Comments 409
Однако, есть люди, которые утверждают, что именно отдельный swap файл/раздел мешает производительности.
Свап это для ситуации «работаем на тех ресурсах которые есть».
--fail-swap-on=false
они добавили, но явно что-то идёт не так
Пытаются протолкнуть поддержку своп с версии 1.22
We are targeting alpha support for a swap MVP in Kubernetes 1.22.
Черновик с деталями
https://docs.google.com/document/d/1CZtRtC8W8FwW_VWQLKP9DW_2H-hcLBcH9KBbukie67M/edit#
А что до советов на nvme засунуть своп. Нередко куберовские ноды вообще не имеют локальных дисков. Они грузят в память какой-нить coreos, а диски выделяется из отдельного распределенного хранилища.
Дело не в производительности. Проблема в том что использование swap файла мешает правильному учету памяти процесса и ломает правильную работу memory limits для контейнера. Т.е. потенциально контейнер может занимать больше памяти чем вы ему разрешили т.к. часть этой памяти вытеснена в swap файл.
Совершенно верно. Корень причины тупо в том, что в cgroups v1 (на которых построено отслеживание ресурсов кублетом) попросту нет учёта занятого swap space, поэтому планировщик тупо не будет знать, когда нужно перестать пихать на ноду новые контейнеры.
Впрочем, учёт занятого swap swace делу особо не поможет, потому что с этой информацией особо ничего нельзя сделать кроме как просуммировать с занятой основной памятью. Тут нужен учёт memory pressure (который в линуксе тоже развивается в виде PSI). Так что через пяток лет, когда технологии "дотекут" до самых верхних уровней абстракции, вполне возможно, что ограничение снимут :-)
процессу придет сигнал SEGFAULT — и процесс умрет
Что мешает ему перехватить этот сигнал и сделать longjmp в код, который приведёт процесс в известное состояние? Утверждение некорректно. То, что этим практически никто не пользуется, не значит, что этим нельзя пользоваться.
Ну а по тексту: отключал swap и буду отключать, так как в моих сценариях использования его наличие всегда приводит к значительной деградации скорости работы и отзывчивости. Гораздо эффективнее убивать периодически разжирневших гадов (привет, браузеры! особенный привет хрому). Ещё раз повторю: всегда и в разы становится хуже.
И нет, наличие большого количества свободного ОЗУ (за вычетом дискового кеша) не спасает: на системе, очень активно работающей с диском (большим объёмом), где в каждый момент времени общий объём выделенной процессам памяти меньше половины (и даже трети) ОЗУ, очень быстро память процессов уходит в swap и становится «весело».
Если ваш сценарий использования это документики в пару страничек набрать, да в браузере поковыряться — можете продолжать мучиться со swap'ом. Гораздо эффективнее — выкинуть хлам: как лишнее работающее ПО, так и «железо», не соответствующее аппетитам ПО.
Если он не нужен — он не будет использован.
Соответственно, это — ложь: с политиками по умолчанию планировщик памяти ошибается и сбрасывает в swap то, что нужнее.
- Интересно, как вы написали бы «код, который приведёт процесс в известное состояние». Ведь чтобы прийти в «состояние» нужно освободить выделенную память, а для этого нужно знать все указатели, по которым она была выделена (сложно) и порядок выделения. А так как среди них, вероятно, есть указатели, которые приводят к SEGFAULT (уже приводили), то придется постоянно отлавливать SEGFAULT и продолжать процесс возвращения в состояние заново.
Короче, это а) сложно, б) медленно, в) ненадежно. И чревато утечками памяти.
Гораздо проще сохранять ценные данные в постоянную память на регулярной основе. - Кстати, по поводу утечек. Swap способен продлить uptime процесса с умеренно растущими утечками — он будет складировать на диск неиспользуемые «утекшие» страницы, оставляя «живые» страницы в оперативной. В итоге будет расти занимаемый объем swap, а не оперативной памяти
- Возможно много ситуаций, где swap будет вреден. Например, когда необходим быстрое пробуждение давно ждущего процесса. Система может выгрузить старый «ждущий» процесс в swap, и быстрого отклика вы не получите.
Но это всё специфичные случаи, а в среднем swap скорее полезен, чем вреден. Особенно для домашнего пользователя - Сценарий с кучей вкладок в барузере — идельный вариант использования swap. Ценная оперативная память отдается по максимуму тем вкладкам, что использовались недавно. А старые можно сгрузить на диск.
Исключением будет, если вы постоянно переключаетесь между всеми вкладками в хаотичном порядке.
Кстати, Chrome теперь сам сгружает на диск неисользуемые вкладки и сам почти не попадает в swap.
Вы манипулируете фактами: я указал на ошибочное утверждение, что SEGFAULT всегда приводит к смерти процесса и не более. И я нигде не утверждал, что нужно всегда реагировать на него и восстанавливаться.
Да, в большинстве случаев гораздо дешевле расстреливать каждого провинившегося: пуля в лоб — и в крематорий. Вот только есть критические элементы инфраструктуры, где такая казнь оказывается гораздо дороже: электростанции, управление транспортом, да автоматические космические аппараты, в конце концов.
Сложнее? — Да. Медленно? — Нет: гораздо быстрее восстановиться без убийства процесса. Ненадёжно? — Надёжнее на порядки: ту же память может съесть другой процесс между убийством и запуском нового. Чревато утечками памяти? — Нет: состояние кучи можно приводить также в изначальное (известное) состояние. Все проблемы решаемы там, где это действительно нужно.
Swap способен продлить uptime процесса с умеренно растущим утечками
Способен. Только это откладывание проблемы, которая никуда не уходит.
Кстати, Chrome теперь сам сгружает на диск неисользуемые вкладки и сам почти не попадает в swap.
Да, именно поэтому оказывается, порой, быстрее его убить и перезапустить, чем дожидаться, когда он отсвапирует своими силами. Хром — очень плохой пример.
Swap — это костыль в условиях нехватки ОЗУ, за который приходиться платить. В текущих реалиях утверждение «никогда не отключайте swap» — вредно. Гораздо интереснее было бы решить проблему планировщика памяти с настройками по умолчанию, чтобы он не приводил к деградации работы системы: в указанном мною выше прецеденте производительность падает в четыре раза при наличии swap'а.
Swap — это костыль в условиях нехватки ОЗУ, за который приходиться платить. В текущих реалиях утверждение «никогда не отключайте swap» — вредно. Гораздо интереснее было бы решить проблему планировщика памяти с настройками по умолчанию, чтобы он не приводил к деградации работы системы: в указанном мною выше прецеденте производительность падает в четыре раза при наличии swap'а.
все так, но это требует комплексного подхода.
так все правильно — за это отвечает отдельный параметр ядра линукса (overcommit?)
Т.е. у нас минимум три разных параметра есть (swap on/off, агрессивность свопирования, оверкомит)
Вот буквально как вчера мой jupyter notebook с python+Pandas выжрал 55Gb (из 64), и дальше отказался работать
Тут надо смотреть для начала, откуда именно он память выжрал. В Windows у ядра есть неподкачиваемый пул памяти, которая никогда не сбрасывается на диск (потому что используется той частью ядра, которая не может использовать виртуальную память), и если он заполняется (например, утекет память в драйвере или остаются незакрытые описатели потоков в процессе), то система нормально работать уже не может. Смотреть можно много откуда — в Диспетчере задач, например.
В 32-битных Windows Server, в которых размер этого пула был ограничен сотнями мегобайт, утечка памяти из неподкачиваемого пула была нередкой проблемой. В 64-битных системах проблема возникает реже, но пару раз видел.
Если у вас дело в этом, то источник проблемы найти можно: могу рассказать, как, или самому найти не сложно по ключевому слову poolmon (это утилита, которая показывает, чем знаяты пулы памяти ядра)
В Windows нет overcommit: под любую выделенная память (committed) должно быть зарезервировано место в page file (сумма физической памяти за вычетом non-paged area и swap file). Но до первого обращения к выделенной памяти страницы указывают в никуда и потому не учитываются в статистике потребления памяти процессом.
Собственно, по этой причине мне перестало хватать 16 гигов памяти без свопа. Современные ААА-игры коммитят по 10–12 гигов памяти, а реально используют только 3–4. И если нет свопа, тогда, чтобы поиграть, приходится выгружать браузер и IDE.
Игроделы могут не использовать это, потому что выделение памяти — далеко не мгновенная операция, можно в интервал отрисовки кадра не успеть выполнить.
При обращении к такой памяти, естественно, возникнет исключение, но его несложно перехватить, выделить память под это обращение и вернуть управление в ту точку, в которой произошло обращение к памяти, для повторного выполнения — это стандартная функциональность обработки исключений.
Немного не согласен с выделенными моментами. Такой функционал невозможно реализовать с помощью механизма исключений, используемого в языках программирования. Здесь уже нужно опускаться до уровня WinAPI. Я уж молчу по то, что далеко не все игры пишутся на C++, и опуститься до уровня ручного управления памятью довольно сложно.
Немного не согласен с выделенными моментами. Такой функционал невозможно реализовать с помощью механизма исключений, используемого в языках программирования. Здесь уже нужно опускаться до уровня WinAPI.
Я как раз и имел в виду Win32 API. Потому что вел разговор про управление памятью на уровне ОС.
И проблемы именно для игроделов возникают уже на этом уровне.
Но вот если вы запустите два, то ОБА могут получить всю память и успешно работать.
Вот я сижу на 32-битной ОС, объём поддерживаемой физпамяти ограничен числом чуть меньшим, чем 4 Гб. При этом у меня огромный файл подкачки, размещённый на специально выделенном ради этого SSD-диске. Естественно у меня процессов, выдеряющих огромные объёмы, сумма которых больше, чем объём всей физпамяти на порядок.
Вот я сижу на 32-битной ОС, объём поддерживаемой физпамяти ограничен числом чуть меньшим, чем 4 Гб.
32битные ОС поддерживают больше 4Гб через PAE, про который вы кстати и говорите
и, в 32-битных серверных версиях windows сплошь и рядом на серверах было больше 4 гигабайт памяти (до 64Гб вроде), ограничения настольных версий были чисто маркетинговыми
32битные ОС поддерживают больше 4Гб через PAE, про который вы кстати и говорите
Я прекрасно знаю об этом, но в XP поддержка физпамяти больше 4 Гб принудительно зарезана. Где только я говорил про PAE, не могу понять? В комментариях к этой публикации я PAE не упоминал — разве что в комментах к другим статьям мог где-то сказать про PAE в рамках развенчания мифа про лимит в 4 Гб для 32-битных систем, налагаемый, якобы, архитектурой.
в Ultimate вроде можно включить PAE, но это не точно...
Так PAE в Windows 7 включена по умолчанию (просто потому что без PAE не работает DEP).

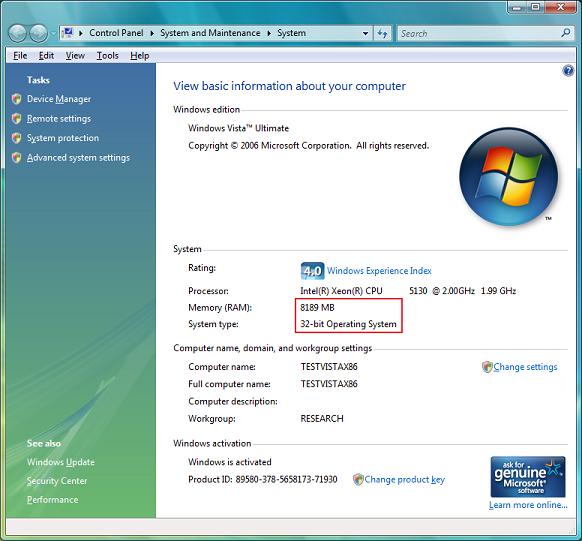

В общем, работая на 8ГБ под х86 я заметил следующее: это не снимает ограничение на лимит в 4ГБ линейного пространства (и 2ГБ ОЗУ) на каждый процесс, но позволяет запустить несколько жирных процессов, которые могут выделить себе по 2ГБ ОЗУ каждый.
электростанции, управление транспортом, да автоматические космические аппараты, в конце концов.
В таких случаях не занимаются нетрадиционными практиками камасутры, а используют более логичные инструменты типа гарантированного выделения ресурсов и лимитирования использования ресурсов потребителям в общей среде. А проще говоря, ставят ulimit и железо такое, чтобы в оперативку влез весь объем потребителей и делают mlock на свою память.
И как это спасёт КА от падения в случае ошибка работы с памятью при обращении по недействительному адресу? SegFault ≠ PageFault. В случае критических систем используют всё множество практик для уменьшения ущерба.
Я не понимаю, зачем снова и снова пытаться оправдать неверное утверждение. Оно неверно: SegFault можно обработать. Смысл слова «можно» разъясняется в мириадах стандартов и спецификаций.
Вопрос к знатокам: у данногоподхода есть какие-то минусы о которых стоит знать?
Я уже дважды указал на проблемы планировщика памяти с настройками по умолчанию в ряде прецедентов. Ну а регулировка этого параметра, как минимум в одном из моих активно используемых прецедентов лишь откладывает проблему.
