Продолжаю тему межпроцедурных оптимизаций, введение в которую можно найти в предыдущем посте. Сегодня хочется немного порассуждать о подстановке функции (inlining) и о том, как подстановка влияет на производительность приложения.
Периодически приходится анализировать случаи, когда одно и тоже приложение, скомпилированное разными компиляторами, показывает различную производительность. Часто причиной является различие в подстановке, которая выполняется автоматически. Вдруг оказывается, что в одном случае подставляется один набор вызовов, а в другом несколько иной. В результате анализ конкурирующих компиляторов сильно осложняется, поскольку становится невозможным напрямую сравнивать какие-то горячие функции. Время их выполнения сильно зависит от того, какие вызовы были проинлайнены.
Подстановка — самая популярная межпроцедурная оптимизация, которая вместо вызова какой-либо функции вставляет ее тело в тело вызывающей функции. Какие задачи приходится решать компилятору при принятии решения о подстановке и как программист может улучшить производительность приложения с помощью этой оптимизации? Как решения об инлайнинге принимает компилятор Intel, я примерно знаю, но интересно проверить предлагаемые методы и на компиляторе gcc.
Почему подстановки улучшают производительность?
- Исчезают накладные расходы на вызов функции, т.е. не нужно выделять место на стеке для хранения аргументов вызова или записывать аргументы в регистры.
- Улучшается локальность кода. Вместо перехода на инструкции вызываемой процедуры, которые могут оказаться не в кэше, управление «плавно перетекает» на вставленные в результате подстановки строки кода.
- Большинство компиляторных оптимизаций связаны с обработкой графа потока управления (CFG). Поэтому такие оптимизации работают на уровне процедуры. Подстановка позволяет использовать для оптимизации тела подставленной процедуры весь контекст вызывающей процедуры. Благодаря этому после подстановки может быть получен выигрыш, например, от протяжки констант, от цикловых оптимизаций и т.п.
Может ли подстановка оказать негативное влияние на производительность? Легко. Благодаря подстановке может увеличиваться размер кода процедуры, количество локальных переменных, размещаемых на стеке. Оба эти фактора могут повлиять на принцип локальности кода. Т.е. из-за увеличения объема исполняемого кода нужные инструкции и данные реже оказываются в кэше и выполнение замедляется. К тому же разрастание кода негативно влияет на время компиляции и размеры получаемых исполняемых файлов (что может быть особенно критично для мобильных архитектур). Хорошим исключением для подстановки являются «маленькие» функции, т.е. такие, тело которых содержит меньше инструкций, чем затраты на вызовы таких функций. Таким образом, как и большинство оптимизаций подстановка – палка о двух концах. И компилятору, и программисту нужны критерии, определяющие, какие функции нужно стремиться подставлять в первую очередь, какие во вторую, а какие совсем не подставлять.
Автоподстановщики
Итак, можно улучшать производительности за счет подстановки. Естественно, такая благодатная область для улучшения производительности приложения не может не оказаться под пристальным вниманием оптимизирующих компиляторов. Компиляторы умеют делать подстановки автоматически. Пользователь добавляет одну опцию, а оптимизирующий компилятор сам выбирает какие вызовы оставить нетронутыми, а какие подставить.
Если посмотреть опции компилятора Intel (icc –help), то легко обнаружить кнопку включения этого механизма.
-inline-level=<n>
control inline expansion:
n=0 disable inlining
n=1 inline functions declared with __inline, and perform C++
inlining
n=2 inline any function, at the compiler's discretion
Из этого описания опций видно, что существует несколько режимов работы. Вообще запретить подстановку, использовать директивы для компилятора, выставленные программистом, дать возможность компилятору самому выбирать объекты для оптимизации. Т.е. опция –inline-level=2 — это то, что нам нужно, и именно эта опция используется по умолчанию. Также в этом списке огромное кол-во опций вида:
inline-max-total-size=<n>
maximum increase in size for inline function expansion
-no-inline-max-total-size
no size limit for inline function expansion
-inline-max-per-routine=<n>
maximum number of inline instances in any function
-no-inline-max-per-routine
no maximum number of inline instances in any function
-inline-max-per-compile=<n>
maximum number of inline instances in the current compilation
-no-inline-max-per-compile
no maximum number of inline instances in the current compilation
-inline-factor=<n>
set inlining upper limits by n percentage
Отсюда понятно, что постановка задачи для автоматического подстановщика — осуществить подстановки функций так, чтобы добиться наилучшей производительности и уложиться в определенные рамки увеличения кода программы. Видно, что в списке есть опции, контролирующие разрастание кода программы в целом, так и разрастание каждой процедуры.
