Это перевод статьи Якоба Стейнхардта, где он описывает и обосновывает свои оценки того, как будут выглядеть языковые модели в 2030 году. Статья подводит базу для ещё двух, в которых он описывает возможные при наличии подобных систем катастрофические сценарии. Их переводы тоже скоро будут выложены.
Способность GPT4 программировать, творчески генерировать идеи, писать письма и делать немало чего ещё много кого удивила. В машинном обучении она в этом не одинока: до неё меня, как и многих способных прогнозистов удивили математические способности Minerva.
Как меньше удивляться при появлении новых ИИ‑разработок? Наш мозг часто совершает прогноз нулевого порядка: смотрит на нынешнее положение дел и добавляет усовершенствования, которые «кажутся осмысленными». Но оценка, что именно «кажется осмысленным», подвержена когнитивным искажениям и будет недооценивать прогресс в столь быстро развивающейся области как машинное обучение. Более эффективный подход — прогнозирование первого порядка: численно оценить историческую скорость прогресса и экстраполировать её вперёд, обращая при этом внимание на возможные причины замедления или ускорения.1
В этом посте я использую этот подход для прогнозирования свойств больших предобученных ИИ в 2030 году. Я дальше буду говорить о «GPT2030». Это гипотетическая система, которая обладает способностями, вычислительными ресурсами и скоростью вывода, которые получатся, если экстраполировать большие языковые модели на 2030 год (но эта система скорее всего будет обучена и в других модальностях, таких как изображения). Чтобы предсказать свойства GPT2030, я рассмотрел много источников информации, включая эмпирические законы масштабирования, прогнозы о будущих вычислительных мощностях и будущей доступности данных, скорость улучшения по конкретным метрикам, скорость вывода нынешних систем и возможные будущие улучшения параллелизма.
Способности GPT2030 оказываются удивительными (по крайней мере, для меня). В частности, GPT2030 будет обладать некоторыми значительными преимуществами как над нынешними системами2, так и (по крайней мере, в некоторых важных аспектах), над нынешними работниками‑людьми:
GPT2030 скорее всего будет обладать сверхчеловеческими навыками исполнения многих конкретных задач, включая программирование, взлом, математику, и, возможно, проектирование белков (Раздел 1).
GPT2030 сможет «работать» и «думать» быстро: по моей оценке, она будет в 5 раз [диапазон: 0.5–20] быстрее людей, если измерять по словам, обработанным за минуту3, и это можно будет увеличить до 125 раз, заплатив в 5 раз больше за FLOP (Раздел 2).
GPT2030 будет легко копировать и запускать параллельно. Обучившая GPT2030 организация будет обладать достаточными вычислительными мощностями, чтобы запустить много параллельных копий: по моей оценке, достаточно, чтобы исполнить 1.8 миллионов лет работы [диапазон: 0.4М-10М лет] при пересчёте на человеческую скорость. (Раздел 3). При учёте пятикратного ускорения из предыдущего пункта, эта работа сможет выполниться за 2.4 месяца.
Благодаря идентичным весам копии GPT2030, смогут делиться знаниями, что допускает параллельное обучение: по моей оценке, эквивалентное 2,500 человеческим годам обучения за 1 день (Раздел 4).
Кроме текста и изображений GPT2030 сможет обучаться на дополнительных модальностях, включая, возможно, и контринтуитивные, вроде молекулярных структур, низкоуровневого машинного кода, астрономических снимков и сканов мозга. Так что не исключено, что она будет обладать мощной интуицией и сформирует незнакомые нам концепции в областях, в которых у людей опыт ограничен (Раздел 5).
Такие способности, как минимум, ускорят многие области исследований, и в то же время откроют значительные возможности для злоупотребления (Раздел 6). Программистские способности GPT2030 вкупе с параллелизацией и скоростью сделают её мощным инструментом для кибератак. Вдобавок, параллельное обучение можно будет направить на поведение людей, и использовать для манипуляций и дезинформации с тысячами «лет» практики.
Главным ограничителем ускорения будет автономность. Я ожидаю, что в областях вроде математики, где работу можно проверять автоматически, GPT2030 будет превосходить самых профессиональных математиков. Ещё я ожидаю, что в машинном обучении GPT2030 будет независимо проводить эксперименты и генерировать графики и отчёты, но аспиранты и исследователи будут указывать направление и оценивать результаты. В обоих случаях GPT2030 будет неотъемлемой частью процесса исследований.
Если исходить из того, как выглядят нынешние системы, мои прогнозы свойств GPT2030 кажутся контринтуитивными, и они действительно могут оказаться ошибочными, потому что нель��я быть точно уверенным в том, как машинное обучение будет выглядеть в 2030 году. Однако, пункты (1.-5.) выше — моя медианная оценка, и чем бы ни оказалась GPT2030, я сомневаюсь, что это будет «GPT-4, но немного лучше».
Если я прав, то влияние ИИ уж точно будет немаленьким. Нам надо готовиться к нему сейчас, задаваясь вопросами о том, что произойдёт на самых крупных масштабах (порядка триллионов долларов, десятков миллионов жизней и значимых изменений социальных процессов). Лучше удивляться сейчас, а не через 7 лет, когда эти системы уже будут работать.
1. Конкретные cпособности
Я ожидаю, что GPT2030 будет превосходить людей в программировании, взломе и математике, а также способности читать и обрабатывать большие объёмы текста для поиска закономерностей или фактов и генерации озарений. Наконец, раз AlphaFold и AlphaZero превосходили людей в проектировании белков и играх, GPT2030 тоже будет на это способна, например, если она будет мультимодально обучена на данных, похожих на обучающие данные AlphaFold/AlphaZero.
Программирование. GPT-4 опередила сильные человеческие результаты на задачах с LeetCode, выложенных после отсечки её обучающих данных (Bubeck et al. 2023, таблица 2), и прошла имитацию интервью нескольких больших технических компаний (Рис. 1.5). Скорость улучшений всё ещё высока, между GPT-3 и 4 произошёл скачок в 19%. С более сложным соревнованием CodeForces GPT-4 справилась хуже, но AlphaCode сравнялась с медианным участником‑человеком. На ещё более сложном датасете APPS, Parsel опередил AlphaCode (7.8%→25.5%). Платформа прогнозирования Metaculus даёт 2027 в качестве медианного года достижения 80% на APPS, что превзошло бы почти всех людей.4
Взлом. Я ожидаю, что вместе с навыками программирования в целом будут расти и навыки взлома, и что вдобавок к этому модели смогут просматривать большие базы кода в поисках уязвимостей на куда больших масштабах и с куда большей тщательностью, чем люди. ChatGPT уже использовали для генерации эксплойтов и создания полиморфного вредоносного кода, что обычно считается продвинутой техникой атаки.
