Даже в век цифровых технологий мы пока не можем обходиться без бумажных документов. Но содержание бумажного документа всё равно должно переместиться в информационную систему. И хорошо бы этот процесс миграции данных с бумаги в цифру сделать максимально быстрым. В связке компьютер-человек самое медленное звено, конечно, человек. Поэтому хорошо бы человека из этого процесса по максимуму исключить, сделать процесс «бесчеловечным».
Для этого мы разработали облачный сервис распознавания документов с использованием нейросетей и машинного обучения. Какие алгоритмы мы использовали, как учили наши нейросети, как распознавали мятые документы, почему отвергли архитектуру U-Net и использовали сети контекстной агрегации – под хабракатом.

Основная задача сервиса – упростить ввод самых распространенных в бизнесе документов (счета-фактуры, товарные накладные, акты и т.п). При этом мы хотели сделать сервис «всеядным» – чтобы он мог обрабатывать документы, сфотографированные на телефон, оцифрованные поточным сканером, загруженные в цифровом формате (Word, Excel, PDF, OpenDocument, …). Вся обработка должна происходить полностью автоматически, без участия человека, и качество распознавания должно являться примерно одинаковым.
Сервис работает по принципам HTTP API, на вход получает картинку, на выход выдает JSON с извлеченной из картинки документа структурированной информацией.
Как работает сервис – живой пример. Пользователь перетащил несколько файлов из проводника; качество исходного материала не самое хорошее, документ мятый, присутствуют посторонние загрязнения, вторая страница сфотографирована с большими перспективными искажениями. Примерно через минуту после отправки документов в сервис документ будет обработан и распознан, и оператор сможет посмотреть – что, собственно, распозналось.
Мы видим, что сервис склеил две страницы документа; мы видели, что вторая страница документа была сфотографирована не вполне удачно, но сервис с этим справился – «выпрямил» страницу так, чтобы она была перпендикулярна объективу. При этом, когда оператор выбирает те или иные поля на форме – подсвечивается соответствующая область на отсканированном документе, из которой была извлечена информация.
В чем сложность задачи?
В чём же, собственно сложности построения такого сервиса? Почему бы не взять типовые документы, нарисовать, из каких областей извлекать данные для распознавания и тем самым решить задачу?

Как показала практика, разработка такого сервиса требует очень большой гибкости, которую может обеспечить только применение методов машинного обучения.
Во-первых, это вариативность (мягко говоря) даже в стандартных документах, вот некоторые примеры одного и того же документа (акт о выполненных работах):

С точки зрения пользователя это один и тот же документ, но при этом видно, что общего у этих документов довольно мало – абсолютно разная разметка страниц, разное расположение блоков данных, разный вид таблиц. Тем не менее всё это – один и тот же документ, акт о выполненных работах, и все эти документы должны быть распознаны и разобраны одинаковым образом и распознанные данные помещены в JSON единого формата.
Следующая интересная задача – это разбор многостраничных документов.

Тут, кроме вариативности форм, добавляется ещё и вариативность со стороны пользователя; пользователь может случайно перепутать страницы местами, или отсканировать их в обратном порядке, или поместить несколько листов на одной фотографии.
Особый интерес представляют дефекты печати:

По каким-то причинам картриджи после очередной заправки склонны к двум крайностям – либо оставляют непропечатанные полосы, либо оставляют на бумаге слишком много тонера, рассыпанного неравномерно по всей поверхности листа.
А иногда документы бывают мятыми:

Ещё бывают форсмажорные обстоятельства – документ уронили в лужу, на документ пролили кофе и т.п. Документ могли сфотографировать дрожащей рукой, под странным ракурсом:

Рассмотрим ключевые механизмы сервиса.
Во-первых, мы разработали специальный цикл предобработки входных данных, который включает в себя исправление проблем фотографии, устранение проблем перспективы, освещенности, дефектов печати, перекосов, поворотов, заломов от скрепок, выхода части документа из зоны сканирования, а также проблемы перевода цифровых форматов (Word, Exсel и т.п.) в единый формат изображения. В конце цикла мы получаем документ в виде картинки единого формата вне зависимости от того, в каком формате пришли входные данные.
Сервисная модель работы позволяет привлекать большие вычислительные мощности, использовать вычисления на GPU (это позволяет использовать сложные алгоритмы для повышения качества распознавания).
Шаги улучшения исходного изображения:
Выравнивание изображения в пространстве.
Повышение резкости изображения.
Сегментирование документа (определение, где на документе расположен текст, где – линии и таблицы, где – печати и другие элементы документа).
Следующая задача – понять, что на изображении, самостоятельный документ или часть многостраничного документа.
Финальная часть – собрав все страницы документа, определив тип, можно начать собирать структурированную информацию, извлекать текстовую часть, формировать таблицу и извлекать из неё текст и числа.
Выравнивание документа в пространстве:

