
Я обучил небольшой (порядка 10 миллионов параметров) трансформер по превосходному туториалу Let’s build GPT: from scratch, in code, spelled out Андрея Карпати. После того, как он заработал, я захотел максимально глубоко понять, как он устроен внутри и как создаёт свои результаты.
В исходной научной статье, как и во всех туториалах по трансформерам упор в основном делается на многоголовом самовнимании, — механизме, при помощи которого трансформеры обучаются множественным взаимосвязям между токенами, не используя рекурретности или свёртку. Ни в одной из этих статей или туториалов я не нашёл удовлетворительного объяснения того, что происходит после внимания: как конкретно результаты вычисления внимания превращаются в точные прогнозы следующего токена?
Я подумал, что могу пропустить несколько примеров промтов через обученный мной небольшой, но работающий трансформер, изучить внутренние состояния и разобраться в них. То, что казалось мне быстрым исследованием, оказалось полугодовым погружением, но дало результаты, которыми стоит поделиться. В частности, у меня появилась рабочая теория, объясняющая, как трансформер создаёт свои прогнозы, и эмпирические свидетельства того, что это объяснение, по крайней мере, правдоподобно.
Если вы знакомы с трансформерами и хотите сразу узнать вывод, то он таков: каждый блок трансформера (содержащий слой многоголового внимания и сеть с прямой связью) изучает веса, связывающие конкретный промт с классом строк, найденных в обучающем корпусе. Распределение токенов, соответствующее этим строкам в обучающем корпусе, и есть приблизительно то, что блок выводит как прогноз для следующего токена. Каждый блок может ассоциировать один и тот же промт со своим классом строк обучающего корпуса, что приводит к другому распределению следующих токенов, а значит, и к другим прогнозам. Окончательный результат работы трансформера — это линейное сочетание прогнозов каждого блока.
Я написал императивный код, выполняющий то, что, по моему мнению, делает трансформер. Он создаёт результаты, очень похожие на результаты трансформера, о чём я подробнее расскажу ниже.
В этом посте я вкратце познакомлю вас с моделью и обучающими данными, продемонстрирую доказательства предлагаемого мной объяснения, подробно объяснив его реализацию в императивном коде, а также представлю доказательства в подтверждение моей теории. Я стремился сделать основной текст сжатым, со ссылками на соответствующие технические подробности в приложениях и других ноутбуках репозитория.
Этот проект — мой первый экскурс в данный тип открытых исследований машинного обучения. Я уверен, что допустил ошибки или упустил что-то, очевидное для более опытных исследователей. Любые отзывы по моей работе можно отправлять на shyam.pather at gmail dot com.
Модель и система
Предисловие
Я хочу сразу заявить, что код обученной мной модели написан не мной. Он взят из видео Андрея Карпати Let’s build GPT: from scratch, in code, spelled out (крайне рекомендую его посмотреть).
Я писал код, копируя всё, что видел на экране в процессе просмотра видео. То, что было непонятно на экране, я смотрел в репозитории GitHub этого видео и в репозитории nanoGPT. После того, как код заработал, я внёс небольшие изменения, чтобы он мог взаимодействовать со структурой/кодом моего репозитория, что привело к созданию этой реализации. Итого: базовая языковая модель — это работа Андрея Карпати, не моя. Анализ и весь поддерживающий код — мой личный вклад. В соответствующих местах поста я будут упоминать и цитировать важные статьи, посты, туториалы и другие ресурсы.
Описание модели
Моя модель — это трансформер только с декодером, состоящий из шести блоков:
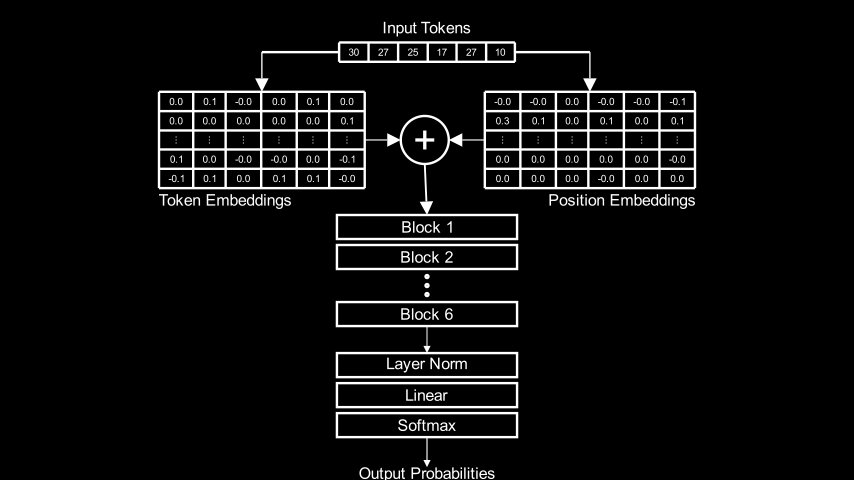
Он обучался на датасете TinyShakespeare, содержащем 40 тысяч строк пьес Шекспира. Спустя примерно час после обучения на GPU RTX 4000 он мог создавать прилично выглядящие поддельные шекспировские строки.
Получив промт, модель предсказывает токены, которые, по её мнению, должны получаться дальше. Рассмотрим пример: начав с промта ROMEO и сэмплировав 500 токенов из прогнозов модели, мы получим:
Код запуска модели и генерации пример результата по промту ROMEO:
device = 'cuda' if torch.cuda.is_available() else 'cpu' ts = TinyShakespeareDataSet(cache_file=environment.code_root / 'nbs/artifacts/input.txt') m, tokenizer = create_model_and_tokenizer( saved_model_filename=environment.code_root / 'nbs/artifacts/shakespeare-20231112.pt', dataset=ts, device=device, ) encoding_helpers = EncodingHelpers(tokenizer, device) accessors = TransformerAccessors(m, device) torch.manual_seed(2321) # Обеспечиваем детерминированность результатов при каждом прогоне prompt = 'ROMEO:' tokens = encoding_helpers.tokenize_string(prompt) print(tokenizer.decode(m.generate(tokens, max_new_tokens=500)[0].tolist()))
ROMEO: If thou wilt triumphant be virtue, and since from any bold virtue that is made a bawd of earth, then the duke desires of patience and perish: take up the other husband, dislike his tent back. First Citizen: Ourself goes, go back: you have no consul, but the disguised gods. Second Citizen: We choose him in the world, he did runk itself. First Citizen: Sir, I am I a man changed him and thriving, I have heard the king. CORIOLANUS: Consider him! AUFIDIUS: Most gracious irice, and you must danc
Это не Шекспир, но структурно вполне походит на него. Текст похож на сценарий пьесы, язык выглядит архаичным, имена/титулы персонажей взяты из реальных пьес Шекспира. Большинство слов — из английского. Пунктуация и капитализация по большей части вполне логичны. Очевидно, что текст не имеет никакого смысла, но всё равно неплохо для часа обучения.
