
В сортировках распределением элементы распределяются и перераспределяются по классам до тех пор, пока массив не отсортируется.
В самом общем случае это происходит по примерно одинаковой схеме. Элементы разбрасываются по классам по какому-либо признаку. Если это не привело к упорядочиванию массива, то происходит уточнение признаков принадлежности к классу и элементы раскидываются по уточнённым классам снова. И так происходит до тех пор, пока массив не станет упорядоченным.
В сортировках распределением почти всегда отсутствуют сравнения элементов между собой и их обмены. Главное — это принадлежит ли элемент к некоторому классу или нет, его сравнение с другими элементами редко играет роль.
Обычно у этих сортировок линейная сложность по времени (а не логарифмическая, как у эффективных сортировок обменами, слиянием, выбором или вставками). Также алгоритмы этого класса почти всегда требуют много дополнительной памяти, поскольку сгруппированные по классам элементы приходится где-то хранить.
Сортировки распределением хороши для упорядочивания целых чисел и строк. Сортировать ими же вещественные числа, обычно, неудобно. Также сортировки распределением прекрасно сортируют массивы, состоящие из повторяющихся чисел — чем больше повторений, тем меньше разных классов требуется.
Рассмотрим алгоритм, наиболее выпукло демонстрирующий вышеперечисленные свойства.
Статья написана при поддержке компании EDISON.
Мнение Заказчика: 10 плюсов программистов из EDISON
Это интересно и полезно знать: Завтрак программиста

Вёдерная сортировка :: Bucket sort
Другие названия — корзинная сортировка, блочная сортировка, карманная сортировка.
Раскидываем числа по корзинам, затем в каждой корзине раскидываем по более мелким корзинам и так до тех пор пока на каком-то уровне в корзинке только одинаковые элементы. Тогда из таких корзин самого нижнего уровня легко восстановить массив в упорядоченном состоянии.
Поясним на конкретном примере. Допустим, у нас есть неупорядоченный массив. Известно, что в этом массиве содержатся числа от 1 до 8.
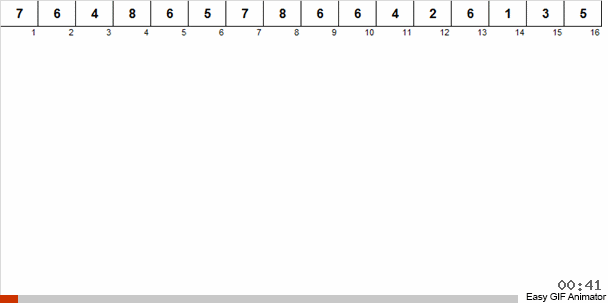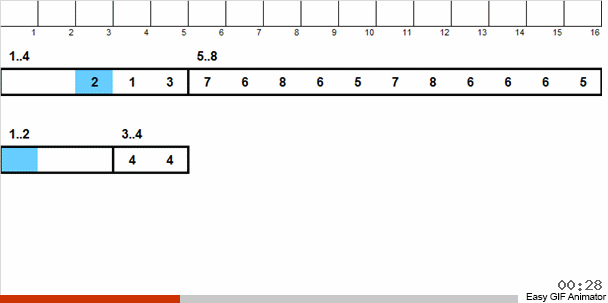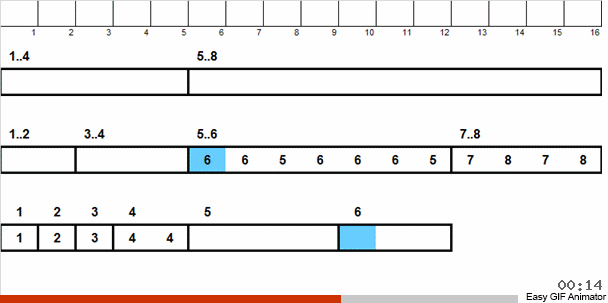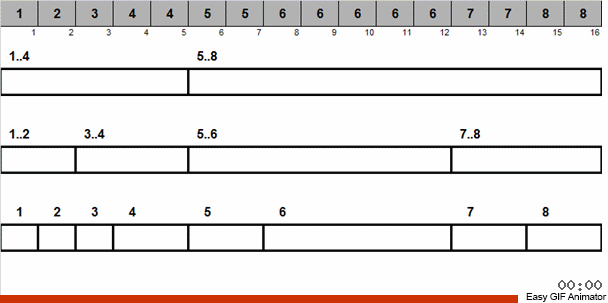
Мы раскидываем эти числа на 2 группы: в одну группу попадают числа от 1 до 4, во вторую — от 5 до 8. Затем числа в первой корзине распределяем по двум корзинам: в одной числа 1 и 2, а в другой 3 и 4. Эти корзинки тоже распределяем по лукошкам, в которых уже находятся числа одинакового размера. К той большой корзине, где содержатся числа от 5 до 8, применяем аналогичную рекурсию.
