
Сегодня публикуем перевод третьей части серии материалов об ускорении instagram.com. В первой части мы говорили о предварительной загрузке данных, во второй — об отправке данных клиенту по инициативе сервера. Здесь речь пойдёт о кэшировании.

Мы уже отправляем данные клиентскому приложению, делая это в ходе загрузки страницы настолько рано, насколько возможно. Это значит, что единственным более быстрым способом доставки данных был бы такой, который вообще не предусматривает этапов, связанных с запросом информации клиентом или с отправкой её клиенту по инициативе сервера. Сделать это можно, воспользовавшись таким подходом к формированию страниц, при котором на первый план выступает кэш. Это, правда, означает, что нам придётся, хоть и очень ненадолго, показывать пользователю устаревшую информацию. При использовании такого подхода, мы, после загрузки страницы, немедленно демонстрируем пользователю кэшированную копию его ленты и историй, а затем, после того, как будут доступны свежие данные, заменяем всё это такими данными.
Для управления состоянием instagram.com мы используем Redux. В результате общий план реализации вышеописанной схемы выглядит так. Мы храним подмножество хранилища Redux на клиенте, в таблице indexedDB, заполняя это хранилище при первой загрузке страницы. Однако работа с indexedDB, загрузка данных с сервера и взаимодействие пользователя со страницей — это процессы асинхронные. В результате мы можем столкнуться с проблемами. Они заключаются в том, что пользователь работает со старым кэшированным состоянием, а нам нужно сделать так, чтобы действия пользователя применялись бы к новому состоянию при получении его с сервера.
Например, если мы будем пользоваться стандартными механизмами работы с кэшем, мы можем столкнуться со следующей неувязкой. Мы начинаем параллельную загрузку данных из кэша и из сети. Так как данные из кэша будут готовы быстрее сетевых данных, мы показываем их пользователю. Пользователь затем, например, лайкает пост, но после того, как ответ сервера, несущий в себе самую свежую информацию, приходит на клиент, эта информация перезаписывает сведения о лайкнутом посте. В этих свежих данных не будет сведений о лайке, который пользователь поставил кэшированной версии поста. Вот как это выглядит.