Это означает, что vm.swappiness — это по существу просто соотношение дорогой анонимной памяти, которую можно высвобождать и приводить к отказам, в сравнении с файловой памятью для вашего железа и рабочей нагрузки. Чем ниже значение, тем активнее вы сообщаете ядру, что редкие обращения к анонимным страницам дороги для перемещения в swap и обратно на вашем оборудовании. Чем выше это значение, тем вы больше говорите ядру, что стоимость swapping'а анонимных и файловых страниц одинакова на вашем оборудовании. Подсистема управления памятью будет по-прежнему пытаться решить, помещать в swap файловые или анонимные страницы, руководствуясь тем, насколько «горяча» память, однако swappiness склоняет подсчёт стоимости в пользу большего swapping'а или большего пропуска кэшей файловой системы, когда доступны оба способа. На SSD-дисках эти подходы практически равны по стоимости, поэтому установка vm.swappiness = 100 (т.е. полное равенство) может работать хорошо. На вращающихся дисках swapping может быть значительно дороже, т.к. в целом он требует случайного чтения, поэтому вы скорее всего захотите сместиться в сторону меньшего значения.откуда то.
vm.swappiness = 100 (т.е. полное равенство)
Если это не проценты, тогда что? Другое дело, что вовсе не проценты оперативки...
```This control is used to define how aggressive the kernel will swap
memory pages. Higher values will increase aggressiveness, lower values
decrease the amount of swap. A value of 0 instructs the kernel not to
initiate swap until the amount of free and file-backed pages is less
than the high water mark in a zone.```
```A value from 0 to 100 which controls the degree to which the system favors anonymous memory or the page cache. A high value improves file-system performance, while aggressively swapping less active processes out of physical memory. A low value avoids swapping processes out of memory, which usually decreases latency, at the cost of I/O performance. The default value is 60.```
Потому как я установил 40Гб оперативки и решил — ну вот, оперативки много, можно теперь файл подкачки отключить. Ха, как бы не так, винда ушла в BSOD через 2 часа. Ну подумал, всякое бывает, перегрузился и через 4 часа опять BSOD. Понял, что дело в отключенном файле подкачки, включил назад и больше BSOD'ов не было.
Так посмотрите что именно вызывает BSOD и что происходит в системе перед ним — очень маловероятно что это связано с нехваткой памяти.
У меня на вынь всего 32GB и никакого свопа — и я не могу вспомнить когда у меня был BSOD или даже просто нехватка памяти, всё просто работает, при этом иногда (если лень апдейты ставить) аптайм до полугода доходит.
И для вынь и для линь верно одно — если памяти хватает для всех потенциально запускаемых одновременно приложений — своп не нужен. Если без него возникает проблема нехватки — добавьте оперативки. Если бюджет или железо не позволяет — ок, тогда выхода нет и придётся добавлять своп.
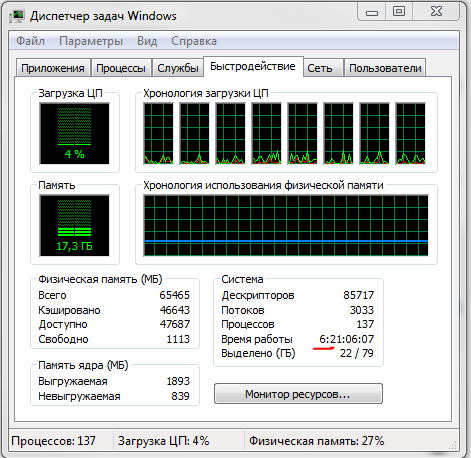
Но я привык держать диспетчер задач в фоне на случай таких ситуаций, когда запускаю что-то, что может вызвать подобную ситуацию. При этом у меня открыто постоянно 2 окна браузера (по одному на каждый монитор) с несколькими вкладками в каждом, пара разных IDE, всякие логгеры и я ещё бывает запускаю какую-нибудь игруху для отвелчения без необходимости выгружать что-то из уже запущенного. А аптайм у меня редко меньше недели (на скрине меньше потому что перегружался по причине отключения света на длительное время а UPS уже практически разрядился):
Сейчас же я поставил 64ГБ и продолжаю жить без свопа. Я его достаточно натерпелся ещё во времена 3.11 :)
Однако, есть один нюанс. Есть игры, особенно из новомодных, которые при отключенном свопе пишут, что мало памяти и выключаются. Поэтому на игровом компьютере, к которому подключён VR, у меня своп есть, но он задан небольшим, буквально 1ГБ, хотя ОЗУ там тоже 64ГБ.
Вот во времена Win3.11 он ещё назывался swap file. Сейчас же он уже давным-давно называется page file. И логика работы на винде в целом такая же, как описана в этой статье.
но он задан небольшим, буквально 1ГБ
Кстати, это отлично предохраняет винду от старадания фигней при половине свободной памяти в наличии. При этом, из-за пренебрежимо малого размера, она его практически не использует.
«Сейчас же я поставил 64ГБ и продолжаю жить без свопа. Я его достаточно натерпелся ещё во времена 3.11 :~) Хочу натерпеться от его отсутствия.»
Так посмотрите что именно вызывает BSOD и что происходит в системе перед ним — очень маловероятно что это связано с нехваткой памяти.Ирония в том, что при отключенном свопе minidump для анализа будет недоступен, т.к. его логи пишутся используя своп.
И для вынь и для линь верно одно — если памяти хватает для всех потенциально запускаемых одновременно приложений — своп не нуженUWP приложения в виндах суспендятся в своп, например.
Лог при дампе в виндах пишется используя своп.
Виртуалки своп очень любят, даже если им хватает памяти.
Если без него возникает проблема нехватки — добавьте оперативки. Если бюджет или железо не позволяет — ок, тогда выхода нет и придётся добавлять своп.А чем своп-то мешает? Если нет места на диске, просто купите диск побольше:) Если оперативы достаточно и своп не нужен — он не мешает, но всё равно может быть полезен. Если недостаточно, он необходим. Что за культ с отключением свопа?
Поправлю вас: UWP отправляются в swapfile, а не в pagefile, про который идёт речь (и размером которого можно управлять через классические настройки файла подкачки).
Ирония в том, что при отключенном свопе minidump для анализа будет недоступен, т.к. его логи пишутся используя своп.
А смотреть на processhacker/taskmanager в фоне? Проверить журнал после падения? С вероятностью 99.9% проблема в том что кто-то сожрал всю память — и это обычно видно и без minidump.
А чем своп-то мешает? Если нет места на диске, просто купите диск побольше
Вы же не будете покупать лопату для уборки снега и зимнюю одежду если в вашем регионе температура не опускается ниже 30°C? Они ведь не мешают.
Вы же не будете покупать лопату для уборки снега и зимнюю одежду если в вашем регионе температура не опускается ниже 30°C? Они ведь не мешают.Своп файл в виндах создается по умолчанию и составляет жалкие доли процента от объема диска.
Поэтому это скорее «купил 250 метровый домик в горах где снег бывает 2 раза в год, в комплектации была куртка и лопата, но я их выкинул, т.к. нужны редко и не всем» :)
Не, ну реально. Своп файл в виндах у нас дефолтный, на 1тб диске занимает 2гб. Какая, блин, причина в принципе идти и тратить свое время на его удаление? Цель в чем?
p.s.: На некоторых сайтах в файрфоксе течет память, к концу дня если не закрыть/открыть вкладку, может до 16гб на вкладку набежать, а вкладок далеко не одна.
Ирония в том, что при отключенном свопе minidump для анализа будет недоступен, т.к. его логи пишутся используя своп.
Есть информация, что можно выделить под дамп памяти отдельный файл при отключённом файле подкачки.
Своп сам по себе как бы не мешает...
Вот только во всех эти хитроумных алгоритмах работы, либо в их виндовой реализации, где-то есть недоработка, потому что стоит разрешить своп в винде, как она начинает постоянно дёргать диск. Мне как бы вроде и не жалко, но вот у меня уже второй SSD дохнет, потому что, вероятнее всего, достиг лимита перезаписи... И вот потерянные данные это уже обидно, знаете ли.
А с отключенным свопом - всё хорошо, диск без причины не дёргается.
Мне как бы вроде и не жалко, но вот у меня уже второй SSD дохнет, потому что, вероятнее всего, достиг лимита перезаписи.
вы смарт контролируете? (вы же предположили, что объём записи превысил ресурс накопителя)
и что за накопители?
по моему опыту никакого массового падежа ssd на машинах с включенным свопом не наблюдается.
да, ультра-бюджетные накопители дохнут достаточно часто (в первую очередь, думаю, из-за того, что используется некачественный кэш), но, думается, отключение кэша там не поможет (например, видел достаточное количество сдохших ssd класса «самая дешёвый ssd в прайсе» на кассах с linux, где свопа нет и вообще объём записи на диск невелики; потом стали покупать брендовые накопители и проблема ушла).
Честно говоря в смарте даже у заведомо качественных дисков часто какой-то мусор вместо нормальных данных. По крайней мере на моём опыте.
Что касается предположения о бюджетности, тут мимо - один дохляк это Crucial CT500MX500SSD1, он, конечно, даже близко не топовый, но точно не самый бюджетный. Второй это какой-то Intel, там не вспомню модель, но тот вообще был не из дешёвых, покупал лет пять назад где-то за 11-12к, но он как раз мог и правда просто от старости отъехать, учитывая что я бывало частенько node_modules переставлял и прочее подобное...
В целом, я конечно не утверждаю, что включенный swap это гарантированно мёртвый диск, я лишь хотел отметить, что время жизни диску это неминуемо урежет.
Честно говоря в смарте даже у заведомо качественных дисков часто какой-то мусор вместо нормальных данных. По крайней мере на моём опыте.
не видел ни разу мусора в счётчиках записанных данных.
датчик температуры тоже, наверное, стоит контролировать (но там есть различие между моделями — где-то датчик только на nand, где-то только на контроллере, где-то и там, и там).
ну и процент износа тоже (хотя бы потому, что некоторые по превышению износа в 100% переходят в режим readonly).
полезность остальных аттрибутов действительно сомнительна.
не видел ни разу мусора в счётчиках записанных данных.
я видел, правда не на ssd, а еще когда с НЖМД работал. Как пример - в working hours атрибуте вроде были не часы, а минуты, а сигейты классически отличались тем, что у них вместо raw read error rate был какой-то мусор. Да, т.е. там число, возможно, даже осмысленное, но угадать его единицу измерения и базу измерения невозможно. Нет стандарта на значения смарта
Нет стандарта на значения смарта
вроде бы некоторые атрибуты vendor-specific, некоторые же стандартные, но стандарта не читал, спорить не буду.
в любом случае если подходить с практической точки зрения, то тот же smartctl умеет парсить атрибуты разных моделей.
а если речь всё-таки про sata ssd, то там всё интересное в выводе
smartctl --log=devstat /dev/sdXи тут разночтений между накопителями разных производителей я не встречал.
P. S. но вообще ситуация, когда одновременно существуют три стандарта smart — для sata, sas/scsi и nvme, и при этом как минимум первый имеет кучу вариаций, конечно, печалит.
Там традиционно программы выделяют себе гигабайты памяти «на всякий случай» и если свопа нет, у вас может быть 1байт из гигабайта занят — и памяти уже нету.
А если есть своп — просто весь этот гигабайт виртуально в свопе, а страничка с байтом данных — в памяти.
В виндоуз желательно иметь двойной от памяти своп.
Мне казалось, это то, для чего придуман механизм виртуальной памяти. Система же знает, какие страницы памяти процесса им действительно используются, может не хранить их в оперативке.
Без swapfile система виртуальной памяти нормально не работает.
Если у вас достаточно памяти, то из swapfile ничего и не читается по сути. Но он все равно нужен.
А если у вас процесс выделил 1гб из 8, система их не выделила, все остальное заняли другие процессы, а потом процесс начал запись в выделенный кусок — вот тут будет BSOD, ибо обработки записи в несуществующий фрагмент нигде нету. Вообще даже обработка ситуации «не смогли выделить кусок памяти» современными программистами не всегда выполняется.
А если swapfile есть — будет вытетеснение вместо bsod.
Непонятно, зачем вообще что-то хранить хоть в swap-е, хоть в оперативке, если программа туда ничего не писала никогда после выделения. Ситуация "выделили гигабайт, записали 1 байт" ведь из этой серии? Что-то не верится, что менеджер памяти любой современной ОС настолько глупый, что не может оптимизировать эту ситуацию.
В ситуации, что вы описали, вы что подразумеваете под "все остальное заняли другие процессы"? Все реально записали эти 8 Гб данных? Тогда вы правы, но и в Linux было бы так же. Но ведь вначале у нас было другое предположение — что из всех этих 8 Гб реально была запись в 8 байт, и система это знает.
Человек выше все правильно описал.
Вы запросили 1гб, по факту записали 1мб, ваше приложение занимает 1мб озу и 1023мб свопа. Да, фактически записи в своп нет, но система должна гарантировать, что если озу нет, вы все равно сможете использовать 1гб который вам адресовали. Соответственно если своп выключен, то даже если приложение по факту записало всего 1мб в память но затребовало 1гб, весь 1гб будет считаться занятым. Самое смешное, что диспетчер задач и монитор ресурсов этого не покажут и вы будете получать сообщение про нехватку памяти при свободных 20гб в диспетчере, и без шансов вообще узнать что съело память.