Критерий полезности подстановки
Давайте попытаемся оценить качество работы компилятора при выполнении автоматической подстановки. Для этого необходимо выработать какой-то очевидный критерий полезности подстановки и понять, можно ли обеспечить его использование.
На мой взгляд, можно сформулировать следующий приблизительный критерий выгодности подстановки. Каждая подстановка несет в себе некоторые издержки, которые ухудшают качество всей программы в целом, но при этом улучшается качество конкретного фрагмента кода, где выполнена подстановка.
Самый простой случай, когда подстановка невыгодна, на мой взгляд, выглядит так:
If (almost_always_false) {
Foo();
}
В этом случае мы получили все негативные последствия от подстановки функции Foo, «пригрели» на стеке вызывающей функции ее локальные переменные, увеличили размер кода вызывающей функции. Но функция практически никогда не вызывается и наш локально улучшенный фрагмент кода не используется, то есть издержки не окупаются. Таким образом, при принятии решения о подстановке хорошо бы знать, насколько горячим является тот или иной вызов. Предлагаемый критерий следующий: чем чаще при выполнении вызывается функция, тем выгоднее ее инлайнить. Вторым очевидным фактором является размер функции. Чем меньше размер функции, тем выгоднее ее подставлять, поскольку в этом случае нам удастся вместить больше подстановок в границы, определяемые порогом расширения программы.
Очевидно, что можно придумать еще много различных критериев полезности подстановки, например, считать, что выгоднее инлайнить вызовы внутри циклов, если инлайнинг поможет векторизации или выгоднее инлайнить вызов с константными аргументами и т.д. Не совсем понятно только, как может компилятор получить эти знания до принятия решения об инлайнинге без усложнения анализа и увеличения времени компиляции. Некоторые случаи, когда подстановка выгодна, являются не очевидными до того момента, пока эта выгода будет получена. Например, при межпроцедурном анализе нам вряд ли удастся понять, что благодаря подстановке мы гарантировано получим выгоду от векторизации. Поскольку для этого нужно сделать почти всю ту работу, которая делается при оптимизации процедуры, перед принятием решения об инлайнинге.
При наличии ограничений на разрастание кода очень важным становится порядок, в котором принимается решение об инлайнинге. Компилятор обходит в каком-то порядке все вызовы и принимает решение о подстановке. При этом он изменяет размер вызывающей функции и проверяет, не превышен ли лимит разрастания кода. Если сначала были сделаны какие-то подстановки внутри вызываемой функции, то размер ее кода уже не равен оригинальному в момент принятия решения об подстановке. Можно манипулировать эвристиками, принимающими решение о выгодности, но если в момент принятия решения лимиты разрастания кода уже превышены, то компилятор такую функцию инлайнить не будет. Для достаточно больших проектов ситуация достижения лимитов разрастания кода очень обыденна.

Подсчитать размер кода подставляемой функции легко, хотя после подстановки или каких-то оптимизаций он может сильно измениться, но компилятор во время компиляции не обладает знанием, какие части кода вызывающей функции являются «горячими», а какие нет. В компиляторе есть профилировщик, который «глубокомысленно взирая» на код процедуры пытается оценить вероятность того или иного перехода, и, благодаря его работе, каждому непрерывному фрагменту обрабатываемой процедуры присваивается какой-то вес. К сожалению, оценки профилировщика очень приблизительны и вызывают аналогию с известным анекдотом про блондинку, которую спросили о вероятности встретиться с динозавром. «50 на 50, или встречу или нет» — ответила блондинка. И была абсолютно права с точки зрения логики и оптимизирующего компилятора! Авторы анекдота предполагают, что блондинка должна что-то знать о динозаврах. Но если знаний нет, то и ответ вполне логичен. Практически все переходы if получают вероятность 50%. Ну еще можно погадать на кофейной гуще на тему, сколько итераций имеет среднестатистический цикл for c неконстантными нижней и верхней границами.