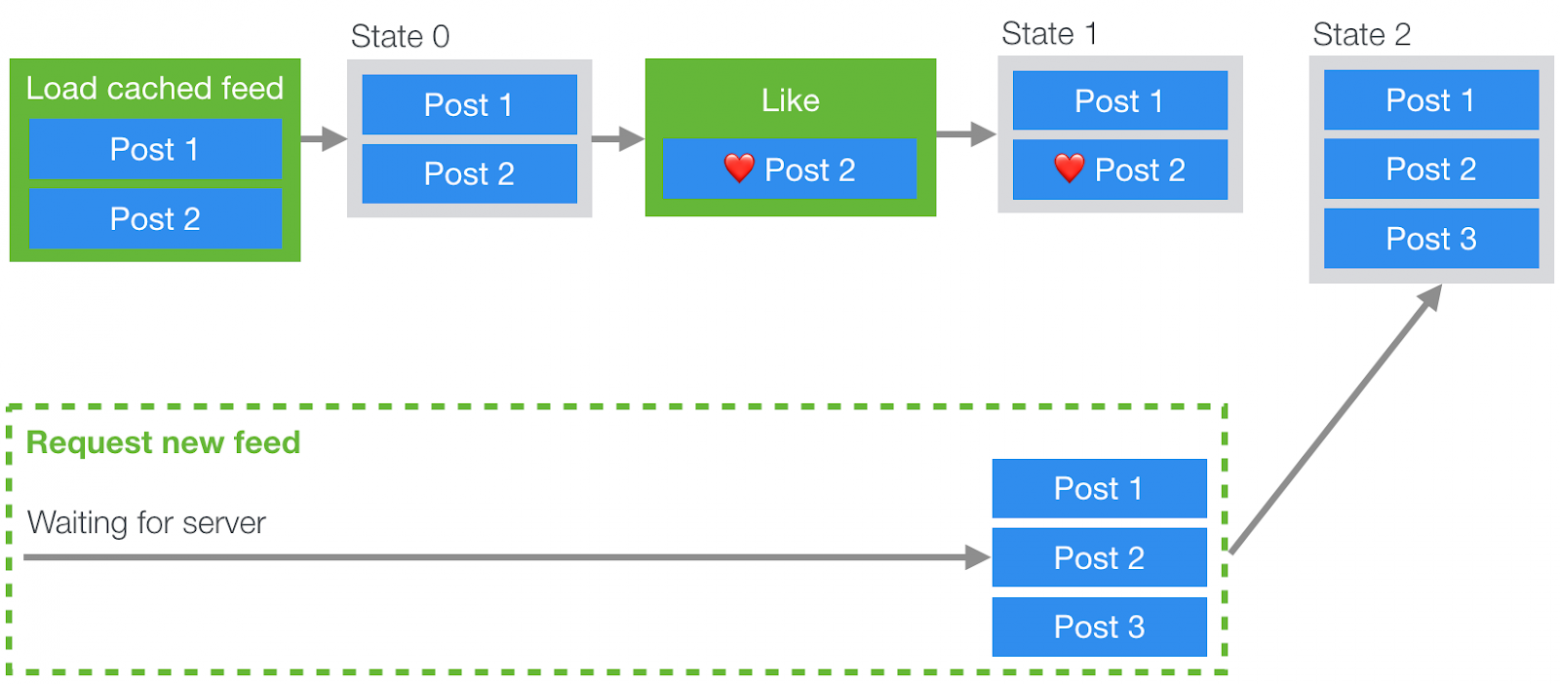
Состояние гонки, возникающее при взаимодействии пользователя с кэшированными данными (действия Redux выделены зелёным цветом, состояние — серым)
Для решения этой проблемы нам нужно было и поменять кэшированное состояние в соответствии с действиями пользователя, и сохранить сведения об этих действиях, что позволило бы воспроизвести их в применении к новому состоянию, поступившему с сервера. Если вы когда-нибудь пользовались Git или другой системой контроля версий, то вам эта задача может показаться знакомой. Предположим, что кэшированное состояние ленты — это локальная ветка репозитория, а ответ сервера со свежими данными — это ветка master. Если так — то можно сказать, что мы хотим выполнить операцию перебазирования, то есть — хотим взять изменения, зафиксированные в одной ветке (например — лайки, комментарии и так далее), и применить их к другой.
Эта идея приводит нас к следующей архитектуре системы:
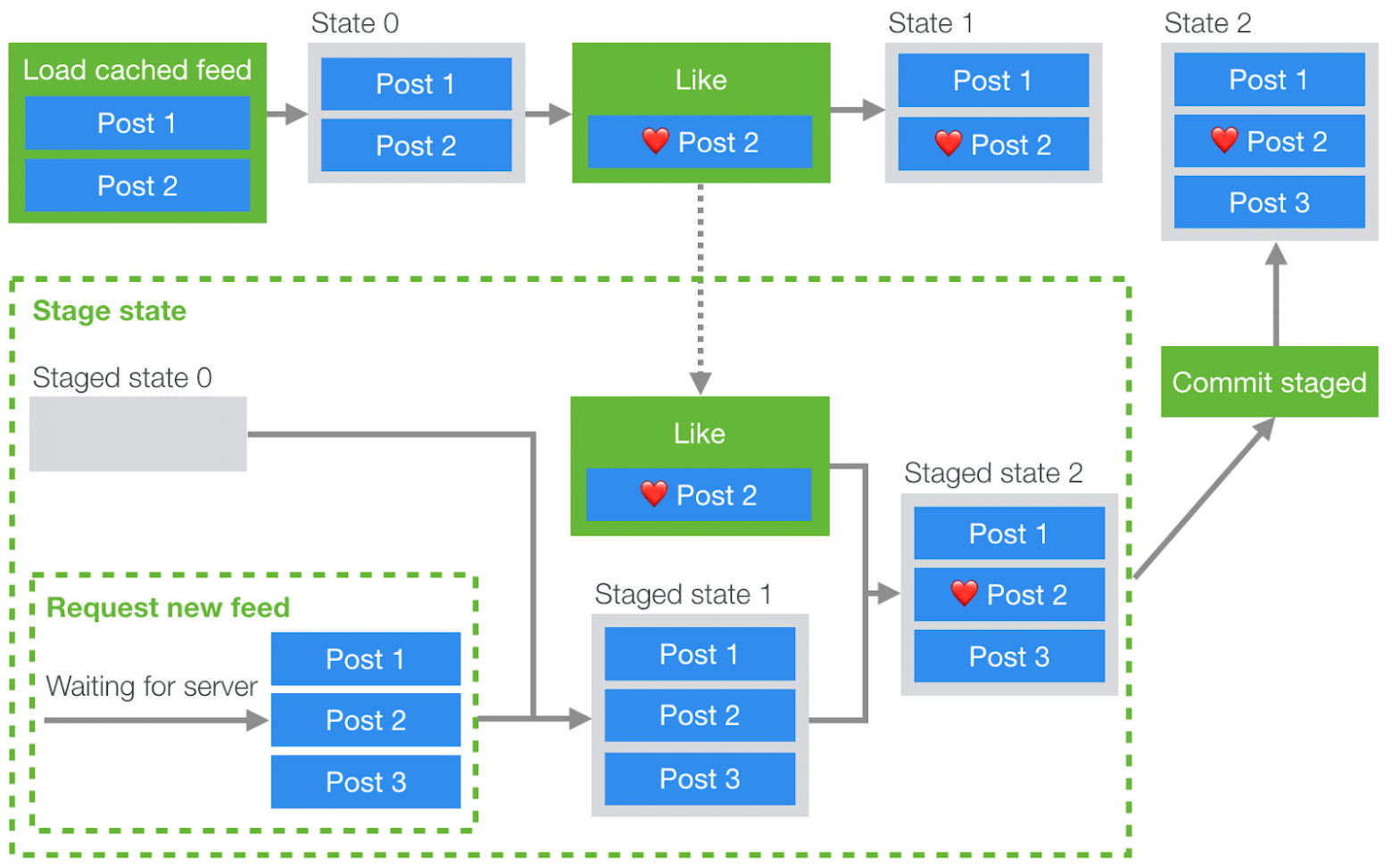
Решение проблемы, вызванной состоянием гонки, с использованием промежуточного состояния (действия Redux выделены зелёным цветом, состояние — серым)
Благодаря наличию промежуточного состояния мы можем повторно использовать все существующие редьюсеры. Это, кроме того, позволяет хранить промежуточное состояние (в котором содержатся самые свежие данные) отдельно от текущего состояния. А, так как работа с промежуточным состоянием реализована с использованием Redux, нам, для использования этого состояния, достаточно просто отправлять действия!
API, предназначенный для работы с промежуточным состоянием, состоит из двух основных функций. Это —
Там есть и несколько других функций, предназначенных, например, для отмены изменений и для обработки пограничных случаев, но мы их тут не рассматриваем.
Функция
Функция
Для того чтобы включить систему работы с промежуточным состоянием, мы обернули корневой редьюсер в расширитель возможностей редьюсера. Он обрабатывает действие
Использование для ленты и историй подхода к рендерингу, при котором на первый план выходит кэш, позволило ускорить вывод материалов, соответственно, на 2.5% и 11%. Это, кроме того, способствовало тому, что, в восприятии пользователей, веб-версия системы сблизилась с клиентами Instagram для iOS и Android.