Токены модели — это символы, а не слова. Получив промт, модель прогнозирует распределение вероятностей для следующего символа. Например, получив промт my most gr, модель прогнозирует для следующего токена следующие вероятности:
'a' 0.819 'e' 0.081 'i' 0.059 'o' 0.036 'u' 0.004 'y' 0.001 'w' 0.000 'r' 0.000 'g' 0.000 's' 0.000
Код для отображения вероятностей следующего токена промта my most gr
prompt = 'my most gr' tokens = encoding_helpers.tokenize_string(prompt) logits, _ = m(tokens) logits = LogitsWrapper(logits.detach(), tokenizer) for token, prob in logits.topk_tokens(k=10)[0][-1]: print(f'{repr(token)} {prob:.3f}')
В Приложении I приведены дополнительные подробности о модели. Если вы хотите знать больше, то лучше всего использовать код и видео Андрея.
Структура блока трансформера
Каждый из шести блоков в показанной выше диаграмме архитектуры содержит два важных подкомпонента: слой многоголового самовнимания и сеть с прямой связью, соединённые вместе сочетанием прямых и остаточных связей, как показано на диаграмме ниже:

Модуль Block реализует это соединение на PyTorch:
class Block(nn.Module): """One transformer block""" def __init__(self, n_embed, n_head): super().__init__() head_size = n_embed // n_head self.sa = MultiHeadAttention(n_head, head_size) self.ffwd = FeedForward(n_embed) self.ln1 = nn.LayerNorm(n_embed) self.ln2 = nn.LayerNorm(n_embed) def forward(self, x): x = x + self.sa(self.ln1(x)) # часть с `x +` - это skip connection x = x + self.ffwd(self.ln2(x)) # часть с `x +` - это skip connection return x
О многоголовом внимании сказано многое, но гораздо меньше говорится о сети с прямой связью, потому что, как кажется, о ней известно относительно мало:

Я начал своё исследование, заинтересовавшись тем, что идёт после внимания. После него в буквальном смысле идёт сеть с прямой связью. В исследованном мной трансформере внутри всех шести блоков сети с прямой связью составляют более 65% от общего количества обучаемых параметров, поэтому они должны играть какую-то важную роль.
Как я покажу позже, оказалось, что результат работы сети с прямой связью — это основной фактор, определяющий то, как блок преобразует свои входные данные в выходные.
Демо: моё предложение в действии
В этом разделе я покажу пример, демонстрирующий мою гипотезу о работе трансформера. В следующем разделе я подробнее расскажу о том, как это реализовано.
Представьте, что мы сделали следующее:
Пропустили через модель промт
And only lи извлекли выходное значение сети с прямой связью в первом блоке трансформера.Вернулись к обучающему корпусу, нашли все подстроки той же длины, что и наш промт (10 символов), пропустили их все через модель и отфильтровали только те, косинусный коэффициент выходных значений сети с прямой связью первого блока равен или выше 0.95 по сравнению с промтом
And only l.
Мы получим следующий набор строк:
'hat only l' 's sickly l' ' as\nthey l' 'r kingly l' 're; they l' 'eby they l' 'ar, they l' 'im, only l' 'ling any l' 'life may l' 'nobility l' 'e\nBy any l' ' as they l' ', if any l' ' hastily l' 'tly they l' ' ghastly l' '\nMy only l' 'For many l' 'r in any l' ' till my l' 'all they l' 'hen they l' 'at Henry l' 'oolishly l' 'er:\nThey l' 'may they l' 'or stony l' 'ur Henry l' 'l gladly l' 'yet they l' 'y;\nDelay l' 'e, on my l' 'or Henry l' 'I dearly l' ' if they l' ' she may l' 't\nfairly l' 'ould say l' 'd all my l' 'her they l' ' Stanley l' ' and may l' 'uld they l' 'u all my l' 'friendly l' 'h gently l' 'e deadly l' 'f all my l' 'n all my l' 'Ere they l' 'steel my l' ' tell my l' 'e kingly l' 'learn my l' 'd he say l' 't basely l' 'Thursday l' 'iciously l' " 'if any l" ' as many l' 'hy glory l' 'not very l' 'a goodly l' 'e surely l' 'quiously l' ', fairly l' 'lord! my l' 'entle my l' ', he may l' 'our holy l' ' worldly l' ' my only l' ' all, my l' 'ul, they l' 'o lately l' 's in any l' ' no lady l' 'ter many l' 'Our holy l' 't vainly l' 'e\nA lady l' ' you may l' 'y greedy l' 'untimely l' 'directly l' 'er on my l' 'e wistly l' 'ng Henry l' 'And only l' 's kindly l' 'KE:\nThey l' ' of many l' 'o, on my l'
Вспомогательная функция для вывода результатов в таблицу
def text_table( headers: Iterable[str], data_columns: Sequence[Sequence[str]], col_widths: Sequence[int] ): assert len(headers) == 0 or len(headers) == len( data_columns ), "Must have either zero headers or the same number as data columns" assert len(data_columns) == len(col_widths), "Must have same number of column widths as data columns" if len(headers) > 0: output = "".join([f"{header:{col_widths[i]}}" for i, header in enumerate(headers)]) + "\n" header_underlines = ["-" * len(header) for header in headers] output += ( "".join( [ f"{header_underline:{col_widths[i]}}" for i, header_underline in enumerate(header_underlines) ] ) + "\n" ) else: output = "" max_len = max([len(col) for col in data_columns]) for i in range(max_len): items = [ data_column[i] if i < len(data_column) else " " for data_column in data_columns ] output += "".join([f"{item:{col_widths[i]}}" for i, item in enumerate(items)]) + "\n" return output
Код для генерации схожих строк (будет объяснён позже)
# Получаем все уникальные подстроки в тексте strings10 = all_unique_substrings(text=ts.text, substring_length=10) # Настройки для предварительной фильтрации prefiltered_threshold=0.7 prefiltered_results_folder = environment.data_root / 'cosine_sim_results/large_files/slen10' / f'prefiltered_{prefiltered_threshold}' def prefiltered_filename(block_idx: int, q_idx: int) -> Path: return prefiltered_results_folder / f'cosine_sim_ffwd_out_{q_idx:05d}_{block_idx:02d}.pt' def load_prefiltered_data(block_idx: int, q_idx: int): return torch.load(prefiltered_filename(block_idx, q_idx)) block_idx = 0 similarity_threshold=0.95 q_idx = 57 # Индекс запроса для `And only l` similar_indices = filter_on_prefiltered_results( load_prefiltered=lambda q_idx: load_prefiltered_data(block_idx, q_idx), q_idx_start=q_idx, q_idx_end=q_idx+1, filter_fn=lambda values: values > similarity_threshold ) similar_strings = [ [strings10[i] for i in indices] for indices in similar_indices ] data_columns=[ [repr(s) for s in similar_strings[0][i : i + 20]] for i in range(0, len(similar_strings[0]), 20) ] print(text_table( headers=[], data_columns=data_columns, col_widths=[16 for _ in data_columns] ))
Здесь виден чёткий паттерн: все они заканчиваются на y l и многие из них оканчиваются на ly l. Схожесть в пространстве сети с прямой связью, похоже, соответствует интерпретируемым человеком паттернам.
