
В этой главе автор собирается поделиться своим видением на способы хранения и поддержания в актуальном состоянии знаний, накопленных в результате длительного хождения по граблям. Основная сложность при их хранении и поддержании массива знаний — найти людей, которые бы сочетали несочетаемое: были тщательны, креативны, усидчивы, обладали острым аналитическим умом, интуицией
Содержание
Глава 1. Управление вашим IT окружением: четыре вещи, которые вы делаете неправильно
Глава 2. Устранение практики управления по отдельным участкам в IT-менеджменте
Глава 3. Соединяем всё в единый цикл управления ИТ
Глава 4. Мониторинг: взгляд за пределы ЦОД
Глава 5: Превращаем проблемы в решения
Глава 6: Унифицированное управление на примерах
Глава 5: Превращаем проблемы в решения
Сатирический журнал The Onion недавно опубликовал историю, связанную с экономикой. В ней, рассказывалось как особый вид учёного, под названием историк, продвигал оригинальную идею взгляда на прошлое. «Иногда», говорил один псевдо-историк, «мы можем посмотреть на то, как люди пытались решить проблемы, подобные тем, что мы имеем сегодня. Мы можем изучить и понять, как их решения работали тогда, и это может дать нам представление о том, будет ли это решение работать у нас». Ха!
Хотя это относилось больше к политикам, которые раз за разом продолжают делать одни и те же ошибки, колкости The Onion применимы и к ИТ. «Посмотрите, если у нас проблема случилась три месяца назад, и мы её тогда решили, возможно, мы сумеем её решить гораздо быстрее, если она вдруг появится сейчас. А что, кстати, мы делали в прошлый раз? Может, если мы сделаем всё тоже самое, то будет такой же результат, что и тогда?».
Можно сказать и другими словами: Возможно, у вас есть дети, или по крайней мере, вы знаете тех, у кого они есть. Говорили ли вы когда-нибудь ребенку не трогать горячую кастрюлю, стоящую на плите? Конечно. Трогали они её? Конечно. Сколько раз? Обычно только один. Это потому, что обучение человеческих существ преимущественно строится на совершаемых ими ошибках. Мы запомнили ошибку, и сам факт, что мы поняли, как её избежать или разрешить случившиеся последствия, даёт нам уверенность, что мы сможем быстро это сделать и в будущем. Память становится ключевым фактором, и по мере того, как мы становимся старше, мы прекращаем тянуться к горячим кастрюлям и начинаем играться с нашими компьютерами на работе, а вот тут нам становится всё труднее вспоминать. Эта глава посвящена последнему аспекту унифицированного менеджмента: анализ решённой проблемы и превращение её в решения для использования в будущем.
Закрываем цикл: соединяем сервис-деск с мониторингом
До того как мы погрузимся в такой аспект решения проблем как память, нам надо сначала закрыть операционный цикл в нашем наборе инструментов для унифицированного мониторинга. Ранее в этой книге, мы обсуждали, что один из аспектов объединенной системы мониторинга – это способность отслеживать состояние устройств и сервисов, такие например, как сервер СУБД. Когда регистрируется проблемное состояние, система мониторинга создает сообщение о тревоге, как правило, отображаемое на консоли, и извещает кого-либо ещё посредством электронной почты или SMS. Действительно унифицированная система, может также создать тикет о проблеме в системе отслеживания тикетов. Тикет дает возможность менеджменту видеть состояние проблемы и сколько времени она существует, также система позволяет тикету переходить между различными сотрудниками, работающими над совместным решением проблемы. Тикет может быть автоматически заполнен информацией, относящейся к проблеме, помогая сотруднику решать ее быстрее. На рис. 5.1 показан этот первый шаг: На консоли отображается аварийное сообщение, и из него генерируется тикет.
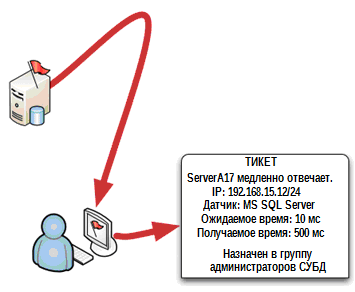
Рисунок 5.1: Получение аварийного сообщения и открытие тикета.
Надеемся, что в итоге, проблема будет решена. Обычно, к этому моменту, специалист, завершивший работу над тикетом, закрывает его и делает об этом специальную отметку.