Математика. Minerva достигла пятидесятипроцентного результата на бенчмарке соревновательной математики (MATH), что лучше результатов большинства людей. Скорость прогресса велика (больше 30% за год), и низковисящих плодов ещё много: автоформализация, избавление от арифметических ошибок, улучшение техники цепочки мыслей, и улучшение качества данных5. Metaculus предсказывает 92% на MATH к 2025, и выдаёт 2028 как медианный год, когда ИИ выиграет золотую медаль Международной Математической Олимпиады, то есть выйдет на уровень лучших студентов в мире. Я лично ожидаю, что GPT2030 будет лучше самых профессиональных математиков доказывать хорошо сформулированные теоремы.6
Обработка информации. Способность отыскивать нужные факты в больших объёмах данных естественно вытекает из способностей больших языковых моделей к запоминанию и больших контекстных окон. Как выяснилось, GPT-4 достигает 86% точности на MMLU, широком наборе стандартизированных экзаменов, включающем юридический экзамен, MCAT, и экзамены по математике, физике, биохимии и философии уровня колледжа; даже если сделать поправку на вероятное пересечение с обучающими данными, это скорее всего превзойдёт широту эрудиции любого человека. Что касается больших корпусов данных, Чжун и пр. (2023) использовали GPT-3 для конструирования системы, которая открыла и описала несколько ранее неизвестных закономерностей в больших базах текста, и тренды масштабирования на схожих задачах от Биллс и пр. (2023) указывают, что модели скоро превзойдут в этом людей. Обе работы использовали большие контекстные окна LLM, сейчас они превысили 100,000 токенов и растут дальше.
Если обобщить, модели машинного обучения обладают не таким же набором навыков, что люди, потому что обучение на больших массивы данных из интернета, сильно отличается от «обучения» естественным отбором в ходе эволюции. К моменту, когда модели достигнут человеческого уровня в задачах вроде распознавания объектов на видео, они скорее всего уже будут обладать сверхчеловеческими навыками во многих других задачах, таких как математика, программирование и взлом. Более того, из‑за роста моделей и совершенствования данных скорее всего со временем выявятся дополнительные мощные способности, и нет особых причин ожидать, что способности моделей «выйдут на плато» на человеческом уровне или ещё ниже. Хоть и возможно, что нынешние подходы глубинного обучения не дойдут до человеческого уровня в некоторых областях, равно возможно и что они его превзойдут, может быть, превзойдут сильно, особенно в областях вроде математики, для которых люди эволюционно не специализировались.
2. Скорость вывода
(Благодарю Льва МакКинни за результаты по бенчмаркам в этом разделе)
Для оценки скорости моделей машинного обучения мы измеряем, как быстро они генерируют текст, сравнивая с скоростью мышления человека в 380 слов в минуту (Корба (2016), см также Приложение A). Использование API продолжения чата от OpenAI, мы оценили, что в апреле 2023 года gpt-3.5-turbo может генерировать 1200 слов в минуту (wpm), а gpt-4 генерирует 370 wpm. Меньшие модели с открытым кодом вроде pythia-12b достигают как минимум 1350 wpm при привлечении дополнительных инструментов и на A100 GPU. Кажется, что при дальнейшей оптимизации это можно удвоить.
Следовательно, если рассматривать модели от OpenAI по состоянию на апрель, они получаются либо примерно в три раза быстрее людей, либо примерно на том же уровне. Я ожидаю, что модели в будущем будут быстрее, потому что для ускорения вывода есть мощные коммерческие и практические стимулы. И правда, согласно данным отслеживания от Фабиена Роджера, в неделю до выкладывания этого поста скорость GPT-4 уже увеличили до 540 wpm (12 токенов в секунду). Это демонстрирует возможности улучшений и желание этими возможностями пользоваться.
Мой медианный прогноз — что модели будут в пять раз превосходить людей по словам в минуту (диапазон: [0.5, 20]), так как примерно там практические преимущества дальнейшего ускорения пойдёт на спад. Однако, есть соображения и в пользу как более, так и менее высоких чисел, их подробный список, как и сравнение скоростей моделей разных масштабов и подробности упомянутых выше экспериментов можно посмотреть в Приложении A.
Большое значение имеет то, что скорость моделей машинного обучения не фиксирована. Последовательную скорость вывода можно увеличить в k2 раз ценой уменьшения пропускной способности в k раз (иными словами, k3 параллельно работающих копий модели можно заменить на одну в k2 раз более быструю). Этого можно достигнуть при помощи параллельной схемы, теоретически работающей даже для больших значений k2, скорее всего как минимум до 100, а может и больше. Так что модель, в пять раз превышающую по скорости человека, можно ускорить до 125-кратного превосходства при k=5.
Важная оговорка — скорость не обязательно сопровождается качеством: как описано в Разделе 1, набор навыков GPT2030 будет отличаться от человеческого, она будет проваливаться на некоторых задачах, которые мы считаем простыми и в совершенстве исполнять некоторые, которые мы считаем сложными. Так что нам не надо думать о GPT2030, как о «ускоренном человеке», но, скорее, как о «ускоренном работнике» с потенциально контринтуитивным набором навыков.
Несмотря на это, ускорение рассматривать полезно, особенно когда оно большое. Языковые модели, опережающие по скорости людей в 125 раз, будут выполнять входящие в их набор навыков когнитивные задачи, которые заняли бы у человека целый день, за считанные минуты. Если опять взять пример взлома — системы машинного обучения смогут быстро находить эксплойты и проводить атаки, отнявшие бы у человека много времени.
3. Пропускная способность и параллельные копии
Копирование моделей ограничено только доступными вычислительными мощностями и памятью. Это позволяет им быстро выполнять любую работу, которую можно эффективно распараллелить. К тому же, особенно эффективно донастроив одну модель, можно сразу же перенести изменение на другие экземпляры. Ещё модели можно дистиллировать под конкретные задачи, что ускорит и удешевит их использование.
