуют, так что стану плюсовать людей, которые задают те же самые вопросы)
Итераторов никто не боится. Более того, в этом конкретном примере итератор очень даже подходит, потому что
1. позиции, в которые Вы хотите вставлять — локализованы (n, n+2, n+4, ...). Это подходящий юзкейс для итератора — я уже писал Вам об этом выше.
2. сама терминология, в которой Вы формулируете задачу («вставить свой элемент, пропустить один существующий, вставить следующий свой элемент») — это описание именно в терминах итератора (add, next, add, next). Так что ничего удивительного. Попробуйте ради интереса найти подобную задачу в реальной жизни.
1. позиции, в которые Вы хотите вставлять — локализованы (n, n+2, n+4, ...). Это подходящий юзкейс для итератора — я уже писал Вам об этом выше.
2. сама терминология, в которой Вы формулируете задачу («вставить свой элемент, пропустить один существующий, вставить следующий свой элемент») — это описание именно в терминах итератора (add, next, add, next). Так что ничего удивительного. Попробуйте ради интереса найти подобную задачу в реальной жизни.
То вы отрицаете всякую необходимость раздельных операций поиска и вставки, то отрицаете существование таких раздельных операций в Java, то вам задачи не те. Да, не всегда в ваших способах асимптотика выше, но остается множество совершенно лишних операций типа создания объектов, копирования списков и так далее.
Удалите все четные элементы in-place.
Удалите все четные элементы in-place.
Удалите все четные элементы in-place.
Тут вполне хватит простого итератора, да :)
Только вот in-place непонятно зачем. Зачем такое требование? Портить данные, переданные неизвестно откуда. Есть риск что-то где-то поломать. А вот при копировании — риска нету. Поэтому обычный foreach с добавлением в конец каждого второго элемента в новый список выглядит безопаснее. А с учётом того, что длина известна заранее (N/2) то непонятно, почему не ArrayList.
О боже, тихий ужас. А каком джуниорстве вы говорите? Я бы забивал камнями любого осмелившегося назваться «программистом», но при этом оставившего без верного ответа более одного вопроса (его даже можно назвать — число корзин в хеш-таблице на момент ее создания — какая разница, для начала? Идиотский вопрос. Сегодня их там 16, в следующей версии Java станет 12 или 20 — это не имеет никакого значения абсолютно). Обратите внимание, я говорю — «программистом», а не «Java-программистом». Чтобы ответить на все вопросы не нужно даже знать о существовании Java — вся необходимая информация полностью раскрывается названиями классов. Есть такая замечательная книга: «Кормен Т., Лейзерсон Ч., Ривест Р. — Алгоритмы. Построение и анализ». Из вашей статьи только и можно сделать вывод, что открывали ее исключительно ребята с гордым именем «senior developer» и тремя годами опыта работы. Куда катится мир. Куда катится хабр. Только и прочесть теперь можно, что про бизнес, сделанный на адаптерах для сим-карт. Крайне увлекательно.
Нет, серьезно. Я крайне советую найти эту книгу и заставить себя изучить хотя бы избранные главы. Если кто-то заинтересуется, какие именно нужны для понимания работы коллекций — спрашивайте, потружусь перечислить. И да: лучше читать не самое современное издание, если вам нужен русский язык, а второе, в переводе замечательной организации МЦНМО
Я в свою очередь крайне рекомендую, скинуть спесь и пафос, выглядит плохо это все. Да приведенная книжка это классика, ее стоит изучить, но к чему закатывать глаза и артистично говорить «О, Боже, как темны все эти люди на хабре. Я еще читать не умел, но мог ответить на все эти вопросы». Утрирую конечно, но общий смысл Ваших комментариев таков. Сорри, что так эмоционально.
Я лишь искренне (и да, очень эмоционально, уж простите) расстроен, что подобные вопросы вызвали затруднение у «крепких середнячков» индустрии, а не у студентов первого семестра технического ВУЗа, что «лидеры рынка», интервьюируя человека с опытом работы, претендующего на должность а ля «Java разработчик» валят его на таких вопросах, до Java-то не успевая добраться. Понимаете, у человека, который хотя бы коснулся программ технического ВУЗа, очно ли, самостоятельно ли, не возникнет вопросов, в какой литературе подобную информацию искать, равно как не возникнет сомнений в том, что это надо знать. Так что такую статью все бы мы приняли разве что от школьника, который самостоятельно, без поддержки незаинтересованных в нем, как это почти всегда бывает, преподавателей пытается разобраться в чём-то для него безусловно непростом. А в таком формате это лишь вызывает изумление всё.
Ох, как вы тонко троллите меня, называя «школьником». Скажите, а что Вы заканчивали, что у Вас для «студентов первого семестра технического ВУЗа» сходу раскрывают довольно неплохо структуры данных?:) Мне, к сожалению, не повезло, я закончил самый обычный уездный технический ВУЗ, где на первом семестре преподавали Delphi с кучей общеобразовательных предметов до комплекта. Уж извините, реалии современной России таковы: в большинстве ВУЗов страны все так печально, что 100% выпускников по Вашей классификации ни на что не годятся, кроме как работать грузчиками.
Неплохо раскрывают структуры данных? Квадртатики, связанные стрелочками (связный список), и расчерченную на клеточки полосу (массив) на доске нам нарисовали на второй паре практики по информатике (практике по программированию), потому что на первой прошло что-то вроде тестирования — кто, откуда, чем раньше занимался. В группу я попал самую обычную, и впоследствии мы алгоритмам уделяли мало внимания. Даже очень мало. Больше преподаватель акцентировался на кратеньком введении в C++ (функции, модули), на стиле кодирования, Фредерика Брукса нам посоветовал прочесть (его «Мифический человеко-месяц»). Рассказал кратенько о водопадной модели разработки, agile-ах — и тому подобных вещах. В начале второго семестра — о системах контроля версий (мы дружно переехали со своими домашками на github), о модульном тестировании и прочем. А на теории, на лекциях, все это время шла низкосортная ерунда про синтаксис паскаля. Мало кто ходил на эти лекции. А, про обычную группу. Действительно хорошо структуры данных и алгоритмы раскрывали одной необычной группе, из которой потом подразумевалось набирать ACM-спорстменов. Вот эти ребята действительно разбираются в таких вопросах. И я не закончил учёбу. Я учусь на втором курсе. Мат-Мех СПбГУ. Кучи общеобразовательных у нас нет, у нас есть куча математик. Которые пытаются отнимать почти все время, на деле отнимают лишь большую часть. Все же стараемся заниматься побольше по специальности. Хоть и самостоятельно преимущественно.