А что насчёт нашего алерта — тревожного сообщения?
Конечно, та часть системы мониторинга, которая занимается отслеживанием в реальном времени, поймёт, что проблемы больше не существует, но это совершенно не означает, что тревожное сообщение пропадёт.
Обычно, вам нужно, чтобы алерты сохранялись до момента, пока проблема не будет разрешена, вплоть до её полного исправления, что означает, что при закрытии тикета, вам надо каким-то образом сбросить тревожное сообщение.
Такая проблема весьма часто встречается среди организаций, не имеющих системы унифицированного мониторинга: закрыть тикет в одной системе, затем войти в систему мониторинга и пометить, что алерт обработан. Однако, в полностью унифицированной системе, обычно устроено так, что закрытие тикета, также сбрасывает исходное тревожное сообщение. На рисунке 5.2 показано как данный цикл закрывается в рамках единой системы.

Рисунок 5.2: Закрытие тикета сбрасывает оригинальный алерт.
Есть достаточно хорошая причина разделять между собой алерты и тикеты.
Тикет является предметом для внутреннего пользования. Он содержит техническую информацию, предназначенную для решения проблем и извещений о процессе работ над ситуацией. Тревожное сообщение, однако, пригодно для использования более широкой группой людей. Алерт может быть использован в большом количестве индикаторов, используемых в компании. Например, для демонстрации пользователям, что данная система, в настоящий момент работает неправильно. Алерт сбрасывать нет необходимости, потому что система мониторинга больше не видит неправильных показателей, но временное облегчение от ситуации, совершенно не означает, что она разрешилась. Вы можете захотеть, чтобы алерт оставался на месте, как высокоуровневый индикатор, типа того что «мы знаем, что сейчас там не всё в порядке», но в какой-то момент вам его всё равно понадобиться сбросить и вернуть внешние признаки системы в состояние «работает нормально». Если такое делается автоматически, как составная часть закрытия тикета, то это может быть удобным способом для извещения двух различных между собой аудиторий пользователей.
Сохраненное знание означает более быстрое разрешение проблем в будущем
После того как проблема решена, информация о ней никуда не пропала. По крайней мере, вы надеетесь, что это так. Как я уже говорил в начале этой главы, каждая решенная проблема – это потенциальное ускоренное разрешение проблем в будущем – равно как если встретится в точности такая же, или просто похожая. Другими словами, вам понадобиться сохранить информацию о проблеме и о методе её решения для будущего использования.
Базы знаний
Наверное, самый старый способ сохранения информации – это база знаний(БЗ).
Когда-то, в самом начале, это были разрозненные базы данных, состоящие из статей, описывающих, где искать выход в той или иной ситуации. Если у вас есть проблема, вы сначала делаете поиск в базе знаний, проверяя, есть ли хоть какие-то намёки на решение проблем.
Одна из самых ранних баз знаний, получивших широкое распространение, была БЗ компании Microsoft, поставлявшаяся на CD в начале 90-х годов. Сегодня, она представляет собой большое собрание онлайновых статей — настолько большое, что в базе знаний существует отдельная статья о том, как делать правильно запросы к ней (показана на рис. 5.3, если вы вдруг мне не поверили).
Рисунок 5.3: статья из Microsoft Knowledge Base.
Это демонстрирует нам одну проблему, связанную с базами знаний: людям необходимо учиться с ними работать и надо постоянно помнить, как это делается. К несчастью, ИТ-профессионалы не обязательно относятся к аудитории, для которой в большинстве случаев необходимо доставать руководство (или базу знаний), если где-то на горизонте замаячил инцидент.
С большей долей вероятности, они погрузятся в изучение случившегося и попытаются использовать свои собственные навыки для решения задачи, Использование базы знаний, говоря простым языком – «поиск по БЗ», случается обычно уже после того, как внутреннее знание исчерпано. Частично такая ситуация возникает из-за внутренней профессиональной компетенции, частично из–за плохого использования ими большинства баз знаний, и частично потому, что базы знаний устаревают очень быстро.
