Comments 155
И по встраиванию тех же изображений, в MD не хватает нормальной настройки атрибутов, не говоря уже о попытках обернуть картинку в figure, чтобы приделать нормальное название. Хорошо бы этот момент учесть.
Если попытаться засунуть в язык всё на свете, то он уже не будет легковесным. Подпись к картинкам вполне можно сделать и обычнымпараграфом. В легковесный язык имеет смысл вносить лишь те штуки, без которых ну совсем никак.
Только идея про таблицы понравилась. Про довод что символов нет в английской раскладке большинству плевать. Читаемость важнее, например > удобнее чем " для цитирования имхо.
Отзывы огонь!
Набирать угловые скобки не удобно. Читаемость — вопрос привычки.
Пара лишних переключений раскладки клавиатуры — это более неудобно, независимо от того, несколько вы к этому неудобству привыкли.
Поддерживаю. В качестве облегчения страдания от постоянных переключений,
я забиндил на клавишу Alt переключение раскладки и на клавишу Win (while pressed) временную её смену. Стало чуть проще, хотя и к этому варианту тоже нужно привыкнуть.
угловая скобочка есть лишь в английской раскладке.
Ложное заявление
При наборе данного комментария русская раскладка не была переключена ни одного раза (]>_<[)
Ну так возьмите какую-нибудь расширенную раскладку с третьим/четвёртым слоями на альтГР. Сразу появятся и [], и {}, <>, и |, и даже "экзотика" вроде ≠, ±, «».
Где я её возьму?
Добрые люди уже многое наклепали, даже на хабре статьи были https://habr.com/ru/post/450042/.
Набирать цифры с альтом — такое себе удовольствие.
Вопрос привычки, не более. Тем более, что вопрос ведь не в абсолютном, а относительном удобстве (имеется в виду, относительно велосипедных имплементаций маркдаунов).
Циферки люди вводят куда чаще редактирования маркдауов.
Во-первых, всё зависит от области. Я, к примеру, цифры использую редко. А даже когда использую, частенько набираю на нампаде.
Во-вторых, раскладка по ссылке далеко не единственная. Можете поискать сами (надеюсь, в гугле не забанили?) или даже соорудить самостоятельно.
Смысл всей этой дискуссии в том, что спецсимволы на нелатинских раскладках вполне себе есть, и использовать их отсутствие на наиболее популярном ЙЦУКЕНе как аргумент для своего велосипеда не стоит.
Попробуйте типографскую раскладку Ильи Бирмана, там и скобки есть, и тире, и кавычки-ёлочки, и ещё много чего полезного
Ну а смысл проектирования этой разметки, если её нигде и никто не будет использовать, даже автор, потому что рендера не существует в природе. Напоминает специальную олимпиаду.
Есть конвертер в HTML.
Мне кажется, подобные языки разметки лучше всего реализовывать сразу как плагины к pandoc. Тогда почти автоматом появляются конвертеры в/из почти всего, что можно придумать.
Вот я и хотел сказать — все эти MD, вики-разметки и т.д. рендерятся все равно в HTML. Но сразу на HTML, почему-то, никто писать не хочет
Двойной пробел в середине строки — это очень большой wtf. И совсем не понятно где оно заканчивается (у нас не может быть двойного пробела или восклицательного знака в коде?).
В целом markdown'овая отбивка для code отлична. Там даже есть место для указания каким парсером подсвечивать.
Насчёт таблиц — я не видел удачных вариантов, и ваш тоже не очень, увы.
pandoc

Всё понравилось, кроме последних двух пунктов про \ в ссылках и два пробела.
* Со слешами в ссылках возникает визуально неприятный забор типа \\/\//\\ (субьективно).
* Два пробела очень сложно увидеть, особенно если шрифт в редакторе не моноширинный.
Тут вполне реально придумать более лучшие варианты, если ещё поднапрячься.
Например, если развивать идею с удвоенными символами, почему бы не использовать ;; ,,?
Еще можно использовать %%. Такое сочетание символов иногда используется в текстах в смысле "проценты", но этим можно пренебречь. Символ % действительно используется в гиперссылках, но удвоенный вроде не встречается.
Ещё осталось неиспользованным ::, но оно будет конфликтовать с кодом на C++, Rust, и т.п.
Если конкретно, то я бы предложил использовать для инлайна либо \\ (можно провести некоторую смутную аналогию с эскейпингом в строковых литералах), либо ,, (должно выглядеть красивее и визуально похоже на кавычки, но путаницы при этом вызывать не должно).
Для ссылок можно попробовать использовать %%. В качестве разделителя при этом сойдёт хотя бы и ;;
%%Ссылка;;https://ru.wikipedia.org/wiki%2F%D0%A1%D1%81%D1%8B%D0%BB%D0%BA%D0%B0%%
Признаю, что выглядит не фиг лучше, чем \\, но как вариант.
Два пробела очень сложно увидеть, особенно если шрифт в редакторе не моноширинный.
Если шрифт не моноширинный, то поедут ещё и все отступы в преформатированных блоках. По факту шрифт в редакторах для редактирования легковесных форматов обязан быть моноширинным.
Например, если развивать идею с удвоенными символами, почему бы не использовать ;; ,,?
Потому, что порой надо выводить именно эти (в том числе и удвоенные) символы: ;;, ,,. Особенно при описании спецсимволов такого вот легковесного формата.
я бы предложил использовать для инлайна либо \
Какая-нибудь регулярка в таком случае будет выглядеть так: \\/\t\\\\/\\ вместо /\t\\\\/
%%Ссылка;;https://ru.wikipedia.org/wiki%2F%D0%A1%D1%81%D1%8B%D0%BB%D0%BA%D0%B0%%
В этом случае у пользователя будет рябить в глазах от процентов, от чего он будет чаще ошибаться, и ему сложнее будет искать границы ссылки, особенно, когда идёт несколько ссылок подряд.
А что там в ямлах с пробелами?
