В предыдущих сериях (FAQ • 1 • 2 • 3 • 4 • 5 ) мы весьма подробно рассмотрели, как написать на Java собственный интерпретатор объектно-ориентированного диалекта SQL поверх Spark RDD API, заточенный на задачи подготовки и трансформации наборов данных.
В данной части поговорим о том, как добавить в выражения SQL поддержку функций. Например,
SELECT MAX(score1, score2, score3, score4, score5) AS max_score, MIN(score1, score2, score3, score4, score5) AS min_score, MEDIAN(score1, score2, score3, score4, score5) AS median_score, score1 + score2 + score3 + score4 + score5 AS score_sum FROM raw_scores INTO final_scores WHERE ABS(score1 + score2 + score3 + score4 + score5) > $score_margin;
— тут у нас функции MAX, MIN и MEDIAN принимают любое количество аргументов типа Double и возвращают Double, а ABS только один такой аргумент.
Вообще, кроме общей математики, в любом уважающем себя диалекте SQL как минимум должны быть функции для манипуляций с датой/временем, работы со строками и массивами. Их мы тоже обязательно добавим. В classpath, чтобы движок мог их оттуда подгружать. До кучи, ещё и операторы типа >= или LIKE, которые у нас уже были реализованы, но хардкодом, сделаем такими же подключаемыми.
Уровень сложности данной серии статей в целом высокий. Базовые понятия в тексте совсем не объясняются, да и продвинутые далеко не все. Однако, эта часть несколько проще для ознакомления, чем предыдущие. Но всё равно, понимать её будет легче, если вы уже пробежались по остальным хотя бы по диагонали.
Для начала, давайте определимся, что такое «функция» в контексте записи выражений подобных математическим, и как она отличается от «оператора».
На самом деле — да почти никак не отличается.
Можно даже сказать, что с точностью до условностей синтаксиса запись sum(a, b) это ровно то же самое, что и a + b. И если записывать +(a, b), то символ + у нас будет всего лишь более коротким псевдонимом для имени sum. В случае унарных операторов ещё нагляднее: ~HEX против bitwise_negation(HEX).
То есть, с точки зрения как минимум синтаксиса, функция и оператор в выражениях — это одно и тоже, и интерпретировать их можно единообразно. Различия начинаются только с уровня семантики, но об этом чуть позже.
А пока что посмотрим, как у нас разбираются выражения.
Во-первых, есть лексер/парсер, написанный на ANTLR, а в нём определено такое правило:
expression : ( is_op | between_op | in_op | comparison_op | var_name | property_name | L_NUMERIC | L_STRING | S_NULL | S_TRUE | S_FALSE | S_OPEN_PAR | S_CLOSE_PAR | expression_op | digest_op | random_op | bool_op | default_op )+ ;
Это правило говорит нам, что «выражение» для нас выглядит как некий «суп» из токенов, среди которых:
• строковые и числовые литералы,
• предопределённые символы для булей и нулей,
• имена переменных и свойств записей,
• целая куча подвыражений для всяких разных групп операторов, включающих в себя SQL-ные IS/BETWEEN/IN, сравнения, логику, и ещё пару штук нужных только нам,
• и, наконец, скобки — открывающая и закрывающая.
Хорошо, великий суп заварили. Чтобы его расхлебать во что-нибудь интерпретируемое, можно с успехом использовать классический алгоритм Shunting Yard, у которого на выходе будет запись выражения в «обратной польской записи». А любое выражение в RPN можно уже напрямую выполнять на ещё более простом конечном автомате на основе стека, чем сам Shunting Yard.
В коде на Java эти два компонента будет выглядеть как-то так (осторожно, Java очень многословна):
Выжимка из TDL4Interpreter.java:
private List<Expression<?>> expression(List<ParseTree> exprChildren, ExpressionRules rules) { List<Expression<?>> items = new ArrayList<>(); Deque<ParseTree> whereOpStack = new LinkedList<>(); List<ParseTree> predExpStack = new ArrayList<>(); int i = 0; // doing Shunting Yard for (; i < exprChildren.size(); i++) { ParseTree child = exprChildren.get(i); if ((child instanceof TDL4.Expression_opContext) || (child instanceof TDL4.Comparison_opContext) || (child instanceof TDL4.Bool_opContext) || (child instanceof TDL4.In_opContext) || (child instanceof TDL4.Is_opContext) || (child instanceof TDL4.Between_opContext) || (child instanceof TDL4.Digest_opContext) || (child instanceof TDL4.Random_opContext) || (child instanceof TDL4.Default_opContext)) { while (!whereOpStack.isEmpty()) { ParseTree peek = whereOpStack.peek(); if (peek instanceof TerminalNode) { TerminalNode tn = (TerminalNode) peek; int tt = tn.getSymbol().getType(); if (tt == TDL4Lexicon.S_OPEN_PAR) { break; } } if (isHigher(child, peek)) { predExpStack.add(whereOpStack.pop()); } else { break; } } whereOpStack.push(child); continue; } if (child instanceof TerminalNode) { TerminalNode tn = (TerminalNode) child; int tt = tn.getSymbol().getType(); if (tt == TDL4Lexicon.S_OPEN_PAR) { whereOpStack.add(child); continue; } if (tt == TDL4Lexicon.S_CLOSE_PAR) { while (true) { if (whereOpStack.isEmpty()) { throw new RuntimeException("Mismatched parentheses at query token #" + i); } ParseTree pop = whereOpStack.pop(); if (!