Скорее всего, после обучения модели будет доступно достаточно ресурсов, чтобы запустить много её копий, потому что обучение модели требует запуска многих параллельных копий, и какая бы организация её не обучила, вероятно, те же ресурсы будут ей доступны и при развёртывании. Следовательно, мы можем получить нижнюю границу числа копий, оценив затраты на обучение.
Пример такого расчёта — затраты на обучение GPT-3 были бы достаточны для 9×1011 её же запусков. Приводя к человеческому эквиваленту, люди думают со скоростью в 380 слов в минуту (см. Приложение A), а одно слово — это в среднем 1.33 токена, так что 9×1011 запусков соответствуют ~3400 годам работы с человеческой скоростью. Следовательно, организация может запускать 3400 параллельных копий модели на целый год на человеческой скорости работы, или то же число копий на 2.4 месяца с пятикратной скоростью. (Примечание: последнее зависит от того, сколько экземпляров модели организация может запустить параллельно, см. сноску7 за подробностями.)
Давайте теперь экстраполируем, насколько обучение «забегает вперёд», то есть, соотношение стоимостей обучения и запуска, на будущие модели. Оно должно вырасти: в основном потому, что оно примерно пропорционально размеру датасета, а они растут. Этот тренд замедлится, когда мы исчерпаем запасы естественных языковых данных, но новые модальности и синтезированные/самосгенерированные данные не позволят ему остановиться.8 В Приложении B я рассмотрел эти факторы подробно, чтобы экстраполировать их на 2030 год. Я ожидаю, что вычислительные ресурсы, затраченные на обучение модели в 2030 году, будут примерно равны ресурсам, необходимым на исполнение той же моделью, при пересчёте на человеческую скорость, 1,800,000 лет работы [диапазон: 400K-10M].
Отмечу, что Котра (2020) и Дэвидсон (2023) оценивали схожие параметры и пришли к бОльшим числам, чем у меня. Я полагаю, основное различие — то, как я моделирую эффект исчерпания данных на естественном языке.
Экстраполяция выше несколько консервативна, потому что модель можно запустить и с привлечением больших ресурсов, чем использовалось при обучении, если организация докупит дополнительные мощности. Быстрая оценка выдаёт, что GPT-4 обучили, используя примерно 0.01% от всех вычислительных ресурсов мира. Впрочем, я ожидаю, что будущие процессы обучения будут использовать бОльшую долю мировых вычислительных мощностей, так что у них будет меньше возможностей для дальнейшего масштабирования. Всё равно организация, если у неё будет хороший повод это сделать, сможет увеличить число копий ещё на порядок.
4. Разделение знаний
(Спасибо Джеффу Хинтону, который первый высказал мне этот аргумент.)
Разные копии модели могут делиться обновлениями параметров. К примеру, ChatGPT может взаимодействовать с миллионами пользователей, узнавать что‑то новое из каждого взаимодействия, и скидывать градиентные сдвиги на центральный сервер, где их усреднят и применят ко всем копиям модели. Таким образом ChatGPT может получить больше информации о людях за час, чем человек за всю жизнь (1 миллион часов = 114 лет). Параллельное обучение может быть одним из главных преимуществ моделей, потому что оно позволит им быстро обучаться любым упущенным навыкам.
Скорость параллельного обучения зависит от того, сколько копий модели запущены разом, как быстро они могут получать данные, и можно ли эти данные эффективно использовать параллельно. Наконец, даже очень мощная параллелизация не должна особо вредить эффективности, ведь на практике нередки многомиллионные размеры датасетов, а масштабирование градиентного шума (МакКэндлиш и пр., 2018) предсказывает минимальное снижение качества обучения до достижения «критического размера батчей». Так что мы сосредоточимся на числе копий и получении данных.
Я приведу две оценки, и из обеих получается, что вполне достижимо будет параллельно обучать с человеческой скоростью по меньшей мере ~1 миллион копий модели. Это соответствует 2500 человеческим годам обучения за день, потому что 1 миллион дней — это примерно 2500 лет.
Первая оценка использует числа из Раздела 3, в котором получился вывод, что затрат на обучение модели достаточно для симуляции этой же модели на протяжении 1.8 миллиона лет работы (приводя к человеческой скорости). Предполагая, что обучение продолжалось менее, чем 1.2 года (Севилла и пр., 2022), получим, что организация, обучившая модель, будет обладать достаточными GPU, чтобы запустить 1.5 миллиона копий на человеческой скорости.
Вторая оценка берётся из рассмотрения доли рынка организации, развернувшей модель. К примеру, если 1 миллион пользователей одновременно дают запросы модели, организации уж точно надо обладать ресурсами на обслуживание 1 миллиона копий модели. Для примера, у ChatGPT в мае 2023 года было 100 миллионов пользователей (не все активны одновременно), а в январе — 13 миллионов активных пользователей в день. Я предположу, что типичный пользователь запрашивал генерацию текста, занимающую несколько минут, так что январское число скорее всего сводится к всего лишь 0.05 миллиона человеко‑дней текста каждый день. Однако, кажется весьма правдоподобным, что будущие модели в духе ChatGPT обойдут это раз в двадцать и достигнут 250 миллионов активных пользователей и 1 миллиона человеко‑дней генерации в день. Для сравнения — у Facebook сейчас 2 миллиарда активных пользователей каждый день.
5. Модальности, инструменты и физические устройства
До сих пор схожие с GPT модели в основном обучались на тексте и программном коде и обладали сильно ограниченными методами взаимодействия с окружающим миром — через чат. Но это быстро меняется, модели обучаются на дополнительных модальностях вроде изображений, обучаются использовать инструменты и взаимодействовать с физическими устройствами. Более того, модели не будут ограничены доступными людям модальностями вроде текста, естественных изображений, видео и речи — скорее всего их будут обучать и на незнакомых нам модальностях вроде сетевого трафика, астрономических снимков и иных больших объёмов данных.
