Математика заключает в себе не только истину, но и высочайшую красоту – красоту холодную и строгую, подобную красоте скульптуры.
Бертран Рассел
Кто интересуется темой рисующих нейросетей знают, что сейчас самый продвинутый и часто используемый интерфейс для Stable Diffusion (далее SD) это Automatic1111. Он позволяет использовать, вероятно, все существующие возможности SD на сегодня. Множество расширений, регулярные обновления и поддержка сообщества делают его мощным и удобным инструментом для генерации изображений. Но есть и альтернативные решения, одно из которых я сегодня рассмотрю.
Несмотря на то, что ComfyUI решает те же задачи, что и A1111, он обладает важными преимуществами и особенностями, которые делают его более гибким и универсальным (но в тоже время более сложным для освоения) инструментом, чем A1111.
Основной такой особенностью является нодовое (узловое) представление компонентов, с которыми работает SD:

У такого решения есть как минимум два преимущества:
позволяет создавать сложные, мульти итеративные конфигурации и даже автоматизации процесса создания изображений;
помогает лучше понять, что происходит “под капотом” SD и как следствие лучше управлять этими процессами, повышая предсказуемость результата и его условное качество.
В этой статье я расскажу как этим интерфейсом пользоваться, какие нам доступны ноды и что интересного можно сделать. Не буду рассказывать, как установить интерфейс – это несложно (в конце дам все нужные ссылки).
Начать стоит с этой маленькой и очевидной по функционалу панельки:
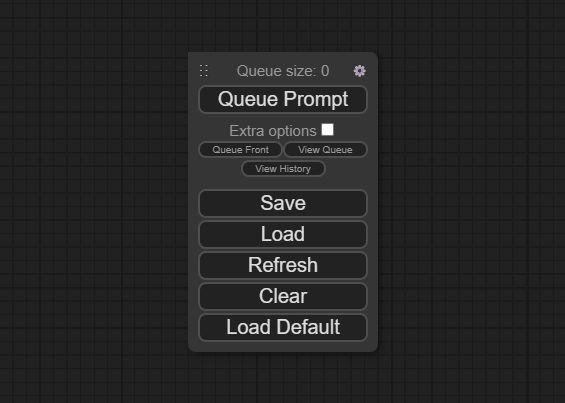
Помимо того что она запускает генерацию (queue prompt), в ней можно установить количество генераций подряд (extra options), посмотреть результаты предыдущих генераций (view history), а также загрузить пример простейшей схемы нод (load default), которые здесь называются “воркфлоу”. Рассмотрим эту схему:

Уже сейчас вы можете сгенерировать изображение, но при нажатии на queue prompt, скорее всего получите ошибку:
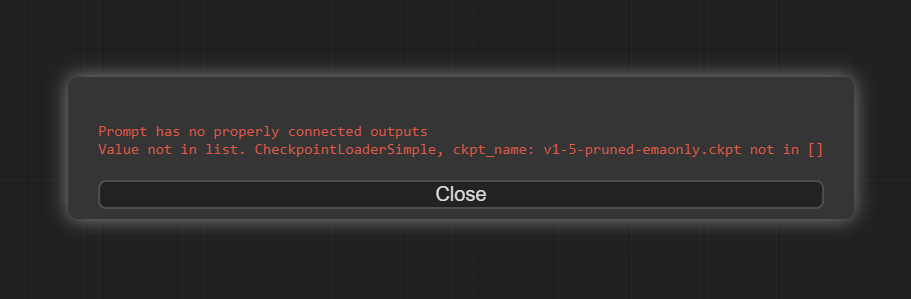
Это значит, что у вас нет модели, которая установлена в этом воркфлоу по умолчанию. Нам подойдет любая, например, стандартная 1.5. Модели складываются в папку: ComfyUI_windows_portable\ComfyUI\models\checkpoints
После этого у нас есть повод познакомиться с первой ключевой нодой:

Функционал у нее простой: она загружает модель, которую мы будем использовать. Про некоторые интересные модели я писал в одной из статей. У ноды есть одно поле, которое ссылается на модель, и три выхода.