(pop instanceof TerminalNode)) { predExpStack.add(pop); } else { break; } } continue; } } // expression predExpStack.add(child); } while (!whereOpStack.isEmpty()) { predExpStack.add(whereOpStack.pop()); } for (ParseTree exprItem : predExpStack) { if (exprItem instanceof TDL4.Property_nameContext) { switch (rules) { case QUERY: { String propName = resolveName(((TDL4.Property_nameContext) exprItem).L_IDENTIFIER()); items.add(Expressions.propItem(propName)); continue; } case AT: { String propName = resolveName(((TDL4.Property_nameContext) exprItem).L_IDENTIFIER()); items.add(Expressions.stringItem(propName)); continue; } default: { throw new InvalidConfigurationException("Attribute name is not allowed in this context: " + exprItem.getText()); } } } if (exprItem instanceof TDL4.Var_nameContext) { TDL4.Var_nameContext varNameCtx = (TDL4.Var_nameContext) exprItem; String varName = resolveName(varNameCtx.L_IDENTIFIER()); items.add(Expressions.varItem(varName)); continue; } if (exprItem instanceof TDL4.Between_opContext) { TDL4.Between_opContext between = (TDL4.Between_opContext) exprItem; items.add(Expressions.stackGetter(1)); double l = resolveNumericLiteral(between.L_NUMERIC(0)).doubleValue(); double r = resolveNumericLiteral(between.L_NUMERIC(1)).doubleValue(); items.add((between.S_NOT() == null) ? Expressions.between(l, r) : Expressions.notBetween(l, r) ); continue; } if (exprItem instanceof TDL4.In_opContext) { TDL4.In_opContext inCtx = (TDL4.In_opContext) exprItem; if (inCtx.array() != null) { items.add(Expressions.setItem(resolveArray(inCtx.array(), ExpressionRules.QUERY))); } if (inCtx.var_name() != null) { items.add(Expressions.arrItem(resolveName(inCtx.var_name().L_IDENTIFIER()))); } if (inCtx.property_name() != null) { items.add(Expressions.propItem(resolveName(inCtx.property_name().L_IDENTIFIER()))); } items.add(Expressions.stackGetter(2)); boolean not = inCtx.S_NOT() != null; items.add(not ? Expressions.notIn() : Expressions.in()); continue; } // column_name IS NOT? NULL if (exprItem instanceof TDL4.Is_opContext) { items.add(Expressions.stackGetter(1)); items.add((((TDL4.Is_opContext) exprItem).S_NOT() == null) ? Expressions.isNull() : Expressions.nonNull()); continue; } if ((exprItem instanceof TDL4.Expression_opContext) || (exprItem instanceof TDL4.Comparison_opContext) || (exprItem instanceof TDL4.Bool_opContext) || (exprItem instanceof TDL4.Digest_opContext) || (exprItem instanceof TDL4.Random_opContext) || (exprItem instanceof TDL4.Default_opContext)) { Operator eo = Operator.get(exprItem.getText()); if (eo == null) { throw new RuntimeException("Unknown operator token " + exprItem.getText()); } else { items.add(Expressions.stackGetter(eo.ariness)); items.add(Expressions.opItem(eo)); } continue; } TerminalNode tn = (TerminalNode) exprItem; int type = tn.getSymbol().getType(); if (type == TDL4Lexicon.L_NUMERIC) { items.add(Expressions.numericItem(resolveNumericLiteral(tn))); continue; } if (type == TDL4Lexicon.L_STRING) { items.add(Expressions.stringItem(resolveStringLiteral(tn))); continue; } if (type == TDL4Lexicon.S_NULL) { items.add(Expressions.nullItem()); continue; } if ((type == TDL4Lexicon.S_TRUE) || (type == TDL4Lexicon.S_FALSE)) { items.add(Expressions.boolItem(Boolean.parseBoolean(tn.getText()))); continue; } } return items; }
Выжимка из Operator.java:
public static Object eval(AttrGetter props, List<Expression<?>> item, VariablesContext vc) { if (item.isEmpty()) { return null; } Deque<Object> stack = new LinkedList<>(); Deque<Object> top = null; for (Expression<?> ei : item) { // these all push to expression stack if (ei instanceof Expressions.PropItem) { stack.push(((Expressions.PropItem) ei).get(props)); continue; } if (ei instanceof Expressions.VarItem) { stack.push(((Expressions.VarItem) ei).get(vc)); continue; } if (ei instanceof Expressions.StringItem) { stack.push(((Expressions.StringItem) ei).get()); continue; } if (ei instanceof Expressions.NumericItem) { stack.push(((Expressions.NumericItem) ei).get()); continue; } if (ei instanceof Expressions.NullItem) { stack.push(((Expressions.NullItem) ei).get()); continue; } if (ei instanceof Expressions.BoolItem) { stack.push(((Expressions.BoolItem) ei).get()); continue; } if (ei instanceof Expressions.SetItem) { stack.push(((Expressions.SetItem) ei).get()); continue; } if (ei instanceof Expressions.OpItem) { stack.push(((Expressions.OpItem) ei).eval(top)); continue; } if (ei instanceof Expressions.IsExpr) { stack.push(((Expressions.IsExpr) ei).eval(top.pop())); continue; } if (ei instanceof Expressions.InExpr) { stack.push(((Expressions.InExpr) ei).eval(top.pop(), top.pop())); continue; } if (ei instanceof Expressions.BetweenExpr) { stack.push(((Expressions.BetweenExpr) ei).eval(top.pop())); continue; } // and this one pops from it if (ei instanceof Expressions.StackGetter) { top = ((Expressions.StackGetter) ei).get(stack); continue; } } if (stack.size() != 1) { throw new RuntimeException("Invalid SELECT item expression"); } return stack.pop(); }
Кода много, но он просто рассортировывает токены по нужным местам стека, превращая их в примитивы типа
• «положить на стек константу такого-то вида»,
• «положить на стек свойство записи»,
• «взять со стека N элементов»,
• «положить на стек результат вызова оператора со взятыми ранее элементами»,
и так далее, — а затем пробегается по полученному списку, и выполняет примитивы в порядке просмотра, в конце получая вычисленный результат, который должен остаться только один. Если вдруг остался не один, то либо где-то в выражении попались несбалансированные скобки, либо неправильное количество операндов.
