
Сегодня вышел в свет первый официальный релиз новой библиотеки Intel для аналитики данных — Intel Data Analytics Acceleration Library. Библиотека доступна как в составе пакетов Parallel Studio XE, так и как независимый продукт с коммерческой и бесплатной (community) лицензией. Что это за зверь и зачем она нужна? Давайте разбираться.
Где нужна Intel DAAL?
На сегодняшний день существует целая наука о данных (data science), которая изучает проблемы обработки, анализа и представления данных. В неё входит множество различных областей, такие как статистические методы, методы интеллектуального анализа данных (data mining), машинное обучение (machine learning), теория распознавания образов (pattern recognition), приложения искусственного интеллекта (AI) и так далее.

При этом все эти области исследований имеют достаточно много пересечений, но есть и различия. Так, статистика базируется на теории более, чем data mining, и сосредотачивается на проверке гипотез. Машинное обучение более эвристично и концентрируется на улучшении работы агентов обучения. А data mining представляет интеграцию теории и эвристик, концентрируясь на едином процессе анализа данных, включая очистку данных, обучение, интеграцию и визуализацию результатов. Библиотека Intel DAAL будет интересна всем, кто имеет отношение к науке о данных и её областях.
Для методов интеллектуального анализа данных имеются свои стандарты, наиболее распространенным из которых является межотраслевой стандартный процесс для интеллектуального анализа данных CRISP-DM (Cross Industry Standard Process for Data Mining). Согласно этому стандарту, процесс анализа данных является итеративным и включает в себя 6 этапов: осмысление бизнеса (business understanding), осмысление данных (data understanding), подготовка данных (data preparation), моделирование (modeling), оценка результатов (evaluation), внедрение (deployment).
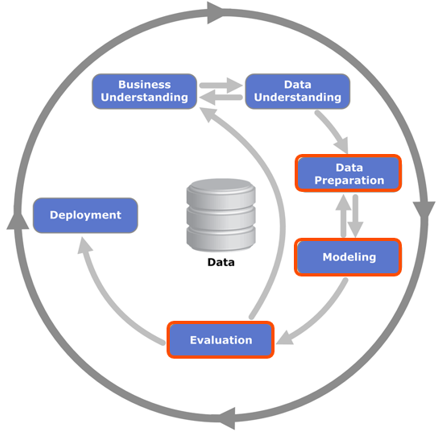
Библиотека DAAL предназначена, в основном, для этапа подготовки данных, моделирования и оценки результатов, если говорить о представлении методов интеллектуального анализа данных в рамках этого стандарта. При этом она оптимизирована с помощью алгоритмов библиотек Intel Math Kernel Library и Intel Integrated Performance Primitives.
Проблемы и решения
Почему именно DAAL и чем эта библиотека должна понравиться разработчикам?
В области аналитики данных сейчас имеется огромное количество различных технологий и средств. Это вполне естественно, учитывая темпы роста этой отрасли:

Интересная статистика от Wikibon: к 2017 году объём рынка больших данных составит около 50 млрд. американских президентов, из которых 8 приходится на софт и аналитику.
Хранение данных, полученных от большого числа различных источников, реализуется как средствами традиционных реляционных СУБД с доступом к данным средствами языка SQL, так и не традиционных NoSQL (not only SQL). Кроме того, данные могут сразу располагаться в памяти. Для обработки этих данных сейчас применяются большие фреймворки типа Hadoop, Spark, Cassandra и так далее.
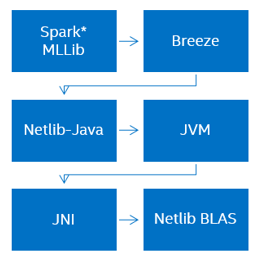
Существует одна большая проблема, связанная с текущими решениями, а именно – производительность. Рассмотрим в качестве примера фреймворк с открытым кодом Spark, точнее библиотеку машинного обучения Spark MLLib.
Spark MLLib написан с помощью языка Scala и использует ещё один opensource пакет линейной алгебры Breeze, который зависит от Netlib-Java, являющейся оберткой Netlib для Java. В итоге, используется Netlib BLAS, реализация которой обычно является последовательной и не оптимизированной. Очевидно, что мы имеем проблему слишком большого числа зависимостей, «многослойности» и слабой производительности.
