Часто от приложения требуется максимально возможная производительность, и нередко помочь ее достигнуть может переход на новую платформу. А дополнительный прирост производительности может быть получен не только за счет архитектурных изменений новой платформы, т.е. увеличения частоты процессора, пропускной способности памяти и прочих изменений, но и за счет использования новых наборов команд процессора. Этот подход и будет рассмотрен в данной статье на примере векторных инструкций, появлявшихся последовательно в процессорах Intel от SSE до нового набора инструкций AVX 3.1, опубликованного недавно в соответствующей спецификации на сайте компании Intel.
Автор данной статьи принимает участие в разработке библиотеки Intel IPP, поэтому в данной статье рассматривается прирост производительности на примере одной из функции из данной библиотеки. Хочется надеяться, что данная статья будет полезна следующим категориям читателей:
Помимо этих категорий читателей, разработчикам, заинтересованным в оптимизации своего приложения и желающим минимизировать свои затраты на низкоуровневую оптимизацию, данная статья может помочь познакомиться поближе с IPP библиотекой.
API данной функции выглядит следующим образом.
Функция читает исходное float изображение по указателю pSrc с шагом в srcStep между строками и размером width x height, переставляет каналы в каждом пикселе в соответствии с новым порядком dstOrder и записывает результирующее изображение по указателю pDst. Фукнция также может записать указанное пользователем фиксированное значение val в канал. Допускается дублирование каналов в выходном изображении. Схема работы функции представлена на рисунке 1.

Надеемся, что читатель уже знаком с понятием векторных регистров, если же нет, то можно ознакомиться и воспользоваться удобным навигатором интринсиков.
Итак, посмотрим, как можно было бы векторизовать, т.е. переписать код этой функции с использованием векторных регистров SSE. В соответствии с логикой функции, нам необходимо осуществить перестановку float элементов внутри векторного регистра, поэтому нам нужны соответствующие инструкции перестановки элементов. К таким инструкциям можно отнести следующие инструкции из набора SSE:
Данные инструкции очень полезны и для нашей задачи они тоже могут быть использованы, но возникает следующая проблема. Инструкция SHUFPS имеет непосредственный операнд imm8, формирующий перестановку элементов. Третий параметр данной инструкции это imm8 — значение, т.е. некая константа. При попытке же использовать в интринсике переменную компилятор выдаст ошибку. А инструкции UNPCKHPS/UNPCKLPS чередуют элементы в регистрах лишь единственным способом. Допустимых вариантов перестановки каналов, указываемых в dstOrder довольно много и поэтому для реализации всех возможных комбинаций пришлось бы разработать код со множеством веток и различным значением параметра mask на каждую возможную комбинацию каналов. Это довольно утомительная задача, к тому же на сегодняшний день изначальный SSE набор инструкций существенно расширен и код можно сделать значительно проще. Ближайшее к SSE поколение, которое содержит очень полезную для наших целей инструкцию, называется SSSE3. И речь конечно же об инструкции:
Эта инструкция может быть эффективно использована во множестве алгоритмов, где для вычисления одного выходного элемента, используются несколько соседних входных элементов. Данная инструкция переставляет байты приемника в абсолютно произвольном порядке, а также может обнулить байт при установленном старшем бите в регистре маске, см. Рис 2.

Несмотря на то, что инструкция переставляет байты, мы можем ее применить и для float данных.
Как видно, наш SSSE3 код использует довольно много SIMD инструкций, и в строке комментария поясняется, зачем они используются. Инструкции _mm_unpacklo_pd используются для того чтобы объединить в один XMM регистр, значения, прочитанные в разные регистры. Инструкции _mm_and_ps, _mm_or_ps используются для объединения по маске с немодифицированным каналом и val значением. Непосредственно для перестановки элементов мы и используем инструкцию _mm_shuffle_epi8. Измеряем, сколько времени уходит на выполнение и получаем P=0.4. Несмотря на то, что код выглядит более громоздко по сравнению с C кодом, прирост производительности составил примерно 2.5X. И это довольно неплохой результат.

Поэтому AVX вариант нашего кода может выглядеть примерно так:
Закономерно может возникнуть вопрос: почему же в нашем 256-битном AVX коде используется загрузка с помощью 128 битных инструкций? Дело в том, что в нашем коде была использована инструкция VPERMPS в строке
ymm0 = _mm256_permutevar_ps(ymm0, ymm8)
Как уже объяснялось выше, данная инструкция переставляет элементы внутри младшей и старшей части регистра (или по другому lane) независимо. Поэтому, несмотря на то, что 2 пикселя лежат в памяти рядом, мы вынуждены читать их таким образом, чтобы они попали в разные lane. Обратите внимание, как формируется регистр-маска ymm8, он содержит абсолютно одинаковые значения в старшей и младшей части для перестановки. Код написан таким образом, чтобы количество итераций в циклах сохранилось и не влияло на итоговую производительность. Измеряем производительность: P=0.31. Таким образом прирост AVX кода по отношению к C составил 3.2X, а у SSSE3 было 2.48X
Обратите внимание что маска перестановки в регистре ymm8 совершенно изменилась и является сквозной по всему регистру, т.е. индексы в ней относятся в целом ко всему 256 битному регистру.