Самый простой способ повернуть документ в пространстве – это найти его границы, построить по ним четырехугольник, и найти аффинное преобразование, которое приведет его в прямоугольник.
Однако не всё так просто. Бывает, что фотографии не содержат границ документа:
Также бывают сканы, у которых всё в порядке с перспективой (лист плоско лежит на стекле сканера), но они бывают повернуты в плоскости, и их нужно выровнять. Для этого разработан отдельный механизм поворота, который ориентируется на содержимое документа (а не на его границы) и ищет преобразование, которое сделает большинство линий в документе параллельными оси X или оси Y.
После выравнивания документа необходимо найти на нём различные структурные элементы – текст, линии, подписи, печати и другие структурные единицы. Многие из этих подзадач решаются методами классического компьютерного зрения. Но такие решения получаются как правило громоздкими и очень сложными в сопровождении, т.к. они накапливают со временем огромное количество веток для решения проблем специфичных случаев (например, пунктирные линии вместо обычных, размашистая подпись через всю таблицу, скрепка степлера в углу, высыпающийся на страницу тонер и т.д.). Обработка таких случаев ведёт к большому количеству if-ов в алгоритме, эти if-ы начинают конфликтовать друг с другом, и поддержка алгоритма становится практически невозможной.
По этой причине мы решили разработать систему сегментации документов на основе ансамбля свёрточных нейронных сетей.

Одна из наиболее интересных нейронных сетей, разработанных нами – это детектор линий, текстовых строк и параграфов. Задачей этой сети является не только поиск линий, напечатанных на бумаге, но и дорисовка линий в случае дефектов печати. Так, на приведенном ниже изображении слева – оригинальный документ с не полностью пропечатанными линиями, справа – размеченный нейронной сетью документ. Горизонтальные линии на выходном документе размечены синим цветом, вертикальные – красным.

Как мы видим, сеть успешно нашла все не полностью пропечатанные линии и восстановила их.
На первой итерации этой задачи была обучена классическая для задач сегментации архитектура U-Net.

В целом она довольно неплохо сегментировала изображения, но обладала рядом недостатков, затрудняющих её использование для решения нашей задачи. Во-первых, это очень высокая вычислительная сложность сети, особенно при условии, что задача требует сохранения мелких деталей, что приводит к необходимости работать с полноразмерным изображением (а это долго и требует больших вычислительных ресурсов). Во-вторых, это сверхчувствительность сети к масштабу; проблема в том, что бывают документы, на которых высота буквы составляет 30, 40, иногда – 50 пикселей, а бывают документы, на которых высота строк в таблицах всего 20-30 пикселей, т.е. масштаб элементов картинок очень сильно варьируется от одного изображения к другому. В-третьих, выход сети получился достаточно «шумным» - с большим количеством высокочастотного шума, что требовало достаточно сложной фильтрации в постобработке.
В результате большого количества экспериментов мы пришли к архитектуре сети с мультиразмерным входом. Исходное изображение масштабируется к трем размерам (оригинальный размер, 75% от оригинала и 50% от оригинала) и подается в трех масштабах на независимые свёрточные нейронные сети, которые извлекают из изображений пространственные признаки (некоторое внутреннее представление сети, поверх которых уже агрегируется выход с понятным для человека результатом). После этого извлеченные признаки приводятся к одному масштабу и уже все вместе поступают в следующую сеть, которая формирует финальный отклик сети.