Теперь представим, что мы вернулись к обучающему корпусу, нашли каждую из этих строк и построили распределение всех символов, идущих после них. Мы выясним, например:
что за
hat only lследуетi(That only like a gulf it did remain)что за
l gladly lследует e (I’ll gladly learn)что за
n all my lследуютaиi(In all my lands and leases whatsoever и never saw you before in all my life)
Проделав это для полного множества из 94 подстрок, мы получим следующее распределение:

Вспомогательная функция составления графика распределения вероятностей для токенов
def plot_prob_distribution_for_tokens( prob_distribution: torch.Tensor, title: str = "", ax: Optional[Axes] = None, figsize=(12, 4), ): if ax is None: _, ax = plt.subplots(figsize=figsize) x_indices = np.arange(tokenizer.vocab_size) x_labels = [repr(c)[1:-1] for c in tokenizer.chars] ax.bar(x_indices, prob_distribution) ax.set_xticks(x_indices, x_labels, rotation="vertical") ax.set_title(title) ax.set_ylim(0.0, 1.0)
Код создания распределения из токенов, следующих за схожими строками
next_token_map10 = build_next_token_map( text=ts.text, prefix_len=10, vocab_size=tokenizer.vocab_size, stoi=tokenizer.stoi ) total_freq_distribution = torch.stack([ next_token_map10[string] for string in similar_strings[0] ]).sum(dim=0) prob_distribution = total_freq_distribution / total_freq_distribution.sum() plot_prob_distribution_for_tokens(prob_distribution, title='Normalized frequency distribution from block 0 similar strings')
Токены словаря модели отложены по оси X, а их нормализованная частота появления — по оси Y. Этот график демонстрирует, что самый частый токен — это i, за ним идёт o, потом a и, наконец, e.
Давайте взглянем на окончательный результат работы трансформера как на целое с промтом And only l:

Код для создания прогнозов модели
prompt = 'And only l' tokens = encoding_helpers.tokenize_string(prompt) logits, _ = m(tokens) logits = LogitsWrapper(logits.detach(), tokenizer) logits.plot_probs(title='Probability distribution from model')
Это распределение вероятностей отражает прогнозы модели для следующего токена. Обратите внимание, насколько поразительно они похожи на распределение с нормализованной частотой, показанное на предыдущем графике!
Мы можем численно оценить степень их схожести. Расстояние Хеллингера — это мера степени пересечения между распределениями вероятностей. Если обозначить распределения за P и Q, то расстояние Хеллингера между ними будет таким:

В коде это будет выглядеть так:
def hellinger_distance( p: torch.Tensor, q: torch.Tensor, ): return ((p.sqrt() - q.sqrt())**2).sum(dim=-1).sqrt() / math.sqrt(2)
Расстояние Хеллингера, равное 0, означает, что два распределения идентичны, а 1 означает, что у них нет пересечений.
Расстояние Хеллингера между двумя представленными выше распределениями (распределением, образованным из токенов, следующих за строками со схожими результатами сети с прямой связью и распределение, прогнозируемое моделью) равно 0.07: они почти идентичны.
Чтобы не делать демо слишком длинным, я выбрал пример, в котором одних только схожих строк в первом блоке достаточно для создания распределения, близко схожего с готовым результатом трансформера. Обычно нам нужно выполнять одно и то же упражнение (нахождение строк в обучающем корпусе, создающих результаты работы сети с прямой связью, схожие с промтом и создание распределения токенов, превышающих их) для всех шести блоков трансформера, а затем вычислять взвешенную сумму получившихся распределений, чтобы получить хорошее совпадение. Мы сделаем это в следующем разделе и увидим, что в выборке из 20000 промтов среднее расстояние Хеллингера между вычисленными таким образом распределениями и соответствующим результатом трансформера составляет всего 0.17.
Такое малое расстояние Хеллингера даёт нам понять, что результаты, полученные таким способом, являются хорошей аппроксимацией результатов трансформера. Кроме того, как я объясню в разделе «Интерпретация», мне кажется, такой подход является приемлемой аппроксимацией того, что делает трансформер.
Реализация: аппроксимация результатов работы трансформера при помощи результатов сети с прямой связью
В этом разделе я рассмотрю процедуру, которую я использовал для аппроксимации результатов работы трансформера при помощи строк, которые дают схожие результаты работы сети с прямой связью.
Повторюсь, что это процедура для вычисления аппроксимации:
Пропустить промт через модель и сохранить результаты сети с прямой связью для каждого блока.