Однако в этом коде есть проблема в том, как происходит чтение регистра ymm0. В нем загружаются лишние 2 float элемента. Так делать неправильно, поскольку может произойти чтение за границей изображения и исправить это нам поможет опять же появившаяся лишь в AVX2 инструкция чтения по маске
__m256i _mm256_maskload_epi32(int const *, __m256i);
Данная инструкция читает необходимые элементы из памяти и не читает ничего лишнего, что предотвращает возможную memory segmentation ошибку. Теперь наш правильный код будет выглядеть так.
Производительность этого кода составляет P=0.286. Ускорение таким образом изменилось от k=3.2X до k=3.5X. Помимо чтения по маске, мы можем использовать и сохранять немоди��ицированный канал без изменения, используя инструкцию
void _mm256_maskstore_ps(float *, __m256i, __m256);
Обратите внимание на то, что 128 битная предшественница данной инструкции
void _mm_maskmoveu_si128(__m128i, __m128i, char *)
сохраняет данные, используя non-temporal запись, а вот в AVX версиях _mm256_maskstore_ps и _mm_maskstore_ps от этого механизма было решено отказаться. О том, что такое non-temporal запись и как она применяется в IPP библиотеке будет рассказано в одной из следующих статей. Меряем производительность и получаем небольшой прирост, P=0.27, k=3.7X.
Как следует из названия длина векторных регистров увеличилась в два раза с 256 бит до 512. Lane концепция также сохранилась. Второе новшество заключается в том, что операции с масками приобрели массовый характер и затрагивают теперь большинство векторных операций. Для этого были введены специальные масочные регистры. Масочные регистры имеют свой тип данных __mmask8, __mmask16, __mmask32, __mmask64, но с ними можно оперировать как с целочисленными типами данных, поскольку они так и объявлены в заголовочном файле zmmintrin.h. Использование масок делает AVX512 обрабатывающий цикл функции довольно минималистичным.
Количество интринсиков в одной итерации цикла сократилось до трех, и каждый из них использует маску. Первый интринсик
z0 = _mm512_mask_loadu_ps(_mm512_setzero_ps(), 0xFFF, (float *)(pSrc+s))
использует маску 0xFFF для того чтобы прочитать из памяти 4 RGB пикселя или 12 float, в двоичном виде 0xFFF=1111111111111111b. Следующий интринсик
z0 = _mm512_mask_permutexvar_ps(zv, mskv, zi0, z0)
выполняет сразу 2 функции: переставляет каналы входного пикселя и объединяет их по маске со значением val. Маска mskv формируется перед началом цикла и биты маски используются следующим образом: значение бита равное ‘1’ означает «поместить результат операций в результирующий регистр», а ‘0’ – «cохранить значение того регистра, который указан до маски», в нашем случае zv. Третий интринсик
_mm512_mask_storeu_ps(pDst+d, mska, z0)
сохраняет полученные 4 пикселя в память, при этом он не пишет ничего в немодифицированный канал. Производительность кода составляет P=0.183, k=5.44X.
Читатель может сравнить код SSSE3 с AVX512 кодом, в котором используется всего 3 интринсика. Именно краткость avx512 кода и вдохновила автора на написание данной статьи.
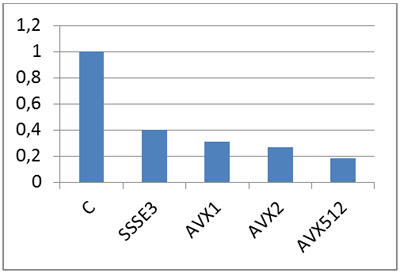
Итоговая таблица роста производительности.
Ознакомившись с данной статьей, читатель может попробовать использовать SIMD код в своих приложениях, а читатель, уже имеющий такой опыт, может оценить по достоинству преимущества crosslane инструкций перестановки и инструкций с масками в новых процессорах Intel, поддерживающих набор инструкций AVX512.
Также хотелось бы отметить, что в данной статье приведена незначительная часть приемов оптимизации, используемых в библиотеке IPP и позволяющих достичь ее уникальной производительности.
Читатель может и сам попробовать использовать библиотеку IPP в своем приложении, освободив возможности для решения своих прикладных задач. Дополнительным эффектом использования IPP станет то, что после выхода на рынок процессоров с набором инструкции AVX512, библиотека IPP уже будет иметь оптимизированную на AVX512 версию наиболее востребованных функций.