Начнем с того, что все это происходит в вузах, которые можно конкретно пересчитать на пальцах одной руки — ВМК МГУ, МФТИ, СПбГУ, ИТМО, матмех УрФУ (который был УрГУ). Я мог что-то упустить, но во всех остальных даже и близко (т.е. хоть-сколько-нибудь-близко) ничего подобного нет. Ну вот нет и все. Грустно, да.
Ну в моем вузе все-таки это было. Не скажу что в «полном» объеме, но все же Кнута почитывали. И кстате, не пойму почему Кормен стал таким популярным в ВУЗах теперь, а также начал считаться уже классикой. По-видимому из-за очень сжатого изложения.
Ого. Кнута нам только посоветовали. Не более того. Для первых курсов это слишком сложная литература по нашим меркам. Как называются ваши ВУЗ и факультет?
ВУЗ у меня довольно посредственный (не то что СПбГУ) — СГТУ. Факультет Электронной техники и приборостроения, специальность «Программирование вычислительных машин». Но в то время работали очень хорошие преподаватели. Сумели, кому надо было, научить и алгоритмам и промышленному программированию. Сейчас, насколько я знаю, старая школа почти развалилась, лучшие преподы уволились.
Впрочем, я уже остыл, за такую длительную беседу, и готов принести извинения за излишнюю резкость. При первом прочтении статья оставила очень сильные впечатления, потому я так и отреагировал.
Вызывает уважение такое высказывание в конце спора.
На самом деле, вы просто плохо осведомлены о рынке труда программистов вообще и в нашей стране в частности. Безусловно, знание лучше незнания, и где-то и кому-то даже ваши свежепрочитанные знания пригодятся, но не хочу вас расстраивать — это очень и очень узкий круг компаний. В 95% случаев подобное банально не нужно от сотрудника (а иногда даже и вредно для компании — возомнит себя спецом и начнет бабла требовать, а выгоды от этих знаний — никаких), так и живет индустрия.
И, опять же, разработка не на одних алгоритмах зиждется — очень часто важны умения грамотно проектировать систему и разрабатывать сложные архитектурные решения, потому не стоит так однобоко относиться к саморазвитию — можно неожиданно оказаться полным профаном в разработке реального софта.
И, опять же, разработка не на одних алгоритмах зиждется — очень часто важны умения грамотно проектировать систему и разрабатывать сложные архитектурные решения, потому не стоит так однобоко относиться к саморазвитию — можно неожиданно оказаться полным профаном в разработке реального софта.
Я знаю, что разработка не на одних алгоритмах зиждется. Это знает и мой преподаватель — я уже отметил, что мы почти не занимаемся алгоритмами. А пишем семестровые проекты (кто UML-диаграммы с рукописных рисунков распознает, кто обучает нейронные сети распознавать пол человека по фотографиям, кто ломает голову, как автоматизировать процесс проверки соблюдения правил code style'ов (styleguide'ов) в проектах на C++, мучая Clang), да зачёты по паттернам проектирования сдаём. Не сомневаюсь, что большинству работодателей нужна недорогая рабочая сила, хотя бы потому, что несложных, рутинных задач в индустрии больше, чем содержательных. Но самые первые строки статьи я понял так, что автор не мечтает оставаться такой вот рабочей силой. И кто вам сказал об однобокости? Если б я изложил что-то очень нетривильное из теории алгоритмов, можно было бы заподозрить однобокость. А я до сих пор говорил какие-то совершенно банальные вещи. Опыт работы у меня есть, я знаю, что технический директор компании, не первый месяц пытающейся побороть неудовлетворяющую клиента тормознутость своего продукта, выполняющего преимущественно поиск, может впервые от меня, стажёра — первокурсника, услышать, что такое бинарные деревья поиска вообще и красно-чёрные деревья в частности. И одновременно я знаю, что компания, позволяющая себе офис на пересечении канала Грибоедова и Невского проспекта, по-прежнему пользуется CVS, а то и вовсе хранит код в БД или даже на дисках в папочках. Это не значит, что всё так и должно оставаться, а вам не надо понимать, что это — не лучшее, что могло бы быть.
Вообще говоря, ситуация с Computer Science в России очень плохая. Даже на матмехе приходится прикладывать сильные усилия, чтобы что-то узнать. Так что ваши расстройства понятны.
И, как уже отметили ниже, далеко не всегда на работе требуются подобные знания.
Обычно нужно уметь быстро написать что-то, что будет выглядеть как работающий код (и не важно, приложение это или сайт).
PS: Матмех лучше всех.
Рекомендую открытый ещё yurylifshits семинар в ПОМИ с названием Computer Science — он периодически мелькает в статьях на Хабре.
Когда я заканчивал ММ, его принял под руководство alexanderskulikov, но что с ним стало сейчас, я не в курсе.
И, как уже отметили ниже, далеко не всегда на работе требуются подобные знания.
Обычно нужно уметь быстро написать что-то, что будет выглядеть как работающий код (и не важно, приложение это или сайт).
PS: Матмех лучше всех.
Рекомендую открытый ещё yurylifshits семинар в ПОМИ с названием Computer Science — он периодически мелькает в статьях на Хабре.
Когда я заканчивал ММ, его принял под руководство alexanderskulikov, но что с ним стало сейчас, я не в курсе.
Я не принимал. =)
Но мы всё же как-то пытаемся улучшать ситуацию с CS в Питере и России:
compscicenter.ru/
compsciclub.ru/
logic.pdmi.ras.ru/~csr/
Но мы всё же как-то пытаемся улучшать ситуацию с CS в Питере и России:
compscicenter.ru/
compsciclub.ru/
logic.pdmi.ras.ru/~csr/
CS-клуб при ПОМИ живет, здравствует, радует своими лекциями, материалами, гостями — спасибо ему за то, что он делает.
