
Технологии распознавания печатного текста появились около 30 лет назад, существенно облегчив жизнь и ускорив многие бизнес-процессы. В то же время распознавание курсива оказалось куда более сложной задачей, которую удалось решить лишь благодаря развитию нейросетей.
В этом посте рассказываем о собственной технологии Content AI — распознавании русского рукописного текста, которая уже вошла в новую версию нашего продукта ContentCapture — универсальную платформу для интеллектуальной обработки информации.

Почему так долго
Еще в 90-х наши технологии научились распознавать рукопечатный текст и постепенно охватили большой набор языков. С рукописным текстом все оказалось намного сложнее. Решения, подходящие для распознавания печатного и рукопечатного текстов, недостаточно корректно работали на рукописном. Проблема заключалась в том, что классические методы, в которых распознается каждый символ отдельно, плохо применимы к произвольному рукописному тексту, т.к. машине (да и порой и человеку) сложно понять, где начинается один символ и заканчивается другой. Нужно было найти другой подход.
Кроме того, мир не был готов к распознаванию рукописного текста и технически: обучение современных сетей требовало таких вычислительных мощностей и объемов памяти, о которых еще 10 лет назад можно было только мечтать. А менее требовательные решения с точки зрения затрат на обучение и работу не смогли показать хороший результат.
Помимо роста мощностей, решающее значение оказала эволюция архитектур нейросетей. К примеру, развитие рекуррентных нейросетей (прежде всего LSTM) позволило впервые добиться практически приемлемого распознавания рукописного текста. Затем широко прогремела архитектура Трансформер, да и в целом в сфере нейросетей произошло много всего интересного. Однако продакшн поспевает за таким стремительным развитием с заметным отставанием, поэтому, например, у нас распознавание английского и немецкого рукописного появилось только в 2022 году.
Зачем распознавать рукописный текст
Функция распознавания текста — в целом очень полезная штука, которая помогла не только оцифровать многочисленные архивы, но и заметно улучшить, ускорить и автоматизировать многие бизнес-процессы: одобрение кредита за 3 часа, ответ техподдержки в течение 10 минут или денежные переводы за 2 секунды. Распознавание рукописного текста — еще одна ступень в этом направлении, которая откроет новые возможности в реализации полезных фич для бизнеса и пользователей.
К примеру, во многих документах, используемых в документообороте компаний, или паспортах до сих пор встречаются поля с рукописным текстом — адрес прописки, личные данные, даты в договоре на какие-либо услуги. И распознаются они заметно хуже печатной или рукопечатной информации. Для тех же банков, которые ежедневно обрабатывают тысячи паспортов и различных документов, наличие такой функции поможет заметно ускорить многие процессы и в целом улучшить качество обслуживания клиентов.