Инструменты. Недавно выпущенные модели используют внешние инструменты, см. плагины ChatGPT, а также Шик и пр. (2023), Яо и пр. (2022) и Гао и пр. (2022). В комплекте с использованием инструментов, генерации текста становится достаточно, чтобы писать код, который будет исполняться, убеждать людей совершать действия, взаимодействовать с API, совершать транзакции и, потенциально, проводить кибератаки. Использование инструментов экономически выгодно, так что для дальнейшего его развития есть сильные стимулы.
ChatGPT реактивна — пользователь говорит X, ChatGPT отвечает Y. Риски есть, но ограничены. Скоро будет большое искушение создавать проактивные системы — помощник, который отвечает за вас на e‑mail»ы, сам совершает действия для вашей выгоды, и т. д. Риски будут куда выше.
— Percy Liang (@percyliang) February 27, 2023
Новые модальности. Сейчас уже есть большие обученные на тексте и изображениях модели, как коммерческие (GPT-4, Flamingo), так и с открытым исходным кодом (OpenFlamingo). Исследователи экспериментируют и с более экзотическими парами модальностей, например, язык и строение белков (Гуо и пр., 2023).
Стоит ожидать, что модальности больших предобученных моделей будут расширяться. На то есть две причины. Во‑первых, экономически полезно добавлять к менее знакомым модальностям (таким как белки) язык, чтобы пользователи могли получать объяснения и эффективно править результаты. Так можно спрогнозировать мультимодальное обучение с строением белков, биомедицинскими данными, моделями CAD, и любыми другими модальностями, ассоциированными с большим сектором экономики.
Во‑вторых, языковые данные начинают заканчиваться, так что разработчики моделей будут искать новые типы данных, чтобы продолжать наращивать масштабы. Кроме традиционных текста и видео, некоторые из крупнейших источников существующих данных — это астрономические (скоро будут измеряться экзабайтами в день) и геномные (около 0.1 экзабайта в день). Правдоподобно, что как эти, так и другие крупные источники данных будут использоваться для обучения GPT2030.
Применение экзотических модальностей означает, что у GPT2030 могут быть контринтуитивные способности. Она может понимать звёзды и гены куда лучше нас, с трудом при этом справляясь с базовыми физическими задачами. Это может привести к нарушению ожиданий, основанных на уровне «обобщённого» интеллекта GPT2030, например, к проектированию новых белков. Важно учитывать, что благодаря экзотическим источникам данных она вполне может обладать подобными специфическими сверхчеловеческими способностями.
Актуаторы. Модели начинают использовать физические актуаторы: ChatGPT уже использовали для управления роботами, а OpenAI инвестирует в робототехническую компанию. Однако, в физических областях куда дороже собирать данные, чем в цифровых, да и люди к ним эволюционно приспособлены лучше (так что планка для конкуренции с нами для ML‑моделей будет выше). Так что я ожидаю, что в сравнении с цифровыми областями овладевание актуаторами будет происходить медленнее, и я не уверен, стоит ли этого ожидать к 2030. Я оцениваю в 40% вероятность, что к 2030 будет модель общего назначения, способная сама собрать реплику Ferrari в натуральную величину, как сформулировано в этом вопросе на Metaculus.
6. Значимость GPT-2030
Давайте проанализируем, что система вроде GPT2030 будет значить для общества. Система с характеристиками GPT2030 как минимум значительно бы ускорила некоторые области исследований, одновременно обладая немалым потенциалом злонамеренного использования.
Я начну с перечисления некоторых основных сильных и слабых сторон GPT2030, и посмотрю, что они значат для ускорения и для злонамеренного использования.
Сильные стороны. GPT2030 — это многочисленная, быстро адаптируемая и высокопродуктивная рабочая сила. Напомню, что копии GPT2030 смогут выполнить 1.8 миллиона лет работы9, и каждая копия будет работать в 5 раз быстрее человека. Это означает, что мы сможем симулировать 1.8 миллиона агентов, работающих по год каждый, за 2.4 месяца. Как описано выше, мы также сможем заплатить впятеро больше за FLOP, чтобы получить дополнительное ускорение — до 125-кратной человеческой скорости. Получается 14 тысяч агентов, работающих по году каждый за 3 дня10.
Слабые стороны и ограничения. Есть три препятствия к использованию этой цифровой рабочей силы — набор навыков, стоимость экспериментов и автономность. По первому — GPT2030 будет обладать не таким набором навыков, что люди, так что она будет хуже справляться с некоторыми задачами (но лучше с другими). По второму — симулированным рабочим надо взаимодействовать с миром для сбора данных, и у этого будут свои затраты времени и вычислительных мощностей. Наконец, по автономности — сейчас модели могут сгенерировать лишь несколько тысяч токенов цепочки мыслей, прежде чем «застрянут» в состоянии, в котором больше не могут выдавать высококачественный вывод. Нам потребуется значительное повышение надёжности, чтобы мы смогли поручать моделям сложные задачи. Я ожидаю, что надёжность будет расти, но не безгранично: моя (очень грубая) оценка такова, что GPT2030 сможет работать несколько человеко‑эквивалентных дней, прежде чем её надо будет перезапустить или перенаправить внешней обратной связью. Если модели будут работать в пять раз быстрее людей, получается, что присматривать за ними надо будет раз в несколько часов.
Получается, задачи, в которых влияние GPT2030 будет наивысшим, это те, которые:
Используют навыки, в которых GPT2030 сильнее людей.
Требуют только таких внешних эмпирических данных, которые можно легко и быстро собрать (дорогие физические эксперименты, например, не подходят).
Могут быть разделены на подзадачи, с которыми модель справляется стабильно и надёжно, или для которых есть хорошие и автоматизированные механизмы обратной связи для направления модели.
Ускорение. Одна хорошо соответствующая этим критериям задача — математические исследования. По первому — у GPT2030 скорее всего будут сверхчеловеческие математические способности (см. Раздел 1). По второму и третьему — математикой можно заниматься исключительно думая и записывая, а узнать, когда теорема доказана, легко. Кроме того, в мире не так много математиков (например, в США всего около 3000), так что GPT2030 сможет симулировать десятикратный годовой выхлоп математиков за несколько дней.
