Comments 152
интересно было бы еще как-то оценить собственно степень говно-кода у тех и у других
Мне интересно почему для Go эта зависимость тоже работает: там же строго табы согласно официальному гайду и найти проекты где забивают на gofmt и используют пробелы не так просто.
а где те анализ тех, которые используют Smart Tab?
Кстати, на ту же тему: http://tylervigen.com/spurious-correlations
Вспоминается эта история:
В отделение Pontiac корпорации General Motors пришло письмо. "Я понимаю, — писал автор, — что могу показаться идиотом, но все, что я хочу рассказать, — святая правда.
В нашей семье все очень любят мороженое. Каждый вечер после ужина мы решаем, какой сорт будем есть на десерт, и я еду за ним в магазин. Проблемы начались после того, как я приобрел новый Pontiac. Каждый раз, когда я покупаю ванильное мороженое и собираюсь вернуться с ним домой, машина напрочь отказывается заводиться! Если мороженое клубничное, шоколадное или любого другого сорта — никаких проблем с пуском. Звучит глупо, но, может быть, в Pontiac есть нечто, что реагирует на ванильное мороженое?".
Президент отделения, понятное дело, отнесся к письму скептически, но все-таки послал инженера на проверку. Владелец автомобиля производил приятное впечатление — вежливый, образованный и явно не псих… Встретились после ужина, поехали в магазин, купили ванильное мороженое.
Все точно — машина не заводится! Так продолжалось несколько дней подряд. Шоколадное — заводится. Клубничное — заводится. Ванильное — не заводится! Инженер был человеком здравомыслящим и отказался верить тому, что у автомобиля может быть аллергия на ваниль. Он продолжал ездить с хозяином в магазин, но теперь отмечал все детали — время поездки, каким бензином и на какой колонке заправляли машину, даже температуру и облачность…
Довольно быстро выяснилось, что дело не в ванили, а в расположении товаров в торговом зале магазина. Ванильное мороженое — как самое ходовое — размещалось в холодильнике самообслуживания у самого входа, а все остальные сорта — в глубине зала, и продавались через кассира. Купить ванильное можно было намного быстрее, чем любое другое…
Задача перешла в разряд технических — почему машина не заводится, если хозяин возвращается к ней быстро? И ответ был найден сразу же — двигатель не успевал остыть, и в карбюраторе оставались пробки, вызванные интенсивным испарением бензина!
PS Я использую пробелы в коде и табы в табличных данных
Для таблиц хорошо походят таблицы.
Если у вас таб например 8 символов, а в какой-то строчке столбец с текстом в 11 символов — то тут-то все форматирование и поедет. :(Всегда можно поставить два таба. Но для этого нужно, чтобы размер таба был фиксирован. Он может быть любым — но известным заранее. Исторически — это таки 8 символов, да.
А таблицы — всем хороши, ктоме того, что не поддерживаются теминалами и текстовыми редакторами, языками программирования и многими другими вещами. Там где они есть — да, лучше использовать их…
А если буковки в шрифте разного размера, то либо это не терминал, либо это редактор который умеет таблицы, либо это редактор который и табы-то адекватно не умеет, либо да — счастливый случай.
Я не против табов. Особенно они хороши когда надо сделать printf
Если размер таба заранее известен, то он не лучше пробела для моноширного шрифта.Он лучше, так как при добавлении данных в таблицу позволяет нажимать меньше клавиш. Для чего и был, в общем-то, придуман.
1 2 3
a b c
d e f
123456 123 12345678 1234 123 123456 1234 12345678 1234567890 12345678901 1234567890123 123
изменение длины контента в любой из колонок в рамках своего таба не будет менять форматирование
А для отступа пробелы естественно без вариантов особенно в современных IDE
Для выравнивания без вариантов. Для отступов табы идеальны.