Особенности распознавания курсива
Курсив удалось «взломать» благодаря смене модели распознавания: перейдя от посимвольного распознавания текста к пониманию контекста вокруг символа. Иными словами, рукописный текст распознается на уровне отдельных слов, их небольших групп или фрагментов. Кстати, изначально такое End-to-end распознавание появилось в наших технологиях для распознавания печатного текста для некоторых непростых языков (например, арабского).
Сложность обучения модели для распознавания рукописного текста заключалась в требовании большого количества данных, поскольку вариантов рукописного написания — широкое разнообразие — сотни тысяч текстовых фрагментов в 1-3 слова. Также требуется больше времени на разметку корпуса текстов или наличие готовых датасетов с лицензией, разрешающей коммерческое использование.
Еще один важный нюанс — для достижения хорошего результата распознавание и языковая модель должны быть плотно интегрированы, поскольку во многих случаях выбор между вариантами результата распознавания может быть определен только из языкового контекста.
Как мы боролись за русский курсив
С начала текущего года команда Content AI плотно занялась разработкой технологии по распознаванию русского рукописного текста.
Изначально мы решили протестировать ту же архитектуру нейросети, которая уже успешно применялась для распознавания английского рукописного. Результат получился приемлемым для использования в ряде сценариев, но все-таки содержал немалое количество ошибок, поэтому технология особо бы не ускорила работу пользователя по сравнению с ручным вводом данных.
Тогда решено было перейти на более современную архитектуру, заодно сменив фреймворк NeoML на PyTorch. И с таким подходом нам удалось добиться существенно лучших результатов.
В нашей технологии используется архитектура типа энкодер-декодер. В качестве энкодера — Visual Transformer, в качестве декодера — хитрая система, работающая как ансамбль трансформеров, которые шарят веса друг друга.
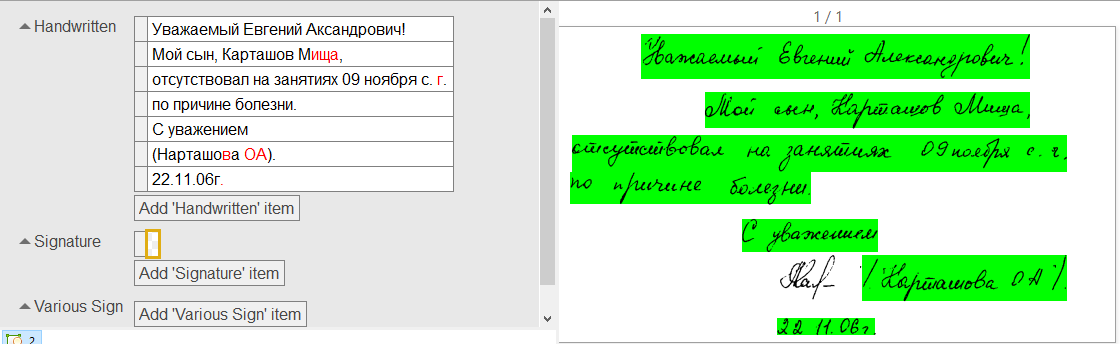
Модель обучалась на разных типах документов, в которых есть специальные поля для заполнения информации от руки: документы, удостоверяющие личность, платежные поручения, накладные, путевые листы, европротоколы при ДТП и пр. Кроме того, модель обучена числам, датам, суммам, адресам, именам собственным, знает знаки препинания и сокращения.
Схематично распознавание русского рукописного можно описать так.
Технология в целом построена на распознавании небольших фрагментов текста, длиной до 30 символов. Сначала сеть семантической сегментации находит в документе фрагменты рукописного текста и линки между ними. Затем каждый фрагмент поступает на вход обученной нами нейросети для распознавания.
На выходе выдается таблица вероятностей, в которой указано, с какой вероятностью в конкретном месте находится именно этот распознанный символ. Далее эта таблица обрабатывается теми же алгоритмами, что используются при распознавании печатного текста, и выдается финальный вариант распознанного текста. Если технология не уверена в распознавании каких-то символов, то на выходе подсветит их красным цветом, чтобы пользователь смог указать корректный вариант.
В целом количество неуверенных распознаваний должно свестись к минимуму из-за встроенного в нейросеть механизма внимания (Attention), который работает на локальном контексте (на уровне одного фрагмента). К примеру, в скане есть фрагмент «кто в лес, кто», где предлог «в» затерт. По контексту сеть безошибочно поймет, что имеется в виду, и выдаст при распознавании верный вариант. Без этого механизма нейросеть выдала бы что-нибудь в духе «кто 88 лет, кто».
Также мы обучили нейросеть распознавать «мусорные фрагменты». Иными словами, если попробовать распознать закорючки или фон вокруг слова, то нейросеть не будет пытаться подобрать для них приемлемый существующий в языке аналог, а выдаст пустую строку.
Качество распознавания
Показатель качества распознавания рукописного текста сильно зависит от типа документа и разборчивости почерка. К примеру, если сравнить качество распознавания двух первых страниц паспорта, то оно может быть разным, т.к. на первом развороте, как правило, данные написаны каллиграфическим почерком, а на втором, поле с пропиской, — как получится. По этой причине процент качества посимвольного распознавания русского рукописного нашей технологией в определенных типах документов мы обозначили в пределах 85-95%.

Если говорить о более конкретных цифрах, то тест на датасете рукописного текста от лаборатории ШИФТ ЦФТ на Kaggle показал качество распознавания нашей модели в 78,0% пословного распознавания и 95,1% посимвольного распознавания.
Кстати, помимо разработки технологии для распознавания русского рукописного, мы также по аналогии усовершенствовали предыдущую модель распознавания английского рукописного текста (он тоже поддерживается в ContentCapture). Тесты говорят сами за себя: если раньше word accuracy составлял 83,7%, то сейчас — 89,6%.
Что дальше
На ближайшую перспективу, помимо работы с обратной связью от клиентов, мы видим два направления развития технологии. И возьмемся за них, если получим соответствующие запросы от бизнес-сообщества.
Первое. Улучшение выделения строк для многострочных текстов. Сейчас технология может распознать многострочные тексты, однако разделение на отдельные строки выполняется полностью корректно в случае большого межстрочного интервала и ровного построчного написания текста, тогда как на практике во многих рукописных текстах строки слипаются, а текст пишется под наклоном.
Второе. Поддержка смешанного распознавания текста для русского и английского языков, например, «автомобиль Lexus». Сейчас каждая отдельная строка распознается только одним выбранным пользователем языком, поэтому если в документе встречаются два языка, то пользователю необходимо вручную переключить способ распознавания.