Следующая важная нода:
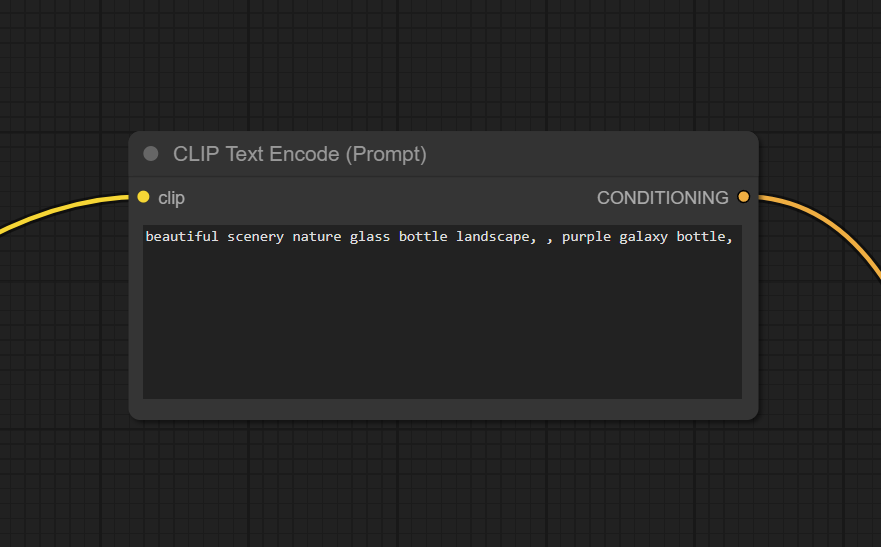
Это поле для ввода промпта. В любом воркфлоу используется минимум две таких ноды: одна для промпта, другая для негативного промпта. Кто генерит, уже знает, что “промптом” называется подсказка, по которой нейросеть будет генерировать изображение. Тут можно использовать похожий на A1111 синтаксис промптов (например (word:1.3)), для управления влиянием тех или иных слов, но работает он несколько иначе, поэтому будьте готовы столкнуться с некоторыми проблемами. Если вы про синтаксис ничего не знаете, просто пишите слова, и все будет работать. На вход обязательно нужно подать CLIP из предыдущей ноды, а выход пойдет в следующую:
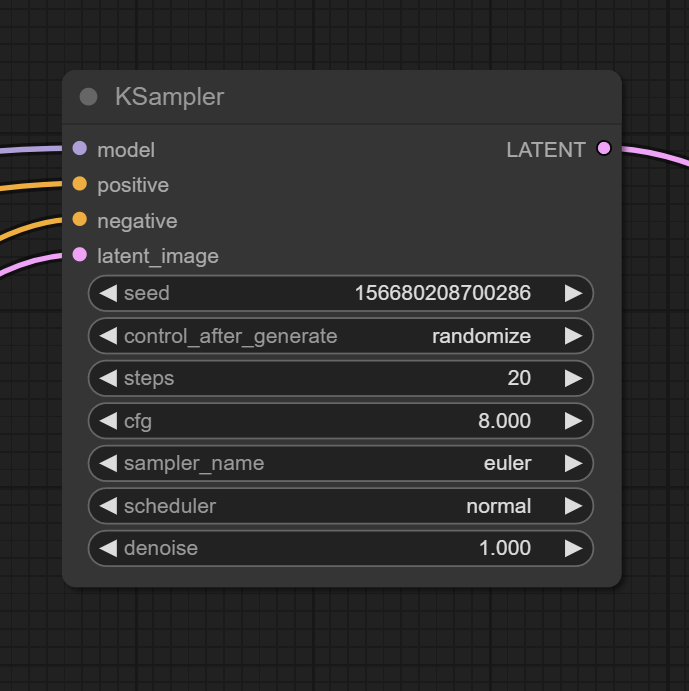
Это нода, в которой происходят все настройки генерации. Если вы пользовались А1111, то все параметры будут вам знакомы, и уже сейчас вы начинаете понимать, как все устроено. Если же с SD вы раньше не сталкивались, то оставьте все по умолчанию и поищите гайд по параметрам генерации, сейчас их очень много.
На вход мы подаем:
модель;
промпт;
негативный промпт;
изображение в латентном пространстве.
Для последнего нам понадобится следующая нода:
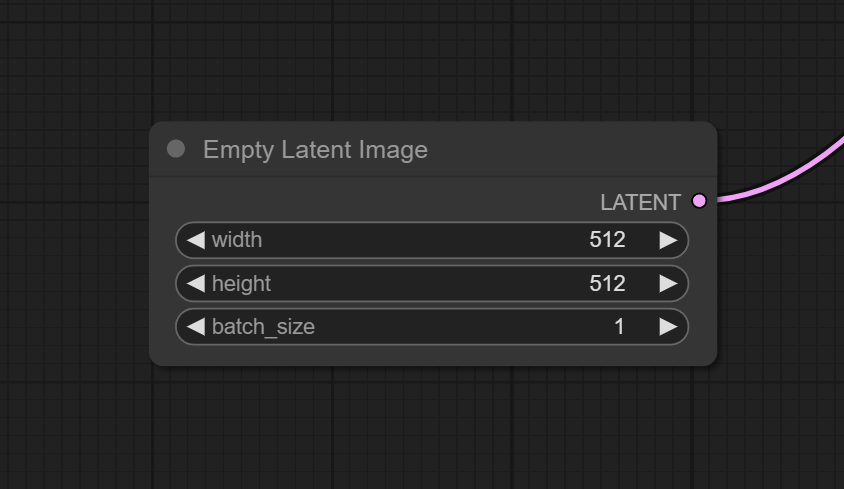
SD генерирует изображения в латентном пространстве и только потом преобразует их в пиксельное пространство. Это довольно важная концепция, понимание которой позволит строить собственные воркфлоу и гибко управлять выходящими изображениями. Данная нода создает “пустое” (буквально 0) изображение в латентном пространстве, указанного в полях размера. Поле batch size, позволяет за один проход генерировать сразу несколько изображений, но это потребует больше времени и памяти вашего GPU.
Возвращаемся к семплеру: получив все нужные входы, он создает наше изображение в латентном пространстве. Чтобы увидеть получившийся результат, нужно перевести его в пространство пикселей – декодировать. Для этого используются Variational Autoencoder (или коротко VAE) и нода:

В каждой модели содержится свой VAE, поэтому на вход надо подать VAE из модели. Но мы также можем загрузить отдельный (например популярный vae-ft-mse-840000-ema-pruned) с помощью ноды Load VAE.