Для каждого блока:
Найти строки в обучающем корпусе, создающие наиболее схожие результаты сети с прямой связью на промт для этого блока.
Для каждой найденной строки построить распределение частот токенов, идущих после неё в обучающем корпусе.
Суммировать распределения частот всех строк для текущего блока.
Вычислить взвешенную сумму распределений частот для каждого блока, вычисленных на предыдущем этапе.
Нормализовать взвешенную сумму, чтобы получить распределение вероятностей.
Подготовка процедуры
Первый этап процедуры (пропускание промта через модель и сохранение результатов работы сети с прямой связью для каждого блока) легко выполнить простыми хуками PyTorch. Но первая часть второго этапа (поиск строк в обучающем корпусе, создающих схожие результаты сети с прямой связью) для эффективной работы требует дополнительной подготовки.
Для эффективности вычислений и хранения я выполнял весь анализ со строками длиной 10 (но также убедился, что результаты остаются такими же и для более коротких, и для более длинных строк). Обучающий корпус длиной 1115394 символа содержит 858 923 уникальные подстроки длиной 10. Каждый результат работы сети с прямой связью — это 384-мерный вектор значений float32; модель создаёт шесть таких векторов (по одному для каждого блока). Сравнение шести 384-мерных результатов работы сети для любого промта с 6 * 858923 = 5153538 результатами сети с прямой связью для всех остальных строк занимает долгое время. Чтобы иметь возможность работать с этими данными, нужны предварительные вычисления. Я создал следующий конвейер:
Выбрал из обучающего корпуса 20000 случайных строк длиной 10, чтобы использовать их в качестве промтов для этого эксперимента.
Запустил на ночь процесс вычисления косинусного коэффициента между результатами сети с прямой связью, созданными моделью для 20000 промтов, и тех, которые она создала для 858923 уникальных подстрок длиной 10 из обучающего корпуса. Я делал это пакетно и сохранял результаты на диск.
Даже после предварительного вычисления результатов косинусного коэффициента поиск среди них всех для нахождения ближайшего совпадения занимал много времени. Эксперименты показали, что важные для нас совпадения никогда не имели косинусный коэффициент ниже 0.7, поэтому я добавил ещё один этап для предварительной фильтрации результатов второго этапа, выбирая только те элементы, косинусный коэффициент которых >= 0.7. Это сильно уменьшило количество элементов для поиска.
Код этих предварительных вычислений и фильтрации слишком большой, чтобы включать его в пост, реализацию можно посмотреть в экспериментальном ноутбуке cosine-sims.
Подробное описание процедуры
В этом разделе мы поэтапно создадим код и будем выполнять его по одному промту за раз и только для одного блока. В последующих разделах мы расширим его до дополнительных блоков, пропустим через него большое количество промтов и изучим результаты.
Сначала нам нужно взять из обучающего корпуса 20 000 строк длиной 10, которые будут использоваться как промты:
# Получаем все уникальные подстроки в тексте strings10 = all_unique_substrings(text=ts.text, substring_length=10) n_prompts = 20000 torch.manual_seed(1337) indices = torch.randperm(len(strings10))[:n_prompts] prompts = [strings10[i.item()] for i in indices]
Как говорилось в разделе «Подготовка процедуры», я заранее пропустил все эти строки через модель, взял результаты работы сети с прямой связью для каждого блока и предварительно вычислил косинусные коэффициенты для всех уникальных подстрок длиной 10 в обучающем корпусе. А затем предварительно отфильтровал результаты, ограничившись результатами, косинусный коэффициент которых >= 0.7.
Реализующий всё это экспериментальный ноутбук cosine-sims также экспортирует вспомогательную функцию filter_on_prefiltered_results(), которую можно использовать для поиска наиболее схожих строк для конкретного промта путём поиска в предварительно отфильтрованных результатах.
Если вам любопытно, как это работает, то загляните в ноутбук. Он достаточно простой, а в юнит-тесте есть простой пример, иллюстрирующий вид входных и выходных данных.
Чтобы использовать filter_on_prefiltered_results(), нам просто нужно сообщить ей, как найти предварительно отфильтрованные файлы:
prefiltered_threshold=0.7 prefiltered_results_folder = environment.data_root / 'cosine_sim_results/large_files/slen10' / f'prefiltered_{prefiltered_threshold}' def prefiltered_filename(block_idx: int, q_idx: int) -> Path: return prefiltered_results_folder / f'cosine_sim_ffwd_out_{q_idx:05d}_{block_idx:02d}.pt' def load_prefiltered_data(block_idx: int, q_idx: int): return torch.load(prefiltered_filename(block_idx, q_idx))
Обратите внимание на использование q_idx здесь и в остальной части кода: q_idx обозначает query index («индекс запроса»). Задача, которая заранее вычисляет все косинусные коэффициенты, получает множество «запросов» или значений для сравнения. Запросы — это результаты сети с прямой связью, которые модель создаёт для промтов. Между запросами и промтами существует соотношение 1:1, поэтому в коде я использую эти термины взаимозаменяемо.
Для начала мы воспользуемся тем же промтом And only l, который мы брали для демо. Он оказывается промтом по индексу 57:
prompts[57]
'And only l'
Мы найдём строки, результаты работы сети с прямой связью которых в блоке 0 имеют косинусный коэффициент 0.95 или выше при сравнении с результатом сети с прямой связью промта в блоке 0.