И тем не менее, даже самую обычную группу у вас пытаются держать более-менее в курсе текущих вещей, у меня про agile не было ни слова, про системы контроля версий тоже. Был синтаксис си, паскаля, java, немного о структурах данных, lisp и prolog, asm, а так же занимательная веселуха с БД FoxPro (просто препод его когда изучил и требовла от нас курсачи на нем). Это за 5 лет. Вы учитесь в ведущем ВУЗе страны, с богатой историй и группами для спортивного программирования. Цените то, что у Вас есть, но не зарывайтесь: многим остается только мечтать об учебе в подобном ВУЗе и эти многие не глупее, просто по тем или иным причинам не могут это осуществить. Опять же реалии нашей страны.
В МЦНМО издавали русский перевод первого издания, насколько я помню.
А что бы вы спросили на собеседовании на джуниора?
Минуточку. Автор говорит о том, что уже прошел этап джуниорства и претендовал на место у «лидера рынка» не джуниором. У джуниора такие вещи можно спрашивать и нужно. Так как наверняка у работодателя будут сущестовать определенные планы на кандидата, следует в довесок спросить что-нибудь специальное. Кандидату нужно будет работать с сетью? Спросите его что-нибудь из этой области. С графическими интерфейсами? Спросите оттуда. И так далее. Неплохие рекомендации по проведению собеседований можно найти у Джоуэла Спольски, «Джоуэл о программировании». Хорошая книга, много полезного в ней можно почерпнуть.
И сам себе я не противоречу. У джуниора можно все это спросить. У джуниора нельза на это все получить неверные или неполные ответы — иначе это не джуниор. Джуниор должен все это прекрасно знать — и знать еще чуть-чуть (см. выше). Он не знает чего-то более сложного, и, главный момент, имеет очень небольшой опыт работы в реальных коммерческих проектах — либо не имеет такого опыта вовсе.
Интересно. Вероятно, меня нельзя назвать программистом — я не могу ответить даже на половину этих вопросов. В большинстве случаев ответ «а какая разница»?
Я понятия не имею, как ArrayList устроен внутри. Судя по названию, это нечто с интерфейсом списка, как-то использующее в реализации массивы. Возможно, весь список помещен в один массив. Возможно, массив разрезан на кусочки, организованные в виде списка или дерева. Это слегка замедлит доступ, слегка ускорит удаление и расширение, уменьшит требования к памяти. И позволит не хранить куски, заполненные null-ами. Как поступили авторы, мне не известно. И пока в интерфейсе не появится метода вроде unsafe object* GetRawArray() (или IntPtr GetRawArray), я не вижу причины как-то закладываться на его структуру или изучать подробности — достаточно знать, что вставка или удаление могут занять какое-то время, а доступ по индексу — более-менее быстрые.
HashMap? Наверное, сегодня и в этом языке эта структура называется так. В другое время и в других местах она называлась map, Hashtable, Dictionary<>, и т.д. Как устроена? А какая разница? Может быть, это вёдра со списками (внешнее разрешение коллизий). Может быть, один массив — с внутренним разрешением. Может быть, какой-то их гибрид. Из всего обсуждения важным мне показалось только, что нельзя менять элемент, который используется в качестве ключа (если это изменение повлияет на результаты сравнения).
Что касается прямой работы с элеменами списков, вставкой элемента за единичное время и т.п. — опять же, здесь и сейчас это может быть такой интерфейс. Если для указателя внутрь списка решили использовать итераторы — пожму плечами: по-моему, модификация объекта — не из функционала итератора. Хотя использовать ListNode для этих целей еще хуже: он был бы слишком завязан на структуру списка. Но называть «указатель внутри списка» итератором… слегка запутывает.
Но в любом случае, помнить, как бибиотечные стуктуры реализовано здесь и сейчас, по-моему, смысла нет — пять лет назад классы и функции были слегка другими, и через пять лет они тоже могут измениться. Главное, знать, что при необходимости можно найти то, что надо.
Если зачем-то нужны детали реализации структуры, то лучше реализовать её самому. Потому что библиотечная реализация может измениться без предупреждения.
С другой стороны, мне регулярно требуются такие структуры, как приоритетная очередь (в которой «добавить элемент» и «взять наименьший элемент» выполняются за log(N)) и динамический массив фиксированного типа. Я иногда вспоминаю, что изобретать велосипеды сейчас не модно, иду искать эти объекты в стандартной библиотеке, ругаюсь на в очередной раз потраченные 20 минут, и достаю какую-нибудь свою реализацию.
Я понятия не имею, как ArrayList устроен внутри. Судя по названию, это нечто с интерфейсом списка, как-то использующее в реализации массивы. Возможно, весь список помещен в один массив. Возможно, массив разрезан на кусочки, организованные в виде списка или дерева. Это слегка замедлит доступ, слегка ускорит удаление и расширение, уменьшит требования к памяти. И позволит не хранить куски, заполненные null-ами. Как поступили авторы, мне не известно. И пока в интерфейсе не появится метода вроде unsafe object* GetRawArray() (или IntPtr GetRawArray), я не вижу причины как-то закладываться на его структуру или изучать подробности — достаточно знать, что вставка или удаление могут занять какое-то время, а доступ по индексу — более-менее быстрые.
HashMap? Наверное, сегодня и в этом языке эта структура называется так. В другое время и в других местах она называлась map, Hashtable, Dictionary<>, и т.д. Как устроена? А какая разница? Может быть, это вёдра со списками (внешнее разрешение коллизий). Может быть, один массив — с внутренним разрешением. Может быть, какой-то их гибрид. Из всего обсуждения важным мне показалось только, что нельзя менять элемент, который используется в качестве ключа (если это изменение повлияет на результаты сравнения).
Что касается прямой работы с элеменами списков, вставкой элемента за единичное время и т.п. — опять же, здесь и сейчас это может быть такой интерфейс. Если для указателя внутрь списка решили использовать итераторы — пожму плечами: по-моему, модификация объекта — не из функционала итератора. Хотя использовать ListNode для этих целей еще хуже: он был бы слишком завязан на структуру списка. Но называть «указатель внутри списка» итератором… слегка запутывает.