Автор данной статьи принимает участие в разработке библиотеки Intel IPP, поэтому в данной статье рассматривается прирост производительности на примере одной из функции из данной библиотеки. Хочется надеяться, что данная статья будет полезна следующим категориям читателей:
- начинающим разработчикам, желающим познакомиться на конкретном примере, как с помощью SIMD инструкций можно повысить производительность кода;
- тем, кто уже имеет достаточный опыт в использовании SIMD инструкций и интересуется новым набором инструкций AVX3.1 для оптимизации своих приложений.
Помимо этих категорий читателей, разработчикам, заинтересованным в оптимизации своего приложения и желающим минимизировать свои затраты на низкоуровневую оптимизацию, данная статья может помочь познакомиться поближе с IPP библиотекой.
Функция ippiSwapChannels_32f_C3C4R
Библиотека IPP содержит оптимизированные 32-х и 64-х битные версии для процессоров, поддерживающих наборы инструкций SSSE3, SSE41, AVX, AVX2, AVX31. Поэтому и рассмотрим возможности оптимизации с использованием этих наборов данных. Вообще, IPP содержит много функций для различных областей обработки данных. Эти функции реализуют как довольно сложные для понимания математические алгоритмы, к примеру преобразование Фурье, так и алгоритмы, не представляющие особых сложностей для понимания. Именно такую довольно простую функцию ippiSwapChannels_32f_C3C4R и рассмотрим в данной статье, постараясь последовательно применить к ней наборы инструкций от SSSE3 до AVX31.API данной функции выглядит следующим образом.
int ippiSwapChannels_32f_C3C4R(
const float* pSrc, int srcStep, float* pDst, int dstStep,
int width, int height, const int dstOrder[4], float val )
Функция читает исходное float изображение по указателю pSrc с шагом в srcStep между строками и размером width x height, переставляет каналы в каждом пикселе в соответствии с новым порядком dstOrder и записывает результирующее изображение по указателю pDst. Фукнция также может записать указанное пользователем фиксированное значение val в канал. Допускается дублирование каналов в выходном изображении. Схема работы функции представлена на рисунке 1.
C код
Код функции на языке C довольно прост (см. ниже). В каждой итерации цикла формируется один пиксель выходного изображения при этом с каждым каналом выходного пикселя может произойти одно из 3-х возможных действий:- скопироваться канал пикселя исходного изображения, если индекс в dstOrder меньше 3;
- поместиться фиксированное значение val, если индекс в dstOrder равен 3;
- сохраниться старое немодифицированное значение, если индекс в dstOrder больше 3
Код
int s, d, h, ord0 = dstOrder[0], ord1 = dstOrder[1], ord2 = dstOrder[2], ord3 = dstOrder[3];
for( h = 0; h < height; h++ ) {
for( s = 0, d = 0; d < width*4; s += 3, d += 4 ) {
if( ord0 < 3 ) {
pDst[d] = pSrc[s + ord0];
} else if( ord0 == 3 ) {
pDst[d] = val;
}
if( ord1 < 3 ) {
pDst[d + 1] = pSrc[s + ord1];
} else if( ord1 == 3 ) {
pDst[d + 1] = val;
}
if( ord2 < 3 ) {
pDst[d + 2] = pSrc[s + ord2];
} else if( ord2 == 3 ) {
pDst[d + 2] = val;
}
if( ord3 < 3 ) {
pDst[d + 3] = pSrc[s + ord3];
} else if( ord3 == 3 ) {
pDst[d + 3] = val;
}
}
pSrc = (float*)((char*)pSrc + srcStep);
pDst = (float*)((char*)pDst + dstStep);
}
Первая версия SIMD кода с использованием SSSE3
А теперь, как и планировалось, попробуем оптимизировать данный код используя векторные SIMD инструкции вплоть до AVX3.1. Будем использовать Intel Composer, а производительность всех вариантов кода измерять на внутреннем симуляторе серверной версии SkyLake, поддерживающей набор AVX31 — SKX, поскольку нужно оценить именно преимущества новых инструкций без влияния архитектурных изм��нений. Для компилятора также указываем максимально возможный уровень оптимизации, одинаково для всех вариантов кода. Измерянную таким образом производительность C кода примем за некую условную величину P=1.Надеемся, что читатель уже знаком с понятием векторных регистров, если же нет, то можно ознакомиться и воспользоваться удобным навигатором интринсиков.