Это свидетельствует о другой серьезной проблеме: необходимость поддержания баз знаний в актуальном состоянии. Ровно до тех пор, пока вы аккуратно расставляете тэги по статьям — к каким версиям продуктов относится решение и так далее, то ваши статьи полезны, в противном случае они становятся источником дезинформации. Рассмотрим версию бизнес-приложения, например версии 1.5, у которого есть специфичная проблема. Вы документируете это в статье БЗ, затем вы полагаетесь на её содержание, после того как проблема возникает снова. В итоге, ваши разработчики исправляют ошибку в версии 1.6. Кто-нибудь потрудился над тем, чтобы вернуться и исправить статью в БЗ? Нет. Даже если в статье указано, что она применима к версии 1.5, больше никакой полезной информации в ней нет. Была ли проблема исправлена в 1.6? Будет ли процедура исправления работать в 1.5? Если вы используете 1.6. и проблема возникает снова, должны ли вы следовать процедуре, указанной в 1.5 или сообщить о ней, как о новой проблеме – потому что разработчики посчитали, что всё исправлено и работает как надо?
Все эти предположения, строятся на том, что вы понимаете главную проблему баз знаний: своевременное размещение в ней статей. Вендоры, типа Microsoft тратят миллионы долларов в год на зарплаты людей, которые занимаются не более чем написанием документации и составлением статей для баз знаний. Есть желание заняться такого рода инвестициями? Я видел множество компаний, создавших у себя базы знаний, которые с энтузиазмом использовались в течение нескольких месяцев, потом работа с ними начинала буксовать и, в конце концов, их использование сводилось на нет.
Тикеты как статьи базы знаний
Первое решение многих свойственных базам знаний проблем заключается в прекращении использования под эти задачи отдельной БЗ и применение в качестве хранилища знаний закрытых тикетов. В основном, все современные системы отслеживания тикетов сегодня имеют такую возможность. Данный подход решает глобальную проблему БЗ: первичное наполнение контентом, так как тикеты – это уже контент. Хорошая система обработки тикетов также поможет ответить на вопрос «что к чему относится», потому что ваши тикеты обычно распределены по каким-то конкретным продуктам или сервисам. И если вы читаете старый тикет, то, по крайней мере, знаете с каким продуктом или версией он связан – хотя вам может быть совершенно неизвестно, применима ли содержащаяся в нём информация, к конкретному продукту или устройству?
Использование тикетов хелп-деска в качестве БЗ не решает проблему вовлечения людей в поиск ответов с её использованием. На самом деле, масса тикетов с хелп-деска может сделать решение проблемы еще хуже. Представьте: каждый раз, как возникает проблема, создается новый тикет, и когда вы делаете поиск по базе знаний (например, по какому-то старому тикету), используя ключевое слово, или просто выбирая продукт или устройство, вам выдается гораздо больше результатов поиска, где фигурирует каждый тикет, соответствующий вашим критериям.
Тикеты, собранные на хелп-деске, не всегда представляют собой источник документации для самостоятельной помощи. Не все сотрудники ИТ – лучшие писатели в мире, и в самих тикетах есть нечто, связанное с их способом сбора… назовём это «неформальным» языком, который вы, скорее всего, не захотите вытаскивать на поверхность и демонстрировать своим конечным пользователям. Например, пользователь, вошедший в вашу базу знаний, пытается решить проблему сам, вместо того чтобы просить об этом хелп-деск, то ему может не понравиться, если он найдёт что-нибудь типа «Перегрузите тупой пользовательский компьютер». Технические специалисты могут не указать никаких деталей. Например, нередко в качестве решения по тикету пишется «исправлено» — то есть, ничего полезного для решения. Тем не менее, использование тикетов с хелп-деска в качестве источника для базы знаний не так далеко от реального выправления ситуации.
Унификация базы знаний
Есть две вещи, с помощью которых можно постараться превратить тикеты из хелп-деска в полезные статьи БЗ. Во-первых, потребуется некоторая автоматизация. Когда создается новый тикет, система, где это делается, должна автоматически просмотреть последние тикеты и представить их в виде кандидатов на решение техническому специалисту, собирающемуся работать над проблемой.
Отличный пример того, как это может быть сделано, если вы задаёте какой-то вопрос – сайт StackOverflow.com; сам по себе он уже представляет комбинацию тикетов/баз знаний. Он автоматически ищет последние вопросы и представляет их визуально раздельным образом: они вставляются ниже вашего вопроса, но выше поля, где вы вводите детали вашего запроса, как это показано на рис.5.4. Это заставляет вас принудительно просматривать предположения из базы знаний, так что вы можете быстро увидеть, что, возможно, на ваш вопрос уже есть ответ.