block_idx = 0 similarity_threshold=0.95 q_idx = 57 similar_indices = filter_on_prefiltered_results( load_prefiltered=lambda q_idx: load_prefiltered_data(block_idx, q_idx), q_idx_start=q_idx, q_idx_end=q_idx+1, filter_fn=lambda values: values > similarity_threshold ) similar_strings = [ [strings10[i] for i in indices] for indices in similar_indices ] len(similar_strings[0])
Так мы получаем 94 схожих строк, которые видели в демо. Можно вывести их, чтобы быть уверенными:
print(f"Original string: {repr(prompts[q_idx])}") print("Similar strings: \n") data_columns=[ [repr(s) for s in similar_strings[0][i : i + 20]] for i in range(0, len(similar_strings[0]), 20) ] print(text_table( headers=[], data_columns=data_columns, col_widths=[18 for _ in data_columns] ))
Original string: 'And only l' Similar strings: 'hat only l' 's sickly l' ' as\nthey l' 'r kingly l' 're; they l' 'eby they l' 'ar, they l' 'im, only l' 'ling any l' 'life may l' 'nobility l' 'e\nBy any l' ' as they l' ', if any l' ' hastily l' 'tly they l' ' ghastly l' '\nMy only l' 'For many l' 'r in any l' ' till my l' 'all they l' 'hen they l' 'at Henry l' 'oolishly l' 'er:\nThey l' 'may they l' 'or stony l' 'ur Henry l' 'l gladly l' 'yet they l' 'y;\nDelay l' 'e, on my l' 'or Henry l' 'I dearly l' ' if they l' ' she may l' 't\nfairly l' 'ould say l' 'd all my l' 'her they l' ' Stanley l' ' and may l' 'uld they l' 'u all my l' 'friendly l' 'h gently l' 'e deadly l' 'f all my l' 'n all my l' 'Ere they l' 'steel my l' ' tell my l' 'e kingly l' 'learn my l' 'd he say l' 't basely l' 'Thursday l' 'iciously l' " 'if any l" ' as many l' 'hy glory l' 'not very l' 'a goodly l' 'e surely l' 'quiously l' ', fairly l' 'lord! my l' 'entle my l' ', he may l' 'our holy l' ' worldly l' ' my only l' ' all, my l' 'ul, they l' 'o lately l' 's in any l' ' no lady l' 'ter many l' 'Our holy l' 't vainly l' 'e\nA lady l' ' you may l' 'y greedy l' 'untimely l' 'directly l' 'er on my l' 'e wistly l' 'ng Henry l' 'And only l' 's kindly l' 'KE:\nThey l' ' of many l' 'o, on my l'
Далее нам нужно создать распределение частот токенов, которые идут после этих строк в тексте. Чтобы это было просто и эффективно (нам придётся делать это много раз), можно предварительно вычислить распределения частот следующих токенов для всех уникальных подстрок длиной 10 обучающего корпуса. Этим занимается вспомогательная функция build_next_token_map(), реализованная в модуле text-analysis.)
next_token_map10 = build_next_token_map( text=ts.text, prefix_len=10, vocab_size=tokenizer.vocab_size, stoi=tokenizer.stoi )
Возвращаемое значение, сохраняемое в next_token_map10 — это словарь, сопоставляющий каждые уникальные подстроки длиной 10 в обучающем корпусе с распределением частот токенов, идущих после них. Концептуально это выглядит примерно так:
{ 'the common': { ' ': 12, "'": 1, ',': 1, '?': 1, 'a': 1, 's': 5, 'w': 3 }, ' the gods ': { 'b': 1, 'c': 1, 'd': 2, 'f': 1, 'g': 1, 'h': 2, 'k': 2, 's': 2, 't': 1, 'w': 2 }, ' authority': { '\n': 1, ' ': 5, ',': 5, ':': 2, ';': 1 }, ... }
На самом деле, значения — это тензоры вида (vocab_size,) где vocab_size — количество уникальных токенов в словаре (в нашем случае 65). Элемент по индексу i в тензоре — это количество вхождений i-того токена после строки в ключе этой записи. Это больше походит вот на такое:
{ 'the common': torch.tensor([ 0, 12, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 5, 0, 0, 0, 3, 0, 0, 0 ]), ' the gods ': torch.tensor([ 0, 12, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 5, 0, 0, 0, 3, 0, 0, 0 ]), ' authority': torch.tensor([ 0, 12, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 5, 0, 0, 0, 3, 0, 0, 0 ]), ... }
Далее нам нужно суммировать распределения частот для всех найденных строк, которые имеют схожие с нашим промтом результаты сети с прямой связью. Так как в next_token_map10 хранятся в виде тензоров отдельные распределения частот, это сделать легко:
total_freq_distribution = torch.stack([ next_token_map10[string] for string in similar_strings[0] ]).sum(dim=0)
Мы объединяем распределения каждой схожей строки в единый тензор, а затем суммируем их все. Теперь можно превратить это в распределение частот, разделив каждую запись на сумму всех записей:
prob_distribution = total_freq_distribution / total_freq_distribution.sum()
Далее можно визуализировать это распределение:
plot_prob_distribution_for_tokens(prob_distribution, title='Probability distribution using only block 0 similar strings')

Это тоже распределение, что мы видели в демо.
Теперь давайте закодируем сравнение с результатом работы модели:
tokens = encoding_helpers.tokenize_string(prompts[q_idx]) logits, _ = m(tokens) logits = LogitsWrapper(logits.detach(), tokenizer) logits.plot_probs(title='Probability distribution from model')

Два распределения снова выглядят очень похоже, и в этом примере аппроксимация использует только значения из первого блока. Чтобы лучше сравнить их, можно посмотреть на распределения в текстовом виде:
Вспомогательная функция для вывода сравнения распределений в виде таблицы
def print_distribution_comparison( approx_top_tokens: Sequence[Tuple[str, float]], model_top_tokens: Sequence[Tuple[str, float]], ): max_len = min(len(approx_top_tokens), len(model_top_tokens)) print( text_table( headers=["Model Predictions", "Approximation Predictions"], data_columns=[ [ f"{repr(token)[1:-1]}: {prob:.3f}" for i, (token, prob) in enumerate(model_top_tokens) if i < max_len ], [ f"{repr(token)[1:-1]}: {prob:.3f}" for i, (token, prob) in enumerate(approx_top_tokens) if i < max_len ], ], col_widths=[20, 20], ) )
approx_top_tokens = top_nonzero_tokens(prob_distribution, tokenizer.itos) model_top_tokens = logits.topk_tokens(k=10)[0][-1] print_distribution_comparison(approx_top_tokens, model_top_tokens)
Model Predictions Approximation Predictions ----------------- ------------------------- i: 0.437 i: 0.389 o: 0.204 o: 0.250 a: 0.195 a: 0.222 e: 0.160 e: 0.139
Теперь мы также можем сравнить расстояние Хеллингера между этими распределениями:
hellinger_distance(prob_distribution, logits.probs()[0][-1])
tensor(0.0711)
Скомбинировав распределения частот следующих токенов схожих строк из только первого слоя модели, мы смогли достаточно близко аппроксимировать результат работы трансформера. Разумеется, я выбрал пример, который подошёл особенно хорошо.