Значительная часть исследований ML тоже удовлетворяет этим критериям. GPT2030 будет сверхчеловеческим программистом, что включает в себя составление и проведение экспериментов. Думаю, она будет хороша и в презентации и объяснении их результатов, учитывая, что GPT-4 уже хороша в доступном объяснении сложных тем (и у этого навыка немалый рыночный запрос). Исследование ML можно свести к придумыванию хороших экспериментов и получению хорошо оформленных (но потенциально ненадёжных) описаний результатов. Таким образом, в 2030 аспиранты смогут пользоваться ресурсами, которые сейчас доступны профессору с несколькими сильными студентами.
Значительному ускорению подвергнутся и некоторые социальные науки. Есть много статей, которые в основном описывают поиск, категоризацию и разметку интересных с научной точки зрения источников данных и выявление значимых паттернов — за примерами см. Асемоглу и пр. (2001) или Вебб (2020). Это соответствует критерию (3), потому что категоризация и разметка декомпозируются на простые подзадачи, и критерию (2), пока данные доступны в Интернете или могут быть собраны онлайн‑опросом.
Злоупотребление. Кроме ускорения, возникнут и серьёзные риски злоупотребления. Самый прямой путь — способности к взлому. Изучить конкретную цель в поисках уязвимостей конкретного вида просто, проверить (при возможности взаимодействовать с кодом), работает ли эксплойт — тоже, так что критерий (3.) выполняется вдвойне. По (2.), GPT2030 придётся взаимодействовать с целевыми системами, чтобы знать, работает ли эксплойт, что может быть затратно, но не настолько, чтобы значительно помешать. Более того, модель может локально проектировать и тестировать эксплойты, используя как обучающие данные открытый код, так что она может стать очень хороша в взломе без необходимости взаимодействовать с внешними системами. Так что GPT2030 сможет быстро исполнять сложные кибератаки параллельно против большого количества целей.
Второй тип злоупотреблений — манипуляция. Если GPT2030 будет взаимодействовать с миллионами пользователей за раз, то за час она будет получать больше информации о взаимодействиях с людьми, чем человек получает за всю жизнь (1 миллион часов = 114 лет). Если использовать это для обучения манипуляции, то итоговые навыки могут сильно превосходить человеческий уровень — для сравнения, некоторые мошенники хорошо обманывают своих жертв, потому что практиковались на сотнях людей, а GPT2030 сможет обойти это на несколько порядков. Так что она сможет очень хорошо манипулировать пользователями в разговорах один на один и в написании статей для сдвига общественного мнения.
Подводя итоги, GPT2030 сможет автоматизировать практически все математические исследования и значимую часть других областей, и она откроет мощные пути злоупотребления, как через кибератаки, так и через убеждение/манипуляцию. Большая часть её воздействия на мир будет ограничиваться «бутылочным горлышком присмотра», так что оно усилится, если она сможет долго автономно работать.
Выражаю благодарность Louise Verkin за переделывание этого поста в формат Ghost, и Lev McKinney за проведение эмпирических экспериментов с бенчмарками. Благодарю Karena Cai, Michael Webb, Leo Aschenbrenner, Anca Dragan, Roger Grosse, Lev McKinney, Ruiqi Zhong, Sam Bowman, Tatsunori Hashimoto, Percy Liang, Tom Davidson, и других за обратную связь к черновикам этого поста.
Приложение: Оценки скорости работы и обучения будущих моделей
A. Слова в минуту
Для начала мы оценим, сколько слов в минуту выдают люди и современные модели, а затем — экстраполируем с современных моделей на будущие.
Что касается людей, есть пять чисел, которые можно измерять: скорость речи, чтения, восприятия на слух, а также «эллипсическая» и «расширенная» скорость мысли. По первым трём Рэйнер и Клифтон (2009) утверждают, что скорость чтения — 300 слов в минуту,11 скорость речи — 160 слов в минуту12, а восприятие речи возможно в два‑три раза быстрее (то есть, ~400 слов в минуту)13. Скорость мысли нам надо разделять на «эллипсическую» и «расширенную» — оказывается, мы думаем своего рода вспышками слов, а не целыми фразами, и если расширить эти вспышки до полных предложений, то получится совсем другое число слов (отличие примерно в 10 раз). Корба (2016) выяснил, что эллипсическая мысль работает со скоростью примерно в 380 слов в минуту, а расширенная — ~4200 слов в минуту. Так как большая часть этих чисел находятся где‑то в области 300–400 слов в минуту, я буду использовать 380 слов в минуту как свою оценку скорости мышления человека. Если взять предлагаемое OpenAI соотношение 3 слова: 4 токена, то получается 500 токенов в минуту.14
(Благодарю Льва МакКинни за проведение оценок из следующих абзацев.) Далее рассмотрим современные модели. Мы исследовали gpt-3.5-turbo, gpt-4, и несколько моделей с открытым исходным кодом от EleutherAI, чтобы оценить их скорость вывода. Мы просили их считать от 1 до n, а n изменяли от 100 до 1900 включительно шагами по 100. Так как числа содержат больше одного токена, мы прерывали выполнение, когда модель генерировала n токенов, и измеряли прошедшее время. Затем мы провели линейную регрессию с учётом временного лага, чтобы оценить асимптотическую скорость в токенах в секунду.
GPT-4 и GPT-3.5-turbo использовались при помощи OpenAI API в начале апреля 2023 года. Все эксперименты с моделями pythia проводились при помощи технологии «deepspeed»s injected kernels» и моделей fp16 на одной видеокарте A100 GPU.15 Код для воспроизведения этих результатов можно найти https://github.com/levmckinney/llm‑racing.
Ниже показаны сырые данные на Рисунке 1, и конечные оценки токенов в минуту — на Рисунке 2 и в Таблице 1.