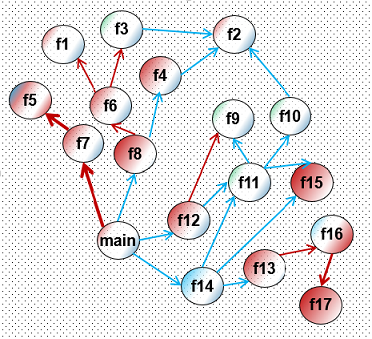
В общем, задача определения веса кода сложна уже на уровне одной функции. А что же можно сказать о весе того или иного вызова в рамках всей программы? Может оказаться, что функция имеет внутри себя очень «горячий» вызов. Да только может случиться так, что сама функция страшно «холодная» и практически никогда не получает управления. Получается, что по-хорошему нужно иметь метод оценки важности каждого вызова внутри программы, который бы анализировал и граф вызовов, и граф потока управления для каждой функции, и выставлял бы на основе такого анализа вес для каждой дуги в графе вызовов. Но такие оценки могут оказаться совсем неточными. Реальный же вес каждого вызова очень сильно зависит, например, от набора входных данных.
Собственно, эту идею иллюстрирует рисунок к моему посту. Здесь на основе анализа CFG я попытался выделить цветами холодные и горячие вызовы (грани графа вызовов). Красный цвет обозначает «горячие» участки внутри процедуры, ну а красные стрелки горячие вызовы. К сожалению, как уже подчеркивалось, вся эта раскраска может быть различна для разных входных наборов данных. Расставить правдоподобно веса при компиляции очень трудно.
Тестирование критерия
Тем не менее, предложенный критерий достаточно прост и в соответствии с ним можно сказать, что при прочих равных выгоднее подставлять вызовы, встречающиеся в циклах. Менее выгодно подставлять вызовы встречающиеся после проверки различных условий. Кажется что это очевидно? Давайте проверим, используют ли компиляторы такое соображение? Напишем что-то предельно очевидное. В данном примере подставляется одна и та же функция, поэтому с точки зрения размера вызываемой функции все вызовы одинаковы. Частота использования вызовов зависит от того, какие константы введет пользователь.
Cat main.c
#include <stdio.h>
static void inline foo(int i) {
printf("foo %d\n",i);
}
int main() {
int n,k,m;
printf("Enter 3 integer numbers\n");
scanf("%d",&n);
scanf("%d",&k);
scanf("%d",&m);
foo(1);
for(int i=0; i<n; i++) {
foo(2);
}
for(int i=0; i<n; i++) {
for(int j=0; j<m; j++) {
foo(3);
}
}
foo(4);
foo(5);
if(n<k)
foo(6);
if(n<m)
if(k<m)
foo(7);
foo(8);
foo(9);
}
Интересно посмотреть, в каком порядке компилятор Intel будет эти вызовы инлайнить. Это легко исследовать, добавив в строку компиляции опцию –inline-max-total-size=XX и постепенно меняя значение этой переменной от 0 в сторону увеличения.
icc -std=c99 -inline-max-total-size=XX -ip main.c init.c
Выясняется, что порядок подстановок в main будет следующий: foo(7), foo(9), foo(8), foo(6), foo(3), foo(5), foo(2), foo(4), foo(1).
Видно, что в данном случае соображения о «весе» каждого вызова не используются. Компилятор не пытается угадать, какие вызовы происходят чаще.
Примерно аналогичную процедуру я проделал и с gcc.
Строка компиляции была следующая:
gcc –O2 --param large-function-insns=40 --param large-function-growth=XX -std=c99 main.c init.c -o aout_gcc
Опция –O2 включает в себя -finline-small-functions, и в этом случае gcc подставляет «маленькие» функции, подстановка которых, по идее, не сильно влияет на размер вызывающей функции.
Опция –O3 включает в себя -finline-functions, когда все функции рассматриваются как кандидаты для подстановки.