Придёт добрый дядя OOM и разрулит ситуацию, по понятиям.
Вы неправы. Читайте про оверкоммит. Приложение может запросить хоть 1ТБ — но пока не будет реальной записи — что со свопом, что без — эта память фактически не существует. Но как только приложение попытается скушать больше, чем free — приплыли. Поэтому Catslinger абсолютно прав.
Нет такой истории, что "виртуальная память" выделяется из свопа
Ситуация «выделили гигабайт, записали 1 байт» ведь из этой серии? Что-то не верится, что менеджер памяти любой современной ОС настолько глупый, что не может оптимизировать эту ситуацию.
Вы это про Windows или про nix-системы говорите?
Если про Windows, то что сейчас, что 20 лет назад, ничего подобного не практиковалось.
Когда вы выделяете 1 гигабайт памяти с помощью VirtualAlloc, создаётся структура MMVAD (она является узлом дерева, всё дерево хранит всю карту выделенных или зарезервированных областей виртуального АП отдельно взятого процесса, точнее «пользовательской» части всего АП), в которую заносятся параметры выделения (база, размер, параметры защиты страниц).
Никаких страниц физической памяти или файла подкачки, ассоциированных со страницами этого гигабайтного региона, в момент выделения памяти не выделяется.
Единственное, что есть такой счётчик как «page file quota», от которого минусуется количество выделенных страниц — этот счётчик не даёт всем процессам в сумме выделить больше страниц, чем теоретически может обеспечить файл подкачки.
Когда вы попробуете записать тот пресловутый 1 байт, произойдёт page fault, который ОС разрулит незаметным для процесса образом — странице виртуального АП, в которую был записан 1 байт, начнёт соответствовать некая страница физической памяти. Эта страница физической памяти будет выбрана из списка заблаговременно заготовленных занулённых страниц, а если таких готовых страниц на данный момент нет — будет занулена прямо сейчас (что дольше, чем если брать из простаивающих занулённых).
В случае, если ОС будет испытывать недостаток страниц физпамяти, страница физпамяти, соответствующая странице виртуального АП, в которую был записан 1 байт, будет сброшена в файл подкачки, а при необходимости затем подгружена.
Все остальные остальные страницы этого гигабайтного региона по прежнему будут существовать только номинального — не более, чем как числа в структуре MMVAD. Никаких страничных фреймов физической памяти или страничных фреймов файла подкачки им (без необходимости) соответсововать не будет.
Вы это про Windows или про nix-системы говорите?
Безотносительно.
Никаких страниц физической памяти или файла подкачки, ассоциированных со страницами этого гигабайтного региона, в момент выделения памяти не выделяется.
… и так далее...
Так я вроде как раз об этом и говорю. Что пока не писали ничего в память, никакого выделения нет и не было, никакой своп не нужен, потому что хранить в нем нечего. А значит и выделять заранее память можно чтобы хоть попой кушать — растут ведь только циферки во внутренних структурах ОС, а не количество занятых транзисторов в микросхеме.
Поэтому на мой взгляд
Там традиционно программы выделяют себе гигабайты памяти «на всякий случай» и если свопа нет, у вас может быть 1байт из гигабайта занят — и памяти уже нету.
если и реально, то совершенно никак не зависит от наличия свопа
5+ лет сервер (вебсервер с Битриксом, почтовый сервер, джаббер сервер) живёт без свопа без каких либо проблем:
total used free shared buff/cache available
Mem: 62G 2,6G 50G 325M 9,1G 59G
Swap: 0B 0B 0B С десяти кратным резервном памяти чего бы не жить


Да, это overkill — у ПК, за которым сейчас работаю, 16 ГБ оперативки, и 7 из них свободны (совсем свободны, даже не под кэшем, пишу дипломную — открыт браузер с десятком табов, Word, Outlook, Консультант+). Но удовольствие от использования стоит того.
Я 16 ГБ оперативки воткнул себе ещё в 2011 году (кстати, это обошлось всего в $100 — тогда память была очень дешёвой). Естественно, отключил своп. Но вот пару лет назад этого объёма стало уже не хватать.
Но вот обидно, когда нет свободных разъемов и приходится покупать новый комплект, а старый отдавать за бесценок — старая мелкая память спросом не пользуется. :)
Как-то пришлось поработать некоторое время на древнем компьютере с нижним Celeron, 0,5 ГБ ОЗУ и Windows XP. Установил максимальный для материнской платы Pentium D945 с большим кешем, максимальных 2ГБ ОЗУ китайскими модулями (материнская плата по паспорту такого не умела), дохленький ssd — и получил турболёт, весь софт просто залетал, даже жалко было переходить на новый компьютер. Весь апгрейд обошёлся в стоимость чашки хорошего кофе.
Но вот обидно, когда нет свободных разъемов и приходится покупать новый комплект, а старый отдавать за бесценокчтобы обидно не было — нужно следить за рынком и апгрейдится не когда приспичило, а когда это выгодно. Если не брать в расчет самые-самые топовые железки, то у остального большинства железа всегда есть момент, когда можно продать за еще нормальные деньги, и с не очень большой доплатой купить железо пошустрее.
Но как интересно… — Вы работали с NT4, и пишете диплом.
А так я и с Win3.1 работал, и с 95/98 — но тогда был студентом и много памяти было не по карману, поэтому страдал и мучился как все — Win95 на 4МБ, открываем Word, печатаем, тыкаем по Excel с диаграммой, чтобы вставить в нужное место — и ждем, пока зомби восстанет из подкачки под громкий хруст винчестера.
Мы писали на Delphi (которая версии 1) и когда запускали программы на Win311 (на i286), было прикольно наблюдать, как перерисовываются все элементы окон — рамочки, кнопочки. Причём по два раза, и медленно.
Это было удивительно, потому что до этого мы писали собственные оконные менеджеры, где эти моменты оптимизировли, чтобы непосредственно процесс вывода на экран был одним, и незаметным, и не мерцал.
А тут — такое… MS тогда в наших глазах сильно упал.
Кстати, в плане потребления памяти — тоже.
OS/2 сильно выигрывал. И в полуосе мы своп всегда смело увеличивали. Он работал совсем по-другому. На четырёх то МЕГАбайтах памяти :)
Полуось она такая да. Сам на ней ровно с такого-же объёма памяти начинал!
А Windows 3.1 минимально требовала 2МБ, если говорить о расширенном режиме — т.е. когда она работала как ОС, полностью забирая на себя управление процессором, а ядро DOS при этом работало под ее контролем в режиме V86.
А в стандартном режиме, когда Windows работала как настройка над DOS с помощью DOS Extender, минимальным требованием было вообще 1МБ.
Скорость отрисовки зависела тогда сильнее не от скорости процессора или памяти, а от видеоадаптера: тогда в них как раз пошли в массы средства аппартного ускорения рисования графических примитивов — всяких линий, фигур, заливка цветом и т.д. — в изначальных EGA или VGA ничего такого и близко не было, там программы должны были самостоятельно каждый пиксель в фрейм-буфер писать. Да ещё и в несколько проходов: в EGA/VGA в 16-цветных режимах каждый из 4 бит пиксела находился на своей «плоскости» (странице фрейм-буфера отображаемого в память на одни и тот же адреса), для переключения доступа которым надо было писать в регистр видеоадаптера. И — от драйвера видеоадаптера, который транслировал вызовы GDI в команды для видеоускорителя. Так что наблюдаемая разница между Windows и OS/2 могла быть связана с этим — с тем, что видеоадаптеры на сравниваемых машинах были разными.
Безобразия по поводу двукратной отрисовки в стандартных программах или в своих, написанных чисто на C, я не наблюдал, даже на самом медленном из используемых компьютеров — с EGA+1МБ памяти. Видать, это была особенность именно Delphi: Windows ничего из нарисованного (в том числе — и элементы оформления окна) в памяти не буферизовала (некуда было), поэтому по команде из программы все перерисовывалось заново: одна команда — одна перерисовка, две команды — две перерисовки.
Короче, OS/2, насколько я могу судить, была тогда совершеннее Windows, но — с бОльшими требованиями к памяти, и при тогдашних ценах на память разница была весьма существенна.
На самом деле ELF парсится. Как минимум для загрузки прилинкованых библиотек, для поиска точки входа. А вот дальше уже разные сценарии могут быть, оптимальный алгоритм выбрать сложно.
Скажем у вас бинарик на десяток мегабайт. Но в начале у него jmp в самый конец. Зачем грузить серединку и занимать память, если она возможно никогда не будет использоваться?
Page fault очень дорогое исключение. Но дорогое оно в сравнении с элементарной машинной командой.
А в сравнении с exec это капля в море.
Однако, в конце статьи делается вывод, что много памяти — это прекрасно, а swap имеет смысл в бюджетных системах (что, в целом, очевидно и без технических подробностей).
Так в чем же бесполезность и вред отключения, если памяти в системе, например, 32 или 64G (что совсем не редкость и не роскошь по сегодняшним меркам)?
И наконец, vmware, если пользуетесь, умеют переводить своп гостевой системы в хостовый.
А потом мы имеем статьи про побег кода из песочницы VMWare в хостовую систему?
Во-первых, через своп пишутся некоторые логи, что позволяет сохранить их в случае падения ядра.
Это актуально кому-то, кроме разработчиков ядра?
Во-вторых, линукс кеширует файлы в память «на все деньги». Пусть лучше там будут возможно нужные файлы, чем почти наверняка не нужные страницы от программ.
Зачем нужен файловый кэш в памяти, если код, который к ним обращается упал на диск?))))
В таком случае, в чём проблема просто докупить памяти, равной по объёму свопу?
И у многих будет вопрос, а как сделать все же так, что бы система начинала ползать, ну когда останется например гигов 10.
Планировщик должен работать и на впс с 2гб памяти же.
Это делается чтобы при (вероятном) запросе новой памяти можно было выделить блок в свободной области.
Для систем на 64гб просто надо подкрутить вероятность, ставить в 1-5.
К тому же значительная часть из «занятой» памяти в свопе может быть мапингом файлов, его в статье описали.
Из настраивамых еще есть vfs_cache_pressure.
Но по моему опыту для 32-256Gb RAM как минимум для баз данных достаточно swappiness выставить в 1 и все.
www.kernel.org/doc/Documentation/sysctl/vm.txt
ну и
vm.watermark_boost_factor = 15000
vm.watermark_scale_factor = 100
толку может быть больше
Статья немного Clickbait-ная: вот мой пример "плохого" swap-а: https://m.habr.com/ru/post/499950/
Чем мой метод РК плох? Работает успешно много лет на многих узлах. Легко восстановить данные. Что не так?
Ну и dd имеет oflag=direct для исключения кеша.
Прочитайте повнимательнее, про oflag=direct я пишу. А метод РК обусловден требованием восстановления данных быстро и просто и природой самих данных — файлы qcow2, в которых изменения постоянно происходят. Какой вариант вы предложите?
Что есть инкрементальный бэкап с тома qcow2? Нет, я знаю как можно делать с помощью средств qemu, только вот это сильно сложнее во всех смыслах. Расшифруйте свой метод. 1. Что монтировать. 2. Как определять части файлов qcow2 для инкрементного бэкапа. 3. Как потом из портянки делать qcow2. А если вы про монтирование томов qcow2 через nbd, то так нельзя в публичных услугах. Так то, и из виртуалки делают люди бжкапы. Мы же делаем за беспечных, не смотря внутрь.
Вы уверены? Сравнивали? У меня нет проблемы с ресурсами IO и какими-то другими. Я лишь привел пример того, как swap влияет на систему.
Просто положу это здесь, чтобы охладить оптимизм: https://forum.proxmox.com/threads/qcow2-corruption-after-snapshot-or-heavy-disk-i-o.32865/
Это официально зареганный баг в трекере, я ловил, еще ряд людей ловили.
Один-единственный ультрадешевый QLC под CoW или таки репрезентативная выборка?
А также еще две на хетзнере, тоже с ssd и с большим его использованием.
Современные диски переназначают блоки на другие участки, выравнивая износ.
Всегда оставляю под swap размер текущая память * 2
Даже если было бы 256гб — заложил бы пол TB на отдельном диске, и точно не там где boot и ядро
Тем более что сейчас ssh nvme на 1-2 TB стоят достаточно адекватно.
Для windows не актуально — там ось сама расширяет swap по необходимости. Для nix тоже есть такая возможность но этим лучше не злоупотреблять.
С другой стороны сейчас у меня всего 8gb и swap на отдельном старом ssd в 16gb спасает еще как. Хотя когда закладывал — думал как и все остальные (нахрена 16 gb — браузер жрет больше всего и в то время максимум съедал 200мб). А оно вон как сейчас вышло. Хорошо что умный человек еще в те давние времена сказал — не отключай swap и всегда выставляй его в виде ram * 2 или хотя-бы просто размером с ram.