Отлично. А как в этот суп запихнуть синтаксис вызова функций? В них ведь открывающие и закрывающие скобочки не просто меняют порядок вычисления операторов, но ещё и задают количество операндов, которые становятся уже даже не операндами, а аргументами.
Очень просто. Надо добавить в суп рекурсию. (Вопрос со звёздочкой «как его расхлебать нерекурсивно?*» оставим на совести читателей, потому что автор напрочь бессовестный, и заморачиваться поиском ответа не желает. Простите уж.)
Перепишем правило:
expression : ( is_op | between_op | in_op | comparison_op | var_name | L_NUMERIC | L_STRING | S_NULL | S_TRUE | S_FALSE | expression_op | digest_op | bool_op | default_op | func_call )+ ; attr_expr : ( is_op | between_op | in_op | comparison_op | var_name | L_NUMERIC | L_STRING | S_NULL | S_TRUE | S_FALSE | expression_op | digest_op | bool_op | default_op | func_attr | attr )+ ; func_call : func S_OPEN_PAR expression ( S_COMMA expression )* S_CLOSE_PAR | func S_OPEN_PAR S_CLOSE_PAR | S_OPEN_PAR expression S_CLOSE_PAR ; func_attr : func S_OPEN_PAR attr_expr ( S_COMMA attr_expr )* S_CLOSE_PAR | func S_OPEN_PAR S_CLOSE_PAR | S_OPEN_PAR attr_expr S_CLOSE_PAR ;
На что следует обратить внимание — правил для самих выражений стало два. Одно нужно для контекста, в котором можно обращаться к атрибутам записей, то есть, выполняемых в SELECT выражение, выражение, ... FROM ... WHERE логическое_выражение. Другое, соответственно, требуется для контекста внутри операторов типа LET $переменная = выражение, которые исполняются на уровне скрипта, и ни к каким записям обращаться не могут.
Сделав различие в парсере, мы избавимся от проверок контекста исполнения в интерпретаторе, про которые в прошлой версии вообще забыли. Работа над ошибками — важна!
Правила для вызова функций описывают три разных синтаксиса:
• func(expression[, expression]...)
• func()
• (expression)
То есть, кусок выражения в скобках без имени перед ним — это у нас тоже теперь «функция», правда, безымянная, и возвращает она нам свой единственный аргумент. Остальные два варианта описывают функцию без аргументов, либо с одним или более аргументами.
