
Пример работы нейросети после обучения на базе лиц знаменитостей. Слева — исходный набор изображений 8×8 пикселей на входе нейросети, в центре — результат интерполяции до 32×32 пикселей по предсказанию модели. Справа — реальные фотографии лиц знаменитостей, уменьшенные до 32×32, с которых были получены образцы для левой колонки
Можно ли повышать разрешение фотографий до бесконечности? Можно ли генерировать правдоподобные картины на основе 64 пикселей? Логика подсказывает, что это невозможно. Новая нейросеть от Google Brain считает иначе. Она действительно повышает разрешение фотографий до невероятного уровня.
Такое «сверхповышение» разрешения не является восстановлением исходного изображения по копии низкого разрешения. Это синтез правдоподобной фотографии, которая вероятно могла быть исходным изображением. Это вероятностный процесс.
Когда стоит задача «повысить разрешение» фотографии, но на ней нет деталей для улучшения, то задачей модели является генерация наиболее правдоподобного изображения с точки зрения человека. В свою очередь, сгенерировать реалистичное изображение невозможно, пока модель не создала контуры и не приняла «волевое» решение о том, какие текстуры, формы и паттерны будут присутствовать в разных частях изображения.
Для примера достаточно посмотреть на КДПВ, где в левой колонке реальные тестовые изображения для нейросети. На них отсутствуют детали кожи и волос. Их никоим образом невозможно восстановить традиционными способами интерполяции вроде линейной или бикубической. Однако если предварительной обладать глубокими знаниями о всём разнообразии лиц и их типичных очертаниях (и зная, что здесь нужно увеличить разрешение именно лица), то нейросеть способна совершить фантастическую вещь — и «нарисовать» недостающие детали, которые с наибольшей вероятностью будут там.
Специалисты подразделения Google Brain опубликовали научную работу «Рекурсивное пиксельное суперразрешение», в которой описывают полностью вероятностную модель, обученную на наборе фотографий высокого разрешения и их уменьшенных копиях 8×8 для генерации изображений размером 32×32 из маленьких образцов 8×8.
Модель состоит из двух компонентов, которые обучаются одновременно: кондиционная нейросеть (conditioning network) и приор (prior network). Первая из них эффективно накладывает изображение низкого разрешения на распределение соответствующих изображений высокого разрешения, а вторая моделирует детали высокого разрешения, чтобы сделать финальную версию более реалистичной. Кондиционная нейросеть состоит из блоков ResNet, а приор представляет собой архитектуру PixelCNN.
Схематично модель изображена на иллюстрации.
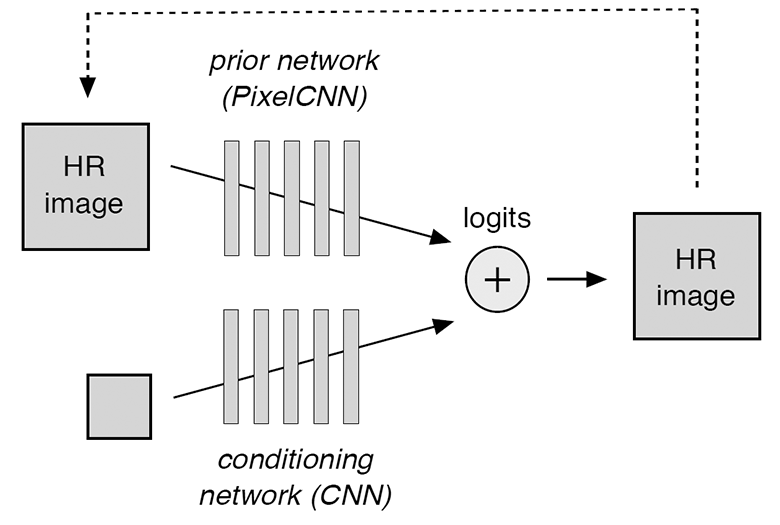
Кондиционная свёрточная нейросеть получает на входе изображения низкого разрешения и выдаёт логиты — значения, которые предсказывают кондиционную логит-вероятность для каждого пикселя изображения с высоким разрешением. В свою очередь, свёрточная нейросеть приор делает предсказания, основанные на предыдущих случайных предсказаниях (обозначены пунктирной линией на схеме). Вероятностное распределение для всей модели вычисляется как softmax-оператор поверх суммы двух наборов логитов с кондиционной нейросети и приора.
Но как оценить качество работы такой сети? Авторы научной работы пришли к выводу, что стандартные метрики типа пикового отношения сигнал/шум (pSNR) и структурного сходства (SSIM) не способны корректно оценить качество предсказания для таких задач сверхсильного увеличения разрешения. По этим метрикам выходит, что лучший результат — это размытые картинки, а не фотореалистичные изображения, на которых чёткие и правдоподобные детали не совпадают по месту размещения с чёткими деталями настоящего изображения. То есть эти метрики pSNR и SSIM крайне консервативны. Исследования показали, что люди легко отзличают реальные фотографии от размытых вариантов, созданных регрессионными методами, а вот отличить сгенерированные нейросетью образцы от реальных фотографий им не так просто.
Посмотрим, какие результаты показывает модель, разработанная в Google Brain и обученная на наборе 200 000 лиц знаменитостей (набор фотографий CelebA) и 2 000 000 спальных комнат (набор фотографий LSUN Bedrooms). Во всех случаях фотографии перед обучением системы были уменьшены до размера 32×32 пикселя, а потом ещё раз до 8×8 методом бикубической интерполяции. Нейросети на TensorFlow обучались на 8 графических процессорах.
Результаты сравнивались по двум основным базам: 1) независимая попиксельная регрессия (Regression) c архитектурой, похожей на нейросеть SRResNet, которая показывает выдающиеся результаты по стандартным метрикам оценки качества интерполяции; 2) поиск ближайшего соседнего элемента (NN), который ищет в базе учебных образцов пониженного разрешения наиболее схожее изображение по близости пикселей в евклидовом пространстве, а затем возвращает соответствующую картинку высокого разрешения, из которой был сгенерирован этот учебный образец.
Нужно заметить, что вероятностная модель выдаёт результаты разного качества, в зависимости от температуры softmax. Вручную было установлено, что оптимальные значения
 лежат между 1,1 и 1,3. Но даже если установить
лежат между 1,1 и 1,3. Но даже если установить  , то всё равно каждый раз результаты будут разными.
, то всё равно каждый раз результаты будут разными.
Различные результаты при запуске модели с температурой softmax
Оценить качестве работы вероятностной модели можете по образцам под спойлером.
Сравнение результатов по спальням