Затем из мелких корзинок, в каждой из которых содержатся одинаковые числа, мы в порядке старшинства возвращаем элементы в основной массив.
Вёдерная сортировка в таком виде не особо применима на практике, но она эталонно демонстрирует, как вообще работают все сортировки распределением.
Сортировка Таноса :: Thanos sort
Мне иногда присылают авторские сортировки и это как раз такой случай. Автор Андрей Данилин назвал её «Русская сортировка половинками», однако я её окрестил сортировкой Таноса. Или же, если формально исходить из используемых методов, можно назвать её средне-арифметическая вёдерная сортировка.
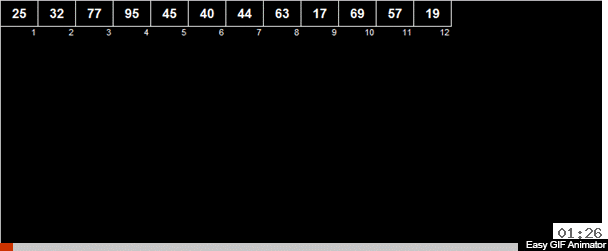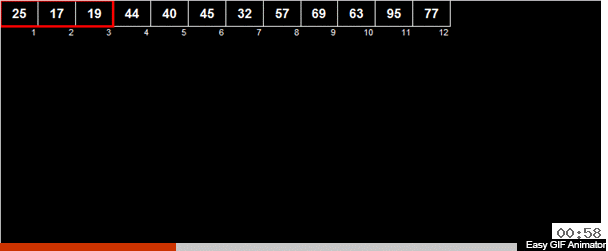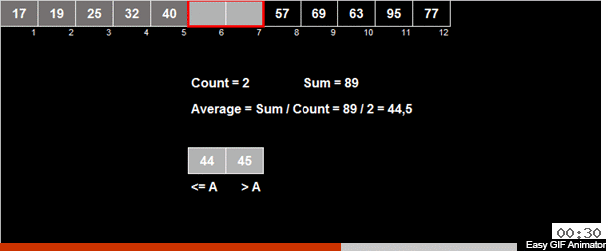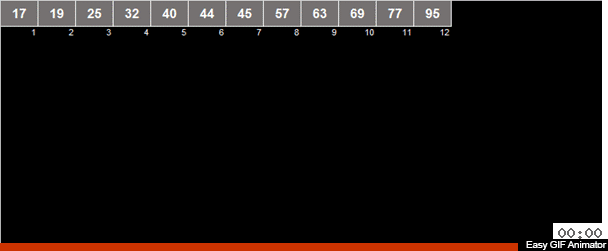
В массиве вычисляется средне-арифметическое элементов и затем все элементы распределяются на 2 группы. В одну группу идут элементы меньшие (или равные) средне-арифметическому, во вторую группу — большие чем средне-арифметическое. Затем эти же действия рекурсивно применяются к обоим группам — и так до победного конца.
Причём тут безумный титан? Если это рандомный массив, то, по большому счёту у элемента, при сравнении со среднеарифметическим, шансы 50/50 что он отправится в одну из двух групп.
Кстати, в Интернете мне попался другой шуточный алгоритм с таким же названием. Если массив не отсортирован, то тогда щёлкаем Перчаткой Бесконечности и отправляем выбранную случайным образом половину элементов массива в небытие. Если оставшиеся в живых образуют упорядоченный массив, то на этом свою великую миссию можно считать выполненной. Если ещё нет, то можно произвести ещё несколько щелчков.

Однако вернёмся к нашим распределительным сортировкам. Всех их можно распределить только по двум группам - сортировки подсчётом и поразрядные сортировки. Ну, если хочется, можно ещё выделить подсчётно-разрядные сортировки, т.е. те, которые можно отнести и к тем и другим.
Ещё есть гибридные алгоритмы (это такие, в которых используются методы разных классов, например, сортировка Тима — это помесь сортировки слиянием и сортировки вставками, интроспективная сортировка — это быстрая сортировка переходящая в сортировку кучей и т.п.), включающие в себя сортировки распределением, однако гибриды — это отдельный раздел. О них потом.