Почти готово – после декодирования остается только визуализировать, получившееся изображение – используем последнюю ноду в этом воркфлоу:
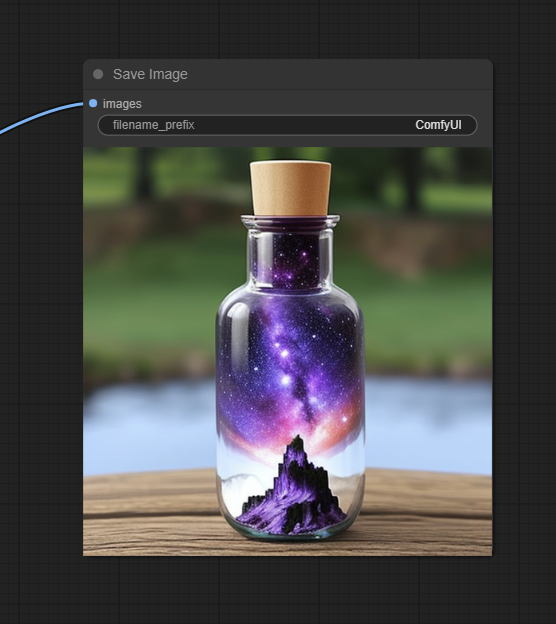
Она просто сохраняет изображение в папку ComfyUI_windows_portable\ComfyUI\output и показывает нам получившийся результат. Есть аналогичная нода, которая показывает результат, но не сохраняет его – Preview Image (зачем она нужна расскажу позже).
Итак, зная как работает наш дефолтный воркфлоу, мы можем начать экспериментировать и вносить изменения.
Разберемся как искать нужные ноды. Правый клик в пустом пространстве вызывает меню выбора нод.

Все ноды поделены по категориям – покажу их все и расскажу в общем о содержании и ключевых нодах.
Первая категория Sampling
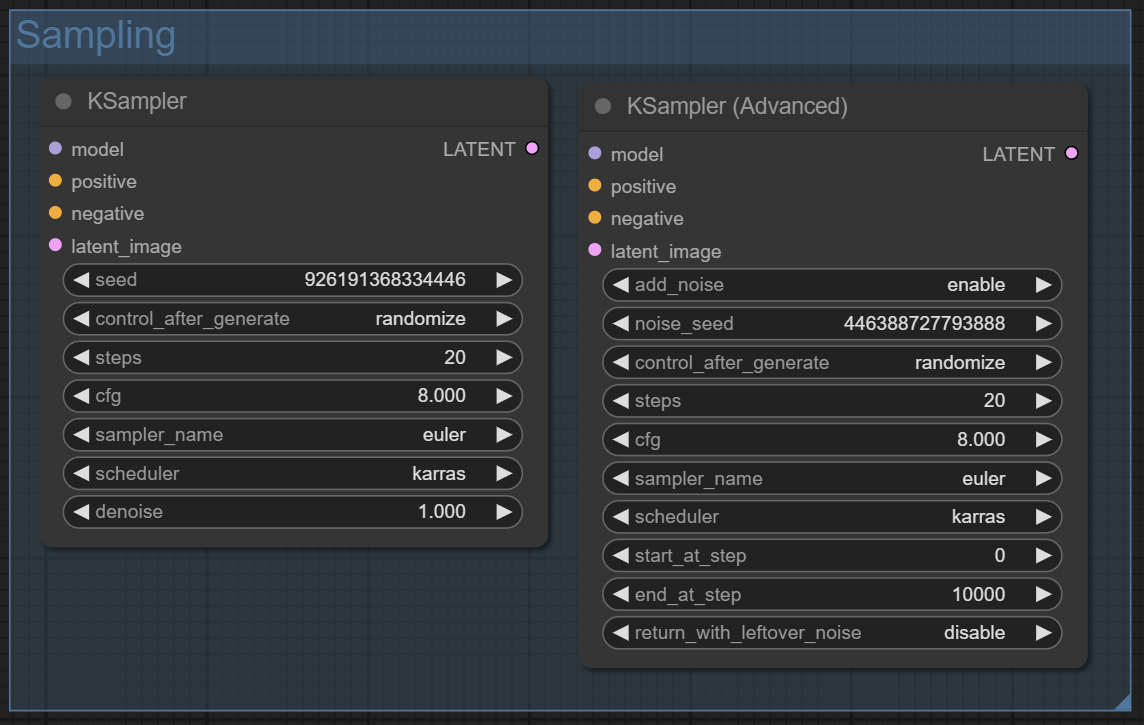
Категория, в которой хранятся самые главные генерирующие изображения ноды. Со стандартным семплером вы уже знакомы, продвинутый отличается главным образом тем, что может генерировать изображение не с первого шага.