Вообще-то наиболее ярко видно в случаях хвостовых пробелов колонки, а не отступов
123456 123 12345678 1234
Знаете, что интересно? Вы использовали пробелы вместо табов, чтобы отобразить таблицу как пример использования табов для отображения таблицы
Это проблемы парсера и трансляции в html
В исходном файле это именно табы.
function foo () { alert(123); }
UPD: Смотрите, у меня просто вставилась табуляция. О каких проблемах парсера и трансляции в html вы говорите? Это исключительно ваша проблема. Скорее всего у вас и в исходном файле пробелы, просто вы не задумывались или не очень в этом разбираетесь.
О каких проблемах парсера и трансляции в html вы говорите?Попробуйте просто в текст сообщения на Хабре вставить табуляцию — и вы увидите, что она будет замена на пробелы. Внутри <source> или <pre> — да, табуляция сохраняется. Просто внутри текста заменяется на 1 (один) пробел, что, разумеется, для выравнивания таблиц использовать непросто.
Это исключительно ваша проблема.Нет, это проблема любого, кто пытается писать на Хабре. Его «интеллект» достоин отдельного рассказа. Но да, с <pre> всё работает:
123456 123 12345678 1234 123 123456 1234 12345678 1234567890 12345678901 1234567890123 123
Скорее всего у вас и в исходном файле пробелы, просто вы не задумывались или не очень в этом разбираетесь.Я думаю он неплохо разбирается в текстовых файлах, но плохо — в Хабраредакторе. Вряд ли его можно в этом винить…
Попробуйте просто в текст сообщения на Хабре вставить табуляцию — и вы увидите, что она будет замена на пробелы
Не на «пробелы», а на один пробел, как вы правильно уточнили далее. Точно так же как несколько пробелов, которые я вставил между этими словами. Это сделано, для того, чтобы удобное программисту форматирование html-файла не влияло на результат.
Его изначальная таблица была обернута именно в pre и там прекрасно поддерживается как табуляция, так и множественные пробелы:

Но да, с pre всё работает
Да, я это прекрасно знаю.
Я думаю он неплохо разбирается в текстовых файлах, но плохо — в Хабраредакторе. Вряд ли его можно в этом винить…
Нет, как раз дело не в хабраредакторе, потому что он ошибся не только на Хабре, но и файлы в Гите у него имеют пробелы там, где, как он считает, стоят табы.
Из двух разных случаев одинаковой ошибки я допускаю, что у Fortop редактор автоматически заменяет табуляцию на пробелы, но он об этом раньше не знал и искренне считал, что это проблемы отображения табуляции в браузере.
Как я уже выше показал (а так же вы в своем сообщении) — табы прекрасно живут что на Хабре в теге pre, что в веб-интерфейсе Гитхаба и не заменяются на пробелы.
То что при копировании в сообщение и обработке парсером заменились табы на пробелы уж точно не моя проблема и отлавливать это я не собираюсь.

Более того, внимательно читая написанное и включив мозг вы бы заметили, что использование пробелов не дает никакого автоматического выравнивания контента по позициям табуляции, если удалить любую цифру в любом столбце. О чем я собственно и писал.
А табы дают.
Скорее всего вы просто не читаете что пишут. Но с определенной долей вероятностью просто не привыкли включать мозг в принципе.
Но с определенной долей вероятностью просто не привыкли включать мозг в принципе.
Ну ты и хамло.
Мне не нужно задумываться о том, что я набрал руками и воспроизвел лично.
Да, я заметил.
табы на пробелы уж точно не моя проблема
Эффект Даннинга — Крюгера
А табы дают.
Не совсем так. Правильно будет «а табы — то дают, то не дают».
Что у меня, что у khim парсер прекрасно работает с табами. Возможно, это недостатки вашего редактора, что вместо табов он копирует пробелы. Пробовали перейти на что-то получше? С другой стороны, вам и правда не стоит разбираться, в чем ваша ошибка и вы просто можете и дальше обвинять всех окружающих в собственном невежестве
Не совсем так. Правильно будет «а табы — то дают, то не дают».