10 советов для хейтеров YAML.
У меня тут тоже много претензий к ямлу:
https://m.habr.com/ru/post/503240/
Но отступы — это всё же совсем иная тема.
Пробелы выглядят спорным решением, но в целом неплохо, хотя я все эти упрощённые языки не жалую — у всех свои потребности и многим чего-то будет не хватать. Я бы хотел подобный читаемый синтаксис, который один к одному конвертируется а docbook, но понятно что это только мечта.
Так что мешает взять и сделать?
Лень видимо, для моей задачи у меня исторически сложилась надстройка над латехом легко конвертируемая (не пинайте, регексами) в докбук и переделка всего этого это большой объём работы не приносящий значимого результата, есть мысль хотя бы на чистый докбук перейти, но опять же, только для нового, когда английская версия будет делаться..
Так-то MarkedText у меня тоже регулярками парсится. Вот, например, регулярка, что разбивает текст на блоки:
$hyoo_marked_flow == /^(?:(--\r?\n)|((?:((?:=){1,6})) (?:((?:[\s\S]){1,}?))\r?\n)|((?:(?:((?: ){0,}?))(?:(-|\+)) (?:((?:[\s\S]){1,}?))\r?\n){1,})|((?:(?:(")) (?:((?:[\s\S]){1,}?))\r?\n){1,})|((?:(?:((?: ){0,}?))(?:(!)) (?:((?:[\s\S]){1,}?))\r?\n){1,})|((?: (?:( |\+\+|--|\*\*))(?:((?:[\s\S]){1,}?))\r?\n){1,})|((?:((?:[\s\S]){0,}?))\r?\n))/gmuА эта ищет инлайн форматирование:
$hyoo_marked_line === /(?:((?:(\*\*))(?:((?:[\s\S]){1,}?))\*\*)|((?:(\/\/))(?:((?:[\s\S]){1,}?))\/\/)|((?:(\+\+))(?:((?:[\s\S]){1,}?))\+\+)|((?:(--))(?:((?:[\s\S]){1,}?))--)|((?:( ))(?:((?:[\s\S]){1,}?)) )|((?:(\\\\))(?:(?:((?:[\s\S]){1,}?))\\){0,1}(?:((?:[^\\]){0,}?))\\\\)|((?:(""))(?:(?:((?:[\s\S]){1,}?))\\){0,1}(?:((?:[^\\]){0,}?))""))/guВсе это неподдерживаемо даже для простых случаем, надо грамматику описать, bnf какой.
Я же не руками их пишу: https://github.com/hyoo-ru/marked.hyoo.ru/blob/master/flow/flow.ts
BNF для маркдауна — это сложно, но можно парсер написать. Регулярки, конечно, не дело.
Почему? Есть всякие расширенные версии и умные парсерогенераторы, я не спец, но помню что автор одного из таких утверждал что его решение может распарсить всё что напишете.
В Markdown очень много заморочек с пробелами, переносами строк и другими контекстыми вещами — для правильного парсера нужно прописывать много сторонней логики, а она плохо вписывается в КС грамматику. Есть еще статья Why isn't there a formal grammar for Markdown?, но я с ней не совсем согласен.
Хотя в настоящее время я пробую сделать грамматику Markdown для ANTLR, посмотрим что получится.
Вышеупомянутый генератор http://blog.erezsh.com/how-to-write-a-dsl-in-python-with-lark/
Посмотрел — это просто еще один генератор парсеров на основе EBNF грамматик. С парсингом Markdown у него будут такие же проблемы, как и у ANTLR.
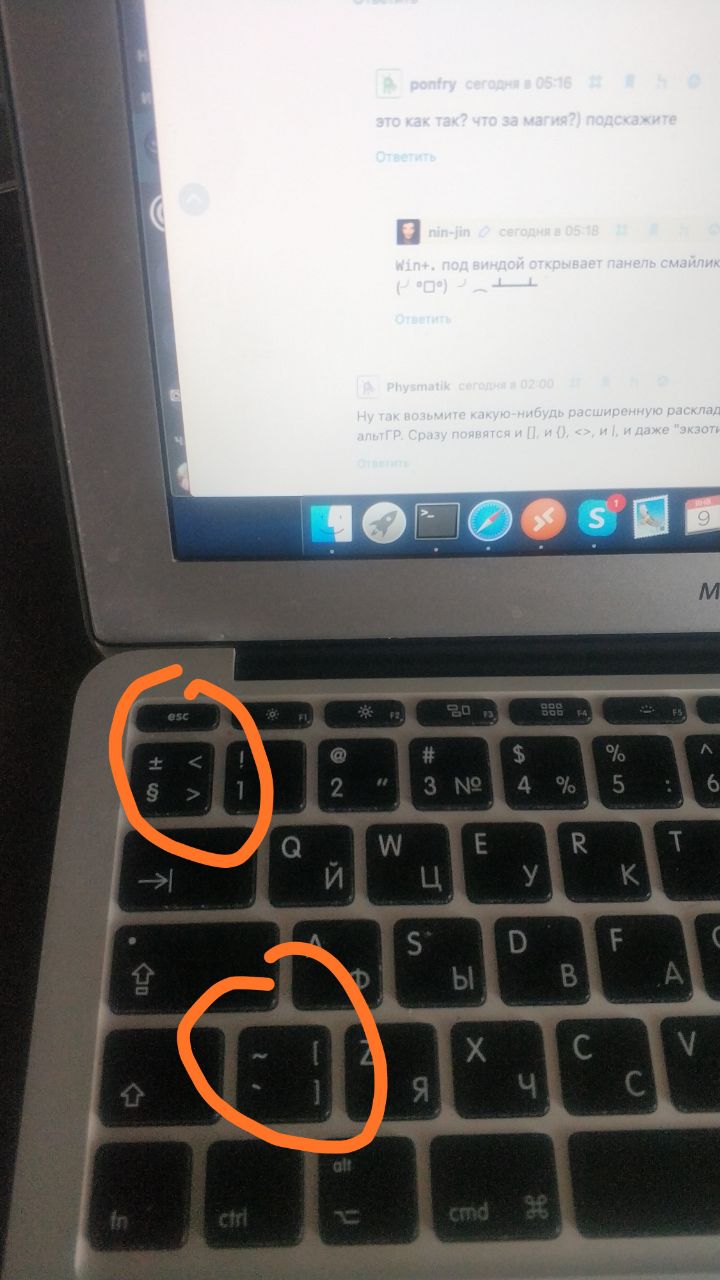
В русской раскладке:
| = alt + shift + 1
< = alt + shift +,
> = alt + shift +.