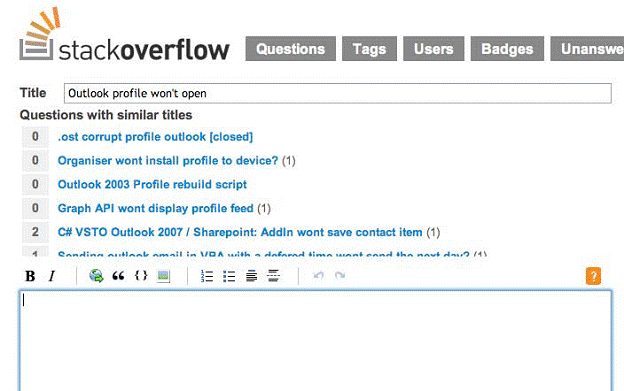
Рисунок 5.4: Предполагаемые ответы на вопрос.
По мере того, как вы начинаете печатать детали вопроса, нерелевантные предположения начинают исчезать с основного поля, снова помогая вам использовать базу данных прошлых ответов, вместо того чтобы требовать от вас явно выполнять поиск на каждом дополнительном шаге.
Унифицированная система тоже помогает делать этот дополнительный шаг (рис. 5.5), либо включая в результаты поиска потенциально относящиеся к проблеме тикеты, либо привязывая их к свежесозданному документу. Таким образом, система может дать техническому специалисту преимущество: он приступает к решению проблемы, имея понимание о подобных ситуациях в прошлом, и как, при этом, выглядят их решения.
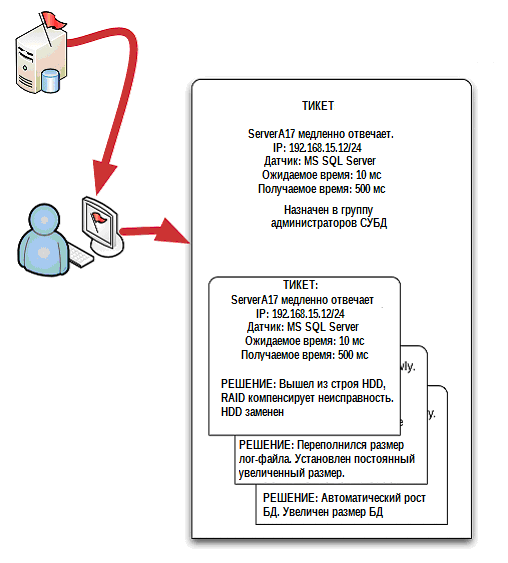
Рисунок 5.5: Использование старых тикетов для решения новых проблем.
На самом деле, для автоматически создаваемых тикетов, система потенциально может сделать очень хорошую работу в виде поиска старых тикетов, имеющих действительное отношение к проблеме. Так как система не забывает делать дополнительные шаги, она может включить дополнительные критерии поиска, такие например как источник проблемы, затрагиваемые устройства или сервисы и так далее. Технический специалист может не догадаться включить все детали, потому что они выдадут очень большое количество результатов, что часто отталкивает от использования поиска на первом шаге. Получая узкий результат, с которого надо начинать, система, автоматически связывающая тикеты, позволит с большей вероятностью иметь на руках релевантную информацию. Такую систему можно сделать еще лучше, если бы система для работы с хелп-деском включала в себя возможность выставлять пары контрольных галочек (чек-боксов) в своих тикетах. При закрытии тикета, технический специалист должен иметь возможность независимо проставить:
- Содержит ли данный тикет добросовестное решение проблемы? Например, иногда технический специалист может решить проблему, посмотрев содержимое старого тикета. Это значит, что текущий тикет не содержит достаточное количество информации о том, как проблема была решена. Но если специалист решил текущую проблему, и заполнил тикет детальным описанием решения, по сравнению с тем, что было сделано раньше, то тогда текущий тикет может быть помечен как «решение», что заставить его появляться в верхних строках результатов поиска.
- Содержит ли данный тикет решение, пригодное для конечного пользователя и которое может быть использовано, в дальнейшем, как материал для самообслуживания? Большинство систем для отслеживания тикетов сегодня содержат «приватные» и «публичные» поля, что помогает удостовериться, что конечные пользователи не увидят информацию, которую пользователи могли бы воспринять неадекватно, хотя при этом допускается, что администраторы могут иногда написать в тикете нечто такое. В тоже время, имея на руках однозначные указания о том, что данный тикет пригоден для использования за пределами ИТ-службы и содержит решения, пригодные для самостоятельного применения конечным пользователем, то можно построить действительно работающую базу знаний самообслуживания.