Уважаемые читатели! Используете ли вы какие-нибудь подходы к оптимизации кэширования при работе над своими проектами?


Работа начинается с кэша
Мы уже отправляем данные клиентскому приложению, делая это в ходе загрузки страницы настолько рано, насколько возможно. Это значит, что единственным более быстрым способом доставки данных был бы такой, который вообще не предусматривает этапов, связанных с запросом информации клиентом или с отправкой её клиенту по инициативе сервера. Сделать это можно, воспользовавшись таким подходом к формированию страниц, при котором на первый план выступает кэш. Это, правда, означает, что нам придётся, хоть и очень ненадолго, показывать пользователю устаревшую информацию. При использовании такого подхода, мы, после загрузки страницы, немедленно демонстрируем пользователю кэшированную копию его ленты и историй, а затем, после того, как будут доступны свежие данные, заменяем всё это такими данными.
Для управления состоянием instagram.com мы используем Redux. В результате общий план реализации вышеописанной схемы выглядит так. Мы храним подмножество хранилища Redux на клиенте, в таблице indexedDB, заполняя это хранилище при первой загрузке страницы. Однако работа с indexedDB, загрузка данных с сервера и взаимодействие пользователя со страницей — это процессы асинхронные. В результате мы можем столкнуться с проблемами. Они заключаются в том, что пользователь работает со старым кэшированным состоянием, а нам нужно сделать так, чтобы действия пользователя применялись бы к новому состоянию при получении его с сервера.
Например, если мы будем пользоваться стандартными механизмами работы с кэшем, мы можем столкнуться со следующей неувязкой. Мы начинаем параллельную загрузку данных из кэша и из сети. Так как данные из кэша будут готовы быстрее сетевых данных, мы показываем их пользователю. Пользователь затем, например, лайкает пост, но после того, как ответ сервера, несущий в себе самую свежую информацию, приходит на клиент, эта информация перезаписывает сведения о лайкнутом посте. В этих свежих данных не будет сведений о лайке, который пользователь поставил кэшированной версии поста. Вот как это выглядит.