{ = alt + 9
} = alt + 0
Заявленная расширяемость не достигнута. Например, pandoc markdown позволяет много где указать {значения=атрибутов}, чтобы не изобретать синтаксис для редкоиспользуемых вещей, вроде размера изображений или вставок/удалений. Атрибуты потом доступны парсеру, например, чтобы реализовать ваш великолепный синтаксис таблиц как плагин.
Для ссылок не хватает синтаксиса, когда в тексте название ([там][there]), а URL отдельно ([there]: https://...) — удобно для длинных адресов или если надо повторить ссылки, например, в конце статьи. В стиле MarkedText было бы что-то вроде ""там\(there)"".
Эти сноски не очень удобно поддерживать. Если ссылка совсем уж длинная, то проще воспользоваться сокращателем ссылок.
А расширяемость достигается за счёт единых ограничений на синтаксис, позволяющих всем синтаксическим конструкциям быть ортогональными. Для добавления своего синтаксиса достаточно взять любой свободный символ и либо использовать его как префикс блока, либо продублировать и использовать как кавычку инлайн форматирования.
Удобство субъективно, но сокращатель ссылок — точно лишняя сущность и точка отказа (сервис лег, ссылка протухла). Оригинальную ссылку даже записать некуда, так как в MarkedText нет комментариев, которые не показываются при рендеринге.
{kind=link}
Сокращалка ссылок означает, что я не могу посмотреть на ссылку и решить, нужно ли мне по ней переходить вообще.
Кроме того, это никак не решает другую проблему: если текст в формате markdown пишется для того, чтобы читали собственно текст в формате markdown, а не получаемый из него HTML¹, то при ограничении ширины одной строки в N символов (от N тут зависит только то, насколько часто возникает проблема, поэтому я не привёл конкретное число), без такого синтаксиса будет часто встречаться ситуация, когда одна строка слишком короткая (и, возможно, содержит только часть текста ссылки), а на следующей URL и последнее слово текста ссылки. Иметь слишком короткую строку мне не нравится, как и разрывать текст ссылки в случае, если он состоит из нескольких слов. Загромождать текст URL, когда URL ведёт на какой‐то справочный материал, нужный только тем, кто не знает термин из текста ссылки, тоже не очень.
И что не так с поддержкой таких ссылок? Там же не требуется оставлять ссылки в порядке их упоминания в тексте или даже присваивать им номера.
Кстати, двойной пробел не годится по таким же соображениям: если текст пишется, чтобы читаться «как есть», а не в виде HTML, то двойной пробел в тексте может возникнуть как минимум по следующим причинам:
- Отступ. И да, иногда начинать даже абзац с кода, встроенного в строку, нужно. А тут вопрос, можно ли начать строку с кода, что совсем не то же самое.
- Конец предложения. В английском языке, вообще‐то, (было) принято делать двойной пробел после конца предложения, просто это сейчас мало кто соблюдает. В качестве примера можете посмотреть в документацию Vim. В русском языке, насколько мне известно, такого принято не было, но вы ведь не только для русского предлагаете?
- Выравнивание. Иногда текст выглядит лучше, если какой‐то элемент расположен строго под другим.
- Просто ошибка.
Замечу, что только конец предложения и выравнивание не могут появится у того, кто беспокоится только о результирующем HTML. Отступ возникнет при использовании списков. Ошибка может быть допущена всегда. А ещё конец предложения абсолютно корректен во всех других известных мне форматах разметки, и может даже быть привычкой: посмотрите, к примеру, на сообщения Bram Moolenaar в vim-dev.
¹: Ситуация у меня возникает, как правило, в трёх случаях:
- если нет штатной возможности использовать форматирование;
- если я хочу отправить письмо в виде простого текста;
- если я пишу README — обычно то, для чего я пишу README не выкладывается на github/…, и смотрят результат все (включая меня) текстовым редактором.
Сокращалка ссылок означает, что я не могу посмотреть на ссылку и решить, нужно ли мне по ней переходить вообще.
Это должно быть понятно из текста ссылки, а не из урла.
на следующей URL и последнее слово текста ссылки
Ставьте пробел после последнего слова и оно не будет переноситься.
И что не так с поддержкой таких ссылок?
Да всё так, но если совать в формат всё подряд, то он резко потеряет в простоте и уже для него потребуется "облегчённая версия". У сносок есть один существенный недостаток — нелокальность. Чтобы они правильно работали нужно распарсить весь текст. При этом конкатенация и сплит текста резко становятся нетривиальными операциями. Однако сноски не кажутся столь уж необходимыми — можно легко обойтись и без них.
Отступ. И да, иногда начинать даже абзац с кода, встроенного в строку, нужно. А тут вопрос, можно ли начать строку с кода, что совсем не то же самое.
Проверьте сами: https://marked.hyoo.ru/#marked=%20%20%D0%BA%D0%BE%D0%B4%20%20%D0%BD%D0%B5%20%D0%BA%D0%BE%D0%B4/html
В английском языке, вообще‐то, (было) принято делать двойной пробел после конца предложения, просто это сейчас мало кто соблюдает.
Атавизмы не вижу особого смысла поддерживать.
Выравнивание. Иногда текст выглядит лучше, если какой‐то элемент расположен строго под другим.
Для этого есть преформатированные блоки.