Следующая категория Loaders
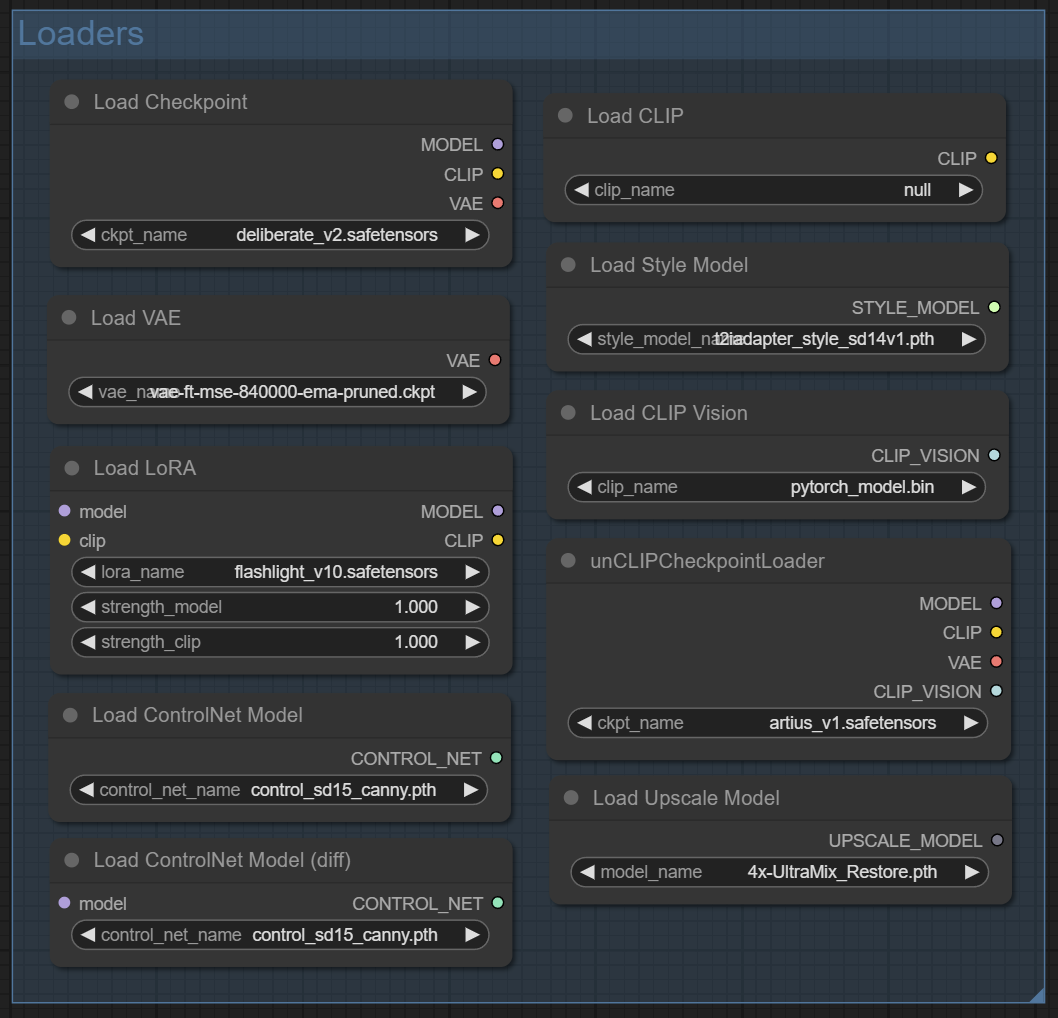
Ноды из этой категории загружают разные модели. Из регулярно используемого тут уже знакомый нам Load Checkpoint, а также ноды:
Load loRA – получить схожесть с конкретным персонажем, или объектом;
Load ControlNet Model – управлять позой;
Load Upscale Model – увеличить разрешение получившегося изображения.
С их функционалом вы знакомы, если пользовались А1111.
Следующая категория Conditioning
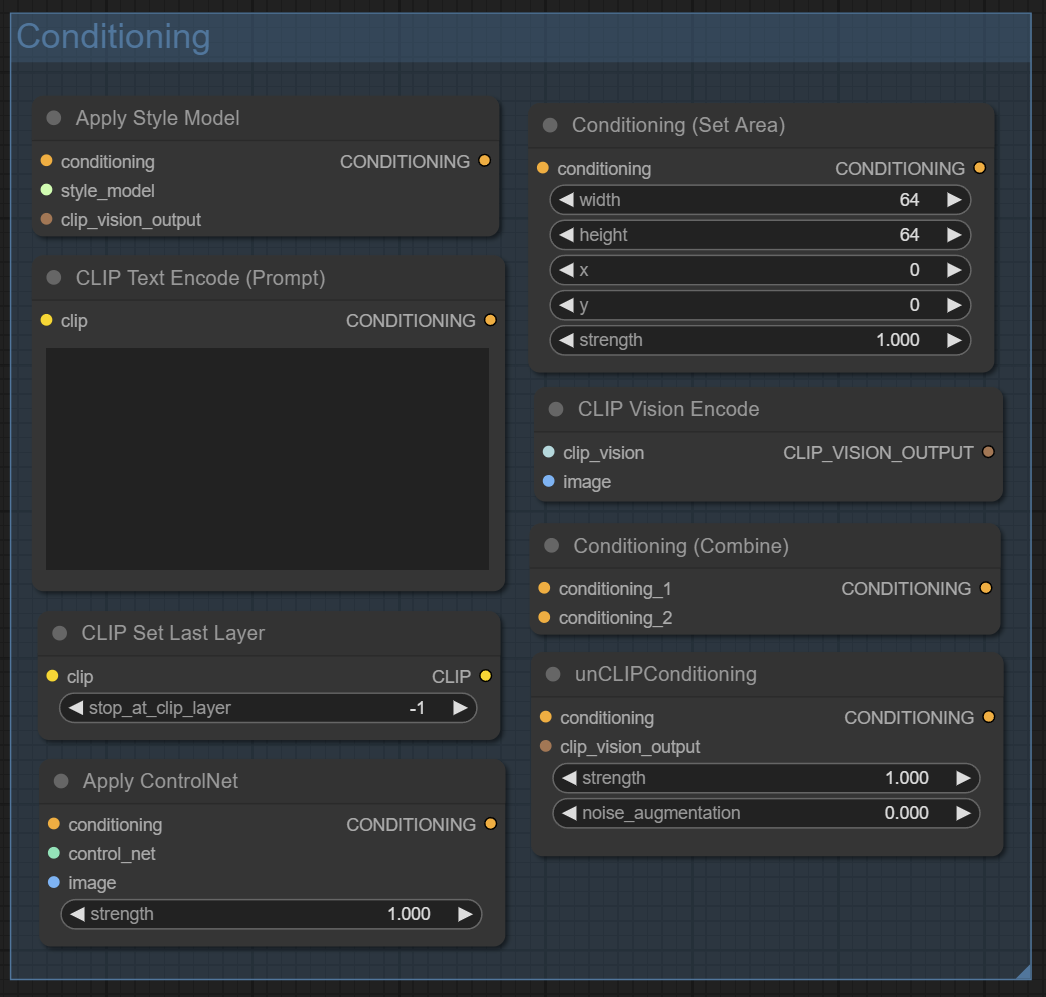
Это ноды, позволяющие взаимодействовать с промптами. Из интересного:
Apply Control Net – применить модель Control Net;
Conditioning (Combine) - смешать две ноды с промптом и использовать их усредненные значения;
Conditioning (Set Area) - задать область на изображении, к которой будет применяться промпт.
