Comments 56
Приложение это хорошо. Но как я понимаю, лучшие результаты (по затратам времени) получаются не от простого зубрения словаря, а общение с нативным спикером с использованием новых слов.
Я думал что практически все функции обучения иностранными языками уже прочно взяли на себя ИИ. Мало того, если речь об английском, можно с бесплатным microsoft copilot поговорить голосом, состряпав голосом системный промпт (главное неудобство) получить неплохую помощь в общении с нативным терпеливым спикером.
Модифицируй свое приложение, добавив 'chatgpt', в системный промпт которого добавь список слов, которые сегодня тебе нужно выучить.
У всех свои слабые места в изучении. Кому-то грамматика нужна, кто-то на слух плохо воспринимает беглую речь, у кого-то проблемы с произношением, а кому-то не хватает словарного запаса. Я сделал ставку на словарный запас и на мне это неплохо сработало. Не скажу, что я был активно погружен в языковую среду, чаще всего я занимался самостоятельно.
Я хотел добавить chatgpt в другое приложение - генерация тренировочных программ на основе входных данных, но потом оказалось что api OpenAI требует минимального пополнения баланса и просит привязать карту. Если поделитесь бесплатными AI api, хотя бы ограниченными - буду благодарен.
у openrouter есть бесплатные модели free, но как обычно результат не гарантируется, лучше заплатить, хоть криптовалютой
p.s. вам жалко 5-10$ на эту задачу?
Зависит от целей. Если это инвестиция в стартап - ок. Я точно не помню, но для генерации тренировочных программ на 4 недели получалось довольно накладно. Думаю, я вернусь к этому вопросу, когда проработаю финансовую модель более подробно.
Вы пробовали использовать OpenAI api? Какой бюджет примерно закладывали что бы протестировать?
протестировать что?
Положите на счет минимальные 5$ и пополняйте по мере необходимости, мой счет на 5$ сгорел через год не использования (мне было удобнее openrouter использовать)
Я хотел максимально облегчить запуск и упростить поддержку: SQLite, простой фронт, минимум зависимостей и так далее т.к. приложение не коммерческое и его цель была - помочь себе и друзьям на языковых курсах. Возможно, в будущем сделаю экспериментальную AI-функцию. Почитаю про openrouter, спасибо за подсказку!
Привет. Честно не эксперт но я сталкивался с нуждой в API и могу предложить Groq API. Они раздают бесплатно. Есть Llama 3 70B. Контекст 8 к примерно. Скорость вроде до 500 токенов сек. Пользовался, работает. Использовал для голосового ассистента личного. Не помню сколько токенов даётся в месяц. Если надо такая информация, могу поискать.
Статья интересная конечно, но где само приложение посмотреть можно?
Не нашел ссылок
Переезжаем с хостингов ionos на aws, поэтому временно крутится на моем рабочем компьютере с другими проектами. Могу предоставить ссылку по запросу на тестовый сервер.
Это было бы здорово. Может многие бы протестировали, написали бы что можно доработать
Напишите мне в лс или в телеграм - дам ссылку.
Мой сервер с apache едва справляется с текущей нагрузкой, активные тестирования его точно положат)
Me: "Я написал свою версию MVC фреймворка с блекджеком и роутингом, что значительно повлияло на скорость работы приложения. Кроме того, я реализовал кэширование на стороне фронтенда, что помогло сократить количество запросов к серверу и позитивно сказалось на производительности.
Also me: "Мой сервер с apache едва справляется с текущей нагрузкой" ¯\(ツ)/¯
AWS так себе выбор если вы 5$ на AI API не хотите выделить. AWS славится своими "скрытымм" и неожиданными платежами.
Будьте с ним очень аккуратно. И детально читайте всю документацию на выбранные вами опции.
AWS мы планируем использовать для проекта по разработке софта, но так же добавим туда все наши проекты. Я не против выделения средств, но у меня должно быть четкое понимание для чего это нужно. Если вы набросали некоммерческое приложение, в которое регулярно вливаете деньги, но не зарабатываете на этом, то эта бизнес идея сомнительная, мягко говоря. По этой причине я стараюсь выжать максимум из того что есть.
Duolingo наше всё! Там есть практически всё, что делают другие разработчики в своих приложениях. А эта статья выглядит как реклама автором своего приложения, которое построено по карточной системе, т.е., показывается слово и надо выбрать его перевод.
Duolingo отличное приложение, с этим не спорю. Но, к сожалению, лично мне оно не дало результата. Возможно, я просто не его целевая аудитория.