Процитирую тот текст, который вы не осилили с первого раза
изменение длины контента в любой из колонок в рамках своего таба не будет менять форматирование
С другой стороны, вам и правда не стоит разбираться, в чем ваша ошибка
Все намного проще. Время потраченное на выяснение этих моментов не окупается ничем.
Ситуации, когда требуется показать недалекому человеку область и границы применимости табов сейчас единичны.
позволяет нажимать меньше клавиш
А вы таки ставите пробелы клавишей пробела?
По моему всё просто. Компании, готовые платить больше, требуют тоже больше. И, в частности, они требуют соблюдение стайлгайда. Большинство стайлгайдов основаны на пробелах.

А ещё там TAB ставит 4 пробела, но второй — удаляет 4 пробела и ставит один TAB на их место.
Было бы интересно сравнить зарплаты тех, кто использует моноширинные или пропорциональные шрифты в IDE (хотя подозреваю что я такой один в мире, не моноширинный, и сравнивать не получится).

Анализ данных приводит нас к интересному выводу. Разработчики которые используют пробелы для отступов, зарабатывают больше денег, чем те, кто используют табы, даже если они имеют такой же объем опыта
А можно еще прийти к такому выводу, что те кто используют пробелы более склонны врать про свою зарплату.
При такой зарплате я могу использовать хоть символы нижнего подчёркивания!
Так что мне пришлось перейти на пробелы, чтобы не отстать от жизни. С понижением зарплаты.
set sw=2
set ts=2
И никаких проблем. Даже не знаю, табы там или пробелы используются.
На премию ингобеля — «заставляет сначала смеяться, потом задуматься».
Пробелы приносят больше денег чем табы
А не кажется ли вам, что авторы статьи путают причину и следствие? Не думаю, что они идиоты, но прикидываются ими ради громкой статьи.
Ошибочность в духе меткого стрелка из Техаса — выбор или подстройка гипотезы после того, как данные собраны, что делает невозможным проверить гипотезу честно.Т.е. сначала сформулировали гипотезу, а потом опросили программистов или взяли bigdata понаходили корреляций, а теперь выдают гипотезы. (А по закону bigdata там будут любые, даже самые абсурдные корреляции.)
Наверное настоящая зависимость между языками программирования, в каких-то принято пользоваться табами, в других — пробелами, это и влияет на зарплату.
Вы правы по поводу того что прикидываются).
Данный эффект как минимум есть в разрезе размера компании, пруф:

А размер компании корелирует с зарплатой, пруф:

Из этого можно сделать вывод, что:
Размер компании влияет на использование пробелов.
И так же размер компании влияет на среднюю зарплату.
Наличие корреляции на ограниченной выборке еще не говорит о наличие какой-либо причинно-следственной связи.
Вот отличный набор примеров странных корреляций
Я уже двести лет никакие отступы руками не ставлю, их вставляет IDE согласно командным правилам форматирования кода.
В правилах же как правило используются пробелы, потому что дифы проще читать.
в некоторых IDE diff-сравнение убирает различия на тему пробелов и табов и акцентируешься только на коде
консоль: http://www.gnu.org/software/diffutils/manual/html_node/White-Space.html#White-Space
Для браузеров есть параметры "w=1" и "ts=N":
https://blog.bitbucket.org/2015/01/30/new-year-new-features/
https://github.com/tiimgreen/github-cheat-sheet#ignore-whitespace
видимо я давно так много за пределами IDE не сравнивал код, чтобы обратить внимание на такое смещение


Я вас разочарую. 3-я строка на скриншота после минуса. Изучайте
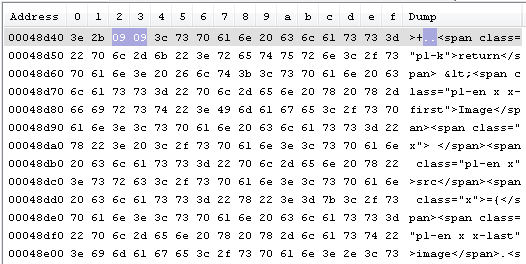
На самом деле очень быстро в браузере можно проверить даже без Хекс-редактора — стоит только посмотреть, как выделяется текст. Если там пробелы, то выделяются по одному символу, табуляция может быть разорвана, а на реальной табуляции каждый отступ — шаг выделения. Попробуйте сами:
Пробелы в качестве отступов:

Табы в качестве отступов:

Эта быстрая проверка однозначно и правильно показывает, какой символ реально используется, но вы всегда можете дополнительно проверить в хекс-редакторе.