Итак, посмотрим, как можно было бы векторизовать, т.е. переписать код этой функции с использованием векторных регистров SSE. В соответствии с логикой функции, нам необходимо осуществить перестановку float элементов внутри векторного регистра, поэтому нам нужны соответствующие инструкции перестановки элементов. К таким инструкциям можно отнести следующие инструкции из набора SSE:
SHUFPS xmm1, xmm2/m128, imm8
UNPCKHPS xmm1, xmm2/m128
UNPCKLPS xmm1, xmm2/m128
__m128 _mm_shuffle_ps(__m128 a, __m128 b, unsigned int mask).
__m128 _mm_unpackhi_ps(__m128, __m128)
__m128 _mm_unpacklo_ps(__m128, __m128)
Данные инструкции очень полезны и для нашей задачи они тоже могут быть использованы, но возникает следующая проблема. Инструкция SHUFPS имеет непосредственный операнд imm8, формирующий перестановку элементов. Третий параметр данной инструкции это imm8 — значение, т.е. некая константа. При попытке же использовать в интринсике переменную компилятор выдаст ошибку. А инструкции UNPCKHPS/UNPCKLPS чередуют элементы в регистрах лишь единственным способом. Допустимых вариантов перестановки каналов, указываемых в dstOrder довольно много и поэтому для реализации всех возможных комбинаций пришлось бы разработать код со множеством веток и различным значением параметра mask на каждую возможную комбинацию каналов. Это довольно утомительная задача, к тому же на сегодняшний день изначальный SSE набор инструкций существенно расширен и код можно сделать значительно проще. Ближайшее к SSE поколение, которое содержит очень полезную для наших целей инструкцию, называется SSSE3. И речь конечно же об инструкции:
PSHUFB xmm1, xmm2/m128
__m128i _mm_shuffle_epi8 (__m128i a, __m128i b)
Эта инструкция может быть эффективно использована во множестве алгоритмов, где для вычисления одного выходного элемента, используются несколько соседних входных элементов. Данная инструкция переставляет байты приемника в абсолютно произвольном порядке, а также может обнулить байт при установленном старшем бите в регистре маске, см. Рис 2.
Несмотря на то, что инструкция переставляет байты, мы можем ее применить и для float данных.
Код
int s, d, h, ord0 = dstOrder[0], ord1 = dstOrder[1], ord2 = dstOrder[2], ord3 = dstOrder[3];
__m128 xmm0, xmm1, xmm2, xmm3, xmm4, xmm5,xmm6, xmm7;
__m128i xmm8 = _mm_set_epi8(4*ord3+3,4*ord3+2,4*ord3+1,4*ord3,
4*ord2+3,4*ord2+2,4*ord2+1,4*ord2,
4*ord1+3,4*ord1+2,4*ord1+1,4*ord1,
4*ord0+3,4*ord0+2,4*ord0+1,4*ord0);
__m128i xmm9 = _mm_set_epi32(0,0,0,0);//unmodified channel mask
__m128i xmm10 = _mm_set_epi32(0,0,0,0);//val
if(ord3 >= 3){
xmm8 = _mm_or_si128(xmm8, _mm_set_epi32(-1, 0, 0, 0));
if(ord3 > 3){ xmm9 = _mm_or_si128(xmm9, _mm_set_epi32(-1, 0, 0, 0));}
else { xmm10 = _mm_or_si128(xmm10, _mm_set_epi32(val, 0, 0, 0));};
}
if(ord2 >= 3){
xmm8 = _mm_or_si128(xmm8, _mm_set_epi32( 0,-1, 0, 0));
if(ord2 > 3){ xmm9 = _mm_or_si128(xmm9, _mm_set_epi32( 0, -1, 0, 0));}
else { xmm10 = _mm_or_si128(xmm10, _mm_set_epi32( 0, val,0, 0));}
}
if(ord1 >=3){
xmm8 = _mm_or_si128(xmm8, _mm_set_epi32( 0, 0,-1, 0));