Такой подход позволяет нам вообще выкинуть обработку скобок из Shunting Yard:
Выжимка из TDL4Interpreter.java:
private List<ParseTree> doShuntingYard(List<ParseTree> exprChildren) { Deque<ParseTree> whereOpStack = new LinkedList<>(); List<ParseTree> predExpStack = new ArrayList<>(); int i = 0; // doing Shunting Yard for (; i < exprChildren.size(); i++) { ParseTree child = exprChildren.get(i); if ((child instanceof TDL4.Expression_opContext) || (child instanceof TDL4.Comparison_opContext) || (child instanceof TDL4.Bool_opContext) || (child instanceof TDL4.In_opContext) || (child instanceof TDL4.Is_opContext) || (child instanceof TDL4.Between_opContext) || (child instanceof TDL4.Digest_opContext) || (child instanceof TDL4.Default_opContext)) { while (!whereOpStack.isEmpty()) { ParseTree peek = whereOpStack.peek(); if (isHigher(child, peek)) { predExpStack.add(whereOpStack.pop()); } else { break; } } whereOpStack.push(child); continue; } if (child instanceof TDL4.Func_callContext) { TDL4.Func_callContext funcCall = (TDL4.Func_callContext) child; if (funcCall.expression() != null) { for (TDL4.ExpressionContext e : funcCall.expression()) { predExpStack.addAll(doShuntingYard(e.children)); } } if (funcCall.func() != null) { predExpStack.add(funcCall); } continue; } if (child instanceof TDL4.Func_attrContext) { TDL4.Func_attrContext funcAttr = (TDL4.Func_attrContext) child; if (funcAttr.attr_expr() != null) { for (TDL4.Attr_exprContext e : funcAttr.attr_expr()) { predExpStack.addAll(doShuntingYard(e.children)); } } if (funcAttr.func() != null) { predExpStack.add(funcAttr); } continue; } // expression predExpStack.add(child); } while (!whereOpStack.isEmpty()) { predExpStack.add(whereOpStack.pop()); } return predExpStack; } private List<Expressions.ExprItem<?>> expression(List<ParseTree> exprChildren, ExpressionRules rules) { List<Expressions.ExprItem<?>> items = new ArrayList<>(); List<ParseTree> predExpStack = doShuntingYard(exprChildren); for (ParseTree exprItem : predExpStack) { if (exprItem instanceof TDL4.AttrContext) { switch (rules) { case QUERY: { String propName = resolveName(((TDL4.AttrContext) exprItem).L_IDENTIFIER()); items.add(Expressions.attrItem(propName)); continue; } case AT: { String propName = resolveName(((TDL4.AttrContext) exprItem).L_IDENTIFIER()); items.add(Expressions.stringItem(propName)); continue; } default: { throw new InvalidConfigurationException("Attribute name is not allowed in this context: " + exprItem.getText()); } } } if (exprItem instanceof TDL4.Var_nameContext) { TDL4.Var_nameContext varNameCtx = (TDL4.Var_nameContext) exprItem; String varName = resolveName(varNameCtx.L_IDENTIFIER()); items.add(Expressions.varItem(varName)); continue; } if (exprItem instanceof TDL4.Between_opContext) { TDL4.Between_opContext between = (TDL4.Between_opContext) exprItem; items.add(Expressions.stackGetter(1)); double l = resolveNumericLiteral(between.L_NUMERIC(0)).doubleValue(); double r = resolveNumericLiteral(between.L_NUMERIC(1)).doubleValue(); items.add((between.S_NOT() == null) ? Expressions.between(l, r) : Expressions.notBetween(l, r) ); continue; } if (exprItem instanceof TDL4.In_opContext) { TDL4.In_opContext inCtx = (TDL4.In_opContext) exprItem; if (inCtx.array() != null) { items.add(Expressions.setItem(resolveArray(inCtx.array(), ExpressionRules.QUERY))); } if (inCtx.var_name() != null) { items.add(Expressions.arrItem(resolveName(inCtx.var_name().L_IDENTIFIER()))); } if (inCtx.attr() != null) { items.add(Expressions.attrItem(resolveName(inCtx.attr().L_IDENTIFIER()))); } items.add(Expressions.stackGetter(2)); boolean not = inCtx.S_NOT() != null; items.add(not ? Expressions.notIn() : Expressions.in()); continue; } // column_name IS NOT? NULL if (exprItem instanceof TDL4.Is_opContext) { items.add(Expressions.stackGetter(1)); items.add((((TDL4.Is_opContext) exprItem).S_NOT() == null) ? Expressions.isNull() : Expressions.nonNull()); continue; } if ((exprItem instanceof TDL4.Expression_opContext) || (exprItem instanceof TDL4.Comparison_opContext) || (exprItem instanceof TDL4.Bool_opContext) || (exprItem instanceof TDL4.Digest_opContext) || (exprItem instanceof TDL4.Default_opContext)) { Operator<?> eo = Operators.get(exprItem.getText()); if (eo == null) { throw new RuntimeException("Unknown operator token " + exprItem.getText()); } else { int arity = eo.arity(); items.add(Expressions.stackGetter(arity)); items.add(Expressions.opItem(eo)); } continue; } if (exprItem instanceof TDL4.Func_callContext) { TDL4.Func_callContext funcCall = (TDL4.Func_callContext) exprItem; TDL4.FuncContext funcCtx = funcCall.func(); Function<?> ef = Functions.get(resolveName(funcCtx.L_IDENTIFIER())); if (ef == null) { throw new RuntimeException("Unknown function token " + exprItem.getText()); } else { int arity = ef.arity(); if (arity == Function.ARBITR_ARY) { items.add(Expressions.stackGetter(funcCall.expression().size())); } else if (arity > 0) { items.add(Expressions.stackGetter(arity)); } items.add(Expressions.funcItem(ef)); } continue; } if (exprItem instanceof TDL4.Func_attrContext) { TDL4.Func_attrContext funcAttr = (TDL4.Func_attrContext) exprItem; TDL4.FuncContext funcCtx = funcAttr.func(); Function<?> ef = Functions.get(resolveName(funcCtx.L_IDENTIFIER())); if (ef == null) { throw new RuntimeException("Unknown function token " + exprItem.getText()); } else { int arity = ef.arity(); switch (arity) { case Function.KEY_LEVEL: { items.add(Expressions.keyItem()); break; } case Function.RECORD_LEVEL: { items.add(Expressions.recItem()); break; } case Function.ARBITR_ARY: { items.add(Expressions.stackGetter(funcAttr.attr_expr().size())); break; } case Function.NO_ARGS: { break; } default: { items.add(Expressions.stackGetter(arity)); } } items.add(Expressions.funcItem(ef)); } continue; } TerminalNode tn = (TerminalNode) exprItem; int type = tn.getSymbol().getType(); if (type == TDL4Lexicon.L_NUMERIC) { items.add(Expressions.numericItem(resolveNumericLiteral(tn))); continue; } if (type == TDL4Lexicon.L_STRING) { items.add(Expressions.stringItem(resolveStringLiteral(tn))); continue; } if (type == TDL4Lexicon.S_NULL) { items.add(Expressions.nullItem()); continue; } if ((type == TDL4Lexicon.S_TRUE) || (type == TDL4Lexicon.S_FALSE)) { items.add(Expressions.boolItem(Boolean.parseBoolean(tn.getText()))); continue; } } return items; }
Что касается конечного автомата для выполнения RPN, то там в конце добавится малюсенький специальный кейс:
// special case if (ei instanceof ObjItem) { top = new LinkedList<>(); top.add(((ObjItem) ei).recOrKey() ? rec : key); continue; }
— он нужен для того, чтобы функции в контексте SELECT могли работать с записью целиком, а не только с её атрибутами. Оп, я, кажется, немножко забежал вперёд. Что ж, давайте исправим эту оплошность.