Категория Latent
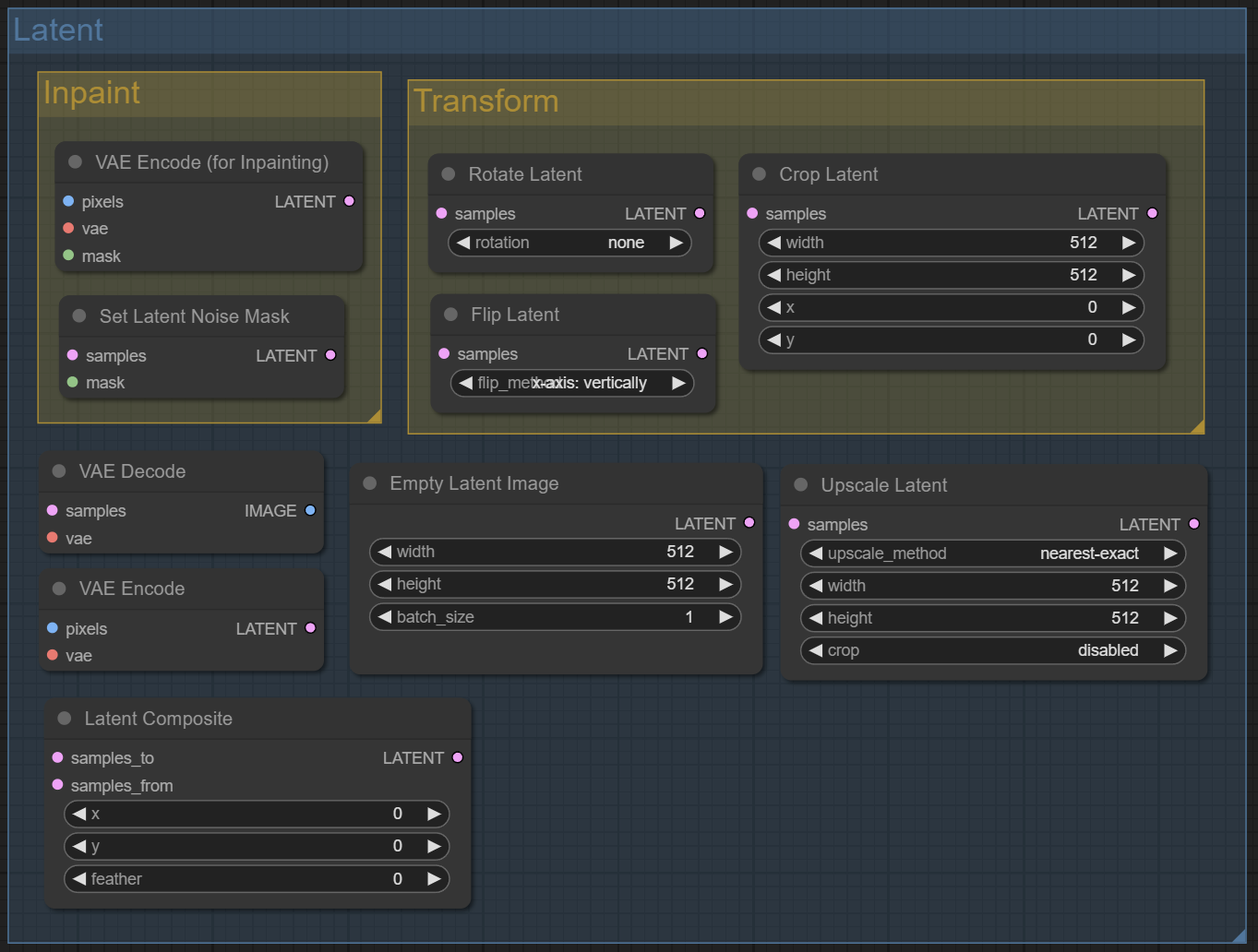
Тут размещены ноды, которыми можно влиять на изображения в латентном пространстве, а также декодировать их в пиксельное или наоборот из пиксельного в латентное. Из важного:
VAE Encode – перевести обычное изображение в латентное пространство;
Latent Composit – смешать два латентных изображений полученных из двух семплеров;
Upscale Latent – изменить размер изображения в латентном пространстве.