Вёдерная сортировка и средне-арифметическая сортировка Таноса относятся к сортировкам подсчётом.
Сортировки подсчётом
Основная идея — мы подсчитываем, сколько чисел содержится в каждом классе.
Сортировка подсчётом :: Counting sort
Считаем, сколько раз встречается то или иное число в массиве. Зная эти количества, быстро формируем уже упорядоченный массив.
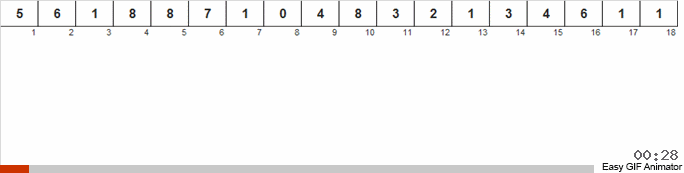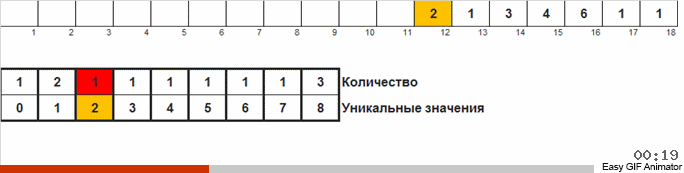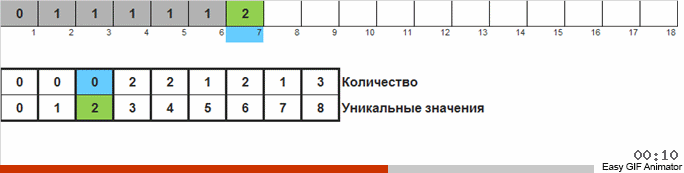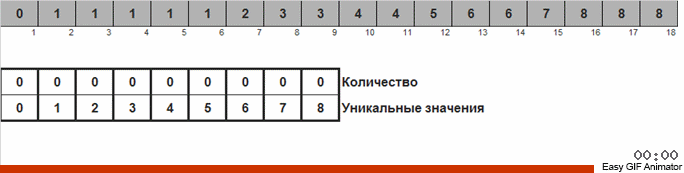
Для этой сортировки нужно знать минимум и максимум в массиве. Тогда генерируются ключи для вспомогательного массива, в котором и фиксируем чего и сколько раз встретилось.
Код на Python:
def CountingSort(array, mn, mx):
count = defaultdict(int)
for i in array:
count[i] += 1
result = []
for j in range(mn,mx+1):
result += [j]* count[j]
return resultГолубиная сортировка :: Pigeonhole sort
Проходим по массиву, если встречается новое число то заводим счётчик (как ключ вспомогательного списка) этого числа. Если число встречается не в первый раз, то просто срабатывает инкремент для этого счётчика.
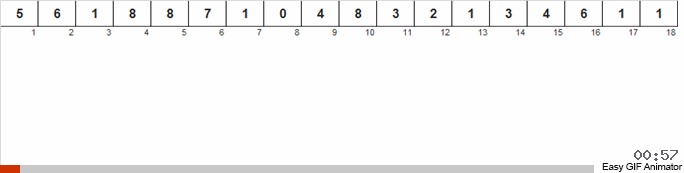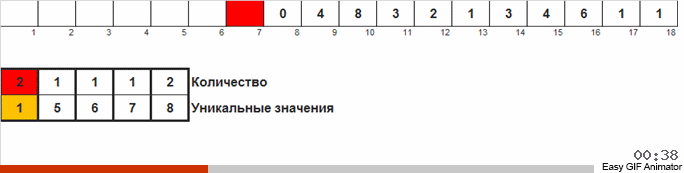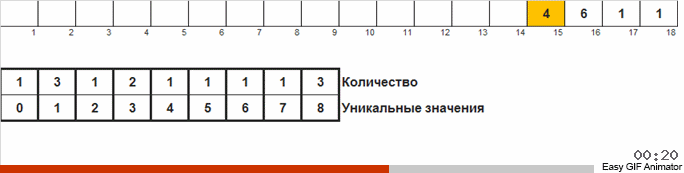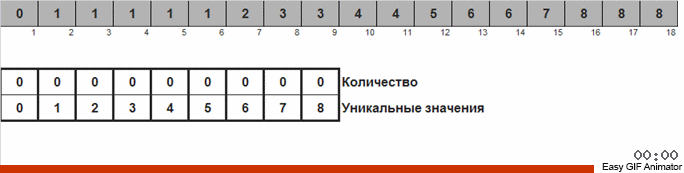
Отличие от предыдущего метода состоит в том, что в сортировке подсчётом мы сразу заводим счётчики для всех возможных чисел, которые, возможно, встретятся в массиве (можем себе это позволить, если известен максимум и минимум в массиве). Некоторые числа так и не встречаются и их счётчики показывают ноль. В голубиной сортировке мы заводим счётчики только для таких чисел, которые действительно встречаются в массиве. В сортировке подсчётом для счётчиков используется массив, а в голубиной сортировке — двусвязный список, позволяющий на ходу добавлять новые счётчики.