Эта статья не про конкуренцию с крупными продуктами, а скорее про путь: как я, столкнувшись с языковым барьером, сделал простое MVP, чтобы заодно и учиться, и развиваться как разработчик. Никакой рекламы — сейчас всё крутится на локалхосте, и выключается, когда я сплю 😅
У Duolingo цель - удерживать посетителей и с этим оно прекрасно справляется. В этом смысле результат есть, но вот процесс затягивается. На сколько не проверял, почти сразу перешел на Busuu и AI языковые обучающие приложения, где можно говорить.
Я пробовал Duolingo на протяжении месяца в мае прошлого года. Да, основная проблема в том, что изучение языка слишком затянуто. Это может быть удобно, когда вы учите язык для себя. Но когда вы с чемоданом приехали в другую страну - приоритеты меняются круто. Именно поэтому я выбрал альтернативный вариант, который помог в сжатые сроки адаптироваться к окружению. На прошлой неделе я быстро перепрыгнул все модули в Duolingo, сдав комплексные тесты.
выглядит как реклама автором своего приложения
Автор написал кучу кода и поделился этим с сообществом, хабр для этого задумывался, ващета.
Дуолинго хорош, если ты язык уже знаешь, или же язык близок к тому, который ты уже знаешь. Новые и непонятные языки там можно выучить разве что до уровня "добрый день, суп горячий, медведь лежать спать". Позанимайтесь пару месяцев турецким, венгерским или любым кельтским (там их как минимум три), потом расскажите об успехах :)
Почему не вышло хотя бы до C1?
Сразу простите за негатив, но у нас в школьные годы были подобные приложения, которые ИМХО были бесполезны. Я просто не понимаю зачем это все если есть Анки? Тем более что вот это очень большая ошибка:
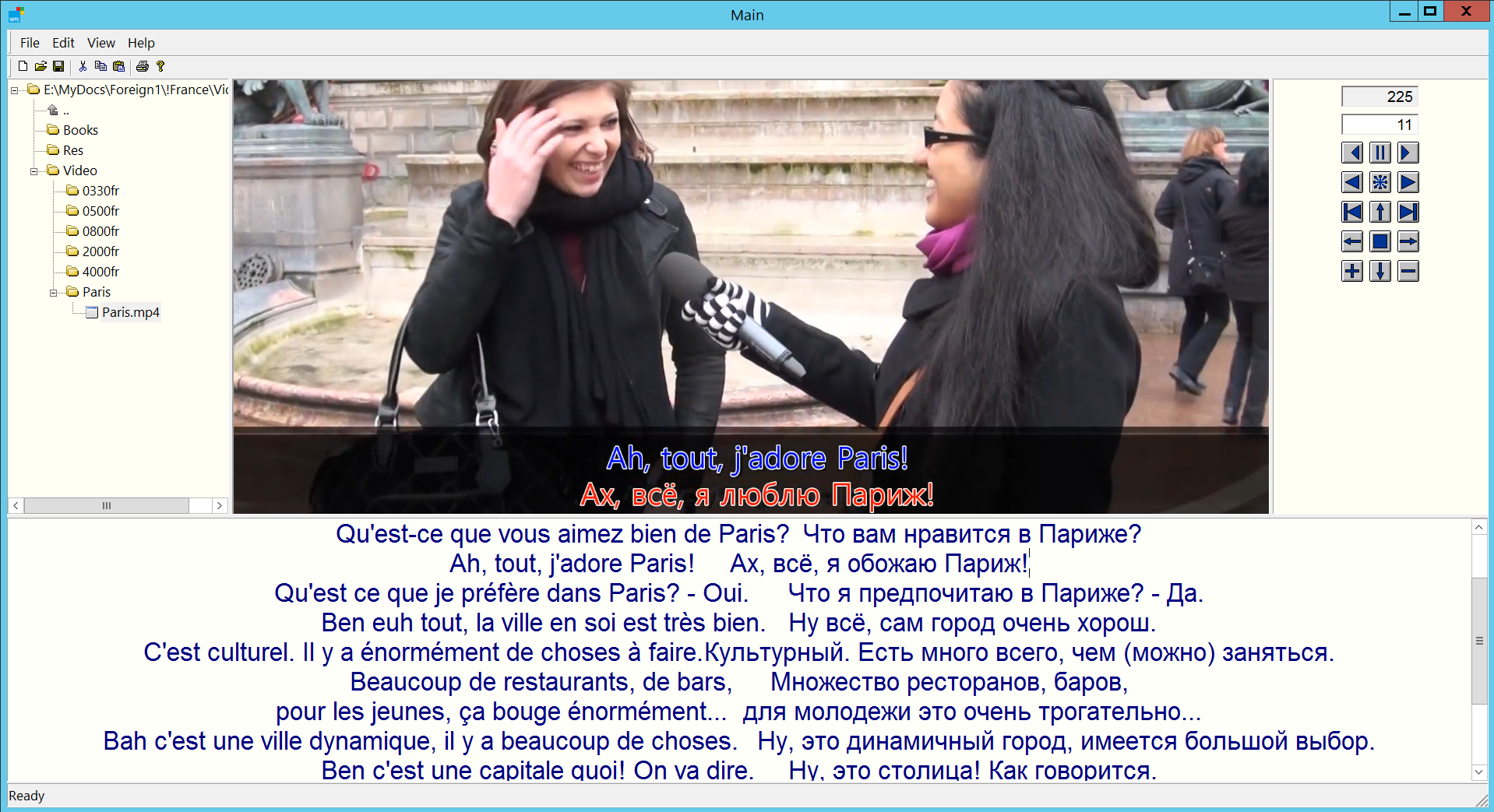
Идея проста: загружается одно слово и четыре варианта перевода. Нужно выбрать правильный ответ.
Почему? Ну вот смотрите, вы знаете как переводится Ironmonger? Допустим, что не знаете. А теперь смотрите, вот четыре варианта ответа:
Кот
Ручка
Полотенце
Торговец скобяными изделиями
А тут смотрите и получается что уже знаете. Плюс, если ответы не рандомятся и не рандомится их порядок, то после какого-то количестве итераций вы даже вопрос читать не будете т.к. мозг привыкнет что из этой конфигурации слов правильно будет вот это вот..
Но только вот это не реальный случай. В реальной жизни у вас не будет вариантов. У вас есть исходное слово- вам нужен перевод здесь и сейчас. Вот поэтому для пополнения словарного запаса Анки лучше всех ИМХО.