Вот пример, в котором распределение частот только из первого слоя срабатывает плохо:
q_idx=40 prompts[q_idx]
'hing tremb'
При помощи той же методики мы можем идентифицировать в обучающем корпусе 57 строк, создающих для промта схожие результаты работы сети с прямой связью:
block_idx = 0 similarity_threshold=0.95 similar_indices = filter_on_prefiltered_results( load_prefiltered=lambda q_idx: load_prefiltered_data(block_idx, q_idx), q_idx_start=q_idx, q_idx_end=q_idx+1, filter_fn=lambda values: values > similarity_threshold ) similar_strings = [ [strings10[i] for i in indices] for indices in similar_indices ] len(similar_strings[0])
57
Мы можем искать, суммировать и нормализовать распределения частот токенов, следующих за этими строками в обучающем корпусе, а также сравнивать результаты с результатами работы модели, как делали ранее:
total_freq_distribution = torch.stack([ next_token_map10[string] for string in similar_strings[0] ]).sum(dim=0) prob_distribution = total_freq_distribution / total_freq_distribution.sum() approx_top_tokens = top_nonzero_tokens(prob_distribution, tokenizer.itos) tokens = encoding_helpers.tokenize_string(prompts[q_idx]) logits, _ = m(tokens) logits = LogitsWrapper(logits.detach(), tokenizer) model_top_tokens = logits.topk_tokens(k=10)[0][-1] print_distribution_comparison(approx_top_tokens, model_top_tokens)
Model Predictions Approximation Predictions ----------------- ------------------------- l: 0.999 e: 0.543 e: 0.000 l: 0.343 r: 0.000 r: 0.114
Эти распределения сильно отличаются от распределений из прошлого примера. Верхние три токена одинаковы в каждом, но они находятся в неверном порядке, а их вероятности далеко разнесены. Из-за этих различий расстояние Хеллингера оказывается большим:
tokens = encoding_helpers.tokenize_string(prompts[q_idx]) logits, _ = m(tokens) logits = LogitsWrapper(logits.detach(), tokenizer) hellinger_distance(prob_distribution, logits.probs()[0][-1])
tensor(0.6305)
Для промта 'hing tremb' простое использование значений из первого блока приводит к плохой аппроксимации результатов работы трансформера. Вскоре мы добавим влияние других блоков и после этого расстояние Хеллингера между аппроксимацией и реальным результатом трансформера снизится с 0.63 до всего 0.02.
Пороговые значения схожести
В предыдущих примерах я использовал пороговое значение схожести 0.95: я искал строки, результаты сети с прямой связью в блоке 0 создавали значения с косинусным коэффициентом 0.95 или выше при сравнении с результатом сети с прямой связью для промта.
При использовании другого порогового значения можно получить другие результаты. Например, проделав то же упражнение для промта id 57 ('And only l') с пороговым значением 0.90, мы найдём 612 схожих строк, а не 94, как раньше:
block_idx = 0 similarity_threshold=0.90 q_idx = 57 similar_indices = filter_on_prefiltered_results( load_prefiltered=lambda q_idx: load_prefiltered_data(block_idx, q_idx), q_idx_start=q_idx, q_idx_end=q_idx+1, filter_fn=lambda values: values > similarity_threshold ) similar_strings = [ [strings10[i] for i in indices] for indices in similar_indices ] len(similar_strings[0])
612
Если проделать оставшуюся часть процедуры аппроксимации, то мы увидим другие (менее качественные) результаты:
total_freq_distribution = torch.stack([ next_token_map10[string] for string in similar_strings[0] ]).sum(dim=0) prob_distribution = total_freq_distribution / total_freq_distribution.sum() approx_top_tokens = top_nonzero_tokens(prob_distribution, tokenizer.itos) tokens = encoding_helpers.tokenize_string(prompts[q_idx]) logits, _ = m(tokens) logits = LogitsWrapper(logits.detach(), tokenizer) model_top_tokens = logits.topk_tokens(k=10)[0][-1] print_distribution_comparison(approx_top_tokens, model_top_tokens)
Model Predictions Approximation Predictions ----------------- ------------------------- i: 0.437 o: 0.584 o: 0.204 i: 0.251 a: 0.195 a: 0.095 e: 0.160 e: 0.066 u: 0.004 u: 0.002 l: 0.000 y: 0.001
Пять верхних токенов остались такими же, но при ранжировании по вероятности порядок аппроксимации отличается от порядка модели. Расстояние Хеллингера тоже выше:
hellinger_distance(prob_distribution, logits.probs()[0][-1])
tensor(0.2856)
При снижении порогового значения схожести в вычислении появились дополнительные строки, что ухудшило аппроксимацию. Если сделать его выше 0.95, то мы тоже получим результаты хуже, чем при 0.95, предположительно потому, что исключаем строки, необходимые для создания хорошей аппроксимации:
block_idx = 0 similarity_threshold=0.97 q_idx = 57 similar_indices = filter_on_prefiltered_results( load_prefiltered=lambda q_idx: load_prefiltered_data(block_idx, q_idx), q_idx_start=q_idx, q_idx_end=q_idx+1, filter_fn=lambda values: values > similarity_threshold ) similar_strings = [ [strings10[i] for i in indices] for indices in similar_indices ] len(similar_strings[0])
33
total_freq_distribution = torch.stack([ next_token_map10[string] for string in similar_strings[0] ]).sum(dim=0) prob_distribution = total_freq_distribution / total_freq_distribution.sum() approx_top_tokens = top_nonzero_tokens(prob_distribution, tokenizer.itos) tokens = encoding_helpers.tokenize_string(prompts[q_idx]) logits, _ = m(tokens) logits = LogitsWrapper(logits.detach(), tokenizer) model_top_tokens = logits.topk_tokens(k=10)[0][-1] print_distribution_comparison(approx_top_tokens, model_top_tokens)
Model Predictions Approximation Predictions ----------------- ------------------------- i: 0.437 o: 0.278 o: 0.204 i: 0.250 a: 0.195 a: 0.250 e: 0.160 e: 0.222
hellinger_distance(prob_distribution, logits.probs()[0][-1])
tensor(0.1498)
Похоже, для первого блока 0.95 подходит лучше всего. Я пришёл к этому значению при помощи ручной подгонки: пробовал разные значения и двоичный поиск, пока не нашёл то, которое даёт наилучшие результаты. Полная история этого упражнения по настройке приведена в ноутбуке анализа схожих пространств.