Лично я начал использовать только пробелы и следить за этим только после того, как узнал Python + натыкался на косяки с отступами в конфигурациях некоторых программ, до этого я об этом даже и не задумывался…
Табуляции — новые мелкие проекты в мелких современных транснациональных корпорациях. Хипстеры, вейперы, вот-это-вот-всё. Массовое использование IDE. Дыроколы в аренду.
На мой взгляд в студии довольно удачное решение этой пролемы, оно похоже на настройку:
git config --global core.autocrlf true
— позволяет разработчикам на разных системах писать код и при этом в репозитории будет порядок. Так же и с отступами — кто использует побеллы, кто-то табы, но в результате у всех пробелы и все счастливы. Единственное замечание — для стирания отступа бэкспейсом приходится уже нажимать 4 раза (но ведь есть Shift+Tab!)
PS: в компании есть один человек, который эту настройку у себя поменял и каждый раз
Хотя (это «бигдата») использование табуляций сокращает время компиляции и размер исходника. В мировых масштабах это позволит сэкономить природный газ на тысячу зажигалок, которые можно раздать африканским детям, научив их курить.
> табуляторщикам.
А для уже нанятых делать так. Вице-президент собирает всех для супер презентации и мотивируя зажигалками для африканских детей обязывает всех использовать табы. А потом все просто получают пониженную зарплату.
> В мировых масштабах это позволит сэкономить природный газ на тысячу зажигалок, которые можно раздать
> африканским детям, научив их курить.
Вы совершенно правы. Тут эффект бабочки. Они будут курить — быстрее умрут, оставят меньше потомства (а то, что оставят умрет от рака легких); а значит это, наверняка, скорее всего, возможно, позволит снизить выбросы CO2 и избежать глобального потепления арктических льдов.
Все используют пробелы, но ставят их все равно другой клавишей.
{kind=link}
А почему нет варианта ответа "а хрен его знает"?
Потому что за меня отступы делает IDE.
if (someLongFunction() === $someLongValue && anotherLongFunction() === $anotherLongValue) {
if ($someObject->attributeLongName !== $someValue) {
foreach ($someObject->attributeLongName as $item) {
doSomethingWithItem($item);
}
someCommonAction();
} elseif ($someObject->anotherAttributeLongName !== $someValue) {
foreach ($someObject->anotherAttributeLongName as $item) {
doSomethingWithItem($item);
}
someCommonAction();
}
}
if (someLongFunction() === $someLongValue && anotherLongFunction() === $anotherLongValue) {
if ($someObject->attributeLongName !== $someValue) {
foreach ($someObject->attributeLongName as $item) {
doSomethingWithItem($item);
}
someCommonAction();
} elseif ($someObject->anotherAttributeLongName !== $someValue) {
foreach ($someObject->anotherAttributeLongName as $item) {
doSomethingWithItem($item);
}
someCommonAction();
}
}
jQuery, Doctrine, HTMLPurifier, Guzzle
Чаще всего встречается, если дальше идет комментарий.
уже отделены от окружающего кода отступом.А если окружающий код это тоже «if», «else if»...? В простом коде с одним оператором это выглядит неплохо, а в коде посложнее иногда приходится отделять. Значит читабельность у такого варианта меньше.
Ну и со отдельными скобками как-то посимметричнее выглядит. Особенно с elseif, который с третьего символа начинается.