Вспомним из предыдущих частей, что в разрабатываемом нами движке SQL все сущности, кроме самых верхнеуровневых операторов SQL, реализованных прямо в интерпретаторе, являются подключаемыми.
То есть, функции, — равно как и операторы выражений, — должны быть имплементациями неких интерфейсов, доступных через classpath, и подгружаемых в интерпретатор при запуске контекста исполнения.
Давайте подумаем, как должен выглядеть общий интерфейс. Назовём его, например, Evaluator:
public interface Evaluator<R> extends Serializable { R call(Deque<Object> args); String name(); String descr(); int arity(); // Тут ещё некоторое количество статических методов для работы со стеком, // типа popDouble(Deque<Object> args), но не будем на них останавливаться }
Что у нас тут? Тут у нас имеется generic тип результата, который возвращается при вызове метода call над списком аргументов/операндов, имя (или символ) с человеко-понятным описанием, а также само количество аргументов/операндов — то есть, арность.
Для операторов нужно ещё кое-что. Опишем их в общем случае как абстрактный класс:
public abstract class Operator<R> implements Evaluator<R> { public abstract int prio(); public boolean rightAssoc() { return false; } public boolean handleNull() { return false; } protected abstract R op0(Deque<Object> args); public Operator() { } @Override public R call(Deque<Object> args) { if (!handleNull()) { for (Object a : args) { if (a == null) { return null; } } } return op0(args); } public static abstract class Unary<R, T> extends Operator<R> { @Override public int arity() { return 1; } } public static abstract class Binary<R, T1, T2> extends Operator<R> { @Override public int arity() { return 2; } } public static abstract class Ternary<R, T1, T2, T3> extends Operator<R> { @Override public int arity() { return 3; } } }
Во-первых, у нас появилась семантика приоритета. А также флаг, который помечает оператор как право-ассоциативный, изменяя порядок вычисления всего выражения.
И ещё один флаг, который позволяет оператору обработать операнд со значением NULL. А то ведь, согласно устоявшимся в SQL правилам, любой затесавшийся в выражении NULL должен давать в итоге NULL. Эта логика у нас прямо по умолчанию и имплементируется. Но некоторые особенные операторы могут желать обрабатывать NULL как-то иначе, и мы такую возможность им обязаны предоставить.
Наконец, операторы у нас бывают унарные, бинарные, и тернарные.
С функциями выходит похожий коленкор, но чуточку другого цвета (то есть, семантически они намного проще):
public abstract class Function<R> implements Evaluator<R> { public static final int KEY_LEVEL = -3; public static final int RECORD_LEVEL = -2; public static final int ARBITR_ARY = -1; public static final int NO_ARGS = 0; public Function() { } public static abstract class KeyLevel<R> extends Function<R> { @Override public int arity() { return KEY_LEVEL; } } public static abstract class RecordLevel<R, REC extends Record<?>> extends Function<R> { @Override public int arity() { return RECORD_LEVEL; } } public static abstract class ArbitrAry<R, TA> extends Function<R> { @Override public int arity() { return ARBITR_ARY; } } public static abstract class NoArgs<R> extends Function<R> { @Override public int arity() { return NO_ARGS; } } public static abstract class Unary<R, T> extends Function<R> { @Override public int arity() { return 1; } } public static abstract class Binary<R, T1, T2> extends Function<R> { @Override public int arity() { return 2; } } public static abstract class Ternary<R, T1, T2, T3> extends Function<R> { @Override public int arity() { return 3; } } }
Но здесь у нас, помимо обычных, словно из ниоткуда возникают особенные арности:
• «нулярная» — для функций без аргументов,
• «минус первая» — для функций с произвольным количеством аргументов,
• «уровня записи» — для функций контекста SELECT, принимающих объект целиком,
• «уровня ключа записи» — тоже для контекста SELECT, но обращаются к ключу записи, до которого иным способом, вообще говоря, не добраться.
