«Регулярные выражения» или «Просто о некрасивом»
Начну с объяснения, что именно меня подвигло на написание этой статьи. Подвигла меня статья о регулярных выражениях которая публиковалась чуть раньше, кто читает хабру, уже наверняка ее видели, статья честно сказать не понравилась, потому как написать ее написали, но привели какой-то сложный пример в качестве использования и предложение купить книгу в 600+ страниц, что как мне кажется только отпугнет людей, которые могли бы ими воспользоваться.
Я специально не буду заглядывать ни в какие мануалы, и пичкать Вас информацией которую я сам не запомнил, уверен, для того чтобы заинтересоваться и начать пользоваться будет достаточно того, что умею и использую сам.
Все примеры я буду приводить используя «grep» который есть и для Windows и для linux ( для него он конечно роднее).
Сам я сижу под linux, поэтому примеры буду показывать используя собственно linux, в некоторых случаях я буду использовать "|" («pipe»), команда перенаправления вывода, но при желании без него можно обойтись используя временный файл результат. Синтаксис регулярных выражений я буду использовать стандартный поэтому, он должен работать везде где полноценно поддерживаются регулярные выражения.
Обращаюсь к тем, кто не знает ничего о grep. Вас не должно смущать, то, что я использую не знакомый вам инструмент, он используется только в качестве примера, регулярные выражения имеют стандартизированный синтаксис который поддерживается многими текстовыми редакторами.
Для затравки. Вам никогда не приходилось писать короткие парсеры, если нужно выбрать некоторые слова или фразы из файла, когда обыкновенный поиск уже не работает?..
1. Допустим мы имеем некоторый текстовый файл содержащие некоторые логины следующего содержания:
.....много слов
login="Figaro"
.....много букв
login="Tolik"
........
а получить нужно именно список логинов, что в этом случае делать пользователю ?, если файл весит так… цать MB или даже GB? или Вам не приходилось сталкиваться с такими задачами?.. Мы с Вами научимся это делать.
2. Далее задача такая, допустим у нас есть исходники некоторого проекта на «с++» и нам нужно посмотреть какие у этого проекта есть классы ( обойдемся без шаблонных для удобства) и структуры,
учитывая что классы и структуры могут быть объявлены как-то так (без апострофов конечно):
'class Foo'
или так
'class Bar'
или так
' class Any'
' struct A'
и это мы тоже научимся делать.
3. Ну и еще, имеется некоторый файл формата,
user="Login" Passwd="anypassword"
в каждой строке, и нам нужно
из этого файла найти
3.1 юзеров у которых пароль состоит только из цифр,
3.2 юзеров у которых пароль состоит только из меленьких букв,
3.3 только из больших букв,
3.4 у которых пароль короче 5 символов и состоит только из меленьких или больших букв.
3.5 у которых логин похож на ip адрес, это очень странные пользователи похожи на ботов :))
(например 243.11.22.03 или 243-11-22-03 или 243_11_22_03 )
Кто уже знаком с регулярными выражениями, может решить эти задачки для разминки и сравнить результат, с тем который мы получим ниже.
Думаю пока этого хватит.
Ну а теперь грамматика регулярных выражений, увы без этого не обойтись, но, обойдемся для начала небольшим списком, описание пишу сам поэтому могут сильно отличаться от канонических:
Cимволы:
. — точка Это произвольный символ. Если не знаете, что там буква или цифра или символ пишите точку
\w — Это некоторая буква word, к сожалению русские буквы таким символом поддерживается мало кем, например KDevelop 3.5.10 поддерживает
\d — Это некоторая цифра digit
\s — Это пробел или табуляция т.е space
\l — Маленькие буквы lower не поддерживается моей версией grep
\u — Большие буквы upper не поддерживается моей версией grep
[abcde] — Может встречаться любой из перечисленных символов в наборе
^ — обозначение начала строки
$ — обозначение окончания строки
() — скобки используются для группировки выражений
Повторения:
Используются как "(выражение)(повторение)" без скобок, ниже будет понятней.