Рисунок 5.6. показывает как система может это реализовать – в данном случае, это не чек-бокс; система использует выпадающее меню пункта «видимость» для смены статуса тикета из состояния «на удержании» в «опубликованный»

Рисунок 5.6: Управление видимостью тикета
Простое присутствие этих галочек (или других индикаторов) может служить напоминанием техническим специалистам, что документированные решения являются необходимостью. С точки зрения менеджмента, организации могут установить определенные квоты: по крайней мере, 75% закрываемых тикетов должны содержать детальное решение, либо ссылаться на тикет, описывающий подробный порядок действий по устранению проблемы. Такие метрики отслеживаются посредством внутренних отчетов в системе работы с тикетами, и могут быть дополнительным способом удостоверения, что закрытые тикеты действительно являются основой для сохранения знаний.
Превращение тикета в актив
Общая идея заключается в том, что надо перестать думать, что тикеты годятся только для отслеживания проблем и поработать над тем, чтобы создать из них полный цикл для решения проблем. Чтобы из этого получилась польза, тикеты-как-решение должны преодолеть ряд общих человеческих предрассудков и проблем реализаций, мешавших им в прошлом:
- Технические специалисты не всегда пользуются поиском в базе тикетов, по мере возможности это должно делаться автоматически, а тикеты должны предлагаться как потенциальное решение.
- Умение пользоваться поиском у технических специалистов не всегда идеально – так что унифицированная система должна, до определенной степени автоматизировать эту деятельность, и, используя имеющуюся информацию, сделать первую попытку в поиске относящихся к делу тикетов.
- Умение связно излагать свои мысли на бумаге для технических специалистов не всегда является хорошо развитым навыком, так что система должна, по мере возможности, сама делать упор на необходимость наличия полных решений, а руководство должно принимать это в качестве метрики. Технические специалисты, в свою очередь, должны иметь возможность предложить версии решения, как «внутреннюю» так и пригодную для «внешнего использования», если такая необходимость возникнет.
При наличии правильной системы – особенно такой, которая может быть интегрирована вместе с системой мониторинга, создается истинно объединенное окружение – превращение решения в проблему может быть сделано на уровне одного щелчка мышью.
Работоспособность в прошлом является индикатором будущих результатов
Еще один способ формирования правильных ожиданий от уровня сервиса – использование исторически накопленных данных. Я намеренно избегают термина «соглашение об уровне обслуживания», потому что SLA является формальным документом, часто включающим в себя элементы политики организации. Тем не менее, ожидания уровня обслуживания – это уровень сервиса, основанный на прошлых показателях работоспособности и производительности, который вы вполне реалистично хотите получить в будущем. В идеале, SLA должно базироваться на этих ожиданиях реального мира, но только, если вы их в состоянии обеспечить.
Есть одна проблема, которая содержится в SLA многих организаций – они оторваны от реальности. Кто-то устанавливает амбициозную цель «хорошо выглядеть», обещая доступность в 99.999% и затем бодро утверждает, что они просто «стараются соответствовать этой цифре», кто-то выбирает при выставлении условий слишком осторожный подход, заставляя организацию принимать меньший уровень сервиса, чем это могло быть на самом деле.
Ну и в случае неудачи – нельзя не забывать про используемый нами инструментарий. Всё возвращается назад к первой главе книги, когда я писал о технологиях управления по отдельным участкам или «башням», с которыми так склонно работать ИТ, а также различным специализированным инструментам, используемых нами для поиска решения и устранения проблем. Теми же специализированными инструментами мы вынуждены пользоваться для измерения уровней производительности. Из-за того, что каждый набор средств использует собственный «понятийный язык» и набор метрик, достаточно сложно всё свести в единую картину и использовать единый набор контрольных значений. Конечно, при этом достаточно сложно понять, какие же у нас уровни сервиса в действительности.