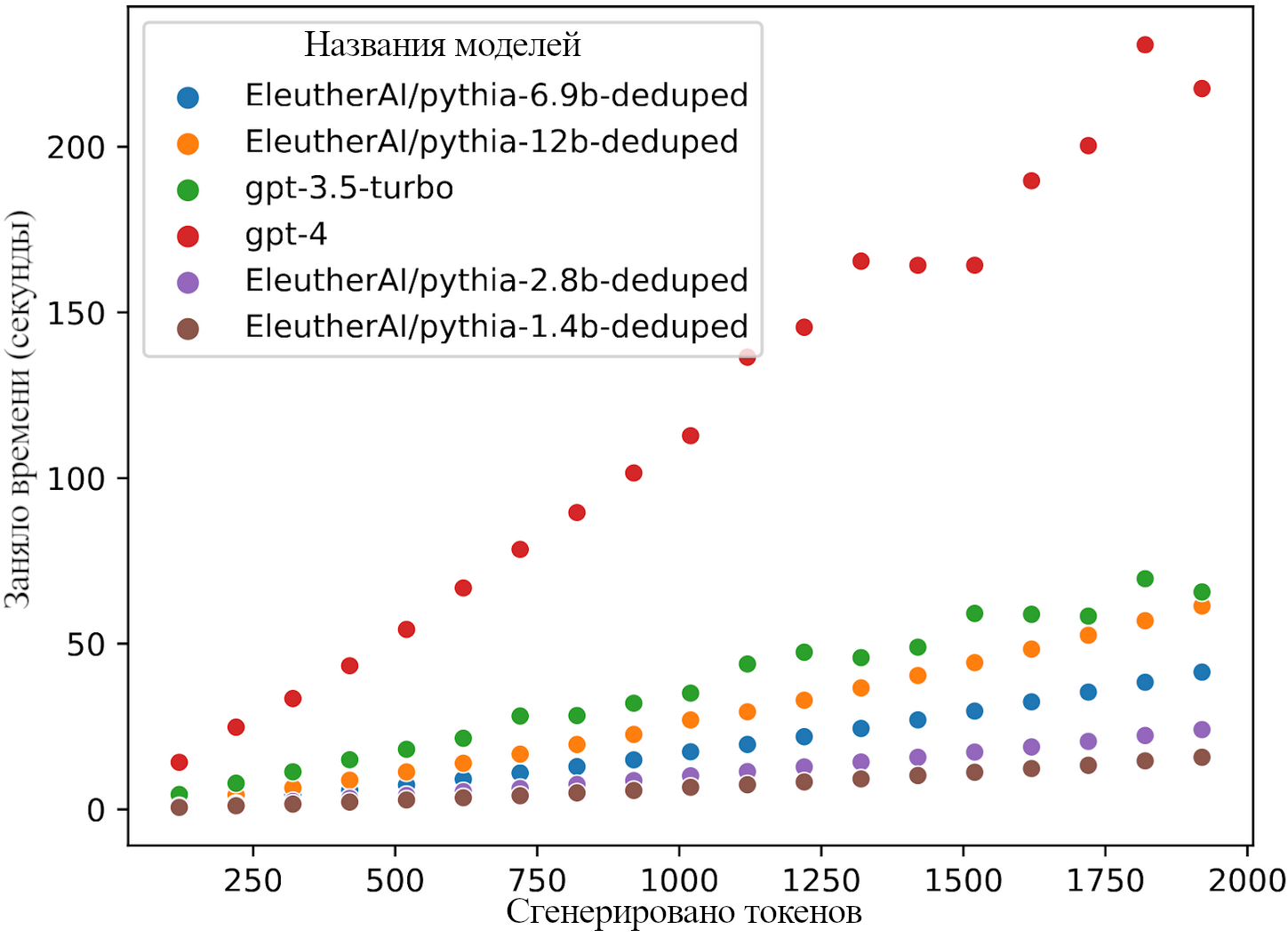
На Рисунке 1 показано, как время вывода модели масштабируется при изменении ввода. Обратите внимание, что время на токен на этих масштабах остаётся приблизительно постоянным.

На Рисунке 2 и в таблице снизу показано, как скорость вывода модели меняется в зависимости от её размера. Полосы ошибок — интервалы уверенности в 95%.
Название модели | Токены в минуту |
gpt-4 | 493 |
gpt-3.5-turbo | 1641 |
EleutherAI/pythia-12b‑deduped | 1801 |
EleutherAI/pythia-6.9b‑deduped | 2659 |
EleutherAI/pythia-2.8b‑deduped | 4568 |
EleutherAI/pythia-1.4b‑deduped | 7040 |
EleutherAI/pythia-410m‑deduped | 11 039 |
EleutherAI/pythia-160m‑deduped | 21 580 |
EleutherAI/pythia-70m‑deduped | 31 809 |
Таким образом, GPT-4 близка к человеческому значению в 500 токенов в минуту, тогда как GPT-3.5-turbo примерно в три раза быстрее. Меньшие модели быстрее ещё на порядок, что указывает и на возможность ещё больших скоростей, и на то, что будущие модели большего размера могут быть медленнее (без учёта лучшего железа и оптимизаций). На практике при росте размера модели скорость замедляется сублинейно — в моделях pythia увеличение размера в k раз уменьшает скорость вывода примерно в k0.6 раз. Как число слов в минуту изменится для будущих моделей?
Есть факторы, толкающие как в сторону ускорения, так и в сторону замедления:
Запускать большие модели дороже, особенно если у них больше слоёв (большую ширину можно скомпенсировать параллелизацией, но большую глубину — нет).
Вывод будет в целом оптимизироваться сильнее, например, ранним выходом, редким вниманием, параллелизацией на многих GPU. или лучшим железом. Тут, особенно касательно последних двух, много пространства для манёвра (см. обсуждение ниже).
Будет сильный стимул делать модели достаточно быстрыми, чтобы их было легко использовать (т. е., быстрее, чем человеческая скорость чтения).
После того, как я больше десяти часов разглядывал кучу данных о размерах моделей, архитектуре GPU, и пр., я в целом пришёл к выводу, что я совершенно не уверен, как будут соотноситься противостоящие тренды роста и оптимизации моделей. Моя медианная оценка — что у нас будут модели, заметно более быстрые, чем люди (в 5 раз), но меня не удивит любой результат от «в 2 раза медленнее» до «в 20 раз быстрее».
Немаловажно, что эти скорости применимы только если нам нужна максимальная пропускная способность GPU. Если бы готовы ею пожертвовать, то, уменьшив её в k раз, мы можем ускорить вывод в k^2 раз для довольно больших значений k. Так что если модели по умолчанию всего в 5 раз быстрее людей, то их можно сделать в 125 раз быстр��е людей взамен на пятикратное снижение пропускной способности, и это не предел.
