Comments 19
Просто взяли два предобученных энкодера, да и все.
Все верно. Действительно, «да и все». В этом и есть движение от few-shot к zero-shot learning. Параметры модели не изменяются. Мы лишь получаем векторы для классификационной головы, используя текстовый энкодер. Этот процесс OpenAI и называет zero-shot learning.
Добрый день,
и у них(на сайте CLIP) в примере и у вас, есть model.context_length и она равна 77. Что это за цифра (символы? слова? лексемы?), можно ли её изменить?
и у них(на сайте CLIP) в примере и у вас, есть model.context_length и она равна 77. Что это за цифра (символы? слова? лексемы?), можно ли её изменить?
Добрый вечер!
Context length: 77 — максимальная длина предложения (например для описания класса), которую может принимать Text Transformer гибридной сети CLIP.
Первый и последний токены в предложении заняты под
Остается 75 токенов на описание предложения. Что для большинства задач будет достаточно, учитывая то, что CLIP не всемогущая модель.
Длина массива из токенов зависит, конечно, как и от частотности (популярности) используемых в тексовом описании слов, так и от размера словаря токенизатора.
Рассмотрим пример
Изображение:

Описание на английском:
После токенизации, превращается в массив длиной 77. Размер словаря токенизатора Vocab size: 49408. Токены
Описание в виде индекса словаря token — embedding:
Даже семь токенов остались неиспользованными.
Context length: 77 — максимальная длина предложения (например для описания класса), которую может принимать Text Transformer гибридной сети CLIP.
Первый и последний токены в предложении заняты под
SOS and EOS (represent the start and end of a sequence):sot_token = tokenizer.encoder['<|startoftext|>']
eot_token = tokenizer.encoder['<|endoftext|>']Остается 75 токенов на описание предложения. Что для большинства задач будет достаточно, учитывая то, что CLIP не всемогущая модель.
Длина массива из токенов зависит, конечно, как и от частотности (популярности) используемых в тексовом описании слов, так и от размера словаря токенизатора.
Рассмотрим пример
Изображение:
Описание на английском:
The focal point of the scene is the Tree Man, whose cavernous torso is supported by what could be contorted arms or rotting tree trunks. His head supports a disk populated by demons and victims parading around a huge set of bagpipes — often used as a dual sexual symbol reminiscent of human scrotum and penis.После токенизации, превращается в массив длиной 77. Размер словаря токенизатора Vocab size: 49408. Токены
SOS = 49406, EOS = 49407, PAD = 0 . Остальные токены представляют слова.Описание в виде индекса словаря token — embedding:
[49406, 518, 30934, 2301, 539, 518, 3562, 533, 518, 2677,
786, 267, 6933, 772, 2214, 879, 937, 706, 533, 8038,
638, 768, 1510, 655, 616, 937, 775, 5706, 541, 532,
1188, 2677, 38531, 269, 787, 1375, 8336, 320, 17970, 38420,
638, 18388, 537, 7131, 699, 15000, 1630, 320, 2699, 1167,
539, 3408, 16991, 2005, 4864, 2026, 601, 320, 5347, 6749,
13085, 41704, 539, 2751, 30768, 8843, 537, 1501, 533, 49407,
0, 0, 0, 0, 0, 0, 0]Даже семь токенов остались неиспользованными.
Спасибо за разъяснение!
собственно, я и собирался подставлять туда большие тексты
в общем я не уверен что это здравая идея, но после токенизации, я отсортировал токены по количеству вхождений, уникализировал, и передал дальше топ-75 штук
собственно, я и собирался подставлять туда большие тексты
в общем я не уверен что это здравая идея, но после токенизации, я отсортировал токены по количеству вхождений, уникализировал, и передал дальше топ-75 штук
после токенизации, я отсортировал токены по количеству вхождений, уникализировал, и передал дальше топ-75 штук
Не уверен, что это хорошая идея. Так как Text Transformer принимает токены именно как последовательность.
Спасибо за разъяснения!
Скажите, а почему, если мало категорий, результат стремится к 100%?
Вот например картинка:

Если поставить одну категорию: «Orange boy is riding a blue horse»
то результат — 100%
Если добавит больше — качество не сильно улучшается
Скажите, а почему, если мало категорий, результат стремится к 100%?
Вот например картинка:
Если поставить одну категорию: «Orange boy is riding a blue horse»
то результат — 100%
Если добавит больше — качество не сильно улучшается
text = clip.tokenize(["Orange boy is riding a blue horse and talking to a squirrel",
"President of the Moon has banned meat from restaurant menu",
"Seahorses don't like when racoons are eating schnitzel on bone",
"A cowboy is passing through prairie",
"An abstract picture with something big"]).to(device)0.03%
41.52%
17.35%
37.31%
3.80%Огромное спасибо за разбор с примерами!
У меня появились вопросы, ответы на которые нигде не могу найти:
— почему модели скормили только по одной картинки из категории, а, например, не по 3 или 5?
— как изменится точность классификации, если число предварительно скормленных картинок увеличить? (и если улучшится, то как это сделать в этом модели)
— на сколько ожидаемо модель будет классифицировать картинки, объекты на которой никогда не встречались в изначальном датасете самой модели, например, классификация портретов людей?
У меня появились вопросы, ответы на которые нигде не могу найти:
— почему модели скормили только по одной картинки из категории, а, например, не по 3 или 5?
— как изменится точность классификации, если число предварительно скормленных картинок увеличить? (и если улучшится, то как это сделать в этом модели)
— на сколько ожидаемо модель будет классифицировать картинки, объекты на которой никогда не встречались в изначальном датасете самой модели, например, классификация портретов людей?
Добрый день! Спасибо за интересе к теме.
Попробую ответить на все Ваши вопросы.
— Мы не кормим ни одного изображения и не дообучаем на них. Сosine similarity мы считаем только для визуализации.
— Это очень хороший вопрос. Как я писал выше мы не обучаем классификатор ни на одном изображении. Это обучение без обучения (zero-shot learning), но мы можем использовать и few-shot learning.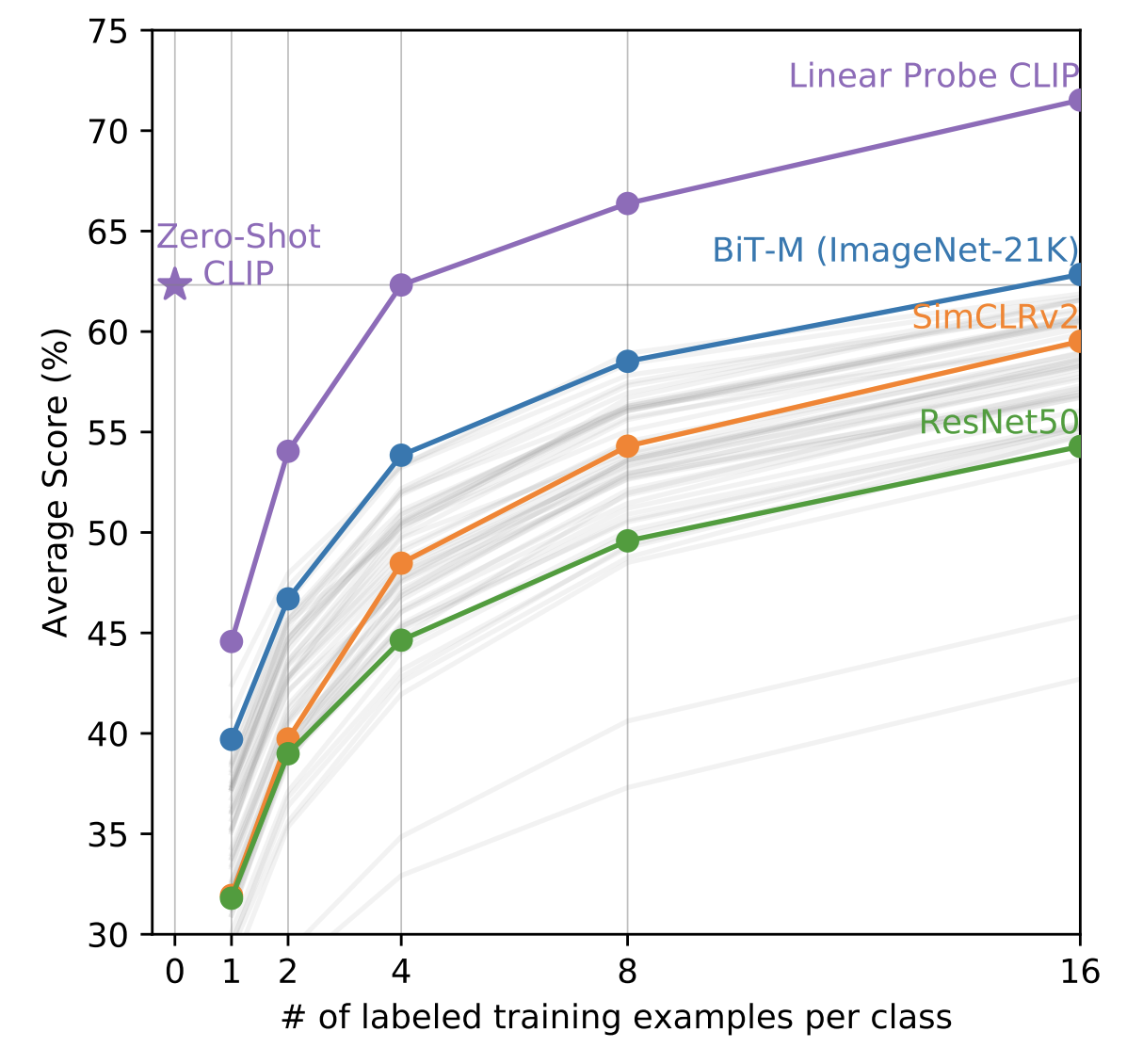 CLIP в режиме few-shot linear probes будет лучше обучения без обучения, если для каждого класса у нас будет хоть по 8-16 изображений.
CLIP в режиме few-shot linear probes будет лучше обучения без обучения, если для каждого класса у нас будет хоть по 8-16 изображений.
— Все зависит от того, как описать изображения на естественном языке. Если достаточно полно по признакам, то есть все шансы, что будет работать хорошо.
Попробую ответить на все Ваши вопросы.
— Почему модели скормили только по одной картинки из категории, а, например, не по 3 или 5?
— Мы не кормим ни одного изображения и не дообучаем на них. Сosine similarity мы считаем только для визуализации.
Давайте скормим модели 10 изображений по одному примеру на класс и их текстовые описания. А потом построим матрицу косинусных расстояний между векторами изображений и векторами текстов (cosine similarity в общем пространстве визуальных и текстовых репрезентаций).
Как мы видим, по матрице cosine similarity, максимальная схожесть векторных репрезентаций изображений и текстовых описаний находится на главной диагонали. Из этого мы можем сделать вывод, что CLIP подходит под нашу задачу.
— Как изменится точность классификации, если число предварительно скормленных картинок увеличить? (и если улучшится, то как это сделать в этом модели)
— Это очень хороший вопрос. Как я писал выше мы не обучаем классификатор ни на одном изображении. Это обучение без обучения (zero-shot learning), но мы можем использовать и few-shot learning.
CLIP в режиме few-shot linear probes будет лучше обучения без обучения, если для каждого класса у нас будет хоть по 8-16 изображений.— На сколько ожидаемо модель будет классифицировать картинки, объекты на которой никогда не встречались в изначальном датасете самой модели, например, классификация портретов людей?
— Все зависит от того, как описать изображения на естественном языке. Если достаточно полно по признакам, то есть все шансы, что будет работать хорошо.
Воспроизвел ваш код, спасибо огромное. Есть ощущение, что скорее работает, чем нет на похожих фотографиях про одно событие.