Ну или когда условие в if занимает несколько строк, как тут, например:
if ( deep && copy && ( jQuery.isPlainObject( copy ) ||
( copyIsArray = Array.isArray( copy ) ) ) ) {Глазами иногда сложно понять, где заканчивается условие. С открывающейся на новой строке скобкой же всё понятно и логично.
Ну и ещё одна мелочь, правда, относящаяся к coding convention: если правила написания кода требуют указания скобок всегда, даже когда в ветке if один return, то такой стиль расстановки скобок приемлем. Если же допустимо опускать скобки для однострочников, чтобы не перегружать код скобками, то нужно видеть каждую скобку, поэтому они и ставятся в начале строки.
Если же допустимо опускать скобки для однострочников, чтобы не перегружать код скобками, то нужно видеть каждую скобку, поэтому они и ставятся в начале строки.А нет ли тут шизофрении? Вы разрешаете «опускать скобки, чтобы не перегружать ими код» и тут же посещаете их в такое место, чтобы они сразу бросались в глаза!
А нет ли тут шизофрении?
Нет. Либо обе скобки видны, либо их просто нет.
Вы разрешаете «опускать скобки, чтобы не перегружать ими код» и тут же посещаете их в такое место, чтобы они сразу бросались в глаза!
Именно так. Если скобки есть, то они обе — и открывающая, и закрывающая — должны быть видны. Преимущество такого подхода: если хотя бы одна из скобок не видна, значит, с балансом скобок что-то не так.
А уж если у вас выработалась привычка вставлять пустую строку в начало блока, то перенос скобки туда выглядит абсолютно логичным.
Преимущество такого подхода: если хотя бы одна из скобок не видна, значит, с балансом скобок что-то не так.Если «с балансом скобок что-то не так», то что этот код вообще делает в репозитории? Я уж не говорю о том, что «одна из скобок не видна» может быть просто потому что у вас часть конструкции за край экрана ушла.
А уж если у вас выработалась привычка вставлять пустую строку в начало блока, то перенос скобки туда выглядит абсолютно логичным.Возможно. Но у меня такой привычки нет — именно потому что «обе скобки должны быть видны». Чем больше вы вставляете всяких «пустых» конструкций (пустые строки, отдельно стоящие складочки), тем меньше остаётся места на экране…
Если «с балансом скобок что-то не так», то что этот код вообще делает в репозитории?
Такое тоже бывает. См. посты от PVS Studio.
Я уж не говорю о том, что «одна из скобок не видна» может быть просто потому что у вас часть конструкции за край экрана ушла.
А если скобки ставить с новой строки, то они видны всегда.
Чем больше вы вставляете всяких «пустых» конструкций (пустые строки, отдельно стоящие складочки), тем меньше остаётся места на экране…
Когда я начинал программировать, тоже экономил место. Потом со временем пришёл к тому, что читаемость кода важнее его компактности, поэтому даже в пределах одного блока вставляю пустые строки, чтобы разделить логику в коде, например, отделить объявление переменных от остального кода.
А если вам недостаточно места, то используйте для разработки соответствующее аппаратное обеспечение. Забудьте про ноутбуки с маленькими экранами, используйте нормальный экран с минимум 1200 логических пикселей по вертикали.
Из того, что нашлось в vendor: ...
Что доказывают эти примеры? Вот совершенно легко, не перебирая, нашёл примеры противоположного стиля:
Symfony
Laravel
AngularJS
VueJS
А если окружающий код это тоже «if», «else if»...?
Прошу прощения, не вполне точно выразился. Лучше было сказать, что код внутри блоков «if», «else if», «else», «for», «while» и т.д. отделён отступом от строк, инициализирующих блоки, соответственно, «if», «else if», «else», «for», «while» и т.д. Например, бессмысленный кусок кода для иллюстрации:
#!/usr/bin/perl
my @arr = (3, 2, 1);
my %hash = (k1 => 'v1', k2 => 'v2');
if (@arr) {
if (%hash) {
for my $el (@arr) {
keys %hash;
for (my ($key, $val) = each %hash) {
print "$el$key$val\n";
}
}
} else {
print "$_\n" for @arr;
}
} elsif (%hash) {
print "%hash\n";
} else {
print "No luck, screw it!\n";
}На мой взгляд, отступы достаточно ясно показывают, где ветвления и циклы, а где предложения (или как лучше на русском сказать "statement"?).