Ошибка может быть допущена всегда.
И везде, пробелы тут не уникальны.
Это должно быть понятно из текста ссылки, а не из урла.
Кому должно? Язык это как‐то гарантирует?
Ставьте пробел после последнего слова и оно не будет переноситься.
Чтобы пробел оказался в ссылке? Кроме того, я говорил про слишком короткую строку из‐за URL. Пробел с этим не поможет ровным счётом никак.
Проверьте сами: …
Markdown хорош в том числе потому, что на нём можно писать письма в plain text и их будут понимать в таком виде. Судя по тому, что я увидел на сайте, у вас новая строка — это всегда новый абзац, а элемент списка не может содержать несколько абзацев. Первое неприемлемо для писем в plain text. Второе — просто недостаток по сравнению с markdown.
Для этого есть преформатированные блоки.
Это не в тему. Если я хочу что‐то выровнять в исходном коде, это не значит, что я хочу что‐то выровнять в результирующем HTML. (Или что оно там не выравнивается другими средствами, впрочем к вашему языку это не относится.) Или, скорее, это не значит, что я считаю, что оформление текста как кода будет выглядеть лучше, чем отсутствие выравнивания в результате.
И везде, пробелы тут не уникальны.
Нажать пробел два раза не проблема — вам даже не нужно промахиваться клавишей. Или скопировать что‐то, ошибившись с границей на символ. Заметить это сложно, всего лишь два пробела не производят визуального мусора. Кроме того, все имевшие дело с программированием привыкли, что за некоторыми исключениями количество пробелов не имеет значения, что делает результат ошибки неожиданным.
Кому должно? Язык это как‐то гарантирует?
У автора есть выбор: вставить сноску или переформулировать текст, чтобы было понятно куда ведёт ссылка. Второе предпочтительнее независимо от поддержки сносок.
Чтобы пробел оказался в ссылке?
Да, ничего страшного не произойдёт.
Кроме того, я говорил про слишком короткую строку из‐за URL. Пробел с этим не поможет ровным счётом никак.
Это вообще не проблема.
Первое неприемлемо для писем в plain text.
Вполне приемлемо. И если уж говорить про plain text, то в нём вы получите ровно то, что ввели, сколько бы переводов строк ни использовали.
Второе — просто недостаток по сравнению с markdown.
Согласен, добавил поддержку любого содержимого в элементах списков.
Если я хочу что‐то выровнять в исходном коде, это не значит, что я хочу что‐то выровнять в результирующем HTML.
Вы хотите писать как попало, но получать что хотите? Довольно бессмысленная хотелка.
все имевшие дело с программированием привыкли, что за некоторыми исключениями количество пробелов не имеет значения
Отвыкайте уже говорить за всех. Да и от незначимости пробелов тоже отвыкайте. Python, YAML, TOML, Tree — полно языков со значимыми пробелами. А в остальных языках по рукам всё равно бьют линтеры, приучая внимательно относиться ко всем символам.
# Indentation (tabs and/or spaces) is allowed but not requiredВзято отсюда: github.com/toml-lang/toml#example
Python, YAML, TOML, Tree — полно языков со значимыми пробелами.
В каком из этих языков значимы пробелы в середине выражения, а не в начале, где они все ещё достаточно хорошо заметны?
YAML, Tree
Например в YAML, следующие пары выражений, отличающиеся только количеством пробелов, не эквивалентны?
[apple, orange, fig]
[apple, orange, fig]
name: John
name: John
- yes:no
- yes :no
- yes: no
- yes : no[
"yes:no",
"yes :no",
{
"true": false
},
{
"true": false
}
]Меня интересовал кейс, когда значимо различие "1 пробел" vs "2 пробела", а не полное отсутствие пробела.
В Питоне такого вроде бы нет, в Tree есть.
А что за Tree? Гугл выдаёт только плагины к markdown и какую-то грамматику
Вы хотите писать как попало, но получать что хотите? Довольно бессмысленная хотелка.
Самая что ни есть осмысленная: писать так, как удобно человеку, а не компьютеру. Markdown как раз об этом. Для сравнения, reStructuredText более формальный, процветает в своей нише документации.
Python, YAML, TOML, Tree — полно языков со значимыми пробелами.
Это языки программирования и конфигурации. А сколько языков разметки текста с таким подходом?
Человеку удобно вообще не заниматься форматированием, однако, приходится объяснять компьютеру что ты от него хочешь. Чем проще и однозначней синтаксис, тем проще это сделать. А попытки угадать что имел ввиду пользователь вырождаются в YAML с многотомными спецификациями, которые всё-равно никто полностью не знает.
Что дозволено языку конфигурации не дозволено языку разметки текста?
Объяснять компьютеру желательно только там, где без этого никак. Если пользователь представляет себе список, который должен получиться, как 1), 2), 3) и так и пишет, чем ему поможет любой другой синтаксис?
Программы и конфигурации пишутся для компьютера специалистом, который специально свое решение в формальном виде представлял и синтаксис учил, потому что понимает — будет выполнено так, как написано. Тексты пишут люди без специальных знаний и попыток говорить на языке машины. Факт, что им удобно, когда компьютер правильно догадывается — Google OneBox, колдунщики Яндекса.
У автора есть выбор: вставить сноску или переформулировать текст, чтобы было понятно куда ведёт ссылка. Второе предпочтительнее независимо от поддержки сносок.
Это не значит, что все так делают.
Да, ничего страшного не произойдёт.
Просто будет некрасиво.
Вы хотите писать как попало, но получать что хотите? Довольно бессмысленная хотелка.
Почему «как попало»? Я хочу, чтобы в исходниках было красиво, а в HTML хотя бы читаемо.
Отвыкайте уже говорить за всех. Да и от незначимости пробелов тоже отвыкайте. Python, YAML, TOML, Tree — полно языков со значимыми пробелами. А в остальных языках по рукам всё равно бьют линтеры, приучая внимательно относиться ко всем символам.