Я установил параметр large-function-insns так, чтобы моя функция main стала «большой» и ее расширение контролировалось параметром large-function-growth. Увеличивая числовое значение, начиная с нуля, получаем, в каком порядке делает подстановки gcc для _O2: foo(9), foo(8), foo(7), foo(6), foo(5), foo(4), foo(3), foo(2), foo(1). Т.е. gcc делает подстановки строго по порядку. С –O3 порядок такой: foo(3), foo(9), foo(2), foo(8), foo(7), foo(6), foo(5), foo(4), foo(1). Мне этот порядок нравится больше. По крайней мере, gcc проявил уважение по отношению к вызовам внутри циклов.
Результаты тестирования. Можно ли помочь компилятору?
Этот эксперимент показал, что порядок, в котором компиляторы осуществляют подстановку, может быть не оптимальным. Компилятор может подставить «невыгодные» вызовы, после этого достичь порога расширения обрабатываемой функции и прекратить свою с ней работу. В итоге пострадает производительность. Если, анализируя свое приложение, вы видите в горячем месте какие-то незаинлайненные функции небольшого размера, то возможны две причины такой ситуации: компилятор не счел конкретный вызов выгодным для подстановки или решение о подстановке не было принято из-за превышения порога расширения кода. Повлиять на это можно, изменяя пороговые значения или навешивая на функцию атрибуты типа inline. Поскольку изменения пороговых величин невозможно сделать для конкретной функции, то такое изменение вызовет увеличение размера всего приложения. То же самое можно сказать о атрибуте inline. Аттрибут будет воздействовать как на «горячие», так и на «холодные» вызовы. При этом inline не гарантирует подстановку, если уже превышены пороги расширения кода. Более мощным аттрибутом является always_inline. В этом случае функция всегда будет заинлайнена.
Более адресно на подстановки можно влиять с помощью прагм. Прагмы воздействуют на конкретный вызов, и с их помощью можно добиться более точного целеуказания, что именно нужно инлайнить. Существуют #pragma inline, #pragma noinline, #pragma forceinline. #pragma inline воздействует на решение компилятора и помогает, если еще не превышен порог расрастания кода, но компилятор не считает подстановку выгодной. #pragma forceinline – обязует компилятор сделать подстановку.
Возращаясь к нашему примеру. Подстановка аттрибута inline никак не поможет в рассматриваемом примере. Можно попросить компилятор сделать подстановку более настойчиво и подставить в код определение функции foo с аттрибутом always_inline:
static void inline foo(int) __attribute__((always_inline));
Это приведет к тому, что все вызовы будут подставлены (несмотря на нарушения порогов расширения). У этого метода очевидный недостаток – будут подставлены и «холодные» и «горячие» вызовы. Более оптимальным является использование прагм. Переписываю код функции main в таком виде:
int main() {
int n,k,m;
printf("Enter 3 integer numbers\n");
scanf("%d",&n);
scanf("%d",&k);
scanf("%d",&m);
foo(1);
for(int i=0; i<n; i++) {
#pragma forceinline
foo(2);
}
for(int i=0; i<n; i++) {
for(int j=0; j<m; j++) {
#pragma forceinline
foo(3);
}
}
foo(4);
foo(5);
if(n<k)
#pragma noinline
foo(6);
if(n<m)
if(k<m)
#pragma noinline
foo(7);
foo(8);
foo(9);
}
Т.е. получился рабочий алгоритм улучшения производительности приложения:
- Построить приложение.
- Собрать информацию о горячих участках приложения с помощью, например, Vtune Amplifier.
- Проверить, есть ли на этих участках неподставленные вызовы и заинлайнить их с помощью прагм.
- Проверить, как это сказалось на производительности приложения.
Критерий выгодности подстановки и динамический профилировщик
Понятно, что такой метод является ресурсно-затратным, особенно из-за использования Amplifier'а и необходимости исследовать что-то глазами. К счастью, есть достаточно надежное средство оптимизации подстановок – динамический профилировщик. Динамический профилировщик используется для того, чтобы получить представление о горячих участках программы и для того, чтобы оценить частоту вызовов тех или иных функций.