Правда забил я его почти полностью только один раз — когда запустил не оптимизированный скрипт парсера на php и натравил его на 5gb xml — но ничего не упало — наоборот через 48 часов получил ожидаемый результат.
После я конечно рефакторил этот скрипт 8 раз и итоговый вариант выполнился за 8 минут. Но оптимизировал его месяц копаясь с xprofile. Первый результат от разбора первого файла нужен был до конца недели.
Понимая что обычный вариант парсера считывает весь xml в память а после мапит его на массивы/объекты — написал потоковый парсер на конечном автомате, отказался от mysql в пользу postgres и на него переложил построение древовидной иерархии данных — которые получал из xml (категории с под-категориями на 5 уровней вложенности)
Товарищи минусующие аргументировать минусы будем? нет?!
А смысл?
Просто представьте себе, сколько будут читаться эти пол-тб с QD=1,BS=4k,random — и сами все поймете.
Хм, этого конечно не учел. Как обновлю машину надо будет посмотреть.
С другой стороны чтение будет в любом случае random при любом размере swap.
Не разбираюсь в низкоуровневых механизмов работы с памятью на уровне ос. Но предполагаю что должен быть некий индекс который точно помнит на каких секторах диска какие страницы памяти записаны и скорее всего он динамический и содержит только фактически записанные на диск страницы. В этом случае большой swap лишь увеличит размер этого индекса и то — только в том случае если фактически потребляемая память действительно вырастет до этого объема и будет вытеснена на диск в остальное время будет зарезервирована и фактически не использована — что для твердотельных накопителей скорее будет в плюс.
Свап — это хранилище вразнобой выгруженных мелких (4k/8k — в зависимости от архитектуры) страниц. Поэтому чтение из него всегда случайное, в один поток (теоретически можно и в большее количество, но смысла в этом немного: это случайные операции, они не группируются нормально все равно).
Есть индекс, нет индекса — две соседние страницы могут быть (и будут) выгружены в произвольном порядке и займут произвольные не смежные слоты.
Забейте, собcтвенно, свап на несколько ГБ и сделайте time swapoff -a — если вас устраивает, что в течение такого времени машина будет жестко тупить, то все в порядке.
Для жестких дисков скорость чтения будет примерно 0.05÷1.0 МБ/с, для SSD — на два порядка больше, для Optane — еще на порядок-два.
Плюс еще момент: свап не на отдельном диске, он конкурирует за IO с другими процессами. Что будет, если система начнет активно свопиться, когда дисковая нагрузка положит график в полку? А если еще диск займется unmap?
Этот вывел для себя эмпирическое правило: комфортный размер свопа (если это не ноутбук, где он нужен для гибернации) должен прочитываться накопителем рандомным чтением за минуту. Что дает совсем смешные цифры для HDD (и на них реально если система ушла похрустеть диском — ее можно пару минут даже не трогать), единицы гигабайт на SSD и десятки для Optane.
Надо ли говорить, что на проде как только ваш чудо-узел с полтером свапа начнем высвапливаться — он весь покраснее в мониторинге и будет безжалостно выкинут из системы?
Для жестких дисков скорость чтения будет примерно 0.05÷1.0 МБ/с, для SSD — на два порядка больше, для Optane — еще на порядок-два.
среднее время доступа у обычных ssd около 100 мкс, у optane около 30 мкс, никакого различия на два порядка тут нет.
Просто представьте себе, сколько будут читаться эти пол-тб с QD=1,BS=4k,random — и сами все поймете.
а в каком случае может потребоваться чтение этих полтерабайт?
среднее время доступа у обычных ssd около 100 мкс
Во-первых, порядок-два величина оценочная, а не точная. Полпорядка по ⁵/₄ — вполне округляются до целого.
Во-вторых: а оно будет таким всегда-всегда, даже при отсустствии доступного SLC-кеша и набортной памяти, на каком-нибудь JMicron вместо контроллера и морально устаревших ячейках?
Товарищ amarao не по наслышке знает, чем отличается среднее по лаборатории от реальной эксплуатации.
а в каком случае может потребоваться чтение этих полтерабайт?
В тех же случаях, что и всегда: когда данные понадобится оттуда вытащить.
Это может быть рестарт подтекающего сервиса или приложения, обработка неправильно собранного пайпа, отключение свопа — в связи с миграцией, например или слишком ранним вызовом umount. В любом случае, если своп таких размеров был нужен и использовался то когда дело дойдет до, собственно, дела — будет больно. Очень.
Впрочем, если вы хотите подчеркнуть, что своп — это хранилище ненужных данных, то это просто проверить экспериментально: дискардить их, назначив свопом /dev/null…
Это может быть рестарт подтекающего сервиса или приложения
разве free области, лежащей в свопе, потребует чтения этого свопа?
Впрочем, если вы хотите подчеркнуть, что своп — это хранилище ненужных данных
не «ненужных», а «редкоиспользуемых»
Простите, как free оказалось в свопе?
Это могут быть недеаллоцированные правильно объекты, например, которым разом придет вызов деструкторов. Память утекать может разными способами, стандарта на утечку памяти нет.
Есть такая редкоиспользуемая вещь — огнетушитель… Вот когда он становится реально нужен, а до него не добраться, наступает ой.
Простите, как free оказалось в свопе?
вы неправильно поняли, речь про free(3).
Есть такая редкоиспользуемая вещь — огнетушитель… Вот когда он становится реально нужен, а до него не добраться, наступает ой.
разверните мысль, пожалуйста.
набрало приложение памяти, ничего с ней не делает, ушло в своп. потом проснулось, и давай со свопа подбирать память и тормозить. ну да, не особо хорошо, ну и фиг бы с ним. остальным приложениям это работать не мешает (если своп не на hdd, конечно)
А, вы про системный вызов.
Но ведь память однозначно может быть освобождена таким образом только если кто-то умер через SIGKILL.
Во всех остальных случаях результирующее поведение будет зависеть от множества факторов, но в целом, корректный выход требует корректной деструкции всех созданных объектов, освобождения блокировок и закрытия ручек, что потребует перечитывания как минимум части их данных и кода.
разверните мысль, пожалуйста
Что-то, внезапно оказавшееся нужным, оказалось закопано черти-где. Даже в случае ssd это та еще боль, просто проходит быстрее.
И оно конкурирует за I/O с другими процессами, при том.
Пока это происходит редко — все, в целом, нормально и даже не очень заметно.
И оно конкурирует за I/O с другими процессами, при том.
и пусть конкурирует.
Вы сами писали:
Свап — это хранилище вразнобой выгруженных мелких (4k/8k — в зависимости от архитектуры) страниц. Поэтому чтение из него всегда случайное, в один поток
фоновое чтение с небольшой глубиной очереди на ssd практически незаметно.
боль, конечно, может быть. если у вас в своп ушли почти все процессы. или иксы (мы же про десктоп говорим).
ну да, своп — не серебряная пуля, я этого и не говорил.
Это отдельный ssd что ли под ненапряжный своп? Или тот же, с которого грузится система, приложения, данные и временные файлы?
Даже лишнее чтение отнимает ресурсы контроллера, часть кеша накопителя, а ведь в своп что-то и положить надо, а тут ещё пользователь со своими котиками.
Некоторым данным вообще не место на накопителе, тем более в свопе — те же временные файлы, большинство из которых повторно не понадобятся, массово оседающие на диске и съедающие его ресурс и свободные ячейки — их логично было бы держать только в ОЗУ, но на данный момент избыток ОЗУ стоит дороже избытка ssd. Кажется, пора делать ОЗУ с многоуровневыми ячейками, как у флеш-памяти, для резкого снижения стоимости.
Это отдельный ssd что ли под ненапряжный своп? Или тот же, с которого грузится система, приложения, данные и временные файлы?
тот же самый.
не поленился, проверил
запустил fio на чтение с заполненного раздела с данными
root@edo-home:~# fio -ioengine=libaio -direct=1 -name=test -bs=4k -iodepth=1 -rw=randread -runtime=1m -filename=/dev/sda4 -time_based=1
test: (g=0): rw=randread, bs=(R) 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B, ioengine=libaio, iodepth=1
fio-3.25
Starting 1 process
Jobs: 1 (f=1): [r(1)][100.0%][r=30.8MiB/s][r=7893 IOPS][eta 00m:00s]
test: (groupid=0, jobs=1): err= 0: pid=592224: Tue Feb 23 15:27:55 2021
read: IOPS=7679, BW=29.0MiB/s (31.5MB/s)(1800MiB/60001msec)
slat (usec): min=2, max=54026, avg= 8.51, stdev=111.11
clat (nsec): min=996, max=40579k, avg=119089.36, stdev=287547.53
lat (usec): min=28, max=54033, avg=127.84, stdev=308.14
clat percentiles (usec):
| 1.00th=[ 94], 5.00th=[ 96], 10.00th=[ 97], 20.00th=[ 99],
| 30.00th=[ 100], 40.00th=[ 106], 50.00th=[ 112], 60.00th=[ 113],
| 70.00th=[ 115], 80.00th=[ 117], 90.00th=[ 128], 95.00th=[ 137],
| 99.00th=[ 217], 99.50th=[ 363], 99.90th=[ 1598], 99.95th=[ 2671],
| 99.99th=[13698]
bw ( KiB/s): min=25016, max=34712, per=99.99%, avg=30716.77, stdev=1624.95, samples=119
iops : min= 6254, max= 8678, avg=7679.19, stdev=406.24, samples=119
lat (nsec) : 1000=0.01%
lat (usec) : 2=0.03%, 4=0.01%, 10=0.01%, 20=0.01%, 50=0.03%
lat (usec) : 100=29.97%, 250=69.18%, 500=0.41%, 750=0.12%, 1000=0.06%
lat (msec) : 2=0.11%, 4=0.04%, 10=0.02%, 20=0.01%, 50=0.01%
cpu : usr=3.84%, sys=8.30%, ctx=468144, majf=0, minf=13
IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued rwts: total=460771,0,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs):
READ: bw=29.0MiB/s (31.5MB/s), 29.0MiB/s-29.0MiB/s (31.5MB/s-31.5MB/s), io=1800MiB (1887MB), run=60001-60001msec
Disk stats (read/write):
sda: ios=459929/1336, merge=0/22, ticks=50364/678, in_queue=252, util=97.26%запустил его же + в параллель чтение-запись своп-раздела
root@edo-home:~# fio -ioengine=libaio -direct=1 -name=test -bs=4k -iodepth=1 -rw=randread -runtime=1m -filename=/dev/sda4 -time_based=1
test: (g=0): rw=randread, bs=(R) 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B, ioengine=libaio, iodepth=1
fio-3.25
Starting 1 process
Jobs: 1 (f=1): [r(1)][100.0%][r=22.2MiB/s][r=5675 IOPS][eta 00m:00s]
test: (groupid=0, jobs=1): err= 0: pid=593900: Tue Feb 23 15:39:46 2021
read: IOPS=6058, BW=23.7MiB/s (24.8MB/s)(1420MiB/60001msec)
slat (usec): min=2, max=29879, avg= 9.43, stdev=87.35
clat (nsec): min=907, max=44641k, avg=152586.89, stdev=369362.55
lat (usec): min=42, max=44644, avg=162.39, stdev=384.55
clat percentiles (usec):
| 1.00th=[ 95], 5.00th=[ 97], 10.00th=[ 98], 20.00th=[ 101],
| 30.00th=[ 106], 40.00th=[ 112], 50.00th=[ 114], 60.00th=[ 116],
| 70.00th=[ 120], 80.00th=[ 127], 90.00th=[ 145], 95.00th=[ 196],
| 99.00th=[ 1385], 99.50th=[ 1975], 99.90th=[ 2573], 99.95th=[ 2769],
| 99.99th=[19006]
bw ( KiB/s): min=21104, max=26824, per=100.00%, avg=24256.47, stdev=1091.10, samples=119
iops : min= 5276, max= 6706, avg=6064.13, stdev=272.78, samples=119
lat (nsec) : 1000=0.01%
lat (usec) : 2=0.01%, 4=0.01%, 10=0.01%, 20=0.01%, 50=0.02%
lat (usec) : 100=17.87%, 250=78.41%, 500=1.16%, 750=0.46%, 1000=0.49%
lat (msec) : 2=1.08%, 4=0.45%, 10=0.01%, 20=0.01%, 50=0.01%
cpu : usr=3.24%, sys=7.71%, ctx=368317, majf=0, minf=14
IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued rwts: total=363515,0,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs):
READ: bw=23.7MiB/s (24.8MB/s), 23.7MiB/s-23.7MiB/s (24.8MB/s-24.8MB/s), io=1420MiB (1489MB), run=60001-60001msec
Disk stats (read/write):
sda: ios=634574/272861, merge=0/17, ticks=94131/10423, in_queue=152, util=98.20%root@edo-home:~# fio -ioengine=libaio -direct=1 -name=test -bs=4k -iodepth=1 -rw=randrw -runtime=1m -filename=/dev/sda5 -time_based=1
test: (g=0): rw=randrw, bs=(R) 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B, ioengine=libaio, iodepth=1
fio-3.25
Starting 1 process
Jobs: 1 (f=1): [m(1)][100.0%][r=16.8MiB/s,w=16.6MiB/s][r=4297,w=4246 IOPS][eta 00m:00s]
test: (groupid=0, jobs=1): err= 0: pid=593908: Tue Feb 23 15:39:46 2021
read: IOPS=4546, BW=17.8MiB/s (18.6MB/s)(1066MiB/60004msec)
slat (usec): min=2, max=23254, avg= 8.47, stdev=45.31
clat (nsec): min=811, max=44681k, avg=158310.89, stdev=419182.65
lat (usec): min=94, max=44687, avg=167.04, stdev=421.56
clat percentiles (usec):
| 1.00th=[ 94], 5.00th=[ 96], 10.00th=[ 98], 20.00th=[ 100],
| 30.00th=[ 104], 40.00th=[ 111], 50.00th=[ 113], 60.00th=[ 115],
| 70.00th=[ 118], 80.00th=[ 125], 90.00th=[ 141], 95.00th=[ 208],
| 99.00th=[ 1631], 99.50th=[ 2147], 99.90th=[ 2671], 99.95th=[ 2769],
| 99.99th=[21890]
bw ( KiB/s): min=15120, max=21336, per=100.00%, avg=18206.79, stdev=861.84, samples=119
iops : min= 3780, max= 5334, avg=4551.70, stdev=215.46, samples=119
write: IOPS=4552, BW=17.8MiB/s (18.6MB/s)(1067MiB/60004msec); 0 zone resets
slat (usec): min=2, max=1731, avg= 8.69, stdev= 8.11
clat (nsec): min=702, max=37628k, avg=38890.83, stdev=169189.64
lat (usec): min=28, max=37634, avg=47.85, stdev=169.43
clat percentiles (usec):
| 1.00th=[ 26], 5.00th=[ 28], 10.00th=[ 29], 20.00th=[ 30],
| 30.00th=[ 31], 40.00th=[ 32], 50.00th=[ 33], 60.00th=[ 36],
| 70.00th=[ 39], 80.00th=[ 43], 90.00th=[ 49], 95.00th=[ 58],
| 99.00th=[ 91], 99.50th=[ 117], 99.90th=[ 314], 99.95th=[ 734],
| 99.99th=[ 2999]
bw ( KiB/s): min=15672, max=20416, per=100.00%, avg=18231.20, stdev=852.33, samples=119
iops : min= 3918, max= 5104, avg=4557.80, stdev=213.08, samples=119
lat (nsec) : 750=0.01%, 1000=0.01%
lat (usec) : 2=0.06%, 4=0.01%, 10=0.02%, 20=0.10%, 50=45.50%
lat (usec) : 100=14.67%, 250=37.38%, 500=0.78%, 750=0.26%, 1000=0.27%
lat (msec) : 2=0.62%, 4=0.31%, 10=0.01%, 20=0.01%, 50=0.01%
cpu : usr=5.10%, sys=10.25%, ctx=551242, majf=0, minf=18
IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued rwts: total=272821,273180,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs):
READ: bw=17.8MiB/s (18.6MB/s), 17.8MiB/s-17.8MiB/s (18.6MB/s-18.6MB/s), io=1066MiB (1117MB), run=60004-60004msec
WRITE: bw=17.8MiB/s (18.6MB/s), 17.8MiB/s-17.8MiB/s (18.6MB/s-18.6MB/s), io=1067MiB (1119MB), run=60004-60004msec
Disk stats (read/write):
sda: ios=635730/273535, merge=0/17, ticks=94319/10263, in_queue=56, util=98.36%проседание дисковой производительности ≈27%, вы такое, скорее всего, просто не заметите (редко когда ssd на десктопе становится узким местом).