А сколько языков со значимыми пробелами в середине строки? В Python, YAML и TOML если вы можете написать в каком‐то месте один пробел, то превращение его в два может изменить семантику ровно в двух случаях:
- Вы находитесь внутри строкового литерала или чего‐то подобного, где пробел имеет значение «байт 0x20».
- Вы находитесь в начале строки, где пробел означает отступ.
Если в этих языках пробел в некоторой позиции просто разделяет токены, его всегда можно безбоязненно удваивать, что очень часто используется для выравнивания.
(Возможно, за исключением tree. Я его не использовал и не знаю спецификации.)
Ака ilyabirman.ru/projects/typography-layout только для маркдауна.
Потому что пытаться изобрести новый стандарт взамен настолько популярному довольно неблагодарная задача. А вот упростить работу с текущей можно. Особенно когда вся статья начинается с посыла «у меня нету таких символов на клавиатуре»
Проблемы можно решать только для себя, а можно сразу для всех. Я не на столько эгоцентричен, чтобы заставлять каждого пользователя постоянно решать одни и те же проблемы.
Отдельный формат тоже заставляет каждого его пользователя прилагать усилия на его изучение, на поиск/установку плагинов для IDE, на убеждение всех в комманде что именно этот формат лучше чем тот что поддерживается везде по дефолту и т.п
— Linux — искаропки
— macOS — искаропки
— Windows — recaps
Как ни крути, а в кириллической раскладке со спецсимволами всю дорогу ерунда.
И это не исправить пока 33 > 26.
— Справа внизу (Linux) или справа вверху (MacOS) — флажочек.
— Cправа вверху (PC keyboard) или слева посредине (MacBook) горит CapsLock.
Всё это ловится боковым зрением.
Конечно же держать в голове смысла нет, потому что щелкаешь мизинцем туда-сюда и не факт что переключил куда надо. Ну и
PS. Эх, помнится под DOS'ом была переключала, на русском расцвечивала border CGI-экрана в красный цвет. Вот там точно невозможно было промахнуться раскладкой.
У меня разные раскладки на разных шифтах. Это всё равно напрягает при частом переключении.
Погроммисты привыкли всё время сидеть в en, поэтому иногда с удивлением обнаруживают, что 95% нормальных людей имеют дефолтной раскладкой ru (внезапно!). И крайне редко переключаются в en.
Т.к. на хабре в основном тусят ИТшники, то Ваши проблемы здесь видятся необычными. Уж простите уж, нам/им из-за облаков плохо видно проблемы этих ваших человеков.
Спасибо за саму попытку провести мысленный эксперимент, редкость ныне.
Меж тем, идеи для заголовков и таблиц — окупили все затраты.
Два замечания:
- Где-то символ-идентификатор должен быть отбит пробелом, где-то (в инлайновых) — нет. Может просто принять, что маркер — это два "редких" символа подряд?
- Преформатированный текст в инлайне, если будет определяться двумя пробелами, также будет очень ·сложно заметить· среди тысячи разрывов. В том числе и два ошибочных пробела. Может поискать дополнительные сочетания, например:
::?
В инлайн форматировании удвоение — вынужденная мера, в префиксах блоков же в этом нет необходимости и можно сделать более наглядно для восприятия. А удвоение можно задействовать в иных целях:
- показывать уровень заголовка
- объединять ячейки таблицы
По поводу пробелов можно много спекулировать в обе стороны, но думаю стоит попробовать, чтобы понять насколько это удобно/неудобно.
Так а что не так с AsciiDoc-то?
К markdown есть такие вопросы:
- Как сделать ссылку не на внешний документ, а на загловок в этом же документе.
- <!-- комментарии делать как в html -->
- Как делать сноски
- Почему heading абсолютный, и нет относительного
- Как вложить таблицу в таблицу
- URL-ы допускают кодирование данных в самом урл например картинок. Можно гигабайтные видео вставлять, архивы, музыку, исполняемые файлы… или просто печатную версию документа в pdf. Или есть какие-то ограничения?
BBCode не является легковесным — это практически HTML с квадратными скобками вместо угловыхТак и в markdown допускается голый html если markdown-а не хватило => скрипты, стили, чудеса unicode-а, webgl… короче еще и санитайзеры надо.
А вот что не так с tex-ом? Может чуть более чем всё.
Он не является легковесным языком.
Как сделать ссылку не на внешний документ, а на загловок в этом же документе.
[ссылка на заголовок](#some-header)Почему heading абсолютный, и нет относительного
Потому что относительный плохо читается человеком.
Как вложить таблицу в таблицу
Оригинальный маркдаун вообще таблицы не поддерживает и предлагает использовать html.
Или есть какие-то ограничения?
Ограничения есть всегда, но не задача формата разметки их регламентировать.
Так и в markdown допускается голый html
Это скорее не "в", а "между". HTML частью синтаксиса маркдауна не является.
Я бы предложил альтернативный синтаксис:
!== Сравнительная таблица
! **Язык**
!(+) **Плюсы**
!(-) **Минусы**
!--
! MarkedText (modified)
!(+)
- Те же, что и в MarkedText
- Строки таблицы чётко разделены с помощью `!--` (фактически это просто вариант `--`);
- Новый столбец всегда начинается с `!` в начале строки, поэтому дополнительные уровни не нужны (хотя и не возбраняются!); при малом количестве столбцов (2-4) их нетрудно считать, при большом - см. ниже.
- Как следствие, ещё более удобное редактирование таблиц, потому что не нужно следить за отступами, особенно при большом количестве колонок. Текст каждой ячейки -- обычный текст.
И в ячейку можно безбозяненно вставлять обычные параграфы. Пустые строки не разорвут ячейку таблицы -- нужен либо маркер новой колонки/строки, либо конца таблицы.
- У таблицы есть маркеры начала `!==` (фактически вариант оглавления, с опциональным текстом для заголовка таблицы) и конца `==!` (тоже с опциональным текстом для удобства поиска конца длинной таблицы; парсер должен игнорировать его).