В итоге: у вас есть некоторое существующее окружение. Все политические и внутренние проблемы отставляем в сторону, ваша существующая инфраструктура в состоянии предоставить вам определенный уровень технически измеримой производительности и работоспособности. Вам только лишь необходимо понять и определить её, прописав в виде понятных и легко объяснимых наборов метрик, основанных на текущей емкости вашей инфраструктуры. Это сложно сделать, если у вас мешанина из специализированного инструментария, и уж тем более это сложно сделать, если в вашей инфраструктуре появляются элементы, вынесенные на аутсорсинг. Начните сводить воедино платформы для облачных вычислений, коаллоцированные сервера, платформы SaaS и так далее, и вы увидите, что ваш специализированный инструментарий не в состоянии предоставить вам информацию, достаточную для решения. Возникает вопрос: как в этом случае вы можете установить хороший уровень ожиданий от сервиса?
Это возвращает нас к предыдущим главам в данной книге. Например, у вас есть отличный набор сервисов и приложений – у кого его сейчас нет? На рисунке 5.7 приведена инфраструктура, предлагающая множество различных элементов, некоторые внутри датацентра, некоторые снаружи.

Рисунок 5.7: Современное окружение включает множество компонент.
Вы начинаете свои измерения на одном, самом важном месте: конечном пользователе. Размещаете несколько датчиков, агентов, синтетических транзакций и чего-нибудь еще, что вам нужно, для понимания происходящего — что же пользователи на самом деле видят, в отдельно взятый момент, в терминах производительности. Необходимо отслеживать в течение нескольких дней их работу, отражающую реальную и рабочую нагрузку, при этом не стоит выбирать выходные для мониторинга, где значения нагрузки ощутимо ниже и нерепрезентативны. Теперь вы знаете, что ваша инфраструктура в состоянии предоставить на самом деле. Стоит принять за должное, что вам вряд ли стоит ожидать чего-то лучшего, но также не стоит ожидать чего-то совсем плохого. Если уровень ожидания сервиса не настолько хорош, как ваши SLA – ну, в общем, всё замечательно. Вы можете начать искать области для улучшения, подтягивая их до уровней, прописанных в SLA.
Возможно, вам потребуется собирать информацию по индивидуальной производительности каждого компонента – в этом месте может возникнуть ряд сложностей. Важно, чтобы на данном уровне мониторинга, вы собрали всё на одну консоль, использовали один язык (для описания процессов) и использовали единый набор метрик. Вам надо найти диапазон значений производительности для каждого компонента, работающего под нагрузкой нормального рабочего дня.
Убедившись, что каждый компонент работает в пределах наблюдаемых значений, вам следует понять и оценить ощущения конечных пользователей, связанные с этими измерениями. Эти значения являются базисом для ваших значений мониторинга: обо всём, что находится за их пределами, вы должны своевременно извещаться.
После того, как у нас установлены ожидаемые уровни сервиса, вы можете начать измерять различные уровни рабочей загрузки. Посмотрите, как обстоят дела в сильно нагруженные дни и как они выглядят в дни с невысокой нагрузкой (например, выходной день). Тогда вы начнёте чувствовать, как меняются ощущения пользователей, в периоды различных нагрузок, и как воспринимает нагрузку ваша инфраструктура, вместе с ее элементами.
Конечно, крайне важно удостовериться, что все аутсорсные элементы сюда также включены. Как я указывал в предыдущих главах, мониторинг всего этого, немного отличается от мониторинга вещей, находящихся в вашем датацентре. Вам потребуется либо решение для унифицированного мониторинга, имеющее возможность для гибридного мониторинга, либо вам потребуется специальный набор инструментов для сбора информации по производительности с этих частей инфраструктуры, вынесенных за географические пределы вашей компании.
Обратите внимание, что для мониторинга выделены два набора метрик: производительность и рабочая нагрузка. Слишком часто, мне попадаются SLA, в которых не принимается во внимание нагрузка. «Мы обеспечим время ответа в пределах 100 мс»,- Окей, а под какой конкретно нагрузкой? Возможно, я смогу предоставить вам стомиллисекундное время ответа под нагрузкой, которую я понимаю как нормальную, но если вы начнёте добавлять пользователей и дополнительные задачи, то, очевидно, что время ответа начнёт проседать. И снова, решения для мониторинга могут помочь нам с этим, не только измеряя производительность таких вещей как процессор, память, диски и так далее, но еще и рабочую нагрузку, выражаемую, например, в количестве обработанных транзакций, числе маршрутизированных сетевых пакетов и так далее. Важно, чтобы ваши ожидания производительности также включали понятие рабочей нагрузки – это необходимо для формирования соглашений об уровне обслуживания в будущем.