Категория Image
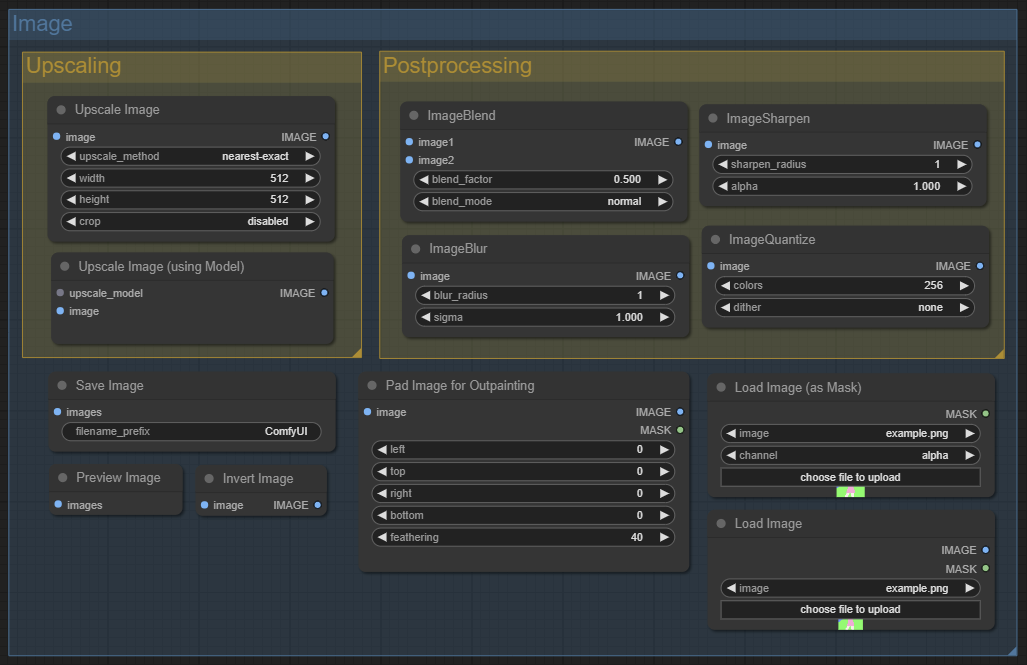
Ноды для работы с изображениями в пространстве пикселей. Многие будут знакомы тем, кто работал с редакторами растровых изображений. Тут расположены упоминавшиеся уже Save Image и Preview Image, а также:
Load Image – нода для загрузки изображений с жесткого диска;
Upscale Image (Using model) – для увеличения размера итогового изображения с помощью модели.
Оставшиеся три категории вряд ли понадобятся вам на начальном этапе.
Теперь если вы внимательно читали статью и пользовались А1111, у вас в голове должны были возникнуть ряд идей и вопросов и варианты их решения. Для тех же, кто еще не собрался с мыслями, я покажу несколько интересных воркфлоу.
Пример первый - Img2img
Добавим три ноды:
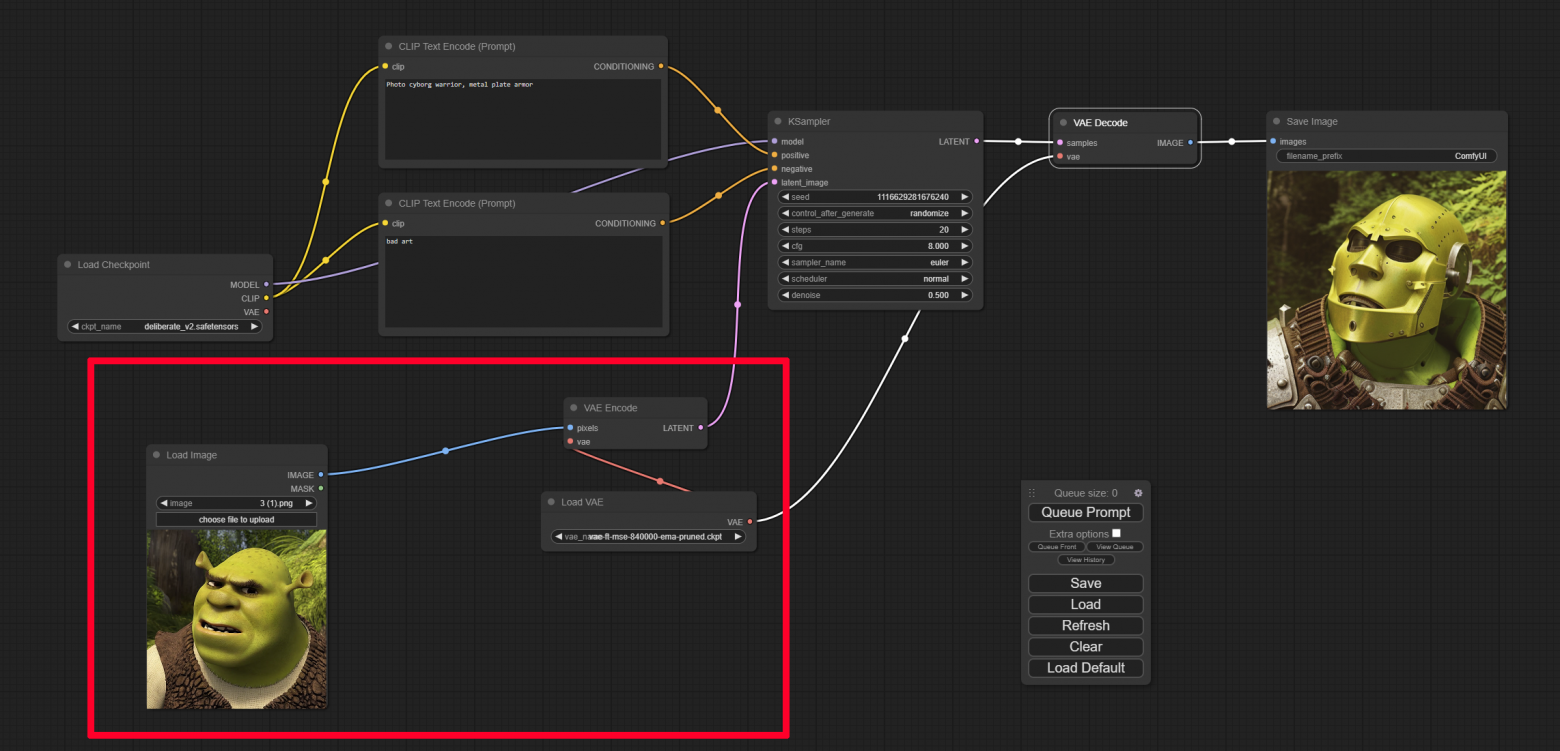
Load Image – мы загрузим изображение, которое будем преобразовывать;
VAE Encode – переведёт изображение в латентное пространство;
Load VAE – загрузит альтернативный Variational Autoencoder, которым мы будем кодировать и декодировать изображения.