Но в любом случае, помнить, как бибиотечные стуктуры реализовано здесь и сейчас, по-моему, смысла нет — пять лет назад классы и функции были слегка другими, и через пять лет они тоже могут измениться. Главное, знать, что при необходимости можно найти то, что надо.
Если зачем-то нужны детали реализации структуры, то лучше реализовать её самому. Потому что библиотечная реализация может измениться без предупреждения.
С другой стороны, мне регулярно требуются такие структуры, как приоритетная очередь (в которой «добавить элемент» и «взять наименьший элемент» выполняются за log(N)) и динамический массив фиксированного типа. Я иногда вспоминаю, что изобретать велосипеды сейчас не модно, иду искать эти объекты в стандартной библиотеке, ругаюсь на в очередной раз потраченные 20 минут, и достаю какую-нибудь свою реализацию.
Если я вас правильно понял, вы говорили, стараясь не очень привязываться к Java. Буду дальше исходить из этого предположения.
Да, библиотечные реализации могут измениться. Ничего не могу сказать про Java, но про C++ можно утверждать — могут измениться лишь тонкие детали реализации. Но алгоритмическую сложность всех или почти всех операций фиксирует стандарт языка, и создатели стандартных библиотек, по крайней мере тех, что поставляются вместе с распространенными компиляторами, их придерживаются. Фиксируется в достаточной мере стандартом и интерфейс классов библиотеки. Так случается, что зафиксировав интерфейс коллекции и алгоритмическую сложность её методов, вы почти всегда остаётесь один на один с одной какой-то реализацией без особых альтернатив — не придумать вам реализацию абстракции множества с требованием поиска элемента за константное время в среднем случае на бинарном дереве поиска. Ну вот никак.
Посему довольно удобно поступить обратным способом. Не запоминать сложности методов существующих коллекций, а запоминать принципы их устройства — их, принципов, много меньше произведения «число методов» x «число коллекций». А из принципов устройства автоматически следуют все сложности. Да и такой подход более структурирован и позволяет легче и проще выбирать подходящую коллекцию. Делать это осмысленно.
Зачем запоминать что-либо, когда всегда можно посмотреть в документации? А как мыслить в таком случае, как придумывать алгоритм? Вместо того, чтобы мгновенно понять, что вам больше всего подходит, пойти читать доки одну за другой? Да ради бога. Раз прочтете, два прочтете — да и выучите. А раз еще не выучили, значит, не читали, не интересовались, значит, неосознанно подходили к выбору коллекции. Никогда это еще не мешало? Значит, не сталкивались еще с задачами, когда скорость работы была важна. Конечному пользователю, не вам. Но ведь это не правда, ведь так? У вас есть свои реализации нетривильных вещей, вы сказали, что вам была необходима очередь с приоритетами с хорошей скоростью работы. Были такие задачи. Тогда я не совсем понимаю, почему вам без разницы, чем вы пользуетесь.
В STL С++ вы можете сымитировать очередь с приоритетами на std::vector с помощью свободных функций std::make_heap, std::push_heap, std::pop_heap. Сложность O(n), O(log(n)), O(log(n)) соответственно.
В том, что нет особой разницы, использует хеш-таблица HashMap открытое хеширование или закрытое, а TreeMap является красно-черным деревом или AVL-деревом, я с вами полностью соглашусь. Хотя не знать точно странно.
Да, библиотечные реализации могут измениться. Ничего не могу сказать про Java, но про C++ можно утверждать — могут измениться лишь тонкие детали реализации. Но алгоритмическую сложность всех или почти всех операций фиксирует стандарт языка, и создатели стандартных библиотек, по крайней мере тех, что поставляются вместе с распространенными компиляторами, их придерживаются. Фиксируется в достаточной мере стандартом и интерфейс классов библиотеки. Так случается, что зафиксировав интерфейс коллекции и алгоритмическую сложность её методов, вы почти всегда остаётесь один на один с одной какой-то реализацией без особых альтернатив — не придумать вам реализацию абстракции множества с требованием поиска элемента за константное время в среднем случае на бинарном дереве поиска. Ну вот никак.
Посему довольно удобно поступить обратным способом. Не запоминать сложности методов существующих коллекций, а запоминать принципы их устройства — их, принципов, много меньше произведения «число методов» x «число коллекций». А из принципов устройства автоматически следуют все сложности. Да и такой подход более структурирован и позволяет легче и проще выбирать подходящую коллекцию. Делать это осмысленно.
Зачем запоминать что-либо, когда всегда можно посмотреть в документации? А как мыслить в таком случае, как придумывать алгоритм? Вместо того, чтобы мгновенно понять, что вам больше всего подходит, пойти читать доки одну за другой? Да ради бога. Раз прочтете, два прочтете — да и выучите. А раз еще не выучили, значит, не читали, не интересовались, значит, неосознанно подходили к выбору коллекции. Никогда это еще не мешало? Значит, не сталкивались еще с задачами, когда скорость работы была важна. Конечному пользователю, не вам. Но ведь это не правда, ведь так? У вас есть свои реализации нетривильных вещей, вы сказали, что вам была необходима очередь с приоритетами с хорошей скоростью работы. Были такие задачи. Тогда я не совсем понимаю, почему вам без разницы, чем вы пользуетесь.
В STL С++ вы можете сымитировать очередь с приоритетами на std::vector с помощью свободных функций std::make_heap, std::push_heap, std::pop_heap. Сложность O(n), O(log(n)), O(log(n)) соответственно.
В том, что нет особой разницы, использует хеш-таблица HashMap открытое хеширование или закрытое, а TreeMap является красно-черным деревом или AVL-деревом, я с вами полностью соглашусь. Хотя не знать точно странно.
Начнем с того, что это Вы сказали — «я говорю — «программистом», а не «Java-программистом».». И Ваш пост я прочитал, как «тот, кто не знает подробностей реализации библиотеки Java образца 2012 года (о которых, собственно, шла речь в исходной статье), не может осмелиться назвать себя программистом».
Каюсь, стандарта C++ я не читал. Да и не пользуюсь этим языком уже лет 10. Но неужели в нём в самом деле прописаны сложности операций коллекций, реализованных в библиотеках? Было бы очень странно. В стандарт могли бы войти реализации тех операций, без которых не будет компилироваться программа (вроде operator new), но включать туда какой-нибудь stl??? Не понимаю.