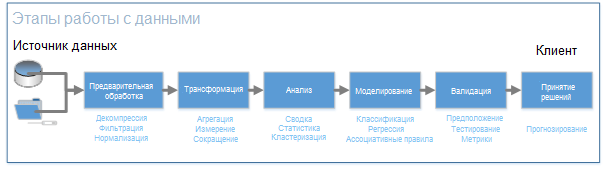
Идея Intel заключается в том, чтобы создать одну библиотеку для работы на всех этапах аналитики данных, исключая подобные многослойные реализации, при этом оптимизировать её под железо:
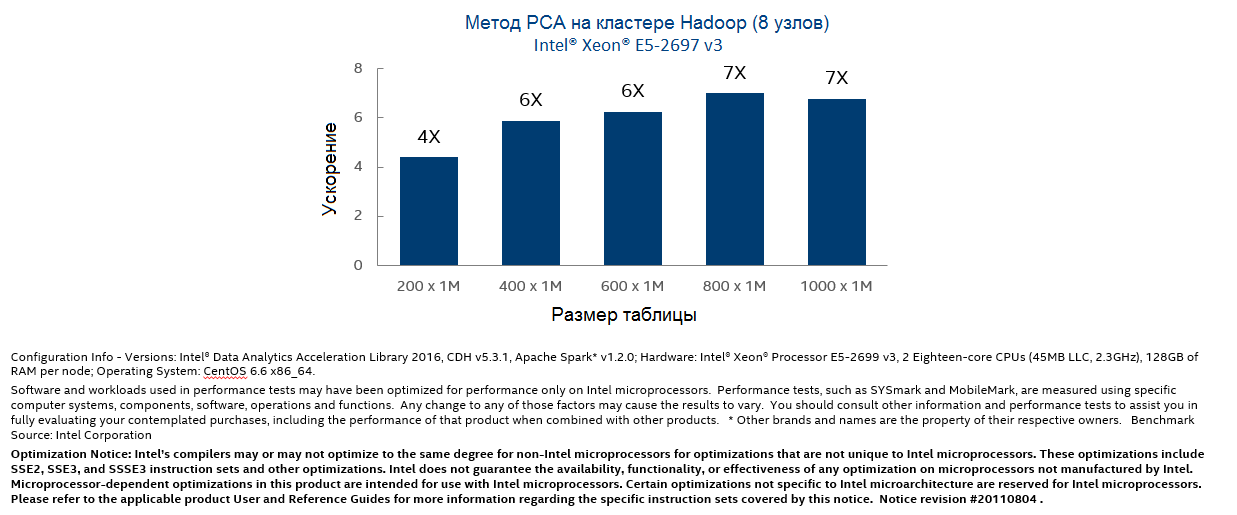
Использование этого решения должно дать нам значительной прирост производительности. Если сравнить реализацию Intel DAAL с той же Spark MLlib на примере использования метода главных компонент (PCA — principal component analysis), то получаемое ускорение может составлять от 4 до 7 раз, в зависимости от размера таблицы данных:
Основные компоненты
Intel DAAL поддерживает языки C++ и Java, а также ОС Windows, Linux и OS X. Она может быть использована с любыми платформами, такими как Hadoop, Spark, R, Matlab и другими, но не привязана ни к одной из них. Кроме того, есть поддержка локальных и распределённых источников данных, включая СSV в файлах и в памяти, MySQL, HDFS, и Resilient Distributed Dataset (RDD) объекты из Apache Spark*.
Библиотека состоит и трех основных компонент: Управление данными, Алгоритмы и Сервисы.
Управление данными
Сюда входят классы и утилиты для получения данных, первичной обработки и нормализации, а также их преобразования в численный формат. Алгоритмы DAAL работают с данными в специальной форме – таблицами данных. Поэтому самым первым этапом при работе с библиотекой будет преобразование данных в эти самые таблицы.
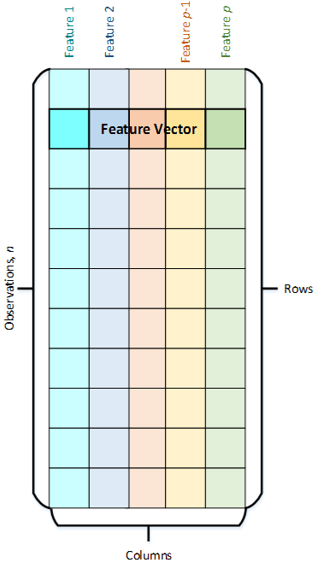
Что они из себя представляют? Каждый объект характеризуется набором атрибутов (Features) – свойств, характеризующих объект. Например, цвет глаз, возраст, температура воды и так далее. Набор атрибутов образует вектор свойств (Feature Vector) размера p. Эти векторы в свою очередь формируют множество наблюдений (Observations) размера n. В DAAL данные хранятся в виде таблиц, в которых строками являются наблюдения (Observations), а столбцами – свойства (Features).
Алгоритмы
Алгоритмы состоят из классов, реализующих анализ данных и их моделирование. Они включают декомпозицию, кластеризацию, классификацию и регрессионные алгоритмы, а также ассоциативные правила.
Алгоритмы могут выполняться в следующих режимах:
- Пакетная обработка (batch processing)
Алгоритмы работают со всем набором данных сразу и выдают результат. Все алгоритмы библиотеки поддерживают этот режим.
- Онлайн обработка (online processing)
Имеются более сложные случаи, при которых все данные не доступны сразу целиком, или, например, не помещаются в память. В этом случае может использоваться режим, при котором работа с данными происходит блоками, загружаемыми в память постепенно. Не все алгоритмы библиотеки имеют онлайн реализацию.
- Распределенная обработка (distributed processing)
Данные распределяются по нескольким вычислительным узлам. Промежуточный результат вычисляется на каждом узле, которые в итоге объединяются на главном узле. Так же как в случае с онлайн обработкой, не все алгоритмы библиотеки имеют распределенную реализацию, но инженеры Intel работают над этим.
Сервисы
Сервисы содержат классы и средства, используемые в алгоритмах и управление данными. Сюда относятся различные классы для выделения памяти, обработки ошибок, реализация коллекций и общих указателей.
Итого
Библиотека Intel DAAL имеет множество различных возможностей, и рассказать о них в рамках одного поста не получится. Я лишь показал зачем она нужна, с какой целью появилась на рынке и рассмотрел её основные составляющие. Хотелось бы услышать вопросы и комментарии тех, кому данный вопрос является интересным и продолжить разговор об этой интересной библиотеке. В планах рассказать об алгоритмах DAAL, а также показать примеры кода c её использованием.
Отмечу, что на сегодняшний день Intel DAAL является единственной библиотекой для аналитики данных, оптимизированной под Intel архитектуры.