!==
! И поэтому можно вставлять вложенные таблицы!
==!
- Опциональные маркеры колонок `!(...)` позволяют помнить где какая колонка в длинных таблицах с большим количеством колонок и информации, как если бы заголовок был "прибит" при скроллинге. Текст маркера -- произвольный, парсер его должен игнорировать. Можно вставить номера колонок, можно -- символические имена, на свой вкус. Здесь я пометил колонки "(+)" и "(-)", и вот, наконец, мы дошли до колонки "(-)". Мы ещё помним её?
!(-)
- Тоже нет инструментов
!--
! MarkedText
!(+)
- Удобное редактирование таблиц.
- Поддержка сложного форматирования внутри ячеек.
- Простота реализации.
- Легко запоминающийся консистентный синтаксис.
- Удобство редактирования в русской раскладке.
- Колонки не расползаются далеко вправо за горизонтальный скроллинг и не переносятся на новую строку.
!(-)
- Не поддерживается пока что никакими сторонними инструментами.
- При большом количестве колонок с кучей информации, последние колонки трудно отследить пока до них доберёшься.
==! Сравнительная таблицаКроме этого, я бы добавил ещё одно опциональное расширение для строк таблиц:
![r:c] — где r — rowspan, c — colspan. Если значение равно 1, его можно опустить. Значение "*" — span до конца таблицы. Примеры:
![2:3] - ячейка займёт 2 строки и 3 столбца
![2:] - 2 строки, 1 столбец
![*:] - столбец до конца таблицы
![:*] - строка до конца таблицыДвойной пробел для monospaced — на любителя; должна быть альтернатива (те же backticks) для тех, кто хочет выделять inline-блоки явно и не бояться, что какой-нибудь автоформаттер в редакторе выкинет все "лишние" пробелы.
У вас потерялась двумерность структуры, из-за чего выискивать глазами ячейки из одной колонки крайне сложно.
Насчёт спанов, я ещё не продумал, но идея такая:
- Пропуская некоторые уровни отступов получаются горизонтальные спаны.
- Дублируя маркер получаются вертикальные спаны.
То есть как-то так:
! 2x1
!! 1x2
! 1x1
! 1x1должна быть альтернатива
Либерализм в синтаксисе ни к чему хорошему не приводит. Лучше простой и однозначный синтаксис, без вольностей.
У вас потерялась двумерность структуры
Она фактически потерялась и с отступами, потому что в сложных таблицах следить за отступами — морока. При этом с отступами усложнилось редактирование. А представьте таблицу с 10 колонками, и в каждой ячейке по абзацу текста, и всё это на пару-другую экранов. Замучаетесь отступы считать и сопоставлять колонки с заголовком. А если там вложенная таблица...
Кроме того, я написал, что отступы не возбраняются: хотите своё 1.5D — делайте на здоровье, парсер проигнорирует начальные пробелы.
Она фактически потерялась и с отступами, потому что в сложных таблицах следить за отступами — морока.
Не потерялась. А следить за отступами всё равно придётся. Или вложенные списки и цитаты вы тоже будете в плоском виде выводить?
Замучаетесь отступы считать и сопоставлять колонки с заголовком.
Навёл указатель мыши и проскроллил.
А следить за отступами всё равно придётся.
Я не против, пока не нужно отслеживать их дальше, чем 5-7 строк максимум (пусть даже через схлопывание уровней). Иначе я предпочитаю символические имена.
Или вложенные списки и цитаты вы тоже будете в плоском виде выводить?
В принципе, таблицы и вложенные списки — это родственники, и у списков та же проблема с пунктами сложной структуры, что и у таблиц. Так что было бы неплохо и для списков иметь "плоский" синтаксис, позволяющий делать такие вещи.
Редактирование списков в нынешних "умных" редакторах меня постоянно выбешивает, ничего сложнее одного параграфа туда практически не вставить, а если список многоуровневый, то это вообще аллес капут.
Навёл указатель мыши и проскроллил.
… сказал человек, который борется за каждый keystroke.
В принципе да, логически список — это таблица из одной колонки. Но обозначать элемент списка вертикальной чертой или ячейку таблицы дефисом — несколько противоестественно.
В том редакторе, что разрабатывал я, в список можно было засунуть что угодно. Но он, к сожалению, не дожил до прода.
Я не борюсь за каждое нажатие, я борюсь за удобство редактирования. Порой его можно повысить практически бесплатно, просто заменив один символ на другой. И порой новый символ подходит даже лучше оригинала.
Но обозначать элемент списка вертикальной чертой или ячейку таблицы дефисом — несколько противоестественно.
Моё понимание таково: вертикальная черта или дефис или плюсик — это не столько обозначения элементов, сколько индикаторы стиля форматирования:
- item: "вывести как элемент ненумерованного списка",
+ item: "вывести как элемент нумерованного списка",
! item: "вывести как ячейку таблицы".
Структура данных одна и та же, отличается лишь визуальное представление.
Так как таблица — это список списков, то, тупо заменив "-" на "!" в обычном списке глубины 2, мы должны получить что-то типа
!
! item 1,1
! item 1,2
! item 1,3
!
! item 2,1
! item 2,2
! item 2,3 — и это само по себе уже должно быть выдано в табличной форме, без дополнительных телодвижений. Всё остальное — сахар и устранение неоднозначностей: !-- вместо голого ! в строках позволяет не заботиться об отступах колонок и открывает возможность вставлять в элементы любой контент (кроме таблиц); а !== и ==! позволяют также вкладывать и таблицы.
Должно работать и в обратную сторону: если в получившемся "плоском" синтаксисе таблиц заменить все ! обратно на - или +, то получится "плоский" синтаксис для обычных списков, способных принять сложную структуру текста в качестве содержимого элементов:
+==
+ Example 1
This item contains:
- An inner unnumbered list
- Of two items
+==
+ An inner numbered list
+ Of two items
==+
+ This should work too
+ Because of the indentation.