В простом коде с одним оператором это выглядит неплохо, а в коде посложнее иногда приходится отделять. Значит читабельность у такого варианта меньше.
Без конкретного примера мне не вполне ясно, о чём тут речь. И кому конкретно приходится отделять. Но если речь о сложных условиях в операторах ветвления — настолько сложных, что за несколько секунд не разобраться, то я вполне согласен с мнением Роберта Мартина в его "Чистом коде", что такое условие следует выносить в функцию, по названию которой будет понятно, о какой проверке речь. Часто бывает нужно не досконально понять условие, а (в терминах Р. Мартина) "прочитать осмысленную историю" на пути к предмету, по-настоящему требующему внимания.
И опять же, лично мне дополнительные пустые строки сами по себе не помогают понять логику того или иного кода. Отступы необходимы, чтобы видеть (а не вычислять) иерархию вложенности блоков. Пустые строки, объединяющие отдельные совокупности предложений по некоторому общему логическому признаку (группы инициализаций, последовательности какого-то вычисления) — бывают полезны для быстрого просмотра кода, хотя ещё полезней часто бывает разбивать длинные простыни на вызовы функций с лаконичными названиями, после чего код читать куда удобнее. И в любом случае, при столкновении со сложным условием лично мне пустые строки не помогут понять его быстрее. Да, есть случаи с многострочными условиями, когда код внутри блока имеет тот же отступ, что и строки условия. Мне это как-то не мешает, б.м., потому, что сталкиваясь с инициализацией блока, сразу ищу открывающую его фигурную скобку (или двоеточие в случае с Python).
Ну и со отдельными скобками как-то посимметричнее выглядит. Особенно с elseif, который с третьего символа начинается.
Что значит "с отдельными скобками"? Когда фигурная скобка открывается на новой строке? Вообще говоря, для разных языков (по крайней мере, для некоторых) существуют в той или иной мере стандартизированные рекомендации по стилю. Например, для PHP есть PSR-1 и PSR-2. Во многих командах также практикуется следовать какому-то общему стилю. Т.е., мы должны понимать, что абсолютно идеального подходящего всем решения попросту нет — Вам удобнее с дополнительными к отступам пустыми строками, а меня это будет отвлекать и раздражать при чтении кода, кому-то хочется видеть открывающие фигурные скобки на отдельной строке, а кому-то отрадно их видеть на последней строке инициализации блока. Такова жизнь.
Что доказывают эти примеры?
Без конкретного примера мне не вполне ясно, о чём тут речь. И кому конкретно приходится отделять.
Хм. Приведенные ссылки и были конкретные примеры. Отделяют авторы кода, разработчики известных проектов. Наверно у них есть причины.
И опять же, лично мне дополнительные пустые строки сами по себе не помогают понять логику того или иного кода.
Это не столько логика, сколько улучшение удобочитаемости. В середине экрана текст сливается, а закрывающая скобка на отдельной строке визуально группирует код не в соответствии с логикой.
При быстром просмотре кода это часто воспринимается как один блок:
}
someCommonAction();
} elseif ($someObject->anotherAttributeLongName !== $someValue) {
foreach ($someObject->anotherAttributeLongName as $item) {
doSomethingWithItem($item);
}разбивать длинные простыни на вызовы функций с лаконичными названиями, после чего код читать куда удобнее
В общем виде это конечно хорошо и правильно, читать может и удобнее. Но вот искать, где ошибка в логике, удобнее далеко не всегда. Потому что эти отдельные функции находятся на одном логическом уровне, внутри них нет сведений о вложенности. Приходится держать в голове весь контекст, что откуда вызывается и при каких условиях, какие данные туда передаются в каждом случае.