Сложность операций понять и запомнить можно. С различными возможными вариантами реализаций и плюсами и минусами каждого из них. Но как это поможет определить стратегию роста размера HashMap или ArrayList? Во сколько раз увеличивается размер того же ArrayList — в два? в полтора? Или в 1.32 раза, что может дать заметные преимущества перед другими стратегиями?
Как мыслить, придыувая алгоритм… Сначала понять задачу, подобрать нужные структуры (сложность и реализация которых вам известны). Потом, вероятно, полезть в документацию, посмотреть, реализованы ли нужные структуры в стандартных библиотеках. Если реализованы — типизированы ли они (создавать ArrayList из int-ов я буду только если меня совсем не волнует производительность). Если нет — подумать, доверяете ли вы (или ваш начальник) сторонним библиотекам, или предпочтете реализовывать самостоятельно. Если не верите, что можете хорошо реализовать — то нет ли чуть менее подходящей, но стандартной библиотеки… и далее, пока процесс не сойдется. И в критических случаях всё равно придётся проверить скорость стандартной реализации и сравнить её с самодельной.
Каюсь, стандарта C++ я не читал. Да и не пользуюсь этим языком уже лет 10. Но неужели в нём в самом деле прописаны сложности операций коллекций, реализованных в библиотеках? Было бы очень странно. В стандарт могли бы войти реализации тех операций, без которых не будет компилироваться программа (вроде operator new), но включать туда какой-нибудь stl??? Не понимаю.
Сложность операций понять и запомнить можно. С различными возможными вариантами реализаций и плюсами и минусами каждого из них. Но как это поможет определить стратегию роста размера HashMap или ArrayList? Во сколько раз увеличивается размер того же ArrayList — в два? в полтора? Или в 1.32 раза, что может дать заметные преимущества перед другими стратегиями?
Как мыслить, придыувая алгоритм… Сначала понять задачу, подобрать нужные структуры (сложность и реализация которых вам известны). Потом, вероятно, полезть в документацию, посмотреть, реализованы ли нужные структуры в стандартных библиотеках. Если реализованы — типизированы ли они (создавать ArrayList из int-ов я буду только если меня совсем не волнует производительность). Если нет — подумать, доверяете ли вы (или ваш начальник) сторонним библиотекам, или предпочтете реализовывать самостоятельно. Если не верите, что можете хорошо реализовать — то нет ли чуть менее подходящей, но стандартной библиотеки… и далее, пока процесс не сойдется. И в критических случаях всё равно придётся проверить скорость стандартной реализации и сравнить её с самодельной.
Начнем с того, что это Вы сказали — «я говорю — «программистом», а не «Java-программистом».». И Ваш пост я прочитал, как «тот, кто не знает подробностей реализации библиотеки Java образца 2012 года (о которых, собственно, шла речь в исходной статье), не может осмелиться назвать себя программистом».
Эмм… Извините, утверждая процитированное вами и «Чтобы ответить на все вопросы не нужно даже знать о существовании Java — вся необходимая информация полностью раскрывается названиями классов.» я стремился акценты расставить прямо противоположным образом. То есть, не только версия Java не важна в данном случае, не важно, что это Java. Хеш-таблица как структура данных всегда имеет определенное устройство, будь она в Java, C++, C#, Python etc. (захотите свой собственный язык создать и добавить в его стандартную библиотеку абстракцию «ассоциативный массив» — построите или самобалансирующееся бинарное дерево поиска, или хеш-таблицу и устроены он у вас будут каноническим образом, как в классической литературе описано. Иначе работать будут или медленее, или неправильно, или и то, и другое сразу)
А мне наоборот очень удивительно, что вас изумляет существование строгого стандарта языка, на котором пишется крайне много вещей, в том числе таких, от скорости работы которых могут зависеть человеские жизни. Разумеется сложность операций ограничена сверху! Разработчик должен быть уверен, что та или иная операция не займет слишком много времени. Посмотрите у Мейерса («Эффективное использование c++»), какие сложности вызвал метод std::list<T>::splice, который позволяет перемещать отрезки списков за константное время (кстати, сама причина существования этого метода в том, что можно гарантировать выполнение такой операции («врезки» отрезка списка из источника, в котором этот отрезок исчезает, в список-назначение) за константное время). Сложность оказалась в реализации std::list<T>::size(). Все остальные контейнеры STL гарантируют константую сложность этого метода. Как такое сделать для списков со splice? Ведь такая гарантия вынуждает хранить текущий размер (вот пример однозначного отображения требований в детали реализации) в самом списке. А если в него осуществили врезку (splice) отрезка другого списка? Сколько прибавить к хранимому размеру? Столько, каков размер врезки? Ну это чудесно, вот только подсчитать этот размер можно только за линейное от размера врезки время. Зачем стандарту давать такие гарантии на ::size() вот вообще в принципе? Пусть вы написали
for(size_t i = 0; i < something.size(); ++i) {
/* blah-blah */
}Если ::size() работает за O(1), а в теле цикла происходит что-то, имеющее сложность O(1), то такой цикл имеет сложность O(n), где n — размер something. Если, скажем, ::size() работает за линейное время, то сложность этого цикла — O(n^2). Пусть вы считали, что верно первое. Написали такой код. Пустили в продакшн. Тут вдруг сменили авторы библиотек реализацию так, что изменилась сложность (ведь вы говорите, что ее не нужно стандартизировать), цикл стал квадратичным. Ваша программа замедлилась в n раз в общем случае. Положим, n = 100000000000. Ой.
Более того. Почему до стандарта 2011 года в стандартной библиотеке сущестовала толко одна реализация абстракции «ассоциативный массив», это был std::map(), реализованный на красно-черном дереве, а не на в общем случае быстрее (O(log(n)) против O(1)) выполняющей поиск хеш-таблице? А всё потому же. Красно-черное дерево гарантирует, что операция поиска пройдет за O(log(n)), а хеш-таблица только обещает O(1), но предупреждает: может получиться O(n).