if(ord1 > 3){xmm9 = _mm_or_si128(xmm9, _mm_set_epi32( 0, 0,-1, 0));}
else {xmm10 = _mm_or_si128(xmm10, _mm_set_epi32( 0, 0,val, 0));}
}
if(ord0 >= 3){
xmm8 = _mm_or_si128(xmm8, _mm_set_epi32( 0, 0, 0,-1));
if(ord0 > 3){xmm9 = _mm_or_si128(xmm9, _mm_set_epi32( 0, 0, 0,-1));}
else {xmm10 = _mm_or_si128(xmm10, _mm_set_epi32( 0, 0, 0,val));}
}
for( h = 0; h < height; h++ ) {
s = 0;
d = 0;
for(; d < width*4; s += 3*4, d += 4*4 ) {
xmm0 = _mm_load_sd(pSrc+s ); //читаем g0 r0
xmm1 = _mm_load_ss(pSrc+s+2 ); //читаем b0
xmm2 = _mm_load_sd(pSrc+s +3);
xmm3 = _mm_load_ss(pSrc+s+2+3);
xmm4 = _mm_load_sd(pSrc+s +6);
xmm5 = _mm_load_ss(pSrc+s+2+6);
xmm6 = _mm_load_sd(pSrc+s +9);
xmm7 = _mm_load_ss(pSrc+s+2+9);
xmm0 = _mm_unpacklo_pd(xmm0, xmm1); //получаем b0 g0 r0 в один регистр
xmm1 = _mm_unpacklo_pd(xmm2, xmm3);
xmm2 = _mm_unpacklo_pd(xmm4, xmm5);
xmm3 = _mm_unpacklo_pd(xmm6, xmm7);
xmm4 = _mm_loadu_ps(pDst+d+0); //читаем немодифицируемый канал
xmm5 = _mm_loadu_ps(pDst+d+4);
xmm6 = _mm_loadu_ps(pDst+d+8);
xmm7 = _mm_loadu_ps(pDst+d+12);
xmm0 = _mm_shuffle_epi8(xmm0, xmm8); //осуществляем перестановку в соответствии с маской
xmm1 = _mm_shuffle_epi8(xmm1, xmm8);
xmm2 = _mm_shuffle_epi8(xmm2, xmm8);
xmm3 = _mm_shuffle_epi8(xmm3, xmm8);
xmm4 = _mm_and_ps(xmm4,xmm9); //обнуляем ненужные значения прочитанные из dst
xmm5 = _mm_and_ps(xmm5,xmm9);
xmm6 = _mm_and_ps(xmm6,xmm9);
xmm7 = _mm_and_ps(xmm7,xmm9);
xmm0 = _mm_or_ps(xmm0,xmm4); //объединяем переставленные каналы с немодифицированным каналом
xmm1 = _mm_or_ps(xmm1,xmm5);
xmm2 = _mm_or_ps(xmm2,xmm6);
xmm3 = _mm_or_ps(xmm3,xmm7);
xmm0 = _mm_or_ps(xmm0,xmm10); //объединяем переставленные каналы с val значением
xmm1 = _mm_or_ps(xmm1,xmm10);
xmm2 = _mm_or_ps(xmm2,xmm10);
xmm3 = _mm_or_ps(xmm3,xmm10);
_mm_storeu_ps(pDst+d , xmm0); //записываем результат
_mm_storeu_ps(pDst+d+ 4, xmm1);
_mm_storeu_ps(pDst+d+ 8, xmm2);
_mm_storeu_ps(pDst+d+12, xmm3);
}
for(; d < width*4; s += 3, d += 4 ) {
__m128 xmm0, xmm1, xmm4;
xmm0 = _mm_load_sd(pSrc+s );
xmm1 = _mm_load_ss(pSrc+s+2);
xmm0 = _mm_unpacklo_pd(xmm0, xmm1);
xmm4 = _mm_loadu_ps(pDst+d);
xmm0 = _mm_shuffle_epi8(xmm0, xmm8);
xmm4 = _mm_and_ps(xmm4,xmm9); //apply unmodified mask
xmm0 = _mm_or_ps(xmm0,xmm4);
xmm0 = _mm_or_ps(xmm0,xmm10);
_mm_storeu_ps(pDst+d, xmm0);
}
pSrc = (float*)((char*)pSrc + srcStep);
pDst = (float*)((char*)pDst + dstStep);
}
Как видно, наш SSSE3 код использует довольно много SIMD инструкций, и в строке комментария поясняется, зачем они используются. Инструкции _mm_unpacklo_pd используются для того чтобы объединить в один XMM регистр, значения, прочитанные в разные регистры. Инструкции _mm_and_ps, _mm_or_ps используются для объединения по маске с немодифицированным каналом и val значением. Непосредственно для перестановки элементов мы и используем инструкцию _mm_shuffle_epi8. Измеряем, сколько времени уходит на выполнение и получаем P=0.4. Несмотря на то, что код выглядит более громоздко по сравнению с C кодом, прирост производительности составил примерно 2.5X. И это довольно неплохой результат.