Таким образом, получается двухступенчатая архитектура; три ветви первой ступени (обработка изображения в трех разных масштабах) работают параллельно, извлекают признаки каждая своего размера и потом объединяют результаты в итоговой сети.
Первая ступень
Подробнее рассмотрим пример для одного из размеров. Мы пришли к архитектуре, идейно похожей на сети контекстной агрегации (Context Aggregation Network); кратко идея таких сетей заключается в том, что используется большая последовательность свёрток с увеличивающимся коэффициентом разреженности. В таких сетях каскад разреженных свёрток служит инструментом увеличения области видимости сети (receptive field), тем самым позволяя не использовать пулинги; пулинги достаточно сильно снижают способность сети высокоточно сегментировать мелкие детали изображения.

На архитектурном уровне для всех масштабов была построена примерно одинаковая архитектура; различия заключались лишь в количестве каналов во внутренних слоях, и количестве таких слоев.
Для каждого размера (1, ¾, ½) входа была подобрана своя схема с разным количеством шагов свертки и количеством промежуточных каналов, так, чтобы суммарная область видимости сети (reception field) и количество потребляемой памяти было примерно равным для всех трёх веток. Таким образом, сеть с большим входом (большим исходным изображением) содержит меньше каналов на внутренних слоях, а сеть для самого маленького размера изображения содержит и больше слоев, и больше каналов в каждом из слоев.
Вторая ступень
Таким образом, мы получаем из экстрактора первой ступени три независимых набора признаков, которые поступают на вход второй ступени сети. Все признаки приводятся к единому размеру (каналы из ветки с большой размерностью сжимаются до средних, каналы из ветки с малой – наоборот, увеличиваются тоже до размеров средней ветки), и весь этот набор объединяется в единый массив каналов. Поверх объединенных слоев применяются несколько слоев сверток для получения итогового выхода сети. Это, по сути, компактный блок конволюций, который сжимает многоканальное пространство полученных признаков до нужного размера выхода; один канал – на текст, один – на параграф, один – на вертикальные линии, один – на горизонтальные и т.д.

Блок Blender представляет собой слои, масштабирующие все извлечённые пространственные признаки к одному размеру, конкатенирующего слоя и блока из нескольких свёрточных слоёв для получения набора желаемых выходных каналов – с линиями, текстовыми строками и параграфами.
Немного о нюансах обучения получившейся сети. Первая проблема, с которой мы столкнулись – это плохая сходимость сети и чувствительность к начальному распределению весов. Часто приходилось перезапускать обучение заново с новым набором весов, т.к. сеть не сходилась и не обучалась. Для решения этой проблемы мы стали поэтапно независимо учить каждую ветку для своего размера изображения. Т.е. при обучении мы заменили блок Blender на три слоя конволюции 3*3, и выход из слоя конволюций был таким же, какой требовался от всей сети. Далее мы обучили все три ветки (для разных масштабов изображения) независимо, каждую ветку со своим блоком конволюций. В такой конфигурации все ветки хорошо сходились, сеть легко обучалась.
После того, как были получены веса для всех трех сеток, мы смогли их зафиксировать и вернуть на место блок Blender и учить всю систему с заблокированными начальными тремя ветками (т.е. фактически обучать только Blender). После обучения Blender-а мы разблокировали веса всей конструкции и окончательно дообучили всю сеть целиком.
Этот приём позволил нам обучить сеть быстрее и качественнее. В результате нам удалось решить основные проблемы:
Исчезла сверчувствительность к масштабу.
Исчез мелкий шум на выходе.
Снизилась вычислительная сложность сети (количество нейронов в сети в 10 раз меньше, чем в UNET).
Примеры выходов сети:

Мы видим, что сеть хорошо сегментировала даже текст, напечатанный мелким шрифтом.
Пример работы той же сети для нахождения вертикальных и горизонтальных линий:

На основе выхода сети строится большое количество алгоритмов сегментации, нахождения интересующих нас данных, в том числе алгоритм построения и разбора таблиц. Ниже – пример выхода сети с линиями, из которых собрана табличная структура.