* — выражение может повторяться произвольное количество раз начиная с 0 т.е может отсутствовать
+ — выражение может повторяться 1 раз и более, т.е должно обязательно присутствовать
{3,6} это универсальный способ задания повторений в данном случае от 3 до 6 повторений
{3,} от трех и более повторений
? — выражение может повторяться 0 или 1 раз можно записать как {0,1}
некоторые символы которые должны быть экранированы в регулярных выражениях, только если вы не имеете их регулярную суть
\?,
\+,
\|,
\(,
\)
\.
\[
\]
\-
\~
На самом деле синтаксис регулярных выражение больше, но это основное, тем не менее для общего развития можно ознакомиться и с остальными возможностями, для того чтобы писать более лаконичные и менее понятные выражения :))
немного о grep, это консольная утилита которая принимает параметры из командной строки, есть и GUI-шные версии этого инструмента, ключи:
-P говорит что выражение является регулярным,
-o вывести только найденное регулярное выражение а не всю строку
-r рекурсивно спускаться в поддиректории
* обрабатывать все файлы ( если только нет include )
--include "*.h" использовать только файлы с расширением .h
Перейдем от слов к делу.
Задача 1,
итак начнем решать наши задачи, напомним условие первой: Допустим мы имеем некоторый текстовый файл logins.txt содержащие некоторые логины следующего содержания :
.....много слов
login="Figaro"
.....много букв
login="Tolik"
........
а получить нужно именно список логинов
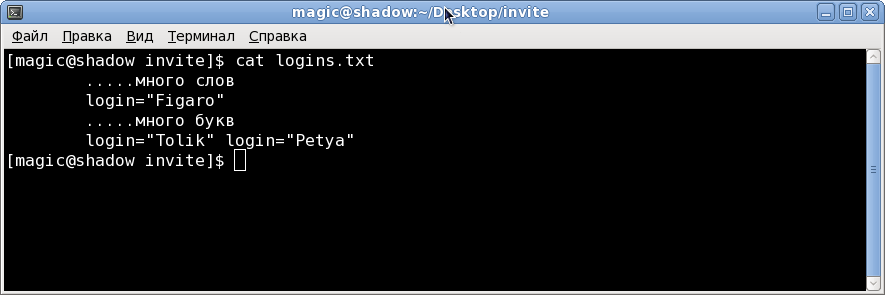
Текст файла logins.txt на котором я проверял:
.....много слов
login="Figaro"
.....много букв
login="Tolik" login="Petya"
файл:
Имеем пример выражения которое мы ищем:
name="Figaro"выделим его изменяющуюся часть, это непосредственно слово записанное в кавычках, смотрим синтаксис, используемые символы это "\w" количество повторений это "+", тогда чтобы найти все пары получаем выражение вида:
name="\w+"т.е имея файл logins.txt команда которая получит список name=«login» получится такой:
grep -Po 'login="\w+"' logins.txtно в условии говорится, что нужно получить список логинов, а не пар, смотрим на выражение типа name=«login» с целью выделить из него только login, очевидно надо забрать выражение в кавычках, регулярное выражение будет выглядеть как часть, того которое у нас уже было:
"\w+" тогда чтобы забрать из результата список логинов получим следующую конструкцию
grep -Po 'login="\w+"' logins.txt | grep -Po '"\w+"'(либо вместо '|' использовать промежуточный файл и применить вторую команду к этому файлу )
Результат вывода команды:
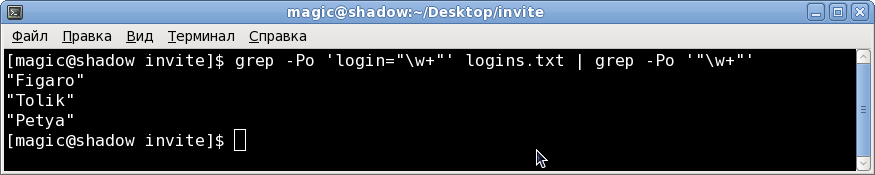
Готово с первой задачей разобрались, получаем список логинов, при желании можно убрать и кавычки, но это самостоятельно.