Вторая версия SIMD кода с использованием AVX
На сегодняшний день процессоры Intel из топовой линейки уже давно поддерживают как минимум набор инструкций AVX. Векторные регистры, используемые в инструкциях AVX, имеют длину 256 бит и соответственно в 2 раза шире 128 битных SSE регистров. Однако AVX содержит два существенных для нас ограничения. Во-первых, AVX содержит 256-битные инструкции перестановки только для float и double типов данных и мы не можем использовать 256-битный аналог _mm_shuffle_epi8. Во-вторых, после выхода набора инструкций AVX была введена так называмая lane концепция для векторных инструкций. В рамках данной концепции один 256-битный AVX регистр представляет собой связку двух 128-битных регистров, именуемых словом lane. Большинство 256-битных расширений 128-битных инструкции с горизонтальным доступом работают только внутри каждой lane. Таким образом, зачастую AVX вариант кода, который уже имеет SSE версию выглядит так как это показано на рис. 3Поэтому AVX вариант нашего кода может выглядеть примерно так:
Код
int s, d, h, ord0 = dstOrder[0], ord1 = dstOrder[1], ord2 = dstOrder[2], ord3 = dstOrder[3];
__m256 ymm0, ymm1, ymm2, ymm3, ymm4, ymm5,ymm6, ymm7;
__m128 xmm0, xmm1, xmm2,xmm3;
__m256 ymm10= _mm256_setzero_ps();//val
__m256i ymm8 = _mm256_set_epi32(
dstOrder[3],dstOrder[2],dstOrder[1],dstOrder[0],
dstOrder[3],dstOrder[2],dstOrder[1],dstOrder[0]);
__m256 ymm9 = _mm256_setzero_ps();
__m256 ymm11 = _mm256_setzero_ps();
__m256i YMM_N[4], YMM_V[4];
YMM_N[0]= _mm256_set_m128(_mm_set_epi32( 0, 0, 0,-1), _mm_set_epi32( 0, 0, 0,-1));
YMM_N[1]= _mm256_set_m128(_mm_set_epi32( 0, 0,-1, 0), _mm_set_epi32( 0, 0,-1, 0));
YMM_N[2]= _mm256_set_m128(_mm_set_epi32( 0,-1, 0, 0), _mm_set_epi32( 0,-1, 0, 0));
YMM_N[3]= _mm256_set_m128(_mm_set_epi32(-1, 0, 0, 0), _mm_set_epi32(-1, 0, 0, 0));
YMM_V[0]= _mm256_set_m128(_mm_set_epi32( 0 , 0, 0,val), _mm_set_epi32( 0 , 0, 0,val));
YMM_V[1]= _mm256_set_m128(_mm_set_epi32( 0 , 0,val, 0), _mm_set_epi32( 0 , 0,val, 0));
YMM_V[2]= _mm256_set_m128(_mm_set_epi32( 0 ,val, 0, 0), _mm_set_epi32( 0 ,val, 0, 0));
YMM_V[3]= _mm256_set_m128(_mm_set_epi32(val, 0, 0, 0), _mm_set_epi32(val, 0, 0, 0));
//генерируем маски
for(s=0;s<4;s++){
if(dstOrder[s] >= 3){
ymm9 = _mm256_or_ps(ymm9, YMM_N[s]);
if(dstOrder[s] > 3){ ymm11 = _mm256_or_si256(ymm11, YMM_N[s]);} //маска немодифицированного канала
else { ymm10 = _mm256_or_si256(ymm10, YMM_V[s]);}; //val значение
}
}
for( h = 0; h < height; h++ ) {
s = 0;
d = 0;
for(; d < (width&(~1))*4; s += 3*2, d += 4*2 ) {//обрабатываем по 2 пикселя за итерацию
xmm0 = _mm_loadu_ps (pSrc+s ); //читаем src
xmm2 = _mm_load_sd (pSrc+s +3);
xmm3 = _mm_load_ss (pSrc+s+2 +3);
xmm2 = _mm_unpacklo_pd (xmm2, xmm3 );
ymm0 = _mm256_set_m128 (xmm2, xmm0 ); //собираем их в один 256битный регистр
ymm4 = _mm256_loadu_ps (pDst+d ); //читаем выходное изображение
ymm0 = _mm256_permutevar_ps(ymm0, ymm8 ); //переставляем
ymm4 = _mm256_and_ps (ymm4, ymm11); //применяем маску немодифицированного канала
ymm0 = _mm256_andnot_ps (ymm9, ymm0 ); //обнуляем каналы где немодифицированное или val значение
ymm0 = _mm256_or_ps (ymm0, ymm4 ); //объединяем с немодифицированным каналом
ymm0 = _mm256_or_ps (ymm0, ymm10 ); //объединяем с val значением
_mm256_storeu_ps(pDst+d, ymm0);
}
//обрабатываем хвост по 1 пикселю
pSrc = (float *)((char*)pSrc + srcStep);
pDst = (float *)((char*)pDst + dstStep);
}
Закономерно может возникнуть вопрос: почему же в нашем 256-битном AVX коде используется загрузка с помощью 128 битных инструкций? Дело в том, что в нашем коде была использована инструкция VPERMPS в строке
ymm0 = _mm256_permutevar_ps(ymm0, ymm8)