В конечном итоге выяснилось, что наилучшие результаты для каждого блока дают следующие пороговые значения:
Блок | Пороговое значение схожести |
|---|---|
0 | 0.95 |
1 | 0.94 |
2 | 0.85 |
3 | 0.76 |
4 | 0.81 |
5 | 0.89 |
Когда я только начал исследовать эту тему, то предположил, что аппроксимация будет становиться тем лучше, чем больше схожести я смогу найти. Я попробовал множество техник, в том числе и эксперименты с эвклидовым расстоянием вместо косинусного коэффициента, поиск в строках разной длины и так далее. Каждый раз, когда мне успешно удавалось найти строки с более схожими результатами работы сети с прямой связью для использования в аппроксимации, тем хуже становились результаты. Я понял, что, по крайней мере, для некоторых блоков, включение менее схожих значений приводило к более качественным аппроксимациям, вероятно, потому, что эти блоки учились сопоставлять промты с более широкими классами строк в обучающем корпусе.
Выходим за пределы первого блока
До этого мы рассматривали результаты работы сети с прямой связью только из первого блока. Теперь мы добавим вклад всех остальных блоков.
Для начала найдём строки, создающие схожие результаты сети с прямой связью в каждом из блоков, воспользовавшись указанными выше пороговыми значениями схожести. Пока мы сделаем это только для одного запроса (индекс 57, 'And only l'):
similarity_thresholds=[0.95, 0.94, 0.85, 0.76, 0.81, 0.89] q_idx = 57 similar_strings_per_block = [] for block_idx in range(n_layer): similar_indices = filter_on_prefiltered_results( load_prefiltered=lambda q_idx: load_prefiltered_data(block_idx, q_idx), q_idx_start=q_idx, q_idx_end=q_idx+1, filter_fn=lambda values: values > similarity_thresholds[block_idx] ) similar_strings = [ [strings10[i] for i in indices] for indices in similar_indices ] similar_strings_per_block.append(similar_strings)
Давайте посмотрим, сколько строк мы нашли для каждого блока на основании этих пороговых значений:
print(text_table( headers=["Block Index", "Similarity Threshold", "# of Similar Strings"], data_columns=[ [f"{block_idx:>10}" for block_idx in range(n_layer)], [f"{threshold:>19}" for threshold in similarity_thresholds], [f"{len(similar_strings[0]):>19}" for similar_strings in similar_strings_per_block], ], col_widths=[14, 23, 23] ))
Block Index Similarity Threshold # of Similar Strings ----------- -------------------- -------------------- 0 0.95 94 1 0.94 47 2 0.85 70 3 0.76 108 4 0.81 175 5 0.89 2237
Теперь, когда мы идентифицировали подходящие строки для каждого блока, можно перейти к следующему этапу процедуры аппроксимации: созданию распределений частот для токенов, следующих за этими строками, и их суммированию. Мы будем это делать часто, так что определим для этого функцию:
def frequency_distribution_from_similar_strings( similar_strings_per_block: Sequence[Sequence[Sequence[str]]], next_token_map: Dict[str, torch.Tensor], ) -> torch.Tensor: # freqs_per_block_per_query - это список списка тензоров. Внешний список содержит # по одному элементу на блок. Внутренний список содержит по одному элементу на запрос. # Каждый тензор - это распределение частот следующих токенов для конкретного # блока и запроса. freqs_per_block_per_query: List[List[torch.Tensor]] = [[] for _ in range(n_layer)] for block_idx in range(n_layer): for similar_strings in similar_strings_per_block[block_idx]: freqs_per_block_per_query[block_idx].append( torch.stack([next_token_map[string] for string in similar_strings]).sum( dim=0 ) ) # Объединяем все тензоры частот в единый тензор вида # (n_layer, n_queries, vocab_size) freqs = torch.stack( [ torch.stack(freqs_per_block_per_query[block_idx]) for block_idx in range(n_layer) ] ) return freqs
Эта функция frequency_distribution_from_similar_strings() выполняет эквивалент того когда, который мы рассматривали выше:
total_freq_distribution = torch.stack([ next_token_map10[string] for string in similar_strings[0] ]).sum(dim=0)
Но с двумя важными различиями:
Она выполняет расчёты для всех блоков с использованием схожих строк, которые мы нашли для каждого блока выше.
Она позволяет использовать несколько запросов. В ранее рассмотренном нами коде мы вычисляли аппроксимацию для одного промта. В следующем разделе мы будем выполнять её для множества промтов, поэтому я написал код в более общем виде. В частности, код позволяет, чтобы
similar_strings_per_blockсодержала не только единый список строк на блок, а несколько: по одному для каждого запроса.
Давайте выполним это для созданной выше similar_strings_per_block:
freq_distribution = frequency_distribution_from_similar_strings( similar_strings_per_block, next_token_map10, ) freq_distribution.shape
torch.Size([6, 1, 65])
Мы получаем тензор вида (6, 1, 65): 6 блоков, 1 запрос, 65 токенов в словаре. Если бы мы работали с бóльшим количеством запросов, то средняя размерность была бы больше.
Итак, теперь у нас есть распределение частот для каждого блока на основании строк, найденных для каждого блока с использованием пороговых значений схожести. Далее нам нужно превратить это в распределение вероятностей.
Выше, когда у нас было только одно распределение частот для одного блока, мы просто нормализовали его. Но теперь у нас есть несколько распределений частот (по одному на блок) и их нужно скомбинировать. В своих экспериментах я выяснил, что наилучшие результаты даёт взвешенная сумма этих распределений.
Как и в случае с пороговыми значениями схожести, я смог путём проб и ошибок найти множество хороших весов. Я пробовал и методику глубокого обучения для поиска весов, но результаты оказались не лучше, чем при подборе вручную. Процедура ручного подбора и изучения весов реализована в ноутбуке схожих пространств, где мы подбирали и пороговые значения.