По поводу загружаемого словаря. По моему опыту гораздо эффективнее вести свой словарь. Т.е. вы читаете, смотрите что-то и все слова, которые не знаете, добавляете в свой Анки словарь и так его учите. Например, сейчас у меня так накопилось уже почти 6к слов. Но это слова, которые я знаю что мне нужны, а не за меня их выбрали.
Я не утверждал, что это единственный способ изучения. Я рассказал об опыте, который был лучшим для меня и который помог мне в сжатые сроки решить мои проблемы с адаптацией. Все остальные споры по поводу эффективности методик я бы оставил профессиональным коучам и преподавателям из инстаграма - я абсолютно точно не претендую на звание одного из них)
Я рассказал об опыте, который был лучшим для меня и который помог мне в сжатые сроки решить мои проблемы с адаптацией.
А чем вам Анки не подошел?
Смею предположить, что Анки прокачал бы только один язык, а своё приложение прокачало сразу три (PHP, SQL).
Насчёт прокачал, кстати, большие сомнения. Нормальный сервер для SQL не осилил, ограничился огрызком. Ну и нежелание выкладывать код, кстати, вполне объяснимо. У таких гениев со "своим MVC фреймворком" обычно дыра на дыре - от SQL инъекций до LFI и XSS. В общем, так же как с английским.
Нормальный сервер для SQL не осилил, ограничился огрызком.
Втаскивать в прототип полноценный SQL-сервер — типичный пример дизайна школоты.
обычно дыра на дыре
О, мсье — ясновидящий?
Элементарно, Ватсон! Вот предыдущее поделие этого же персонажа. Разумеется, про контекстное экранирование он даже не слышал.
Ну в целом не нужно быть ясновидящим, чтобы предсказать дыры в коде у новичка, на ходу учившего язык в перерывах между перебиранием карточек. Тут скорее будет сюрпризом, если дыр не окажется.
Текущий *.db файл весит 20кб и не требует дополнительного развертывания. Можете назвать хоть одну причину что бы заменить его на MySql или любую другую серверную СУБД, кроме комплекса неполноценности?
Ну гипотетически, через Анки можно и PHP и SQL учить, почему нет. Хотя в контексте практики конечно писать свой лесопед лучше ;)
Как выпустишь его, надо будет попробовать)
ОМГ, реклама убогого приложения с дизайном из 90-х под соусом "я выучил английский!" Ага-ага, ультра-модным способом из позапрошлого века - перекладыванием карточек.