Следующая задача – это найти зоны таблицы и правильно собрать таблицу. Для решения этой задачи надо уметь классифицировать колонки, правильно находить подвал таблицы, уметь извлекать текст из ячеек и применять правила валидации на числовые ячейки.
Остановимся подробнее на задаче классификации колонок и разбора числовых ячеек. Казалось бы, задача довольно тривиальная – находим верхний ряд, распознаем в нем тексты – заголовки колонок, и сопоставили эти тексты с типовыми документами.
Для примера возьмем колонку «Сумма». На первый взгляд ничего сложного. Однако даже для такой простой колонки вариативность очень велика:
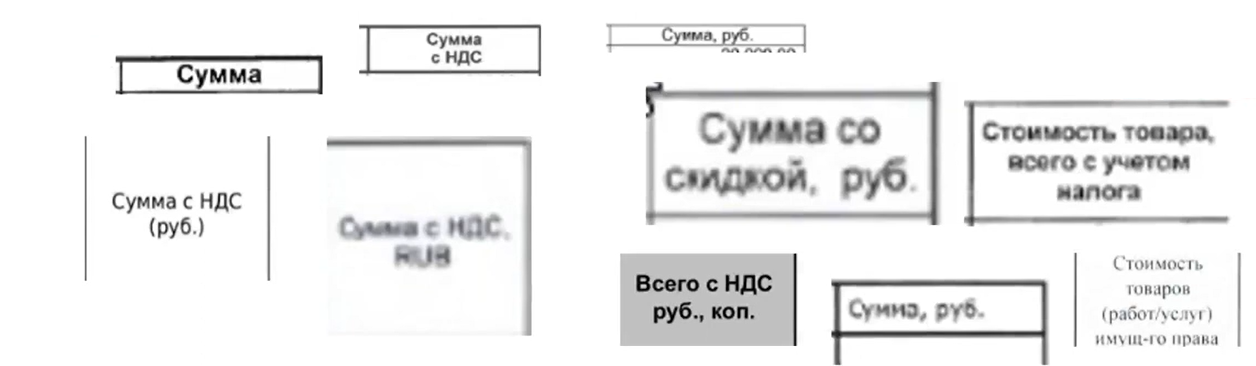
Для решения этой задачи мы использовали сочетание двух различных техник – машинное обучение и арифметика. Мы обучили текстовый классификатор и дополнительно задали систему правил валидации числовых колонок. Т.е. если классификатор предполагает, что эта колонка – сумма, то дополнительно проверяется, что колонка «Количество», умноженная на «Цену», в большинстве строк дает значение, написанное в колонке «Сумма».
В результате сборки таблицы получается JSON, в котором построчно записываются значения всех найденных ячеек с привязкой к известным классам колонок.

Отдельно расскажем про систему разбора числовых ячеек. Числа крайне важны в бухгалтерских документах и ошибки в них очень нежелательны. К сожалению, в ячейках таблиц помимо стандартных для распознавания проблем (размытость, маленькое разрешение, дефекты печати) накладывается ещё одна специфическая проблема. Часто в ячейках содержатся посторонние артефакты – галочки, крестики, другие пометки от руки, бывают подписи и печати поверх ячеек.

Для решения задачи точного разбора чисел была реализована и обучена двухуровневая нейронная сеть, специализирующаяся на разборе чисел. Первая ступень сети представляет собой блок сегментации, вторая – это блок сборки текстов.
Блок сегментации строит 14-канальное изображение, где все цифры и служебные знаки располагаются на своих каналах:
10 каналов цифр
Разделитель порядка
Пробел
Процент
Дефис
Далее это многоканальное изображение передается в рекуррентный блок, основанный на двунаправленной LSTM-сети, которая переводит сегментированное поканальное изображение в текст; каждая ступень при этом обучается независимо.
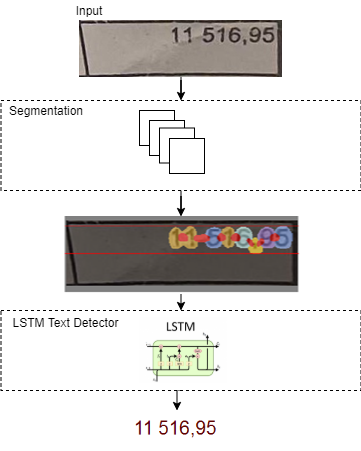
Для обучения сети мы разработали генератор синтетических данных, ниже – примеры его работы. Генератор эмулирует размытие изображения, дефекты печати и т.д.

По окончании обучения сети её точность на 20 000 картинок (вырезанных из реальных таблиц реальных документов) составила 99, 93%. Система успешно справляется даже со сложными случаями, когда у изображения плохая резкость, при наличии большого количества посторонних элементов (подписей, печатей и т. п.).