Некоторым данным вообще не место на накопителе, тем более в свопе — те же временные файлы, большинство из которых повторно не понадобятся, массово оседающие на диске и съедающие его ресурс и свободные ячейки
не надо про ресурс говорить, с моего домашнего накопителя:
9 Power_On_Hours -O--CK 100 100 000 - 41378
233 Media_Wearout_Indicator -O--CK 088 088 000 - 0аптайм больше 4.5 лет, износ по мнению накопителя 12%.
накопитель никак не берегу, своп используется весьма и весьма активно.
ssd, как мы уже выяснили, бывают несколько разные.
Пожалуй даже разница внутри класса может быть даже больше, чем разница с другими классами устройств.
И критерии тоже у разных людей разные… кого-то устраивает, что виртуалка ушла в своп вся, а кто-то к qemu прикручивает huge pages, лишь бы виртуалка не вздумала высвопиться.
Про очередь уже упомянули чуть ниже.
Минусуем потому что вы раздаете очень вредные советы, подкрепляя их вырожденным примером системы с недостатком RAM.
Принято, если не сложно — сможете детально объяснить:
1 — вред данного совета
2 — почему 5-7 лет назад выделять на swap при 8gb памяти 16gb swap считали крайне не рациональным использованием места на диске, но сейчас оно в принципе допустимо. И почему через те-же 5 лет данная экстраполяция работать не будет?
Если вам нужно 512 GB Swap, то это вас не спасет. Это лишь значит, что в системе не хватает примерно 512 GB RAM. RAM должна быть сильно быстрее SWAP, чтобы приложения могли работать. В вашем случае просто все приложения "встанут". Либо столько подкачки не нужно.
Правда забил я его почти полностью только один раз — когда запустил не оптимизированный скрипт парсера на php и натравил его на 5gb xml — но ничего не упало — наоборот через 48 часов получил ожидаемый результат.И компьютером в это время, полагаю, вы не пользовались.
Прокомментируйте, пожалуйста, рекомендацию устанавливать swap-раздел равным двум объёмам ram.
Пользуясь случаем хочу поблагодарить за статью, пойду сегодня раздел отрезать
Эта рекомендация была актуальна лет 15 назад.
https://opensource.com/article/18/9/swap-space-linux-systems первая таблица.
Линукс прекрасно работает с файловым свопом. У меня так вообще динамический файловый своп, организованый через systemd-swap.
Только гибернация тогда не работает...
DMGarikk поднимал.
А статья у него про это есть?
Вроде нет.
Емнип, свелось все к подставлению из root=UUID= в resume=UUID= и калькуляции смещения.
Вот про калькуляцию смещения и хотелось-бы посмотреть. А то может я этот неиспользуемый раздел, который у меня под гибернацию оставлен и использую в более полезное русло.
Гляньте тут
Работает. Только настраивать гибернацию на файловый своп несколько более геморройно чем на раздел. Поэтому у меня на ноуте давно лежит неиспользуемый раздел под это дело, только руки всё никак не дойдут настроить.
Когда вы записываете большой файл, у вас возникает большой пул грязных страниц. При массовой записи, система может начать освобождать чистые страницы и отдавать их под буфер записи. Ситуация очень похожая на анонимные страницы с тем только отличием, что грязные страницы можно сохранить (превратив в чистые) и снова использовать.
Ситуация очень похожа на то как если бы приложение начало активно отъедать память и описывается как вытеснение часто используемых данных из кэша.
Она имеет другую причину, но в целом получается то же следствие — просто есть шанс, что ситуация вернется в нормальное состояние, когда грязные страницы будут сброшены на диск



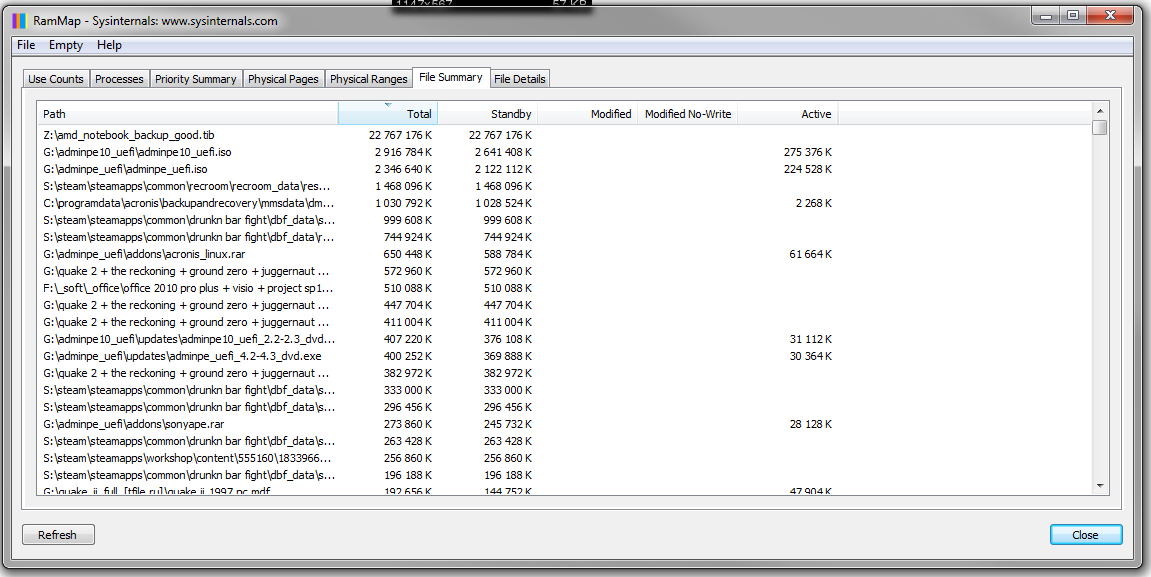
Это то, что получилось в итоге, а в процессе копирования планка поднималась практически до 60ГБ и балансировала на краю. Напомню, что подкачка у меня отключена. И вот теперь, этот набор висит и не освобождается. Запуск «Empty standby list» в программе RamMap изменил ситуацию вот так:
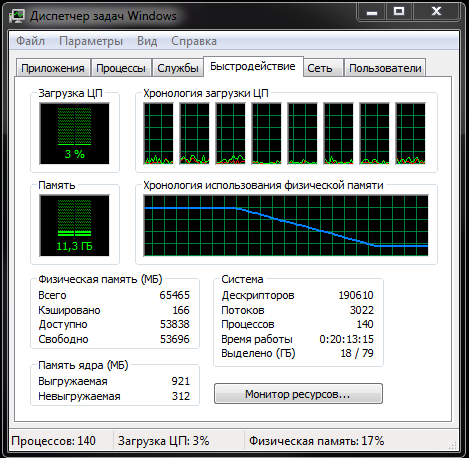


Интересно то, что при той же, с точки зрения пользователя, операции — простое копирование файлов — использование памяти при MTP и при обычном копировании в одной и той же программе (в эксплорере) так разительно отличается: при простом копировании занимается «Ожидание» (голубой цвет), а при MTP копировании «Используется» (зелёный цвет).
Какой именно драйвер держал память — это можно было бы посмотреть с помощью poolmon64, по четырехсимвольному тегу элементов пула, но сейчас уже, понятно, это не скажешь.
А в принципе, при таком хорошем поведении дравера на эту забираемую им под кэш память можно обращать не больше внимания, чем на кэш файловой системы.
PS Хотя вы пишете, что у вас подкачка отключена, но система в дополнение к физическим 64ГБ видит где-то ещё 16.
PS Хотя вы пишете, что у вас подкачка отключена, но система в дополнение к физическим 64ГБ видит где-то ещё 16.
А, блин, действительно. Я что-то проверял и действительно установил 16ГБ на своп. Видимо этот своп и юзался, когда при копировании балансировал на уровне 60ГБ. Я ещё удивился, что не выстрелило окно об нехватке ресурсов.
Если я смогу повторить этот случай, куда и чем конкретно мне следует посмотреть? Вдруг это тоже будет интересно.
(не говоря уж об ультрабюджетных ноутбуках с распаянными и нерасширяемыми 4GB), то swap достаточного объема (не менее 1 x ) это "то, что доктор прописал".
На таких ультрабуках и памяти на диске не то что бы много. И большую её часть занимает ОС. И порой этих самых свободных 1x вообще нет.
до отключения — были тормоза были частые, но система отмерзала минут через 5
после — компьютер зависал редко, но намертво
с точки зрения пользования компом для меня второй вариант предпочтительнее
Он, среди прочего, поучаствовал активно в разработке линуксового ядра и у него есть несколько интересных статей — в том числе про swap.
И почему-то мне кажется, что мнение человека, который участвовал в разработке подсистем, которые используются едва ли не половиной современного IT (cgroup и cgroups_v2, которые в общем то лежат по дкапотом systemd, докера — а значит и кубика и много чего ещё) обосновано на существенно более широком и глубоком представлении о предмете, чем привычная многим «доказательная база» «а вот у меня на ноутбуке» :-)
Вы, вероятно, русскоязычный перевод читали? Потому что в оригинале чётко видно:
- Disabling swap does not prevent disk I/O from becoming a problem under memory contention, it simply shifts the disk I/O thrashing from anonymous pages to file pages.
Поразительно, но в русскоязычной версии это звучит совсем иначе:
Отключение подкачки не мешает дисковому вводу/выводу стать проблемой при работе с памятью, а просто сдвигает дисковую подкачку ввода/вывода с анонимных страниц на файловые.
И куда же делось "under memory contention" (это можно перевести как "нехватка памяти")?
Второй момент тоже ссылается на OOM:
Disabling swap doesn't prevent pathological behaviour at near-OOM, although it's true that having swap may prolong it.