Задача номер 2
, напомню условие: Допустим у нас есть исходники некоторого проекта на "с" и нам нужно посмотреть какие у этого проекта есть классы ( обойдемся без шаблонных для удобства) и структуры, учитывая что классы и структуры могут быть объявлены как-то так (без апострофов конечно) :
'class Foo'
или так
'class Bar'
или так
' class Any'
' struct A'
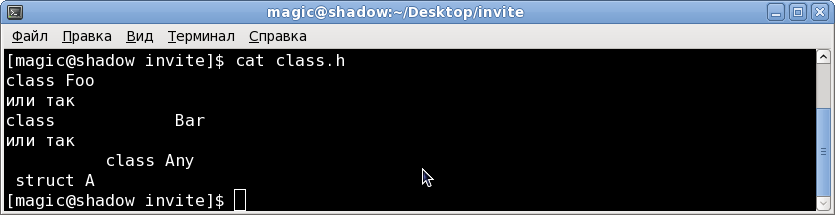
--Текст файла class.h на котором я проверял:
class Foo
или так
class Bar
или так
class Any
struct A
— содержимое файла:
Итак что имеем, заложимся на то, что заголовки классов находятся в начале строки, иначе по мне так это чудовищно. берем пример строки объявления:
' class Any'и пробуем превратить это выражение в шаблон который подойдет ко всем остальным объявлениям обобщаем:
идет начало строки => '^',
потом идет пробел или табуляция => '\s', может быть а может не быть => '*',
идет слово class => class, или => '|' слово struct => struct,
идет пробел => '\s', как минимум один => '+',
идет название =>'\w', должен содержать как минимум одну букву => '+'
Логика построения выглядит более сложно чем само выражение которое получается в результате:
^\s*(class|struct)\s+\w+и так команда которая найдет объявления:
grep -Pr "^\s*(class|struct)\s+\w+" class.hвывод результата:
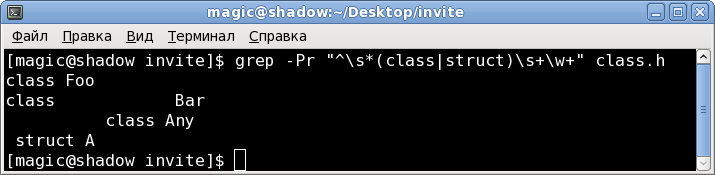
или звездочка, чтобы применить ко всем файлам:
grep -Pr "^\s*(class|struct)\s+\w+" *Готово, со второй задачей разобрались.
Задача номер 3
, условие: 3) Ну и еще, имеется некоторый файл формата, user="Login" Passwd="anypassword" в каждой строке, и нам нужно
из этого файла найти
3.1 юзеров у которых пароль состоит только из цифр,
3.2 юзеров у которых пароль состоит только из меленьких букв,
3.3 только из больших букв,
3.4 у которых пароль короче 5 символов и состоит только из меленьких или только больших букв.