Как уже объяснялось выше, данная инструкция переставляет элементы внутри младшей и старшей части регистра (или по другому lane) независимо. Поэтому, несмотря на то, что 2 пикселя лежат в памяти рядом, мы вынуждены читать их таким образом, чтобы они попали в разные lane. Обратите внимание, как формируется регистр-маска ymm8, он содержит абсолютно одинаковые значения в старшей и младшей части для перестановки. Код написан таким образом, чтобы количество итераций в циклах сохранилось и не влияло на итоговую производительность. Измеряем производительность: P=0.31. Таким образом прирост AVX кода по отношению к C составил 3.2X, а у SSSE3 было 2.48X
Третья версия SIMD кода с использованием AVX2
Развитием AVX стал набор AVX2. Длина векторных регистров в нем не изменилась, но появились новые инструкции, которые нам помогут еще ускорить код. В AVX2 появились acrosslane инструкции перестановки _mm256_permutevar8x32_ps. Эти инструкции позволяют переставить элементы внутри 256 битного регистра произвольным образом и наш код мог бы выглядеть уже так.Код
__m256i ymm8 = _mm256_set_epi32(
dstOrder[3]+3,dstOrder[2]+3,dstOrder[1]+3,dstOrder[0]+3,
dstOrder[3],dstOrder[2],dstOrder[1],dstOrder[0]);
for(; d < (width&(~1))*4; s += 3*2, d += 4*2 ) {
ymm0 = _mm256_loadu_ps (pSrc+s);
ymm4 = _mm256_loadu_ps (pDst+d );
ymm0 = _mm256_permutevar8x32_ps(ymm0, ymm8);
ymm4 = _mm256_and_ps (ymm4, ymm11); //apply unmodified mask
ymm0 = _mm256_andnot_ps (ymm9, ymm0 ); //apply unmodified and val mask with inverse
ymm0 = _mm256_or_ps (ymm0, ymm4 ); //join with unmodified
ymm0 = _mm256_or_ps (ymm0, ymm10 ); //join with val
_mm256_storeu_ps(pDst+d, ymm0);
}
Обратите внимание что маска перестановки в регистре ymm8 совершенно изменилась и является сквозной по всему регистру, т.е. индексы в ней относятся в целом ко всему 256 битному регистру.
Однако в этом коде есть проблема в том, как происходит чтение регистра ymm0. В нем загружаются лишние 2 float элемента. Так делать неправильно, поскольку может произойти чтение за границей изображения и исправить это нам поможет опять же появившаяся лишь в AVX2 инструкция чтения по маске
__m256i _mm256_maskload_epi32(int const *, __m256i);
Данная инструкция читает необходимые элементы из памяти и не читает ничего лишнего, что предотвращает возможную memory segmentation ошибку. Теперь наш правильный код будет выглядеть так.
Код
__m256i ld_mask = _mm256_set_epi32(0,0,-1,-1,-1,-1,-1,-1);
for(; d < (width&(~1))*4; s += 3*2, d += 4*2 ) {
ymm0 = _mm256_maskload_ps (pSrc+s, ld_mask);
ymm4 = _mm256_loadu_ps (pDst+d );
ymm0 = _mm256_permutevar8x32_ps(ymm0, ymm8);
ymm4 = _mm256_and_ps (ymm4, ymm11); //apply unmodified mask
ymm0 = _mm256_andnot_ps (ymm9, ymm0 ); //apply unmodified and val mask with inverse
ymm0 = _mm256_or_ps (ymm0, ymm4 ); //join with unmodified
ymm0 = _mm256_or_ps (ymm0, ymm10 ); //join with val
_mm256_storeu_ps(pDst+d, ymm0);
}
Производительность этого кода составляет P=0.286. Ускорение таким образом изменилось от k=3.2X до k=3.5X. Помимо чтения по маске, мы можем использовать и сохранять немоди��ицированный канал без изменения, используя инструкцию
void _mm256_maskstore_ps(float *, __m256i, __m256);
Код
__m256 ymmNA = _mm256_set_epi32( 0,-1,-1,-1, 0,-1,-1,-1);
for(; d < (width&(~1))*4; s += 3*2, d += 4*2 ) {
ymm0 = _mm256_maskload_ps (pSrc+s, ld_mask);
ymm0 = _mm256_permutevar8x32_ps(ymm0, ymm8);
ymm0 = _mm256_andnot_ps (ymm9, ymm0 ); //apply unmodified and val mask with inverse
ymm0 = _mm256_or_ps (ymm0, ymm10 ); //join with val
_mm256_maskstore_epi32(pDst+d, ymmNA, ymm0);
}
Обратите внимание на то, что 128 битная предшественница данной инструкции
void _mm_maskmoveu_si128(__m128i, __m128i, char *)
сохраняет данные, используя non-temporal запись, а вот в AVX версиях _mm256_maskstore_ps и _mm_maskstore_ps от этого механизма было решено отказаться. О том, что такое non-temporal запись и как она применяется в IPP библиотеке будет рассказано в одной из следующих статей. Меряем производительность и получаем небольшой прирост, P=0.27, k=3.7X.