Теперь размер будет браться из загруженного изображение, поэтому не стоит загружать изображения больших размеров. Регулировать силу воздействия семплера на изображение можно с помощью параметра denoise (чем меньше, тем слабее воздействие).
Пример второй - Двойное семплирование
Добавим к стандартному воркфлоу ноды:
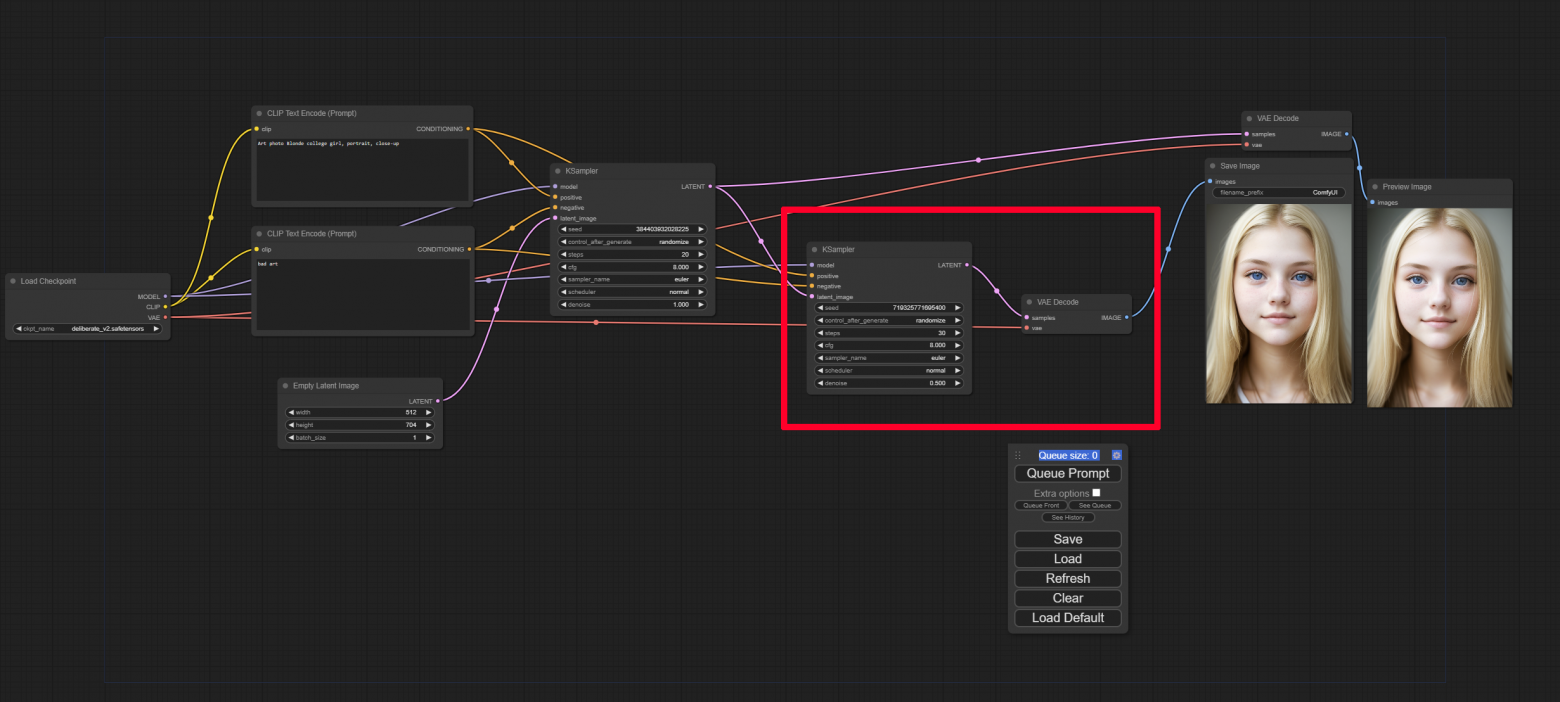
Как видно мы просто скопировали ноды семплера и декодера. Теперь из первого семплера мы будем передавать данные не только в декодер, но и во второй семплер, в котором немного изменим настройки: denoise на 0.5 и steps на 30. Save image от первого сэмплера можно заменить на Preview image, так как он нам нужен только для сравнения результатов:

Как видно на изображении слева детализация выше, само изображение более четкое и реалистичное. И это происходит не только потому что во втором семплере больше шагов, но и потому что за входные данные берется уже сгенерированное первым семплером изображение. С помощью такого метода можно поправлять деформированные зрачки, артефакты на лице, неправильно рисующаяся уши или губы, увеличивать общую детализацию изображения.