Отдельного рассказа заслуживает семантический анализ текстовых данных.
Для решения задач, связанных с анализом текстов, в рамках нашего сервиса разработан
механизм по семантическому разбору и поиску информации. На рисунке ниже –
пример разбора параграфа с полными реквизитами организации.
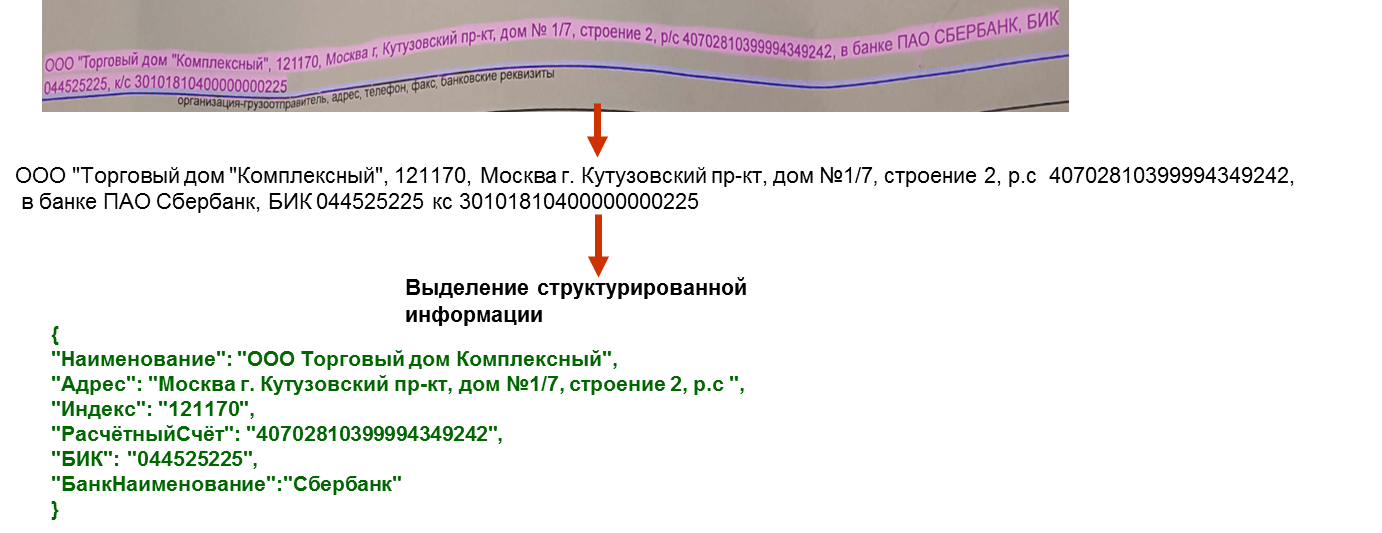
Эта задача особенно важна, т.к. при распознавании встречаются лишние знаки, пробелы в неожиданных местах, и решения, основанные на классических методах (например, на регулярных выражениях) становятся непригодными или слишком сложными и недостаточно гибкими.