Версия SIMD кода с использованием AVX512
Итак, переходим к самой интересной части нашей статьи – оптимизации кода на AVX512.Как следует из названия длина векторных регистров увеличилась в два раза с 256 бит до 512. Lane концепция также сохранилась. Второе новшество заключается в том, что операции с масками приобрели массовый характер и затрагивают теперь большинство векторных операций. Для этого были введены специальные масочные регистры. Масочные регистры имеют свой тип данных __mmask8, __mmask16, __mmask32, __mmask64, но с ними можно оперировать как с целочисленными типами данных, поскольку они так и объявлены в заголовочном файле zmmintrin.h. Использование масок делает AVX512 обрабатывающий цикл функции довольно минималистичным.
Код
int s, d, h, ord0 = dstOrder[0], ord1 = dstOrder[1], ord2 = dstOrder[2], ord3 = dstOrder[3];
__mmask16 mskv; //mask for joing with val
__mmask16 mska; //mask for unmodified channel
__m512 z0,z1,z2,z3,z4,z5;
__m512i zv = _mm512_set1_epi32(val);
__m512i zi0 = _mm512_set_epi32(ord3+9,ord2+9,ord1+9,ord0+9, ord3+6,ord2+6,ord1+6,ord0+6,
ord3+3,ord2+3,ord1+3,ord0+3, ord3+0,ord2+0,ord1+0,ord0+0);
mska = mskv = 0xFFFF;
for (int i = 0; i < 4; i++){
if(dstOrder[i] == 3) { mskv ^= (0x1111<<i); }
if(dstOrder[i] > 3) { mska ^= (0x1111<<i); }
}
for( h = 0; h < height; h++ ) {
s = 0; d = 0;
for(; d < ((width*4) & (~15)); s += 3*4, d += 4*4 ) {
z0 = _mm512_mask_loadu_ps(_mm512_setzero_ps(), 0xFFF,(float *)(pSrc+s));
z0 = _mm512_mask_permutexvar_ps(zv,mskv,zi0, z0);
_mm512_mask_storeu_ps(pDst+d, mska, z0);
}
pSrc = (float *)((char*)pSrc + srcStep);
pDst = (float *)((char *)pDst + dstStep);
}
Количество интринсиков в одной итерации цикла сократилось до трех, и каждый из них использует маску. Первый интринсик
z0 = _mm512_mask_loadu_ps(_mm512_setzero_ps(), 0xFFF, (float *)(pSrc+s))
использует маску 0xFFF для того чтобы прочитать из памяти 4 RGB пикселя или 12 float, в двоичном виде 0xFFF=1111111111111111b. Следующий интринсик
z0 = _mm512_mask_permutexvar_ps(zv, mskv, zi0, z0)
выполняет сразу 2 функции: переставляет каналы входного пикселя и объединяет их по маске со значением val. Маска mskv формируется перед началом цикла и биты маски используются следующим образом: значение бита равное ‘1’ означает «поместить результат операций в результирующий регистр», а ‘0’ – «cохранить значение того регистра, который указан до маски», в нашем случае zv. Третий интринсик
_mm512_mask_storeu_ps(pDst+d, mska, z0)
сохраняет полученные 4 пикселя в память, при этом он не пишет ничего в немодифицированный канал. Производительность кода составляет P=0.183, k=5.44X.
Читатель может сравнить код SSSE3 с AVX512 кодом, в котором используется всего 3 интринсика. Именно краткость avx512 кода и вдохновила автора на написание данной статьи.
Итоговая таблица роста производительности.
Заключение
Конечно, использование масок в данном алгоритме довольно очевидно, но они могут использованы и в других, более сложных алгоритмах, и об этом будет другая статья.Ознакомившись с данной статьей, читатель может попробовать использовать SIMD код в своих приложениях, а читатель, уже имеющий такой опыт, может оценить по достоинству преимущества crosslane инструкций перестановки и инструкций с масками в новых процессорах Intel, поддерживающих набор инструкций AVX512.
Также хотелось бы отметить, что в данной статье приведена незначительная часть приемов оптимизации, используемых в библиотеке IPP и позволяющих достичь ее уникальной производительности.
Читатель может и сам попробовать использовать библиотеку IPP в своем приложении, освободив возможности для решения своих прикладных задач. Дополнительным эффектом использования IPP станет то, что после выхода на рынок процессоров с набором инструкции AVX512, библиотека IPP уже будет иметь оптимизированную на AVX512 версию наиболее востребованных функций.