Две разные темы:

Две разные темы:
Классификатор животных из мультфильмов
А если это мультфильм про инопланетных животных — т.е. это как бы животное, но не похоже ни на одно земное?)))
На самом деле очень хороший вопрос. А давайте попробуем!
Очевидно, что модель не будет понимать имена вещей и животных, которых никогда не было в датасете.

А вот если описать, например: «Большое инопланетное животное, похожее на тигра и крысу с двумя хвостами».
Я постараюсь набрать примеров и посмотреть, как CLIP справится с задачей.
Если же

«Инопланетное животное, похожее параллелепипед с ножками»
Очевидно, что модель не будет понимать имена вещей и животных, которых никогда не было в датасете.
А вот если описать, например: «Большое инопланетное животное, похожее на тигра и крысу с двумя хвостами».
Я постараюсь набрать примеров и посмотреть, как CLIP справится с задачей.
Если же
животное, но не похоже ни на одно земное, то мы все равно можем описать его словами. Например:
«Инопланетное животное, похожее параллелепипед с ножками»
Михаил, шикарный туториал!
Очень круто, практически «на пальцах» объясняете механику работы сетки. Можете в паре предложений рассказать про ew-shot learning? Какую именно часть сетки дообучают? Может даже есть инфа по времени обучения на тех же 16 примерах для 10 классов?
Очень круто, практически «на пальцах» объясняете механику работы сетки. Можете в паре предложений рассказать про ew-shot learning? Какую именно часть сетки дообучают? Может даже есть инфа по времени обучения на тех же 16 примерах для 10 классов?
как это все работает на большом количестве классов (>1000) ?
*текстовое описание картинок для 1000 классов, очевидно, трудоемко. можно, конечно, использовать мультимодальные LLM для описания картинок, чтобы упростить себе работу. но они выдают иногда описание > 77 токенов или очень схожее. речь идет о предметах, допустим, на полке в магазине. текстовое описание получается очень похожим, а на 1000 классах так вообще, все в одно большое пятно сливается.
Sign up to leave a comment.
Собираем нейросети. Классификатор животных из мультфильмов. Без данных и за 5 минут. CLIP: Обучение без Обучения + код