Этот способ иногда альтернативно называется сортировка Дирихле, потому что сам алгоритм является иллюстрацией различных следствий из принципа Дирихле.
Если N объектов, распределены по M контейнерам, и при этом N > M, то хотя бы в одном контейнере содержится более одного элемента.
Код на Python:
def PigeOnHoleSort(a):
mi = min(a)
size = max(a) - mi + 1
holes = [0] * size
for x in a:
holes[x - mi] += 1
i = 0
for count in range(size):
while holes[count] > 0:
holes[count] -= 1
a[i] = count + mi
i += 1Поразрядные сортировки
Мы распределяем числа в зависимости от того, какая цифра находится в том или ином разряде числа. Если мы сделаем это несколько раз для разных разрядов, то внезапно получаем отсортированный массив.
Поразрядная сортировка по младшим разрядам :: LSD radix sort

Двигаемся от младших разрядов к старшим и на каждой итерации распределяем элементы массива в зависимости от того, какая цифра содержится в разряде.
После очередного распределения мы возвращаем элементы в основной массив в том порядке, в котором элементы попали в классы при очередном перераспределении.
Для поразрядных сортировок важно, чтобы элементы рассматривались, как имеющие одинаковое количество разрядов. Если фактически количество разрядов отличается, то проблема решается припиской дополнительных нулей в качестве старших разрядов.
Поразрядная сортировка по старшим разрядам :: MSD radix sort

Сначала распределяем по старшим разрядам, от которых двигаемся к младшим.
Этот вариант сложнее в реализации, так как переход к нижним разрядам рекурсивно осуществляется внутри классов, а не среди всех элементов массива.
Но эта сложность вознаграждается тем, что MSD работает быстрее чем LSD. При проходе от младших разрядов к старшим приходится обрабатывать все разряды всех чисел, чтобы корректно отсортировать. Если же двигаться от старших к младшим, то по факту не приходится обрабатывать все разряды всех чисел, состояние отсортированности, как правило, наступает раньше.
Большинство поразрядных сортировок являются разновидностью именно более эффективной MSD. Особенно это полезно для сортировки строк, для этого как правило используется суффиксное дерево. Разберём в одной из последующих статей.
Подсчётно-поразрядные сортировки
Иногда распределительная сортировка одновременно является и подсчётной и поразрядной.
Бисерная сортировка :: Bead sort

Другие названия алгоритма: абаковая сортировка, сортировка гравитацией.
Про эту сортировку уже пару раз писал (1, 2), поэтому буду краток, только самую суть.
Допустим, каждое число в массиве — это набор шариков, количество шариков — это величина числа. Если числа расположить друг по другом как горизонтальные ряды этих шариков и затем сдвинуть до упора по вертикали, то получим упорядоченный массив.
Здесь фокус в том, что каждое число мы с помощью шариков представляем в унарной системе счисления. И фактически, мы просто подсчитываем сколько раз у всех чисел встречается каждый разряд.
BeadSort на Python в одну строчку:
#!/bin/python3
from itertools import zip_longest
def beadsort(l):
return list(map(sum, zip_longest(*[[1] * e for e in l], fillvalue=0)))Погодя разберём более сложные подсчётно-поразрядные сортировки, среди которых видное место занимает сортировка "Американский флаг".
Ссылки
Статьи серии:
- Excel-приложение AlgoLab.xlsm
- Сортировки обменами
- Сортировки вставками
- Сортировки выбором
- Сортировки слиянием
- Сортировки распределением
- Подсчётные сортировки с приблизительным распределением
- Сортировка «Американский флаг»
- Суффиксное дерево в поразрядных сортировках
- Сравнение сортировок распределением
- Гибридные сортировки
Excel-приложение AlgoLab заметно обновлено. Некоторые алгоритмы из сегодняшней статьи там появились впервые. Обновите, кто пользуется.