Провожу следующий эксперимент с первоначальным текстом моей минипрограмки:
icc -std=c99 init.c main.c -prof_gen -o prof_a
./prof_a < 345.txt >& prof_out
Здесь с помощью опции –prof_gen было создано инструментированное приложение. Затем это приложение было запущено, в результате его работы появился файл с расширением dyn, содержащий собранную статистику о работе приложения. Запуск компилятора с опцией –prof_use позволяет использовать эту статистику для оптимизации приложения. Файл 345.txt содержит ввод констант 3,4,5. Манипулируя опцией –inline-max-total-size получаю порядок, в котором компилятор подставляет функции.
icc -std=c99 -prof-use -inline-max-total-size=XX -ip main.c init.c
Порядок получается такой: foo(3), foo(2), foo(7), foo(9), foo(8), foo(7), foo(6), foo(5), foo(4), foo(1). Если посмотреть на вывод приложения, то понятно, что большинство вызовов были сделаны 1 раз и только foo(3) и foo(2) вызывались чаще. Благодаря динамическому профилировщику компилятору удалось более качественно определить порядок функций для подстановки.
Теперь поменяем входные данные для констант (n=5, k=4, m=3). В этом случае foo(6) и foo(7) не вызываются. Удалим (!) предыдущий файл со статистиками и, повторив эксперимент, получим новый порядок: foo(3), foo(2), foo(9), foo(8), foo(5), foo(4), foo(1). Вызовы foo(6) и foo(7) не были подставлены даже при большом пороге расширения кода. (Что безусловно радует).
Если не удалять файл со статистиками, то получим файл, отражающий статистику двух запусков.
Ну и аналогично сделаем такое же исследование для gcc 4.9.
gcc -O2 -fprofile-generate -std=c99 main.c -o aout_gcc_prof
./aout_gcc_prof < 543.txt
Появились файл со статистиками c расширением gdca.
gcc -O2 -fprofile-use --param max-unrolled-insns=0 --param large-function-insns=40 --param large-function-growth=XX -std=c99 main.c -o aout_gcc
Манипулируя c XX можно увидеть, что после получения информации от динамического профилировщика, компиляторы gcc и icc ведут себя одинаково, т.е. делают подстановку в соответствии с реальным весом каждого вызова.
Рассматривание кода при различных опциях и тем более в случаях различных компиляторов бывает достаточно интересно. Вот, например, в момент, когда компилятор gcc уже подставил foo(3), но порог расширения кода не позволил подставить foo(2), gcc сделал клонирование функции foo для вызова с 2. То есть создал новую функцию без аргументов с затянутой внутрь константой 2. При этом оба компилятора попытались улучшить локальность кода и вынесли «холодный код» в отдельную локацию. Icc в конец процедуры main, а gcc создал для этого отдельную секцию main.cold. При запуске инструментированного компилятора с входными данными 543.txt в эти секции попали вызовы foo(6) и foo(7).
Выводы
Конечно, описанный здесь эксперимент не является полным, и его можно было бы расширить, проанализировав, учитывает ли компилятор, формируя очередь вызовов для подстановки, другие факторы, например, размер функции для подстановки. Можно было бы попытаться понять в каком порядке обходится граф вызовов и т.д. Но в целом получился следующий вывод. Без динамического профилировщика компиляторы не пытаются угадать возможный «вес» или возможную частоту выполнения того или иного вызова. Соответственно, порядок подстановок выглядит достаточно случайным. В случае использования динамической профилировки, когда вес каждого вызова определяется экспериментально, оба компилятора используют эту информацию, и в результате порядок подстановок вполне соответствует предложенному здесь критерию. Т.е. наилучшую пользу от подстановок можно получить с использованием динамического профилировщика.
Ну а разработчики могут эффективно использовать при своей работе прагмы, чтобы подсказать компилятору какие вызовы следует инлайнить в первую очередь. Если программисту ясно, что какие-то вычисления будут выполняться редко, то имеет смысл выносить их в отдельные функции и запрещать их подставлять директивно. Это улучшит локальность выполняемого кода и, скорее всего, приведет к небольшому выигрышу в производительности за счет более оптимального использования подсистемы кешей.
Прекрасная блондинка и динозавр заимствованы из общедоступных ресурсов интернета, не содержащих указаний на авторов этих материалов и каких-либо ограничений для их заимствования:
1. www.pinterest.com
2. solnushki.ru