Например, для PHP есть PSR-1 и PSR-2. Т.е., мы должны понимать, что абсолютно идеального подходящего всем решения попросту нет
Я про них и говорю. Требования в них основаны на каких-то причинах. Обсудить эти причины ничего не мешает. Идеальное решение я не предлагаю.
К тому же, для классов и функций скобка должна быть на отдельной строке. И на это тоже есть какие-то причины.
Я, конечно, не программист на PHP, но что мешает вместо добавления строк просто переносить саму скобку, как в C#?
if (someLongFunction() === $someLongValue && anotherLongFunction() === $anotherLongValue)
{
if ($someObject->attributeLongName !== $someValue)
{
foreach ($someObject->attributeLongName as $item)
{
doSomethingWithItem($item);
}
someCommonAction();
}
elseif ($someObject->anotherAttributeLongName !== $someValue)
{
foreach ($someObject->anotherAttributeLongName as $item)
{
doSomethingWithItem($item);
}
someCommonAction();
}
}Некоторые люди не находят преимуществ ни в добавлении пустых строк, ни в переносе открывающей скобки на отдельную строку. Кстати, рекомендации PHP-FIG (PSR-1, PSR-2) применительно к ветвлениям и циклам тоже. Хотя, имхо, если уж тратить место на отдельную строку, то хотя бы открывающую скобку туда вставить… :)
if (someLongFunction() === $someLongValue && anotherLongFunction() === $anotherLongValue)
{ if ($someObject->attributeLongName !== $someValue)
{ foreach ($someObject->attributeLongName as $item)
{ doSomethingWithItem($item);
}
someCommonAction();
}
elseif ($someObject->anotherAttributeLongName !== $someValue)
{ foreach ($someObject->anotherAttributeLongName as $item)
{ doSomethingWithItem($item);
}
someCommonAction();
}
}if (someLongFunction() === $someLongValue && anotherLongFunction() === $anotherLongValue) {
if ($someObject->attributeLongName !== $someValue) {
foreach ($someObject->attributeLongName as $item) {
doSomethingWithItem($item); }
someCommonAction(); }
elseif ($someObject->anotherAttributeLongName !== $someValue) {
foreach ($someObject->anotherAttributeLongName as $item) {
doSomethingWithItem($item); }
someCommonAction(); } }if (someLongFunction() === $someLongValue && anotherLongFunction() === $anotherLongValue)
{ if ($someObject->attributeLongName !== $someValue)
{ foreach ($someObject->attributeLongName as $item)
{ doSomethingWithItem($item);
}
someCommonAction();
}
elseif ($someObject->anotherAttributeLongName !== $someValue)
{ foreach ($someObject->anotherAttributeLongName as $item)
{ doSomethingWithItem($item);
}
someCommonAction();
}
}
if (someLongFunction() === $someLongValue && anotherLongFunction() === $anotherLongValue)
{
if ($someObject->attributeLongName !== $someValue)
{
foreach ($someObject->attributeLongName as $item)
{
doSomethingWithItem($item);
}
someCommonAction();
}
elseif ($someObject->anotherAttributeLongName !== $someValue)
{ foreach ($someObject->anotherAttributeLongName as $item)
{
doSomethingWithItem($item);
}
someCommonAction();
}
}
if (someLongFunction() === $someLongValue && anotherLongFunction() === $anotherLongValue) {
if ($someObject->attributeLongName !== $someValue) {
foreach ($someObject->attributeLongName as $item) {
doSomethingWithItem($item);
}
someCommonAction();
} elseif ($someObject->anotherAttributeLongName !== $someValue) {
foreach ($someObject->anotherAttributeLongName as $item) {
doSomethingWithItem($item);
}
someCommonAction();
}
}Можно взять что угодно, разделить это на "да\нет". Какой то с вариантов будет "больше"....
Разработчики, которые пользуются 4х слойной туалетной бумагой, зарабатывают больше, чем те, которые пользуются однослойной
Результаты опроса Stack Overflow 2017: разработчики, которые используют пробелы, зарабатывают больше