! A inner table
! With two rows
! And a single column
Note that these inner lists and a table and this paragraph do not cause ambiguity here. If we didn't bracket the first inner numbered list into `+== ... ==+`, then it would cause a confusion due to lack of indentation.
+ Example 2
Note that we can still continue counting 1-level items despite all the line breaks, because we didn't reach the end-of-list market yet, so any `+` in a first position means a new list item.
If we use complex item structure, then we must use `+== ... ==+` brackets to mark the end of the list.
+--
Example 3
+ This inner numbered list without indentation
+ Does not cause ambiguity
+ Because we started to use `+--` as an item delimiter
+ (like in a table row case)
+ So now we expect either a next `+--`, or the end of the list.
+ If we use `+--`, the we must also use `+== ... ==+` brackets to stop
==+Либерализм в синтаксисе ни к чему хорошему не приводит. Лучше простой и однозначный синтаксис, без вольностей.
С таблицами не всё так однозначно. Ваш вариант лучше markdown, когда в ячейках много текста, но его не удобно читать и с большим количеством колонок он не очень удобен. Вариант markdown лучше читается, если в таблице немного нешироких колонок, но редактировать его неудобно. Лучше всего с таблицами в reStructuredText, где их четыре варианта (но из четырёх вариантов grid table, правда, весьма неудобен для написания и не слишком нужен): simple table для таблиц без большого количества текста в столбцах, csv для отображения чего‐то генерируемого, list на случай, когда текст не влезает нормально в simple. Эти три нормально редактируются и два из трёх (кроме csv) нормально читаются (насколько вообще нормально могут читаться таблицы в plaintext).
Зачем вообще нужно, чтобы таблицы можно было записать единственным способом?
Всего-то надо:
— интерпретаторы кнопок в маркдаун-разметку;
— панель с кнопками над окном (полем) с текстом;
— окно/панель/колонка WYSIWYG-превью и возможность сделать его основным (а окно/панель/колонку с маркдауном скрыть).
Если такое уже реализовано, вопрос снят, просто сообщите имя программы. :)
Панель ввода комментария и есть такой редактор :)
WYSIWYG-редакторы языков разметки неудобны:
- дольше тянуться мышью, чем вбить разметку;
- diff после такого редактора неряшлив (длинные строки, приведение существующей разметки к "стандартному" для редактора виду);
- не поддерживает или, хуже, портит расширенную разметку.
Ребят, спасибо за обсуждение двойных пробелов. Это позволило выявить критичную проблему, когда перенос текста происходит как раз по двойному пробелу. В этом случае без подсветки переводов строк невозможно понять число пробелов. Поэтому я поменял маркер инлайн кода на ;;.
Таблицы особенно понравились!
А вот ссылки совершенно нечитаемы, может лучше для них использовать двойные скобки с последним пробелом разделителем? Если ссылка нужна в скобках, то будут тройные скобки.
((Ссылка на подвал https://habr.com/#footer))
((habr.com))
Habr (((habr.com)))
((""http://img.habr.com/1.png"" http://habr.com))
E-mail: ((mailto::info@habr.com))
""Рисунок 1 http://habr.com/pic1.png""Последняя строка это картинка с alt и title атрибутом, без ссылки.
К сожалению, в таком случае невозможно отличить скобку, как часть урла, от скобки вокруг ссылки. Битые ссылки — типичное следствие этого в маркдаунах.
Любая ссылка будет заканчиваться пробелом, возможно после каких-либо знаков, или концом строки, внутри ссылки пробела уже быть не может, любые скобки внутри ссылки легко можно пропустить, лишь в тексте ссылки не может быть двойных закрывающих ссылок. Но это всё если простыми регулярками парсить, скобки идут всегда парами, если следить за количеством открывающих скобок, то можно надёжно выделить ссылку, в которой может быть и сложное описание со множеством скобок.
В русской раскладке лишь круглые скобки доступны, и их можно вполне использовать для разметки, даже удобнее других символов, так как они идут парой, и возможно делать вложенные структуры.
Пример ((поиска https://yandex.ru/search/touch/?text=(test%20(abc))&oprnd=2395118338&mda=0&lr=213)).Здесь после первой пары )) до второй пары )) нет пробелов, очень легко определить ссылку.
Вместо отступов у таблиц можно сделать двойной восклицательный знак у ячеек, у новых строк один:
! 1.1
!! 1.2
!! 1.3
! 2.1
!!/2 2.2-3Из Textile можно взять align, colspan, rowspan, как пример, последняя строка это colspan=2.
По поводу форматирования кода, можно вполне использовать символы, отсутствующие в русской раскладке, ведь код набирают в английской раскладке, кавычки всё же лучше выглядят:
``code``
;;code;;Тексты я пишу на русском, но большая часть спецсимволов есть только в английской раскладке клавиатуры.
Знакомая проблема. В Notepad++ я решил её через плагин jN следующим кодом:
// trdm 2020-02-17 10:21:08
// script: trdmUtil.js
function typeSymbol( psSymb ) { Editor.currentView.selection = psSymb; }
function addHotSym(psFu, psKey) {
var rv = {
ctrl: false,
shift: false,
alt: true,
key: psKey, // "I"
cmd: psFu
};
addHotKey(rv); // Различные клавиши <>
}
// Ввоод символов в русской раскладке схема Alt+' >> ' ; Alt+$ >> $. Можно не переключать раскладку.
function typeSymbol_1() { typeSymbol( '<' );} addHotSym(typeSymbol_1,0xBC);
function typeSymbol_3() { typeSymbol( '\'' );} addHotSym(typeSymbol_3,0xDE);
function typeSymbol_2() { typeSymbol( '>' );} addHotSym(typeSymbol_2,0xBE);
function typeSymbol_4() { typeSymbol( '~' );} addHotSym(typeSymbol_4,0xC0);
function typeSymbol_5() { typeSymbol( '$' );} addHotSym(typeSymbol_5,0x34);//$
function typeSymbol_6() { typeSymbol( '#' );} addHotSym(typeSymbol_6,0x33); //#########
function typeSymbol_7() { typeSymbol( '|' );} addHotSym(typeSymbol_7,0xDC); //
function typeSymbol_8() { typeSymbol( '[' );} addHotSym(typeSymbol_8,0xDB); //
function typeSymbol_9() { typeSymbol( ']' );} addHotSym(typeSymbol_9,0xDD); //
function typeSymbol_10() { typeSymbol( '\'' );} addHotSym(typeSymbol_10,0xDE); //
Этот код вешает хоткеи позволяющие без переключения на английский по клавише Alt+… вводить соответствующие спец символы.