Но самое важное идёт чуть дальше, где он описывает ситуации, в частности отсутствие нехватки памяти:
With swap: We can choose to swap out rarely-used anonymous memory that may only be used during a small part of the process lifecycle, allowing us to use this memory to improve cache hit rate, or do other optimisations.
Without swap: We cannot swap out rarely-used anonymous memory, as it's locked in memory. While this may not immediately present as a problem, on some workloads this may represent a non-trivial drop in performance due to stale, anonymous pages taking space away from more important use.
Со свопом — мы может улучшить попадание кэша и ещё что-то мелкое, но очевидно что если памяти более чем достаточно они и так будут хороши. А без свопа — таки да — после дождичка в четверг, когда (если) рак на горе свистнет — отсутствие свопа может стать проблемой и когда памяти достаточно, но это не точно. Я вот на своих и клиентских системах (многие не имеют свопа) и не встречал такого, да и кубернеты его не используют и не жужжат.
Так что да, мнение специалиста существенно — если конечно читать его полностью.
обосновано на существенно более широком и глубоком представлении о предмете, чем привычная многим «доказательная база» «а вот у меня на ноутбуке» :-)
Так себе аргумент, если честно. Может для рядовых пользователей все таки важнее их личный опыт, а не стороннее, хоть и экспертное мнение?
А по существу — будучи более программистом, чем сисадмином, всегда отключаю своп, потому что в стандартной Убунте, например, при включенном свопе просто-напросто не отрабатывает OOM killer. В результате в ситуации пробуксовки (например, если компилируется что-то большое на всех ядрах) система зависает намертво, спасает только перезакгрузка.
но в моем случае я привел пример двух случаев в которых нет вообще варианта который был бы лучше или хуже всегда и для всех
и не представляю что тут возразит эксперт. видимо по мнению тс что лучше чтобы висло чаще, но отмирало
И почему-то мне кажется, что мнение человека, который участвовал в разработке подсистем… «а вот у меня на ноутбуке» :-)С точки зрения человека, использующего линукс на ноутбуке, результаты рядовых пользователей меня волнуют больше, чем мнение разработчика ядра. Всё же ситуации бывают разные.
К тому же в статье вы совершенно не упомянули другую ситуацию, когда система начинает непрерывно гонять страницы разных процессов, например компилятора и браузера, в результате чего звук начинает залипать как пластинка, экран не перерисовывается не то что минутами, а по пол часа, а ядро даже не пытается что-то сделать, своп же есть, значит всё хорошо.
Держу только zram, там даже если и возникнет такая ситуация, то будет длится недолго.
На своей файлопомойке (16ГБ оперативной, из работающего торенты и nginx для раздачи файлов в локальной сети и nfs) заметил, что всегда используется 30-150МБ свопа при
$ free
всего занято свободно общая буф./врем. доступно
Память: 16060308 1685156 179480 1444 14195672 14034148
Подкачка: 2097148 39424 2057724
и подозреваю кэш забит тем большим архивом на 4ГБ который я копировал 3 дня назад, именно тогда забился весь кэш, и да — это просто пример, на самом деле часто бывает перелил большой файл и он тебе больше не нужен, а оперативка уже полная. В такой ситуации лучше оперативку освободить, чем держать своп.
zram кажется достаточно костыльным как решение для свопа — это всё-таки главным образом просто решение по созданию сжатого блочного устройства в памяти
zswap несколько интереснее выглядит в данном контексте
Но zswap должен быть подперт реальным свопом, по сути, он перехватывает выгрузку страниц, сохраняя их в сжатом виде (и разжимает при реальной записи в свап).
Не совсем так. Вернее совсем не так.
Zswap пытается сжать данные перед записью на диск и, в случае успеха, оставляет данные в оперативной памяти, занимая в ней место по мере необходимости и до достижения указанного предельного процента от общего объема памяти.
Те же данные, что не сжимаются или сжимаются плохо уже пишутся на реальный диск.
В итоге у вас всё сжимаемое точно так же, как в zram, в памяти и остаётся. А вот несжимаемое перестаёт висеть в оперативке, вместо этого выгружаясь в несжатом виде на диск.
И такой подход лишен некоторого количества подводных камней zram
Ага… про несжимаемые страницы — важное уточнение, спасибо.
У zram главный подводный камень, вроде, zsmalloc, у которого проблемы с инвалидацией, отчего время от времени активно используемый zram надо пересоздавать. И те же проблемы будут и у zswap, если использовать этот аллокатор.
Этот использует z3fold в качестве аллокатора для zswap.
Мне, как-то, мои процессы, с несохранёнными данными, важнее чем отсутствие свопа.
Почему в 2021 можно запустить жирный SQL запрос к локальной БД (на десктопе с ubuntu 20.04 допустим) и она поставит компьютер на колени, да так что только ребут поможет.
Памяти нет?
Засвопим иксы на диск!
Запустить тот же стресс на память и тоже самое => компьютер в коматозном состоянии.
Своп вредная и глупая (по меркам 2021 года) для решения проблем с нехваткой и просто организацией памяти.
Перекладывать проблему высокого I/O и малого количества ОЗУ с больной головы на здоровую, так себе идейка.
Памяти нет?
Засвопим иксы на диск!
то что в линуксе gui не имеет такого приоритета как в винде, что если чтото тормозит, то даже консоль переключить не можешь, к свопу отношения никакого не имеет.
Почему в 2021 можно запустить жирный SQL запрос к локальной БД (на десктопе с ubuntu 20.04 допустим) и она поставит компьютер на колени, да так что только ребут поможет.
чтобы такого не было, существуют специально обученные люди, DBA, они настраивают базу так чтобы она не рушила сервак на котором работает
Дешевле?
Для меня дело не в есть-нет, а в том, что дешевле — один из критериев лучшести. Оценки лучше-хуже бессмысленны без списка критериев и оценочной функции. Кто-то готов платить любые деньги за 1% производительности (а это не одна метрика, а тоже несколько), а кто-то и доллара лишнего не выделит за 100% прироста
— почему линукс использует awap?
— потом, что хозяин экономит на ram
не осуждаю, но если дело тольков этом, то можно и не мудрствовать было.
потом, что хозяин экономит на ram
Или потому, что запустил ресурсоемкую задачу, которую ранее не было необходимости решать но которая вроде бы должна влазить в ресурсы. И теперь не понимает, почему всё тормозит хотя вроде бы показатели в пределах нормы
Причем задача очень точно подогнана по ресурсоемкости: так, чтобы памяти не хватало, но хватало со свопом.
И этот случай возводится в абсолют.
А, и еще постулируется, что обязательно есть куча памяти, к которой гарантировано не будет обращений.
Вы же сами утверждаете, что размер свопа зависит от юзкейсов и индивидуален для каждого юзера. Почему вы при это настаиваете, что нулевой размер является каким-то особым числом, которое недопустимо?
> к свопу отношения никакого не имеет
Как оно не имеет отношения, если кернел решает засвопить важный код и потом при обращении к нему, его надо доставать из свопа и это приводит к аду.
> то что в линуксе gui не имеет такого приоритета
Дело не в приоритете (в каком смысле «приоритет» вообще, как процесс в ОС или в плане внимания как к подсистеме в целом?), а в плохом дизайне системы.
Я уже молчу про легендарные баги типа 12309.
Страницы просто реклеймятся и НЕ отправляются в свап, и потом поднимаются НЕ из свапа а с системного раздела. Поэтому если у вас есть свап — у вас есть шанс сохранить код в памяти при стрессовой нагрузке, а если свапа нет — то ваш код гарантированно из памяти вылетит — и начнется трешинг и 12309.
Максимум пользовался в каком-то лайтовом режиме.
Управление памятью в линуксе это буквально фрактал плохого дизайна, начиная со свопа и заканчивая банальным копированием файлов на флешки (при котором диалог копирования исчезает через секунду и надо долго и нудно безопасно «извлекать устройство», что технически «работает же», а с точки зрения UX просто позор).
Управление памятью в линуксе это буквально фрактал плохого дизайна, начиная со свопа и заканчивая банальным копированием файлов на флешки
Утащил в цитаты, более точного определения ситуации не встречал
Вот это дело.
Это не у одного меня проблемы, и эти проблемы просто не замечают.
Единственная проблема моих постов тут это направленность на десктоп, а обсуждается всё таки серверное применение больше. Ну сорян, наболело.
Своп всё равно не может устранить I/O полностью, которое на современной системе ставит крест на отзывчивости и стабильности системы на десктопе.
Ещё раз напомню, 2021 год, многоядерные системы, даже в телефонах и впс уже 2-4-6гб озу это вполне доступные характеристики, нет совершенно ни одной причины, почему система могла бы становится неотзычивой.
В таких условиях защищать подсистему своппинга лозунгами «это механизм оптимизации подсистемы виртуальной памяти», это как кричать «ПОДУМАЙТЕ О ДЕТЯХ» на любую реплику оппонента.
Люди отключают своп и живут годами, выполняя самые разные задачи с самыми разными требования и пограничными значениями нагрузки на различные подсистемы памяти без крашей.
Опять же я не отвергаю того, что крашей нет вообще, они бывают и свап иногда приходится включать. Но всё это лишь подтверждает плохой дизайн системы, не отвечающий современным требованиям.
Я просто оставлю это здесь. 6 гигов памяти, телеграм, браузер с полтинником вкладок, музплееер, кучка терминалов. В фоне крутится всякий докер swapon показывает вот так.
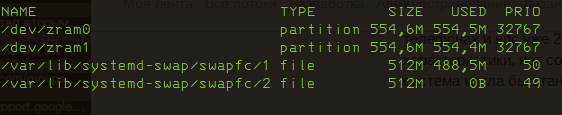 Да. Правда занятость памяти в среднем 80-87%.
Да. Правда занятость памяти в среднем 80-87%.
А зачем два zram устройства?
> Дайте мне ту большую кнопку со всем известной надписью сделать мне… хорошо!
Когда нечего сказать — начинай корчить из себя остряка.
И все эти «остроты» никак не объясняют почему, нельзя выставить нормальные дефолты для десктопной (да и для серверной ОС) изначально (особенно если это возможно и линукс претендует на звание лучшей или хотя бы хорошей алтернативы ОС от майкрософт и эпла).
Тем более если ты, сам очень рад понастраивать всё самостоятельно, а те кто не знакомы будут сразу иметь нормальную систему, которая внезапно не встанет колом.
Если ты, умник, думаешь что я не умею пользоваться гуглом, или сам не решают эти проблемы у себя на машинах и просто критикую потому что я лаааааамир, то ты ошибаешься.
И шрифт у тебя в консоли паршийвый, а прозрачность без размытия вообще стыдно должно показывать.
И все эти «остроты» никак не объясняют почему, нельзя выставить нормальные дефолты для десктопной (да и для серверной ОС) изначально (особенно если это возможно и линукс претендует на звание лучшей или хотя бы хорошей алтернативы ОС от майкрософт и эпла).
в целом поддержу, потому что такая же проблема с настройкой под 10k rps, безопасности и всего прочего. То что является дефолтами в линуксе — это мусор, который каждый здравомыслящий пользователь затюнивает под себя (не без боли!).
Тем более если ты, сам очень рад понастраивать всё самостоятельно, а те кто не знакомы будут сразу иметь нормальную систему, которая внезапно не встанет колом.
лично я уже не рад, потому что есть куча других вещей, которые интересно поделать — например, ракеты в космос с Илоном позапускать, а не ковырять — почему в конфиге по дефолту не та цифирка прописана )
Хорошо, когда тюнинг — это стиль жизни, но тогда чем такой человек отличается от фаната автотюнинга?
То что является дефолтами в линуксеНет такого понятия «дефолтно в линуксе». Все настройки специфичны для каждого конкретного дистрибутива.
(осталось только написать что надо использовать гну+линукс, а не просто линукс, и отправиться в плавание по волнам шизофазии придираясь к каждому слову — ну не может же так быть что даже в народе словом линукс обозначают любой достаточно популярный и крупный дистрибутив десктопного или серверного линукса, нееееееееееееееее)
Настройки в дистрах тоже дифолты, а ты чудачелло.
Upd: и такой минусом доказал, что настройки в дистрах это не дефолты (и то что они не причиняют неудобств пользователям), а минусом в карму закрепил пройденное — закономерное поведение для человека которому вахтёрские полномочия заменили честь и достоинство.
Ты что думаешь что я вру о своих проблемах и просто хочу опорочит святую репутацию линукса на десктопе?
Это не у одного меня проблемы, и эти проблемы просто не замечают.
десктоп, linux, 32 гигабайта памяти и столько же свопа.
почему система могла бы становится неотзычивой.
система становится неотзывчивой только когда съедаются эти 64 гига (обычно это фф+хром+виртуалки), прибьёшь что-нибудь и отпускает.
чяднт?
P. S. недавно приехал nvme на терабайт, сделаю своп на 64 гигабайта
Чего это не восстановлю? С какого перепугу? GUI не отвечают? Так для этого SysRq комбинации никто не отменял. Ни разу не было такого, что невозможно было перейти в tty после нажатия Atl-SysRq-B и там уже порешать все вопросы.