Да ещё и с неграмотными переводами. "Случайно" тут переводится корявым программистским "randomly" а не человеческим "accidentally". Но главное даже не это, а давно всем известные минусы этого способа - полное отсутствие грамматики и многозначность слов в английском, когда одно и то же слово (взятое само по себе) может быть и существительным, и прилагательным, и глаголом, и наречием. Не говоря уже о совсем разных смыслах слова, как, например, log или sound. Так и будет счастливый финалист этой программы, обвешанный медальками геймификации, читать по складам - "Бревно в"...
Это позволило быстро разрабатывать прототипы приложений, не загружая множество различных зависимостей, как в случае с Laravel, что значительно повлияло на скорость работы приложения.
ОМГ, снова этот детский лепет. Загрузка зависимостей у него влияет и на скорость разработки приложения (которая получается сравнимой с парой минут, требуемых на загрузку. Да с такой скоростью этот вундеркинд скоро выкинет всех нас из профессии!) и - внезапно - на скорость работы приложения. Видимо этот гений полагает, что зависимости загружаются каждый раз снова при каждом обращении к приложению
На втором курсе преподаватель орал на студентов, которые для счетчиков вместо byte использовали integer, потому что он потребляет в 4 раза больше памяти. 7 раз отмерь, 1 раз скомпилируй. Но ваше стремление к изобилию вычислительных ресурсов похвально. Как только найду применение контейнерам и тяжеловесным ORM в данном приложении - сразу перепишу на laravel, а может и на symfony. Насчет дизайна полностью согласен, но могло быть и хуже, командная строка dos, например.
PHP — это не профессия.
Как я прокачал английский до B2 в США, разработав своё языковое приложение
Ничто не ново под Луной!
Я же выбрал, пожалуй, самый неочевидный способ – решил просто читать словарь.
Ну, есть более интересные способы. Например, смотреть видео с озвучкой, словами и переводом. См., допустим, мои ролики (у меня интерес к французскому языку):
«Французско-русский словарь - Часть 01а» – https://www.youtube.com/watch?v=Oevqk0z5SrA .
Если нужно просто научиться читать по-французски, то:
«Французская фонетика - чтение по слогам» – https://www.youtube.com/watch?v=42XI2ad6OwE .
Но, для работы со словами и фразами (по методу «запоминание руками + интерактивный звук») можно воспользоваться моей программой «L'école» (см. мою статью: «Новая компьютерная программа для запоминания иностранных слов и фраз» – https://habr.com/ru/articles/848836/ ). Там приведены примеры и по другим иностранным языкам. Кроме того, готовлю дополнительные материалы для публикации.
Второй подход это использование двуязычных субтитров к оригинальным видео, лучше в виде внешних файлов. Демонстрацию можно посмотреть на моих каналах:
https://www.youtube.com/@scholium9807
https://dzen.ru/id/66ef0791df72c165d37a34ea
https://my.mail.ru/mail/emmerald/video/_myvideo
Есть также мое описание процесса создания таких субтитров: «Создание двуязычных субтитров к видео, распознавание и перевод речи» – https://habr.com/ru/articles/862716/ .
Первым делом предстояло выяснить, как получить словарь слов, желательно с разбивкой по секциям. Изучив GitHub, я не нашел ни одного адекватного словаря в формате JSON.
Плохо искали. См. сайт https://kaikki.org (с разными языками), на который я вышел из Гитхаба – https://github.com/hbenbel/French-Dictionary .
В какой-то момент я получил бан за слишком активные запросы. Эту проблему удалось обойти, хаотично подставляя различные прокси-серверы из списка в 500 штук.
Несколько часов мучений спустя, у меня наконец был JSON-словарь из 8000 слов.
Ну, я без особых проблем скачивал онлайн-словари и mp3-файлы к ним на десятки тысяч слов, используя собственное расширение Хром. Правда, приходилось выставлять паузу – пять секунд, между запросами, зато, вэпээн-ом пользовался редко. Полученные html-страницы, естественно, пришлось конвертировать в более удобоваримый вид, но, в итоге, нужные мне данные я получил.
На всякий случай я сделал обе языковые пары: англо-русскую и русско-английскую.
В моей обучающей программе это делается на автомате. Плюс есть еще режим «Видео» (всего поддерживается шесть режимов работы с данными).