Я решил проблему, написав дополнение для Vim, транслитерирующее ввод: такой подход позволяет использовать только одну (английскую) раскладку для ввода (для которой я ещё и освоил слепую печать), хотя и не всегда удобен. Думал как‐нибудь написать на замену что‐то более системное — разобраться, как вводятся иероглифы и сделать по аналогии, но до этого как‐то не дошло.
Добавил немножко символов.
// trdm 2020-02-17 10:21:08
// script: trdmUtil.js
//[[[[[[[[[[[[[[[[[[[[[[[[[
// Ввоод символов в русской раскладке схема Alt+Символ: Alt+> =>> > ; Alt+$ =>> $. Можно не переключать раскладку.
function typeSymbol( psSymb ) {
if(psSymb.length > 0) {
Editor.currentView.selection = psSymb;
}
}
function addHotSym(psFu, psKey) {
var rv = {ctrl: false, shift: false, alt: true, key: psKey, cmd: psFu};
addHotKey(rv);
}
function addHotSymC(psFu, psKey) {
var rv = {ctrl: true, shift: false, alt: false, key: psKey, cmd: psFu};
addHotKey(rv);
}
function typeSymbol_1() { typeSymbol( '<' );} addHotSym(typeSymbol_1,0xBC); //<>>
function typeSymbol_2() { typeSymbol( '>' );} addHotSym(typeSymbol_2,0xBE);
function typeSymbol_3() { typeSymbol( '\'' );} addHotSym(typeSymbol_3,0xDE);
function typeSymbol_4() { typeSymbol( '~' );} addHotSym(typeSymbol_4,0xC0); //~
function typeSymbol_5() { typeSymbol( '$' );} addHotSym(typeSymbol_5,0x34);//$$$
function typeSymbol_6() { typeSymbol( '#' );} addHotSym(typeSymbol_6,0x33); //###
function typeSymbol_7() { typeSymbol( '|' );} addHotSym(typeSymbol_7,0xDC); //|||
function typeSymbol_8() { typeSymbol( '[' );} addHotSym(typeSymbol_8,0xDB); //[[[
function typeSymbol_9() { typeSymbol( ']' );} addHotSym(typeSymbol_9,0xDD); //]]]
function typeSymbol_10() { typeSymbol( '\'' );} addHotSym(typeSymbol_10,0xDE); //'''
function typeSymbol_11() { typeSymbol( '%' );} addHotSym(typeSymbol_11,0x35); //%%
function typeSymbol_12() { typeSymbol( '^' );} addHotSym(typeSymbol_12,0x36); //^^
function typeSymbol_13() { typeSymbol( '&' );} addHotSym(typeSymbol_13,0x37); //&&
function typeSymbol_14(){ typeSymbol( '`' );} addHotSymC(typeSymbol_14,0xC0);// `
function typeSymbol_15(){ typeSymbol( '@' );} addHotSym(typeSymbol_15,0x32);// @
function typeSymbol_16(){ typeSymbol( '' );} addHotSym(typeSymbol_16,0x31);// Заглушка для свертывания блоков. не пользуюсь
//]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]]Думаю для поклонников Notepad++ будет некое полезное подспорье…
Как использовать:
- установить плагин jN
- в кателоге %Notepad++\plugins\jN\jN\includes\ добавить файл trdmUtil.js (UTF-8)
- Закинуть в файл этот текст
- Перезагрузить N++
- Пользоваться.
Разрабатывать удобный текстовый формат оптимально, но придавать излишний вес фактору «это не удобно набирать на русской раскладке клавиатуры» мне кажется малооптимально в этом вопросе.
Хочу поинтересоваться — а Вы бы хотели, чтобы все люди на планете общались одним единым языком?
Мне кажется их можно только самые простые делать в простом формате, хотите красоты — пользуйтесь не простыми форматами, используйте для этого навороченные редакторы.
С ручным выравниванием колонок я тоже намучался.
С другой стороны если будет возможность вставить картинку, то проще таблицу нарисовать в продвинутом редакторе и в документ вставить ссылку на картинку.
По части «Преформатированный текст», не соглашусь, писать ```php или ```sql не напрягает, 4 пробела подряд — очень спорное решение. Я понимаю что спец символов доступных из русской раскладки, не так много, но. Почему бы не сделать тройной символ;
С другой стороны что бы написать php всё равно надо раскладку переключить поэтому и символ ` тоже норм. Можно конечно вместо php писать «пхп», «скл», «иксмл», что бы не переключать раскладу, но мне кажется это будет слишком для консервативных умов.
Оххх как меня сейчас флешбекнуло…
Буквально пару месяцев назад делал себе блог. И решил сделать его с 0, для фана на собственном движке. Выбрал сначала markdown. Но в итоге, забил на него и реализовал свой собственный markdown, с возможностью создавать grid, указывать классы, мультилайн итд.
Грид то типа.
Не скажу что вышло прям удобно, но зато функционально. :D
||:3:(.bold_header) заголовок 1 ||:1:(.bold_header) заголовок 2 ||:2:(.bold_header) заголовок 3 ||
||---||---||---||
||:(center) текст по центру ||:(.class) Мульти
Лайн || без класса однострочный ||
||---||---||---||
MarkedText — маркдаун здорового человека