Хм. Даже при работе через xRDP (ssh/vnc/etc.)?
Было так, что перехожу в TTY логинюсь и всё, невозможные тормоза, никакую команду полностью не ввести.
А бывало ещё, что в некоторых дистрибутивах отключены комбинации sysrq и узнаешь ты об это когда потеряешь данные.
И?
И надо настраивать. Что у вас, дистрибутив гвоздями все настройки прибил?
Вот у меня тоже кстати были проблемы с входом в tty консоль после того, как все повисло в графической сессии. Т.е. переключится в нее (по Ctrl+Alt+1/2/3/...) может еще и удастся, но так как это первый вход в нее, то туда еще залогинится нужно, а там все висит. В тот раз проще было просто сделать физический ребут
У нас на сервере с 4ТБ памяти своп отключен.
Поэтому ответ на вопрос «нужен ли своп» — по ситуации. Просто надо понимать как это все работает.
а вот залипший агент какойнить мониторилки может выжрать всю оставшуюся память и уронить сервак, до того момента когда это заметят ответственные.
иногда в таких случаях своп может дать время до того как всё рухнет
Баги могут быть любыми, сама БД тоже может выжрать всю память из-за бага.
Основной посыл был про «ответ на вопрос «нужен ли своп» — по ситуации.»

а вот залипший агент какойнить мониторилки может выжрать всю оставшуюся память и уронить сервак, до того момента когда это заметят ответственные.
Он и своп так же выжрет. Поэтому нужно:
1) Адекватный мониторинг и реакция
2) Правильная настройка oom_score чтобы ядро гасило "агент мониторилки", а не СУБД или что там
3) Запускать всякую хрень в своих cgroup с лимитированной памятью. У меня так несколько stateless сервисов крутятся, которые могут кушать память зверски если клиент запрос необдуманный пришлёт. Дохнут при достижении 5-10гиг и запускаются заново.
Если «есть достаточное количество быстрой», то «медленная» использоваться не будет.
Ошибочное утверждение. У меня на железке с 256Гб RAM линукс умудряется свапить даже когда там и 10% не занято. И это при vm.swappiness=0/1
Скорее, это механизм защиты SSD от износа. Так как многие могут арендовать дешевый сервер с 0.5 ОЗУ и довольствоваться файлом подкачки. Об этом, например, пишет DigitalOcean:
https://www.digitalocean.com/community/tutorials/how-to-add-swap-space-on-ubuntu-18-04-ru
Во первых, значительная часть их EBS, тоесть вообще том в сети. Задержки сети очень сильно влияют на своп
Во вторых, часть имеет ephemeral storage, на который вы как раз и должны поместить своп, если он вам нужен, уже после подгрузки AMI.
Ну и не забывайте, что Amazon выгодно продать инстансы с большей памятью, они дороже.
И, пожалуй, едва ли не самая частая неправильная оптимизация — отключение swap-файла.
кубернетес не умеет работать со свапом, так что его отключение необходимо — шах и мат.
Не говоря уже о том, что можно было линукс спроектировать так, чтобы свап ему был не нужен в принципе, но нет… Кривая архитектура, что поделать
Гуглите vm.swappiness. Если сильно упрощать понятия, то можно считать этот параметр процентом свободной оперативной памяти при котором страницы начинают сбрасываться в swap. большинстве дистрибутивов сброс страниц в swap начинается при занятом объёме оперативной памяти более 60%. Особенно это влияет на производительность в случае размещения swap раздела/файла на механическом накопителе так как приводит к простою процессорных ядер (iowait). Для своей рабочей станции я всегда устанавливаю этот параметр в 10 — 20 что значительно сокращает операции ввода/вывода, и работать становится комфортно.
Господи, как мы докатили себя до такой жизни?
Начинали с
Когда возникает необходимость в swap-файле? Самый частый ответ — «когда не хватает памяти». И, естественно, это ответ неправильный почти полностью.
, а закончили
Таким образом, отключение / отсутствие swap-файла, равно как и его малый размер, отрицательно влияет на производительность в условиях начала нехватки памяти, не позволяя системе выгружать наименее используемые страницы и заставляя делать лишние записи там, где запись, на самом деле, не нужна — ведь вместо того, чтобы удержать код, к которому мы обращаемся часто, система вынуждена сохранять в памяти данные, к которым мы не обращаемся — потому что их негде больше сохранить.
Но суть здесь:
Ведь ответ очень прост — этот кэш на самом деле не просто кэш, а код. И если код используется чаще, чем данные — то в данном случае более важно сохранить в памяти код (сохранить кэш) чем удерживать в памяти данные!
Именно поэтому свап отключают: чтобы "глупая" система вообще никогда не отправляла код в свап и работала быстрее. Потому что иначе может быть другая ситуация — есть куча чистых страниц, но часть кода все равно ушла в свап и при переключении приложений будут тормоза(хотя в системе может быть куча свободной памяти).
P.S. про vm.swappiness я знаю
Код лежит в кэше и свап позволяет этот кэш сохранить.
Код может быть «вымыт» из кэша неиспользуемыми данными, если у вас нет свапа.
Вся эта мышиная возня актуальна только тогда, когда памяти не хватает.
А если ее хватает, то свап должен быть отключен для максимальной производительности.
Но со свапом отзывчивость системы практически не изменится
Зато отзывчивость ВМок упадет до неюзабельного состояния. А когда их страницы все же попадут в память, начнет тупить что-то другое. И так до бесконечности.
Снова абсурдный и вымученный пример одной и той же ситуации: недостатка памяти для задачи.
В случае ВМок — что еще хуже — мы вообще не понимаем, что там на слое гипервизора происходит. Там может происходить любая магия от свопинга памяти виртуалки до ее уплотнения через всякие zram'ы.
Все-таки не похоже, что своп для ВМок (именно внутри ВМ на уровне ОСи, не говорим про гипер, которым мы в общем случае не управляем) — хорошая идея.
Но со свапом отзывчивость системы практически не изменится, поскольку эти ВМ примерно 50% своей оперативки не используют — и её можно отгрузить в свап.Только за счёт этого обмана всё и держится.
проблему которого для большинства пользвателей свап достаточно хорошо решает.
Это ложное или как минимум — неподтвержденное утверждение
Теперь я хочу понять, утверждаете ли вы, что если я докуплю RAM размером со SWAP и выключу последний, система станет хуже работать?
Код не уходит в свап.
а как же самомодифицирующийся код? Такое же бывает. Тот же UPX.
Для бытовых задач ресурс SSD можно считать бесконечным, плюс он прогнозируется.
В начале десятых использовал SSD как раз на компьютере с малым количеством RAM чтобы хоть как-то его ускорить. К концу десятых этот 64 ГБ ссд все еще имел ресурс.
ЕСЛИ у вас достаточный объем свапа, чтобы сгрузить туда такие редко используемые редко меняющиеся данные.
либо столь же стремительный расход ресурса SSD за счёт записи данных в swap.
Вы серьёзно? Я вот поначалу тоже пытался экономить ресурс, потом плюнул на это дело и настроил своп на SSD, потому что комфорт важнее копеечной экономии. И оказалось, что своп не так уж сильно и расходует ресурс — скорость износа выросла примерно в полтора раза. В итоге сейчас у SSD, купленного в 2011 году и отработавшего уже 79196 часов, осталось ещё 97% ресурса. При его использовании в том же темпе он полностью износится к ~2300 году.
Расход ресурса SSD, при своппинге, это не более чем миф.
Например, Java приложения с установленным Xmx практически всегда потребляет ровно столько, сколько ему выделили (плюс, например, фиксированный процент на G1 и память помимо heap). В этом случае, если службы сконфигурированы таким образом, чтобы потреблять всю физическую память, но практически никогда ее не превышать. И когда linux начинает в определенные моменты задействовать зачем-то своп, то этот немного напрягает (даже при выключенном vm.swappiness в 0).
Но в целом, иногда поведение свопа в linux очень загадочно. У меня, например, было, когда на сервере с 512ГБ и 4ГБ свопа (так получилось), linux начал загонять в своп при free memory где-то под 64ГБ и vm.swappiness = 1.
Для критических служб, которые не должны высвапливаться, есть замечательная директива в юнитах sysytemd. MemorySwapMax=0. Ну и разумеется по памяти, при необходимости, службу можно жёстко зафиксировать, директивой MemoryMax=. Так что не только Java ;-). Всё это безобразие, разумеется, работает через механизмы cgroups и описано в man systemd.resource-control. Кстати новомодным (с версии systemd 247) Early OOM тоже можно рулить, регулируя его реакцию на нехватку оперативы не только для всей системы но и для отдельных юнитов.
Но если у вас бюджетная система с 8 … 16ГБ оперативной памяти (не говоря уж об ультрабюджетных ноутбуках с распаянными и нерасширяемыми 4GB), то swap достаточного объема (не менее 1 x ) это «то, что доктор прописал».
Вот этого не очень понял.
Не отключал swap, так как во-первых особо и не жалко, во-вторых, он при спящем режиме ещё используется.
Но почему именно x1?
Предположим, спящий режим не нужен, и я вижу, что с 16 гигабайтами оперативки в swap иногда попадает от силы сотня-другая мегабайт. Допустим, сделаю swap-раздел 1 гигабайт, ну 2 максимум — этого достаточно? 16 гигабайт как-то жалко отдавать, особенно если более 15 из них не будет использоваться, можно на более полезное потратить…
Есть ли причина в этих обстоятельствах именно 16 гигабайт делать, а не 1?
Понятно, что в случае спящего режима нужно больше, мне хочется понять механику.
Предположим, спящий режим не нужен, и я вижу, что с 16 гигабайтами оперативки в swap иногда попадает от силы сотня-другая мегабайт. Допустим, сделаю swap-раздел 1 гигабайт, ну 2 максимум — этого достаточно? 16 гигабайт как-то жалко отдавать, особенно если более 15 из них не будет использоваться, можно на более полезное потратить…
насколько мне известно — в винде под гибернацию отдельный файл — hiberfile.sys, а это вовсе не то же самое, что и page cache.
Линукс гибернируется в своп. Причём менее гемморойна настройка гибернации именно в раздел.
Спасибо за разъяснение, но очевидно, что это нужно только для рабочих машин (и ноутов) под линуксом, т.е. вовсе даже не основное предназначение этой ОС (мы не в основном на серверах и в IoT используем, где гибернация не нужна)
Более того, это нужно более для ноутов, чем для десктопов. А так-то конечно. Серверам гибернация нафиг не сдалась… Кстати интересная мысль, в порядке академического интереса так-сказать. А бывает гибернация для виртуалок?
На proxmox да. Скрин не загружается на hsto, но оно там в дропдауне Shutdown.
А средствами гостевой ОС оно работает? А это-то я знаю. Сам пользуюсь. Оно сейчас наверно на всех средствах виртуализации есть.
В смысле, увести гостя в его собственную гибернацию, дернув агента, чтобы не плодить отдельный файл состояния?
Qemu-guest-agent позволяет выполнять произвольную команду с хоста.
С выключением получалось у людей, должно прокатить и с гибернацией. Что-то вроде:
qm guest exec <VMID> -- shutdown.exe -h
бывает гибернация для виртуалок?
У виртуалок есть pause/suspend с сохранением состояния вм (включая ОЗУ) в файл на диске. Это было ещё в VMware 3-й версии более десяти лет назад
Спор древний, как сам swap :). Автору спасибо за пост, навевает ностальгию.
Я просто оставлю это тут:
MemTotal: 65775944 kB
MemFree: 7217460 kB
MemAvailable: 63834360 kB
Buffers: 7088764 kB
Cached: 46322704 kB
SwapCached: 0 kB
Active: 33390252 kB
Inactive: 20965760 kB
Active(anon): 513356 kB
Inactive(anon): 505112 kB
Active(file): 32876896 kB
Inactive(file): 20460648 kB
Unevictable: 8276 kB
Mlocked: 8276 kB
SwapTotal: 134217724 kB
SwapFree: 134216180 kB
Dirty: 64 kB
Writeback: 0 kB
AnonPages: 952856 kB
Mapped: 449444 kB
Shmem: 71196 kB
KReclaimable: 3899904 kB
Slab: 3965808 kB
SReclaimable: 3899904 kB
SUnreclaim: 65904 kB
KernelStack: 13280 kB
PageTables: 16960 kB
NFS_Unstable: 0 kB
Bounce: 0 kB
WritebackTmp: 0 kB
CommitLimit: 167105696 kB
Committed_AS: 5746280 kB
VmallocTotal: 34359738367 kB
VmallocUsed: 57500 kB
VmallocChunk: 0 kB
Percpu: 8256 kB
DirectMap4k: 277680 kB
DirectMap2M: 16408576 kB
DirectMap1G: 50331648 kB

Это все хорошо, но как заставить oom killer убивать процессы до того как система намертво повиснет при нехватке памяти? Мне помог только earlyoom.
все настраивается и работает, было бы желание. earlyoom не смотрел за ненадобностью, но подозреваю что как раз и дергает в конечном итоге настройки штатного oom-killera…
как заставить oom killer убивать процессы до того как система намертво повиснет при нехватке памяти?