Состояние гонки, возникающее при взаимодействии пользователя с кэшированными данными (действия Redux выделены зелёным цветом, состояние — серым)
Для решения этой проблемы нам нужно было и поменять кэшированное состояние в соответствии с действиями пользователя, и сохранить сведения об этих действиях, что позволило бы воспроизвести их в применении к новому состоянию, поступившему с сервера. Если вы когда-нибудь пользовались Git или другой системой контроля версий, то вам эта задача может показаться знакомой. Предположим, что кэшированное состояние ленты — это локальная ветка репозитория, а ответ сервера со свежими данными — это ветка master. Если так — то можно сказать, что мы хотим выполнить операцию перебазирования, то есть — хотим взять изменения, зафиксированные в одной ветке (например — лайки, комментарии и так далее), и применить их к другой.
Эта идея приводит нас к следующей архитектуре системы:
- При загрузке страницы мы отправляем на сервер запрос на загрузку новых данных (или ждём их отправки по инициативе сервера).
- Создаём промежуточное (staged) подмножество состояния Redux.
- В процессе ожидания данных от сервера мы сохраняем отправленные действия.
- После получения данных от сервера мы выполняем действия с новыми данными и воспроизводим сохранённые действия на новых данных, применяя их к промежуточному состоянию.
- После этого мы фиксируем изменения и заменяем текущее состояние промежуточным.
Решение проблемы, вызванной состоянием гонки, с использованием промежуточного состояния (действия Redux выделены зелёным цветом, состояние — серым)
Благодаря наличию промежуточного состояния мы можем повторно использовать все существующие редьюсеры. Это, кроме того, позволяет хранить промежуточное состояние (в котором содержатся самые свежие данные) отдельно от текущего состояния. А, так как работа с промежуточным состоянием реализована с использованием Redux, нам, для использования этого состояния, достаточно просто отправлять действия!
API
API, предназначенный для работы с промежуточным состоянием, состоит из двух основных функций. Это —
stagingAction и stagingCommit:function stagingAction(
key: string,
promise: Promise<Action>,
): AsyncAction<State, Action>
function stagingCommit(key: string): AsyncAction<State, Action>Там есть и несколько других функций, предназначенных, например, для отмены изменений и для обработки пограничных случаев, но мы их тут не рассматриваем.
Функция
stagingAction принимает промис, разрешающийся событием, которое нужно отправить в промежуточное состояние. Эта функция инициализирует промежуточное состояние и отслеживает действия, которые были отправлены с момента его инициализации. Если сопоставить это с системами контроля версий, то окажется, что мы имеем дело с созданием локальной ветки. Происходящие действия будут поставлены в очередь и применены к промежуточному состоянию после поступления новых данных.Функция
stagingCommit заменяет текущее состояние промежуточным. При этом, если ожидается завершение неких асинхронных операций, выполняемых над промежуточным состоянием, то система, перед заменой, дождётся завершения этих операций. Это похоже на операцию перебазирования, когда локальные изменения (из ветки, хранящей кэш) применяются поверх ветки master (поверх новых данных, полученных с сервера), что приводит к тому, что локальная версия состояния оказывается актуальной.Для того чтобы включить систему работы с промежуточным состоянием, мы обернули корневой редьюсер в расширитель возможностей редьюсера. Он обрабатывает действие
stagingCommit и применяет ранее сохранённые действия к новому состоянию. Для того чтобы всем этим воспользоваться, нам нужно лишь отправлять действия, а всё остальное будет сделано автоматически. Например, если мы хотим загрузить новую ленту и внести её данные в промежуточное состояние, мы можем поступить примерно так:function fetchAndStageFeed() {
return stagingAction(
'feed',
(async () => {
const {data} = await fetchFeedTimeline();
return {
type: FEED_LOADED,
...data,
};
})(),
);
}
// Загружаем новую ленту и помещаем её в промежуточное состояние
store.dispatch(fetchAndStageFeed());
// любые другие действия, отправленные до действия stagingCommit,
// будут применены к промежуточному состоянию 'feed'
// Перенос промежуточного состояния в текущее
store.dispatch(stagingCommit('feed'));Использование для ленты и историй подхода к рендерингу, при котором на первый план выходит кэш, позволило ускорить вывод материалов, соответственно, на 2.5% и 11%. Это, кроме того, способствовало тому, что, в восприятии пользователей, веб-версия системы сблизилась с клиентами Instagram для iOS и Android.
Уважаемые читатели! Используете ли вы какие-нибудь подходы к оптимизации кэширования при работе над своими проектами?