3.5 у которых логин похож на ip адрес, это очень странные пользователи похожи на ботов :))
(например 243.11.22.03 или 243-11-22-03 или 243_11_22_03 )
--Текст файла users.txt на котором я проверял:
user="Login" Passwd="12login"
user="Anya" Passwd="12341234"
user="Masha" Passwd="2345234524"
user="Pasha" Passwd="4657467"
user="234.255.252.21" Passwd="2342346354"
user="Petya" Passwd="0099"
user="Misha" Passwd="victor"
user="Lena" Passwd="VASYA"
user="Sveta" Passwd="PUPKIN"
user="Ira" Passwd="PETR"
user="Lera" Passwd="%^&&@&&@*****"
user="Sasha" Passwd=")(#@*)($#K$@LKJLKJLK"
user="Dima" Passwd="K:LSDKL:FS:LFD"
user="Serega" Passwd=")(*#@$(*#@()$"
user="212_2_3_3" Passwd="JDK"
user="225-234-234-22" Passwd="123"
user="192.116.166.13" Passwd="466"
user="234.255.252.22" Passwd="111"
— фаил:

3.1 Для того чтобы найти пароли только с цифрами, достаточно выполнения условия, где в кавычках
значения пароль находятся только цифры, это очень просто, думаю Вы все поймете без расписывания:
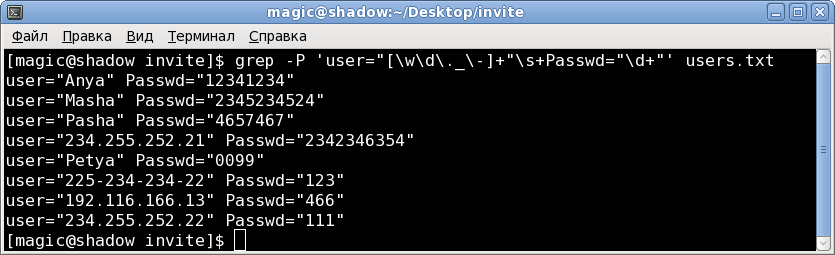
user="[\w\d\._\-]+"\s+Passwd="\d+"grep -P 'user="[\w\d\._\-]+"\s+Passwd="\d+"' users.txt[\w\d\._\-] — это допустимые в логине символы буквы, цифры, точка, подчеркивание, тире.
результат:
3.2 Смотрим на правила грамматики обозначения маленьких букв, здесь аналогичное условие, только вместо цифр здесь маленькие буквы, и получаем в результате:
user="[\w\d\._\-]+"\s+Passwd="[a-z]+"grep -P 'user="[\w\d\._\-]+"\s+Passwd="[a-z]+"' users.txtрезультат:

3.3 Тут аналогично:
user="[\w\d\._\-]+"\s+Passwd="[A-Z]+"grep -P 'user="[\w\d\._\-]+"\s+Passwd="[A-Z]+"' users.txtрезультат:

3.4 Здесь можно немного подумать, и вспомнить похожий случай был когда мы искали class или struct, только добавляются ограничения на длину:
Предлагаю, остановиться немного подумать, и написать самим :)). Я серьезно, еще раз прочитайте пункт 3.4 и решение задачи 2, и напишите выражение самостоятельно. Вернетесь после того как попробуете. =))
Здесь не на много сложнее:
user="[\w\d\._\-]+"\s+Passwd="([a-z]|[A-Z]){1,4}"grep -P 'user="[\w\d\._\-]+"\s+Passwd="([a-z]|[A-Z]){1,4}"' users.txtрезультат:

3.5 Здесь я напишу само выражение, а его разбор, т.е понимание предлагаю сделать самостоятельно, хотя конечно, можно было бы Вам самостоятельно его написать.
Так и сделаю, те кто чувствует в себе силы предлагаю написать самостоятельно решение пункта 3.5, а потом проверить его на тестовых данных, тем же кто самостоятельно писать не хочет, остается осилить выражение ниже, я понимаю выглядит жутко только если я вам его распишу, скорее всего ничего не отложится:
а вот и само выражение:
user="(\d{1,3}[\._\-]){3}\d{1,3}"\s+Passwd=".*"grep -P 'user="(\d{1,3}[\._\-]){3}\d{1,3}"\s+Passwd=".*"' users.txtдам подсказку:
выделяется блок — (\d{1,3}[\._\-]) это предствляет собой к примеру: '251.' который повторяется
3 раза после чего получаем что то вроде '251.243.243.' после которого идет еще одно число \d{1,3}.
результат:

В конце хотелось бы отметить, что имена наборов можно указывать явно, так вместо \d можно написать [1234567890] или [0-9] для явного указания русских букв можно также указывать [а-яА-ЯёЁ], правда такая конструкция не всегда может быть правильно понята. только маленькие английские буквы [a-z] только большие [A-Z] маленькие большие и цифры [a-zA-Z0-9] и т.д.
Спасибо за внимание, хочу посоветовать — потратить немного времени чтобы разобраться, это действительно делает жизнь (особенно программиста) проще.