Пример третий - комбинированное изображение
Теперь сделаем то, что не получится сделать в других интерфейсах – смешаем три модели в одной картинке! Для этого соберем следующий воркфлоу:
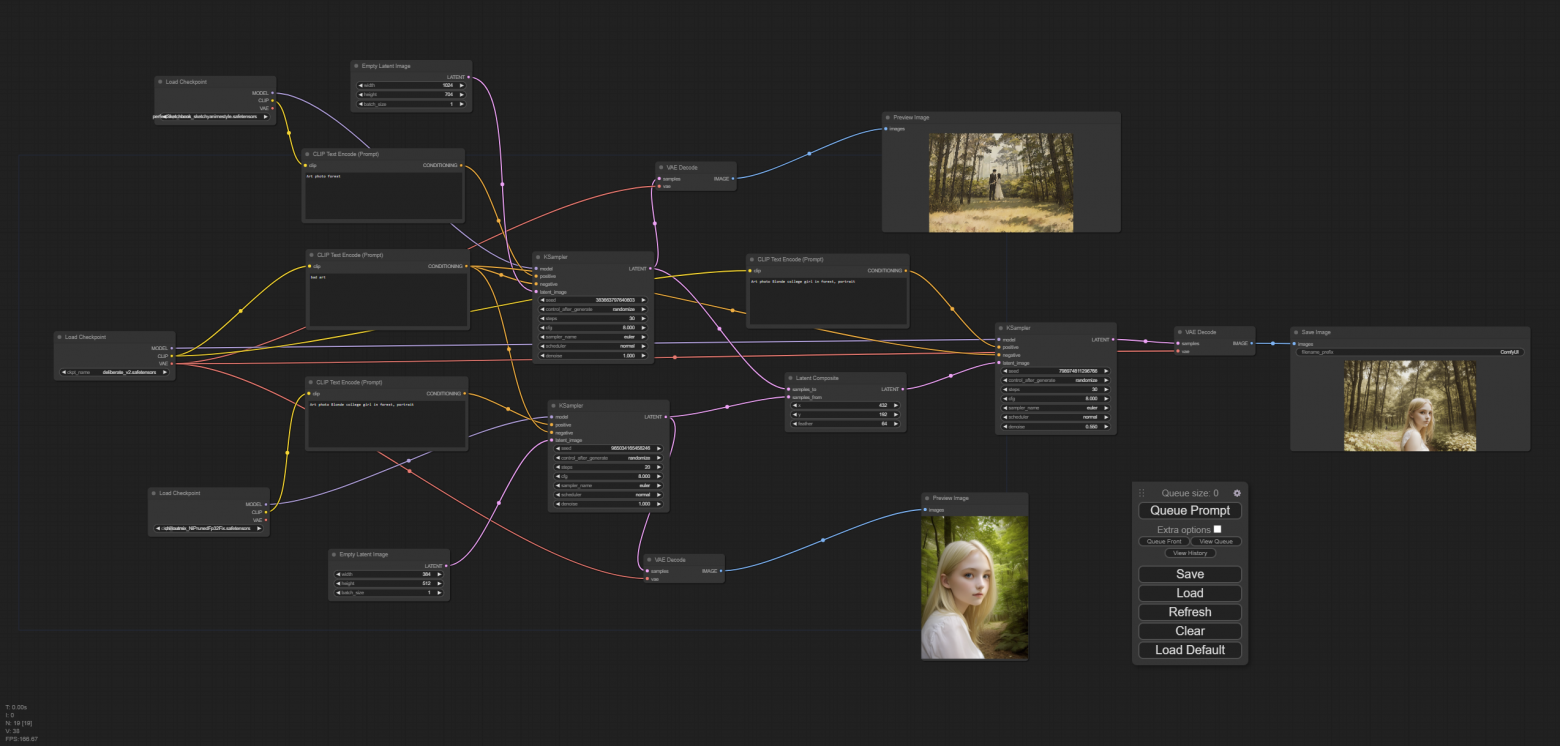
На первый взгляд довольно запутанно, но на самом деле все, что тут происходит тривиально: два семплера с разными моделями генерят два разных изображения. Затем нода Latent Composit смешивает их выставляет одно изображение поверх другого в определенной позиции (x0, y0 это левый верхний угол, feather - бленд-размытие между картинками). Потом получившееся изображение уходит в третий семплер с третьей моделью, который генерирует финальное изображение.

Подводя итог: ComfyUI - уникальный и очень интересный инструмент, который добавляет много творчества и креатива в процесс генерации изображений. Я бы назвал это “процедурное рисование”, по аналогии с “процедурным моделированием”. С момента моего знакомства с рисующими нейросетями прошло чуть больше полугода, но кажется сменилась целая эпоха. В конце своей первой статьи я попробовал порассуждать, что нас ждет в ближайшие год-два – оказалось, что почти все случилось за какие-то 6 месяцев. Думаю, ближайшее будущее за подобными решениями. Как минимум в среде профессионалов, занимающихся созданием 2d контента.
Если у вас возникли вопросы касательно ComfyUI, пишите их в комментариях. Если будет достаточный интерес к теме, то я напишу вторую часть с подробным разбором каждой ноды.
Ссылки к статье:
Github интерфейса ComfyUI
Интерактивный обучение в виде визуальной новеллы (англ.)
Сайт со множеством моделей для SD
Другие мои статьи:
Нейросеть рисует за меня?
Давайте запретим нейронные сети
Илон Маск кисти Ван Гога, или специализированные модели Stable Diffusion
Нейросети убьют 2d художников
Телеграм канал в котором я выкладываю интересные результаты генераций