Этот же механизм семантического анализа мы используем для слабоструктурированных
документов, в которых вся реквизитная информация просто «зашита» внутри текста.
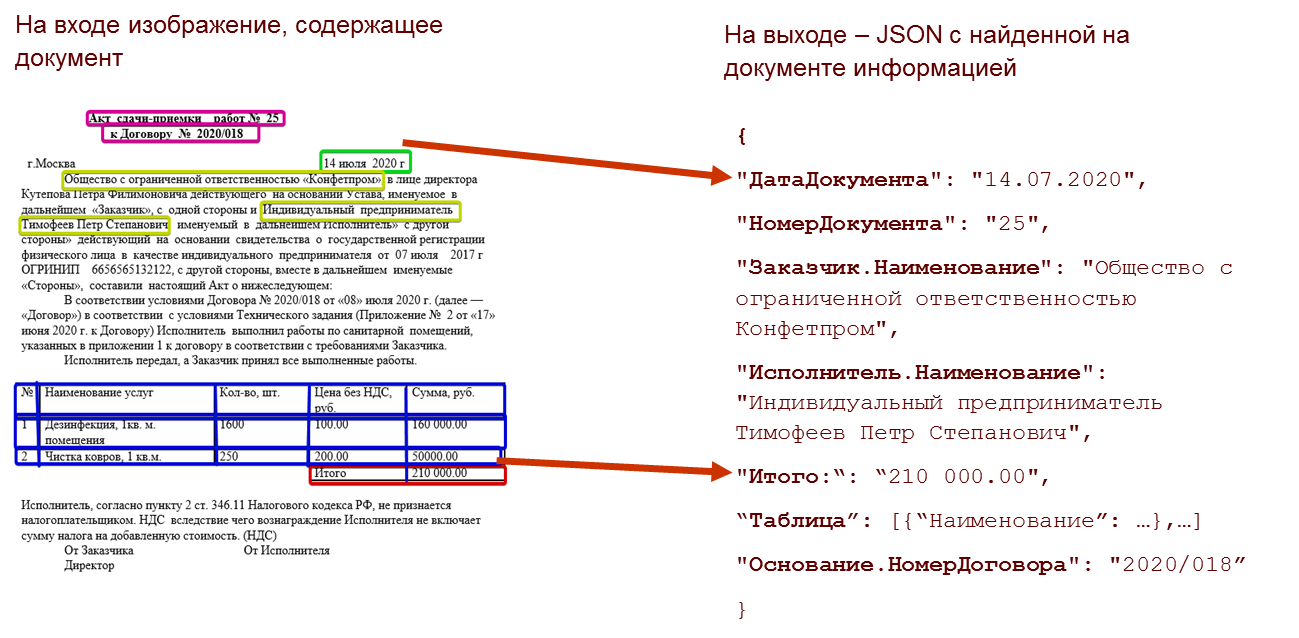
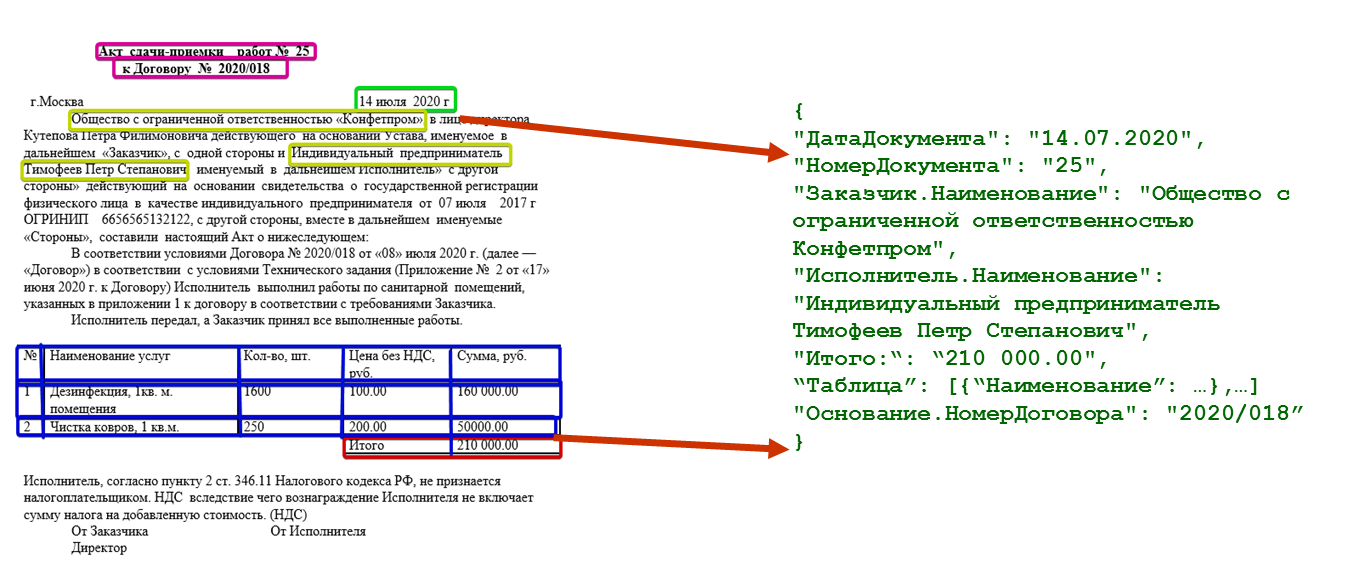
Ниже – пример извлечения такой информации из акта приемки-передачи; механизм
извлек из текста дату документа, номер документа, контрагентов, и собрал
таблицу.
Сервис распознавания документов запущен в коммерческую эксплуатацию с 1 января 2022 года.