Это база данных о производительности
Все данные по работоспособности надо не только где-то собирать, но и еще где-то хранить. Это та самая функциональность, которую многие системы мониторинга упускают: они выполняют мониторинг в реальном времени и сообщают о проблемах, но они не всегда сохраняют проходящую через них информацию. Расширим наш пример базой данных о производительности (рис.5.8)
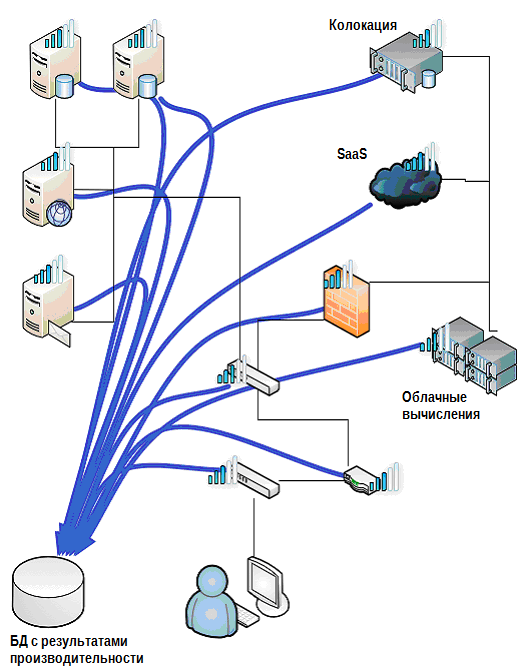
Рисунок 5.8: Добавление БД с информацией о производительности в окружение.
Смысл данной иллюстрации в том, чтобы вам необходимо собирать информацию с каждого компонента – даже с тех, которые вынесены на аутсорсинг, в эту базу данных. Зачем? Причин две:
- Эта БД позволяет вам понимать, на что похожа работоспособность и производительность системы, когда у вас нормальный день. Отсюда берутся ожидания уровня сервиса, и возможно, это позволит вам создать более реалистичные и продуманные SLA.
- Эта БД подскажет вам, когда ваша производительность начнёт выходить за пределы ранее установленных нормативов. Я не говорю о ситуации, когда один из компонентов начинает выпадать из общей картины по причине проблемы – постоянный мониторинг и механизм извещений подскажет об этом. БД нужна для того, чтобы показать долговременные тренды: «Эй, а вы в курсе, что производительность упала за последний месяц на 1%, а за предыдущий еще на 0,75%? С такими темпами, вы прекратите соответствовать SLA уже через 6 месяцев.»
И, честно говоря, хорошее решение для мониторинга не должно вам показывать стандартную «линию тренда» вашей производительности на первом шаге. Будет достаточно простого индикатора со стрелочкой: «Вы соответствуете вашему SLA, и основываясь на текущих перспективах, это будет продолжать соблюдаться и в вашем обозримом будущем». Или, «Вы соответствуете условиям вашего SLA, но, если честно, основываясь на текущих данных, вы не сможете соблюдать SLA через один или два месяца».
И вот с этого момента, можно начинать разбираться в диаграммах и графиках, предоставляющих вам детализированную информацию, так что вы можете суметь найти компонент или компоненты, являющимися узким местом в системе, и начнёте заранее планировать увеличение емкости ваших ресурсов, до того как случится, ненужное вам, несоответствие SLA.
Итоги
Примите в объятья прошлое, и ваше будущее станет лучше — вот о чём мы говорили в этой главе. Собираете ли вы информацию с тикетов, чтобы быстрее и лучше решать проблемы в будущем, либо собираете информацию по производительности системы: для разумных договорённостей об ожиданиях от сервисов и правильного расчёта емкости ресурсов — всё это касается сохранения исторических данных и управления ими, чтобы организация увереннее стояла на ногах в будущем.
В следующей главе…
В последней главе данной книги, мы собираемся пройти еще раз этот путь с самого начала, и посмотреть на унифицированное управление с точки зрения изучения кейсов. Я буду использовать мои практические и консалтинговые навыки для создания составного кейса, обрисовывая элементы унифицированного управления вместе, чтобы показать вам как может выглядеть современное, действительно единое, окружение. Я покажу вам специфичные проблемы в каждом окружении и поясню как объединенное управление помогает решать эти проблемы лучше и эффективнее.