В принципе, ваш вариант изучения языка и подготовки данных для своей обучающей программы, ничуть ни лучше моего. У меня тоже и разные языки есть, в т.ч., испанский и немецкий (правда, данных по ним пока мало, но это дело наживное).
Кроме того, я заинтересовался идеей написания собственного самоучителя по французскому языку на французском языке (!) плюс видео к нему. Смотрите первый пример на эту тему:
001-ФранцузскийАлфавит.mp4 : https://disk.yandex.com/i/G4pJZ__AKhtHsw ,
001-ФранцузскийАлфавит.pdf : https://disk.yandex.com/i/DwEX79lOXZlJyw .
Сейчас, я нашел классный канал на Ютубе с тысячами французско-английских фраз. Обычно, для получения встроенных субтитров я использовал свою неопубликованную программу «МедиаТекст» (см. скриншот: http://scholium.webservis.ru/Pics/MediaText.png ). Здесь можно было бы повторить этот трюк, причем, в итоге, получилось бы два типа данных, с озвучкой: французско-русский и англо-русский варианты. Проблема только в том, что в этих видео оригинальных фраз в несколько раз меньше, просто они чередуются в разном порядке. Однако чередовать я могу и в своей программе, поэтому мне нужны только оригинальные фразы с их озвучкой.
{kind=link}
Для решения этой проблемы можно использовать либо ИИ-сервисы (но, для хорошего, бесплатного, только по десять минут, а у меня озвучки на многие часы) либо распознавание текста субтитров. Я пошел по второму пути и уже научился расщеплять символы по криволинейному контуру между ними. Теперь, вот, перешел к процедуре распознавания этих символов на базе протяженных метрик, на Питоне. Раньше я использовал для этого свою программу на C++/WTL, непосредственно работающую с видео, которая использовала точечные метрики, строго для определенного шрифта. Протяженные метрики, на Питоне, обещают быть более гибкими…
Автор, оффтоп вопрос если можно. Как вы попали в США? Грин карта?
Зубрение слов бесполезно. Слова хорошо набираются просто из книг и фильмов для удовольствия.
Настоящая проблема - активный словарный запас, когда вы не просто знаете слово, а умеете им пользоваться для выражения мыслей. И тут есть два способа как его активировать (не считая самого лучшего - репетитора) - перевод с родного языка и объяснения на тему. Ну и куда здесь без помощи AI.
Как то потеряв работу, за три месяца без дела и осененный этими идеями я создал сайт. Он полу-живой, никак нет времени допилить. Когда-то точно закончу, чтобы польский выучить. Хостится на a2b2.eu, если интересен подход.
Я за то, что бы люди экспериментировали и выбирали наиболее подходящий для них способ решения проблемы. Я не люблю критиковать чужие идеи и навязывать свои решения, но всегда готов к ненавязчивым дискуссиям, это помогает расширить кругозор и получить дополнительный опыт.
По поводу зубрения - каждый человек воспринимает, структурирует и запоминает информацию по своему. Важно найти наиболее эффективный способ, который лучше всего сработает в вашем случае. Именно поэтому индивидуальные занятия, как правило, более эффективны, чем групповые.
А в чём отличие от reword ?
В своё время много всяких мобильных приложений перебрал, понял, что слова зубрить, это может быть полезно только для самых частотных слов, может первая 1000 при нулевом знании языка. Для дальнейшего продвижения нужны обязательно примеры, чтобы контекст формировался. Изучаем мы не слова, а семантические единицы, которые могут состоять из нескольких слов или одно слово может их передавать десятки разных. Поэтому всё несколько усложняется. Одно слово может иметь и A1 и С2 семантическую единицу. Ну, и где-то с С1 уже нужно уходить от этих всех приложений и просто смотреть, слушать, говорить.
Именно поэтому я их не зубрил, а прочитал один раз для ознакомления, после чего длительное время закреплял. Дело в том, что многие слова в русском и английском выглядят похоже, пробегаясь по словарю я быстро выделил все эти слова и запомнил. Второй момент - чем больше слов я перебирал, тем больше улавливал по какому принципу они строятся. По своему опыту могу сказать, что словарный запас важнее - если вы знаете 5000 слов, вы сможете решить свои проблемы намного эффективнее, чем имея отличную грамматику и 600 слов в арсенале. Я часто упирался в словарный запас, но ни разу не упирался в знание грамматики. Если цель учить английский - можете учить методично. Если цель в сжатые сроки сломать языковой барьер - я бы сперва расширил словарный запас.
Как я прокачал английский до B2 в США, разработав своё языковое приложение