Последние две имеют смысл только для такого объектно-ориентированного SQL, как наш. Напомню, что наборы данных в нём — это Spark RDD, и каждая запись набора состоит из пары отдельного объекта ключа (проще всего рассматривать его как набор байт, но там может быть что угодно, хоть строка, хоть прямой номер партиции) и собственно объекта записи (то есть, наследника Record<?>, определённого в терминах API движка). Совсем не как в таблицах RDBMS.Ключ записи в наборе данных, таким образом, штука для SQL несколько чуждая, так как он в общем случае не обязан совпадать ни с атрибутом записи, ни даже с набором атрибутов, и может быть задан извне как результат вычисления какого-то выражения. При этом, роль у него очень важная, ведь именно по ключу определяется та партиция, в которую запись попадёт. Добраться до него обычным способом тоже будет не так просто, раз он обретается вне объекта записи. Но коли уж хочется (да), то можно завести функцию
public static class KEY extends KeyLevel<Object> { @Override public Object call(Deque<Object> args) { return args.pop(); } @Override public String name() { return "REC_KEY"; } @Override public String descr() { return "Returns the Key of DS Record"; } }
которая сама по себе ничего не делает, и поддержать её в интерпретаторе, заменив eval() на что-то такое:
public static boolean boolLoose(List<ExprItem<?>> item, VariablesContext vc) { return boolAttr(null, null, item, vc); } public static Object evalAttr(Object key, Record<?> rec, List<ExprItem<?>> item, VariablesContext vc) { //... }
и соответственно передавая в evalAttr() из контекста данных не только сам объект записи, как раньше, но ещё и ключ. А для выражений, вычисляемых в контексте скрипта, где записей нет, дёргать evalLoose(). Впрочем, изменение это точечное, и ничего особо не аффектит.
Также, следует помнить, что инструмент Data Cooker ETL заточен исключительно на задачи ETL, и не является попыткой сделать пародию на аналитическую СУБД. Поэтому, если нужны агрегирующие функции, редюсеры, и прочие оконки, то для этого следует воспользоваться более подходящим инструментом. Spark это всё умеет, но наш движок нужен только чтобы более эффективно готовить данные для последующего анализа, и принципиально не собирается заниматься оным самостоятельно.
Поэтому функций типа COUNT(*), которые схлопывают весь набор данных в одну запись, у нас точно не будет. Все наши функции работают либо в контексте одной записи, либо ни одной.
Итак, после того, как типы для операторов и функций описаны, добавлять их не составит большого труда. Приведу несколько примеров:
public static class CAT extends Binary<String, Object, Object> { @Override public int prio() { return 125; } @Override public String name() { return "||"; } @Override public String descr() { return "String concatenation"; } @Override protected String op0(Deque<Object> args) { return args.stream().map(String::valueOf).collect(Collectors.joining()); } }
public static class NEQ extends Binary<Boolean, Object, Object> { @Override public int prio() { return 40; } @Override public String name() { return "!="; } @Override public String descr() { return "Checks for inequality. String checks are case-sensitive"; } @Override public boolean handleNull() { return true; } @Override protected Boolean op0(Deque<Object> args) { Object a = args.pop(); Object b = args.pop(); if ((a == null) || (b == null)) { return false; } if (a instanceof Number) { return ((Number) a).doubleValue() != Utils.parseNumber(String.valueOf(b)).doubleValue(); } if (a instanceof Boolean) { return (boolean) a != Boolean.parseBoolean(String.valueOf(b)); } return !Objects.equals(a, b); } }
public static class DIGEST extends Binary<String, Object, String> { @Override public int prio() { return 40; } @Override public boolean rightAssoc() { return true; } @Override public String name() { return "DIGEST"; } @Override public String descr() { return "Right argument is treated as Java digest provider in the format of provider-whitespace-algorithm" + " or only algorithm, and left argument's hash is calculated and converted to hexadecimal string"; } @Override protected String op0(Deque<Object> args) { String r = Evaluator.popString(args); String digest = Evaluator.popString(args); final String[] d = digest.split(" ", 2); MessageDigest md; try { md = (d.length > 1) ? MessageDigest.getInstance(d[1], d[0]) : MessageDigest.getInstance(d[0]); } catch (Exception e) { throw new InvalidConfigurationException("Unknown DIGEST algorithm '" + digest + "'"); } return Hex.encodeHexString(md.digest(r.getBytes())); } }
public static class MAX extends ArbitrAry<Double, Double> { @Override public Double call(Deque<Object> args) { if (args.isEmpty()) { return null; } return args.stream().mapToDouble(o -> Utils.parseNumber(String.valueOf(o)).doubleValue()).max().getAsDouble(); } @Override public String name() { return "MAX"; } @Override public String descr() { return "Returns a mathematical max value from given arguments"; } }
public static class Slice extends Ternary<Object[], Object[], Integer, Integer> { @Override public Object[] call(Deque<Object> args) { Object[] a = Evaluator.popArray(args); return Arrays.copyOfRange(a, Evaluator.popInt(args), Evaluator.popInt(args)); } @Override public String name() { return "ARR_SLICE"; } @Override public String descr() { return "Return a slice of ARRAY given as 1st argument starting with index from 2nd and to index in 3rd (exclusive)"; } }
public static class HASHCODE extends RecordLevel<Integer, Record<?>> { @Override public Integer call(Deque<Object> args) { return Objects.hashCode(args.pop()); } @Override public String name() { return "REC_HASHCODE"; } @Override public String descr() { return "Returns Java .hashCode() of DS Record"; } }
public static class PolyPerimeter extends RecordLevel<Double, PolygonEx> { @Override public Double call(Deque<Object> args) { PolygonEx poly = (PolygonEx) args.pop(); PolygonArea pArea = new PolygonArea(Geodesic.WGS84, false); for (Coordinate c : poly.getExteriorRing().getCoordinates()) { pArea.AddPoint(c.y, c.x); } PolygonResult pRes = pArea.Compute(); return pRes.perimeter; } @Override public String name() { return "POLY_PERIMETER"; } @Override public String descr() { return "The perimeter of the Polygon's outline in meters"; } }
То есть, для добавления новой функции или оператора выражений потребуется написать буквально несколько строк, имплементировав класс, и дальше сработает автомагия.