Сравнение результатов по лицам знаменитостей




Для проверки реалистичности результатов учёные провели опрос черед краудсорсинг. Участникам показывали две фотографии: одну настоящую, а вторую сгенерированную различными методами из уменьшенной копии 8×8 и просили указать — какая фотография сделана камерой.
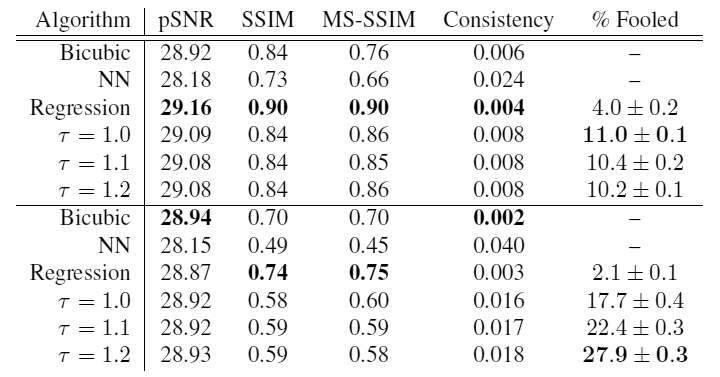
Сверху в таблице — результаты для базы лиц знаменитостей, снизу — для спальных комнат. Как видим, при температуре
на фотографиях спальных комнат модель показала максимальный результат: в 27,9% случаях её выдача оказалась более реалистичной, чем настоящее изображение! Это явный успех. На иллюстрации внизу — самые удачные работы нейросети, в которых она «побила» оригиналы по реалистичности. Для объективности — и некоторые из худших.

В области генерации фотореалистичных изображений с помощью нейросетей сейчас наблюдается очень бурное развитие. В 2017 году мы наверняка услышим много новостей на эту тему.