Но как это поможет определить стратегию роста размера HashMap или ArrayList? Во сколько раз увеличивается размер того же ArrayList — в два? в полтора? Или в 1.32 раза
Я вас не понимаю. То вам асимптотика не важна, то стала жутко важной константа в асимптотике. Странно.
Потом, вероятно, полезть в документацию, посмотреть, реализованы ли нужные структуры в стандартных библиотеках
Лезть в документацию выяснять, есть ли в стандартной библиотеке связный список или массив? Вы вчера вечером программиравать начали? Это знать надо.
создавать ArrayList из int-ов я буду только если меня совсем не волнует производительность
Снова вам стала важна константа в асимтотике. Так важна вам скорость работы используемых коллекций или не важна?
Если нет — подумать, доверяете ли вы (или ваш начальник) сторонним библиотекам, или предпочтете реализовывать самостоятельно.
Вы в себе уверены больше, чем в создателях стандартной библиотеки? Кто же вы? (благоговейный трепет)
И в критических случаях всё равно придётся проверить скорость стандартной реализации и сравнить её с самодельной.
Вот чтобы таким не заниматься, и существуют стандарты языка. И ради того же существуют прекрасные стандартные реализации, которые вы не обгоните. Скажите честно, вы действительно предлагаете не знать устройства стандартных контейнеров одновременно с предложением сомневаться в них и по большей части реализовывать такие вещи, как массив, список, множество, ассоциативный массив — самостоятельно? И что, вы реально этим на работе занимаетесь? И вам за это платят?
Пока в активную разработку эта задача не пошла, но когда пойдёт — придётся разбираться, что там со скоростью, и какими алгоритмами пользоваться.
Хотите обогнать что? C#-шарповскую стандартную сортировку (на парах uint, ulong)? Офигеть. Удачи. Очень вас прошу, поделиться с общественностью результатом. Чем воспользуетесь? Самописный QuickSort? Самодельный TeamSort? Или попробуете сделать CountingSort (при ширине диапазона 2^96)? А как будете реализовывать? На самом шарпе, или на C/C++, а на шарпе только обёртку сделаете?
Я уж и не пытаюсь говорить, что используя стандартные реализации, вы упрощаете жизнь не только себе (а в конечном счете, своим пользователям, которые получат более надежный продукт), но и тем, кому ваш код впоследствии придется поддерживать и развивать. Ведь если человек не с гор спустился, он знает, как работают стандартные контейнеры, и увидев код, их использующий, поймет, что происходит. А быть уверенным в самописных контейнерах ему вряд ли удастся, придется заглядывать в их реализации — и объем кода, который нужно понимать и поддерживать, значительно увеличится. Люди поумнее нас с вами уж устали советовать, например, «используйте стандартные алгоритмы (типа std::copy), старайтесь по минимуму строить самописные циклы» (циклы!), а мы тут с вами всерьез обсуждаем, писать ли целые велосипеды, «доверять» ли стандартной библиотеке.
В конечном счёте, кто что пытается доказать. Я — что надо знать, надо уметь. Остальная публика так или иначе — что знать не надо. Да ради бога. У меня на собеседованиях в нормальные фирмы конкурентов меньше будет.
В конечном счёте, кто что пытается доказать. Я — что надо знать, надо уметь. Остальная публика так или иначе — что знать не надо. Да ради бога. У меня на собеседованиях в нормальные фирмы конкурентов меньше будет.
То есть, не только версия Java не важна в данном случае, не важно, что это Java. Хеш-таблица как структура данных всегда имеет определенное устройство, будь она в Java, C++, C#, Python etc.
Сами же пишете, что «В том, что нет особой разницы, использует хеш-таблица HashMap открытое хеширование или закрытое, а TreeMap является красно-черным деревом или AVL-деревом, я с вами полностью соглашусь». И хеш-таблица, и сбалансированное дерево имеют несколько возможных реализий. И когда человеку задают прямой вопрос «как устроен класс TreeSet», ему (если он не знает точного ответа для этой библиотеки) придётся говорить что-то вроде «ну… это какое-то сбалансированное упорядоченное дерево… Может быть, красно-черное, может быть, AVL. А могли и декартово туда вставить, хотя это вряд ли...» Вы это засчитаете за ответ? Или скажете «не смог ответить на второй вопрос — значит, не программист»? И засчитает ли этот ответ тот, кто проводит собеседование?
То же и с другими вопросами. Это вопросы не на «какие бывают реализации», а «что есть в этой библиотеке».
А мне наоборот очень удивительно, что вас изумляет существование строгого стандарта языка, на котором пишется крайне много вещей, в том числе таких, от скорости работы которых могут зависеть человеские жизни. Разумеется сложность операций ограничена сверху!
Я понимаю, что существует строгий стандарт языка. Я понимаю, что существует документация по библиотеке, указывающая среднюю и максимальную сложность каждой операции над своими структурами данных. Но я не понимаю, почему второе должно входить в первое. Библиотека — не часть языка. Она от языка, конечно, иногда зависит, но язык от неё — нет.
Я вас не понимаю. То вам асимптотика не важна, то стала жутко важной константа в асимптотике. Странно
Мне-то всё равно (а когда будет не всё равно — разберусь). Но если на интервью спросят «как растёт ArrayList?» — опять придётся угадывать?
Лезть в документацию выяснять, есть ли в стандартной библиотеке связный список или массив? Вы вчера вечером программиравать начали? Это знать надо.
Библиотека имеет свойство развиваться. В 2003-м я не нашел в C# библиотеке метода Array.Resize — он там появился позже, с выходом .NET 2.0 А мне и в голову не пришло искать его снова и снова, приходилось удлиннять массивы вручную. Теперь буду знать, что он есть.
Приоритетную очередь я снова не нашел (даже в .NET 4.5). Либо она называется так, что я не могу её опознать, либо в библиотеку её опять не включили. Так что в будущем снова придётся «лезть в документацию выяснять...»
Односвязный список с возможностью указателя «внутрь», позволяющего модифицировать список. Или хотя бы эквивалент Java-ского ListIterator. Не знаю, есть ли в библиотеке. Тоже придётся лезть в документацию проверять.
Снова вам стала важна константа в асимтотике. Так важна вам скорость работы используемых коллекций или не важна?