Пока будем использовать найденные мной оптимальные веса:
weights = torch.tensor([0.01, 0.01, 0.1, 1.5, 6, 0.01]).unsqueeze(dim=1).unsqueeze(dim=2) # (n_layer, 1, 1) total_freq_distribution = (freq_distribution * weights).sum(dim=0) prob_distribution = total_freq_distribution / total_freq_distribution.sum(dim=-1, keepdim=True)
Мы умножаем распределения частот на веса, выполняем суммирование по всем блокам, а затем выполняем нормализацию в распределение вероятностей. Теперь мы можем узнать, как распределение аппроксимации сравнимо с распределением модели.
Примечание: в коде ниже нам пришлось брать для тензора prob_distribution индекс [0], потому что его первая размерность — это количество запросов. Мы работаем только с одним запросом, поэтому нам нужно брать только первый элемент.
approx_top_tokens = top_nonzero_tokens(prob_distribution[0], tokenizer.itos) tokens = encoding_helpers.tokenize_string(prompts[q_idx]) logits, _ = m(tokens) logits = LogitsWrapper(logits.detach(), tokenizer) model_top_tokens = logits.topk_tokens(k=10)[0][-1] print_distribution_comparison(approx_top_tokens, model_top_tokens)
Model Predictions Approximation Predictions ----------------- ------------------------- i: 0.437 i: 0.363 o: 0.204 o: 0.265 a: 0.195 a: 0.213 e: 0.160 e: 0.147 u: 0.004 u: 0.011 l: 0.000 y: 0.000
hellinger_distance(prob_distribution[0], logits.probs()[0][-1])
tensor(0.0731)
В этом конкретном случае сложение других слоёв не особо меняет аппроксимацию (судя по расстоянию Хеллингера, она лишь немного хуже). Но давайте рассмотрим пример, который плохо работал, когда мы рассматривали только первый слой: промт с id 40 ('hing tremb').
similarity_thresholds=[0.95, 0.94, 0.85, 0.76, 0.81, 0.89] q_idx = 40 similar_strings_per_block = [] for block_idx in range(n_layer): similar_indices = filter_on_prefiltered_results( load_prefiltered=lambda q_idx: load_prefiltered_data(block_idx, q_idx), q_idx_start=q_idx, q_idx_end=q_idx+1, filter_fn=lambda values: values > similarity_thresholds[block_idx] ) similar_strings = [ [strings10[i] for i in indices] for indices in similar_indices ] similar_strings_per_block.append(similar_strings) freq_distribution = frequency_distribution_from_similar_strings( similar_strings_per_block, next_token_map10, ) weights = torch.tensor([0.01, 0.01, 0.1, 1.5, 6, 0.01]).unsqueeze(dim=1).unsqueeze(dim=2) # (n_layer, 1, 1) total_freq_distribution = (freq_distribution * weights).sum(dim=0) prob_distribution = total_freq_distribution / total_freq_distribution.sum(dim=-1, keepdim=True) tokens = encoding_helpers.tokenize_string(prompts[q_idx]) logits, _ = m(tokens) logits = LogitsWrapper(logits.detach(), tokenizer) approx_top_tokens = top_nonzero_tokens(prob_distribution[0], tokenizer.itos) model_top_tokens = logits.topk_tokens(k=10)[0][-1] print_distribution_comparison(approx_top_tokens, model_top_tokens)
Model Predictions Approximation Predictions ----------------- ------------------------- l: 0.999 l: 0.997 e: 0.000 e: 0.002 r: 0.000 r: 0.000
hellinger_distance(prob_distribution, logits.probs()[0][-1])
tensor([0.0233])
Вспомним, что для этого примера, когда мы использовали только схожие строки первого слоя, аппроксимация достаточно сильно отличалась от прогноза модели и имела расстояние Хеллингера >0.63. Теперь она почти идентична и имеет расстояние Хеллингера 0.02. То есть использование остальных слоёв сильно помогло в этом примере.
В следующем разделе мы расширим код, чтобы он вычислял аппроксимацию для всего множества из 20000 промтов.
Охватываем все 20000 промтов
Теперь у нас есть все необходимые детали, чтобы выполнить процедуру аппроксимации для всех 20000 промтов. Сначала давайте найдём строки со схожими результатами сети с прямой связью для всех промтов и всех блоков:
# Выполняется примерно семь минут similarity_thresholds=[0.95, 0.94, 0.85, 0.76, 0.81, 0.89] similar_strings_per_block = [] for block_idx in range(n_layer): similar_indices = filter_on_prefiltered_results( load_prefiltered=lambda q_idx: load_prefiltered_data(block_idx, q_idx), q_idx_start=0, q_idx_end=n_prompts, filter_fn=lambda values: values > similarity_thresholds[block_idx] ) similar_strings = [ [strings10[i] for i in indices] for indices in similar_indices ] similar_strings_per_block.append(similar_strings)
Далее мы вычисляем распределения частот для каждого запроса на основании найденных нами строк, выполняем взвешенное суммирование и нормализацию для расчёта распределения вероятностей.
freq_distribution = frequency_distribution_from_similar_strings( similar_strings_per_block, next_token_map10, ) weights = torch.tensor([0.01, 0.01, 0.1, 1.5, 6, 0.01]).unsqueeze(dim=1).unsqueeze(dim=2) # (n_layer, 1, 1) total_freq_distribution = (freq_distribution * weights).sum(dim=0) prob_distribution = total_freq_distribution / total_freq_distribution.sum(dim=-1, keepdim=True) prob_distribution.shape
torch.Size([20000, 65])
В результате получится тензор вида (20000, 65): одно распределение 65 элементов для каждого из 20000 промтов.
Для сравнения нам нужно будет пропустить все промты через модели и получить выходные распределения вероятностей, прогнозируемые моделью:
tokens = encoding_helpers.tokenize_strings(prompts) logits, _ = m(tokens) logits = LogitsWrapper(logits.detach(), tokenizer) model_probs = logits.probs() model_probs = model_probs[:, -1, :] # Нас интересует только последний токен
Теперь у нас есть результаты работы аппроксимации и модели для всех промтов. В следующей части мы вычислим расстояние Хеллингера между ними и оценим результаты.