Наконец, отходя от сырой скорости, слова в минуту — не вполне равное сравнение людей и языковых моделей. Для начала, языковые модели не просто думают, а пишут, и, в некоторых случаях, пишут что‑нибудь, что человек писал бы куда медленнее (например, код или аргументы с ссылками на источники). С другой стороны, языковые модели сейчас довольно многословны, так что одно слово от модели менее значимо, чем одно слово от человека. От этой многословности можно отучить файн‑тюнингом, но неочевидно, возможно ли дойти до эффективности эллипсических человеческих мыслей. Наконец, токенизация и сложность слов меняются со временем, так что соотношение между токенами и словами в 1.333 не будет оставаться константным (я, на самом деле, думаю, что оно уже недооценено, потому что нынешние модели склонны использовать сложные слова с префиксами и суффиксами).
Больше по поводу параллелизации и ускорения «железа». Как описано в «Насколко быстрым можно сделать проход вперёд?», есть схемы параллельного тайлинга, значительно ускоряющие скорость последовательного вывода с лишь минимальной стоимостью. Применительно к GPT-3 это ускорило бы её как минимум в 30 раз при использовании кластера A100 в сравнении с одной машиной с восемью GPU16. Эти оптимизации сейчас не очень широко используют, потому что они бесполезны при обучении и немного уменьшают пропускную способность, но их будут использовать, если время вывода станет критичным.
Что касается «железа», GPU становятся мощнее, что ускорит вывод. Но GPU создают с всё расчётом на всё большее соотношение операций к памяти, что снизит возможный эффект параллельного тайлинга. Ниже приведены характеристики GPU от NVIDIA. В столбце «Mem Bandwidth» указана последовательная пропускная способность без параллелизации по нескольким GPU17, а в последнем столбце M3/С2 — при максимальном распараллеливании с подходящим соотношением18. Первая явно растёт, а вот вторая неравномерно, но скорее снижается.
Дата | GPU | Compute | Memory | Clock Speed | Mem Bandwidth | Interconnect | Network | M3/C2 |
Май 2016 | P100 | ~84TF | 16GB | 1.45GHz | 720GB/s | 160GB/s | 53M | |
Декабрь 2017 | V100 16GB | 125TF | 16GB | 1.49GHz | 900GB/s | 300GB/s | ~25GB/s | 47M |
Март 2018 | V100 32GB | 125TF | 32GB | 1.49GHz | 900GB/s | 300GB/s | ~100GB/s | 47M |
Май 2020 | A100 40GB | 312TF | 40GB | 1.38GHz | 1555GB/s | 600GB/s | ~400GB/s | 39M |
Ноябрь 2020 | A100 80GB | 312TF | 80GB | 1.38GHz | 2039GB/s | 600GB/s | ~400GB/s | 87M |
~Август 2022 | H100 | 2000TF | 80GB | 1.74GHz | 3072GB/s | 900GB/s | 900GB/s? | 7.2M |
B. Обгон обучения
Когда модель обучили, скорее всего можно будет сразу же запустить много её копий. На обучение GPT-3 потребовалось 3.1e23 FLOP, а на один прямой прогон — 3.5e11 FLOP, так что за стоимость обучения можно было совершить 9e11 прогонов. При конверсии в 500 токенов в минуту из Приложения A получаем ~3400 человеческих лет работы.
Как это изменится в будущем? Для своей оценки я сначала использую законы масштабирования Chinchilla и экстраполяции будущих затрат на обучение, а потом смотрю на то, как мы можем от этого отклониться. Для будущих затрат на обучение возьмём оценку из Безироглу и пр. (2022). Они проанализировали больше 500 существующих моделей, чтобы экстраполировать тренды вычислительной мощности машинного обучения. Центральный прогноз FLOP на обучение в 2030 году — 4.7e28, а диапазон — от 5.1e26 до 3.0e30. Metaculus выдаёт схожую оценку в 2.3e27 (для 1 января 2031 года)19. Взяв геометрическую медиану получаем 1.0e28 как оценку FLOP на обучение. Это в 33 тысячи раз больше, чем у GPT-3. Законы масштабирования Chinchilla подразумевают, что размер модели (а значит и затраты на вывод) масштабируется как корень из затрат на обучение. Получается, что обгон обучения увеличится примерно в 180 раз. Это превратит 3400 человеческих лет в 620 000. Но есть и ещё одно соображение: GPT-3 обучали не оптимально. Идеальный размер GPT-3 (исходя из затрат на обучение) был бы в 4 раза меньше. Так получаем целых 2.5 миллиона человеческих лет или, если учесть неуверенность в числе FLOP на обучение, диапазон от 0.8 до 9 миллионов20.
Теперь давайте рассмотрим отклонения от законов масштабирования Chinchilla. Самое очевидное — у нас могут закончиться данные. Последствия могут быть разными. Во‑первых, это может привести к тому, что будет отдаваться предпочтение увеличению размера моделей, а не количества данных. Это уменьшило бы обгон обучения. Во‑вторых, могут начать использовать дополнительные синтетические данные. Это сделало бы создание данных более вычислительно затратным и увеличило бы обгон обучения. Третий вариант — можно перейти к новым богатым данными модальностям вроде видео. Тут эффект на обгон обучения неясен, наверное, всё же, он увеличился бы. Проставим грубые границы этих эффектов:
Нижняя граница: Виллалобос и пр. (2022) оценивают, что в 2026 году у нас закончатся высококачественные языковые данные (т. е. Википедия, книги, научные статьи и подобное), а низкокачественных (т. е. веб‑страниц) хватит ещё до 2030 года. В пессимистичном мире, где высококачественные данные — жёсткое ограничение, их модель означает восьмикратное увеличение размеров датасетов к 2030 году и, соответственно, увеличение обгона обучения всего в 8 раз, а не в 180.
Верхняя граница: Если у нас закончатся данные, мы сможем синтезировать новые. Одна из возможностей — дистилляция цепочек‑мыслей, как у Хуанга и пр. (2022). В этой статье для каждого ввода генерировались 32 цепочки, только некоторые из которых использовались для обучения. Предположим, что в среднем будет использоваться 5 из 32, а затраты на обратный прогон такие же, как на прямой. Тогда стоимость обновления обучения эквивалента 2 + 32/5 = 8.4 прямых прогонов, это увеличение в 2.8 раз относительно 3 прямых прогонов раньше. При законах Chinchilla это выдаёт дополнительно обгона обучения в sqrt(2.8) = 1.7 раз, то есть получается не в 180 раз, а 300.