2 пути:
- Патч ядра, обеспечивающий запрет вытеснения файловых страниц из памяти при нехватке памяти — https://github.com/hakavlad/le9-patch
При применении патча OOM killer приходит быстро и без заморогки гуя. Демо — https://youtu.be/iU3ikgNgp3M — открытие вкладок хрома, MemTotal=2.3G, пространства подкачки нет. Вкладки падают, заморозки нет. В этом видео повторяется известный опыт Артема С. Ташкинова — https://lkml.org/lkml/2019/8/4/15. - Юзерспейсная реализация — prelockd — https://github.com/hakavlad/prelockd. Это демон, блокирующий в памяти разделяемые библиотеки и исполняемые файлы. При этом киллер также приходит быстро. Демо: https://youtu.be/vykUrP1UvcI.
А относится ли это к zRam swap, который использует сжатие данных в ОЗУ вместо записи на диск?
В принципе это мало чем отличается от отсутствия свопа, хотя даёт системе ещё небольшой резерв памяти.
Все остальные случаи требуют индивидуального подхода, может быть с применением шаблонов, но от того подход не перестанет быть индивидуальным.
А что делать на Raspberry Pi 3 с 1Г памяти и 100 мб подкачки на sd-карте, как правильно? Карту не жалко. Производительности хватало бы, но ядро регулярно уходил в Лок по OOM, то есть полное зависание.
тупит будет. Но будет работать
Но можно добавить внешний SSD пусть даже по USB, станет существенно стабильней
SD карта слишком медленная из-за крайне низких показателей IOPS.
Только усугубите ситуацию. SSD через USB будет лучше. Даже саташный.
Либо варианты с zRam.
а на счет «свопить гипервизору» — вот он-то как раз ничего не должен свопить. потому что если он начнет «свопить» память гостей, то это уже будет жессточайший оверселлинг по памяти и такой гипервизор (провайдер) должен идти лесом.
Но если у вас бюджетная система с 8 … 16ГБ оперативной памяти
Бюджетная система — это когда 1 или 2 ГБ памяти.
И про очень тормозную NTFS? )
Была такая боянистая статья, кажется, года 1994, в которой говорилось, что ntfs ест дофига памяти и предлагался всяческий тюнинг… в 2010 еще была популярна в рунете.
примерно как последние лет 8 с zfs.
Ну, корпорация-производитель тоже ставит не оптимальные (в данном конкретном случае) а приемлемые в пределах решета Парето настройки. Причем не факт, что выборка, на базе которой выбирались критерии — репрезентативна.
Плюс это еще отягощяется позиционированием и "тут половина компонентов вообще не нашей разработки", так что дефолты вполне могут (и должны) быть suboptimal на некоторых конфигурациях.
Откуда и растут такие статьи.
И если бы, к примеру, не
Наверное имелась в виду эта статья?
но как-то в ней все смешалось — кони, люди… особенно в комментариях.
как уже говорилось выше, в статье полностью отсутствует упоминание об оверкоммите, хотя речь идет в основном об линукс. из-за этого в коммнтах все в кучу — винда, линукс — хотя это совершенно разные реализации как виртуальной памяти так и механизма выделения памяти в целом. и об этом ни слова, потому в комментариях куча-мала…
Анонимные страницы отсвапливаются если маркер свободной памяти опускается ниже определенного порога и к странице не было обращений очень/достаточно давно. Если свободной памяти много — свапиться ничего не будет. И overcommit тут ни при чем вообще.
и да, и нет.
Он просто не дает процессам запросить слишком много памяти, и он никак не влияет ни на свап, ни на OOM-killer
да, но косвенно — мы потребляем ВЫДЕЛЯЕМ БОЛЬШЕ -> БОЛЬШЕ потребляем памяти -> активнее швоппимся
Если свободной памяти много — свапиться ничего не будет.
проблема в том, что условие "если" неверно — памяти никогда не бывает много )
И overcommit тут ни при чем вообще.
в этом смысле "да"
оверкоммит позволяет запросить процессам (группе процессов) больше физической памяти, чем ее есть на самом деле. это происходит не всегда, но теоретически моет сложится ситуация, когда множество процессов одновременно запросят много больше памяти, чем ее есть в системе. не просто запросят, а начнут юзать — и вот здесь вступает в игру своп.
таким образом оверкоммит хоть и косвенно, но весьма сильно влияет на стратегию распределения памяти. а не будь в системе подкачки он вообще бы не сработал (malloc() вернул бы ошибку).
дальше — в венде, насколько я знаю, оверкоммита нет вообще. а люди здесь, в комментах, по-большей части только про венду и говорят. поэтому я и сказал, что статья в этом плане не полна, так как в ней не сделан акцент на то, что она в общем-то про линукс.
p.s. Получается что у меня редко используемых библиотек, которые безболезненно могут находиться в swap до полугигабайта.
Со свапом вообще парадоксальная ситуация, очень много рассуждающих о нем, в действительности, не понимают механизмов его работы, например:
активная запись в свап в целях превентивного вытеснения анонимных страниц НЕ означает, что система будет тормозить — этот процесс просто в фоне создаст пул свободных страниц, которые приложения смогут использовать когда потребутеся. Такой пул (внезапно!!!) на самом деле необходим, потому что в линуксе (да и везде в общем то) аллокация памяти оптимистичная — память обещается но выделяется при первом обращении. Поэтому чтобы программы могли при необходимости быстро достучаться до своей памяти, часть анонимных страниц может быть унесена в свап, равно как и часть чистых страниц кэша отреклаймлена. И что именно туда будет унесено — будет решено через LRU. То есть к чемы по статистике реже всего ходите — то и уходит на диск
нехватка памяти не обязательно выражается в активной ЗАПИСИ в свап — она может выражаться в активном ЧТЕНИИ из свапа — например вы загрузили десяток 4K картинок в смотрелку и переключаетесь между ним и скроллите их. При этом анонимные страницы пиксмапов могут легко уехать в свап и постоянно — и многократно — оттуда доставаться, но не перезаписываться.
То есть ваш «p.s.» неправилен вообще :-)
активная запись в свап в целях превентивного вытеснения анонимных страниц НЕ означает, что система будет тормозить
Извините, но активное шевеление диском по определению означает тормоза. Своп — не единственный пользователь IO; и, с точки зрения пользователя, — не самый приоритетный.
А вообще, по хорошему, нужен инструмент, позволяющий подглядеть, что именно падает в своп и как падает на реальной системе. Не cat с глоббингом.
Just let it fall.
Если оно кривое — оно не должно все тормозить и приводить монитор в негодность посредством столкновения с мясом.
Оно должно быстро и гарантированно умирать, чтобы багтрекер раскалялся.
EarlyOOM в помощь
Можно не ждать. Если правильно настроен SysRq, то волшебный хоткей Alt-SysRq-F призывает OOMKiller.
Но если у вас бюджетная система с 8 … 16ГБ оперативной памяти
Одна фруктовая компания выпустила такой ноутбук недавно. Такой бюджетный, что даже апгрейд не предусмотрен.
И по ощущениям это совсем другие гигабайты
Когда возникает необходимость в swap-файле? Самый частый ответ — «когда не хватает памяти». И, естественно, это ответ неправильный почти полностью. Правильный ответ — необходимость в использовании swap-файла возникает тогда, когда система не может удержать в памяти необходимый кэш и грязные страницы.
Это прекрасно, когда объем оперативной памяти достаточно велик, чтобы вместить и весь необходимый кэш, и данные. Но если у вас бюджетная система с 8 … 16ГБ оперативной памяти
Взаимоисключающие параграфы? «Памяти хватает, система не бюджетная (32Г думаю достаточно для аргумента), зачем мне своп, если я точно знаю, что если система дошла то того, что полезла в своп, то проще нажать Reset, т.к. фризы будут такие, что даже открыть терминал по хоткею и кильнуть вредный процесс может стать невыполнимой задачей.»
«когда не хватает памяти». И, естественно, это ответ неправильный почти полностью.
В каком месте он тут неправильный? Если:
Это прекрасно, когда объем оперативной памяти достаточно велик, чтобы вместить и весь необходимый кэш, и данные.
И вообще, даже если поверить на слово, что именно swap файл вот так прямо нужен. Давайте может я тогда:
- Создам tmpfs на несколько гигибайт
- Смонтирую в
/tmplol sudo dd if=/dev/zero of=/tmplol/swaplol bs=1M count=4096sudo mkswap /tmplol/swaplolsudo chmod 600 /tmplol/swaplolsudo swapon /tmplol/swaplol
ОС будет мне благодарна? Ведь оперативной памяти у меня, ух, аж на 3 Electron-приложения хватит, положу swapfile прямо туда, в оперативную память. Зачем мне дёргать лишний раз не вечный и медленный диск?
Собственно, для этого используют zram или, если нужна только редукция I/O, zswap.
Спасибо за наводку. Около месяца аптайма компьютера и браузера под кеш нарезервировалось почти все 32ГБ. После большого перерыва стал пересобирать систему, обновление большое, понадобилось оперативной памяти прилично. И вместо того, чтобы откусить от того, что нарезервировалось, система полезла в своп на диск, на 3,5ГиБ примерно. Разумеется всё начало адово фризиться (впрочем не так долго, т.к. SSD, но тем не менее). Отключил к чертям своп на диске и подключил ZRAM swap, чтобы такого больше не повторялось.
Разумеется всё начало адово фризиться (впрочем не так долго, т.к. SSD, но тем не менее)
но как у вас это получается? у меня фризы бывают только когда 32ГБ свопа кончаются (с тех пор, как расширил до 64ГБ пока ни разу не видел, но и времени прошло всего несколько недель).
сейчас вот запустил виртуалку с десятой виндой (8 гигов) и idea (ещё более гигайта резидентно). ff, chromium и несколько мелких виртуалок с линухом были запущены и так.
попереключался туда-сюда, никаких «жёстких фризов» не наблюдал (хотя показалось в момент загрузки винды, что закладки в браузере задумчиво переключались)
по iostat в пике увидел несколько тысяч iops на раздел со свопом с задержкой чтения 0.1 мс и задержкой записи меньше 1 мс (был единичный всплеск в 3 мс).
насколько я понимаю, на отзывчивость системы во время активного свопа влияет именно задержка чтения.
фризы будут такие, что даже открыть терминал по хоткею и кильнуть вредный процесс может стать невыполнимой задачей.
На большинстве систем, с которыми регулярно работаю, свап есть, но фризов не вызывает — что-то в своп один раз вылилось и лежит там спокойно, занимая процентов 10 от памяти, в том числе от 32 Гб на личном ноуте, неделями не перегружаемом.
Это у Вас молниеносно по памяти не текло. Если там чего-то недохватило, то в фризы могут быть и незначительными. А вот если у вас что-то пошло не так, и нечто начало аллоцировать как не в себя, да ещё параллельно в несколько потоков/процессов (ну вот сидели Вы, погромировали, экспериментировали, допустили страшное недоразумение в творческом потоке), а Вы и не заметили сначала, то если есть своп, пиши «пропало», потому что как оно доест до свопа, всё повиснет, и проще ресетнуть компьютер, чем ждать пока оно мееееееедленно доест своп (а диск медленный) и встретит свою OOM-смерть. А вот если свопа нет совсем, то OOM такой франкенштайн встретит гораздо быстрее.
Если подобное и происходит, то хорошо если раз в год...
Если свопа нет, то просто вкладки крашатся иногда. Благо в 202х под каждую отдельный процесс хромиума (ну или у кого там какой). Убить и восстановить брацзер при этом занимает единицы секунд.
Это что, вредительство?! Чья глупость — моя, как чайника, или направительное понимание сути?!
Для таких как я, есть много «полезной» информации в инете, и, конечно, о существовании официальных мануалов я вообще хоть и слышал, но не видел, и еще в минус незнание английского.
Примеры с просторов:
«Раздел подкачки «swap» (своп) мы создавать не будем, так как в Ubuntu, начиная с версии 17.04, вместо раздела подкачки используется файл подкачки (как в Windows). По умолчанию его размер составляет 5% от свободного места на диске, но не более 2 гигабайт. После установки размер файла подкачки в любое время можно будет изменить.»
Это отсюда: info-comp.ru/drugieopersistemi/579-create-disk-partitions-in-ubuntu.html
Теперь с сайта help.ubuntu.ru/manual/%D1%80%D0%B0%D0%B7%D0%BC%D0%B5%D1%82%D0%BA%D0%B0_%D0%B4%D0%B8%D1%81%D0%BA%D0%B0 — для меня этот сайт и есть «мануал»!
«Обычно размер свопа выбирается равным объёму оперативной памяти или чуть больше, поскольку swap используется для сохранения состояния компьютера (то есть содержимого оперативной памяти) при использовании спящего режима (он же hibernate).
В принципе, если у вас много оперативной памяти и вам не нужно использовать спящий режим, вы можете отказаться от использования свопа, однако я настоятельно рекомендую не жалеть лишнего гигабайта-двух на вашем винчестере и создать своп раздел. Правда увлекаться тоже не стоит, выделять под своп слишком много места абсолютно бесполезно.»
Почему линукс использует swap-файл