Про функции для работы с датой/временем мы однозначно не забудем, так как их нужно иметь, — и довольно-таки много, — чтобы реализовать работу с таймштампами в разных таймзонах. Раньше у нас для этого были отдельная операции (то есть, расширения языка), теперь они будут причёсаны под общую гребёнку. (Ознакомьтесь в ними по ссылке, портянок кода в статье уже достаточно.)
Более того, вместе с ними в нашу систему типов данных добавляется специфичный для этого семейства функций тип — DateTime-like Object, который представляется либо как Numeric с секундами/миллисекундами Эпохи, либо как богомерзская жабья ISO8601-подобная строка, которая на самом деле не соответствует никакому стандарту, но частенько попадается в выгрузках данных от поставщиков. Если такое дело есть в природе, нам тоже придётся его поддерживать.
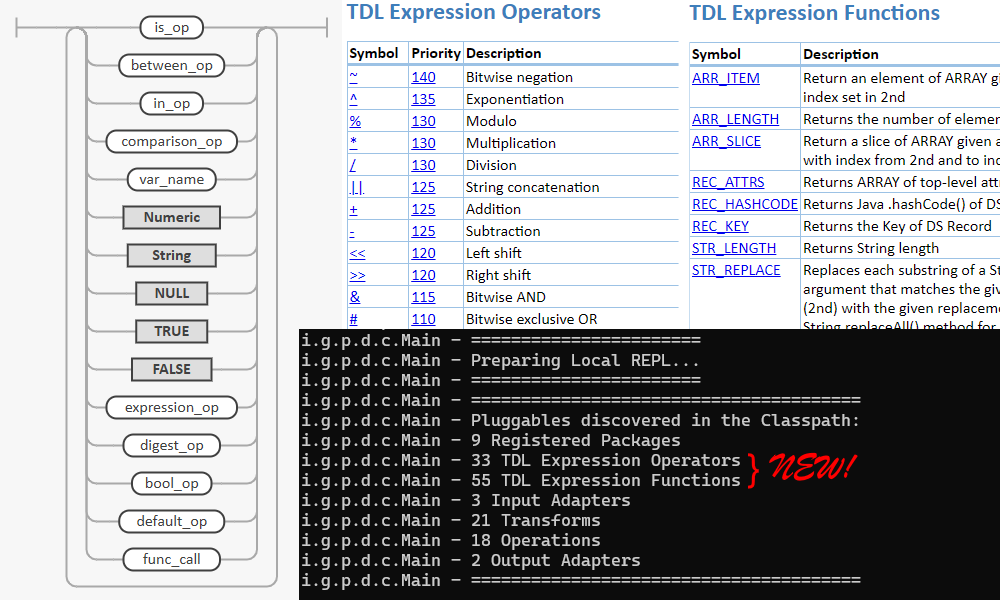
В первом приближении, как следует из заглавного скриншота статьи, функций у нас получилось аж 55 штук. И 33 оператора (правда, среди них есть повторы).
Что ж. До нижнего слоя API мы добрались прям как-то сразу, и вот оно уже готово к использованию.
Но помимо нижнего слоя движка, который в целом представляет собой почти голый интерпретатор с минимальными финтифлюшками, у нас есть ведь ещё немножко слоёв фронта, а именно — REPL, который может работать как локально в процессе, так и подключаться через REST, — и, наконец, автогенератор документации, который собирает доку в том числе из метаданных самого кода. То есть, из тех же generic типов в абстрактных классах Function.Binary<R, T1, T2> и иже с ними.
Но вся эта машинерия уже была неоднократно реализована для других компонентов движка, — таких как «операции», «трансформы», «адаптеры хранилищ», контексты данных и переменных, — поэтому большая часть кода будет копипастой соответствующих компонент, и повторять в этой статье краткое содержание предыдущих серий я, пожалуй, не стану, а отошлю к предыдущей части. Дополнения слоёв фронта выходят слишком уж тривиальными.