В целом, нижняя граница кажется мне довольно пессимистичной, уж точно будут какие‑то способы использовать низкокачественные или синтетические данные. С другой стороны, помимо того, что могут закончится данные, мы можем ещё и найти способы сделать процесс обучения эффективнее. С учётом этого, моя личная догадка — что‑то между двенадцатикратного и двухсоткратного увеличения обгона, с центральной оценкой в 100 раз. Получается примерно 1.8 миллиона человеческих лет мышления. Хочется ещё расширить диапазон из‑за дополнительной неуверенности по поводу отклонений от законов Chinchilla. Интуитивно я получаю от 0.4 до 10 миллионов лет.
Все эти оценки — для 2030. В целом, они должны быть больше для более следующих лет и меньше для предыдущих.
Дополнительная опора для сравнения: Карнофски (2022) (следуя за Котрой, 2020 оценивает, что затрат на обучение модели человеческого уровня хватило бы на запуск 100 миллионов копий модели на год каждая. Впрочем, он использует оценку в 1e30, а не 1e28 FLOP на обучение. Даже так, это мне кажется слишком уж большим числом, и я склоняюсь к 1.8, а не 100 миллионам.
Хотя на самом деле прогнозирование нулевого порядка, если его делать правильно, часто тоже помогает! Многие, кого удивила ChatGPT, были бы впечатлены и text‑davinci-003, которая была выпущена куда раньше, но не имела удобного интерфейса. ↩
Конкретное сравнение: у GPT-3 было вычислительных мощностей на 3400 лет работы и, полагаю, на менее чем 100 лет обучения с человеческой скоростью за день. Я бы предположил, что у GPT-4 это уже 130,000 и 125 лет соответственно. Так что у GPT2030 будет ещё как минимум на порядок больше и там, и там. ↩
Тут и далее диапазоны в скобках соответствуют 25-у и 75-у перцентилю моего распределения вероятностей. На практике, они, наверное, узковаты, потому что я делал только прогноз по основному сценарию, не учитывая «прочих» вариантов. ↩
Что касается качества вывода GPT-4, Бубек и пр. также обнаружили, что она может выдать код трёхмерной игры на 400 строк без примеров, что, вероятно, невозможно для почти всех людей. ↩
См. Прогнозирование ML‑бенчмарков в 2023 за более подробным обсуждением. ↩
Конкретно, я присваиваю 50% вероятность следующему: «Если мы возьмём 5 случайно выбранных условий теорем из Electronic Journal of Combinatorics, и выдадим их математикам из UCSD, GPT2030 решит большую долю задач, и потратит на решённые меньше времени, чем медианный математик». ↩
Я предполагаю, что изначальное обучение продолжалось меньше года (Севилла и пр., 2022, так что организация можем распараллелить процесс как минимум настолько, чтобы обсчитать 9×1011 прямых проходов за год, учитывая ограничения на скорость вывода. Чтобы сделать это за 2.4 месяца, им могут понадобиться дальнейшие улучшения. Я думаю, это правдоподобно (но не факт), как потому, что модель могла быть обучена и быстрее, чем за год, так и потому, что некоторые оптимизации могут быть доступны только при выводе, но не при обучении. ↩
Второй фактор — что GPT-3 обучали субоптимально, и при оптимальном (в духе Chinchilla) масштабировании это будет уже в четыре раза больше. ↩
Приводя к человеческой скорости работы. ↩
Расчёт такой: при идеальном ускорении, 1.8 миллиона / 25 = 72 000, но в 5 раз большие затраты на FLOP превращают это в 14 000. ↩
«скорость чтения много читающих людей типично составляет 250–350 слов в минуту» ↩
«оценки нормальной скорости речи варьируются от 120 до 200 слов в минуту» ↩
«Эксперименты по сжатой речи показывают, что успешного понимания можно добиться на скорости вдвое больше нормальной (напр., Дюпру и Грин, 1997)» ↩
Я лично думаю, что 4:3 — это слишком оптимистично. 3:2 или даже 2:1 может быть реалистичнее, но я оставлю тут 4:3, потому что самое подходящее найденное мной упоминание было с такими цифрами. ↩
Модели pythia скорее всего могут работать и получше. Например, NVIDIA сообщали о 80 токенах в секунду для модели, сравнимой с pythia — 6.9 миллиардов на одном A100. При использовании большего количества «железа» они показывали даже около 90 токенов в секунду. Для этого применялась архитектура SuperPod с распараллеливанием тензорных вычислений на 8 A100 и модель GPT с 20 миллиардами параметров. ↩
Один A100 справляется с умножениями таких маленьких матриц, как 1024×1024, без того, чтобы узким местом стал доступ к памяти. Основная операция в GPT-3 — перемножение матриц 12 288 x (4*12 288). Значит, мы могли бы произвести тайлинг по 576 GPU (72 машины). Наивно можно предположить ускорение в 72 раза, но скорее всего умножения будут достаточно несинхронны, так что я предположу что‑то ближе к ускорению в 30 раз. ↩
Грубо говоря, без тайлинга по многим GPU, скорость последовательного вывода определяется пропускной способностью памяти, то есть A100 с 2039GB/s должен быть способен на 2039/175 — примерно 12 прямых прогонов модели с 175 миллиардами параметров за секунду (с точностью до константы). ↩
С тайлингом число прямых прогонов за секунду пропорционально M3/54C2L, где C — число FLOPS, M — пропускная способность памяти, а L — число слоёв. (см. здесь за подробностями). Последний столбец даёт M3/C2. ↩
Metaculus оценивает, что у самой большлй обученной модели (на 1 января 2030) будет 2.5e15 параметров. Тогда прямой прогон будет стоить 5e15 FLOP. Если мы наивно поделим, то опять получим 9e11 прогонов. Но я думаю, это неправильно, потому что самая большая модель будет скорее всего не самой передовой, а чем‑то вроде BaGuaLu с 174 триллионами параметров. ↩
Я основываюсь на интерквартильном интервале от Metaculus (от 5 до 660) миллионов и беру корень, чтобы получить степень неуверенности. ↩