Я же написал — «создавать не буду». Так что в данном случае коллекцию трудно назвать используемой. Но здесь меня больше волнует даже не скорость, а память. Впрочем, и в скорости я предполагаю, что ArrayList(int) дал бы потерю на порядок, а это может оказаться важным.
Вы в себе уверены больше, чем в создателях стандартной библиотеки?
Здесь речь шла не о стандартной библиотеке, а о библиотеках, написанных «третьими лицами». И я совсем не уверен, что они будут поддерживать и развивать библиотеку столько, сколько это нужно нам. За 13 лет существования проекта мы уже несколько раз обожглись на этом. И одной из таких библиотек (которую мы пока терпим), оказался микрософтовский DirectX, у которого в какой-то момент не обнаружилось 64-битной Managed версии. Говорят, позже она появилсь, придётся ещё с этм разбраться.
Кто же вы?
Человек, который решает определенные задачи. И видит применимость или неприменимость стандартных библиотек к конкретным случаям. И возможные потери от использования этих библиотек в ситуациях, на которые они не были рассчитаны.
Хотите обогнать что? C#-шарповскую стандартную сортировку (на парах uint, ulong)? Офигеть. Удачи.
Спасибо. После того, как моя самописная сортировка целых чисел (на C++) обогнала std::sort (немного — на 5-15%, подробности здесь), я, по крайней мере, надеюсь на успех. Чем буду пользоваться, пока не знаю, но алгоритм наверняка будетучитывать специфику данных и их происхождение. Скорее всего, на C#, но с использованием unsafe mode.
Вы это засчитаете за ответ? Или скажете «не смог ответить на второй вопрос — значит, не программист»? И засчитает ли этот ответ тот, кто проводит собеседование?
Я бы засчитал, конечно. Как поступают те, кто проводят собесодования, не могу сказать. У меня такого на собеседовании не спрашивали, в основном ребят более сложные и предметноориентированные вещи интересовали.
Но если на интервью спросят «как растёт ArrayList?» — опять придётся угадывать?
Я б не стал угадывать. Сказал бы что-нибудь в духе «Мультипликативно. Что обеспечивает константную амортизированную сложность операции добавления элемента в конец „списка“.» (бросаться это доказывать, разумеется, не стал бы. Не поймут. В смысле не оценят). Спросят, какой именно коэффициент используется (не спросят ведь), скажу, что это не имеет особого значения, но чаще всего выбирают или 1.5, или 2, иногда изобретают более сложные политики, которые сначала используют большой коэффициент, да еще и выравнивают полученный размер по 16 (можно объяснить, зачем), потом (с ростом массива) коэффициент уменьшают с целью снизить перерасход памяти, а при очень больших размерах массива могут вообще перейти на аддитивную модель с фиксированным шагом. Примерно так работают QVector/QString в Qt. Желание же получить конкретное значение коэффициента для конкретной версии библиотеки только заставит усомниться в адекватности собеседующего.
Библиотека — не часть языка. Она от языка, конечно, иногда зависит, но язык от неё — нет
Стандартная библиотека С++ стандартизована. Я много усилий приложил, пытаясь объяснить, что это должно быть верным и для других языков, про которые я это утверждать не могу. Про C++ могу. Видимо, плохо получилось. Больше мне нечего добавить.
После того, как моя самописная сортировка целых чисел (на C++) обогнала std::sort (немного — на 5-15%, подробности здесь
Это очень, очень круто. Жаль только, что в режиме сборки с -O2 (а так собирается на C/C++ всё. Бесплатная скорость, кто же откажется), преимущество вашей реализации падает до ~4%, а при сборке с -O3 — ваш вариант начинает отставать от стандартного ~34%. GCC 4.6.3
В конечном счёте, все эти проценты (они ж все сильно меньше ста), со свистом влезают в погрешности, создаваемые неслучайностью входных данных и различными версиями компиляторов, а также режимами сборки. На деле мы имеем два алгоритма, которые работают с одинаковой скоростью, но корректность одного из них доказана формально, проверена десятилетиями и миллиардами «тестов», а корректность второго не доказана, не проверена тестами (достаточно качественно, по крайней мере). При этом первый доступен бесплатно, а второй отнял у разработчика какое-то определенное время. И я полагаю, не час. Так вот вопрос. Зачем?
Зачем? — для тренировки. А кроме того, MergeSort (в том числе, in-place), в отличие от Quicksort, работает за гарантированное время O(N*log(N)). Для меня этого было достаточно, чтобы заняться этой задачей. Так что еще и из любви к искусству.
Что касается 96-битных чисел, то обычный MergeSort (с использованием дополнительной памяти) обогнал стандартную сортировку Array.Sort примерно в полтора раза, если сортировать структуры через IComparable<> и в 2.5 раза — если в стандартной сортировке использовать делегат для сравнения. Кроме того, я получил функцию быстрого слияния массивов, которая всё равно бы понадобилась. Всё вместе заняло часа полтора-два.
Что касается 96-битных чисел, то обычный MergeSort (с использованием дополнительной памяти) обогнал стандартную сортировку Array.Sort примерно в полтора раза, если сортировать структуры через IComparable<> и в 2.5 раза — если в стандартной сортировке использовать делегат для сравнения. Кроме того, я получил функцию быстрого слияния массивов, которая всё равно бы понадобилась. Всё вместе заняло часа полтора-два.
… реализовывать такие вещи, как массив, список, множество, ассоциативный массив — самостоятельно? И что, вы реально этим на работе занимаетесь? И вам за это платят?
Занимаюсь. И платят. Однажды даже такую вещь, как массивы целых чисел размером порядка 20000*10000 пришлось реализовывать самостоятельно — стандарные реализации в 32-битной системе не проходили по памяти.
Очень вас прошу, поделиться с общественностью результатом.
Итак, на массиве из 1.6*10^8 структур.
Моя сортировка: 34.2 сек
Array.Sort через IComparable: 71.3 сек
Array.Sort с использованием делегата: 96.3 сек.
Таким образом, выигрыш составляет 2-3 раза. Я надеялся, что будет лучше.
Правда, структуру пришлось брать не (uint,ulong), а из трёх uint: первый вариант занимал не 12 байт памяти, а 16.