Впрочем, код реестра операторов привести можно, потому как пара небольших заметок по нему всё-таки необходимы:
public class Operators { public final static Map<String, Operator<?>> OPERATORS; static { Map<String, Operator<?>> operators = new HashMap<>(); for (Map.Entry<String, String> pkg : RegisteredPackages.REGISTERED_PACKAGES.entrySet()) { try (ScanResult scanResult = new ClassGraph().acceptPackages(pkg.getKey()).scan()) { ClassInfoList operatorClasses = scanResult.getSubclasses(Operator.class.getTypeName()); List<Class<?>> operatorClassRefs = operatorClasses.loadClasses(); for (Class<?> operatorClass : operatorClassRefs) { try { if (!Modifier.isAbstract(operatorClass.getModifiers())) { Operator<?> operator = (Operator<?>) operatorClass.getDeclaredConstructor().newInstance(); operators.put(operator.name(), operator); } } catch (Exception e) { System.err.println("Cannot instantiate Operator class '" + operatorClass.getTypeName() + "'"); e.printStackTrace(System.err); } } } } OPERATORS = Collections.unmodifiableMap(operators.entrySet() .stream() .sorted(Comparator.comparingInt(o -> -o.getValue().prio())) .collect(Collectors.toMap( Map.Entry::getKey, Map.Entry::getValue, (oldValue, newValue) -> oldValue, LinkedHashMap::new))); } public static Map<String, EvaluatorInfo> packageOperators(String pkgName) { Map<String, EvaluatorInfo> ret = new LinkedHashMap<>(); for (Map.Entry<String, Operator<?>> e : OPERATORS.entrySet()) { if (e.getValue().getClass().getPackage().getName().startsWith(pkgName)) { ret.put(e.getKey(), EvaluatorInfo.bySymbol(e.getValue().name())); } } return ret; } static Operator<?> get(String symbol) { return OPERATORS.get(symbol); } // Those three are in fact peculiar language constructs, so we make sure they // won't go into the list of real Expression Operators. Therefore, this class // is not included in @RegisteredPackage, and we directly reference them in // the interpreter instead. public static Operator<Boolean> IN = new IN(); public static Operator<Boolean> IS = new IS(); public static Operator<Boolean> BETWEEN = new BETWEEN(); public static class IN extends Binary<Boolean, Object, Object[]> { @Override public int prio() { return 35; } @Override public boolean rightAssoc() { return true; } @Override public String name() { return "IN"; } @Override public String descr() { return "TRUE if left argument is present in the right, casted to array, FALSE otherwise." + " Vice versa for NOT variant"; } @Override protected Boolean op0(Deque<Object> args) { throw new RuntimeException("Direct operator IN call"); } } public static class IS extends Binary<Boolean, Object, Void> { @Override public int prio() { return 35; } @Override public boolean rightAssoc() { return true; } @Override public String name() { return "IS"; } @Override public String descr() { return "TRUE if left argument is NULL, FALSE otherwise. Vice versa for NOT variant"; } @Override public boolean handleNull() { return true; } @Override protected Boolean op0(Deque<Object> args) { throw new RuntimeException("Direct operator IS call"); } } public static class BETWEEN extends Ternary<Boolean, Double, Double, Double> { @Override public int prio() { return 35; } @Override public boolean rightAssoc() { return true; } @Override public String name() { return "BETWEEN"; } @Override public String descr() { return "TRUE if left argument is inclusively between min and max, casted to numerics, FALSE otherwise." + " For NOT variant, TRUE if it is outside the range, excluding boundaries"; } @Override protected Boolean op0(Deque<Object> args) { throw new RuntimeException("Direct operator BETWEEN call"); } } }
Тут у нас две отличающиеся от шаблона вещи.
Во-первых, для пущей человеко-читаемости список обнаруженных в classpath операторов сортируется не по символу, а по приоритету — от наивысшего к наименьшему. В таком виде его проще воспринимать что в REPL, что в доке.
Во-вторых, в SQL есть три весьма, кгхм… пекулярных оператора IN, IS и BETWEEN, которые оказалось по-прежнему проще захардкодить в самом интерпретаторе, нежели пытаться сделать по-нормальному. У них есть варианты с NOT, и вообще, странные они:
is_op : S_IS S_NOT? S_NULL ; between_op : S_NOT? S_BETWEEN L_NUMERIC S_AND L_NUMERIC ; in_op : S_NOT? S_IN array | S_NOT? S_IN var_name | S_NOT? S_IN attr ;
В IS второй операнд всегда NULL, для IN можно передать конструктор массива, а в BETWEEN можно указать только литералы Numeric-ов. Короче, как спел классик, «духовные люди особые люди, и если ты не прелюбодей, лучше не трогай духовных людей… дей-дей-дей...» И я склонен с ним согласиться, что эти операторы скорее конструкции языка, чем настоящие товарищи. Так что для них предусмотрим этакие заглушки, сделав заодно невидимыми для автодокументатора, и вынесем их отдельным пунктом в руководство по языку, где опишем всё это девиантное поведение.
В остальном, рассказывать не то что бы что-то было.
Но при этом, получающееся изменение всё-таки тянет на полноценный мажорный релиз, потому как расширение синтаксиса диалекта SQL — это вам не какие-то хухры-мухры. Это довольно серьёзно.
Надеюсь, для кого-нибудь из читателей тема «как писать и расширять интерпретаторы» кажется столь же интересной, как и для меня. Или же, может быть, кому-то нужен движок для ETL с SQL-ным синтаксисом. Пишите ваши комментарии.
Промка: https://pastorgl.github.io/datacooker-etl
Исходники: https://github.com/PastorGL/datacooker-etl
Официальная группа в телеге: https://t.me/data_cooker_etl