Массив после сортировки проверялся на монотонность, а кроме того, я сравнивал сумму чисел до и после сортировки (чтобы убедиться, что данные не терялись и не размножались).
Замеры проводились на AMD FX-8120, система Win7 64 bit, сборка — «Any CPU». Код — чистый шарп, хотя и с указателями.
У вас есть свои реализации нетривильных вещей, вы сказали, что вам была необходима очередь с приоритетами с хорошей скоростью работы. Были такие задачи. Тогда я не совсем понимаю, почему вам без разницы, чем вы пользуетесь.
А здесь ответ простой — когда мне действительно нужна скорость, я не доверяю стандартным реализациям. За исключением, как ни странно, quicksort :) И я знаю, что если скорость нужна, то подгонять задачу под чужой алгоритм часто бывает вредно: на преобразованиях данных к формату, пригодному для этого алгоритма, можно потерять и время, и память. Лучше подогнать алгоритм к данным, чтобы путь к ядру алгоритма (возможно, непригодного для общего потребления) был как можно короче.
А если скорость не важна — какая разница, работает операция с ArrayList за O(1) или за O(log(N))? Особенно, если я в нём использую только Add, а в конце — ToArray()?
Насчёт quicksort я, пожалуй, тоже неправ. Буквально неделю назад пришлось сортировать массив 96-битных чисел (организованных как пара uint,ulong) — показалось, что стандартная сортировка работает слишком долго. Пока в активную разработку эта задача не пошла, но когда пойдёт — придётся разбираться, что там со скоростью, и какими алгоритмами пользоваться. Потому для 3D-сортировки облаков точек это весьма важная процедура.
Я чего-то не уловил? В Java, C++, Python, и т.д. есть очереди с приоритетами и фиксированные массивы, при чем реализованные наилучшим образом.
А вообще, от того, как устроена та или иная структура данных, зависит её применимость к конкретной задаче, только и всего. В какой-то задаче «более-менее быстро» может и удовлетворяет требованиям, но в общем случае это определенно не так.
А вообще, от того, как устроена та или иная структура данных, зависит её применимость к конкретной задаче, только и всего. В какой-то задаче «более-менее быстро» может и удовлетворяет требованиям, но в общем случае это определенно не так.
Я последнее время пишу на C#, причём предпочитаю пользоваться только родными микрософтовскими библиотеками. И там приоритетной очереди пока не нашел. Для «динамического массива» недавно обнаружил Array.Resize(), но он есть (насколько я понял) nолько в .NET 4.5 — а мы даже на 4.0 переходим не очень охотно. Пользователи они такие, консервативные.
Как раз в общем случае «более или менее быстро» задаче удовлетворяет. Если это не так (O(N*log(N)) недопустимо хуже, чем O(N)), то речь, пожалуй, идёт уже о тех самых оптимизациях, «которые вредны». Я бы в такой ситуации точно не стал полагаться на универсальную библиотеку.
Как раз в общем случае «более или менее быстро» задаче удовлетворяет. Если это не так (O(N*log(N)) недопустимо хуже, чем O(N)), то речь, пожалуй, идёт уже о тех самых оптимизациях, «которые вредны». Я бы в такой ситуации точно не стал полагаться на универсальную библиотеку.
Generic method появился в .NET 2.0
msdn.microsoft.com/en-us/library/1ffy6686(VS.80).aspx
3.5:
msdn.microsoft.com/en-us/library/bb348051(VS.90).aspx
Как-то не очень у вас с поиском по доке.
msdn.microsoft.com/en-us/library/1ffy6686(VS.80).aspx
3.5:
msdn.microsoft.com/en-us/library/bb348051(VS.90).aspx
Как-то не очень у вас с поиском по доке.
Спасибо. Действительно что-то с поиском не то.
Может быть, у них и сортировка фрагмента массива с помощью лямбда-выражения есть…
Может быть, у них и сортировка фрагмента массива с помощью лямбда-выражения есть…
Поиск по SO дал много вопросов про использование
Обидно, что весь массив с помощью lambda отсортировать можно.
IComparer в этом методе, но, насколько я понял, нужно химичить, чтобы Comparer на основе lambda превратить в IComparer.Обидно, что весь массив с помощью lambda отсортировать можно.
Любопытно, что Hashtable в .NET реализована совсем по-другому: они используют внутреннее разрешение коллизий (с двойным хешированием), поддерживают простое число корзин (= ячеек массива), и непонятно, что делают, когда нужно удалить элемент, поучаствовавший в коллизии (кажется, оставляют ячейку занятой). Минимальное число корзин — 3.
При этом HashSet реализовано внешним разрешением (с самодельными L1-списками, сделанными на одном массиве структур). Тоже поддерживают простое число корзин, удваивая+ его при переполнении (не то 3,7,17,37..., не то 3,11,29,61...). LoadFactor=1 (число корзин равно ёмкости массива для элементов).
При этом HashSet реализовано внешним разрешением (с самодельными L1-списками, сделанными на одном массиве структур). Тоже поддерживают простое число корзин, удваивая+ его при переполнении (не то 3,7,17,37..., не то 3,11,29,61...). LoadFactor=1 (число корзин равно ёмкости массива для элементов).
По поводу итераторов на элементы списка и тому подобного.
Крайне интересно изучить Boost.MultiIndex, в особенности вот эту страничку (для начала).
Подумайте, как работает
Я не знаю, можно ли найти для Java или C# библиотеку, тем или иным способом повторяющую идеи Boost.MultiIndex (дословно точно нет, ведь, насколько я знаю, там нет «настоящих» шаблонов). MultiIndex тучу велосипедов может прикончить, как считаете?
Крайне интересно изучить Boost.MultiIndex, в особенности вот эту страничку (для начала).
Подумайте, как работает
void delete_word(const std::string& word) (как могут быть устроены методы, с помощью которых она реализована).Я не знаю, можно ли найти для Java или C# библиотеку, тем или иным способом повторяющую идеи Boost.MultiIndex (дословно точно нет, ведь, насколько я знаю, там нет «настоящих» шаблонов). MultiIndex тучу велосипедов может прикончить, как считаете?
Sign up to leave a comment.
Java собеседование. Коллекции